Bonjour à tous! Je m'appelle Pavel Agaletsky. Je travaille en tant que chef d'équipe dans une équipe qui développe un système de livraison Lamoda. En 2018, j'ai pris la parole lors de la conférence HighLoad ++, et aujourd'hui je veux présenter une transcription de mon rapport.
Mon sujet est dédié à l'expérience de notre entreprise dans le déploiement de systèmes et services dans différents environnements. À partir de notre époque préhistorique, lorsque nous avons déployé tous les systèmes sur des serveurs virtuels réguliers, pour finir par une transition progressive de Nomad vers un déploiement vers Kubernetes. Je vais vous dire pourquoi nous avons fait cela et quels problèmes nous avons rencontrés dans le processus.
Déployer des applications sur VM
Pour commencer, il y a 3 ans, tous les systèmes et services de l'entreprise étaient déployés sur des serveurs virtuels ordinaires. Techniquement, il a été organisé de manière à ce que tout le code de nos systèmes soit déposé et assemblé à l'aide d'outils de construction automatique utilisant jenkins. Avec Ansible, il déployait notre système de contrôle de version sur des serveurs virtuels. De plus, chaque système qui était dans notre entreprise a été déployé au moins sur 2 serveurs: l'un d'eux était en tête, le second en queue. Ces deux systèmes étaient absolument identiques l'un à l'autre dans tous leurs paramètres, alimentation, configuration, etc. La seule différence entre eux est que head a reçu du trafic utilisateur, tandis que tail n'a jamais reçu de trafic utilisateur.
Pourquoi cela at-il été fait?
Lorsque nous avons déployé de nouvelles versions de notre application, nous voulions offrir la possibilité d'un déploiement transparent, c'est-à-dire sans conséquences notables pour les utilisateurs. Cela a été réalisé en raison du fait que la prochaine version assemblée utilisant Ansible a été déployée sur la queue. Là-bas, les personnes impliquées dans le déploiement pouvaient vérifier et s'assurer que tout allait bien: toutes les mesures, sections et applications fonctionnaient; les scripts nécessaires sont lancés. Ce n'est qu'après avoir été convaincu que tout allait bien que le trafic a été inversé. Il a commencé à aller vers le serveur qui était la queue avant. Et celui qui était la tête avant, a été laissé sans trafic utilisateur, alors qu'avec la version précédente de notre application.
Ainsi, pour les utilisateurs, c'était transparent. Parce que la commutation est simultanée, car il s'agit simplement d'une commutation d'équilibrage. Il est très facile de revenir à la version précédente en rétablissant simplement l'équilibreur. Nous pouvions également voir la capacité de production de l’application avant même que le trafic des utilisateurs ne s’y rende, ce qui était assez pratique.
Quels avantages avons-nous vu dans tout cela?
- Tout d'abord, cela fonctionne tout simplement. Tout le monde comprend le fonctionnement de ce schéma de déploiement, car la plupart des gens ont déjà déployé sur des serveurs virtuels ordinaires.
- C'est assez fiable , car la technologie de déploiement est simple, testée par des milliers d'entreprises. Des millions de serveurs sont déployés de cette façon. Il est difficile de casser quelque chose.
- Et enfin, nous pourrions obtenir des déploiements atomiques . Déploiements qui se produisent simultanément pour les utilisateurs, sans étape notable de basculement entre l'ancienne version et la nouvelle.
Mais en cela, nous avons également constaté plusieurs lacunes:
- Outre l'environnement de production, l'environnement de développement, il existe d'autres environnements. Par exemple, qa et préproduction. A cette époque, nous disposions de nombreux serveurs et d'une soixantaine de services. Pour cette raison, il était nécessaire que chaque service maintienne la version de la machine virtuelle qui lui était pertinente . De plus, si vous souhaitez mettre à jour des bibliothèques ou installer de nouvelles dépendances, vous devez le faire dans tous les environnements. Il était également nécessaire de synchroniser l'heure à laquelle vous alliez déployer la prochaine nouvelle version de votre application avec l'heure à laquelle devops a effectué les réglages d'environnement nécessaires. Dans ce cas, il est facile de se retrouver dans une situation où notre environnement sera légèrement différent à la fois dans tous les environnements consécutifs. Par exemple, dans l'environnement QA, il y aura certaines versions de bibliothèques, et en production - d'autres, ce qui entraînera des problèmes.
- Difficulté à mettre à jour les dépendances de votre application. Cela ne dépend pas de vous, mais de l'autre équipe. À savoir, à partir de la commande devops, qui prend en charge le serveur. Vous devez définir une tâche appropriée pour eux et donner une description de ce que vous voulez faire.
- À cette époque, nous voulions également diviser les grands grands monolithes que nous avions en petits services séparés, car nous comprenions qu'il y en aurait de plus en plus. À l'époque, nous en avions déjà plus de 100. Il était nécessaire pour chaque nouveau service de créer une nouvelle machine virtuelle distincte, qui doit également être entretenue et déployée. De plus, vous n'avez pas besoin d'une voiture, mais d'au moins deux. À cela, l'environnement QA est toujours en train d'être ajouté. Cela pose des problèmes et rend la création et le lancement de nouveaux systèmes plus difficiles, coûteux et longs pour vous.
Par conséquent, nous avons décidé qu'il serait plus pratique de passer du déploiement de machines virtuelles ordinaires au déploiement de nos applications dans le conteneur Docker. Si vous avez un docker, vous avez besoin d'un système capable d'exécuter l'application dans le cluster, car vous ne pouvez pas simplement soulever le conteneur. Habituellement, vous souhaitez garder une trace du nombre de conteneurs levés afin qu'ils montent automatiquement. Pour cette raison, nous avons dû choisir un système de contrôle.
Nous avons longuement réfléchi à celui qui pouvait être pris. Le fait est qu'à cette époque, cette pile de déploiements sur des serveurs virtuels ordinaires était quelque peu dépassée, car il n'y avait pas les dernières versions des systèmes d'exploitation. À un moment donné, même FreeBSD était là, ce qui n'était pas très pratique à maintenir. Nous avons compris que vous devez migrer vers Docker le plus rapidement possible. Nos développeurs ont examiné leur expérience existante avec différentes solutions et ont choisi un système comme Nomad.
Passer à Nomad
Nomad est un produit HashiCorp. Ils sont également connus pour leurs autres décisions:
 Consul
Consul est un outil de découverte de services.
Terraform est un système de gestion de serveur qui vous permet de les configurer via une configuration appelée infrastructure en tant que code.
