Nous avons déjà discuté du
moteur d'indexation PostgreSQL, de l'interface des méthodes d'accès et des principales méthodes d'accès, telles que:
les index de hachage ,
les arbres B ,
GiST ,
SP-GiST et
GIN . Dans cet article, nous verrons comment le gin se transforme en rhum.
RHUM
Bien que les auteurs affirment que le gin est un génie puissant, le thème des boissons a finalement gagné: le GIN de nouvelle génération a été appelé RUM.
Cette méthode d'accès élargit le concept qui sous-tend GIN et nous permet d'effectuer une recherche en texte intégral encore plus rapidement. Dans cette série d'articles, c'est la seule méthode qui n'est pas incluse dans une livraison PostgreSQL standard et c'est une extension externe. Plusieurs options d'installation sont disponibles pour cela:
- Prenez le paquet "yum" ou "apt" du dépôt PGDG . Par exemple, si vous avez installé PostgreSQL à partir du package "postgresql-10", installez également "postgresql-10-rum".
- Construisez à partir du code source sur github et installez-le vous-même (les instructions sont là aussi).
- À utiliser dans le cadre de Postgres Pro Enterprise (ou au moins lire la documentation à partir de là).
Limitations du gin
Quelles limitations de GIN RUM nous permet-il de transcender?
Tout d'abord, le type de données "tsvector" contient non seulement des lexèmes, mais également des informations sur leur position à l'intérieur du document. Comme nous l'avons observé la
dernière fois , l'indice GIN ne stocke pas ces informations. Pour cette raison, les opérations de recherche de phrases, apparues dans la version 9.6, sont prises en charge par l'index GIN de manière inefficace et doivent accéder aux données d'origine pour une nouvelle vérification.
Deuxièmement, les systèmes de recherche renvoient généralement les résultats triés par pertinence (quoi que cela signifie). Nous pouvons utiliser les fonctions de classement "ts_rank" et "ts_rank_cd" à cette fin, mais elles doivent être calculées pour chaque ligne du résultat, ce qui est certainement lent.
Pour une première approximation, la méthode d'accès RUM peut être considérée comme GIN qui stocke en outre les informations de position et peut renvoyer les résultats dans un ordre nécessaire (comme
GiST peut renvoyer les voisins les plus proches). Passons étape par étape.
Recherche de phrases
Une requête de recherche en texte intégral peut contenir des opérateurs spéciaux qui prennent en compte la distance entre les lexèmes. Par exemple, nous pouvons trouver des documents dans lesquels "main" est séparé de "cuisse" avec deux autres mots:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@ to_tsquery('hand <3> thigh');
?column? ---------- t (1 row)
Ou nous pouvons indiquer que les mots doivent être situés l'un après l'autre:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@ to_tsquery('hand <-> slap');
