
Présentation
J'ai fait ce rapport en anglais lors de la conférence GopherCon Russia 2019 à Moscou et en russe lors de la réunion à Nizhny Novgorod. Il s'agit d'un index bitmap - moins courant que l'arbre B, mais non moins intéressant. Je partage l'
enregistrement du discours de la conférence en anglais et la transcription du texte en russe.
Nous allons examiner comment fonctionne l'index bitmap, quand il est meilleur, quand il est pire que les autres index, et dans quels cas il est beaucoup plus rapide qu'eux; Nous verrons quels SGBD populaires ont déjà des index bitmap. essayez d'écrire le vôtre sur Go. Et pour le dessert, nous utiliserons des bibliothèques prêtes à l'emploi pour créer notre propre base de données spécialisée ultra-rapide.
J'espère vraiment que mon travail vous sera utile et intéressant. C'est parti!
Présentation
http://bit.ly/bitmapindexeshttps://github.com/mkevac/gopherconrussia2019Bonjour à tous! Il est six heures du soir, nous sommes tous super fatigués. Le bon moment pour parler de la théorie ennuyeuse des index de base de données, non? Ne vous inquiétez pas, j'aurai quelques lignes de code source ici et là. :-)
Si sans blagues, alors le rapport est plein d'informations, et nous n'avons pas beaucoup de temps. Commençons donc.

Aujourd'hui, je vais parler des éléments suivants:
- quels sont les index;
- qu'est-ce qu'un index bitmap;
- où il est utilisé et où il n'est PAS utilisé et pourquoi;
- implémentation simple sur Go et un peu de mal avec le compilateur;
- implémentation un peu moins simple, mais beaucoup plus productive dans Go-assembler;
- «Problèmes» des index bitmap;
- implémentations existantes.
Quels sont donc les index?
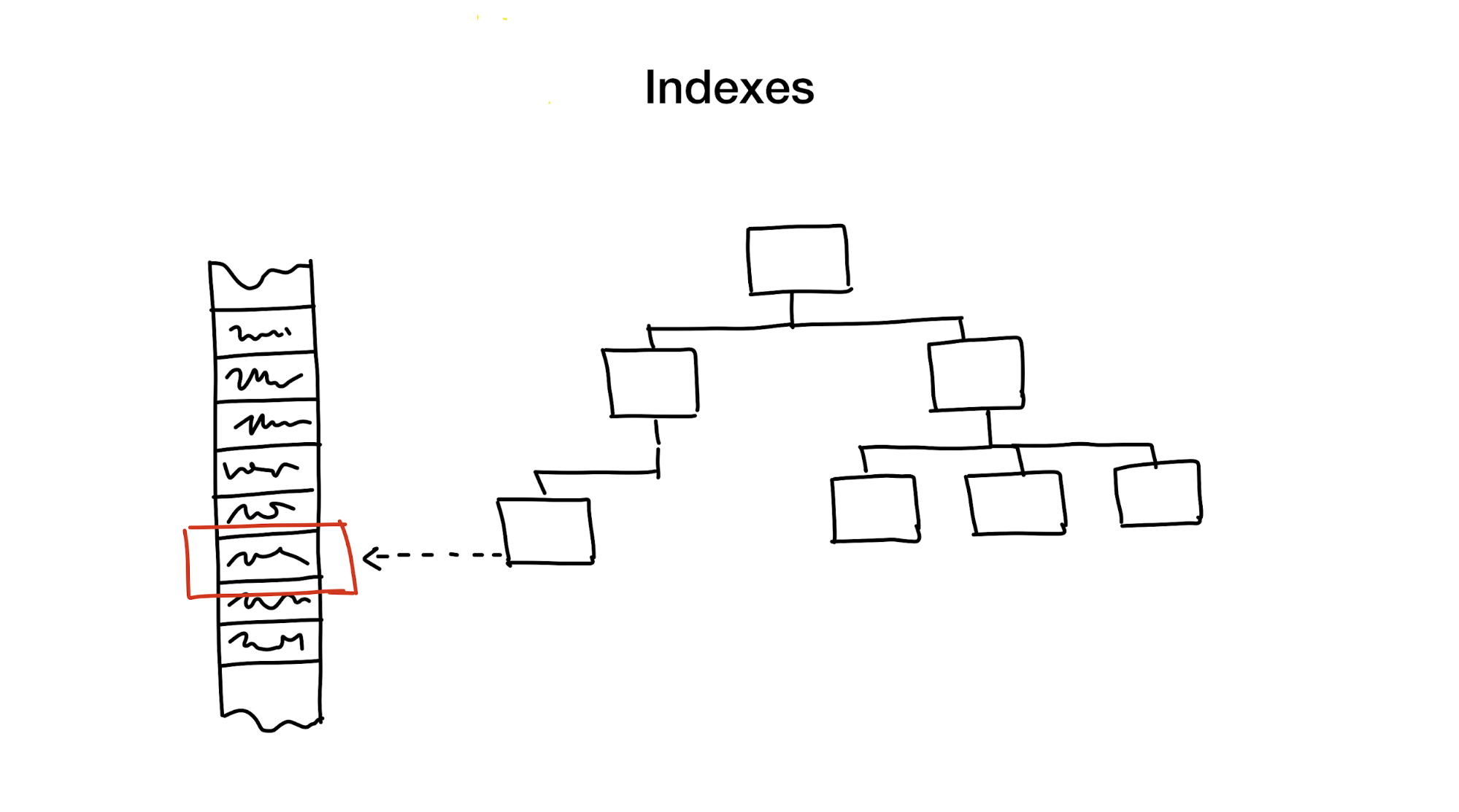
Un index est une structure de données distincte que nous détenons et mettons à jour en plus des données principales. Il est utilisé pour accélérer la recherche. Sans index, une recherche nécessiterait un passage complet à travers les données (un processus appelé analyse complète), et ce processus a une complexité algorithmique linéaire. Mais les bases de données contiennent généralement une énorme quantité de données et la complexité linéaire est trop lente. Idéalement, nous obtiendrions une logarithmique ou une constante.
C'est un énorme sujet complexe, débordant de subtilités et de compromis, mais après avoir examiné des décennies de développement et de recherche de diverses bases de données, je suis prêt à affirmer qu'il n'y a que quelques approches largement utilisées pour créer des index de base de données.

La première approche consiste à réduire hiérarchiquement la zone de recherche, en divisant la zone de recherche en parties plus petites.
Habituellement, nous faisons cela en utilisant toutes sortes d'arbres. Un exemple est une grande boîte avec des matériaux dans votre placard, dans laquelle il y a des boîtes plus petites avec des matériaux divisés par divers sujets. Si vous avez besoin de matériaux, vous les chercherez probablement dans une boîte avec les mots "Matériaux", et non dans celle qui dit "Cookies", non?
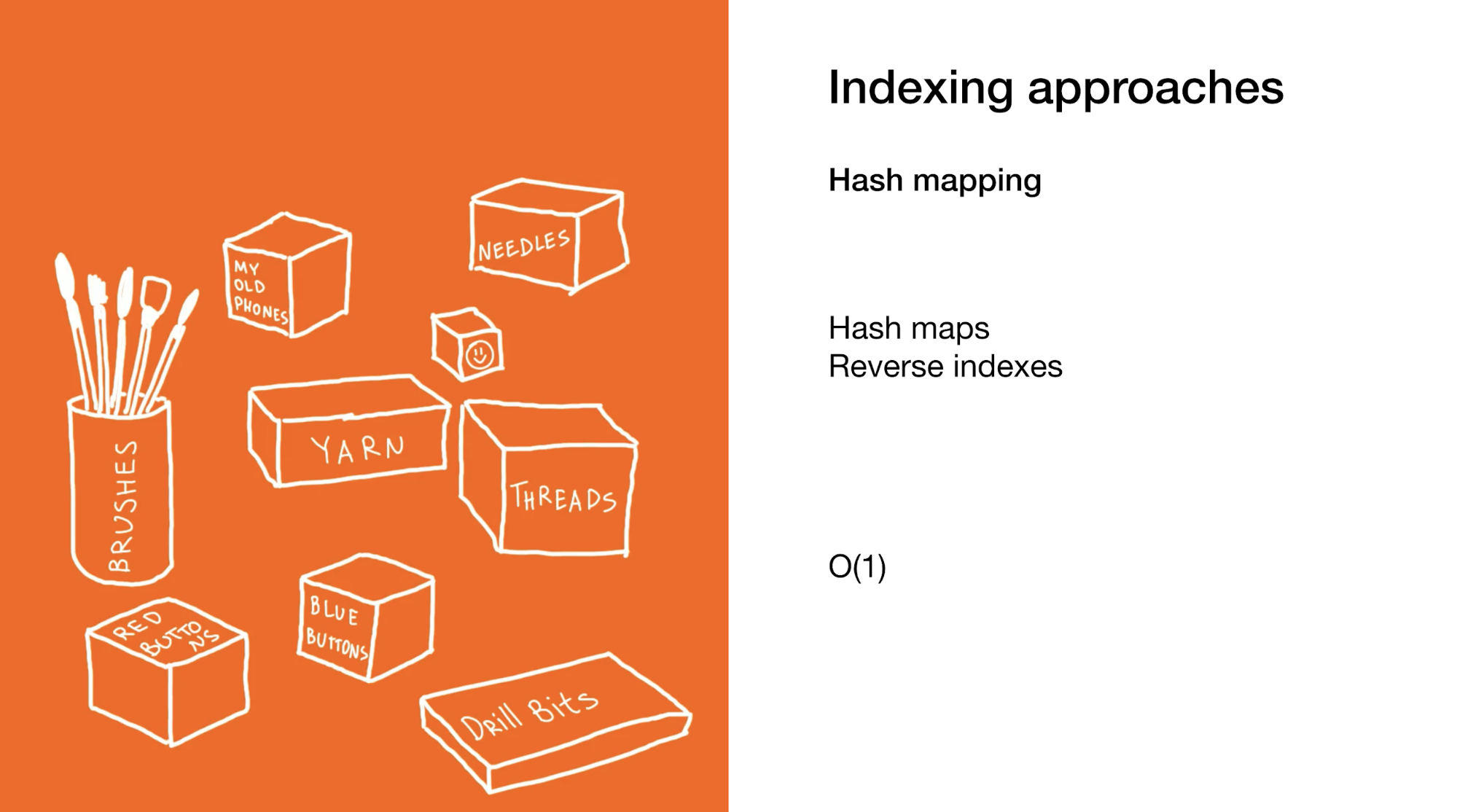
La deuxième approche consiste à sélectionner immédiatement l'élément ou le groupe d'éléments souhaité. Nous le faisons dans des cartes de hachage ou dans des index inverses. L'utilisation de cartes de hachage est très similaire à l'exemple précédent, mais au lieu d'une boîte avec des boîtes dans votre placard, il y a beaucoup de petites boîtes avec des éléments finaux.

