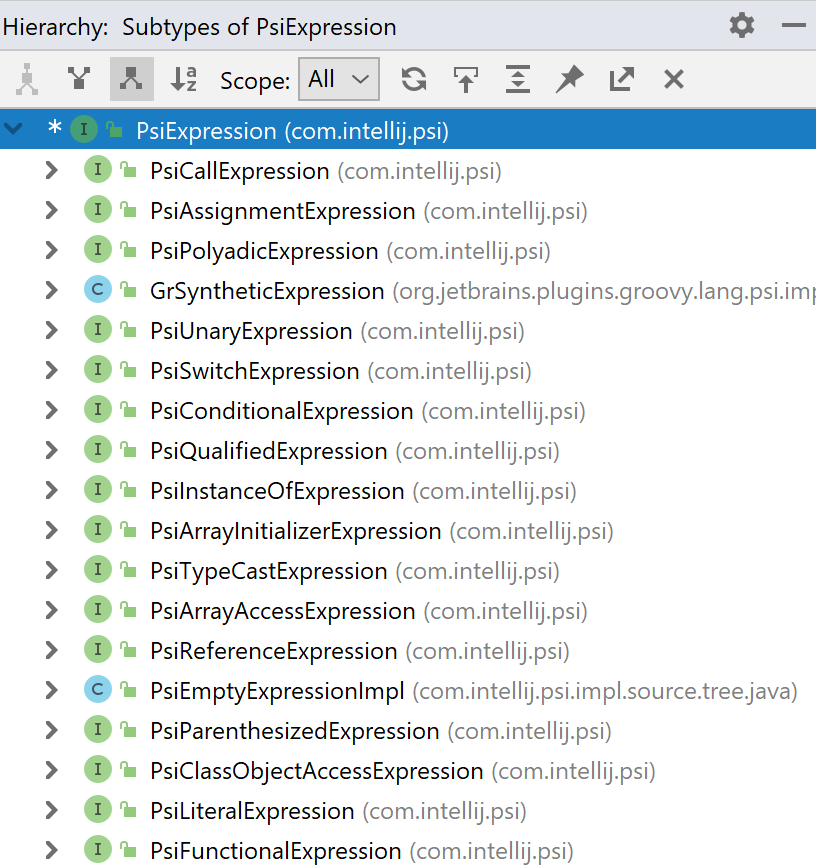
 La recherche de code et la navigation sont des fonctionnalités importantes de tout IDE. En Java, l'une des options de recherche couramment utilisées consiste à rechercher toutes les implémentations d'une interface. Cette fonctionnalité est souvent appelée Hiérarchie des types et ressemble à l'image de droite.
La recherche de code et la navigation sont des fonctionnalités importantes de tout IDE. En Java, l'une des options de recherche couramment utilisées consiste à rechercher toutes les implémentations d'une interface. Cette fonctionnalité est souvent appelée Hiérarchie des types et ressemble à l'image de droite.
Il est inefficace d'itérer sur toutes les classes de projet lorsque cette fonctionnalité est invoquée. Une option consiste à enregistrer la hiérarchie complète des classes dans l'index pendant la compilation, car le compilateur la construit de toute façon. Nous le faisons lorsque la compilation est exécutée par l'EDI et non déléguée, par exemple, à Gradle. Mais cela ne fonctionne que si rien n'a été changé dans le module après la compilation. En général, le code source est le fournisseur d'informations le plus à jour et les index sont basés sur le code source.
