
Bonjour, Habr! La description du fonctionnement de l' intérieur d'une grande plate-forme de paiement se poursuivra logiquement avec une description du fonctionnement exact de tous ces composants dans le monde réel sur du matériel physique. Dans cet article, je parle de la manière et de l'emplacement des applications de la plate-forme, de la façon dont le trafic provenant du monde extérieur les atteint, et je décrirai également le schéma d'un rack standard pour nous avec des équipements situés dans l'un de nos centres de données.
Approches et limites

L'une des premières exigences que nous avons formulées avant le développement de la plate-forme sonne comme "la capacité de mettre à l'échelle les ressources de calcul linéaire pour assurer le traitement de n'importe quel nombre de transactions".
Les approches classiques des systèmes payants utilisés par les acteurs du marché impliquent la présence d'un plafond, quoique plutôt élevé selon les déclarations. Habituellement, cela ressemble à ceci: "notre traitement peut accepter 1000 transactions par seconde."
Cette approche ne cadre pas avec nos objectifs commerciaux et notre architecture. Nous ne voulons pas de limite. En fait, il serait étrange d'entendre Yandex ou Google affirmer "nous pouvons traiter 1 million de recherches par seconde". La plate-forme devrait traiter autant de demandes que l'entreprise en a besoin en raison de l'architecture, ce qui permet, pour le dire simplement, d'envoyer un informaticien avec un chariot de serveurs, qu'il installera dans des racks, se connectera au commutateur et partira. L’orchestrateur de la plate-forme déploiera des copies d’instances d’applications métier vers de nouvelles capacités, ce qui nous permettra d’obtenir l’augmentation du RPS dont nous avons besoin.
La deuxième exigence importante est d'assurer la haute disponibilité des services fournis. Il serait amusant, mais pas trop utile, de créer une plateforme de paiement pouvant accepter un nombre infini de paiements dans / dev / null.
Le moyen le plus efficace pour atteindre la haute disponibilité est peut-être de dupliquer les entités qui servent le service plusieurs fois afin que la défaillance d'un nombre raisonnable d'applications, d'équipements ou de centres de données n'affecte pas la disponibilité globale de la plate-forme.
La duplication multiple d'applications nécessite un grand nombre de serveurs physiques et d'équipements réseau associés. Ce fer coûte de l'argent, dont nous avons bien sûr le montant, nous ne pouvons pas nous permettre d'acheter beaucoup de fer cher. La plate-forme est donc conçue de manière à pouvoir facilement accueillir et se sentir bien sur un grand nombre de fers peu coûteux et pas trop puissants, ou même dans un cloud public.
L'utilisation de serveurs qui ne sont pas les plus puissants en termes de puissance de calcul a ses avantages - leur défaillance n'a pas d'effet critique sur l'état général du système dans son ensemble. Imaginez quoi de mieux - si un serveur de marque cher, grand et super fiable brûle, exécutant un SGBD selon le schéma maître-esclave (et selon la loi de Murphy, il brûlera certainement, et le 31 décembre au soir) ou quelques serveurs dans un cluster de 30 nœuds fonctionnant selon masterless diagramme?
Sur la base de cette logique, nous avons décidé de ne pas créer un autre point de défaillance massif sous la forme d'une matrice de disques centralisée. Les périphériques blocs communs nous sont fournis par le cluster Ceph, qui est déployé hyper-convergent sur les mêmes serveurs, mais avec une infrastructure réseau distincte.
Ainsi, nous sommes logiquement arrivés au schéma général d'un rack universel avec des ressources informatiques sous la forme de serveurs peu coûteux et peu puissants dans le centre de données. Si nous avons besoin de plus de ressources, nous terminons tout rack gratuit avec des serveurs, ou nous en plaçons un autre, de préférence plus près.

Eh bien, au final, c'est tout simplement magnifique. Lorsqu'une quantité claire du même fer est installée dans les racks, cela vous permet de résoudre les problèmes de pose de haute qualité de la ferme de fils, vous permet de vous débarrasser des nids d'hirondelle et du danger de s'emmêler dans les fils, de laisser tomber le traitement. Bon du point de vue de l'ingénierie, le système doit être beau partout - à la fois de l'intérieur sous forme de code et de l'extérieur sous forme de serveurs et de matériel réseau. Un beau système fonctionne mieux et de manière plus fiable, j'avais suffisamment d'exemples pour le vérifier d'après ma propre expérience.
