Bonjour à tous! Je m'appelle Pasha et je suis ingénieur QA pour l'équipe de traitement des commandes chez Lamoda. J'ai récemment parlé à PHP Badoo Meetup. Aujourd'hui, je veux fournir une transcription de mon rapport.
Nous parlerons de Codeception, de la façon dont nous l'utilisons dans Lamoda et comment écrire des tests dessus.
Lamoda a de nombreux services. Il existe des services clients qui interagissent directement avec nos utilisateurs, avec les utilisateurs du site, l'application mobile. Nous n'en parlerons pas. Et il y a ce que notre entreprise appelle des backends profonds - ce sont nos systèmes de back-office qui automatisent nos processus commerciaux. Il s'agit notamment de la livraison, du stockage, de l'automatisation des studios photo et d'un centre d'appels. La plupart de ces services sont développés en PHP.
En parlant brièvement de notre pile, voici PHP + Symfony. Ici et là, il y a de vieux projets sur Zend'e. PostgreSQL et MySQL sont utilisés comme bases de données, et Rabbit ou Kafka sont utilisés comme systèmes de messagerie.
Pourquoi les backends PHP?Parce qu'ils ont généralement une API branchée - c'est soit REST, à certains endroits, il y a un peu de SOAP. S'ils ont une interface utilisateur, cette interface est plus une interface auxiliaire, que nos utilisateurs internes utilisent.
Pourquoi avons-nous besoin d'autotests chez Lamoda?En général, quand je suis venu travailler chez Lamoda, il y avait un tel slogan: «Débarrassons-nous de la régression manuelle». Nous ne testerons rien de régression manuellement. Et nous avons travaillé sur cette tâche. En fait, c'est l'une des principales raisons pour lesquelles nous avons besoin d'autotests - afin de ne pas conduire la régression à la main. Pourquoi en avons-nous besoin? Droit de libérer rapidement. Pour que nous puissions sans douleur, très rapidement déployer nos versions et en même temps avoir une sorte de grille d'auto-tests qu'ils nous diront, bonne ou mauvaise. Ce sont probablement les objectifs les plus importants. Mais il y a quelques auxiliaires, dont je veux également parler.
Pourquoi avons-nous besoin d'autotests?
- Ne testez pas la régression avec vos mains
- Libération rapide
- Utiliser comme documentation
- Accélérez l'intégration de nouveaux employés
- Les autotests sont commodément utilisés (dans certains cas) comme documentation. Parfois, il est plus facile d'entrer dans les tests, de voir quels cas sont couverts, comment ils fonctionnent et de comprendre comment telle ou telle fonctionnalité fonctionne, et d'accélérer l'entrée de nouveaux employés - développeurs et testeurs - dans un nouveau projet. Lorsque vous vous asseyez pour écrire des autotests, il devient immédiatement clair comment fonctionne le système.
Ok, a expliqué pourquoi nous avons besoin d'autotests. Parlons maintenant des tests que nous écrivons dans Lamoda.
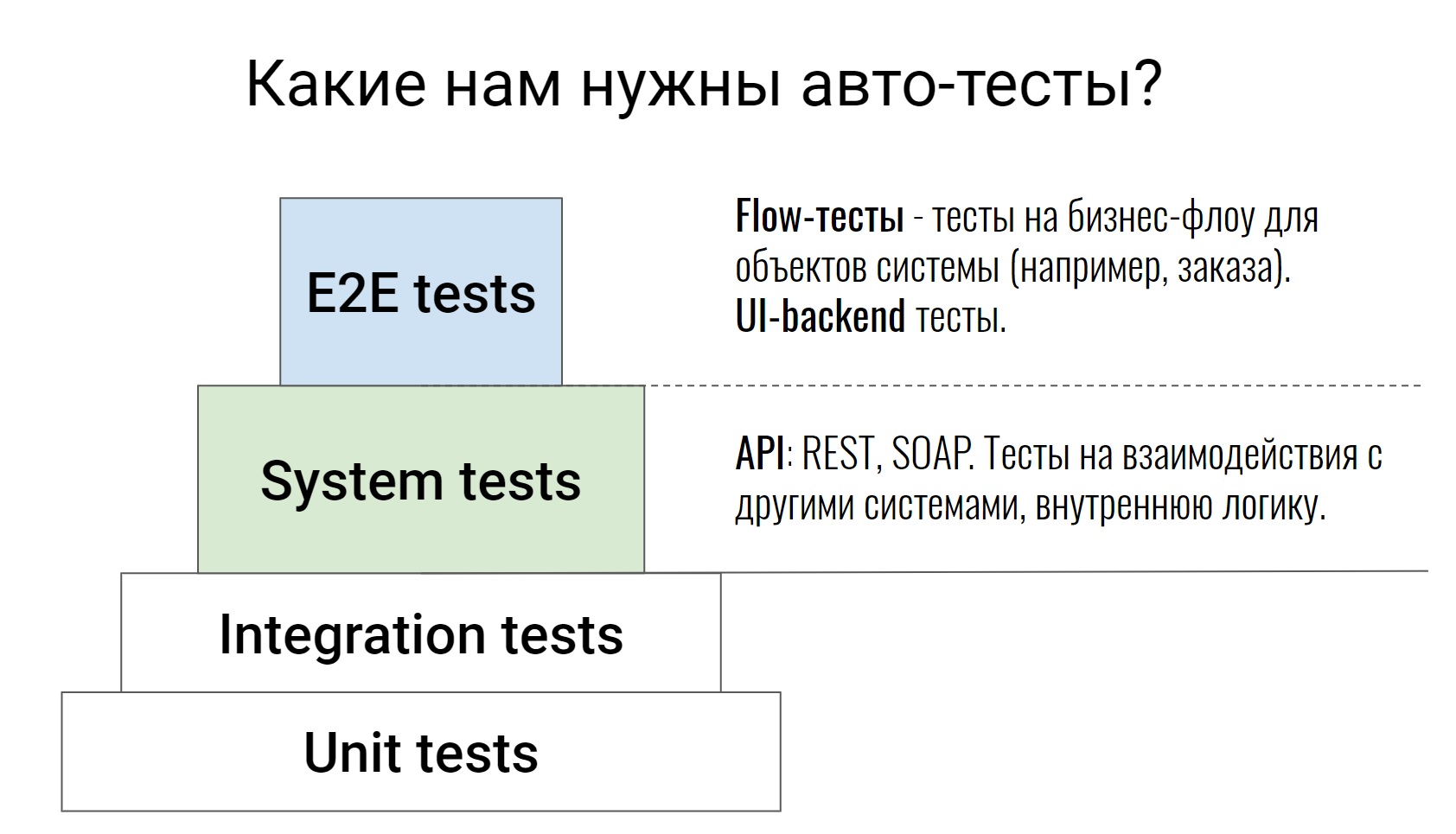
Il s'agit d'une pyramide de tests assez standard, des tests unitaires aux tests E2E, où certaines chaînes commerciales sont déjà testées. Je ne parlerai pas des deux niveaux inférieurs, ce n'est pas pour rien qu'ils sont peints d'une telle couleur blanche. Ce sont des tests sur le code lui-même, ils sont écrits par nos développeurs. Dans les cas extrêmes, le testeur peut accéder à la demande de tirage, consulter le code et dire: "Eh bien, quelque chose ne suffit pas ici, couvrons autre chose." Ceci termine le travail du testeur pour ces tests.
Nous parlerons des niveaux ci-dessus, qui sont écrits par des développeurs et des testeurs. Commençons par les tests du système. Ce sont des tests qui testent l'API (REST ou SOAP), testent la logique du système interne, diverses commandes, analysent les files d'attente dans Rabbit ou échangent avec des systèmes externes. En règle générale, ces tests sont assez atomiques. Ils ne vérifient aucune chaîne, mais vérifient une action. Par exemple, une méthode API ou une commande. Et ils vérifient autant de cas que possible, à la fois positifs et négatifs.
Allez-y, tests E2E. Je les ai divisés en 2 parties. Nous avons des tests qui testent un tas d'interface utilisateur et de backend. Et il y a des tests que nous appelons des tests de flux. Ils testent la chaîne - la vie d'un objet du début à la fin.
Par exemple, nous avons un système de gestion du traitement de nos commandes. À l'intérieur d'un tel système, il peut y avoir un test - une commande de la création à la livraison, c'est-à-dire en passant par tous les statuts. C'est sur de tels tests qu'il est alors très facile et simple de voir comment fonctionne le système. Vous voyez immédiatement le flux entier de certains objets, avec quels systèmes externes tout cela interagit, quelles commandes sont utilisées pour cela.
Étant donné que cette interface utilisateur est utilisée par les utilisateurs internes, l'accès inter-navigateur n'est pas important pour nous. Nous ne réalisons ces tests sur aucune batterie de serveurs, il nous suffit de vérifier dans un navigateur, et parfois nous n'avons même pas besoin d'utiliser un navigateur.
"Pourquoi avons-nous choisi Codeception pour l'automatisation des tests?" - vous demandez probablement.
Pour être honnête, je n'ai pas de réponse à cette question. Quand je suis arrivé à Lamoda, Codeception était déjà sélectionné comme standard pour écrire les autotests, et je l'ai rencontré en fait. Mais après avoir travaillé avec ce cadre pendant un certain temps, j'ai toujours compris pourquoi Codeception. Voilà ce que je veux partager avec vous.
Pourquoi codeception?- Vous pouvez écrire et exécuter les mêmes tests de toute nature (unitaires, fonctionnels, acceptation).
- De nombreux râteaux ont déjà été résolus, de nombreux modules ont déjà été écrits.
- Dans tous les projets, malgré des besoins légèrement différents, les tests seront identiques.
- Le concept de Codeception vous propose d'écrire des tests sur ce framework: unité, intégration, fonctionnel, acceptation. Et vous, au moins, ils seront lancés également.
- Codeception est un processeur assez puissant dans lequel de nombreux problèmes, de nombreuses questions, de nombreuses tâches de tests ont déjà été résolus. Si quelque chose n'est pas décidé, vous trouverez très probablement quelque chose de l'extérieur - un complément pour un travail spécifique. Vous n'avez pas besoin d'écrire de wrappers de test pour les bases de données, pour autre chose. Prenez et connectez simplement les modules à Codeception et travaillez avec eux.
- Eh bien, un tel avantage (il est probablement plus adapté aux grandes entreprises lorsque vous avez de nombreux projets et services) - dans tous les projets, les tests seront plus ou moins les mêmes. C'est très cool.
Je vais dire brièvement à quoi ressemble Codeception, car beaucoup y ont travaillé.

Codeception fonctionne sur un modèle d'acteur. Après l'avoir glissé dans le projet et initialisé, une telle structure est générée.
Nous avons des fichiers yml, ci-dessous -
fonctionnel.suite.yml ,
integration.suit.yml ,
unit.suite.yml . Ils créent la configuration de vos tests. Il y a des papas pour chaque type de test, où ces tests sont, il y a 3 papas auxiliaires:
_
données - pour les données de test;
_
sortie - où les rapports sont placés (xml, html);
_
support - où certains assistants auxiliaires, fonctions et tout ce que vous écrivez sont mis à profit dans vos tests.
Pour commencer, je vais vous dire ce que nous avons retiré de Codeception et l'utiliser immédiatement, sans rien modifier, sans résoudre de tâches ou de problèmes supplémentaires.
Modules standard- Phpbrowser
- REPOS
- Db
- Cli
- AMQP
Le premier de ces modules est PhpBrowser. Ce module est un wrapper sur Guzzle qui vous permet d'interagir avec votre application: ouvrir des pages, remplir des formulaires, soumettre des formulaires. Et si vous ne vous souciez pas des tests inter-navigateurs et des navigateurs, si vous testez soudainement l'interface utilisateur, vous pouvez utiliser PhpBrowser. En règle générale, nous l'utilisons dans nos tests d'interface utilisateur, car nous n'avons pas besoin de logique d'interaction compliquée, nous devons simplement ouvrir la page et y faire quelque chose de petit.
Le deuxième module que nous utilisons est REST. Je pense que le nom indique clairement ce qu'il fait. Pour toute interaction http, vous pouvez utiliser ce module. Il me semble que presque toutes les interactions y sont résolues: en-têtes, cookies, autorisation. Tout ce dont vous avez besoin est dedans.
Le troisième module que nous utilisons hors de la boîte est le module Db. Dans les versions récentes de Codeception, la prise en charge non pas d'une, mais de plusieurs bases de données y a été ajoutée. Par conséquent, si vous avez soudainement plusieurs bases de données dans votre projet, cela fonctionne maintenant hors de la boîte.
Le module Cli, qui vous permet d'exécuter
des commandes
shell et
bash à partir de tests, et nous l'utilisons également.
Il existe un module AMQP qui fonctionne avec tous les courtiers de messages basés sur ce protocole. Je veux noter qu'il est officiellement testé sur RabbitMQ. Puisque nous utilisons RabbitMQ, tout va bien avec lui.
En fait, Codeception, du moins dans notre cas, couvre 80 à 85% de toutes les tâches dont nous avons besoin. Mais je devais encore travailler sur quelque chose.
Commençons par SOAP.