Trouver des enfants immédiats est une tâche simple si nous n'avons pas affaire à une interface fonctionnelle. Lors de la recherche d'implémentations de l'interface Foo , nous devons trouver toutes les classes qui ont des implements Foo et des interfaces qui ont extends Foo , ainsi que de new Foo(...) {...} classes anonymes new Foo(...) {...} . Pour ce faire, il suffit de construire à l'avance une arborescence de syntaxe de chaque fichier de projet, de trouver les constructions correspondantes et de les ajouter à un index. Il y a cependant une complexité ici: vous recherchez peut-être l'interface org.example.evilcompany.Foo , tandis que org.example.evilcompany.Foo est en fait utilisé. Pouvons-nous mettre à l'avance le nom complet de l'interface parent dans l'index? Cela peut être délicat. Par exemple, le fichier dans lequel l'interface est utilisée peut ressembler à ceci:
En regardant le fichier seul, il est impossible de dire quel est le nom réel et complet de Foo . Nous devrons examiner le contenu de plusieurs packages. Et chaque package peut être défini à plusieurs endroits du projet (par exemple, dans plusieurs fichiers JAR). Si nous effectuons une résolution correcte des symboles lors de l'analyse de ce fichier, l'indexation prendra beaucoup de temps. Mais le principal problème est que l'index construit sur MyFoo.java dépendra également d'autres fichiers. Nous pouvons déplacer la déclaration de l'interface Foo , par exemple, du package org.example.foo vers le package org.example.bar , sans rien changer dans le fichier MyFoo.java , mais le nom complet de Foo changera.
Dans IntelliJ IDEA, les index dépendent uniquement du contenu d'un seul fichier. D'une part, c'est très pratique: l'index associé à un fichier spécifique devient invalide lorsque le fichier est modifié. En revanche, il impose des restrictions importantes sur ce qui peut être mis dans l'indice. Par exemple, il n'autorise pas l'enregistrement fiable des noms complets des classes parentes dans l'index. Mais, en général, ce n'est pas si mal. Lorsque vous demandez une hiérarchie de types, nous pouvons trouver tout ce qui correspond à notre demande par un nom court, puis effectuer la résolution de symboles appropriée pour ces fichiers et déterminer si c'est ce que nous recherchons. Dans la plupart des cas, il n'y aura pas trop de symboles redondants et la vérification ne prendra pas longtemps.
 Les choses changent cependant lorsque la classe dont nous recherchons les enfants est une interface fonctionnelle. Ensuite, en plus des sous-classes explicites et anonymes, il y aura des expressions lambda et des références de méthode. Que mettons-nous dans l'index maintenant et que doit-on évaluer pendant la recherche?
Les choses changent cependant lorsque la classe dont nous recherchons les enfants est une interface fonctionnelle. Ensuite, en plus des sous-classes explicites et anonymes, il y aura des expressions lambda et des références de méthode. Que mettons-nous dans l'index maintenant et que doit-on évaluer pendant la recherche?
Supposons que nous ayons une interface fonctionnelle:
@FunctionalInterface public interface StringConsumer { void consume(String s); }
Le code contient différentes expressions lambda. Par exemple:
() -> {}
Cela signifie que nous pouvons rapidement filtrer les lambdas qui ont un nombre inapproprié de paramètres ou un type de retour clairement inapproprié, par exemple, void au lieu de non-void. Il est généralement impossible de déterminer plus précisément le type de retour. Par exemple, dans s -> list.add(s) vous devrez résoudre list et add , et, éventuellement, exécuter une procédure d'inférence de type régulière. Cela prend du temps et dépend du contenu des autres fichiers.
Nous avons de la chance si l'interface fonctionnelle prend cinq arguments. Mais s'il n'en prend qu'un, le filtre gardera un grand nombre de lambdas inutiles. C'est encore pire quand il s'agit de références de méthode. À première vue, on ne peut pas dire si une référence de méthode est appropriée ou non.
Pour clarifier les choses, il pourrait être utile de regarder ce qui entoure la lambda. Parfois, ça marche. Par exemple:
Dans tous ces cas, le nom abrégé de l'interface fonctionnelle correspondante peut être déterminé à partir du fichier actuel et peut être placé dans l'index à côté de l'expression fonctionnelle, qu'il s'agisse d'un lambda ou d'une référence de méthode. Malheureusement, dans les projets réels, ces cas couvrent un très faible pourcentage de tous les lambdas. Dans la plupart des cas, les lambdas sont utilisés comme arguments de méthode:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
Lequel des trois lambdas peut contenir StringConsumer ? Évidemment, aucun. Ici, nous avons une chaîne d'API Stream qui ne comporte que des interfaces fonctionnelles de la bibliothèque standard, elle ne peut pas avoir le type personnalisé.