S'il vous plaît, ne pensez pas que nous sommes des escrocs ou que les affaires sont bloquées par le financement. Développer et maintenir une plateforme distribuée est en fait un plaisir très coûteux. En fait, c'est encore plus cher que de posséder un système classique, construit, conditionnellement, sur un matériel de marque puissant avec Oracle / MSSQL, des serveurs d'applications et d'autres liaisons.
Notre approche porte ses fruits avec une grande fiabilité, des capacités de mise à l'échelle horizontale très flexibles, l'absence de plafond dans le nombre de paiements par seconde, et aussi étrange que cela puisse paraître - beaucoup de plaisir pour l'équipe informatique. Pour moi, le niveau de plaisir des développeurs et des développeurs du système qu'ils créent n'est pas moins important que le temps de développement prévu, la quantité et la qualité des fonctionnalités déployées.
Infrastructure du serveur

Logiquement, nos capacités de serveur peuvent être divisées en deux classes principales: les serveurs pour hyperviseurs, pour lesquels la densité de cœurs CPU et RAM par unité est importante, et les serveurs de stockage, où l'accent est mis principalement sur la quantité d'espace disque par unité, et CPU et RAM sont déjà sélectionnés pour nombre de disques.
À l'heure actuelle, notre serveur classique pour la puissance de calcul ressemble à ceci:
- CPU 2xXeon E5-2630;
- 128 Go de RAM;
- SSD 3xSATA (pool SSD Ceph);
- SSD 1xNVMe (cache-dm).
Serveur de stockage des états:
- CPU 1xXeon E5-2630;
- HDD 12-16;
- 2 SSD pour block.db;
- RAM 32G.
Infrastructure réseau
Dans le choix du matériel réseau, notre approche est quelque peu différente. Nous utilisons toujours des commutateurs de marque pour la commutation et le routage entre vlan-s, maintenant c'est Cisco SG500X-48 et Cisco Nexus C5020 dans SAN.
Physiquement, chaque serveur est connecté au réseau par 4 ports physiques:
- 2x1GbE - réseau de gestion et RPC entre applications;
- 2x10GbE - réseau de stockage.
Les interfaces à l'intérieur des machines sont combinées par liaison, puis le trafic étiqueté diverge selon le vlan souhaité.
C'est peut-être le seul endroit de notre infrastructure où vous pouvez voir l'étiquette d'un célèbre fournisseur. Parce que pour le routage, le filtrage du réseau et l'inspection du trafic, nous utilisons des hôtes Linux. Nous n'achetons pas de routeurs spécialisés. Tout ce dont nous avons besoin est configuré sur des serveurs exécutant Gentoo (iptables pour le filtrage, BIRD pour le routage dynamique, Suricata comme IDS / IPS, Wallarm comme WAF).
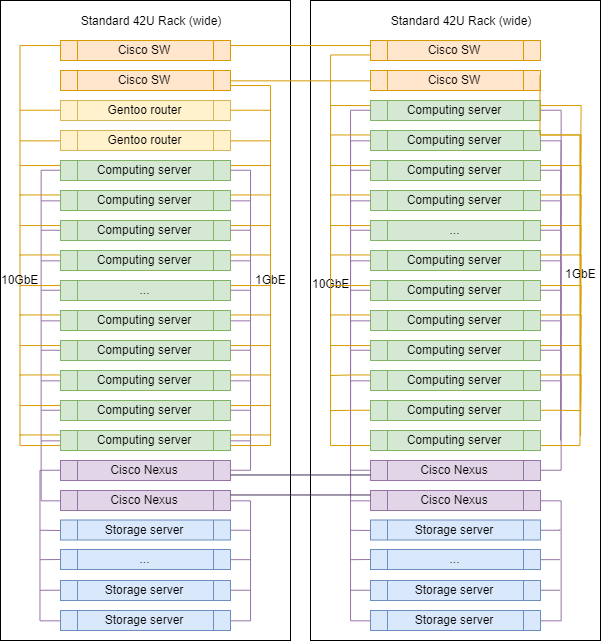
Rack typique en DC
Lors de la mise à l'échelle, les racks des contrôleurs de domaine ne diffèrent pratiquement pas les uns des autres, à l'exception des routeurs de liaison montante, qui sont installés dans l'un d'eux.
Les proportions exactes de serveurs de différentes classes peuvent varier, mais en général, la logique est préservée - il y a plus de serveurs pour l'informatique que de serveurs pour le stockage des données.