?column? ---------- t (1 row)
Un index GIN régulier peut renvoyer les documents qui contiennent les deux lexèmes, mais nous ne pouvons vérifier la distance entre eux qu'en regardant tsvector:
postgres=# select to_tsvector('Clap your hands, slap your thigh');
to_tsvector -------------------------------------- 'clap':1 'hand':3 'slap':4 'thigh':6 (1 row)
Dans l'index RUM, chaque lexème ne fait pas seulement référence aux lignes du tableau: chaque TID est fourni avec la liste des positions où le lexème apparaît dans le document. C'est ainsi que l'on peut envisager l'index créé sur la table "slit-sheet", qui nous est déjà assez familier (la classe d'opérateur "rum_tsvector_ops" est utilisée par défaut pour tsvector):
postgres=# create extension rum; postgres=# create index on ts using rum(doc_tsv);
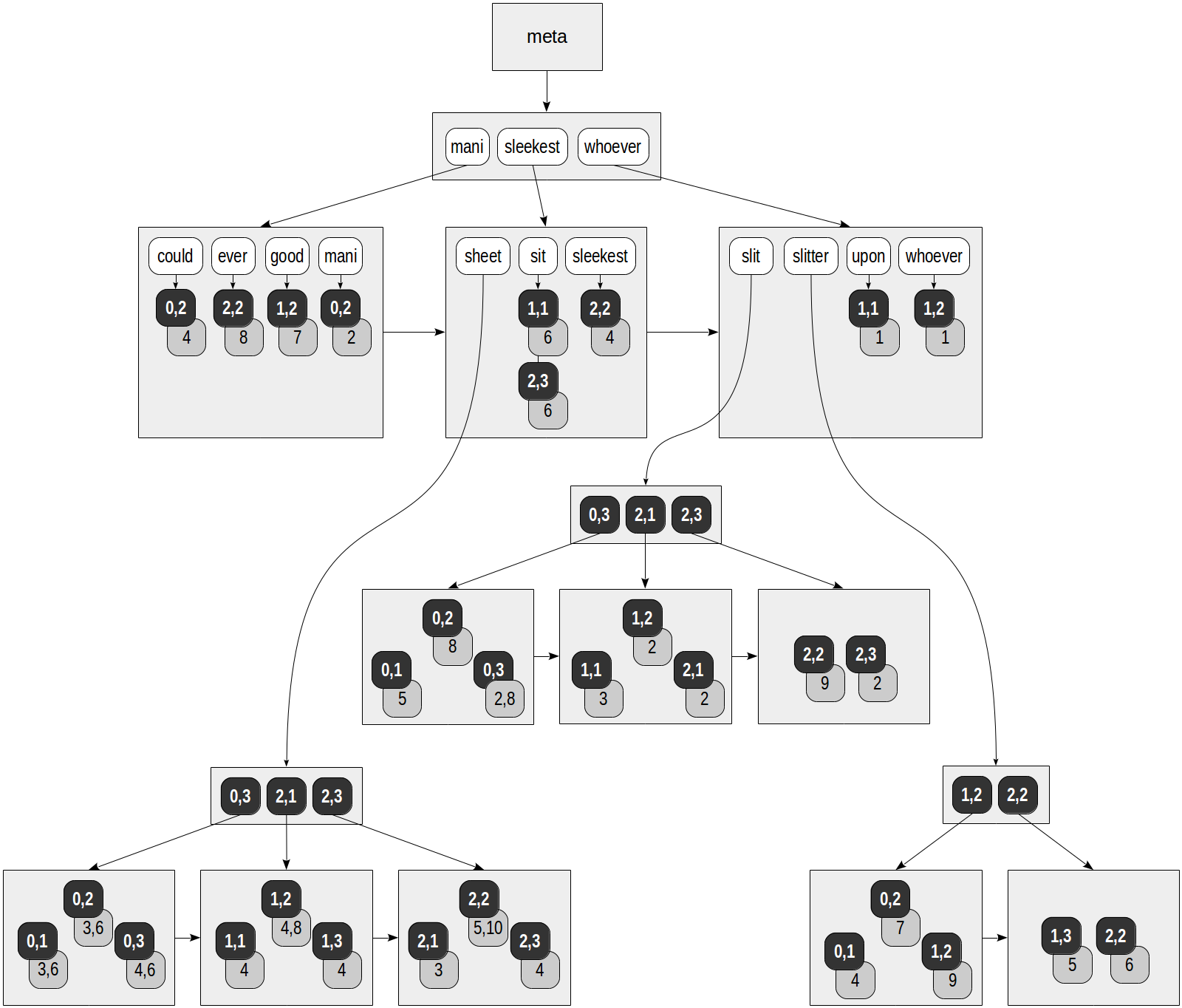
Les carrés gris sur la figure contiennent les informations de position ajoutées:
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv -------+----------------------+--------------------------------------------------------- (0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4 (0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 (0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8 (1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1 (1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 (1,3) | I am a sheet slitter | 'sheet':4 'slitter':5 (2,1) | I slit sheets. | 'sheet':3 'slit':2 (2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 (2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2 (9 rows)
GIN fournit également une insertion différée lorsque le paramètre "fastupdate" est spécifié; cette fonctionnalité est supprimée de RUM.
Pour voir comment l'index fonctionne sur les données en direct, utilisons l'
archive familière de la liste de diffusion pgsql-hackers.
fts=# alter table mail_messages add column tsv tsvector; fts=# set default_text_search_config = default; fts=# update mail_messages set tsv = to_tsvector(body_plain);
... UPDATE 356125
Voici comment une requête qui utilise la recherche de phrases est effectuée avec l'index GIN:
fts=# create index tsv_gin on mail_messages using gin(tsv); fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on mail_messages (actual time=2.490..18.088 rows=259 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Rows Removed by Index Recheck: 1517 Heap Blocks: exact=1503 -> Bitmap Index Scan on tsv_gin (actual time=2.204..2.204 rows=1776 loops=1) Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Planning time: 0.266 ms Execution time: 18.151 ms (8 rows)
Comme nous pouvons le voir sur le plan, l'index GIN est utilisé, mais il renvoie 1776 correspondances potentielles, dont 259 sont laissées et 1517 sont supprimées au stade de la nouvelle vérification.
