Nous commençons une série d'articles décrivant diverses situations dans lesquelles l'utilisation d'outils Intel pour les développeurs a considérablement augmenté la vitesse du logiciel et amélioré sa qualité.
Notre première histoire s'est produite à l'Université de Novossibirsk, où les chercheurs ont développé un outil logiciel pour simuler numériquement les problèmes magnétohydrodynamiques pendant l'ionisation de l'hydrogène. Ce travail a été réalisé dans le cadre du projet global de modélisation d'objets astrophysiques
AstroPhi ;
Les processeurs Intel Xeon Phi ont été utilisés comme plate-forme matérielle. Grâce à l'utilisation d'
Intel Advisor et d'
Intel Trace Analyzer and Collector , les performances informatiques ont été multipliées par 3 et la vitesse de résolution d'un problème est passée d'une semaine à deux jours.
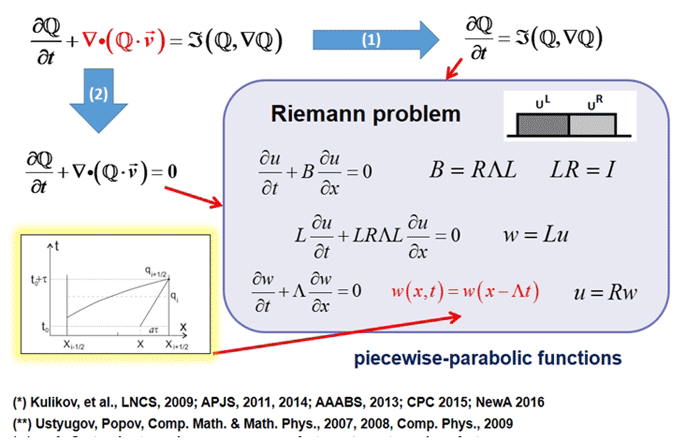
Description de la tâche
La modélisation mathématique joue un rôle important en astrophysique moderne, comme dans toute science; Il s'agit d'un outil universel pour étudier les processus évolutifs non linéaires dans l'univers. La modélisation à haute résolution de processus astrophysiques complexes nécessite d'énormes ressources de calcul. Le projet AstroPhi NSU développe un code logiciel astrophysique pour les superordinateurs basé sur des processeurs Intel Xeon Phi. Les étudiants apprennent à écrire des programmes de simulation pour un runtime extrêmement parallélisé, acquérant des connaissances importantes dont ils auront ensuite besoin lorsqu'ils travailleront avec d'autres superordinateurs.
La méthode de modélisation numérique utilisée dans le projet présentait un certain nombre d'avantages importants:
- manque de viscosité artificielle,
- Invariance galiléenne,
- garantie de non-réduction de l'entropie,
- parallélisation simple
- extensibilité potentiellement infinie.
Les trois premiers facteurs sont essentiels à une modélisation réaliste des effets physiques significatifs des problèmes astrophysiques.
L'équipe de recherche a créé un nouvel outil de modélisation pour les architectures multi-parallèles basé sur Intel Xeon Phi. Sa tâche principale était d'éviter les goulots d'étranglement dans l'échange de données entre les nœuds et de simplifier au maximum le raffinement du code. La solution de parallélisation utilise MPI, et pour la vectorisation, les instructions Intel Advanced Vector Extensions 512 (Intel AVX-512) ajoutent la prise en charge de SIMD 512 bits et permettent au programme d'emballer 8 nombres à virgule flottante double précision ou 16 nombres simple précision (32 bits) ) aux vecteurs de 512 bits. Ainsi, deux fois plus d'éléments de données sont traités par instruction que lors de l'utilisation d'AVX / AVX2 et quatre fois plus que lors de l'utilisation de SSE.
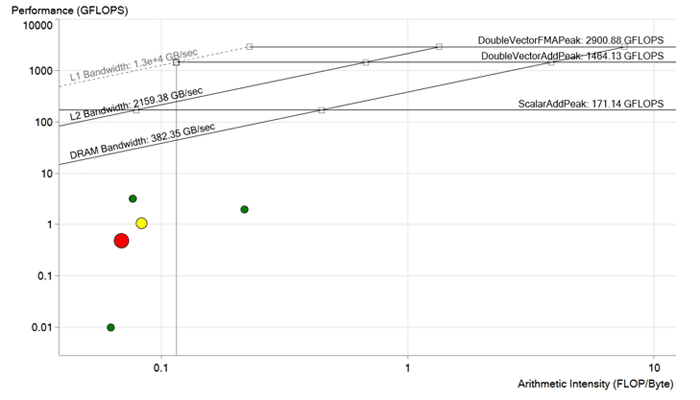 Image avant optimisation. Chaque point est un cycle de traitement. Plus le point est grand et rouge, plus le cycle se poursuit et plus l'effet de son optimisation est perceptible. Le point rouge se situe bien en dessous de la limite de bande passante DRAM et est calculé avec des performances inférieures à 1 GFLOP. Il a un très grand potentiel d'amélioration.
Image avant optimisation. Chaque point est un cycle de traitement. Plus le point est grand et rouge, plus le cycle se poursuit et plus l'effet de son optimisation est perceptible. Le point rouge se situe bien en dessous de la limite de bande passante DRAM et est calculé avec des performances inférieures à 1 GFLOP. Il a un très grand potentiel d'amélioration.Optimisation du code
Avant l'optimisation, le code avait certains problèmes avec les dépendances et les tailles des vecteurs. L'objectif d'optimisation était de supprimer les dépendances des vecteurs et d'améliorer les opérations de chargement des données en mémoire en utilisant la taille optimale des vecteurs et des tableaux pour Xeon Phi. Pour l'optimisation, nous avons utilisé
Intel Advisor et
Intel Trace Analyzer and Collector , deux outils d'
Intel Parallel Studio XE .
Intel Advisor est, comme son nom l'indique, un conseiller - un outil logiciel qui évalue le degré d'optimisation - la vectorisation (à l'aide des instructions AVX ou SIMD) et la parallélisation pour obtenir des performances maximales. Grâce à cet outil, l'équipe a pu faire une analyse d'ensemble des cycles, en mettant en évidence ceux à faible productivité, en indiquant le potentiel d'amélioration et en déterminant ce qui pourrait être amélioré et si le jeu en valait la chandelle. Intel Advisor a trié les cycles par potentiel, ajouté des messages à la source pour une meilleure lisibilité du rapport du compilateur. Il a également fourni des informations importantes telles que les temps de cycle, les dépendances des données et les modèles d'accès à la mémoire pour une vectorisation sûre et efficace.
Intel Trace Analyzer and Collector est une autre façon d'optimiser votre code. Il comprend le profilage des communications MPI et des fonctionnalités d'analyse pour améliorer la mise à l'échelle faible et forte. Cet outil graphique a aidé l'équipe à comprendre le comportement MPI de l'application, à trouver rapidement des goulots d'étranglement et, surtout, à augmenter les performances de l'architecture Intel.
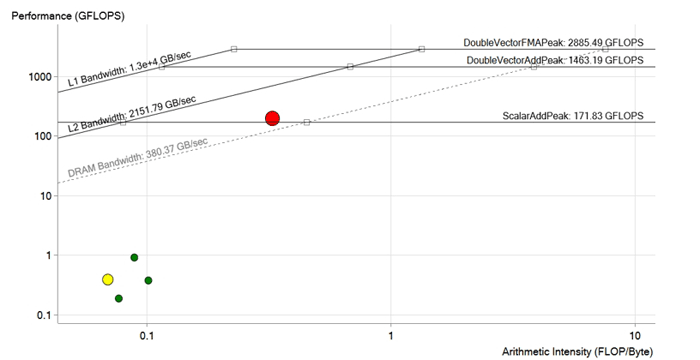 Image après optimisation. Pendant l'optimisation de la boucle rouge, les dépendances de vectorisation ont été supprimées, les opérations de chargement en mémoire ont été optimisées, les tailles des vecteurs et des tableaux ont été adaptées pour les instructions Intel Xeon Phi et AVX-512. Les performances sont passées à 190 GFLOPS, soit environ 200 fois. Maintenant, il est au-dessus de la limite de DRAM et probablement limité par les caractéristiques du cache L2
Image après optimisation. Pendant l'optimisation de la boucle rouge, les dépendances de vectorisation ont été supprimées, les opérations de chargement en mémoire ont été optimisées, les tailles des vecteurs et des tableaux ont été adaptées pour les instructions Intel Xeon Phi et AVX-512. Les performances sont passées à 190 GFLOPS, soit environ 200 fois. Maintenant, il est au-dessus de la limite de DRAM et probablement limité par les caractéristiques du cache L2Résultat
Ainsi, après toutes les améliorations et optimisations, l'équipe a atteint 190 performances GFLOPS avec une intensité arithmétique de 0,3 FLOP / b, une utilisation à 100% et une bande passante mémoire de 573 Go / s.
 Extrait de code optimisé
Extrait de code optimisé