L'article en question.
Présentation
Les systèmes de reconnaissance modernes se limitent à se classer en un nombre relativement restreint de classes sémantiquement indépendantes. L'attraction d'informations textuelles, même sans rapport avec les images, permet d'enrichir le modèle et dans une certaine mesure de résoudre les problèmes suivants:
- si le modèle de reconnaissance fait une erreur, alors souvent cette erreur n'est pas sémantiquement proche de la classe correcte;
- il n'y a aucun moyen de prédire un objet qui appartient à une nouvelle classe qui n'était pas représenté dans l'ensemble de données d'apprentissage.
L'approche proposée suggère d'afficher des images dans un espace sémantique riche dans lequel les étiquettes de classes plus similaires sont plus proches les unes des autres que les étiquettes de classes moins similaires. En conséquence, le modèle donne moins sémantiquement éloigné de la vraie classe de prédictions. De plus, le modèle, en tenant compte à la fois de la proximité visuelle et sémantique, peut classer correctement les images liées à une classe qui n'était pas représentée dans l'ensemble de données d'apprentissage.
Algorithme L'architecture
- Nous pré-formons le modèle de langage, qui donne de bons plongements sémantiquement significatifs. La dimension de l'espace est n. Ensuite, n sera pris égal à 500 ou 1000.
- Nous pré-formons le modèle visuel, qui classe bien les objets en 1000 classes.
- Nous avons coupé la dernière couche softmax du modèle visuel pré-formé et ajouté une couche entièrement connectée de 4096 à n neurones. Nous formons le modèle résultant pour chaque image afin de prédire l'incorporation correspondant à l'étiquette de l'image.
Expliquons-nous à l'aide de mappages. Soit LM un modèle de langage, VM un modèle visuel avec softmax coupé et une couche entièrement connectée ajoutée, I - image, L - étiquette d'image, LM (L) - étiquette encastrée dans l'espace sémantique. Ensuite, dans la troisième étape, nous formons la machine virtuelle afin que:
Architecture:
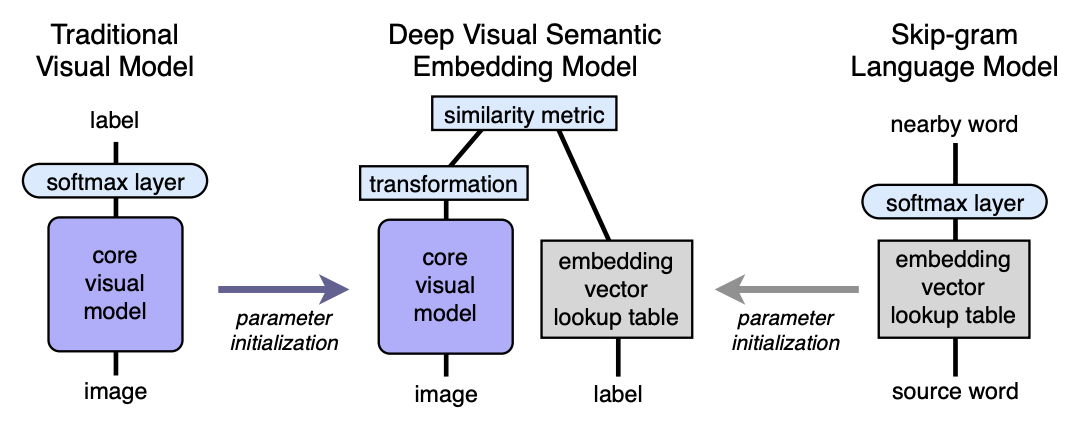
Modèle de langage
Pour apprendre le modèle de langage, le modèle skip-gram a été utilisé, un corpus de 5,4 milliards de mots tiré de wikipedia.org. Le modèle a utilisé une couche hiérarchique softmax pour prédire les concepts associés, une fenêtre - 20 mots, le nombre de passages à travers le corps - 1. Il a été expérimentalement établi que la taille d'intégration était meilleure pour prendre 500-1000.
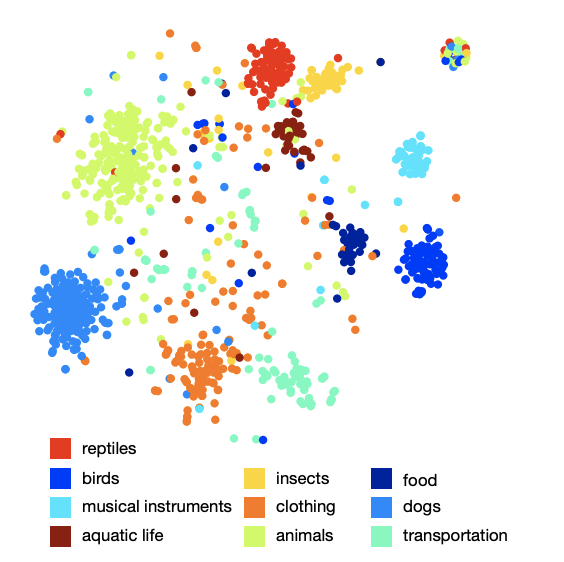
L'image de l'agencement des classes dans l'espace montre que le modèle a appris une structure sémantique qualitative et riche. Par exemple, pour une certaine espèce de requins dans l'espace sémantique résultant, 9 voisins les plus proches sont les 9 autres types de requins.