Vagrant vous permet de déployer des machines virtuelles localement ou dans le cloud via des fichiers de configuration spécifiques.
Nomad à cette époque semblait une solution assez simple à laquelle vous pouvez rapidement passer sans changer l'infrastructure entière. De plus, il est assez facilement maîtrisé. Par conséquent, nous l'avons choisi comme système de filtrage pour notre conteneur.
Que faut-il pour déployer complètement votre système sur Nomad?
- Tout d'abord, vous avez besoin de l' image docker de votre application. Vous devez le créer et le mettre dans le stockage d'images Docker. Dans notre cas, c'est artificiel - un tel système qui vous permet d'y insérer divers artefacts de différents types. Il peut stocker des archives, des images de docker, des packages de compositeur PHP, des packages NPM, etc.
- Vous avez également besoin d'un fichier de configuration qui indique à Nomad quoi, où et combien vous souhaitez déployer.
Lorsque nous parlons de Nomad, il utilise le langage HCL comme format de fichier d'informations, qui signifie
HashiCorp Configuration Language . Il s'agit d'un sur-ensemble de Yaml qui vous permet de décrire votre service en termes de nomade.

Il vous permet de dire combien de conteneurs vous souhaitez déployer, à partir de quelles images les transférer divers paramètres lors du déploiement. Ainsi, vous alimentez ce fichier Nomad, et il lance des conteneurs en production conformément à celui-ci.
Dans notre cas, nous avons réalisé que le simple fait d'écrire exactement les mêmes fichiers HLC identiques pour chaque service ne serait pas très pratique, car il existe de nombreux services et parfois vous souhaitez les mettre à jour. Il arrive qu'un service soit déployé non pas dans un cas, mais dans les plus différents. Par exemple, l'un des systèmes que nous avons en production compte plus de 100 instances dans la production. Ils sont lancés à partir des mêmes images, mais diffèrent dans les paramètres de configuration et les fichiers de configuration.
Par conséquent, nous avons décidé qu'il serait pratique pour nous de stocker tous nos fichiers de configuration pour le déploiement dans un référentiel commun. Ainsi, ils sont devenus observables: ils étaient faciles à entretenir et il était possible de voir quels systèmes nous avions. Si nécessaire, il est également facile de mettre à jour ou de modifier quelque chose. L'ajout d'un nouveau système n'est pas non plus difficile - entrez simplement le fichier de configuration dans le nouveau répertoire. À l'intérieur, il y a les fichiers: service.hcl, qui contient une description de notre service, et quelques fichiers env qui permettent à ce service, déployé en production, de configurer.

Cependant, certains de nos systèmes sont déployés dans le prod non pas en un seul exemplaire, mais en plusieurs à la fois. Par conséquent, nous avons décidé qu'il serait pratique pour nous de ne pas stocker les configurations sous leur forme pure, mais sous forme de modèle. Et comme langue de modèle, nous avons choisi
jinja 2 . Dans ce format, nous stockons à la fois les configurations du service lui-même et les fichiers env nécessaires.
De plus, nous avons placé dans le référentiel un script commun de déploiement pour tous les projets, qui vous permet de lancer et déployer votre service en production, dans l'environnement souhaité, dans la cible souhaitée. Dans le cas où nous avons transformé notre configuration HCL en modèle, le fichier HCL, qui était auparavant une configuration Nomad normale, a dans ce cas commencé à avoir un aspect légèrement différent.
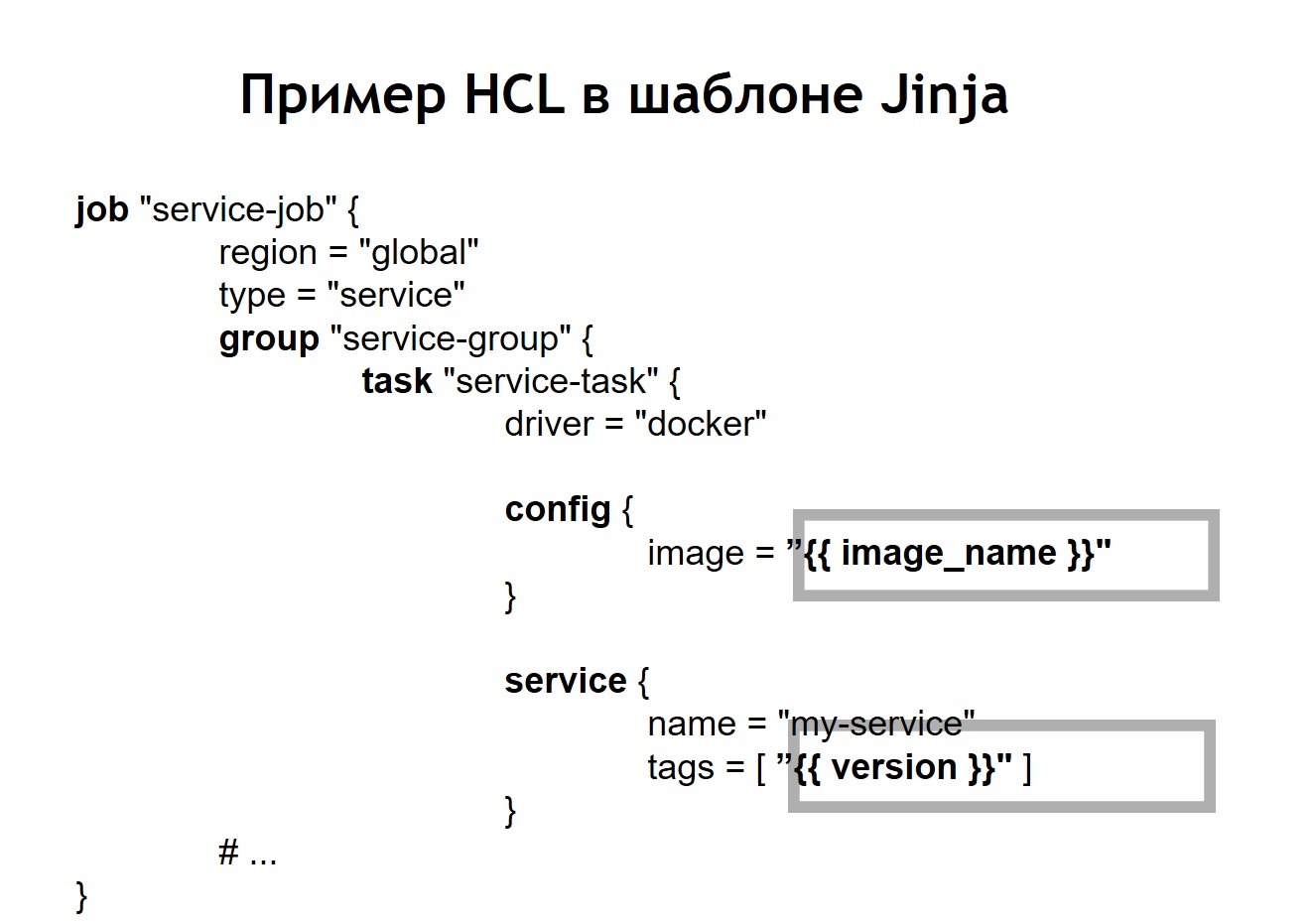
Autrement dit, nous avons remplacé certaines variables dans le fichier de configuration par des insertions de variables, qui sont extraites de fichiers env ou d'autres sources. De plus, nous avons pu collecter des fichiers HL de manière dynamique, c'est-à-dire que nous pouvons utiliser non seulement les insertions de variables habituelles. Étant donné que jinja prend en charge les boucles et les conditions, vous pouvez également y créer des fichiers de configuration, qui varient en fonction de l'emplacement exact où vous déployez vos applications.
