Le marché de l'informatique distribuée et des mégadonnées, selon les
statistiques , croît de 18 à 19% par an. La question du choix du logiciel à ces fins reste donc d'actualité. Dans cet article, nous allons commencer par expliquer pourquoi l'informatique distribuée est nécessaire, nous attarder sur le choix du logiciel, parler de l'utilisation de Hadoop avec Cloudera, et enfin, parlons du choix du matériel et de la façon dont il affecte les performances de différentes manières.
Pourquoi avons-nous besoin de l'informatique distribuée dans une entreprise régulière? Tout est simple et compliqué à la fois. Simple - car dans la plupart des cas, nous effectuons des calculs relativement simples par unité d'information. C'est difficile car il y a beaucoup de telles informations. Beaucoup. Par conséquent, vous devez
traiter des téraoctets de données dans 1000 threads . Ainsi, les scénarios d'utilisation sont assez universels: les calculs peuvent être appliqués partout où il est nécessaire de prendre en compte un grand nombre de métriques sur un tableau de données encore plus large.
Un exemple récent: la chaîne de pizzerias Dodo Pizza a
déterminé, sur la base d'une analyse de la base de commandes des clients, que lors du choix d'une pizza avec un remplissage arbitraire, les utilisateurs opèrent généralement avec seulement six ensembles de base d'ingrédients plus deux au hasard. Conformément à cela, la pizzeria a ajusté ses achats. De plus, elle a pu mieux recommander aux utilisateurs des produits supplémentaires proposés au stade de la commande, ce qui a permis d'augmenter les bénéfices.
Autre exemple: l'
analyse des positions matières premières a permis au magasin H&M de réduire la gamme dans les magasins individuels de 40%, tout en maintenant le niveau des ventes. Cet objectif a été atteint en éliminant les positions mal vendues et la saisonnalité a été prise en compte dans les calculs.
Sélection d'outils
La norme de l'industrie pour ce type de calcul est Hadoop. Pourquoi? Parce que Hadoop est un excellent framework bien documenté (le même Habr publie beaucoup d'articles détaillés sur ce sujet), qui est accompagné de tout un ensemble d'utilitaires et de bibliothèques. Vous pouvez entrer d'énormes ensembles de données structurées et non structurées, et le système lui-même les répartira entre la puissance de calcul. De plus, ces mêmes capacités peuvent être augmentées ou désactivées à tout moment - la même évolutivité horizontale en action.
En 2017, la société de conseil influente Gartner a
conclu que Hadoop serait bientôt obsolète. La raison est assez banale: les analystes estiment que les entreprises migreront massivement vers le cloud, car là, elles peuvent payer pour le fait d'utiliser la puissance de calcul. Le deuxième facteur important, censé pouvoir "enterrer" Hadoop - est la vitesse de travail. Parce que des options comme Apache Spark ou Google Cloud DataFlow sont plus rapides que Hadoop sous-jacent MapReduce.
Hadoop repose sur plusieurs piliers, dont les plus notables sont les technologies MapReduce (un système de distribution de données pour le calcul entre serveurs) et le système de fichiers HDFS. Ce dernier est spécifiquement conçu pour stocker des informations réparties entre les nœuds d'un cluster: chaque bloc de taille fixe peut être placé sur plusieurs nœuds, et grâce à la réplication, le système est immunisé contre les défaillances de nœuds individuels. Au lieu d'une table de fichiers, un serveur spécial appelé NameNode est utilisé.
L'illustration ci-dessous montre le flux de travail MapReduce. Au premier stade, les données sont divisées selon une certaine caractéristique, au second - elles sont réparties en fonction de la puissance de calcul, au troisième - le calcul est effectué.
MapReduce a été créé à l'origine par Google pour les besoins de sa recherche. MapReduce est ensuite passé au code libre et Apache a repris le projet. Eh bien, Google a progressivement migré vers d'autres solutions. Une nuance intéressante: Google a actuellement un projet appelé Google Cloud Dataflow, positionné comme la prochaine étape après Hadoop, en remplacement rapide.
Un examen plus approfondi révèle que Google Cloud Dataflow est basé sur une variété d'Apache Beam, tandis qu'Apache Beam comprend un cadre Apache Spark bien documenté, qui nous permet de parler de la même vitesse d'exécution des décisions. Eh bien, Apache Spark fonctionne très bien sur le système de fichiers HDFS, ce qui vous permet de le déployer sur les serveurs Hadoop.
Nous ajoutons ici le volume de documentation et de solutions clé en main pour Hadoop et Spark contre Google Cloud Dataflow, et le choix de l'outil devient évident. De plus, les ingénieurs peuvent décider eux-mêmes quel code - sous Hadoop ou Spark - exécuter pour eux, en se concentrant sur la tâche, l'expérience et les qualifications.