Supprimons l'index GIN et construisons RUM.
fts=# drop index tsv_gin; fts=# create index tsv_rum on mail_messages using rum(tsv);
L'index contient désormais toutes les informations nécessaires et la recherche est effectuée avec précision:
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on mail_messages (actual time=2.798..3.015 rows=259 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Heap Blocks: exact=250 -> Bitmap Index Scan on tsv_rum (actual time=2.768..2.768 rows=259 loops=1) Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Planning time: 0.245 ms Execution time: 3.053 ms (7 rows)
Tri par pertinence
Pour renvoyer les documents facilement dans l'ordre requis, l'index RUM prend en charge les opérateurs de commande, dont nous avons discuté dans l'article
relatif à
GiST . L'extension RUM définit un tel opérateur,
<=> , qui renvoie une certaine distance entre le document ("tsvector") et la requête ("tsquery"). Par exemple:
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=>l to_tsquery('slit');
?column? ---------- 16.4493 (1 row)
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=> to_tsquery('sheet');
?column? ---------- 13.1595 (1 row)
Le document semble être plus pertinent pour la première requête que pour la seconde: plus le mot apparaît souvent, moins il a de «valeur».
Essayons à nouveau de comparer GIN et RUM sur une taille de données relativement importante: nous sélectionnerons les dix documents les plus pertinents contenant "bonjour" et "pirates".
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello & hackers') order by ts_rank(tsv,to_tsquery('hello & hackers')) limit 10;
QUERY PLAN --------------------------------------------------------------------------------------------- Limit (actual time=27.076..27.078 rows=10 loops=1) -> Sort (actual time=27.075..27.076 rows=10 loops=1) Sort Key: (ts_rank(tsv, to_tsquery('hello & hackers'::text))) Sort Method: top-N heapsort Memory: 29kB -> Bitmap Heap Scan on mail_messages (actual ... rows=1776 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Heap Blocks: exact=1503 -> Bitmap Index Scan on tsv_gin (actual ... rows=1776 loops=1) Index Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Planning time: 0.276 ms Execution time: 27.121 ms (11 rows)
L'index GIN renvoie 1776 correspondances, qui sont ensuite triées en tant qu'étape distincte pour sélectionner les dix meilleurs résultats.
Avec l'index RUM, la requête est effectuée à l'aide d'une simple numérisation d'index: aucun document supplémentaire n'est examiné et aucun tri séparé n'est requis:
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello & hackers') order by tsv <=> to_tsquery('hello & hackers') limit 10;
QUERY PLAN -------------------------------------------------------------------------------------------- Limit (actual time=5.083..5.171 rows=10 loops=1) -> Index Scan using tsv_rum on mail_messages (actual ... rows=10 loops=1) Index Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Order By: (tsv <=> to_tsquery('hello & hackers'::text)) Planning time: 0.244 ms Execution time: 5.207 ms (6 rows)
Informations complémentaires
L'index RUM, ainsi que GIN, peuvent être construits sur plusieurs champs. Mais alors que GIN stocke les lexèmes de chaque colonne indépendamment de ceux d'une autre colonne, RUM nous permet «d'associer» le champ principal («tsvector» dans ce cas) à un autre. Pour ce faire, nous devons utiliser une classe d'opérateur spécialisée "rum_tsvector_addon_ops":
fts=# create index on mail_messages using rum(tsv RUM_TSVECTOR_ADDON_OPS, sent) WITH (ATTACH='sent', TO='tsv');
Nous pouvons utiliser cet index pour renvoyer les résultats triés sur le champ supplémentaire:
fts=# select id, sent, sent <=> '2017-01-01 15:00:00' from mail_messages where tsv @@ to_tsquery('hello') order by sent <=> '2017-01-01 15:00:00' limit 10;
id | sent | ?column? ---------+---------------------+---------- 2298548 | 2017-01-01 15:03:22 | 202 2298547 | 2017-01-01 14:53:13 | 407 2298545 | 2017-01-01 13:28:12 | 5508 2298554 | 2017-01-01 18:30:45 | 12645 2298530 | 2016-12-31 20:28:48 | 66672 2298587 | 2017-01-02 12:39:26 | 77966 2298588 | 2017-01-02 12:43:22 | 78202 2298597 | 2017-01-02 13:48:02 | 82082 2298606 | 2017-01-02 15:50:50 | 89450 2298628 | 2017-01-02 18:55:49 | 100549 (10 rows)
Ici, nous recherchons des lignes correspondantes aussi proches que possible de la date spécifiée, peu importe plus tôt ou plus tard. Pour obtenir les résultats qui précèdent (ou suivent) strictement la date spécifiée, nous devons utiliser
<=| (ou
|=> ).