Par exemple, vous souhaitez déployer votre service en pré-production et en production. Supposons qu'en pré-production, vous ne souhaitiez pas exécuter les scripts de couronne, vous souhaitiez simplement voir le service sur un domaine distinct pour vous assurer qu'il fonctionne. Pour toute personne déployant un service, le processus semble très simple et transparent. Il suffit d'exécuter le fichier deploy.sh, de spécifier le service que vous souhaitez déployer et dans quelle cible. Par exemple, vous souhaitez déployer un certain système en Russie, en Biélorussie ou au Kazakhstan. Pour ce faire, modifiez simplement l'un des paramètres et vous obtiendrez le fichier de configuration correct.
Lorsque le service Nomad est déjà déployé dans votre cluster, il ressemble à ceci.
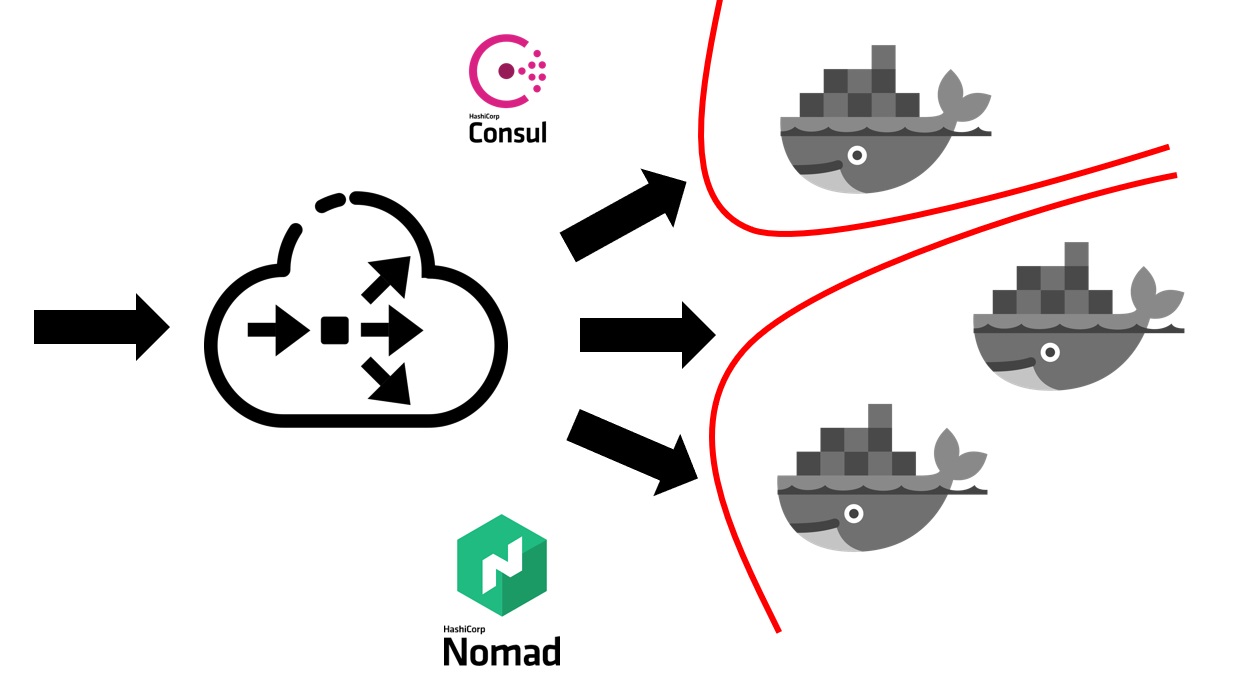
Vous avez d'abord besoin d'un équilibreur extérieur qui prendra tout le trafic utilisateur en lui-même. Il travaillera avec le consul et découvrira auprès de lui où, sur quel nœud, à quelle adresse IP, il existe un service spécifique qui correspond à un nom de domaine particulier. Les services au Consul proviennent de Nomad lui-même. Comme ce sont des produits de la même entreprise, ils sont bien connectés. Nous pouvons dire que Nomad prêt à l'emploi peut enregistrer tous les services qui y sont lancés au sein du Consul.
Une fois que votre équilibreur externe a découvert le service auquel envoyer le trafic, il le redirige vers le conteneur approprié ou vers plusieurs conteneurs correspondant à votre application. Naturellement, il faut aussi penser à la sécurité. Même si tous les services s'exécutent sur les mêmes machines virtuelles dans des conteneurs, cela nécessite généralement l'interdiction de l'accès gratuit de tout service à tout autre. Nous y sommes parvenus grâce à la segmentation. Chaque service a été lancé dans son propre réseau virtuel, sur lequel des règles de routage et des règles pour autoriser / refuser l'accès à d'autres systèmes et services ont été prescrites. Ils pourraient être situés à l'intérieur et à l'extérieur de ce cluster. Par exemple, si vous souhaitez empêcher un service de se connecter à une base de données spécifique, cela peut être fait par segmentation au niveau du réseau. Autrement dit, même par erreur, vous ne pouvez pas vous connecter accidentellement d'un environnement de test à votre base de production.
Combien nous a coûté la transition en termes de ressources humaines?