La troisième approche consiste à se débarrasser de la nécessité d'une recherche. Nous le faisons en utilisant des filtres Bloom ou des filtres à coucou. Les premiers fournissent une réponse instantanément, éliminant le besoin de chercher.
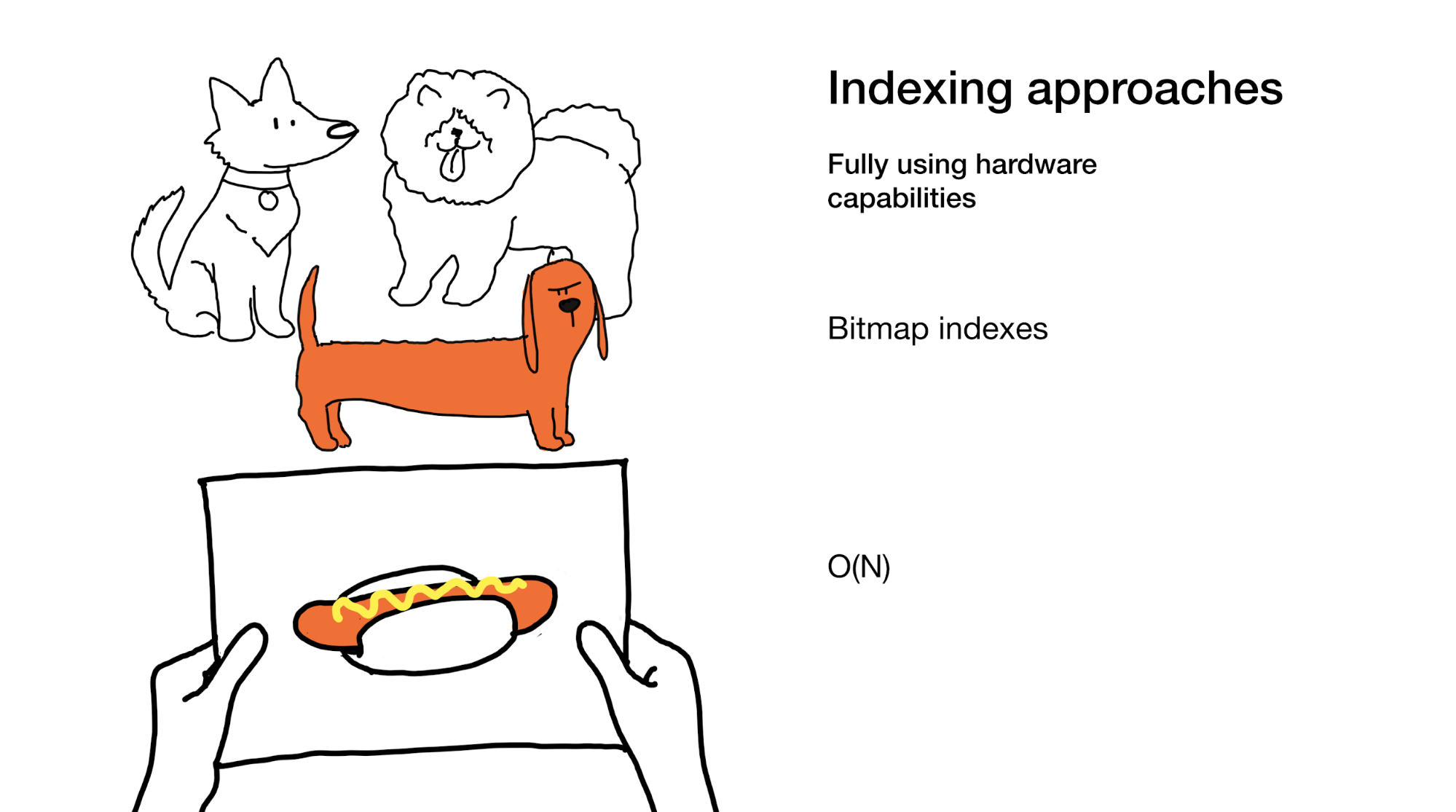
La dernière approche consiste à utiliser pleinement toutes les capacités que le fer moderne nous donne. C'est exactement ce que nous faisons dans les index bitmap. Oui, lors de leur utilisation, nous devons parfois parcourir l'intégralité de l'index, mais nous le faisons de manière très efficace.
Comme je l'ai dit, le sujet des index de base de données est vaste et déborde de compromis. Cela signifie que parfois nous pouvons utiliser plusieurs approches en même temps: si nous devons accélérer encore plus la recherche ou s'il est nécessaire de couvrir tous les types de recherche possibles.
Aujourd'hui, je vais parler de l'approche la moins connue de ces derniers - sur les index bitmap.
Qui suis-je pour en parler?
Je travaille en tant que chef d'équipe à Badoo (vous connaissez peut-être mieux notre autre produit, Bumble). Nous avons déjà plus de 400 millions d'utilisateurs dans le monde et de nombreuses fonctionnalités qui sont engagées dans la sélection de la meilleure paire pour eux. Nous le faisons en utilisant des services personnalisés qui utilisent également des index bitmap.
Qu'est-ce qu'un index bitmap?
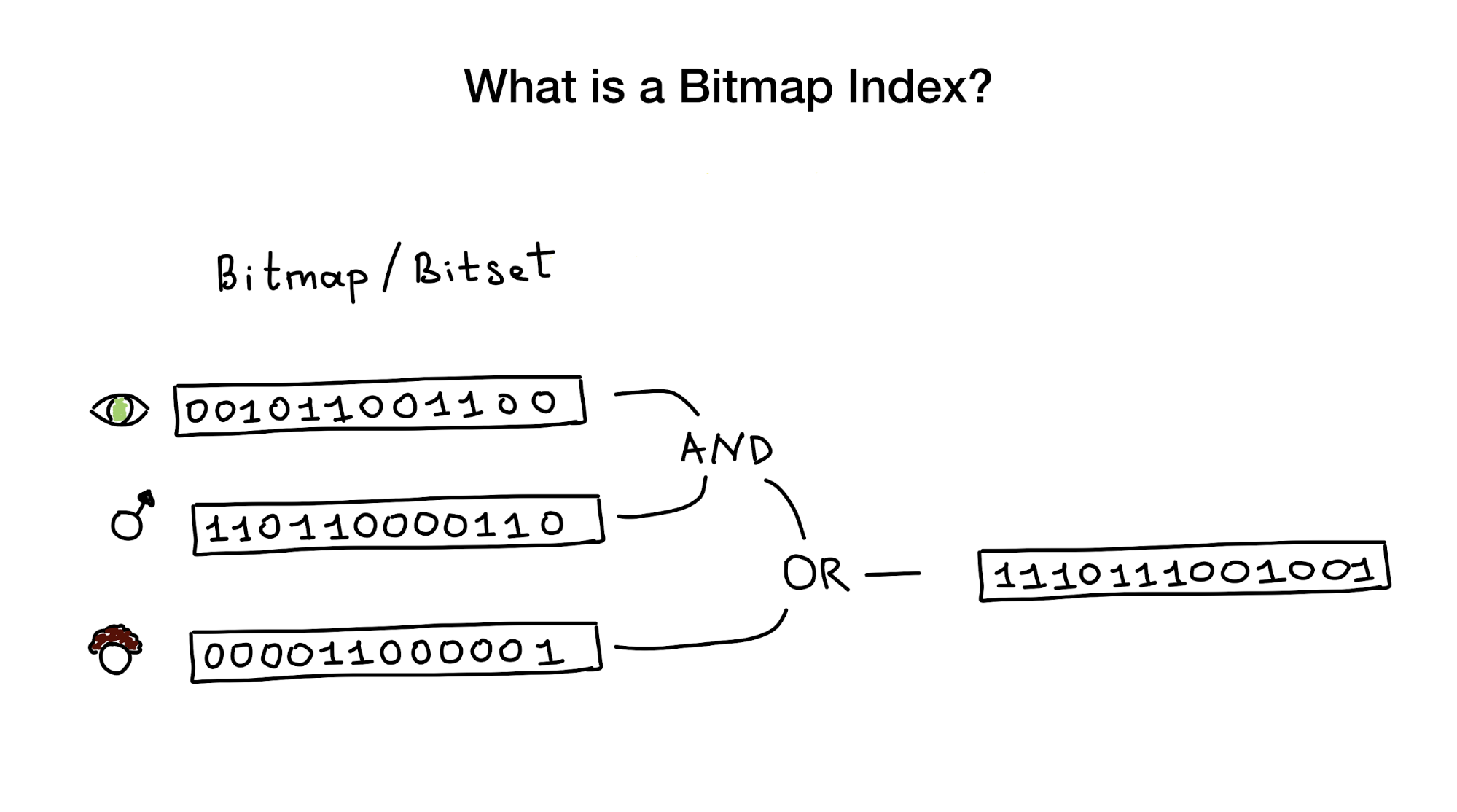
Les index bitmap, comme leur nom nous l'indique, utilisent des bitmaps ou des bitsets pour implémenter un index de recherche. D'un point de vue d'oiseau, cet index se compose d'un ou plusieurs bitmaps représentant des entités (telles que des personnes) et leurs propriétés ou paramètres (âge, couleur des yeux, etc.), et d'un algorithme qui utilise des opérations binaires (ET, OU, NON) pour répondre à une requête de recherche.

On nous dit que les index bitmap sont les mieux adaptés et très productifs dans les cas où il existe une recherche qui combine des requêtes sur de nombreuses colonnes qui ont peu de cardinalité (imaginez la «couleur des yeux» ou «l'état matrimonial» contre quelque chose comme «la distance du centre-ville» ) Mais plus tard, je montrerai qu'ils fonctionnent parfaitement dans le cas de colonnes à cardinalité élevée.
Prenons l'exemple le plus simple d'un index bitmap.

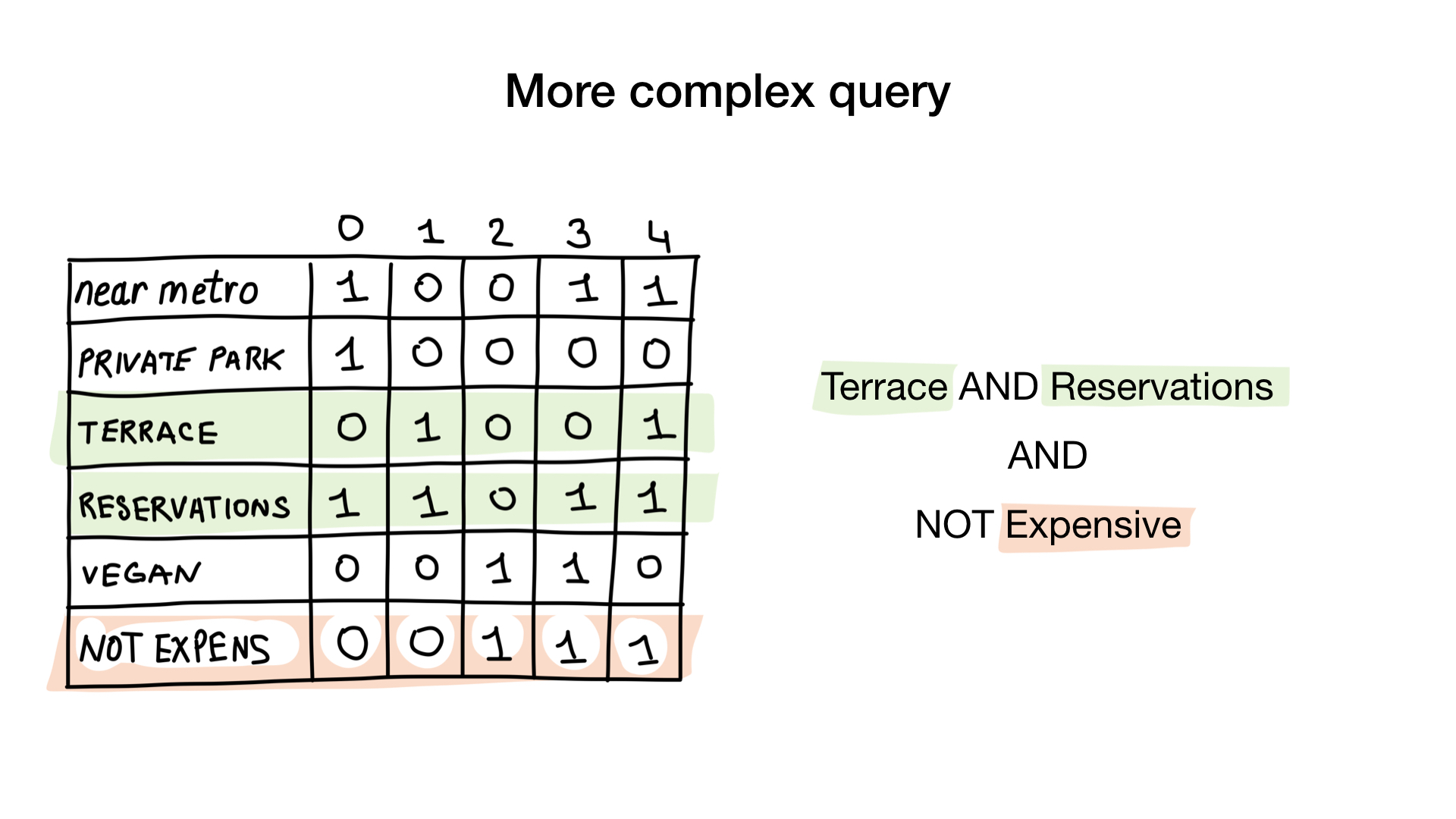
Imaginez que nous avons une liste de restaurants de Moscou avec des propriétés binaires comme celles-ci:
- près du métro (près du métro);
- il y a un parking privé (a un parking privé);
- il y a une véranda (a terrasse);
- Vous pouvez réserver une table (accepte les réservations);
- adapté aux végétariens (végétalien);
- cher (cher).
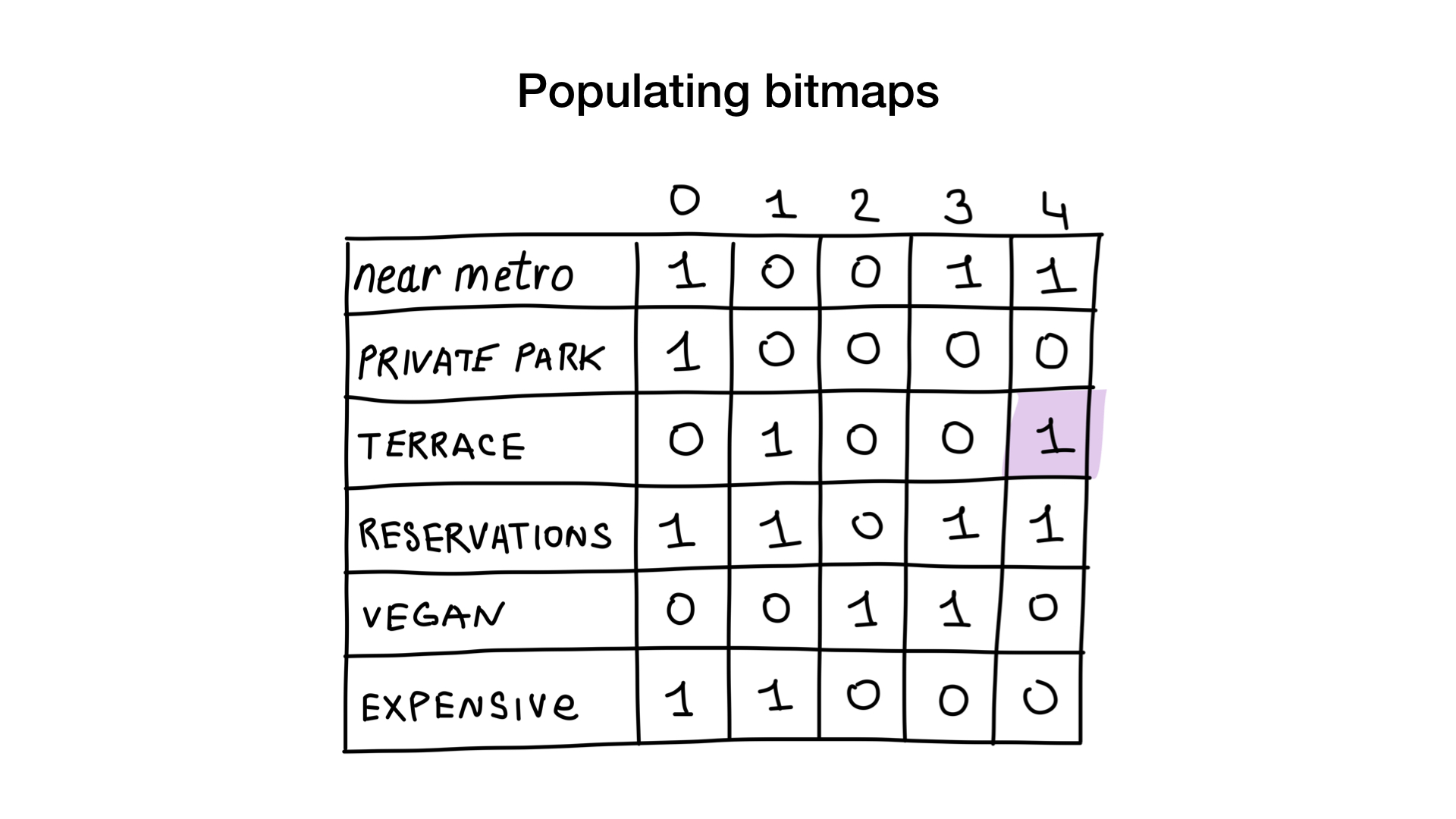
Donnons à chaque restaurant un numéro de série commençant à 0 et allouons de la mémoire à 6 bitmaps (un pour chaque caractéristique). Ensuite, nous remplissons ces bitmaps, selon que le restaurant possède ou non cette propriété. Si le restaurant 4 a une véranda, le bit n ° 4 du bitmap "il y a une véranda" sera mis à 1 (s'il n'y a pas de véranda, alors à 0).

