Comme dans la
plupart des articles , il y avait un problème avec un service distribué, appelons ce service Alvin. Cette fois, je n'ai pas trouvé le problème moi-même, m'ont informé les gars de la partie client.
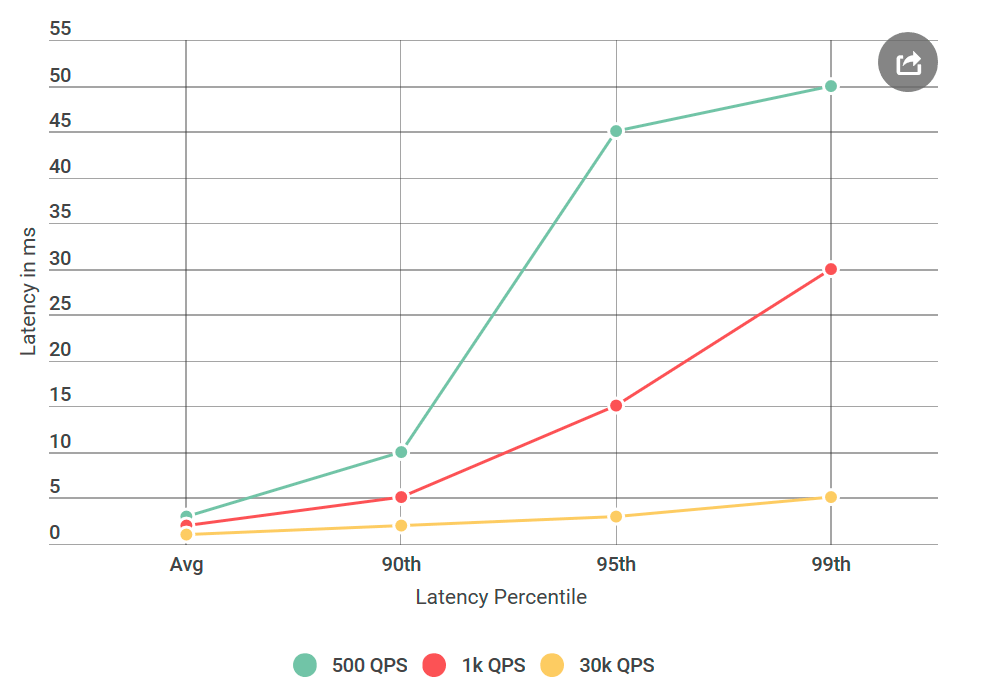
Une fois, je me suis réveillé d'une lettre mécontente en raison des gros retards d'Alvin, que nous avions prévu de lancer dans un avenir proche. En particulier, le client a rencontré un retard du 99e centile d'environ 50 ms, bien supérieur à notre budget de retard. C'était surprenant, car j'ai testé le service à fond, surtout pour les retards, car cela fait l'objet de plaintes fréquentes.
Avant de donner Alvin pour les tests, j'ai mené de nombreuses expériences avec 40 000 requêtes par seconde (QPS), toutes montrant un retard de moins de 10 ms. J'étais prêt à déclarer que je n'étais pas d'accord avec leurs résultats. Mais une fois de plus en regardant la lettre, j'ai attiré l'attention sur quelque chose de nouveau: je n'ai certainement pas testé les conditions qu'ils ont mentionnées, leur QPS était beaucoup plus bas que le mien. J'ai testé sur 40k QPS, et ils seulement sur 1k. J'ai exécuté une autre expérience, cette fois avec un QPS inférieur, juste pour leur faire plaisir.
Depuis que j'écris à ce sujet sur mon blog, vous avez probablement déjà compris: leur nombre s'est avéré correct. J'ai testé mon client virtuel encore et encore, tous avec le même résultat: un faible nombre de demandes augmente non seulement le délai, mais augmente également le nombre de demandes avec un délai supérieur à 10 ms. En d'autres termes, si à 40k QPS, environ 50 requêtes par seconde dépassaient 50 ms, alors à 1k QPS chaque seconde, il y avait 100 requêtes au-dessus de 50 ms. Paradoxe!