La transition de l'ensemble de l'entreprise vers Nomad a pris environ 5-6 mois. Nous avons changé de service, mais à un rythme assez rapide. Chaque équipe a dû créer ses propres conteneurs de services.
Nous avons adopté une telle approche que chaque équipe est responsable des images docker de leurs systèmes de manière indépendante. Les devops fournissent également l'infrastructure générale nécessaire au déploiement, c'est-à-dire la prise en charge du cluster lui-même, la prise en charge du système CI, etc. Et à cette époque, plus de 60 systèmes avaient été déplacés vers Nomad, il s'est avéré qu'environ 2 000 conteneurs.
Devops est responsable de l'infrastructure globale de tout ce qui est lié au déploiement, aux serveurs. Et chaque équipe de développement, à son tour, est responsable de la mise en œuvre des conteneurs pour son système spécifique, car c'est l'équipe qui sait ce dont elle a généralement besoin dans un conteneur particulier.
Raisons d'abandonner Nomad
Quels avantages avons-nous obtenus en passant au déploiement à l'aide de Nomad et de Docker également?
- Nous avons fourni les mêmes conditions pour tous les environnements. Dans une entreprise de développement, QA-environnement, pré-production, production, les mêmes images conteneurs sont utilisées, avec les mêmes dépendances. Par conséquent, vous n'avez pratiquement aucune chance que la production se révèle différente de ce que vous avez précédemment testé localement ou sur un environnement de test.
- Nous avons également constaté qu'il est assez facile d'ajouter un nouveau service . Du point de vue du déploiement, tout nouveau système est lancé très simplement. Il suffit d'aller dans le référentiel qui stocke les configurations, d'y ajouter la configuration suivante pour votre système et vous êtes prêt. Vous pouvez déployer votre système en production sans effort supplémentaire de devops.
- Tous les fichiers de configuration dans un référentiel commun se sont avérés être surveillés . À ce moment, lorsque nous avons déployé nos systèmes à l'aide de serveurs virtuels, nous avons utilisé Ansible, dans lequel les configurations se trouvaient dans le même référentiel. Cependant, pour la plupart des développeurs, il était un peu plus difficile de travailler avec. Ici, le volume de configurations et de code que vous devez ajouter pour déployer le service est devenu beaucoup plus petit. De plus, pour les devops, il est très facile de le réparer ou de le changer. Dans le cas de transitions, par exemple, sur la nouvelle version de Nomad, ils peuvent prendre et mettre à jour massivement tous les fichiers d'exploitation se trouvant au même endroit.
Mais nous avons également fait face à plusieurs lacunes:
Il s'est avéré que nous
ne pouvions pas réaliser des déploiements homogènes dans le cas de Nomad. En déplaçant des conteneurs dans des conditions différentes, il pouvait s'avérer qu'il fonctionnait et Nomad le percevait comme un conteneur prêt à accepter le trafic. Cela s'est produit avant même que l'application à l'intérieur ne parvienne à démarrer. Pour cette raison, le système a commencé pendant une courte période à produire 500 erreurs, car le trafic a commencé à aller vers le conteneur, qui n'est pas encore prêt à le recevoir.
Nous avons rencontré quelques
bugs . Le bogue le plus important est que Nomad n'accepte pas très bien un grand cluster si vous avez de nombreux systèmes et conteneurs. Lorsque vous souhaitez mettre en service l'un des serveurs inclus dans le cluster Nomad, il y a une forte probabilité que le cluster ne se sente pas très bien et se désagrège. Une partie des conteneurs peut par exemple tomber et ne pas monter - cela vous coûtera par la suite très cher si tous vos systèmes de production sont situés dans un cluster géré par Nomad.
Par conséquent, nous avons décidé de réfléchir à la prochaine étape. À cette époque, nous sommes devenus beaucoup plus conscients de ce que nous voulons réaliser. À savoir: nous voulons de la fiabilité, un peu plus de fonctions que Nomad et un système plus mature et plus stable.
À cet égard, notre choix s'est porté sur Kubernetes comme plate-forme la plus populaire pour le lancement de clusters. Surtout à condition que la taille et la quantité de nos conteneurs soient assez importantes. À ces fins, Kubernetes semblait le système le plus approprié de ceux que nous pouvions voir.
Aller à Kubernetes
Je vais parler un peu des concepts de base de Kubernetes et en quoi ils diffèrent de Nomad.
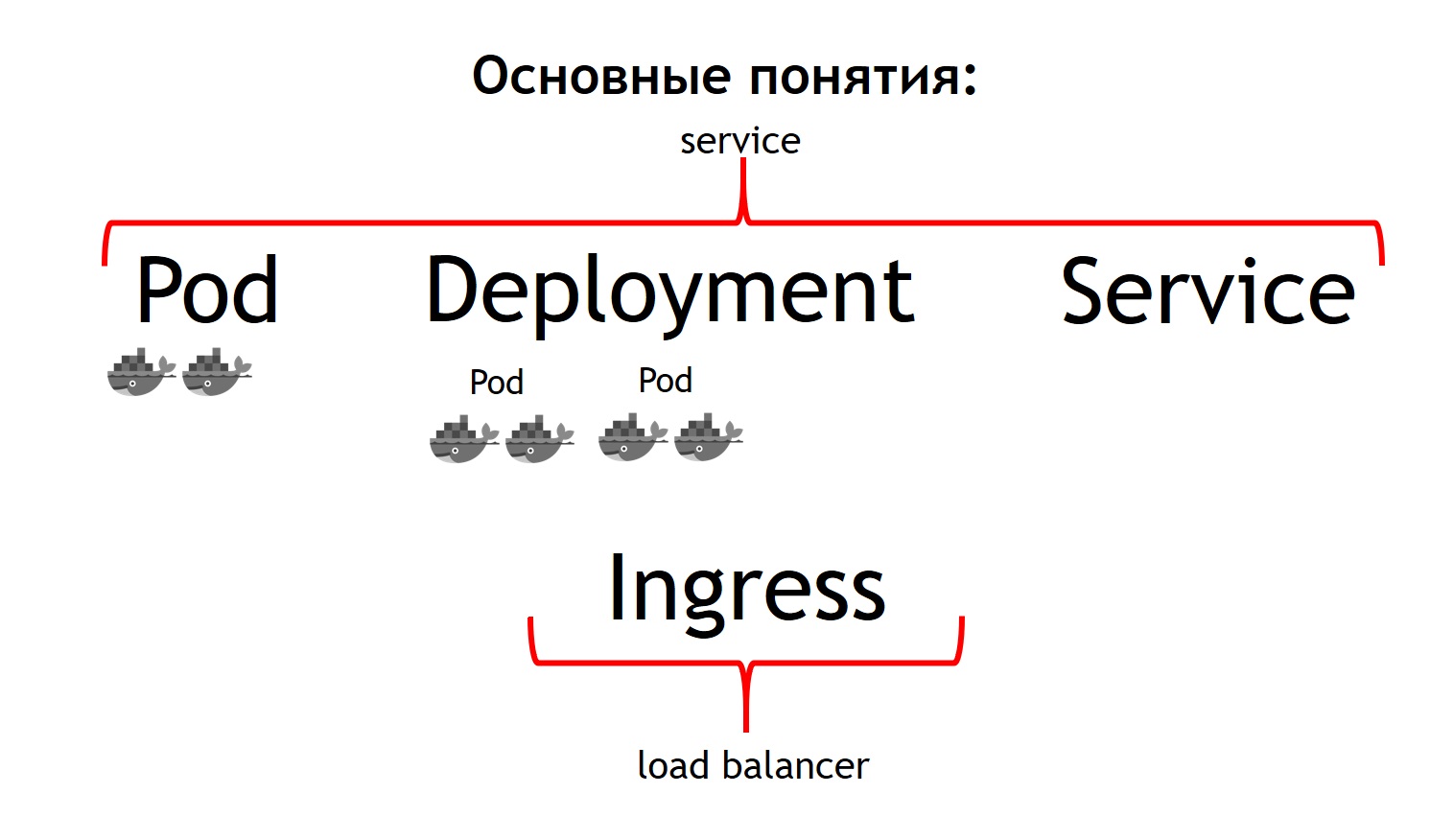
Tout d'abord, le concept le plus élémentaire de Kubernetes est le concept de pod.