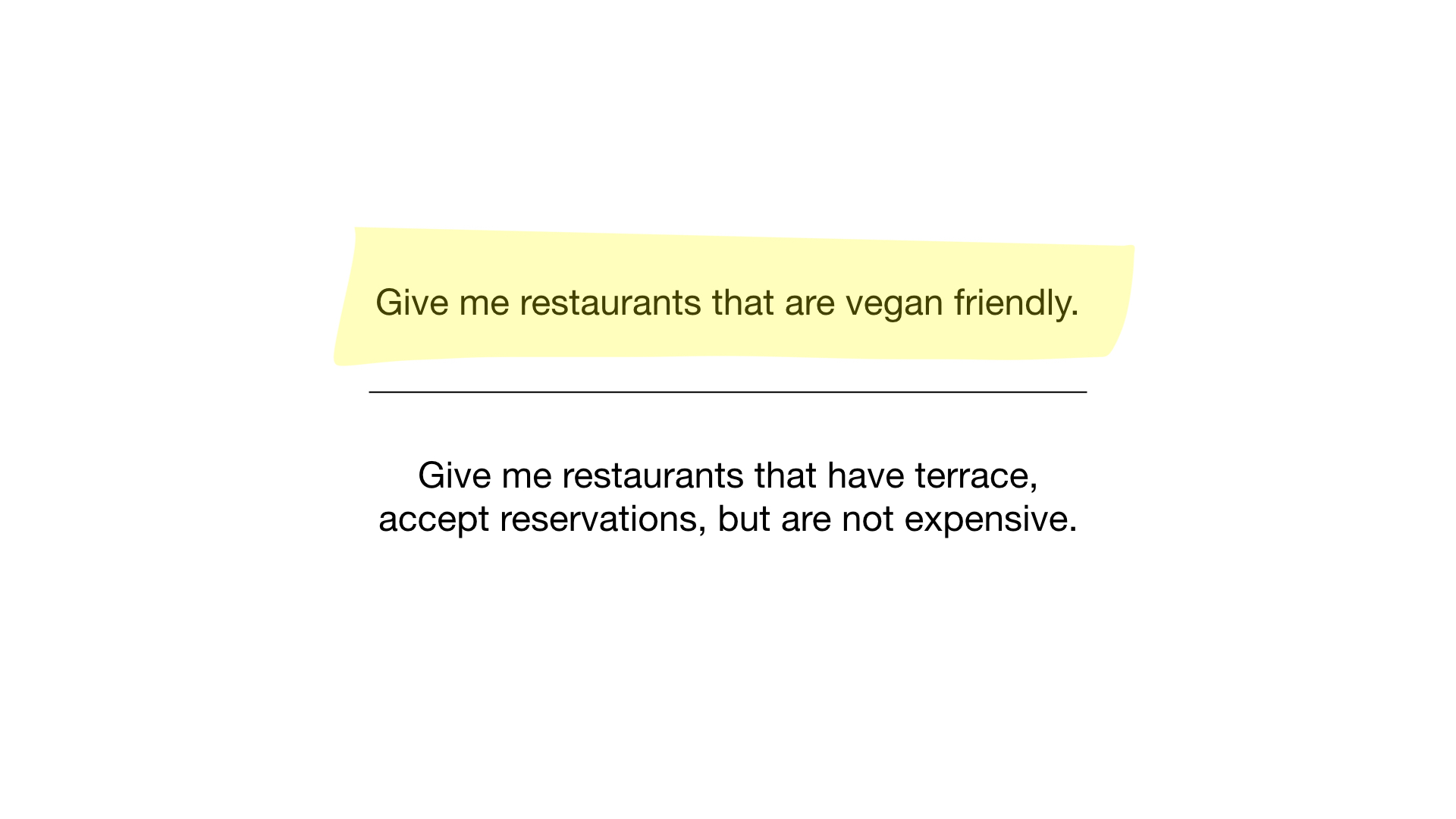
Nous avons maintenant l'index bitmap le plus simple possible, et nous pouvons l'utiliser pour répondre à des requêtes comme:
- «Montrez-moi des restaurants adaptés aux végétariens»;
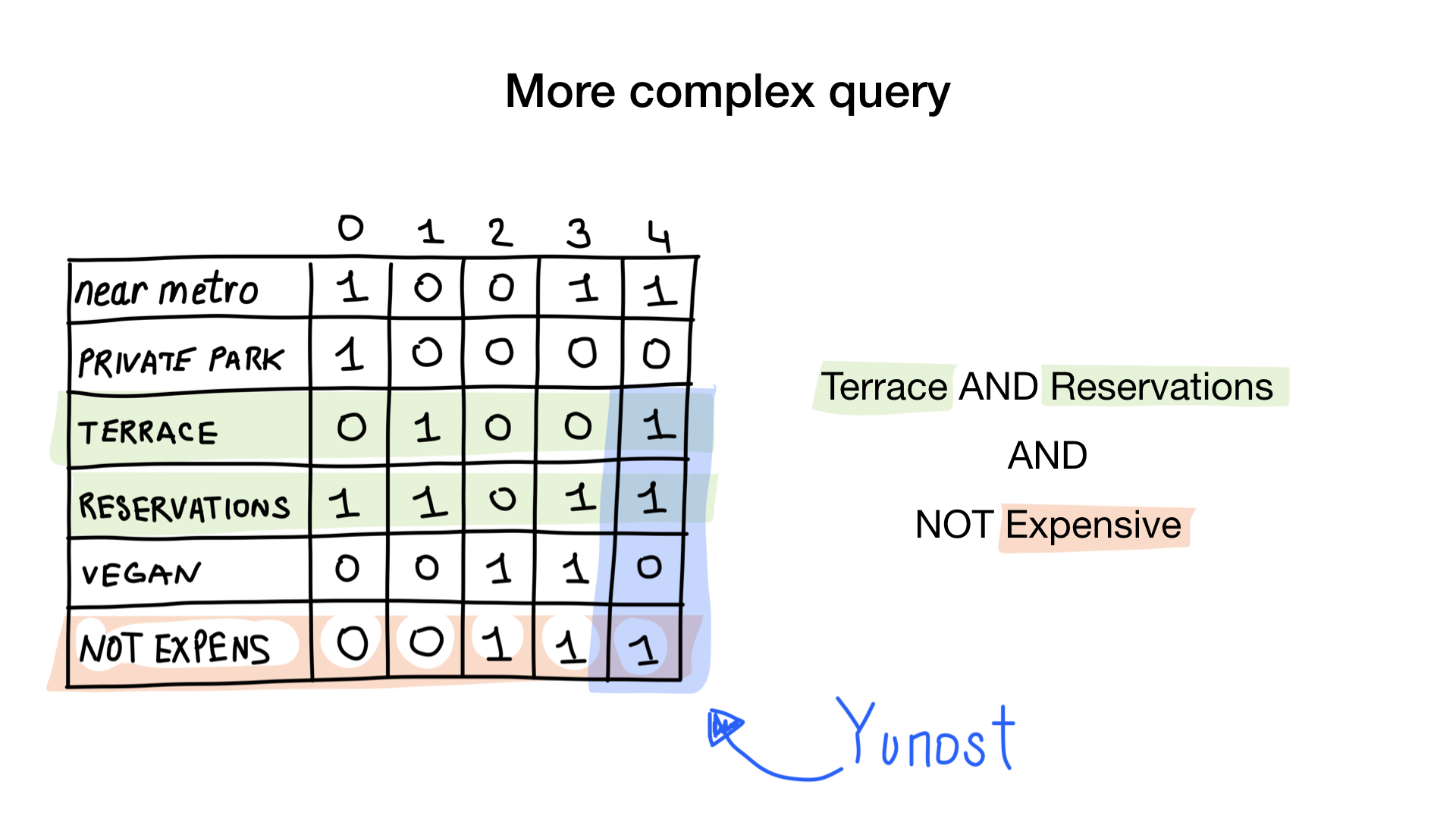
- "Montrez-moi des restaurants bon marché avec une véranda où vous pouvez réserver une table."
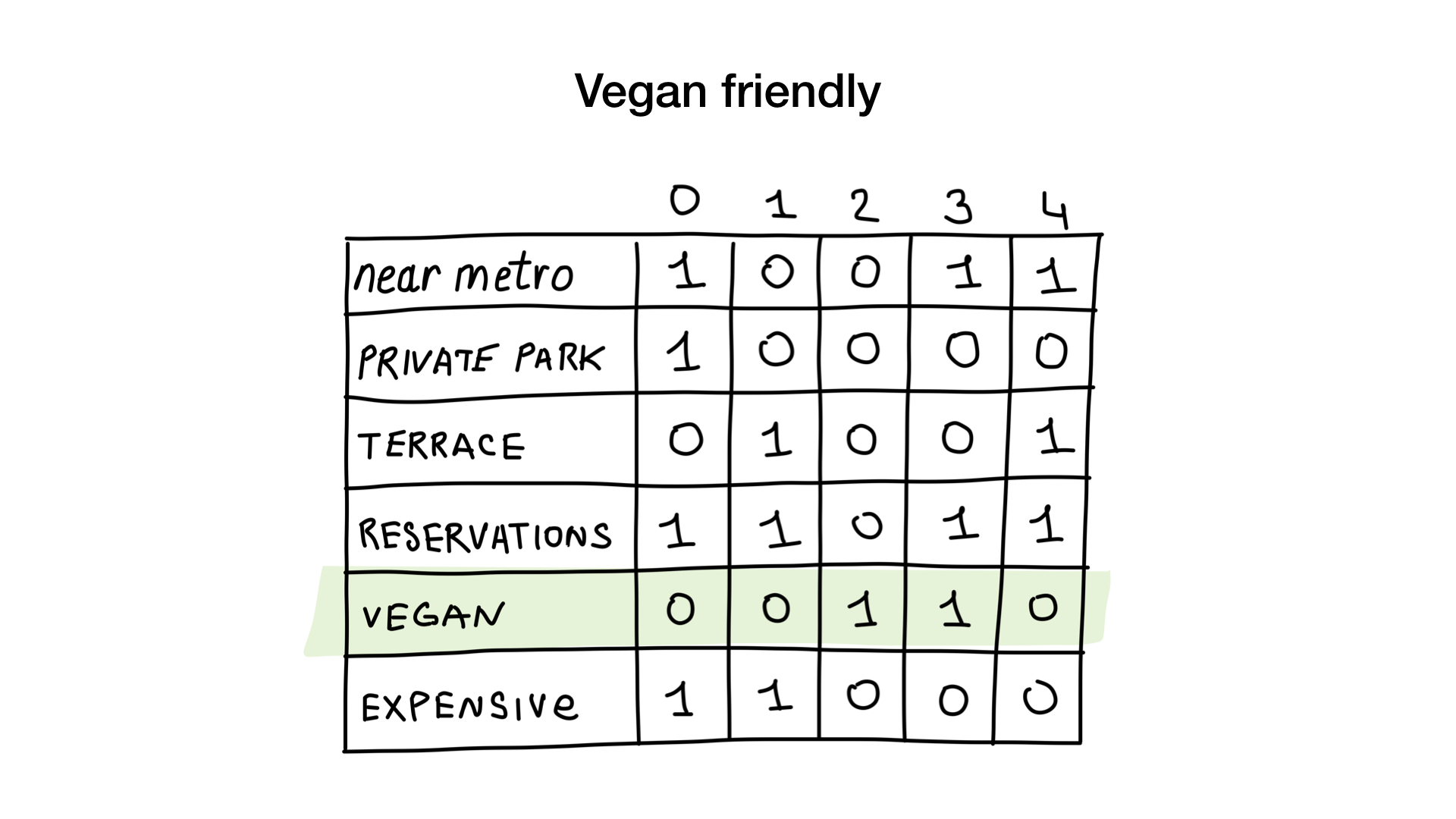
Comment? Voyons voir. La première demande est très simple. Tout ce que nous devons faire est de prendre le bitmap «adapté aux végétariens» et de le transformer en une liste de restaurants dont les morceaux sont affichés.
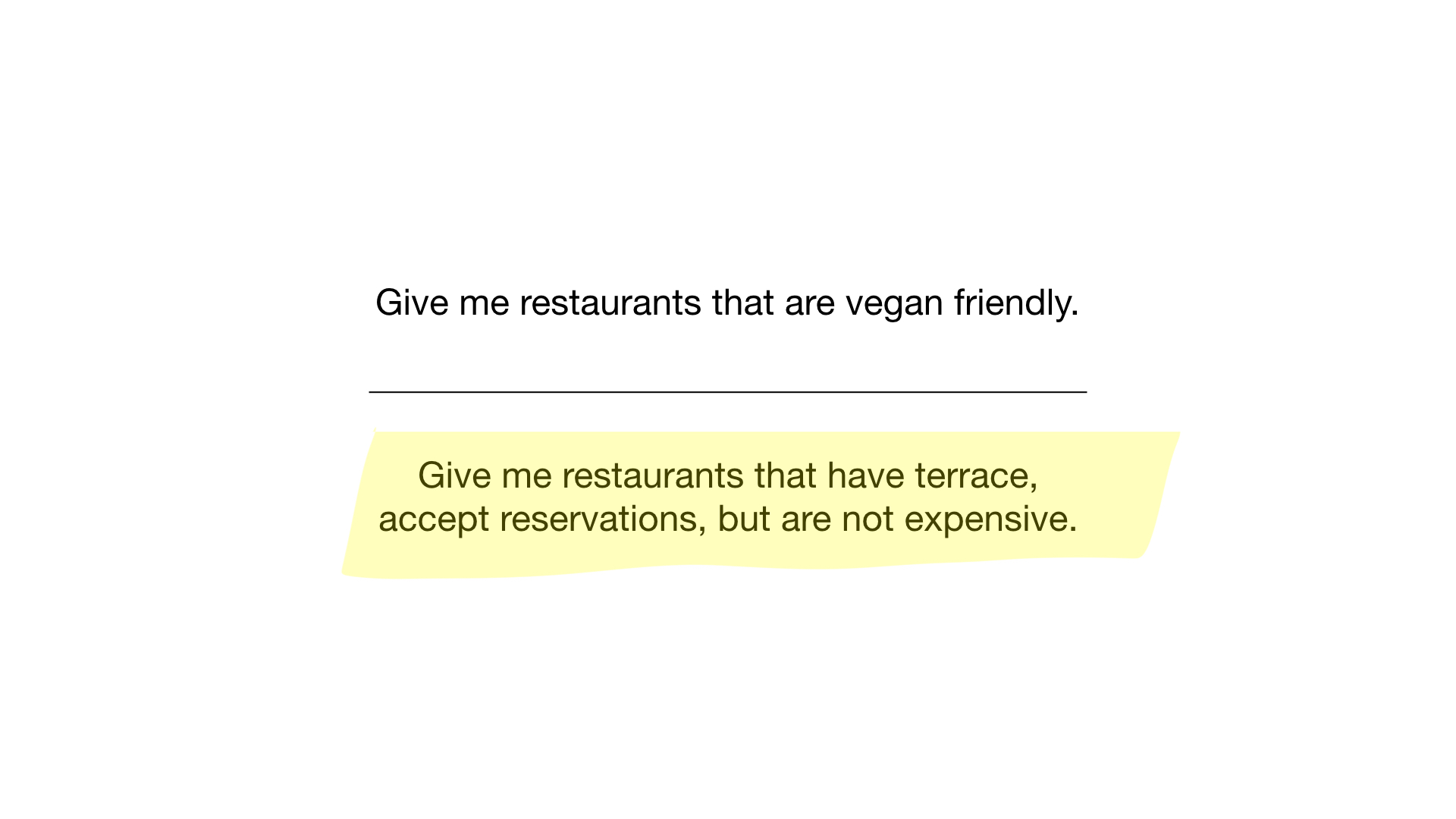

La deuxième requête est un peu plus compliquée. Nous devons utiliser l'opération NOT bit sur le bitmap «cher» pour obtenir une liste de restaurants bon marché, puis le définir avec le bitmap «vous pouvez réserver une table» et définir le résultat avec le bitmap «il y a une véranda». Le bitmap résultant contiendra une liste d'établissements qui répondent à tous nos critères. Dans cet exemple, ce n'est que le restaurant Yunost.
Il y a beaucoup de théorie, mais ne vous inquiétez pas, nous verrons le code très bientôt.
Où sont utilisés les index bitmap?