Affinez votre recherche
Face au problème du retard dans un système distribué à nombreux composants, la première chose que vous devez faire est de dresser une courte liste de suspects. Nous approfondissons un peu plus l'architecture d'Alvin:
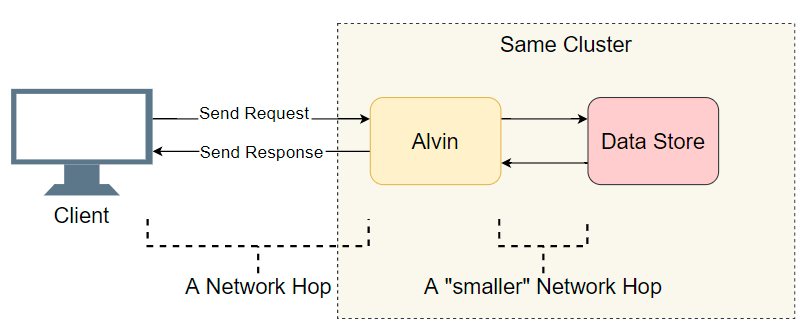
Un bon point de départ est une liste des transitions d'E / S terminées (appels réseau / recherches de disque, etc.). Essayons de savoir où est le retard. En plus des E / S évidentes avec le client, Alvin franchit une étape supplémentaire: il accède à l'entrepôt de données. Cependant, ce stockage fonctionne dans le même cluster avec Alvin, donc il devrait y avoir moins de retard qu'avec le client. Donc, la liste des suspects:
- Appel réseau du client vers Alvin.
- Appel réseau d'Alvin à l'entrepôt de données.
- Recherche sur disque dans l'entrepôt de données.
- Appel réseau depuis l'entrepôt de données vers Alvin.
- Appel réseau d'Alvin au client.
Essayons de rayer certains points.
Entrepôt de données
La première chose que j'ai faite a été de convertir Alvin en un serveur ping-ping qui ne gère pas les requêtes. Dès réception de la demande, il renvoie une réponse vide. Si le délai diminue, alors une erreur dans la mise en œuvre d'Alvin ou de l'entrepôt de données n'est rien de inconnu. Dans la première expérience, nous obtenons le graphique suivant:
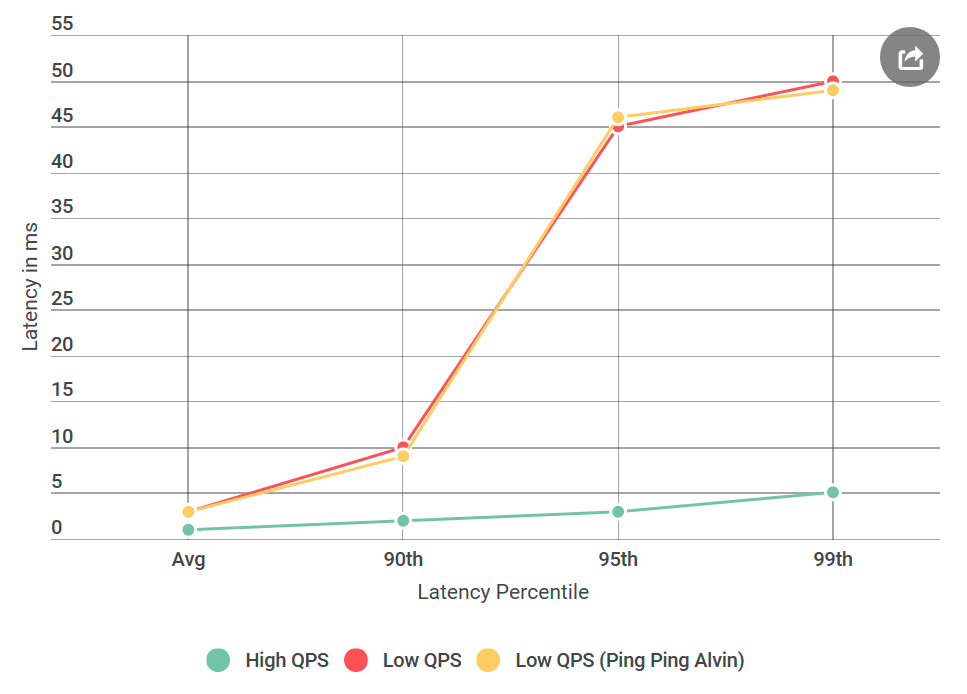
Comme vous pouvez le voir, lors de l'utilisation du serveur ping-ping, il n'y a aucune amélioration. Cela signifie que l'entrepôt de données n'augmente pas le délai et la liste des suspects est divisée par deux:
- Appel réseau du client vers Alvin.