Comme nous nous y attendons, la requête est effectuée simplement par un simple scan d'index:
ts=# explain (costs off) select id, sent, sent <=> '2017-01-01 15:00:00' from mail_messages where tsv @@ to_tsquery('hello') order by sent <=> '2017-01-01 15:00:00' limit 10;
QUERY PLAN --------------------------------------------------------------------------------- Limit -> Index Scan using mail_messages_tsv_sent_idx on mail_messages Index Cond: (tsv @@ to_tsquery('hello'::text)) Order By: (sent <=> '2017-01-01 15:00:00'::timestamp without time zone) (4 rows)
Si nous créons l'index sans les informations supplémentaires sur l'association de champs, pour une requête similaire, nous devons trier tous les résultats de l'analyse d'index.
En plus de la date, nous pouvons certainement ajouter des champs d'autres types de données à l'index RUM. Pratiquement tous les types de base sont pris en charge. Par exemple, une boutique en ligne peut afficher rapidement les marchandises par nouveauté (date), prix (numérique) et popularité ou valeur de remise (entier ou virgule flottante).
Autres classes d'opérateurs
Pour compléter le tableau, mentionnons les autres classes d'opérateurs disponibles.
Commençons par
"rum_tsvector_hash_ops" et
"rum_tsvector_hash_addon_ops" . Ils sont similaires à "rum_tsvector_ops" et "rum_tsvector_addon_ops" déjà discutés, mais l'index stocke le code de hachage du lexème plutôt que le lexème lui-même. Cela peut réduire la taille de l'index, mais bien sûr, la recherche devient moins précise et nécessite une nouvelle vérification. En outre, l'index ne prend plus en charge la recherche d'une correspondance partielle.
Il est intéressant de regarder la classe d'opérateur
"rum_tsquery_ops" . Il nous permet de résoudre un problème "inverse": trouver des requêtes qui correspondent au document. Pourquoi cela pourrait-il être nécessaire? Par exemple, pour abonner un utilisateur à de nouveaux biens selon son filtre ou pour classer automatiquement les nouveaux documents. Regardez cet exemple simple:
fts=# create table categories(query tsquery, category text); fts=# insert into categories values (to_tsquery('vacuum | autovacuum | freeze'), 'vacuum'), (to_tsquery('xmin | xmax | snapshot | isolation'), 'mvcc'), (to_tsquery('wal | (write & ahead & log) | durability'), 'wal'); fts=# create index on categories using rum(query); fts=# select array_agg(category) from categories where to_tsvector( 'Hello hackers, the attached patch greatly improves performance of tuple freezing and also reduces size of generated write-ahead logs.' ) @@ query;
array_agg -------------- {vacuum,wal} (1 row)
Les classes d'opérateurs restantes
"rum_anyarray_ops" et
"rum_anyarray_addon_ops" sont conçues pour manipuler des tableaux plutôt que "tsvector". Cela a déjà été discuté pour GIN la
dernière fois et n'a pas besoin d'être répété.
Tailles de l'index et du journal d'écriture anticipée (WAL)
Il est clair que puisque RUM stocke plus d'informations que GIN, il doit avoir une taille plus grande. Nous comparions la taille de différents indices la dernière fois; ajoutons RUM à ce tableau:
rum | gin | gist | btree --------+--------+--------+-------- 457 MB | 179 MB | 125 MB | 546 MB
Comme nous pouvons le voir, la taille a augmenté de manière assez importante, ce qui est le coût d'une recherche rapide.
Il convient de prêter attention à un autre point non évident: RUM est une extension, c'est-à-dire qu'il peut être installé sans aucune modification du cœur du système. Cela a été activé dans la version 9.6 grâce à un patch d'
Alexander Korotkov . Un des problèmes qui devait être résolu à cette fin était la génération d'enregistrements de journal. Une technique de journalisation des opérations doit être absolument fiable, par conséquent, une extension ne peut pas être laissée dans cette cuisine. Au lieu de permettre à l'extension de créer ses propres types d'enregistrements de journal, les éléments suivants sont en place: le code de l'extension communique son intention de modifier une page, y apporte des modifications et signale l'achèvement, et c'est le cœur du système, qui compare les anciennes et les nouvelles versions de la page et génère les enregistrements de journal unifiés requis.