Bloquer les appareils et le partage des ressources
Essayons de tout mettre ensemble. Imaginez que nous devons placer plusieurs de nos microservices dans l'infrastructure, pour plus de clarté, ce seront des microservices qui doivent communiquer entre eux via RPC et l'un d'eux est Machinegun, qui stocke l'état dans le cluster Riak, ainsi que certains services auxiliaires, tels que comme les nœuds ES et Consul.
Une disposition typique ressemblerait à ceci:
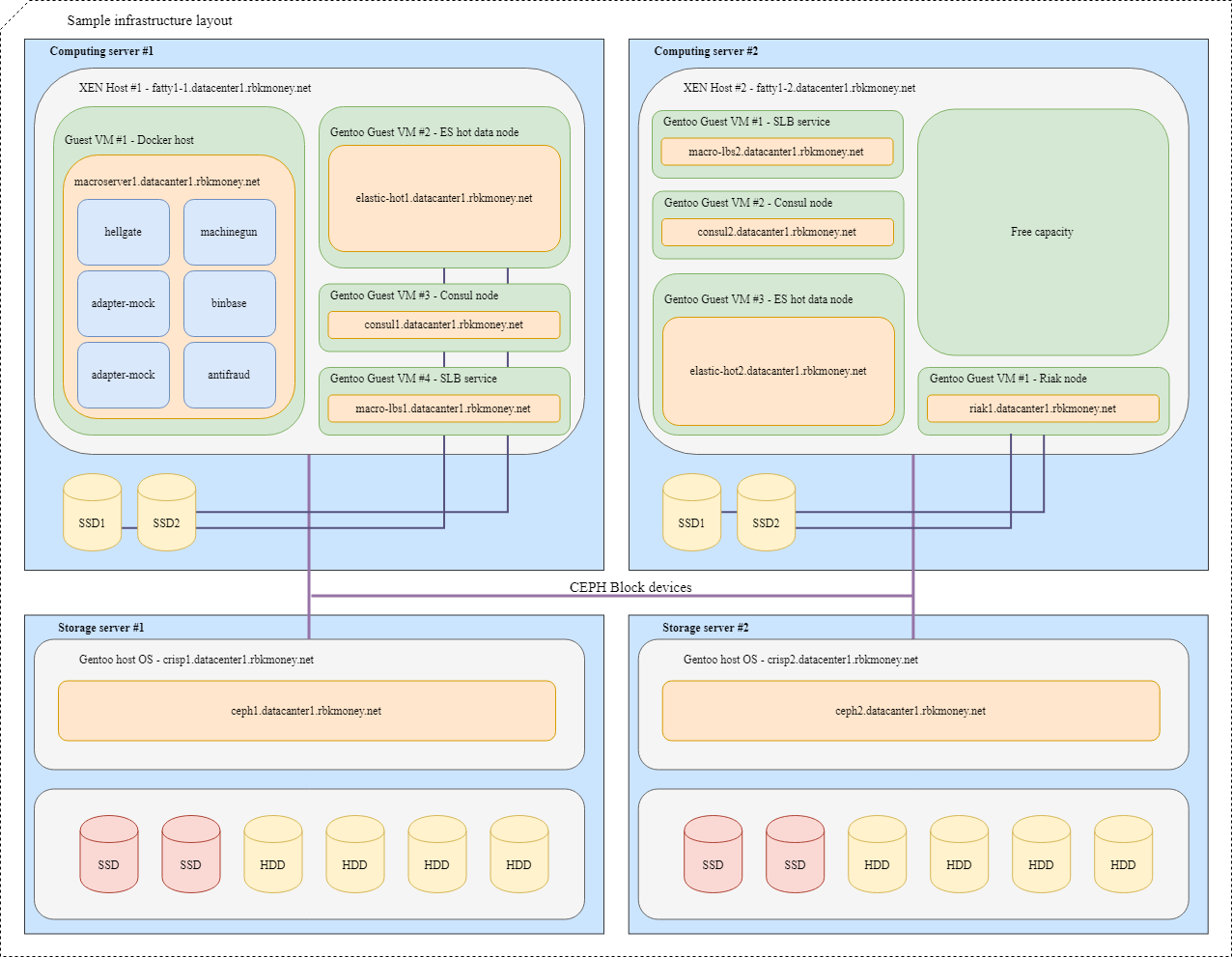
Pour les machines virtuelles avec des applications qui nécessitent une vitesse de périphérique de bloc maximale, telles que les nœuds actifs Riak et Elasticsearch, des partitions sur des disques NVMe locaux sont utilisées. Ces machines virtuelles sont étroitement liées à leur hyperviseur et les applications elles-mêmes sont responsables de la disponibilité et de l'intégrité de leurs données.