- Appel réseau d'Alvin au client.
Ouah! La liste se rétrécit rapidement. Je pensais avoir presque compris la raison.
gRPC
Il est maintenant temps de vous présenter un nouveau joueur:
gRPC . Il s'agit d'une bibliothèque open source de Google pour les communications
RPC en cours . Bien que
gRPC bien optimisé et largement utilisé, je l'ai utilisé pour la première fois sur un système de cette ampleur, et je m'attendais à ce que ma mise en œuvre soit sous-optimale - pour le moins.
La présence de
gRPC dans la pile a soulevé une nouvelle question: peut-être est-ce mon implémentation ou
gRPC lui-même cause-
gRPC -il un problème de retard? Ajouter à la liste du nouveau suspect:
- Le client appelle la bibliothèque
gRPC
- La bibliothèque
gRPC sur le client effectue un appel réseau à la bibliothèque gRPC sur le serveur
gRPC bibliothèque gRPC accède à Alvin (aucune opération en cas de serveur ping-pong)
Pour vous faire comprendre à quoi ressemble le code, mon implémentation client / Alvin n'est pas très différente des
exemples client-serveur
asynchrone .
Remarque: la liste ci-dessus est un peu simplifiée, car gRPC vous permet d'utiliser votre propre (modèle?) Modèle de flux, dans lequel la gRPC exécution gRPC et l'implémentation utilisateur sont entrelacées. Par souci de simplicité, nous nous en tiendrons à ce modèle.
Le profilage résoudra tout
En traversant les entrepôts de données, je pensais que j'avais presque fini: «Maintenant, c'est facile! Nous appliquerons le profil et découvrirons où le retard se produit. " Je suis un
grand fan du profilage précis car les CPU sont très rapides et le plus souvent ils ne sont pas un goulot d'étranglement. La plupart des retards se produisent lorsque le processeur doit arrêter le traitement pour faire autre chose. Un profilage précis du CPU a été fait juste pour cela: il enregistre avec précision tous les
changements de contexte et indique clairement où les retards se produisent.
J'ai pris quatre profils: sous QPS élevé (faible latence) et avec un serveur de ping-pong sur QPS faible (latence élevée), à la fois côté client et côté serveur. Et juste au cas où, j'ai également pris un exemple de profil de processeur. Lorsque je compare des profils, je recherche généralement une pile d'appels anormale. Par exemple, du mauvais côté avec un retard élevé, il y a beaucoup plus de changements de contexte (10 fois ou plus). Mais dans mon cas, le nombre de changements de contexte a presque coïncidé. À mon horreur, il n'y avait rien de significatif là-bas.
Débogage supplémentaire
J'étais désespéré. Je ne savais pas quels autres outils pouvaient être utilisés, et mon prochain plan était essentiellement de répéter les expériences avec différentes variantes, et non de diagnostiquer clairement le problème.
Et si
Dès le début, je m'inquiétais du temps de retard spécifique de 50 ms. C'est un très grand moment. J'ai décidé de couper les morceaux du code jusqu'à ce que je puisse déterminer exactement quelle partie était à l'origine de cette erreur. Puis a suivi une expérience qui a fonctionné.
Comme d'habitude, l'esprit en arrière semble que tout était évident. J'ai mis le client sur la même machine qu'Alvin - et j'ai envoyé la demande à
localhost . Et l'augmentation du retard a disparu!