L'algorithme de génération de journal actuel compare les pages octet par octet, détecte les fragments mis à jour et enregistre chacun de ces fragments, ainsi que son décalage par rapport au début de la page. Cela fonctionne très bien lors de la mise à jour de seulement plusieurs octets ou de la page entière. Mais si nous ajoutons un fragment à l'intérieur d'une page, en déplaçant le reste du contenu vers le bas (ou vice versa, en supprimant un fragment, en déplaçant le contenu vers le haut), beaucoup plus d'octets changeront que ce qui a été réellement ajouté ou supprimé.
De ce fait, un indice RUM en constante évolution peut générer des enregistrements de journal d'une taille considérablement plus grande que GIN (qui, n'étant pas une extension, mais une partie du noyau, gère le journal de lui-même). L'ampleur de cet effet gênant dépend grandement de la charge de travail réelle, mais pour avoir un aperçu du problème, essayons de supprimer et d'ajouter plusieurs lignes plusieurs fois, entrelaçant ces opérations avec le «vide». Nous pouvons évaluer la taille des enregistrements de journal comme suit: au début et à la fin, rappelez-vous la position dans le journal en utilisant la fonction "pg_current_wal_location" ("pg_current_xlog_location" dans les versions antérieures à dix), puis regardez la différence.
Mais bien sûr, nous devons considérer de nombreux aspects ici. Nous devons nous assurer qu'un seul utilisateur travaille avec le système (sinon, les enregistrements "supplémentaires" seront pris en compte). Même si c'est le cas, nous prenons en compte non seulement RUM, mais aussi les mises à jour de la table elle-même et de l'index qui supporte la clé primaire. Les valeurs des paramètres de configuration affectent également la taille (le niveau de journal "réplique", sans compression, a été utilisé ici). Mais essayons quand même.
fts=# select pg_current_wal_location() as start_lsn \gset
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 0;
INSERT 0 3576
fts=# delete from mail_messages where id % 100 = 99;
DELETE 3590
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 1;
INSERT 0 3605
fts=# delete from mail_messages where id % 100 = 98;
DELETE 3637
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 2;
INSERT 0 3625
fts=# delete from mail_messages where id % 100 = 97;
DELETE 3668
fts=# vacuum mail_messages;
fts=# select pg_current_wal_location() as end_lsn \gset fts=# select pg_size_pretty(:'end_lsn'::pg_lsn - :'start_lsn'::pg_lsn);
pg_size_pretty ---------------- 3114 MB (1 row)
Nous obtenons donc environ 3 Go. Mais si nous répétons la même expérience avec l'indice GIN, cela ne fera qu'environ 700 Mo.
Par conséquent, il est souhaitable d'avoir un algorithme différent, qui trouvera le nombre minimal d'opérations d'insertion et de suppression qui peuvent transformer un état de la page en un autre. L'utilitaire "Diff" fonctionne de manière similaire.
Oleg Ivanov a déjà implémenté un tel algorithme, et son
patch est en cours de discussion. Dans l'exemple ci-dessus, ce correctif nous permet de réduire la taille des enregistrements de journaux de 1,5 fois, à 1900 Mo, au prix d'un petit ralentissement.
Malheureusement, le patch est bloqué et il n'y a aucune activité autour de lui.
Propriétés
Comme d'habitude, regardons les propriétés de la méthode d'accès RUM, en faisant attention aux différences avec GIN (des requêtes
ont déjà été fournies ).
Voici les propriétés de la méthode d'accès:
amname | name | pg_indexam_has_property --------+---------------+------------------------- rum | can_order | f rum | can_unique | f rum | can_multi_col | t rum | can_exclude | t -- f for gin
Les propriétés de couche d'index suivantes sont disponibles:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t -- f for gin bitmap_scan | t backward_scan | f
Notez que, contrairement à GIN, RUM prend en charge l'analyse d'index - sinon, il n'aurait pas été possible de renvoyer exactement le nombre requis de résultats dans les requêtes avec la clause "limit". Il n'y a pas besoin de l'équivalent du paramètre "gin_fuzzy_search_limit" en conséquence. Et en conséquence, l'indice peut être utilisé pour prendre en charge les contraintes d'exclusion.
Les propriétés de couche de colonne sont les suivantes:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | t -- f for gin returnable | f search_array | f search_nulls | f
La différence ici est que RUM prend en charge les opérateurs de commande. Cependant, cela n'est pas vrai pour toutes les classes d'opérateurs: par exemple, cela est faux pour "tsquery_ops".
Continuez à lire .