Cloud ou serveur local
La tendance vers une transition universelle vers le cloud a même généré un terme aussi intéressant que Hadoop-as-a-service. Dans ce scénario, l'administration des serveurs connectés est devenue très importante. Parce que, hélas, malgré sa popularité, Hadoop pur est un outil assez difficile à configurer, car beaucoup de choses doivent être faites avec vos mains. Par exemple, configurez individuellement les serveurs, surveillez leurs performances, configurez soigneusement de nombreux paramètres. En général, travailler pour un amateur est une excellente occasion de foirer quelque chose ou de manquer quelque chose.
Par conséquent, diverses distributions, initialement équipées d'outils de déploiement et d'administration pratiques, ont gagné en popularité. Cloudera est l'une des distributions les plus populaires qui prennent en charge Spark et facilitent les choses. Il a à la fois une version payante et une version gratuite - et dans cette dernière, toutes les fonctionnalités de base sont disponibles, et sans limiter le nombre de nœuds.

Pendant la configuration, Cloudera Manager se connectera via SSH à vos serveurs. Un point intéressant: lors de l'installation, il est préférable d'indiquer qu'elle doit être effectuée par les soi-disant
parcelles : packages spéciaux, dont chacun contient tous les composants nécessaires qui sont configurés pour fonctionner les uns avec les autres. En fait, il s'agit d'une telle version améliorée du gestionnaire de packages.
Après l'installation, nous obtenons la console de gestion de cluster, où vous pouvez voir la télémétrie par cluster, les services installés, et vous pouvez ajouter / supprimer des ressources et modifier la configuration du cluster.
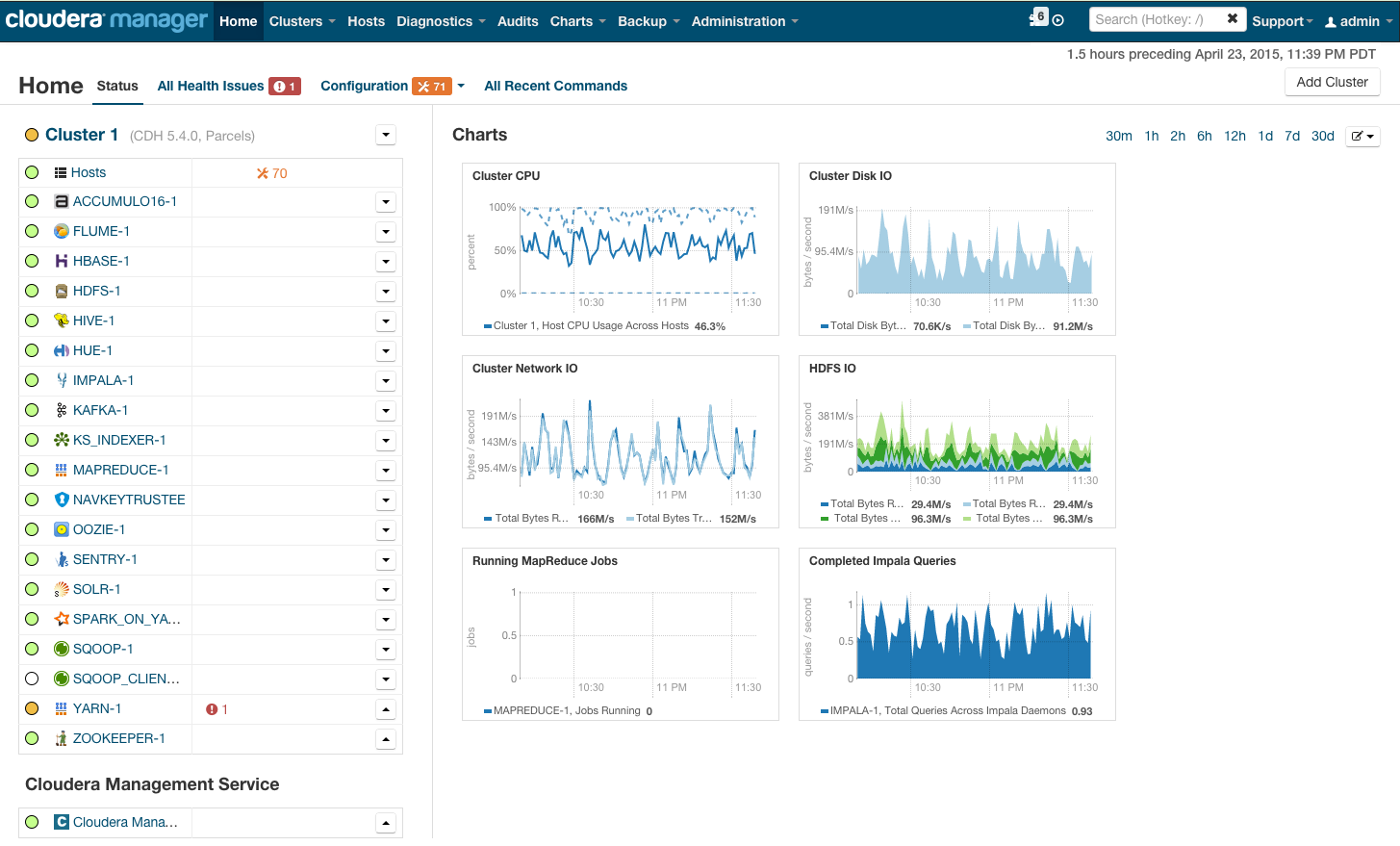
En conséquence, vous voyez la cabine de la fusée qui vous emmènera vers le brillant avenir de BigData. Mais avant de dire «allons-y», passons sous le capot.