Si vous "google" indexez le bitmap, 90% des réponses seront en quelque sorte liées à Oracle DB. Mais le reste du SGBD supporte probablement aussi une chose aussi cool, non? Pas vraiment.
Passons en revue la liste des principaux suspects.

MySQL ne prend pas encore en charge les index bitmap, mais il existe une proposition avec une proposition pour ajouter cette option (
https://dev.mysql.com/worklog/task/?id=1524 ).
PostgreSQL ne prend pas en charge les index bitmap, mais utilise des bitmaps et des opérations bit simples pour combiner les résultats de la recherche sur plusieurs autres index.
Tarantool possède des index de bits, il prend en charge une recherche simple sur eux.
Redis a des champs de bits simples
(https://redis.io/commands/bitfield ) sans possibilité de les parcourir.
MongoDB ne prend pas encore en charge les index bitmap, mais il existe également une proposition avec une proposition pour ajouter cette option
https://jira.mongodb.org/browse/SERVER-1723Elasticsearch utilise des bitmaps à l'intérieur
(https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps ).

- Mais un nouveau voisin est apparu dans notre maison: Pilosa. Il s'agit d'une nouvelle base de données non relationnelle écrite en Go. Il ne contient que des index bitmap et base tout sur eux. Nous parlerons d'elle un peu plus tard.
Mise en œuvre Go
Mais pourquoi les index bitmap sont-ils si rarement utilisés? Avant de répondre à cette question, je voudrais vous montrer l'implémentation d'un index bitmap très simple sur Go.

Les bitmaps ne sont essentiellement que des éléments de données. Dans Go, utilisons des tranches d'octets pour cela.
Nous avons une image bitmap par caractéristique de restaurant, et chaque bit de l'image bitmap indique si un restaurant particulier a cette propriété ou non.

Nous aurons besoin de deux fonctions auxiliaires. L'un sera utilisé pour remplir nos bitmaps avec des données aléatoires. Aléatoire, mais avec une certaine probabilité que le restaurant possède chaque propriété. Par exemple, je pense qu'il y a très peu de restaurants à Moscou où vous ne pouvez pas réserver de table, et il me semble qu'environ 20% des établissements sont adaptés aux végétariens.
La deuxième fonction convertira le bitmap en une liste de restaurants.


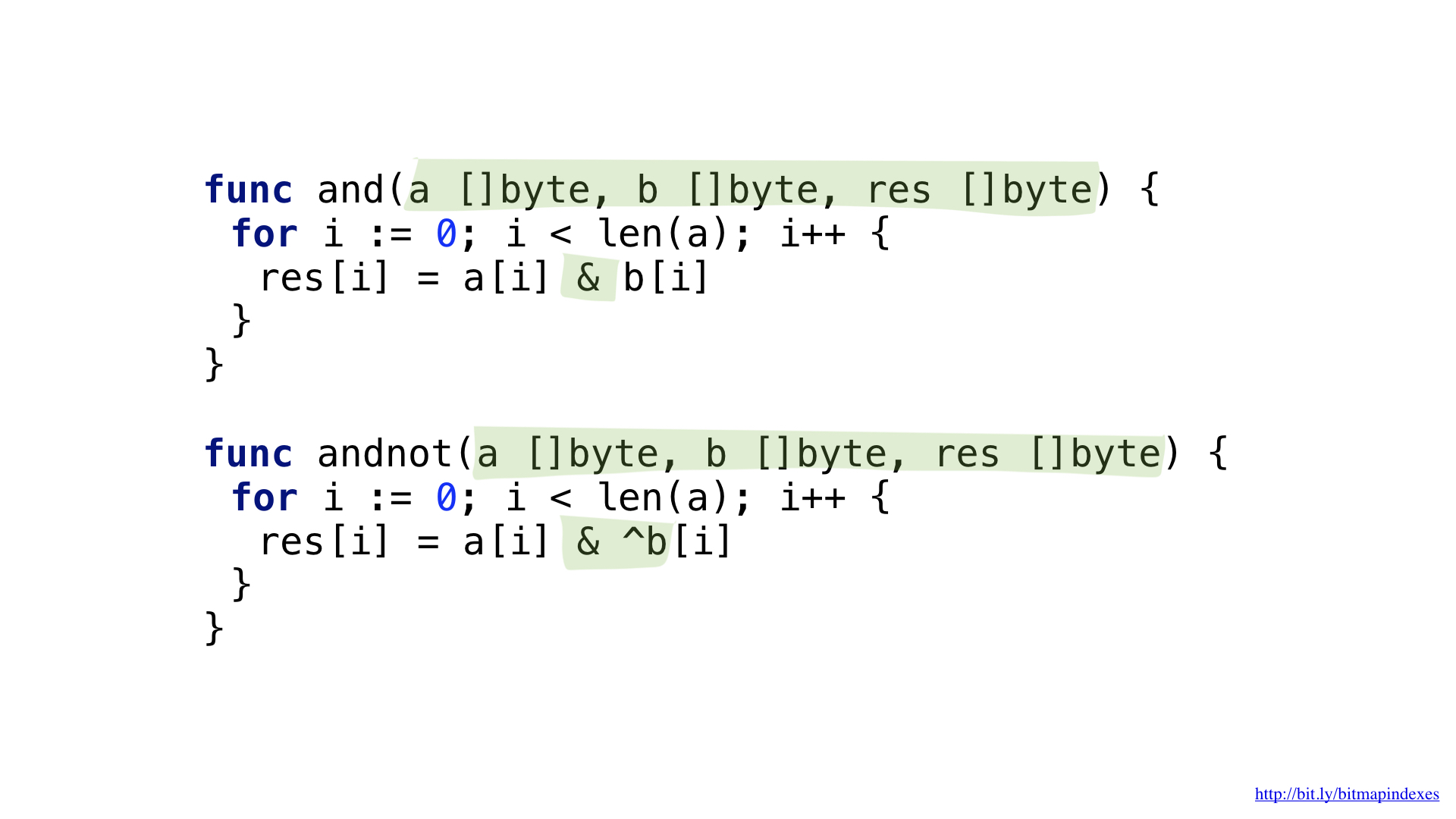
Pour répondre à la demande «Montrez-moi les restaurants bon marché qui ont une véranda et où vous pouvez réserver une table», nous avons besoin de deux opérations de bit: NON et ET.
Nous pouvons simplifier un peu notre code en utilisant l'opération plus complexe ET NON.
Nous avons des fonctions pour chacune de ces opérations. Les deux passent par les tranches, prennent les éléments correspondants de chacune, les combinent avec une opération de bits et mettent le résultat dans la tranche résultante.
Et maintenant, nous pouvons utiliser nos bitmaps et fonctions pour répondre à une requête de recherche.

Les performances ne sont pas si élevées, malgré le fait que les fonctions sont très simples et nous avons décemment économisé sur le fait que nous n'avons pas renvoyé une nouvelle tranche résultante à chaque appel de la fonction.
Ayant un peu profilé avec pprof, j'ai remarqué que le compilateur Go manquait une optimisation très simple, mais très importante: la fonction inline.
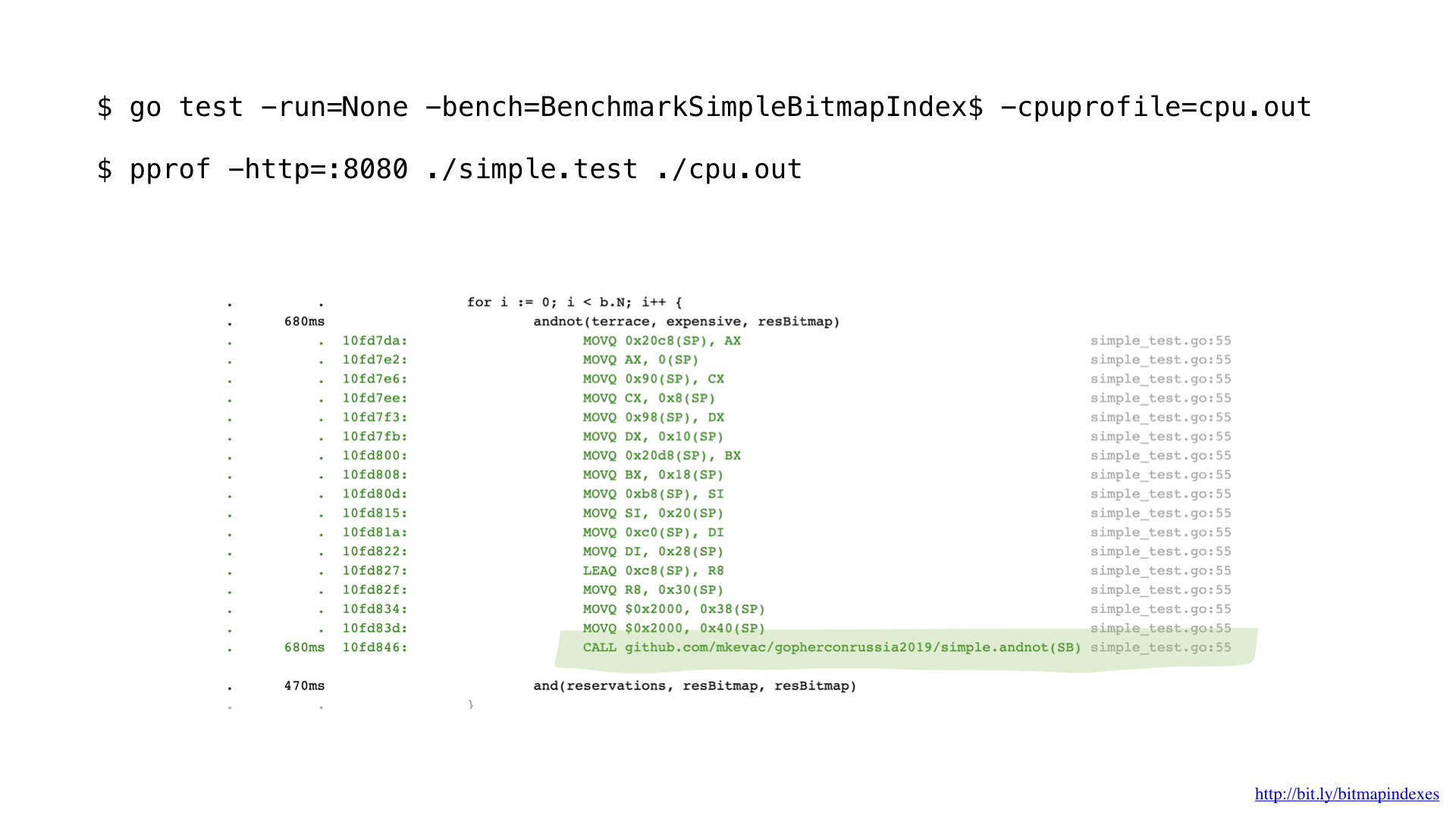
Le fait est que le compilateur Go a terriblement peur des boucles qui passent par des tranches et refuse catégoriquement les fonctions en ligne qui contiennent des boucles.
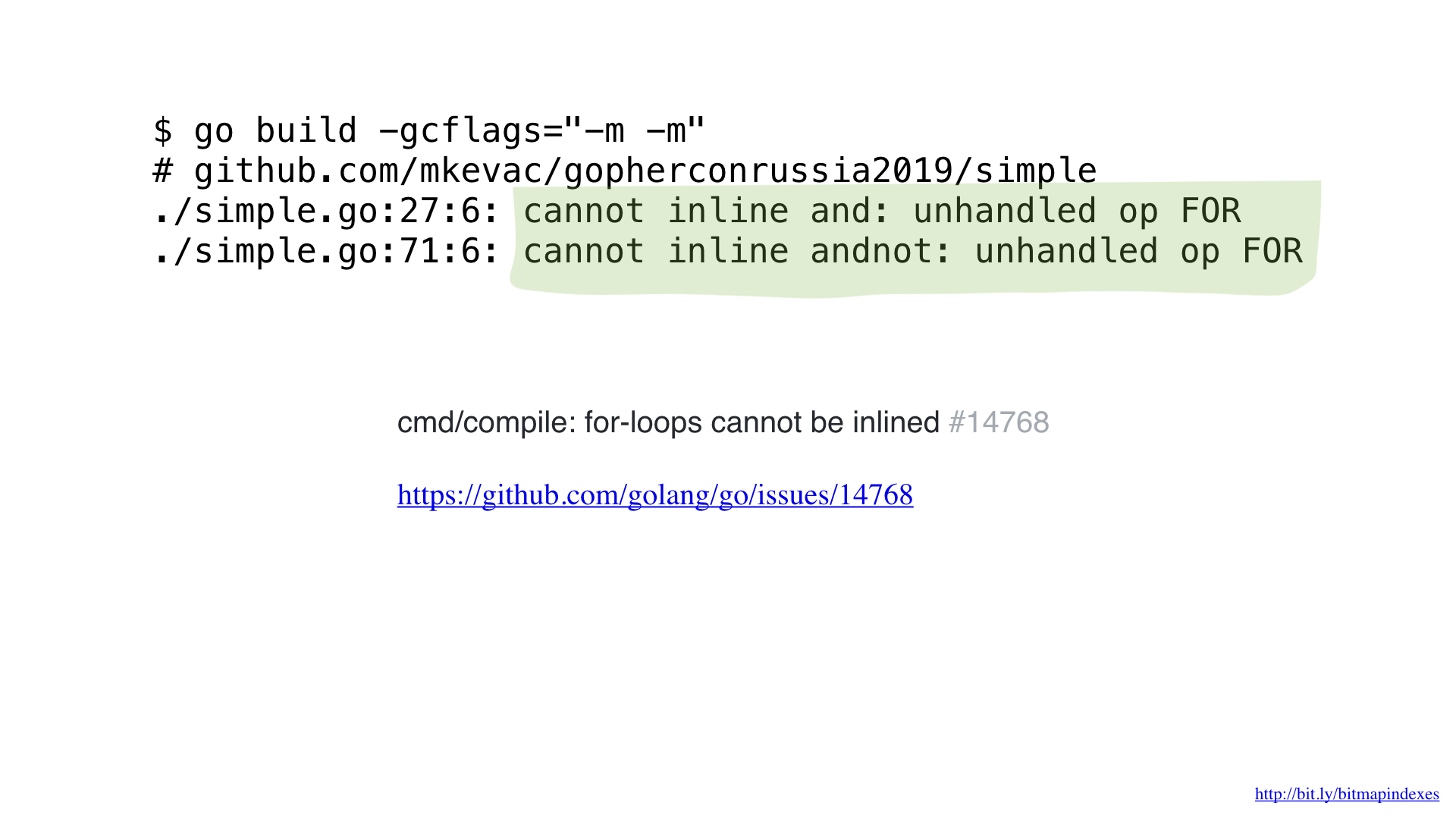
Mais je n'ai pas peur, et je peux tromper le compilateur en utilisant goto au lieu d'une boucle, comme au bon vieux temps.