Un pod est un groupe d'un ou plusieurs conteneurs qui fonctionnent toujours ensemble. Et ils semblent toujours fonctionner strictement sur la même machine virtuelle. Ils sont disponibles entre eux via IP 127.0.0.1 sur différents ports.
Supposons que vous ayez une application PHP composée de nginx et php-fpm - un circuit classique. Très probablement, vous voulez que les conteneurs nginx et php-fpm soient toujours ensemble. Kubernetes le fait en les décrivant comme une seule gousse commune. C'est exactement ce que nous n'avons pas pu obtenir avec l'aide de Nomad.
Le deuxième concept est le
déploiement . Le fait est que la cosse elle-même est une chose éphémère, elle démarre et disparaît. Que vous souhaitiez d'abord supprimer tous vos conteneurs précédents, puis lancer de nouvelles versions en même temps, ou que vous souhaitiez les déployer progressivement - c'est le concept même dont le déploiement est responsable. Il décrit comment vous déployez vos pods, en combien et comment les mettre à jour.
Le troisième concept est le
service . Votre service est en fait votre système, qui reçoit du trafic, puis le dirige vers un ou plusieurs pods correspondant à votre service. Autrement dit, cela vous permet de dire que tout le trafic entrant vers un tel service avec un tel nom doit être envoyé à ces pods particuliers. Et en même temps, il vous offre un équilibrage du trafic. Autrement dit, vous pouvez exécuter deux modules de votre application, et tout le trafic entrant sera équilibré de manière égale entre les modules liés à ce service.
Et le quatrième concept de base est
Ingress . Il s'agit d'un service qui s'exécute dans un cluster Kubernetes. Il agit comme un équilibreur de charge externe, qui prend en charge toutes les demandes. En raison de l'API, Kubernetes Ingress peut déterminer où ces demandes doivent être envoyées. Et il le fait de manière très flexible. Vous pouvez dire que toutes les demandes adressées à cet hôte et à cette URL sont envoyées à ce service. Et nous envoyons ces demandes venant à cet hôte et à une autre URL vers un autre service.
La chose la plus cool du point de vue de celui qui développe l'application est que vous êtes capable de tout gérer vous-même. Après avoir défini la configuration Ingress, vous pouvez envoyer tout le trafic provenant d'une telle API vers des conteneurs distincts enregistrés, par exemple, vers Go. Mais ce trafic venant du même domaine, mais vers une URL différente, devrait être envoyé vers des conteneurs écrits en PHP, où il y a beaucoup de logique, mais ils ne sont pas très rapides.
Si nous comparons tous ces concepts avec Nomad, alors nous pouvons dire que les trois premiers concepts sont tous ensemble Service. Et le dernier concept de Nomad lui-même manque. Nous avons utilisé un équilibreur externe comme ça: il peut être haproxy, nginx, nginx + et ainsi de suite. Dans le cas d'un cube, vous n'avez pas besoin d'introduire ce concept supplémentaire séparément. Cependant, si vous regardez Ingress à l'intérieur, c'est soit nginx, soit haproxy, soit traefik, mais comme s'il était intégré à Kubernetes.
Tous les concepts que j'ai décrits sont essentiellement les ressources qui existent au sein du cluster Kubernetes. Pour les décrire dans le cube, le format yaml est utilisé, plus lisible et familier que les fichiers HCl dans le cas de Nomad. Mais structurellement, ils décrivent dans le cas, par exemple, de la même chose. Ils disent - je veux déployer tel ou tel pod ici et là, avec telle ou telle image, en telle ou telle quantité.

De plus, nous avons réalisé que nous ne voulions pas créer chaque ressource individuelle de nos propres mains: déploiement, services, Ingress, etc. Au lieu de cela, nous voulions décrire chaque système déployé en termes de Kubernetes pendant le déploiement afin de ne pas avoir à recréer manuellement toutes les dépendances de ressources nécessaires dans le bon ordre. Helm a été choisi comme système qui nous a permis de le faire.
Concepts clés à la barre
Helm est un
gestionnaire de packages pour Kubernetes. Il est très similaire à la façon dont les gestionnaires de packages fonctionnent dans les langages de programmation. Ils vous permettent de stocker un service composé, par exemple, de déploiement nginx, de déploiement php-fpm, d'une configuration pour Ingress, de configmaps (il s'agit d'une entité qui vous permet de définir env et d'autres paramètres pour votre système) sous la forme de soi-disant graphiques. En même temps, Helm
court au-dessus de Kubernetes . Autrement dit, ce n'est pas une sorte de système qui se démarque, mais juste un autre service qui s'exécute à l'intérieur du cube. Vous interagissez avec lui via son API via une commande de console. Sa commodité et son charme sont que même si la barre se casse ou que vous la supprimez du cluster, vos services ne disparaîtront pas, car la barre ne sert essentiellement qu'à démarrer le système. Kubernetes lui-même est responsable de la disponibilité et de l'état des services.