Configuration matérielle requise
Cloudera mentionne diverses configurations possibles sur son site Web. Les principes généraux selon lesquels ils sont construits sont illustrés dans l'illustration:
Pour lubrifier cette image optimiste peut MapReduce. Si vous regardez à nouveau le diagramme de la section précédente, il devient évident que dans presque tous les cas, le travail MapReduce peut rencontrer un goulot d'étranglement lors de la lecture des données à partir du disque ou du réseau. Ceci est également présenté sur le blog Cloudera. Par conséquent, pour tous les calculs rapides, y compris via Spark, qui est souvent utilisé pour les calculs en temps réel, la vitesse d'E / S est très importante. Par conséquent, lors de l'utilisation de Hadoop, il est très important que des machines équilibrées et rapides pénètrent dans le cluster, ce qui, pour le dire doucement, n'est pas toujours fourni dans l'infrastructure cloud.
L'équilibrage de charge équilibré est obtenu grâce à l'utilisation de la virtualisation Openstack sur des serveurs dotés de puissants processeurs multicœurs. Les nœuds de données se voient allouer leurs ressources de processeur et leurs disques spécifiques. Dans notre solution
Atos Codex Data Lake Engine , une large virtualisation est obtenue, c'est pourquoi nous gagnons à la fois en performances (l'influence de l'infrastructure réseau est minimisée) et en TCO (les serveurs physiques inutiles sont éliminés).
Dans le cas de l'utilisation de serveurs BullSequana S200, nous obtenons une charge très uniforme, dépourvue de goulots d'étranglement. La configuration minimale comprend 3 serveurs BullSequana S200, chacun avec deux JBOD, plus des S200 supplémentaires en option contenant quatre nœuds de données sont connectés en option. Voici un exemple de charge dans le test TeraGen:
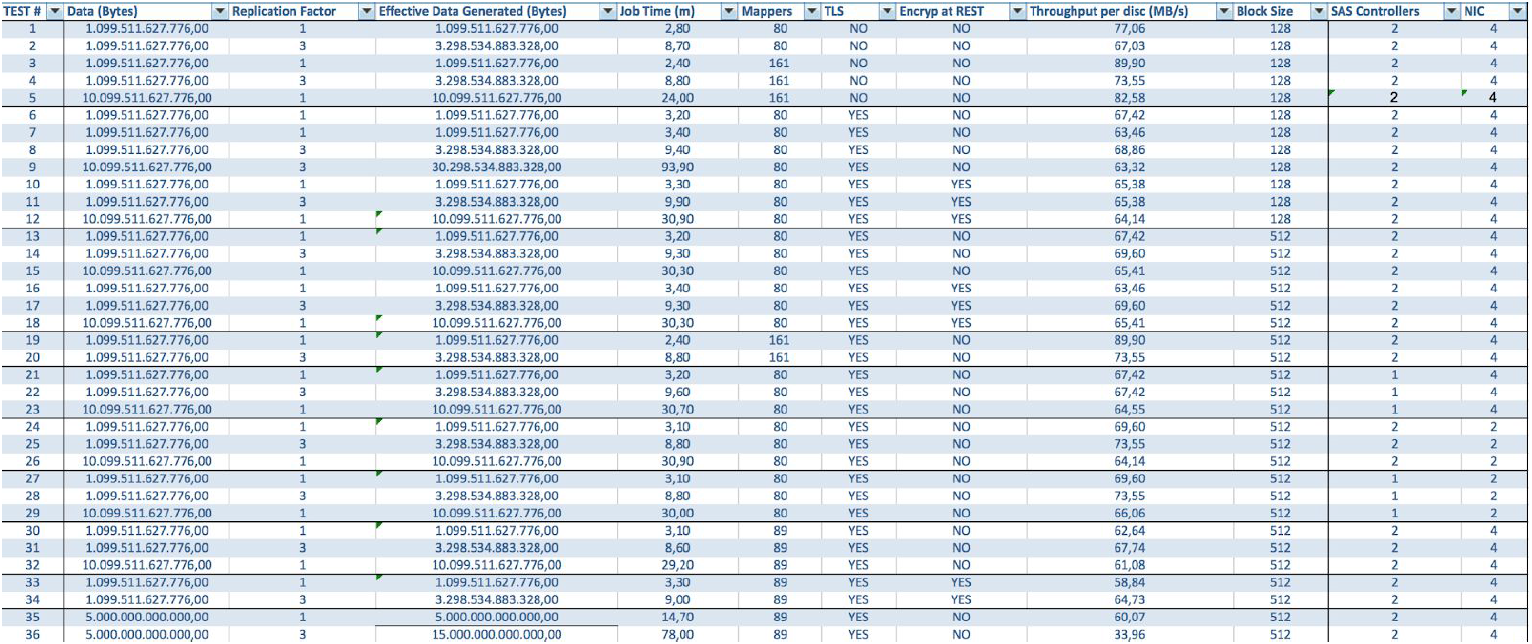
Les tests avec différents volumes de données et valeurs de réplication montrent les mêmes résultats en termes d'équilibrage de charge entre les nœuds de cluster. Vous trouverez ci-dessous un graphique de la distribution de l'accès au disque par des tests de performances.
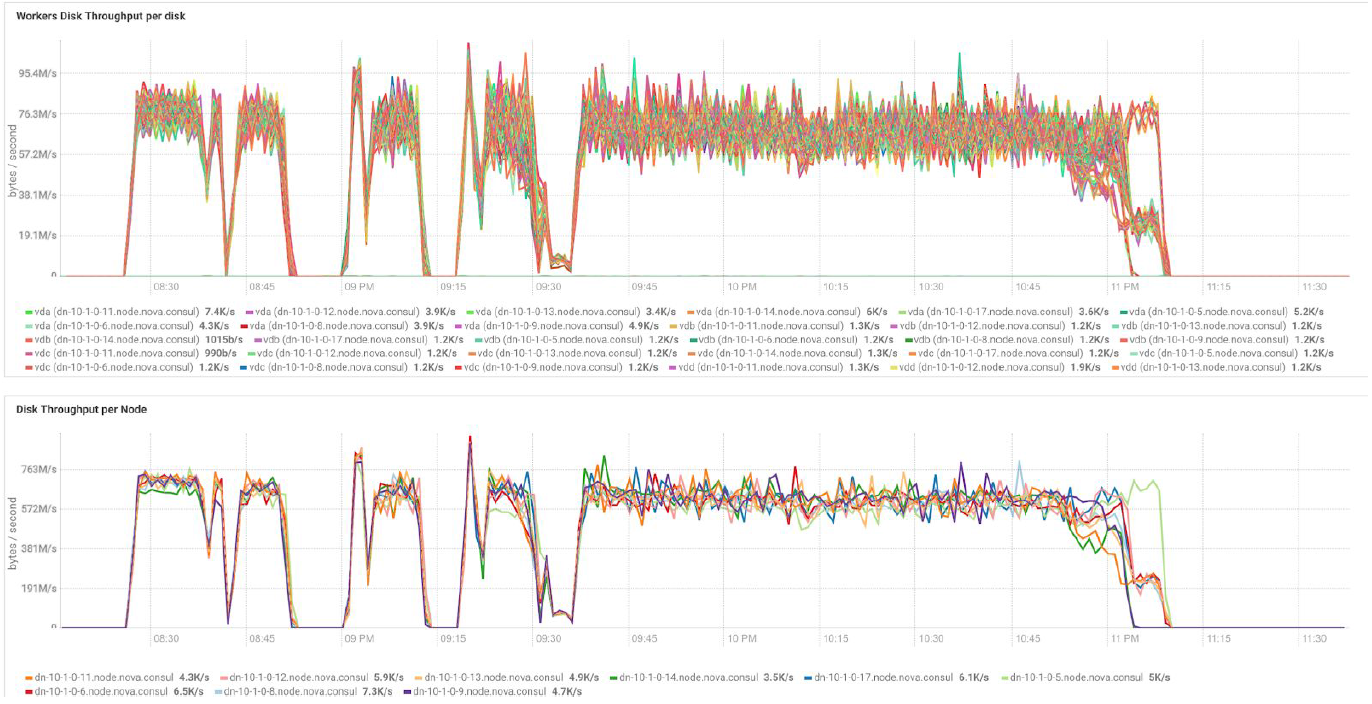
Les calculs sont basés sur la configuration minimale de 3 serveurs BullSequana S200. Il comprend 9 nœuds de données et 3 nœuds principaux, ainsi que des machines virtuelles réservées en cas de déploiement de protection basé sur OpenStack Virtualization. Résultat du test TeraSort: la taille de bloc de 512 Mo du coefficient de réplication de trois avec cryptage est de 23,1 minutes.
Comment puis-je étendre le système? Différents types d'extensions sont disponibles pour Data Lake Engine:
- Nœuds de données: pour 40 To d'espace utilisable
- Noeuds analytiques avec possibilité d'installer un GPU
- Autres options en fonction des besoins de l'entreprise (par exemple, si vous avez besoin de Kafka et similaires)
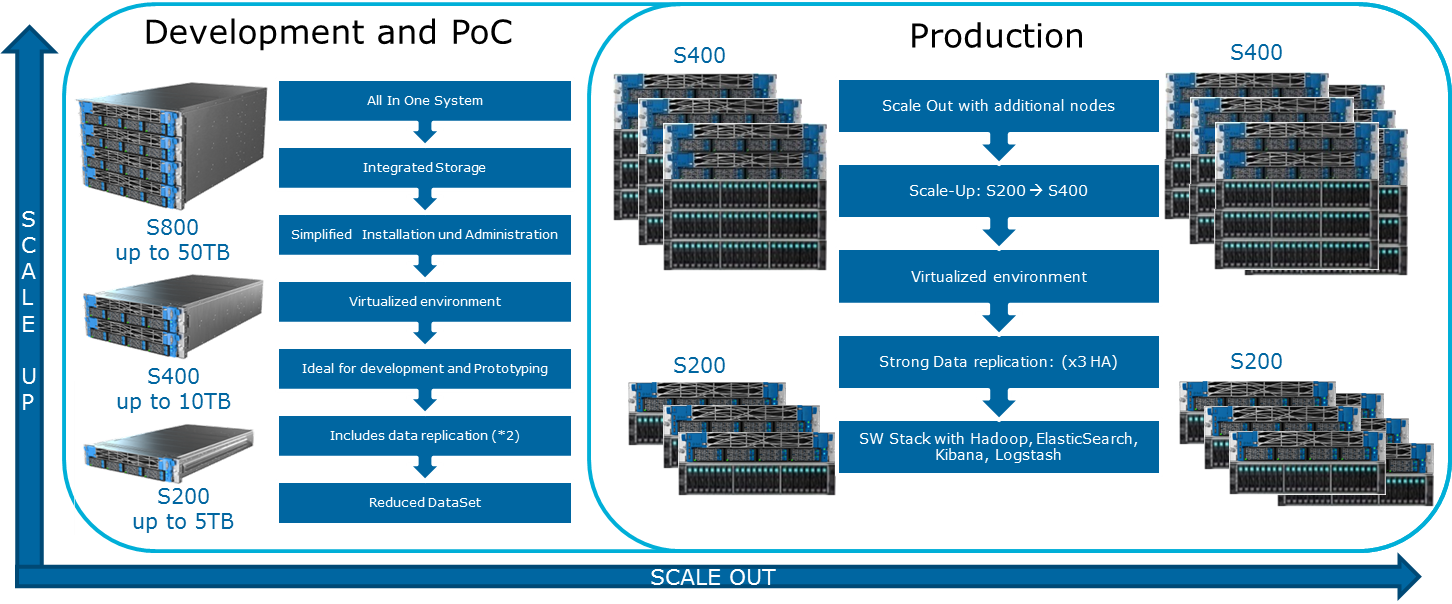
Atos Codex Data Lake Engine comprend à la fois les serveurs eux-mêmes et les logiciels préinstallés, y compris une suite Cloudera sous licence; Hadoop lui-même, OpenStack avec des machines virtuelles basées sur le noyau RedHat Enterprise Linux, le système de réplication des données et la sauvegarde (y compris en utilisant le nœud de sauvegarde et Cloudera BDR - Sauvegarde et récupération après sinistre). Le moteur Atos Codex Data Lake a été la première solution de virtualisation certifiée par
Cloudera .
Si vous êtes intéressé par les détails, nous serons heureux de répondre à nos questions dans les commentaires.