Et, comme vous pouvez le voir, le compilateur intègre désormais notre fonction avec bonheur! En conséquence, nous parvenons à économiser environ 2 microsecondes. Pas mal!

Le deuxième goulot d'étranglement est facile à voir si vous regardez attentivement la sortie de l'assembleur. Le compilateur a ajouté une vérification liée aux tranches juste à l'intérieur de notre boucle la plus chaude. Le fait est que Go est un langage sûr, le compilateur a peur que mes trois arguments (trois tranches) aient des tailles différentes. Après tout, il y aura alors une possibilité théorique d'apparition du soi-disant débordement de tampon.
Rassurons le compilateur en lui montrant que toutes les tranches sont de la même taille. Nous pouvons le faire en ajoutant une simple vérification au début de notre fonction.
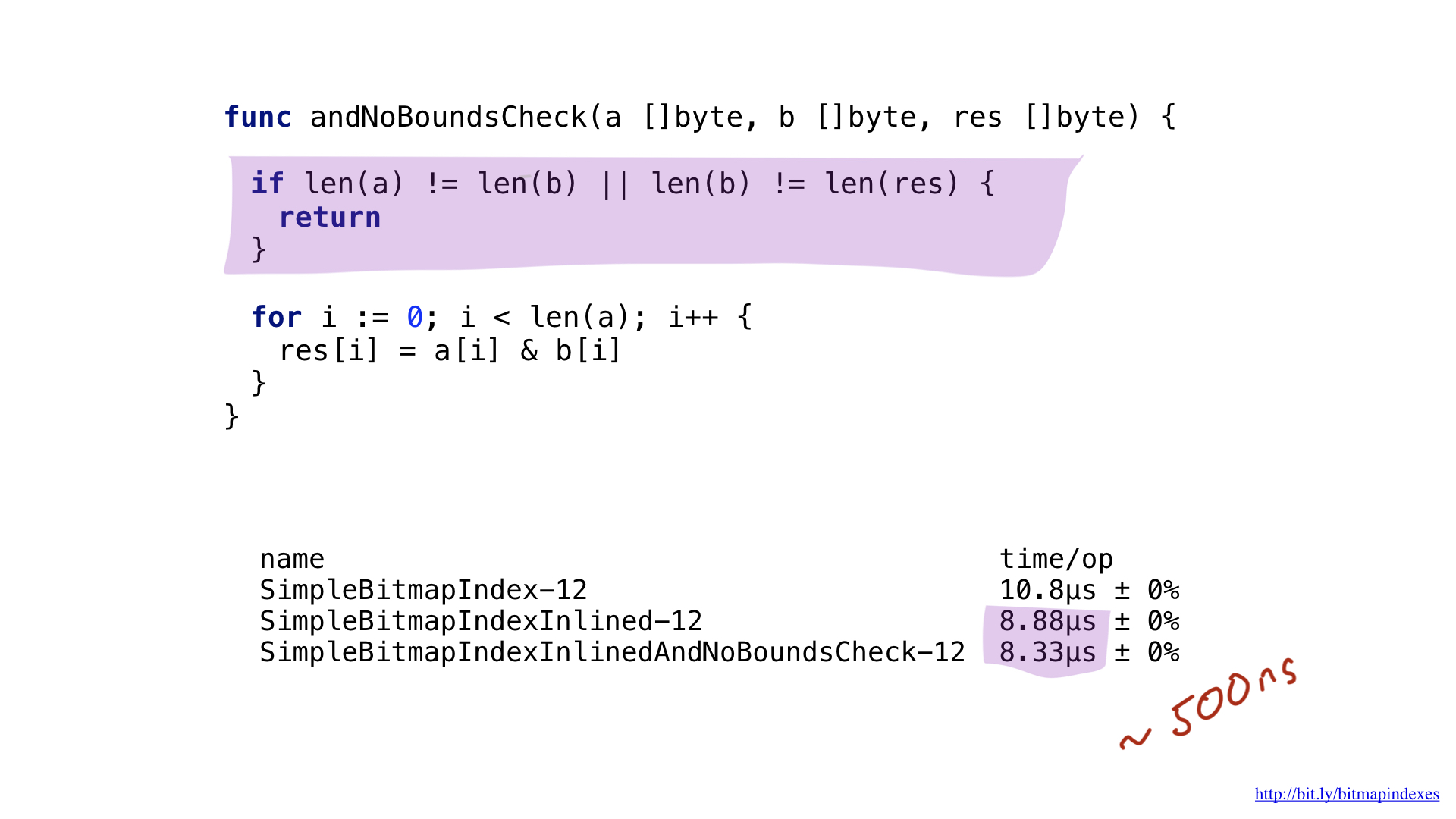
Voyant cela, le compilateur saute joyeusement le test, et nous finissons par économiser encore 500 nanosecondes.
Grands lots
D'accord, nous avons réussi à réduire certaines performances de notre implémentation simple, mais ce résultat, en fait, est bien pire que possible avec le matériel actuel.
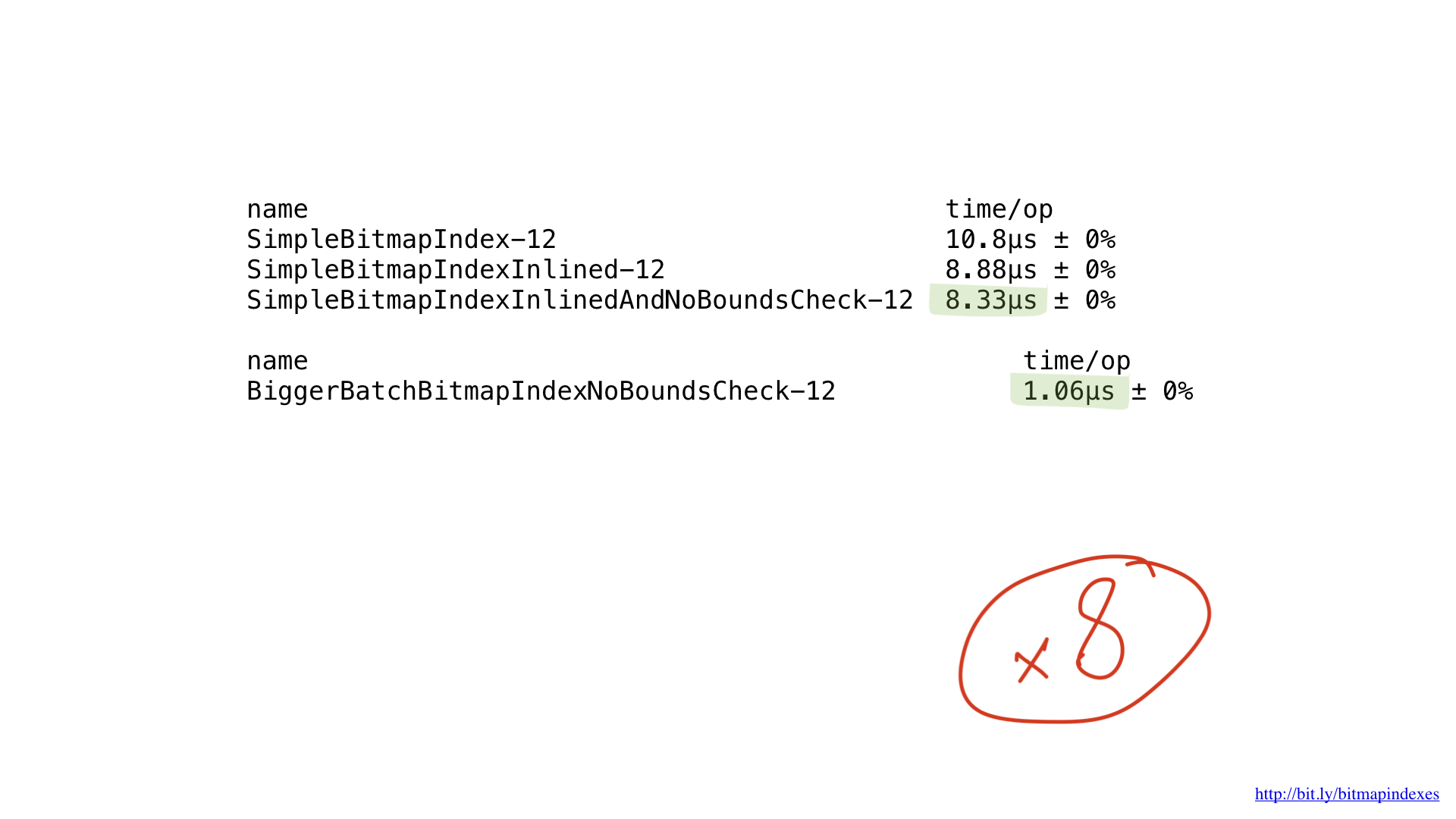
Tout ce que nous faisons, ce sont des opérations de base sur les bits, et nos processeurs les exécutent très efficacement. Mais, malheureusement, nous «alimentons» notre processeur avec de très petits travaux. Nos fonctions effectuent des opérations octet par octet. Nous pouvons très facilement régler notre code pour qu'il fonctionne avec des morceaux de 8 octets à l'aide de tranches UInt64.

Comme vous pouvez le voir, ce petit changement a accéléré notre programme de huit fois en raison d'une augmentation du lot de huit fois. Le gain peut être considéré comme linéaire.
Implémentation de l'assembleur

Mais ce n'est pas la fin. Nos processeurs peuvent fonctionner avec des morceaux de 16, 32 et même 64 octets. De telles opérations "larges" sont appelées données multiples à instruction unique (SIMD; une instruction, beaucoup de données), et le processus de transformation du code pour qu'il utilise de telles opérations est appelé vectorisation.
Malheureusement, le compilateur Go est loin d'être un excellent étudiant en vectorisation. Actuellement, la seule façon de vectoriser du code sur Go est de prendre et de placer ces opérations manuellement à l'aide de l'assembleur Go.

Assembler Go est une étrange bête. Vous savez probablement que l'assembleur est quelque chose qui est fortement lié à l'architecture de l'ordinateur pour lequel vous écrivez, mais ce n'est pas le cas avec Go. L'assembleur Go ressemble plus à un IRL (langage de représentation intermédiaire) ou à un langage intermédiaire: il est pratiquement indépendant de la plateforme. Rob Pike a fait une excellente
présentation à ce sujet il y a quelques années au GopherCon de Denver.
De plus, Go utilise le format inhabituel Plan 9, qui diffère des formats AT&T et Intel généralement reconnus.

Il est sûr de dire que l'écriture manuelle de l'assembleur Go n'est pas l'activité la plus amusante.
Mais, heureusement, il existe déjà deux outils de haut niveau qui nous aident à écrire l'assembleur Go: PeachPy et avo. Les deux utilitaires génèrent des assembleurs Go à partir de code de niveau supérieur écrit en Python et Go, respectivement.

Ces utilitaires simplifient des choses comme l'allocation de registres, les cycles d'écriture et simplifient généralement le processus d'entrée dans le monde de la programmation des assembleurs dans Go.
Nous utiliserons avo, donc nos programmes seront des programmes Go presque normaux.

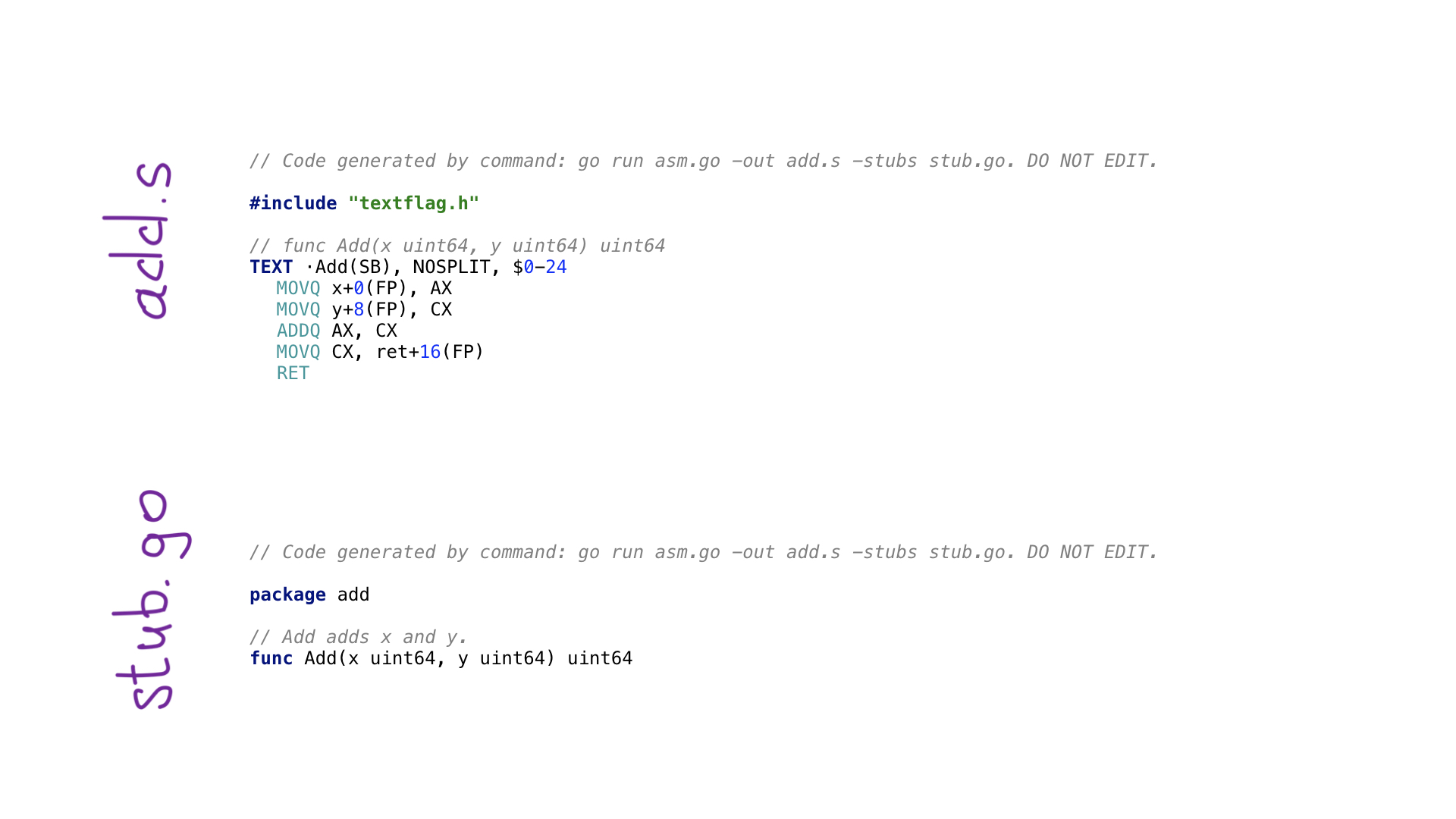
Voici à quoi ressemble l'exemple le plus simple d'un programme avo. Nous avons une fonction main () qui définit la fonction Add () à l'intérieur d'elle-même, ce qui signifie ajouter deux nombres. Il existe des fonctions auxiliaires pour obtenir les paramètres par nom et obtenir l'un des registres de processeur gratuits et appropriés. Chaque opération de processeur a une fonction correspondante sur avo, comme vu dans ADDQ. Enfin, nous voyons une fonction d'aide pour stocker la valeur résultante.