Nous avons également réalisé que la standardisation , qui auparavant devait être effectuée de manière indépendante par l'introduction de jinja dans nos configurations, est l'une des principales caractéristiques de Helm. Toutes les configurations que vous créez pour vos systèmes sont stockées dans helm sous la forme de modèles similaires un peu comme jinja, mais, en fait, en utilisant le modèle de langage Go dans lequel helm est écrit, comme Kubernetes.Helm nous ajoute quelques concepts supplémentaires.Le graphique est une description de votre service. D'autres gestionnaires de packages l'appelleraient package, bundle ou quelque chose comme ça. C'est ce qu'on appelle le graphique ici.Les valeurs sont les variables que vous souhaitez utiliser pour créer vos configurations à partir de modèles.Relâchez. Chaque fois qu'un service déployé à l'aide de helm reçoit une version incrémentielle de la version. Helm se souvient de la configuration du service dans la précédente, l'année précédant la dernière version, etc. Par conséquent, si vous devez annuler, exécutez simplement la commande de rappel de barre, en lui indiquant la version précédente de la version. Même si au moment de la restauration, la configuration correspondante dans votre référentiel n'est pas disponible, helm se souvient toujours de ce qu'elle était et restaure votre système dans l'état où il était dans la version précédente.Dans le cas où nous utilisons helm, les configurations habituelles pour Kubernetes se transforment également en modèles, dans lesquels il est possible d'utiliser des variables, des fonctions, d'appliquer des opérateurs conditionnels. Ainsi, vous pouvez collecter la configuration de votre service en fonction de l'environnement.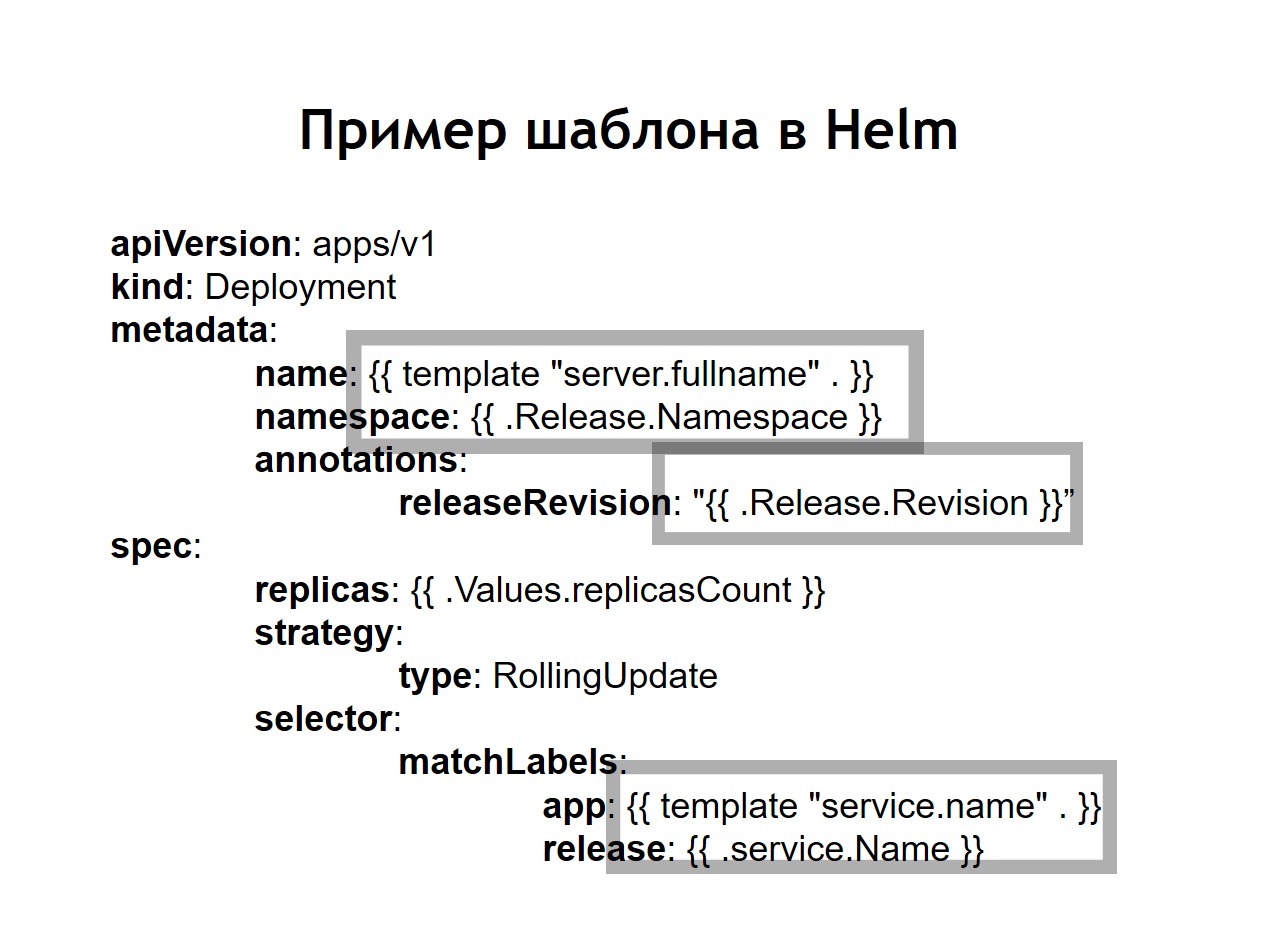 Dans la pratique, nous avons décidé de faire un peu différemment que dans le cas de Nomad. Si, dans Nomad dans le même référentiel, les deux configurations pour le déploiement et les n-variables nécessaires au déploiement de notre service étaient stockées, nous avons décidé de les diviser en deux référentiels distincts. Seules les n-variables nécessaires au déploiement sont stockées dans le référentiel de déploiement et les configurations ou les graphiques sont stockés dans le référentiel de barre.
Dans la pratique, nous avons décidé de faire un peu différemment que dans le cas de Nomad. Si, dans Nomad dans le même référentiel, les deux configurations pour le déploiement et les n-variables nécessaires au déploiement de notre service étaient stockées, nous avons décidé de les diviser en deux référentiels distincts. Seules les n-variables nécessaires au déploiement sont stockées dans le référentiel de déploiement et les configurations ou les graphiques sont stockés dans le référentiel de barre. Qu'est-ce que cela nous a apporté?Malgré le fait que nous ne stockons aucune donnée vraiment sensible dans les fichiers de configuration eux-mêmes. Par exemple, les mots de passe de base de données. Ils sont stockés en tant que secrets dans Kubernetes, mais néanmoins, il y a encore des choses que nous ne voulons pas donner à tout le monde de suite. Par conséquent, l'accès au référentiel de déploiement est plus limité et le référentiel de barre contient simplement une description du service. Pour cette raison, il est possible de donner accès à un plus grand cercle de personnes en toute sécurité.Étant donné que nous avons non seulement la production, mais aussi d'autres environnements, grâce à cette séparation, nous pouvons réutiliser nos cartes de barre pour déployer des services non seulement en production, mais aussi, par exemple, en environnement QA. Même les déployer localement à l'aide de Minikube est une telle chose pour exécuter Kubernetes localement.À l'intérieur de chaque référentiel, nous avons laissé une séparation dans des répertoires séparés pour chaque service. Autrement dit, à l'intérieur de chaque répertoire, il y a des modèles liés au graphique correspondant et décrivant les ressources qui doivent être déployées pour lancer notre système. Dans le référentiel de déploiement, nous n'avons laissé que des enves. Dans ce cas, nous n'avons pas utilisé de modèles avec jinja, car la barre elle-même donne des modèles hors de la boîte - c'est l'une de ses principales fonctions.Nous avons laissé le script de déploiement, deploy.sh, qui simplifie et standardise le lancement pour le déploiement à l'aide de helm. Ainsi, pour quiconque souhaite se déployer, l'interface de déploiement est exactement la même que dans le cas du déploiement via Nomad. Le même deploy.sh, le nom de votre service et l'endroit où vous souhaitez le déployer. Cela fait démarrer la barre à l'intérieur. Il, à son tour, recueille les configurations à partir de modèles, y substitue les fichiers de valeurs nécessaires, puis les déploie, les mettant dans Kubernetes.
Qu'est-ce que cela nous a apporté?Malgré le fait que nous ne stockons aucune donnée vraiment sensible dans les fichiers de configuration eux-mêmes. Par exemple, les mots de passe de base de données. Ils sont stockés en tant que secrets dans Kubernetes, mais néanmoins, il y a encore des choses que nous ne voulons pas donner à tout le monde de suite. Par conséquent, l'accès au référentiel de déploiement est plus limité et le référentiel de barre contient simplement une description du service. Pour cette raison, il est possible de donner accès à un plus grand cercle de personnes en toute sécurité.Étant donné que nous avons non seulement la production, mais aussi d'autres environnements, grâce à cette séparation, nous pouvons réutiliser nos cartes de barre pour déployer des services non seulement en production, mais aussi, par exemple, en environnement QA. Même les déployer localement à l'aide de Minikube est une telle chose pour exécuter Kubernetes localement.À l'intérieur de chaque référentiel, nous avons laissé une séparation dans des répertoires séparés pour chaque service. Autrement dit, à l'intérieur de chaque répertoire, il y a des modèles liés au graphique correspondant et décrivant les ressources qui doivent être déployées pour lancer notre système. Dans le référentiel de déploiement, nous n'avons laissé que des enves. Dans ce cas, nous n'avons pas utilisé de modèles avec jinja, car la barre elle-même donne des modèles hors de la boîte - c'est l'une de ses principales fonctions.Nous avons laissé le script de déploiement, deploy.sh, qui simplifie et standardise le lancement pour le déploiement à l'aide de helm. Ainsi, pour quiconque souhaite se déployer, l'interface de déploiement est exactement la même que dans le cas du déploiement via Nomad. Le même deploy.sh, le nom de votre service et l'endroit où vous souhaitez le déployer. Cela fait démarrer la barre à l'intérieur. Il, à son tour, recueille les configurations à partir de modèles, y substitue les fichiers de valeurs nécessaires, puis les déploie, les mettant dans Kubernetes.Conclusions