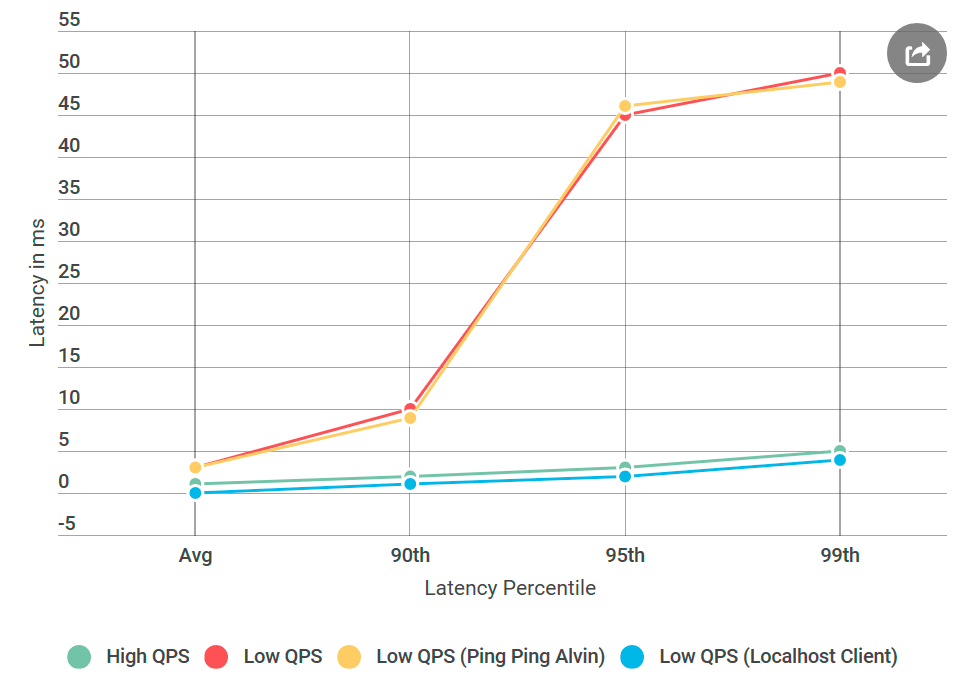
Quelque chose n'allait pas avec le réseau.
Acquérir les compétences d'un ingénieur réseau
Je dois admettre que ma connaissance des technologies réseau est terrible, surtout si l'on considère que je travaille quotidiennement avec elles. Mais le réseau était le principal suspect, et j'avais besoin d'apprendre à le déboguer.
Heureusement, Internet aime ceux qui veulent apprendre. La combinaison de ping et de tracert semblait un bon début pour déboguer les problèmes de transport réseau.
Tout d'abord, j'ai exécuté
PsPing sur le port TCP d'
Alvin . J'ai utilisé les options par défaut - rien de spécial. Sur plus d'un millier de pings, aucun n'a dépassé 10 ms, à l'exception du premier pour l'échauffement. Cela contredit l'augmentation observée du retard de 50 ms dans le 99e centile: là, pour 100 requêtes, nous devrions voir environ une requête avec un retard de 50 ms.
Ensuite, j'ai essayé
tracert : peut-être que le problème est sur l'un des nœuds le long de la route entre Alvin et le client. Mais le traceur est revenu les mains vides.
Ainsi, la raison du retard n'était pas mon code, ni la mise en œuvre de gRPC, ni le réseau. J'ai déjà commencé à craindre de ne jamais comprendre cela.
Maintenant, sur quel système d'exploitation sommes-nous
gRPC largement utilisé sous Linux, mais il est exotique pour Windows. J'ai décidé de mener une expérience qui a fonctionné: j'ai créé une machine virtuelle Linux, compilé Alvin pour Linux et l'ai déployé.