En appelant go generate, nous exécuterons le programme sur avo et à la fin deux fichiers seront générés:
- add.s avec le code assembleur Go résultant;
- stub.go avec des en-têtes de fonction pour connecter deux mondes: Go et assembleur.
Maintenant que nous avons vu ce que fait et comment avo, jetons un œil à nos fonctions. J'ai implémenté des versions scalaires et vectorielles (SIMD) de fonctions.
Tout d'abord, regardez les versions scalaires.

Comme dans l'exemple précédent, nous vous demandons de nous fournir un registre général gratuit et correct, nous n'avons pas besoin de calculer les décalages et les tailles des arguments. Tout cela fait pour nous.

Auparavant, nous utilisions des étiquettes et des goto (ou des sauts) pour améliorer les performances et tromper le compilateur Go, mais maintenant nous le faisons depuis le tout début. Le fait est que les boucles sont un concept de niveau supérieur. Dans l'assembleur, nous n'avons que des étiquettes et des sauts.

Le code restant doit déjà être familier et compréhensible. Nous émulons la boucle avec des étiquettes et des sauts, prenons une petite partie des données de nos deux tranches, les combinons avec une opération de bits (ET PAS dans ce cas), puis mettons le résultat dans la tranche résultante. C’est tout.

Voici à quoi ressemble le code assembleur final. Nous n'avons pas eu besoin de calculer les décalages et les tailles (surlignés en vert) ou de garder une trace des registres utilisés (surlignés en rouge).
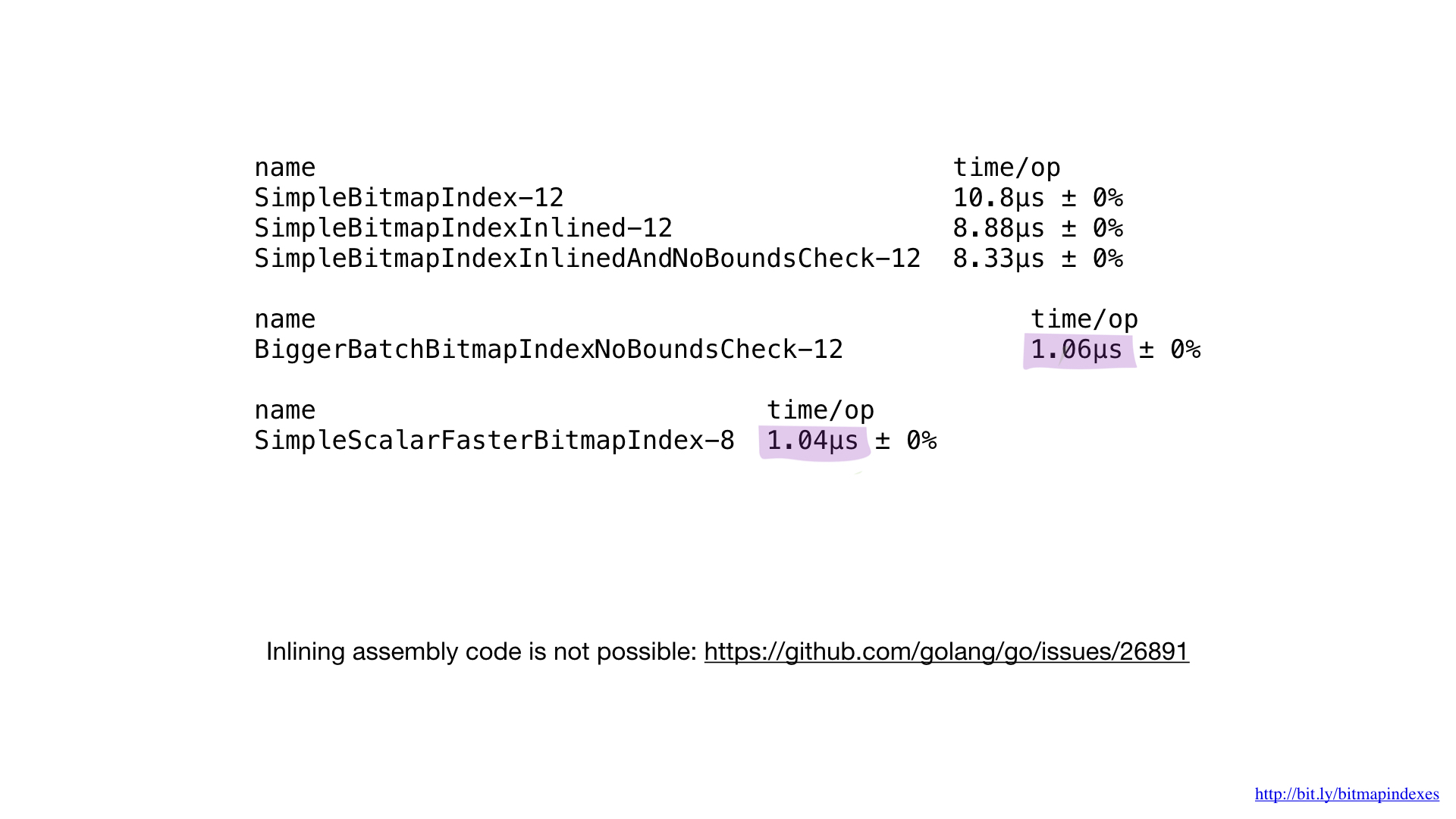
Si nous comparons les performances de l'implémentation dans l'assembleur avec les performances de la meilleure implémentation dans Go, nous verrons que c'est la même chose. Et c'est attendu. Après tout, nous n'avons rien fait de spécial - nous venons de reproduire ce que le compilateur Go ferait.
Malheureusement, nous ne pouvons pas forcer le compilateur à aligner nos fonctions écrites en assembleur. Le compilateur Go n'a pas cette fonctionnalité aujourd'hui, bien que la demande d'ajout existe depuis un certain temps.
C'est pourquoi il est impossible d'obtenir des avantages de petites fonctions dans l'assembleur. Nous devons soit écrire de grandes fonctions, soit utiliser le nouveau package math / bits, soit contourner le côté assembleur.
Voyons maintenant les versions vectorielles de nos fonctions.

