Une leçon d'introduction gratuite est la fonction Skyeng School. Un étudiant potentiel peut se familiariser avec la plate-forme, vérifier son niveau d'anglais et enfin s'amuser. Pour l'école, le cours d'introduction fait partie de l'entonnoir de vente, suivi du premier versement. Elle est dirigée par un méthodologiste de leçon d'introduction - une personne spéciale qui combine un enseignant et un vendeur, son temps est payé, que le client ait acheté le premier forfait ou non, et qu'il soit apparu du tout pour la leçon. L'absentéisme est un phénomène très courant en raison duquel le prix d'une leçon devient trop élevé.
Dans cet article, nous décrirons comment, à l'aide du modèle analytique et de l'expérience des compagnies aériennes, nous avons réussi à réduire de près de moitié les coûts de la leçon d'introduction.
L'entonnoir de vente Skyeng se compose de cinq étapes: s'inscrire sur le site, appeler la première ligne de vente avec une entrée à la leçon d'introduction, leçon d'introduction, sonner la deuxième ligne de vente, payer le premier forfait. Plus tôt, après le premier appel, nous avons fixé une heure de cours pour un méthodologiste de cours d'introduction particulier, qui attendait l'étudiant à ce moment-là. Si une personne s'est inscrite et n'est pas venue, le méthodologiste perd son temps, et l'école gaspille de l'argent pour payer ce temps. L'absentéisme survient en moyenne dans la moitié des cas; un tiers des clients achètent le premier package après une leçon d'introduction. Ainsi, la conversion de l'enregistrement à une leçon d'introduction en paiement n'est que de 0,15. Une leçon d'introduction réussie (convertie en paiement) dans l'ancien système nous a coûté 4 000 roubles, et nous avons dû faire quelque chose.
Vous pouvez simplement le refuser, mais dans ce cas, la conversion finale du plomb au paiement chutera considérablement, ce qui ne nous convient pas. Nous devrons chercher une autre solution, construire des modèles, compter et expérimenter.
Première crêpe
Nous nous sommes tournés vers l'expérience des compagnies aériennes, en particulier vers la pratique de la surréservation. Les transporteurs savent que 100% des passagers qui ont acheté un billet sont rarement sur un vol, et en profitent en vendant plus de billets que de sièges dans l'avion. Si tout à coup tous les passagers arrivent pour l'atterrissage, vous pouvez trouver parmi eux des volontaires qui sont prêts à décoller pour le prochain chignon sur le prochain vol. Les compagnies aériennes augmentent ainsi leurs bénéfices, et nous pouvons réduire les coûts par une méthode similaire.
Donc: nous refusons l'enregistrement à une personne spécifique, nous créons un pool de méthodologistes de la leçon d'introduction, nous dispersons les applications entre eux dans l'espoir que la moitié n'apparaîtra pas. Et si plus est venu, nous vous suggérons de vous inscrire pour un autre jour. Nous avons lancé un tel MVP dans le test et avons immédiatement réalisé que nous avions tout mal fait.
La moitié de ceux qui entrent dans la leçon d'introduction sont des statistiques, en réalité, la proportion varie considérablement en fonction de l'heure, du jour, du canal d'où la personne est venue. De plus, plus de 80% des étudiants potentiels, en réponse à une proposition de report de la leçon, tombent immédiatement ou ne viennent pas au deuxième enregistrement. Tout cela pourrait conduire au fait que les mauvais jours, nous perdrions jusqu'à un tiers des clients. Le test a été désactivé et est allé tout faire de manière intelligente.
Modèle, prévisions, polynômes
Tout d'abord, il a fallu savoir de quoi dépend la proportion de ceux qui vont à la leçon d'introduction. La première observation est que cela dépend du canal de commercialisation d'où provient la personne. Nous divisons ces canaux du point de vue de la conversion en paiement en «chaud», où la conversion est plus élevée, «chaude» et «froide», où elle est plus faible; il s'est avéré que la "température de canal" affecte la conversion en sortie de la leçon d'introduction de la même manière.
Poursuivant l'analogie avec l'aviation, nous avons créé différents «comptoirs d'enregistrement» pour les pistes de différents canaux, en les plaçant avec des coefficients correspondant à la probabilité historique de sortie de ce canal: 0,8, 0,4 et 0,2. Pour les chaînes «chaudes», nous affectons plus de méthodologistes, «froid» - moins. Cela a mieux fonctionné, mais les mauvais jours, il y avait plus de 20% de «départs» (situations où plus de clients assistaient à la leçon d'introduction qu'il n'y avait de méthodologistes gratuits). Ils ont essayé d'augmenter les coefficients en ajoutant une marge de 0,1: d'une part, plus nous éloignons les méthodologistes, moins nous perdons de clients, d'autre part - les coûts de la conduite des cours d'introduction augmentent.
À partir de ces observations, le deuxième MVP a grandi. Pour chaque inscrit, nous faisons une prévision de la probabilité qu'il passe à une leçon d'introduction. Nous faisons une distribution de probabilité et un intervalle de confiance conjoints avec un niveau de confiance de 95%. Pour les rares cas où plus de clients sortent que prévu, nous détenons une réserve de méthodologistes - des enseignants qui sont actuellement engagés dans des travaux non urgents tels que la vérification des essais.
Pour calculer les prévisions pour un élève particulier, nous avons construit un modèle statistique basé sur nos données historiques et prenant en compte plusieurs facteurs: canal, région, enfant / adulte, client privé / entreprise, temps écoulé entre l'enregistrement et la leçon d'introduction.
Le modèle fonctionne avec les concepts suivants:
- créneau : date et heure de la leçon d'introduction;
- facteur de correction : la probabilité d'une sortie anormale ce jour et cette heure;
- poids de la demande : probabilité admissible de sortie d'un client donné;
- Départ : application non desservie (client quitté, tous les méthodologistes sont occupés);
- méthodologiste simple : il s'est avéré moins que prévu, les gens sont assis au ralenti;
- restriction :% sur l'intervalle de confiance, après quoi le modèle interdit d'ajouter des ordres à l'emplacement.
Chaque emplacement contient N méthodologues, et l'emplacement lui-même a un facteur de correction k (avec une base de 100). Le nombre de méthodologistes disponibles pour le modèle est défini comme rond (N * k / 100). Lorsqu'une application apparaît, le modèle détermine son poids , examine la somme de ces poids déjà dans la fente et détermine la fente comme disponible si, à la suite de l'ajout de cette application, la somme des poids de l'application dans la fente ne dépasse pas le nombre de méthodologistes. Les paramètres d'évaluation du modèle sont: la proportion de départs (nécessaire pour minimiser), le chargement des créneaux (maximisé), le temps d'attente pour la leçon d'introduction par le client (minimisé). Les paramètres variables du modèle incluent le poids et la restriction de l' application .
Pour prédire combien de clients seront libérés, la formule du produit des probabilités a été utilisée:

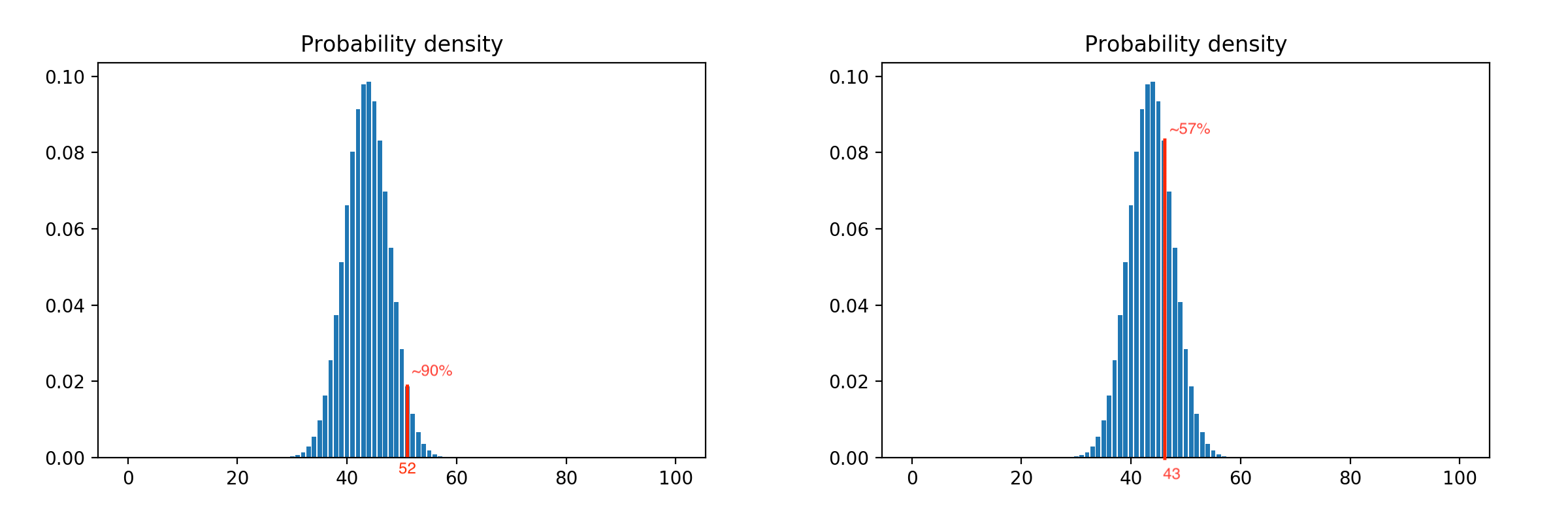
Compte tenu de toutes les combinaisons possibles de sorties, nous obtenons une distribution de probabilité naturelle très proche. La distribution pour cent clients ressemble à ceci:

En lui appliquant l'intervalle de confiance, nous pouvons ajuster l'agressivité du modèle. Par exemple, déplacer la restriction vers la gauche l'augmente, c'est-à-dire nous libérons plus de clients avec le même nombre de méthodologistes, et un décalage vers la droite le réduit, car la restriction est déclenchée plus tôt. Exemple avec restrictions de 90% et 57%:
De plus, l'agressivité du modèle peut être ajustée par un facteur de correction: une diminution le réduit, une augmentation l'augmente. Ceci est utile lorsque nous savons qu'un jour / une heure particuliers, certains facteurs externes peuvent provoquer l'anomalie.
La formule avec multiplication des probabilités s'est bien révélée dans les tests, mais était difficile d'un point de vue informatique, nous l'avons donc réécrite avec des polynômes:

Les inconvénients du modèle comprennent:
- du fait qu'il est basé sur des données historiques, il ne répond pas bien aux changements brusques de sortie;
- si le méthodologiste a un événement de force majeure et qu'il abandonne le créneau horaire, il s'agit d'un départ presque garanti, les gestionnaires doivent réaffecter d'urgence la leçon;
- si le marquage dynamique de la «chaleur» des canaux chute, le modèle estime incorrectement la probabilité de sortie du client.
Grâce à l'utilisation de ce modèle, nous avons économisé jusqu'à 45% sur la leçon d'introduction avec une perte minimale pour les clients.
Pourquoi pas l'apprentissage automatique?
Parce que le modèle statistique fonctionne plutôt bien, et au lieu d'améliorer la précision des prévisions existantes à l'aide de ML, il est plus rentable de diriger les efforts des développeurs de ML vers d'autres tâches.
Par exemple, nous développons un système de notation pour un client potentiel, similaire à distance à un système bancaire. En utilisant le scoring, les banques déterminent la probabilité de remboursement d'un prêt et nous pouvons déterminer la probabilité d'un premier paiement. S'il est très faible, il n'est pas nécessaire de consacrer des ressources à l'organisation d'une leçon d'introduction; si, au contraire, il est très élevé, vous pouvez immédiatement envoyer le client vers la page de paiement.
Mais cette histoire est pour une autre fois.