Pour les périphériques de bloc courants, nous utilisons Ceph RBD, généralement avec un cache dm en écriture sur le disque NVMe local. L'OSD de l'appareil peut être flash intégral ou disque dur avec journal SSD, selon le temps de réponse souhaité.
Livraison du trafic vers les applications
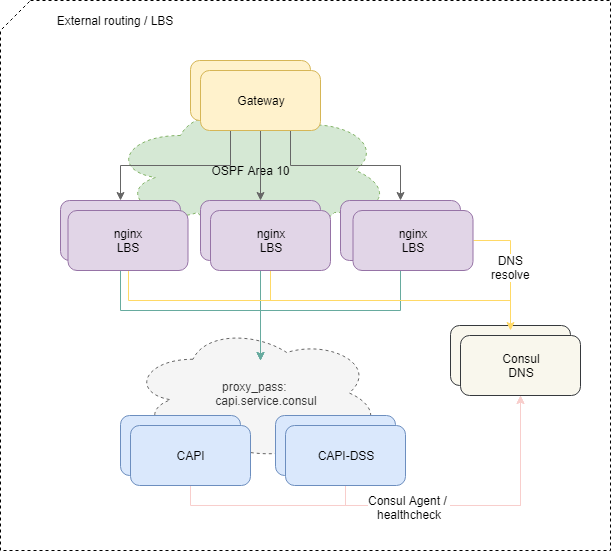
Pour équilibrer les demandes provenant de l'extérieur, nous utilisons le schéma ECMP OSPFv3 standard. De petites machines virtuelles avec nginx, bird, consul annoncent dans le cloud OSPF des adresses anycast communes depuis l'interface lo. Sur les routeurs, pour ces adresses, bird crée des routes à sauts multiples qui fournissent un équilibrage par flux, où le flux est "src-ip src-port dst-ip dst-port". Pour désactiver rapidement l'équilibreur manquant, le protocole BFD est utilisé.
Lors de l'ajout ou de l'échec de l'un des équilibreurs, les routeurs en amont font apparaître ou supprimer l'itinéraire correspondant, et le trafic réseau leur est délivré selon les approches multivoies à coût égal. Et si nous n'intervenons pas spécifiquement, alors tout le trafic réseau est réparti uniformément entre tous les équilibreurs disponibles sur chaque flux IP.
Soit dit en passant, l'approche avec l'équilibrage ECMP présente des pièges non évidents qui peuvent entraîner des pertes complètement non évidentes de certains trafics, en particulier si d'autres routeurs ou pare-feux étrangement configurés sont sur la route entre les systèmes.
Pour résoudre le problème, nous utilisons le démon PMTUD dans cette partie de l'infrastructure.
De plus, le trafic va à l'intérieur de la plate-forme vers des microservices spécifiques en fonction de la configuration nginx sur les équilibreurs.
Et si l'équilibrage du trafic externe est plus ou moins simple et compréhensible, il serait difficile d'étendre un tel schéma vers l'intérieur - nous avons besoin de plus que de simplement vérifier la disponibilité d'un conteneur avec un microservice au niveau du réseau.
Pour que le microservice commence à recevoir et à traiter les demandes, il doit s'enregistrer auprès de Service Discovery (nous utilisons Consul ), subir des contrôles de santé toutes les secondes et avoir un RTT raisonnable.
Si le microservice se sent bien et se comporte bien, Consul commence à résoudre l'adresse de son conteneur lors de l'accès à son DNS par le nom du service. Nous utilisons la zone interne service.consul et, par exemple, le microservice Common API version 2 sera nommé capi-v2.service.consul .
La configuration nginx concernant l'équilibrage à la fin ressemble à ceci:
location = /v2/ { set $service_hostname "${staging_pass}capi-v2.service.consul"; proxy_pass http://$service_hostname:8022; }
Ainsi, si nous n'intervenons pas à nouveau exprès, le trafic provenant des équilibreurs est réparti uniformément entre tous les microservices enregistrés dans Service Discovery, l'ajout ou la suppression de nouvelles instances des microservices nécessaires est entièrement automatisé.