Pour cet exemple, j'ai décidé d'utiliser AVX2, nous allons donc utiliser des opérations qui fonctionnent avec des blocs de 32 octets. La structure du code est très similaire à l'option scalaire: chargement des paramètres, merci de nous fournir un registre général gratuit, etc.
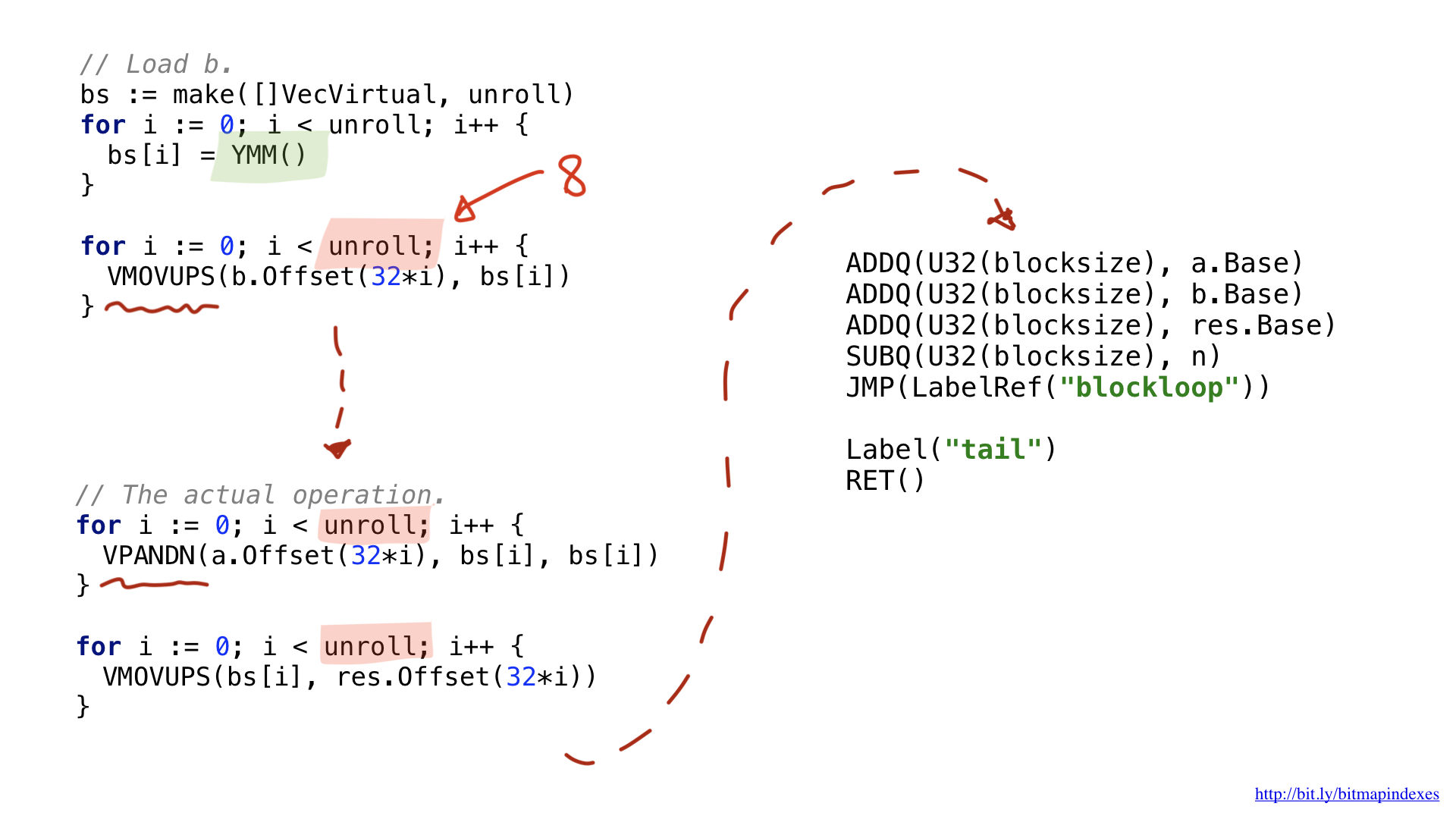
L'une des innovations est que les opérations vectorielles plus larges utilisent des registres larges spéciaux. Dans le cas de blocs de 32 octets, ce sont des registres avec le préfixe Y. C'est pourquoi vous voyez la fonction YMM () dans le code. Si je devais utiliser l'AVX-512 avec des morceaux 64 bits, le préfixe serait Z.
La deuxième innovation est que j'ai décidé d'utiliser une optimisation appelée déroulage de boucle, c'est-à-dire effectuer huit opérations de boucle manuellement avant de sauter au début de la boucle. Cette optimisation réduit le nombre de brunchs (branches) dans le code, et elle est limitée par le nombre de registres gratuits disponibles.
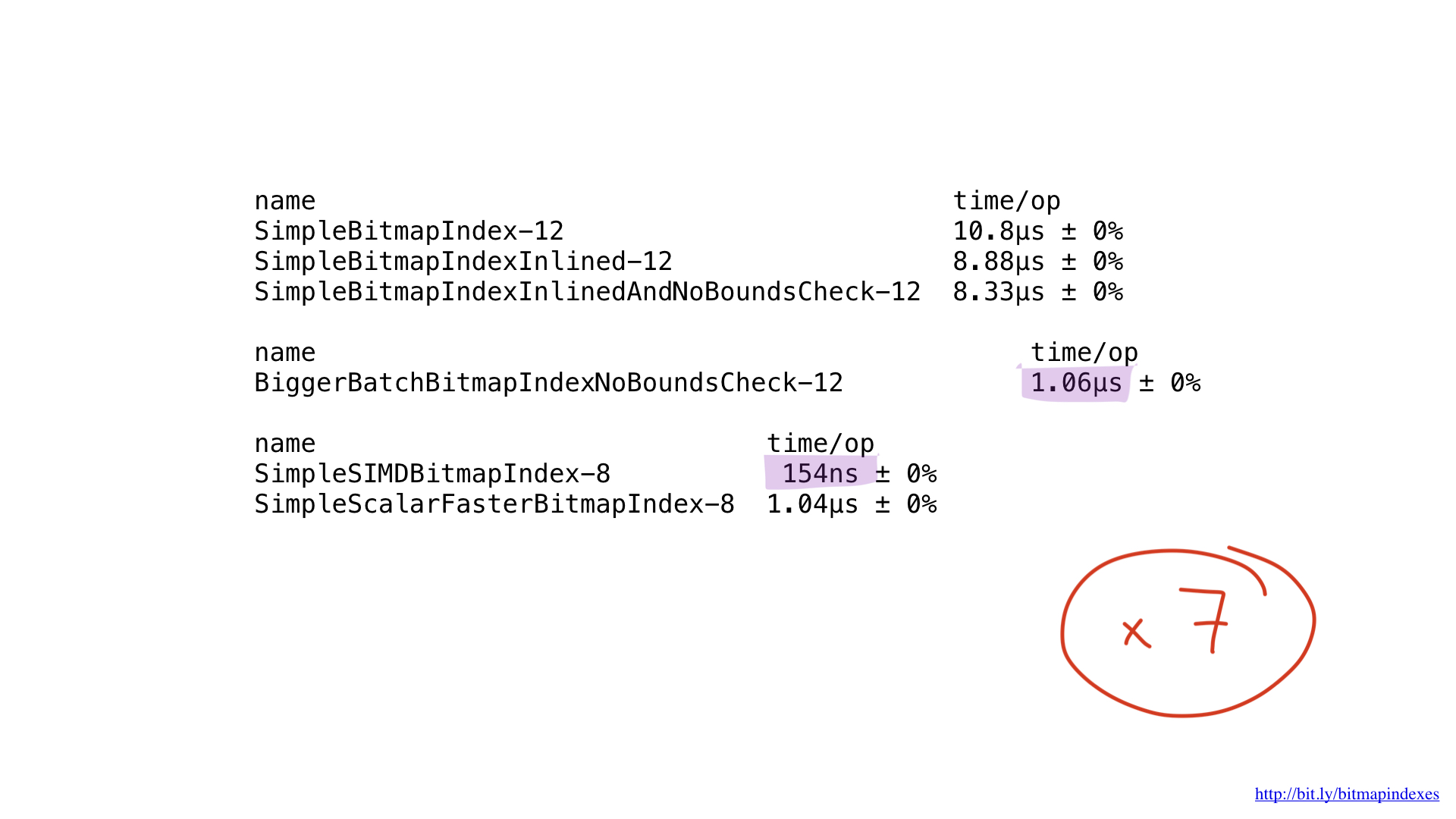
Et la performance? Elle est belle! Nous avons obtenu une accélération environ sept fois par rapport à la meilleure solution sur Go. Impressionnant, hein?
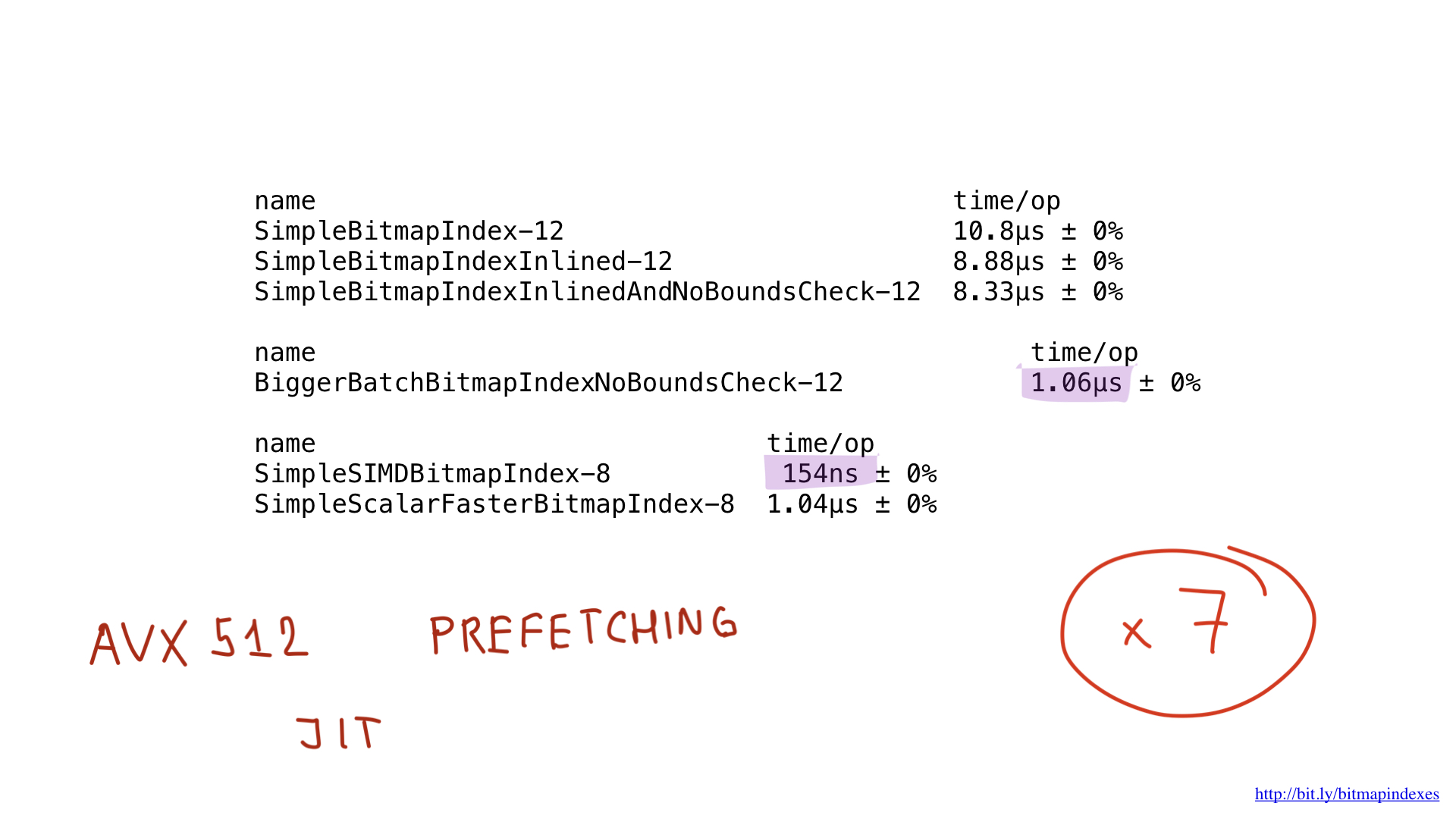
Mais même cette implémentation pourrait potentiellement être accélérée en utilisant AVX-512, la prélecture ou JIT (compilateur juste à temps) pour le planificateur de requêtes. Mais c'est certainement un sujet pour un rapport séparé.
Problèmes d'index bitmap
Maintenant que nous avons déjà examiné une implémentation simple de l'index bitmap Go et un langage d'assemblage beaucoup plus efficace, parlons enfin des raisons pour lesquelles les index bitmap sont si rarement utilisés.
 Dans les anciens articles scientifiques, trois problèmes d'index bitmap sont mentionnés, mais les articles scientifiques plus récents et moi soutenons qu'ils ne sont plus pertinents. Nous n'allons pas approfondir chacun de ces problèmes, mais nous les examinerons superficiellement.
Dans les anciens articles scientifiques, trois problèmes d'index bitmap sont mentionnés, mais les articles scientifiques plus récents et moi soutenons qu'ils ne sont plus pertinents. Nous n'allons pas approfondir chacun de ces problèmes, mais nous les examinerons superficiellement.Le problème de la grande cardinalité
, , bitmap- , , (, ), , ( ) , , bitmap- () .
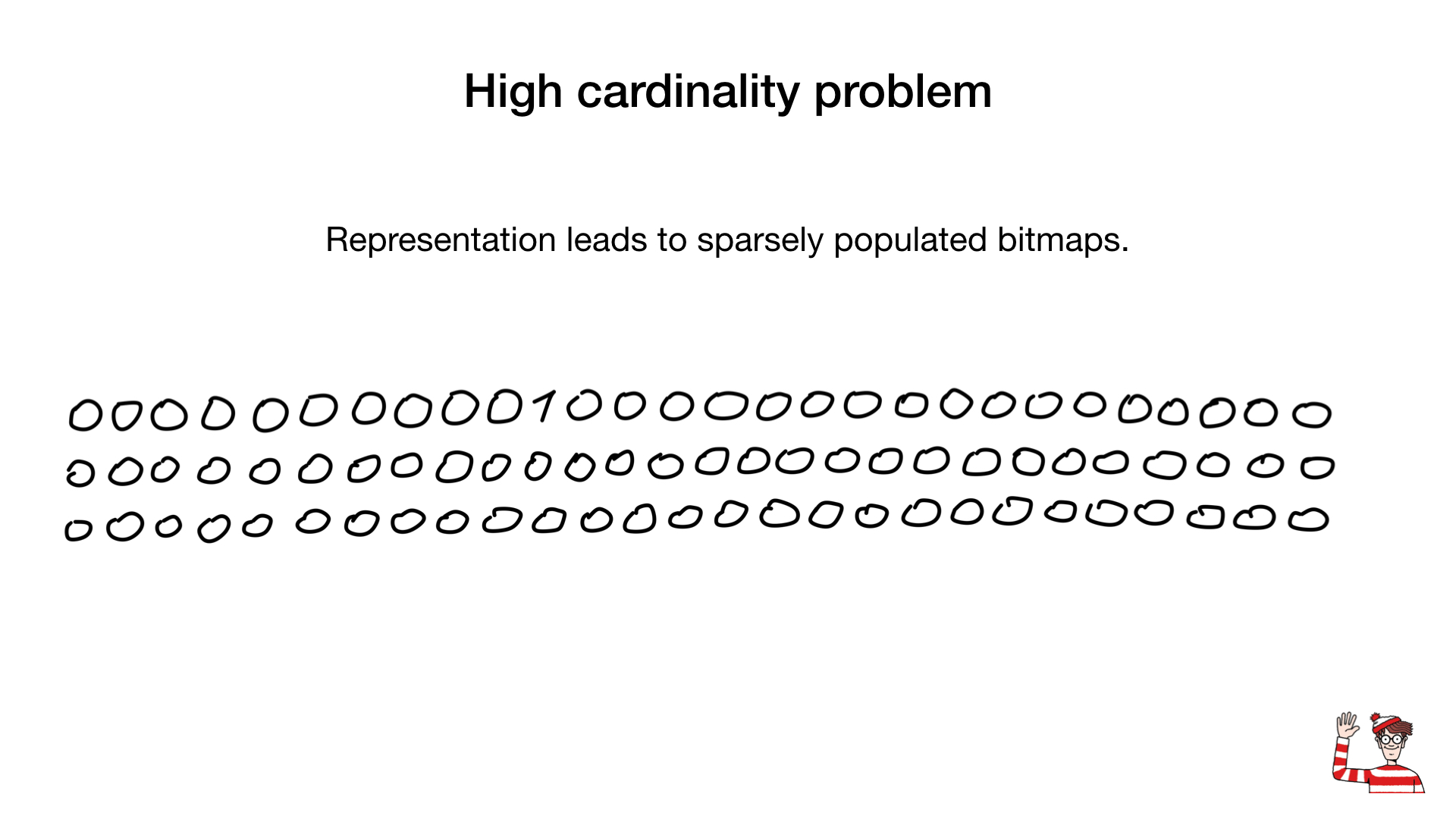
, , . . . , — .

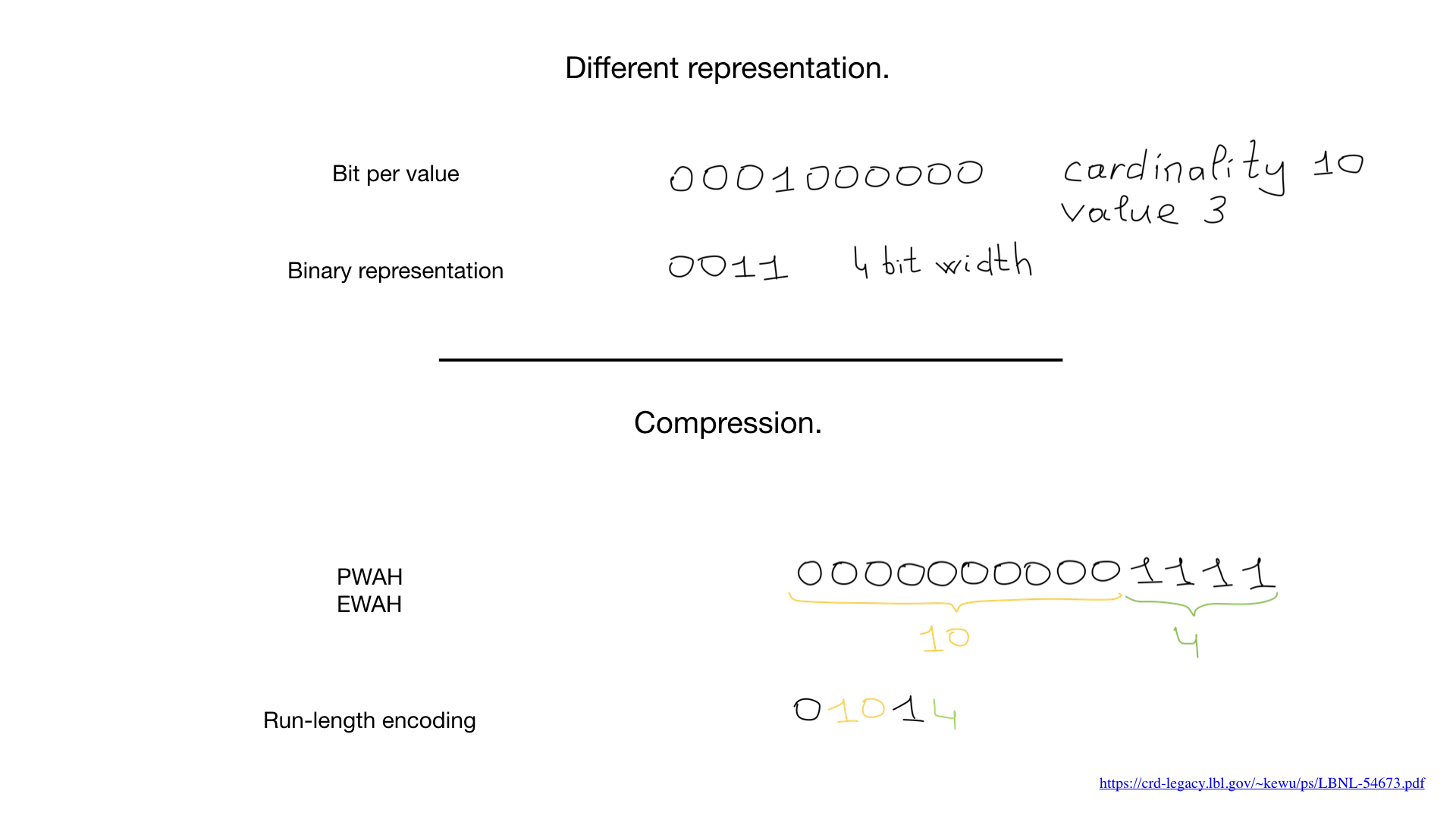
, , , roaring . — , bit runs — , .
roaring . , Go.
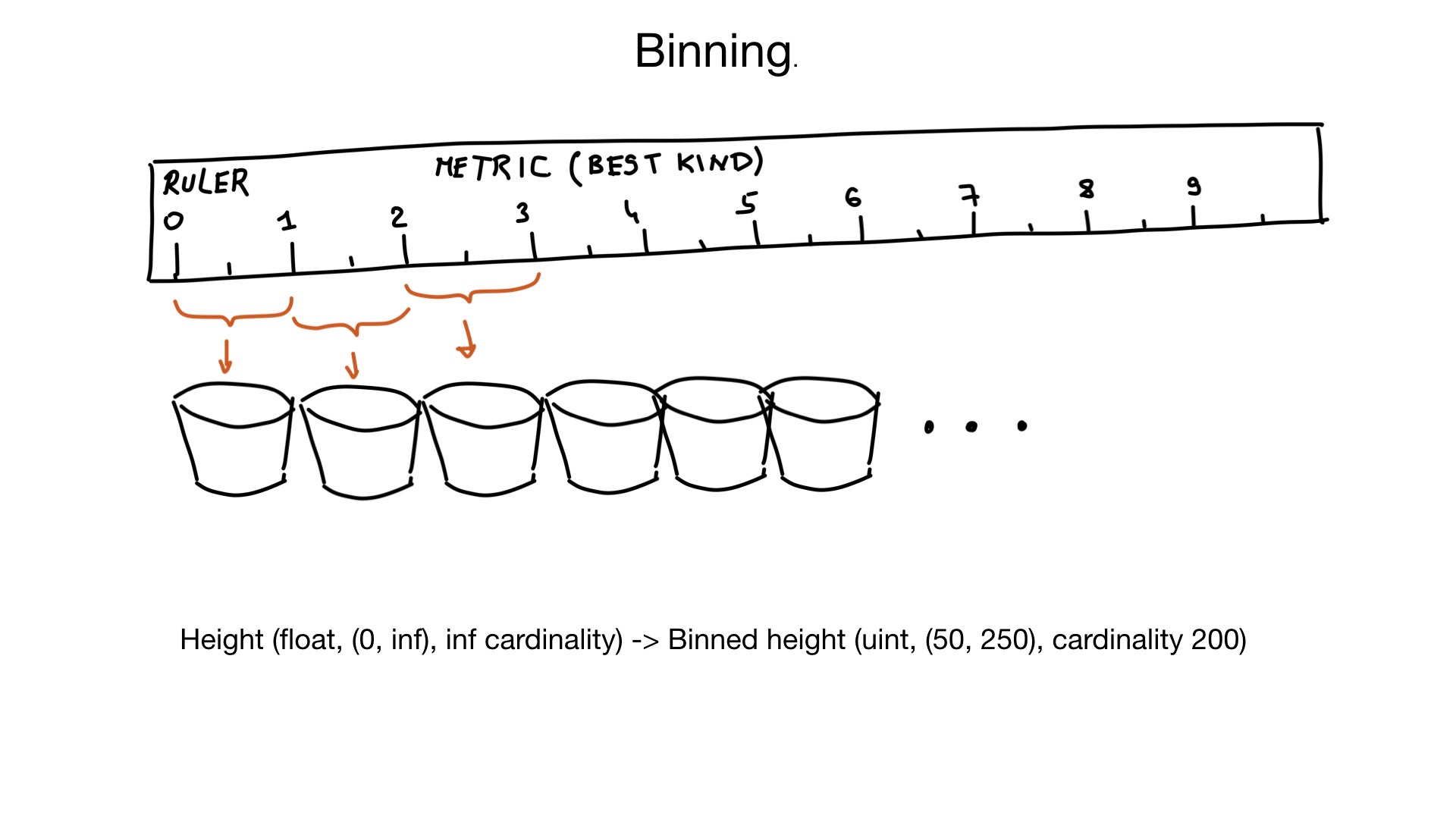
, , (binning). , , . — , , , . 185,2 185,3 .
, 1 .
, 50 250 , , , 200 .
, .
bitmap- , .
, . , . , , — lock contention, .
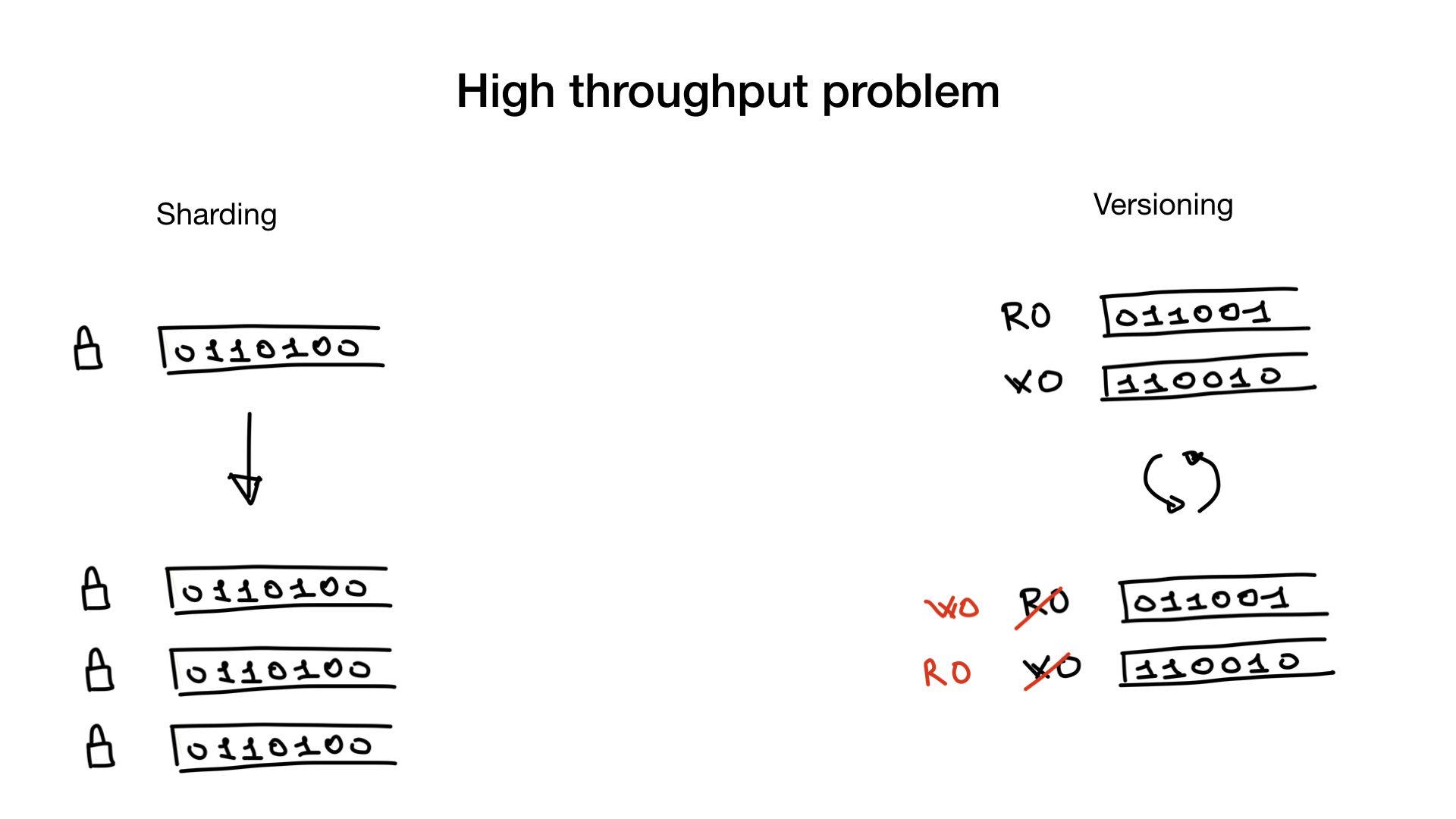
.
— . bitmap- , . lock contention.
— . , , — . - (, 100 500 ) . , , .
: .
bitmap- , , , , « ».
, , AND, OR . . - « 200 300 ».

OR.

. , 50 . 50 .
, . range-encoded bitmaps.

- (, 200), , . 200 . 300: 300 . Et ainsi de suite.
, , . , 300 , , 199 . C'est fait.

, bitmap-. , , . , S2 Google. , . « » ( ).
Solutions prêtes à l'emploi
. - - , , .
, , bitmap- . , SIMD, .
, , .

Roaring
-, roaring bitmaps-, . , , bitmap-.
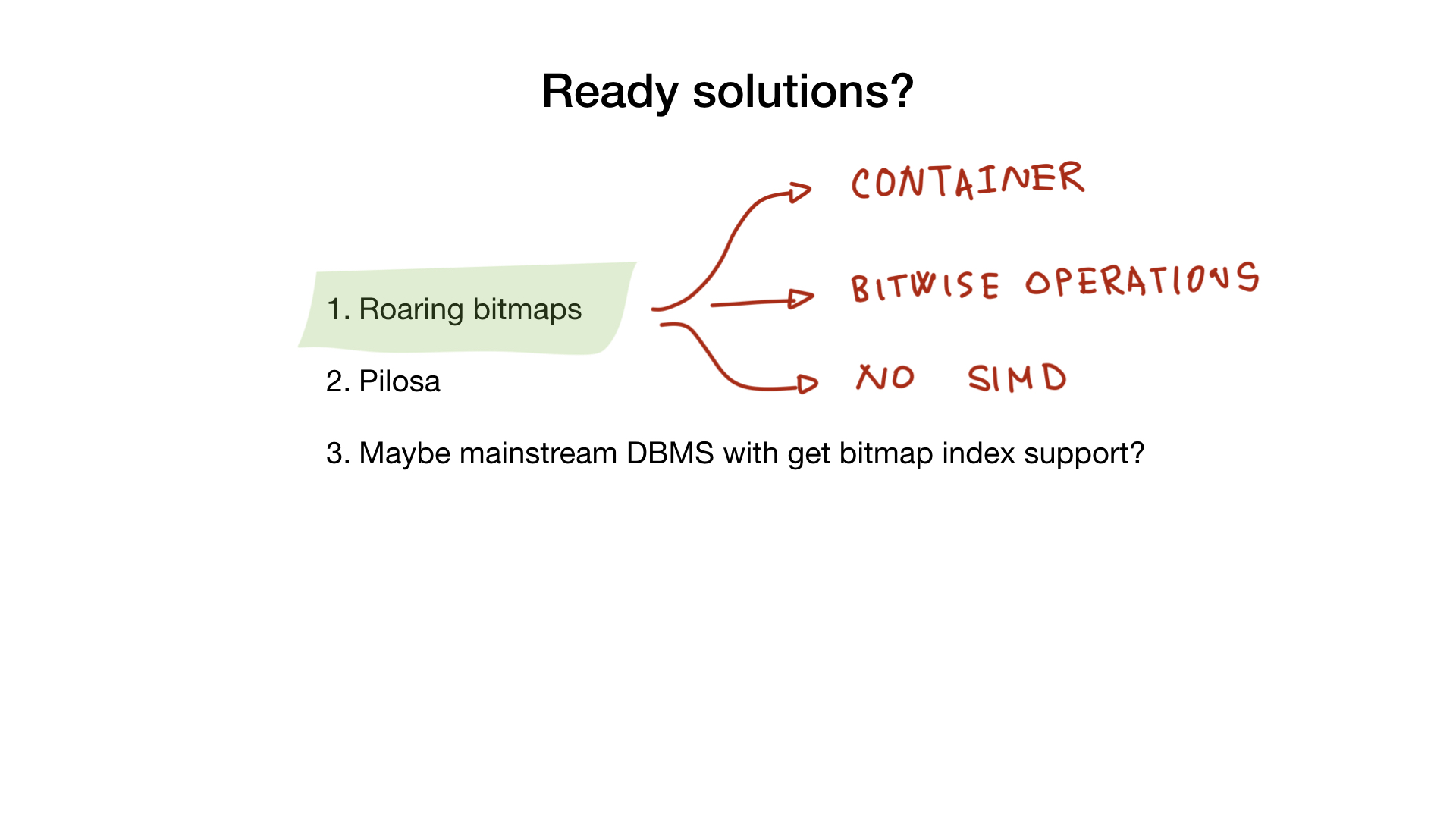
, Go- SIMD, , Go- , C, .
Pilosa
, , — Pilosa, , , bitmap- . , .
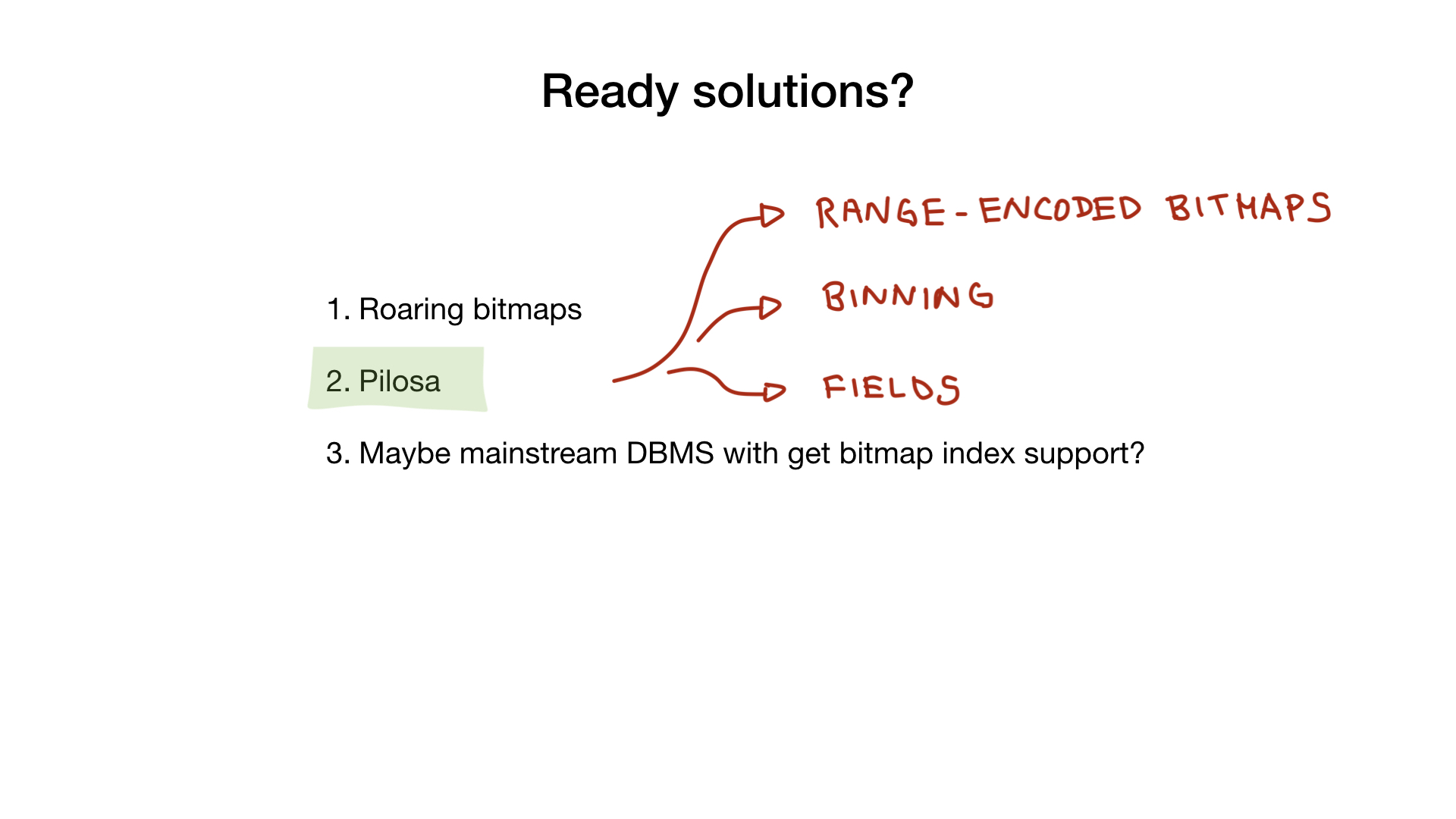
Pilosa roaring , , : , range-encoded bitmaps, . .
Pilosa .

, . Pilosa, , , , .
Après cela, nous utilisons NOT sur le champ «cher», puis coupons le résultat (ou AND) avec le champ terrasse et le champ réservations. Et enfin, nous obtenons le résultat final. J'espère vraiment que dans un avenir prévisible dans les SGBD comme MySQL et PostgreSQL, ce nouveau type d'index apparaîtra également - les index bitmap.
J'espère vraiment que dans un avenir prévisible dans les SGBD comme MySQL et PostgreSQL, ce nouveau type d'index apparaîtra également - les index bitmap.
Conclusion

Si vous ne vous êtes pas encore endormi, merci. J'ai dû aborder de nombreux sujets en passant en raison du temps limité, mais j'espère que le rapport a été utile et peut-être même motivant.
Il est bon de connaître les index bitmap, même si vous n'en avez pas besoin pour le moment. Laissez-les être un autre outil dans votre tiroir.
Nous avons couvert diverses astuces de performance pour Go et les choses avec lesquelles le compilateur Go ne fonctionne pas très bien. Mais il est absolument utile que tout programmeur Go le sache.
C'est tout ce que je voulais dire. Je vous remercie!