Cependant, l'IDE devrait être capable de voir à travers l'astuce et de nous donner une réponse exacte. Que faire si la list n'est pas exactement java.util.List et que list.stream() renvoie quelque chose de différent de java.util.stream.Stream ? Ensuite, nous devrons résoudre la list , qui, comme nous le savons, ne peut pas être effectuée de manière fiable uniquement en fonction du contenu du fichier actuel. Et même si nous le faisons, la recherche ne doit pas reposer sur l'implémentation de la bibliothèque standard. Et si dans ce projet particulier, nous avons remplacé java.util.List par une classe à part? La recherche doit en tenir compte. Et, naturellement, les lambdas sont utilisés non seulement dans les flux standard: il existe de nombreuses autres méthodes auxquelles ils sont transmis.
Par conséquent, nous pouvons interroger l'index pour obtenir une liste de tous les fichiers Java qui utilisent des lambdas avec le nombre de paramètres requis et un type de retour valide (en fait, nous ne recherchons que quatre options: void, non-void, boolean et tout). Et quelle est la prochaine? Avons-nous besoin de construire une arborescence PSI complète (une sorte d'arbre d'analyse avec résolution de symboles, inférence de type et autres fonctionnalités intelligentes) pour chacun de ces fichiers et d'effectuer une inférence de type appropriée pour les lambdas? Pour un gros projet, il faudra du temps pour obtenir la liste de toutes les implémentations d'interfaces, même s'il n'y en a que deux.
Nous devons donc prendre les mesures suivantes:
- Index des demandes (non coûteux)
- Construire PSI (coûteux)
- Inférer le type lambda (très coûteux)
Pour Java 8 et versions ultérieures, l'inférence de type est une opération extrêmement coûteuse. Dans une chaîne d'appels complexe, il peut y avoir de nombreux paramètres génériques de substitution, dont les valeurs doivent être déterminées à l'aide de la procédure de coup dur décrite au chapitre 18 de la spécification. Pour le fichier actuel, cela peut être fait en arrière-plan, mais le traitement de milliers de fichiers non ouverts de cette manière serait une tâche coûteuse.
Ici, cependant, il est possible de couper légèrement les coins: dans la plupart des cas, nous n'avons pas besoin du type de béton. À moins qu'une méthode n'accepte un paramètre générique où le lambda lui est transmis, l'étape de substitution de paramètre finale peut être évitée. Si nous avons déduit le type lambda java.util.function.Function<T, R> , nous n'avons pas à évaluer les valeurs des paramètres de substitution T et R : il est déjà clair d'inclure le lambda dans les résultats de recherche ou non. Cependant, cela ne fonctionnera pas pour une méthode comme celle-ci:
static <T> void doSmth(Class<T> aClass, T value) {}
Cette méthode peut être appelée avec doSmth(Runnable.class, () -> {}) . Le type lambda sera alors déduit comme T , la substitution étant toujours requise. Cependant, c'est un cas rare. Nous pouvons réellement économiser du temps CPU ici, mais seulement environ 10%, donc cela ne résout pas le problème dans son essence.
Alternativement, lorsque l'inférence de type précise est trop compliquée, elle peut être rendue approximative. Contrairement à ce que la spécification suggère, laissez-le fonctionner uniquement sur les types de classe effacés et ne réduisez pas l'ensemble des contraintes, mais suivez simplement une chaîne d'appel. Tant que le type effacé ne comprend pas de paramètres génériques, tout va bien. Examinons le flux de l'exemple ci-dessus et déterminons si le dernier lambda implémente StringConsumer :
- variable de
list -> type java.util.List List.stream() → type java.util.stream.StreamStream.filter(...) -> Type java.util.stream.Stream , nous n'avons pas à considérer les arguments de filter- de même,
Stream.map(...) → type java.util.stream.Stream Stream.forEach(...) → une telle méthode existe, son paramètre a le type Consumer , qui n'est évidemment pas StringConsumer .