Si la demande de l'équilibreur est remontée en amont et qu'il est décédé en cours de route, nous renvoyons 502 - l'équilibreur à son niveau ne peut pas déterminer si la demande était idempotente ou non, nous donnons donc le traitement de ces erreurs à un niveau logique supérieur.
Idempotence et délais
En général, nous n'avons pas peur et n'hésitons pas à donner des erreurs 5xx avec l'API, c'est une partie normale du système si vous effectuez le traitement correct de ces erreurs au niveau de la logique métier RPC. Les principes de ce traitement sont décrits dans notre formulaire sous la forme d'un petit manuel appelé politique de relance des erreurs, nous le distribuons à nos clients marchands et le mettons en œuvre au sein de nos services.
Pour simplifier ce traitement, nous avons mis en place plusieurs approches.
Tout d'abord, pour toute demande de changement d'état à notre API, vous pouvez spécifier une clé d'idempotency unique dans le compte, qui dure éternellement et vous permet d'être sûr qu'un appel répété avec le même ensemble de données renverra la même réponse.
Deuxièmement, nous avons mis en place un mécanisme supplémentaire sous la forme d'un identifiant unique pour la session de paiement, qui garantit l'idempotence des demandes de débit des fonds, offrant une protection contre les débits répétés erronés, même si vous ne générez pas et ne transmettez pas de clé d'idempotence distincte.
Troisièmement, nous avons décidé d'activer un temps de réponse prévisible et contrôlé de l'extérieur à tout appel externe à notre API sous la forme d'un paramètre de coupure de temps qui détermine le temps d'attente maximum pour qu'une opération se termine sur demande. Il suffit de transférer, par exemple, l'en-tête HTTP X-Request-Deadline: 10s pour être sûr que votre demande sera exécutée dans les 10 secondes ou sera tuée par la plateforme quelque part à l'intérieur, après quoi nous pourrons être recontactés, guidés par demande de politique de transfert.
Nous utilisons SaltStack comme outil de gestion pour les configurations et l'infrastructure dans son ensemble. Des outils distincts pour le contrôle automatisé de la puissance de calcul de la plate-forme n'ont pas encore décollé, même si nous comprenons déjà que nous irons dans cette direction. Avec notre amour des produits Hashicorp, ce sera probablement Nomad.
Les principaux outils de surveillance des infrastructures sont les contrôles dans Nagios, mais pour les entités commerciales, nous configurons principalement les alertes dans Grafana. Il dispose d'un outil très pratique pour définir les conditions et un modèle de plateforme basé sur les événements vous permet de tout écrire dans Elasticsearch et de configurer les conditions de sélection.
Les centres de données sont situés à Moscou, dans lesquels nous louons des espaces de stockage, installons et gérons indépendamment tout l'équipement. Nous n'utilisons pas d'optiques sombres n'importe où, nous n'avons accès à Internet qu'en dehors des fournisseurs locaux.
Sinon, nos approches de surveillance, de gestion et de services connexes sont plutôt standard pour l'industrie, je ne suis pas sûr que la prochaine description de l'intégration de ces services mérite d'être mentionnée dans un article.
Dans cet article, je terminerai probablement la série de publications sur la façon dont notre plateforme de paiement est organisée.
Je pense que le cycle s'est avéré assez franc, j'ai rencontré quelques articles qui révéleraient en détail la cuisine intérieure des grands systèmes de paiement.
En général, à mon avis, un niveau élevé d'ouverture et de franchise est une chose très importante pour le système de paiement. Cette approche augmente non seulement le niveau de confiance des partenaires et des payeurs, mais discipline également l'équipe, les créateurs et les opérateurs du service.
Ainsi, guidés par ce principe, nous avons récemment rendu public l'état de la plateforme et l'historique de disponibilité de nos services. L'historique complet de notre disponibilité, des mises à jour et des plantages est désormais public et disponible sur https://status.rbk.money/ .
J'espère que vous étiez intéressé, et peut-être que quelqu'un trouvera nos approches et les erreurs décrites utiles. Si vous êtes intéressé par l'un des domaines décrits dans les articles et que vous souhaitez que je les dévoile plus en détail, n'hésitez pas à écrire dans les commentaires ou dans PM.
Merci d'être avec nous!

PS Pour votre commodité, un pointeur vers les articles précédents de la série: