Malheureusement, le rôle des spécialistes de l'optimisation des performances et du dépannage de la base de données n'est désormais réduit qu'au dernier - le dépannage: ils ne se tournent presque toujours vers des spécialistes que lorsque les problèmes ont déjà atteint un point critique et doivent être résolus «hier». Et même dans ce cas, ils fonctionnent bien et ne retardent pas le problème en achetant un matériel encore plus cher et puissant sans audit détaillé des performances et tests de résistance. En effet, les frustrations sont souvent suffisantes: ils ont acheté des équipements 2 à 5 fois plus chers, et n'ont gagné que 30 à 40% de performances, dont toute l'augmentation est consommée en quelques mois soit par une augmentation du nombre d'utilisateurs, soit par une augmentation exponentielle des données, couplée à une complication de la logique.
Et maintenant, à un moment où le nombre d'architectes, de testeurs et d'ingénieurs DevOps augmente rapidement, et les développeurs Java Core optimisent même le travail
avec des chaînes , lentement mais sûrement, le moment est venu pour les optimiseurs de base de données. Les SGBD avec chaque version deviennent tellement plus intelligents et plus complexes que l'étude des nuances et des optimisations documentées et non documentées demande beaucoup de temps. Un grand nombre d'articles sont publiés chaque mois et des conférences importantes consacrées à Oracle sont organisées. Désolé pour l'analogie banale, mais dans cette situation, lorsque les administrateurs de base de données deviennent similaires aux pilotes d'avion avec d'innombrables interrupteurs à bascule, boutons, lumières et écrans, il est déjà indécent de les charger avec les subtilités de l'optimisation des performances.
Bien sûr, DBA, comme les pilotes, dans la plupart des cas, peut facilement résoudre des problèmes simples et évidents quand ils sont facilement diagnostiqués ou perceptibles dans divers "sommets" (Top events, top SQL, top segments ...). Et qui sont faciles à trouver sur MOS ou Google, même s'ils ne connaissent pas la solution. C'est beaucoup plus compliqué lorsque même les symptômes sont cachés derrière la complexité du système et qu'ils doivent être repérés parmi l'énorme quantité d'informations de diagnostic collectées par le SGBD Oracle lui-même.
L'analyse des prédictions de filtrage et d'accès est l'un des exemples les plus simples et les plus vifs: dans les systèmes volumineux et chargés, il arrive souvent qu'un tel problème soit facilement ignoré, car la charge est répartie assez uniformément sur différentes demandes (avec des jointures pour différentes tables, avec de légères différences de conditions, etc.), et les segments supérieurs ne montrent rien de spécial, ils disent: «Eh bien, oui, à partir de ces tables, les données sont le plus souvent nécessaires et il y en a plus» . Dans de tels cas, vous pouvez démarrer l'analyse avec des statistiques de SYS.COL_USAGE $:
col_usage.sqlcol owner format a30 col oname format a30 heading "Object name" col cname format a30 heading "Column name" accept owner_mask prompt "Enter owner mask: "; accept tab_name prompt "Enter tab_name mask: "; accept col_name prompt "Enter col_name mask: "; SELECT a.username as owner ,o.name as oname ,c.name as cname ,u.equality_preds as equality_preds ,u.equijoin_preds as equijoin_preds ,u.nonequijoin_preds as nonequijoin_preds ,u.range_preds as range_preds ,u.like_preds as like_preds ,u.null_preds as null_preds ,to_char(u.timestamp, 'yyyy-mm-dd hh24:mi:ss') when FROM sys.col_usage$ u , sys.obj$ o , sys.col$ c , all_users a WHERE a.user_id = o.owner
Cependant, une analyse complète de ces informations ne suffit pas, car il ne montre pas de combinaisons de prédicats. Dans ce cas, l'analyse de v $ active_session_history et v $ sql_plan peut nous aider:
with ash as ( select sql_id ,plan_hash_value ,table_name ,alias ,ACCESS_PREDICATES ,FILTER_PREDICATES ,count(*) cnt from ( select h.sql_id ,h.SQL_PLAN_HASH_VALUE plan_hash_value ,decode(p.OPERATION ,'TABLE ACCESS',p.OBJECT_OWNER||'.'||p.OBJECT_NAME ,(select i.TABLE_OWNER||'.'||i.TABLE_NAME from dba_indexes i where i.OWNER=p.OBJECT_OWNER and i.index_name=p.OBJECT_NAME) ) table_name ,OBJECT_ALIAS ALIAS ,p.ACCESS_PREDICATES ,p.FILTER_PREDICATES
Comme vous pouvez le voir dans la requête elle-même, elle affiche les 50 premières colonnes de recherche et les prédicats eux-mêmes par le nombre de fois où ASH a frappé au cours des 3 dernières heures. Malgré le fait que ASH ne stocke que des instantanés toutes les secondes, l'échantillonnage aux bases chargées est très représentatif. Il peut clarifier plusieurs points:
- Le champ cols - affiche les colonnes de recherche elles-mêmes et total_by_cols - la somme des entrées dans le contexte de ces colonnes.
- Je pense qu'il est tout à fait évident que cette information en soi n'est pas un marqueur suffisant du problème, car par exemple, plusieurs analyses complètes uniques peuvent facilement ruiner les statistiques, vous devrez donc certainement tenir compte des requêtes elles-mêmes et de leur fréquence (v $ sqlstats, dba_hist_sqlstat)
- Le regroupement par OBJECT_ALIAS dans SQL_ID, plan_hash_value est important pour combiner les prédicats d'index et de table par objet, car lors de l'accès à la table via l'index, les prédicats seront divisés en différentes lignes du plan:
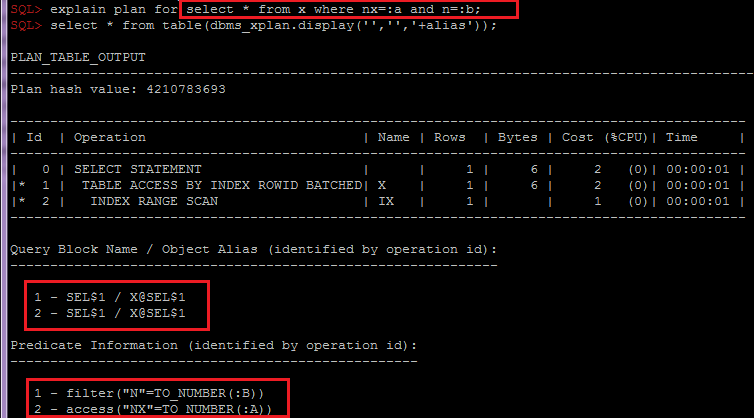
Selon les besoins, ce script peut être facilement modifié pour collecter des informations supplémentaires dans d'autres sections, par exemple, en tenant compte du partitionnement ou des attentes. Et après avoir déjà analysé ces informations, couplé à l'analyse des statistiques de table et de ses index, du schéma de données général et de la logique métier, vous pouvez transmettre des recommandations aux développeurs ou architectes pour choisir une solution, par exemple: des options de dénormalisation ou la modification du schéma ou des index de partitionnement.
Il est également assez souvent oublié d'analyser le trafic net SQL *, et il existe également de nombreuses subtilités, par exemple: fetch-size, SQLNET.COMPRESSION, types de données étendus, qui permettent de réduire le nombre d'aller-retour, etc., mais c'est un sujet pour un article séparé.
En conclusion, je voudrais dire que maintenant que les utilisateurs deviennent moins tolérants aux retards, l'optimisation des performances devient un avantage concurrentiel.