Et c'est ainsi que nous pourrions nous passer de l'inférence de type régulière. Avec cette approche simple, cependant, il est facile d'exécuter des méthodes surchargées. Si nous n'effectuons pas l'inférence de type appropriée, nous ne pouvons pas choisir la bonne méthode surchargée. Parfois, c'est possible, cependant: si les méthodes ont un nombre différent de paramètres. Par exemple:
CompletableFuture.supplyAsync(Foo::bar, myExecutor).thenRunAsync(s -> list.add(s));
Ici, nous pouvons voir que:
- Il existe deux méthodes
CompletableFuture.supplyAsync ; le premier prend un argument et le second en prend deux, nous choisissons donc le second. Il renvoie CompletableFuture . - Il existe également deux méthodes
thenRunAsync , et nous pouvons également choisir celle qui prend un argument. Le paramètre correspondant a le type Runnable , ce qui signifie qu'il n'est pas StringConsumer .
Si plusieurs méthodes prennent le même nombre de paramètres ou ont un nombre variable de paramètres mais semblent appropriées, nous devrons rechercher dans toutes les options. Souvent, ce n'est pas si effrayant:
new StringBuilder().append(foo).append(bar).chars().forEach(s -> list.add(s));
new StringBuilder() crée évidemment java.lang.StringBuilder . Pour les constructeurs, nous résolvons toujours la référence, mais l'inférence de type complexe n'est pas requise ici. Même s'il y avait de new Foo<>(x, y, z) , nous ne déduirions pas les valeurs des paramètres de type car seul Foo nous intéresse.- Il existe de nombreuses méthodes
StringBuilder.append qui prennent un argument, mais elles renvoient toutes le type java.lang.StringBuilder , donc nous ne nous soucions pas des types de foo et bar . - Il existe une méthode
StringBuilder.chars et elle renvoie java.util.stream.IntStream . - Il existe une seule méthode
IntStream.forEach et elle prend le type IntConsumer .
Même s'il reste plusieurs options, vous pouvez toujours toutes les suivre. Par exemple, le type lambda transmis à ForkJoinPool.getInstance().submit(...) peut être Runnable ou Callable , et si nous recherchons une autre option, nous pouvons toujours ignorer ce lambda.
Les choses empirent lorsque la méthode retourne un paramètre générique. Ensuite, la procédure échoue et vous devez effectuer l'inférence de type appropriée. Cependant, nous avons soutenu un cas. Il est bien présenté dans ma bibliothèque StreamEx, qui a une classe abstraite AbstractStreamEx<T, S extends AbstractStreamEx<T, S>> qui contient des méthodes comme le S filter(Predicate<? super T> predicate) . Habituellement, les gens travaillent avec une StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>> concrète StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>> . Dans ce cas, vous pouvez remplacer le paramètre type et découvrir que S = StreamEx .
C'est ainsi que nous nous sommes débarrassés de l'inférence de type coûteuse dans de nombreux cas. Mais nous n'avons rien fait avec la construction de PSI. Il est décevant d'avoir analysé un fichier avec 500 lignes de code pour découvrir que le lambda sur la ligne 480 ne correspond pas à notre requête. Revenons à notre flux:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
Si list est une variable locale, un paramètre de méthode ou un champ de la classe actuelle, déjà au stade de l'indexation, nous pouvons trouver sa déclaration et établir que le nom de type court est List . En conséquence, nous pouvons mettre les informations suivantes dans l'indice de la dernière lambda:
Ce type lambda est un type de paramètre d'une méthode forEach qui prend un argument, appelé sur le résultat d'une méthode map qui prend un argument, appelé sur le résultat d'une méthode de filter qui prend un argument, appelé sur le résultat d'une méthode stream qui ne prend aucun argument, appelé sur un objet List .
Toutes ces informations sont disponibles dans le fichier actuel et peuvent donc être placées dans l'index. Pendant la recherche, nous demandons ces informations sur tous les lambdas de l'index et essayons de restaurer le type lambda sans construire de PSI. Tout d'abord, nous devrons effectuer une recherche globale des classes avec le nom de List court. Évidemment, nous trouverons non seulement java.util.List mais aussi java.awt.List ou quelque chose du code du projet. Ensuite, toutes ces classes passeront par la même procédure d'inférence de type approximative que nous avons utilisée auparavant. Les classes redondantes sont souvent rapidement éliminées. Par exemple, java.awt.List n'a pas de méthode de stream , il sera donc exclu. Mais même s'il reste quelque chose de redondant et que nous trouvons plusieurs candidats pour le type lambda, il est probable qu'aucun d'entre eux ne correspondra à la requête de recherche, et nous éviterons toujours de créer un PSI complet.
La recherche globale peut s'avérer trop coûteuse (lorsqu'un projet contient trop de classes List ), ou le début de la chaîne ne peut pas être résolu dans le contexte d'un fichier (disons, c'est un champ d'une classe parent), ou la chaîne peut se rompre lorsque la méthode renvoie un paramètre générique. Nous n'abandonnerons pas et essaierons de recommencer avec une recherche globale sur la prochaine méthode de la chaîne. Par exemple, pour la map.get(key).updateAndGet(a -> a * 2) , l'instruction suivante va à l'index:
Ce type lambda est le type du paramètre unique d'une méthode updateAndGet , appelé sur le résultat d'une méthode get avec un paramètre, appelé sur un objet Map .
Imaginez que nous avons de la chance, et le projet n'a qu'un seul type de Map java.util.Map . Il a une méthode get(Object) , mais, malheureusement, il renvoie un paramètre générique V Ensuite, nous éliminerons la chaîne et rechercherons la méthode updateAndGet avec un paramètre globalement (en utilisant l'index, bien sûr). Et nous sommes heureux de découvrir qu'il n'y a que trois méthodes de ce type dans le projet: dans les AtomicInteger , AtomicLong et AtomicReference avec les types de paramètres IntUnaryOperator , LongUnaryOperator et UnaryOperator , respectivement. Si nous recherchons un autre type, nous avons déjà découvert que ce lambda ne correspond pas à la demande, et nous n'avons pas à construire le PSI.
Étonnamment, c'est un bon exemple d'une fonctionnalité qui fonctionne plus lentement avec le temps. Par exemple, lorsque vous recherchez des implémentations d'une interface fonctionnelle et que vous n'en avez que trois dans votre projet, il faut dix secondes à IntelliJ IDEA pour les trouver. Vous vous souvenez qu'il y a trois ans, leur nombre était le même, mais l'IDE vous a fourni les résultats de la recherche en seulement deux secondes sur la même machine. Et bien que votre projet soit énorme, il n'a augmenté que de 5% au cours de ces années. Il est raisonnable de commencer à se plaindre de ce que les développeurs IDE ont fait de mal pour le rendre si terriblement lent.
Bien que nous n'ayons rien changé du tout. La recherche fonctionne comme il y a trois ans. Le fait est qu'il y a trois ans, vous venez de passer à Java 8 et n'aviez qu'une centaine de lambdas dans votre projet. À ce jour, vos collègues ont transformé des classes anonymes en lambdas, ont commencé à utiliser des flux ou une bibliothèque réactive. En conséquence, au lieu d'une centaine de lambdas, il y en a dix mille. Et maintenant, pour trouver les trois nécessaires, l'IDE doit rechercher parmi cent fois plus d'options.
J'ai dit «nous pourrions» parce que, naturellement, nous revenons à cette recherche de temps en temps et essayons de l'accélérer. Mais c'est comme ramer sur le ruisseau, ou plutôt sur la cascade. Nous essayons dur, mais le nombre de lambdas dans les projets continue de croître très rapidement.