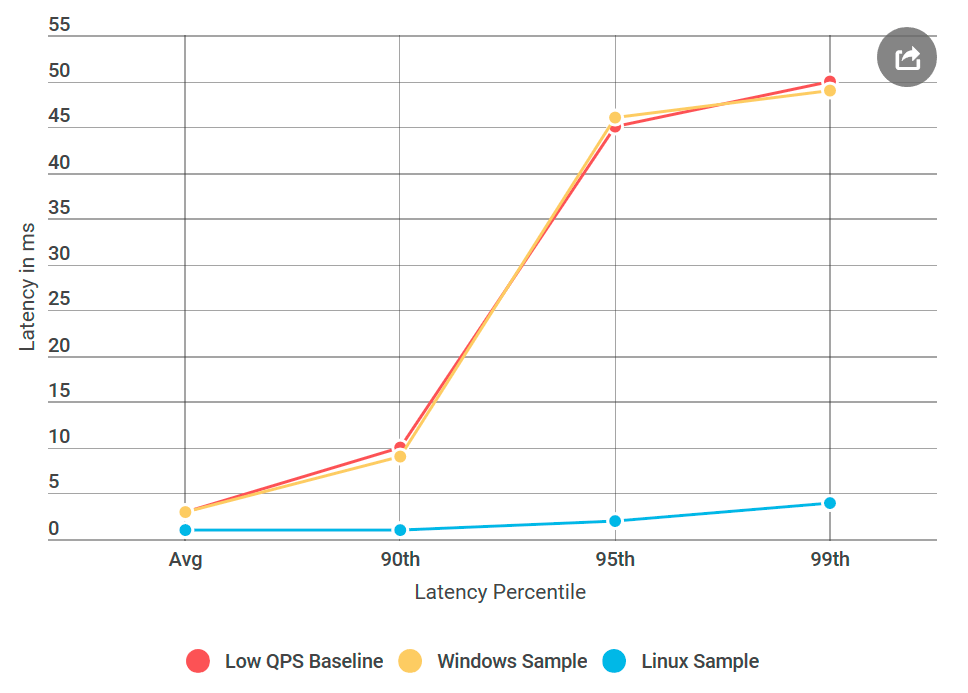
Et voici ce qui s'est passé: le serveur Linux de ping-pong n'a pas eu des retards comme un nœud Windows similaire, bien que la source de données ne diffère pas. Il s'avère que le problème est lié à l'implémentation de gRPC pour Windows.
Algorithme Nagle
gRPC tout ce temps, je pensais que je
gRPC drapeau
gRPC . Maintenant, je me suis rendu compte qu'il manquait en
gRPC le drapeau Windows dans
gRPC . J'ai trouvé la bibliothèque RPC interne, dans laquelle j'étais sûr qu'elle fonctionne bien pour tous
les drapeaux
Winsock installés. Il a ensuite ajouté tous ces drapeaux à gRPC et déployé Alvin sur Windows, dans le serveur de ping-pong fixe pour Windows!
 Presque
Presque terminé: j'ai commencé à supprimer les drapeaux ajoutés un par un jusqu'à ce que la régression revienne, afin de pouvoir en identifier la cause. C'était le tristement célèbre
TCP_NODELAY , un commutateur de l'algorithme Nagle.
L'algorithme Neigl tente de réduire le nombre de paquets envoyés sur le réseau en retardant la transmission des messages jusqu'à ce que la taille des paquets dépasse un certain nombre d'octets. Bien que cela puisse être agréable pour l'utilisateur moyen, il est destructeur pour les serveurs en temps réel, car le système d'exploitation retardera certains messages, entraînant des retards sur un faible QPS.
gRPC avait cet indicateur défini dans l'implémentation Linux pour les sockets TCP, mais pas pour Windows. Je l'ai
réparé .
Conclusion
Un gros retard dans le faible QPS a été causé par l'optimisation du système d'exploitation. Avec le recul, le profilage n'a pas détecté de retard car il a été effectué en mode noyau et non en
mode utilisateur . Je ne sais pas s’il est possible d’observer l’algorithme Nagle via des captures ETW, mais ce serait intéressant.
Quant à l'expérience localhost, elle n'a probablement pas touché le code réseau réel et l'algorithme Neigl n'a pas démarré, de sorte que les problèmes de retard ont disparu lorsque le client a contacté Alvin via localhost.
La prochaine fois que vous constaterez une augmentation de la latence tout en diminuant le nombre de requêtes par seconde, l'algorithme Neigl devrait figurer sur votre liste de suspects!