Modèle visuel
L'architecture qui a remporté le concours ILSVRC 2012 a été prise comme modèle visuel. Softmax a été supprimé et une couche entièrement connectée a été ajoutée pour obtenir la taille d'intégration souhaitée à la sortie.
Fonction de perte
Il s'est avéré que le choix de la fonction de perte est important. Une combinaison de similitude cosinus et de perte de rang de charnière a été utilisée. La fonction de perte a encouragé un produit scalaire plus grand entre le vecteur de résultat du réseau visuel et l'incorporation d'étiquette correspondante, et une amende pour un produit scalaire de grande taille entre le résultat du réseau visuel et l'incorporation d'étiquettes d'image aléatoires possibles. Le nombre d'étiquettes aléatoires arbitraires n'était pas fixe, mais était limité par la condition dans laquelle la somme des produits scalaires avec de fausses étiquettes devenait plus qu'un produit scalaire avec une étiquette valide moins une marge fixe (constante égale à 0,1). Bien sûr, tous les vecteurs ont été pré-normalisés.
Processus de formation
Au début, seule la dernière couche entièrement connectée ajoutée a été formée, le reste du réseau n'a pas mis à jour le poids. Dans ce cas, la méthode d'optimisation SGD a été utilisée. Ensuite, l'ensemble du réseau visuel a été décongelé et formé à l'aide de l'optimiseur Adagrad afin que lors de la propagation arrière sur différentes couches du réseau, les gradients se mettent à l'échelle correctement.
Prédiction
Pendant la prédiction, à partir de l'image utilisant le réseau visuel, nous obtenons un vecteur dans notre espace sémantique. Ensuite, nous trouvons les voisins les plus proches, c'est-à-dire certaines étiquettes possibles et, de manière spéciale, nous les affichons dans les synsets ImageNet pour la notation. La procédure pour le dernier affichage n'est pas si simple, car les étiquettes dans ImageNet sont un ensemble de synonymes, pas seulement une étiquette. Si le lecteur souhaite connaître les détails, je recommande l'article original (annexe 2).
Résultats
Le résultat du modèle DEVISE a été comparé à deux modèles:
- Modèle de base Softmax - un modèle de vision de pointe (SOTA - au moment de la publication)
- Le modèle d'incorporation aléatoire est une version du modèle DEVISE décrit, où les incorporations ne sont pas apprises par le modèle de langage, mais sont initialisées arbitrairement.
Pour évaluer la qualité, des métriques hit @ k «plates» et une métrique de précision hiérarchique @ k ont été utilisées. Le hit «plat» métrique @ k est le pourcentage d'images de test pour lesquelles l'étiquette correcte est présente parmi les k premières options prédites. La précision hiérarchique @ k métrique a été utilisée pour évaluer la qualité de la correspondance sémantique. Cette métrique était basée sur la hiérarchie des étiquettes dans ImageNet. Pour chaque vrai label et k fixe, l'ensemble
étiquettes sémantiquement correctes - liste des vérités fondamentales. Obtenir la prédiction (voisins les plus proches) était le pourcentage d'intersection avec la liste de vérité au sol.

Les auteurs s'attendaient à ce que le modèle softmax affiche les meilleurs résultats sur la métrique plate, car il minimise la perte d'entropie croisée, ce qui est très approprié pour les métriques hit @ k «plates». Les auteurs ont été surpris de voir à quel point le modèle DEVISE est proche du modèle softmax, atteint la parité à grand k et dépasse même à k = 20.
Sur la métrique hiérarchique, le modèle DEVISE se montre dans toute sa splendeur et dépasse le softball softmax de 3% pour k = 5 et de 7% pour k = 20.
Apprentissage zéro
Un avantage particulier du modèle DEVISE est la capacité de fournir une prédiction adéquate pour les images dont les étiquettes n'ont jamais été vues par le réseau pendant la formation. Par exemple, au cours de la formation, le réseau a vu des images étiquetées requin tigre, requin taureau et requin bleu et n'a jamais rencontré la marque de requin. Étant donné que le modèle de langage a une représentation du requin dans l'espace sémantique et est proche des plongements de différents types de requins, le modèle est très susceptible de fournir une prédiction adéquate. C'est ce qu'on appelle la capacité de généraliser - généralisation.
Montrons quelques exemples de prédictions Zero-Shot:

Notez que le modèle DEVISE, même dans ses hypothèses erronées, est plus proche de la bonne réponse que les hypothèses erronées du modèle softmax.
Ainsi, le modèle présenté perd un peu au softmax par rapport à la ligne de base sur des métriques plates, mais gagne significativement sur la précision hiérarchique @ k métrique. Le modèle a la capacité de généraliser, produisant des prédictions adéquates pour les images dont les étiquettes n'ont pas été respectées par le réseau (apprentissage zéro).
L'approche décrite peut être facilement mise en œuvre, car elle est basée sur deux modèles pré-formés - le langage et le visuel.