Le service Kubernetes semble plus complexe que Nomad.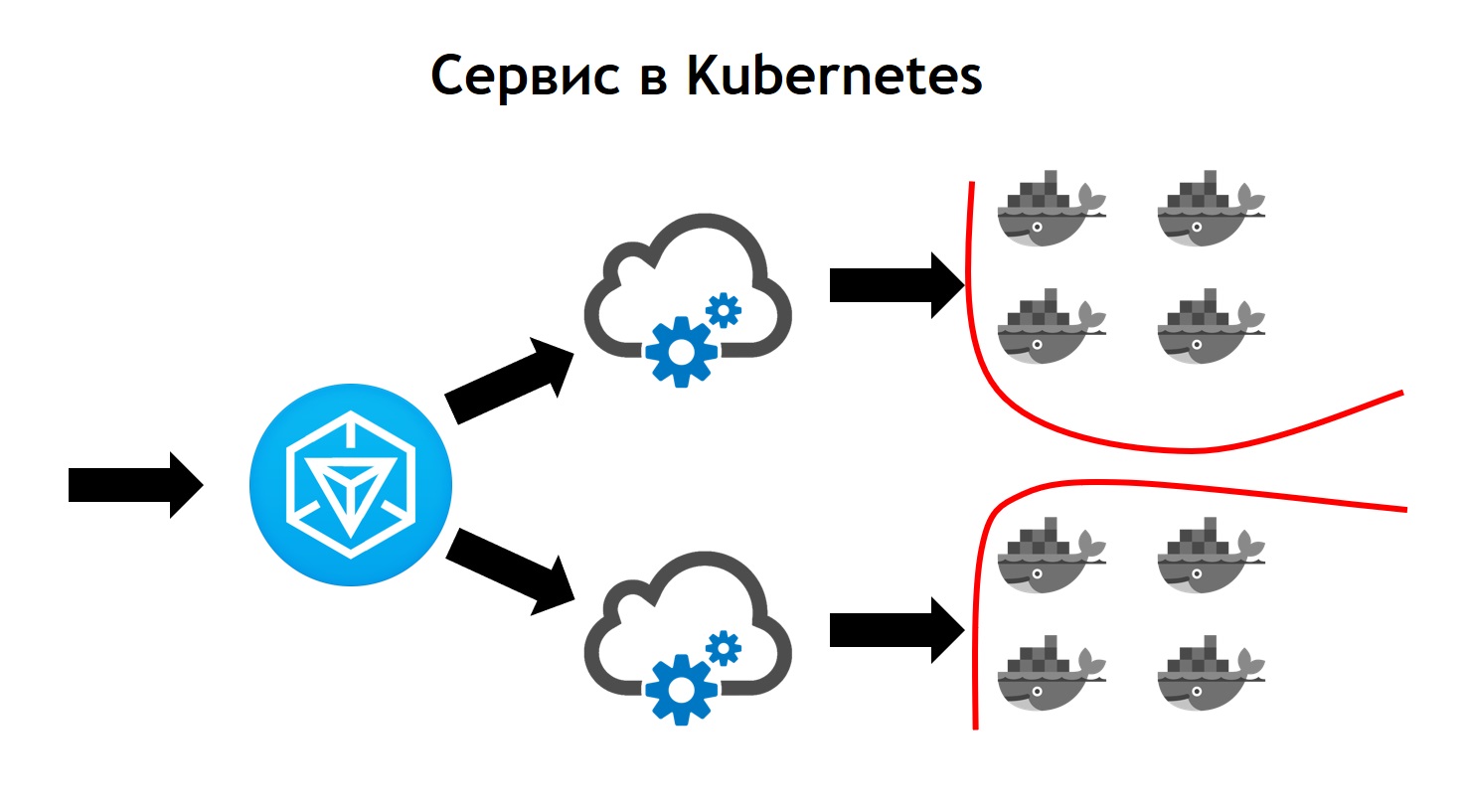 C'est là que le trafic sortant arrive à Ingress. Il s'agit simplement du contrôleur frontal, qui reçoit toutes les demandes et les envoie ensuite aux services correspondant aux données de demande. Il les définit sur la base de configurations, qui font partie de la description de votre application dans Helm et que les développeurs définissent indépendamment. Le service envoie des demandes à ses pods, c'est-à-dire des conteneurs spécifiques, en équilibrant le trafic entrant entre tous les conteneurs qui appartiennent à ce service. Eh bien, bien sûr, n'oubliez pas que nous ne devons aller nulle part de la sécurité au niveau du réseau. Par conséquent, le cluster Kubernetes opère la segmentation, qui est basée sur le balisage. Tous les services ont certaines balises auxquelles les droits d'accès des services à certaines ressources externes / internes sont attachés à l'intérieur ou à l'extérieur du cluster.À la fin de la transition, nous avons vu que Kubernetes possède toutes les fonctionnalités de Nomad, que nous avons utilisées auparavant, et ajoute également beaucoup de nouvelles choses. Il peut être développé via des plugins, et en fait via des types de ressources personnalisés. Autrement dit, vous avez la possibilité non seulement d'utiliser quelque chose qui va dans Kubernetes hors de la boîte, mais de créer votre propre ressource et service qui lira votre ressource. Cela fournit des options supplémentaires pour étendre votre système sans avoir à réinstaller Kubernetes et sans avoir besoin de modifications.Prometheus en est un exemple, qui s'exécute à l'intérieur de notre cluster Kubernetes. Pour qu'il puisse commencer à collecter des métriques d'un service particulier, nous devons ajouter un type de ressource supplémentaire, le soi-disant moniteur de service, à la description du service. Prometheus, du fait qu'il peut lire, lancé dans Kubernetes, un type de ressources personnalisé, commence automatiquement à collecter des métriques à partir du nouveau système. C'est assez pratique.Le premier déploiement que nous avons fait à Kubernetes a eu lieu en mars 2018. Et pendant ce temps, nous n'avons jamais rencontré de problème avec lui. Il fonctionne de manière suffisamment stable sans bugs importants. De plus, nous pouvons l'étendre davantage. Aujourd'hui, nous en avons suffisamment des opportunités et nous aimons vraiment le rythme de développement de Kubernetes. Actuellement, plus de 3 000 conteneurs sont situés à Kubernetes. Le cluster prend plusieurs nœuds. En même temps, il est entretenu, stable et très contrôlé.
C'est là que le trafic sortant arrive à Ingress. Il s'agit simplement du contrôleur frontal, qui reçoit toutes les demandes et les envoie ensuite aux services correspondant aux données de demande. Il les définit sur la base de configurations, qui font partie de la description de votre application dans Helm et que les développeurs définissent indépendamment. Le service envoie des demandes à ses pods, c'est-à-dire des conteneurs spécifiques, en équilibrant le trafic entrant entre tous les conteneurs qui appartiennent à ce service. Eh bien, bien sûr, n'oubliez pas que nous ne devons aller nulle part de la sécurité au niveau du réseau. Par conséquent, le cluster Kubernetes opère la segmentation, qui est basée sur le balisage. Tous les services ont certaines balises auxquelles les droits d'accès des services à certaines ressources externes / internes sont attachés à l'intérieur ou à l'extérieur du cluster.À la fin de la transition, nous avons vu que Kubernetes possède toutes les fonctionnalités de Nomad, que nous avons utilisées auparavant, et ajoute également beaucoup de nouvelles choses. Il peut être développé via des plugins, et en fait via des types de ressources personnalisés. Autrement dit, vous avez la possibilité non seulement d'utiliser quelque chose qui va dans Kubernetes hors de la boîte, mais de créer votre propre ressource et service qui lira votre ressource. Cela fournit des options supplémentaires pour étendre votre système sans avoir à réinstaller Kubernetes et sans avoir besoin de modifications.Prometheus en est un exemple, qui s'exécute à l'intérieur de notre cluster Kubernetes. Pour qu'il puisse commencer à collecter des métriques d'un service particulier, nous devons ajouter un type de ressource supplémentaire, le soi-disant moniteur de service, à la description du service. Prometheus, du fait qu'il peut lire, lancé dans Kubernetes, un type de ressources personnalisé, commence automatiquement à collecter des métriques à partir du nouveau système. C'est assez pratique.Le premier déploiement que nous avons fait à Kubernetes a eu lieu en mars 2018. Et pendant ce temps, nous n'avons jamais rencontré de problème avec lui. Il fonctionne de manière suffisamment stable sans bugs importants. De plus, nous pouvons l'étendre davantage. Aujourd'hui, nous en avons suffisamment des opportunités et nous aimons vraiment le rythme de développement de Kubernetes. Actuellement, plus de 3 000 conteneurs sont situés à Kubernetes. Le cluster prend plusieurs nœuds. En même temps, il est entretenu, stable et très contrôlé.