Dans nos services, il existe à certains endroits des points de terminaison SOAP. Ils doivent être testés, tirés, quelque chose à voir avec eux. Mais vous direz que dans Codeception, il existe un tel module qui vous permet d'envoyer des demandes et ensuite de faire quelque chose avec les réponses. D'une manière ou d'une autre pour analyser, ajouter des chèques et tout va bien. Mais le module SOAP ne fonctionne pas prêt à l'emploi avec plusieurs points de terminaison SOAP.

Par exemple, nous avons des monolithes qui ont plusieurs WSDL, plusieurs points de terminaison SOAP. Cela signifie qu'il est impossible dans le module Codeception de le configurer dans un fichier yml afin qu'il puisse fonctionner avec plusieurs.

Codeception a une reconfiguration de module dynamique, et vous pouvez écrire une sorte d'adaptateur pour recevoir, par exemple, un module SOAP et le reconfigurer dynamiquement. Dans ce cas, il est nécessaire de remplacer le point final et le schéma utilisé. Ensuite, dans le test, si vous devez changer le point de terminaison auquel vous souhaitez envoyer une demande, nous obtenons notre adaptateur et le changeons en un nouveau point de terminaison, en un nouveau circuit et lui envoyons une demande.

Dans Codeception, il n'y a pas de travail avec Kafka et il n'y a pas de modules complémentaires plus ou moins officiels tiers pour travailler avec Kafka. Il n'y a rien à craindre, nous avons écrit notre module.

Il est donc configuré dans un fichier yml. Certains paramètres sont définis pour les courtiers, les consommateurs et les sujets. Ces paramètres, lorsque vous écrivez votre module, vous pouvez ensuite le tirer dans des modules avec la fonction d'initialisation et initialiser ce module avec les mêmes paramètres. Et, en fait, le module a toutes les autres méthodes à implémenter - mettez le message dans la rubrique et lisez-le. C'est tout ce dont vous avez besoin de ce module.
 Conclusion
Conclusion : les modules pour Codeception sont faciles à écrire.
Allez-y. Comme je l'ai dit, Codeception a un module Cli - un wrapper pour
les commandes
shell et travaillant avec leur sortie.

Mais parfois, la commande
shell doit être exécutée non pas dans les tests, mais dans l'application. En général, les tests et les applications sont des entités légèrement différentes, elles peuvent se situer à différents endroits. Les tests peuvent être exécutés à un endroit et l'application peut être à un autre.
Alors, pourquoi devons-nous exécuter
shell dans les tests?
Nous avons des commandes dans les applications qui, par exemple, analysent les files d'attente dans RabbitMQ et déplacent les objets par statut. Ces commandes en mode pro sont lancées sous le superviseur. Le superviseur surveille leur mise en œuvre. S'ils tombent, alors il les recommence et ainsi de suite.
Lorsque nous testons, le superviseur ne fonctionne pas. Sinon, les tests deviennent instables, imprévisibles. Nous voulons nous-mêmes contrôler le lancement de ces commandes à l'intérieur de l'application. Par conséquent, nous devons exécuter ces commandes à partir des tests de l'application. Nous utilisons deux options. Celui-là, que l'autre - en principe, tout est pareil, et tout fonctionne.
Comment exécuter un
shell dans une application?
Tout d'abord: exécutez les tests au même endroit où se trouve l'application. Étant donné que toutes les applications que nous avons dans Docker, les tests peuvent être exécutés dans le même conteneur où se trouve le service lui-même.
La deuxième option: créer un conteneur séparé pour les tests, un certain
lanceur de test , mais le rendre identique à l'application. Autrement dit, à partir de la même image Docker, puis tout fonctionnera de la même manière.

Un autre problème que nous avons rencontré lors des tests est de travailler avec différents systèmes de fichiers. Vous trouverez ci-dessous un exemple de ce avec quoi vous pouvez et devez travailler. Les trois premiers sont pertinents pour nous. Ce sont Webdav, SFTP et le système de fichiers Amazon.
Avec quoi avez-vous besoin de travailler?
- Webdav
- FTP / SFTP
- AWS S3
- Local
- Azure, Dropbox, Google Drive
Si vous fouillez dans Codeception, vous pouvez trouver des modules pour presque tous les systèmes de fichiers plus ou moins populaires.
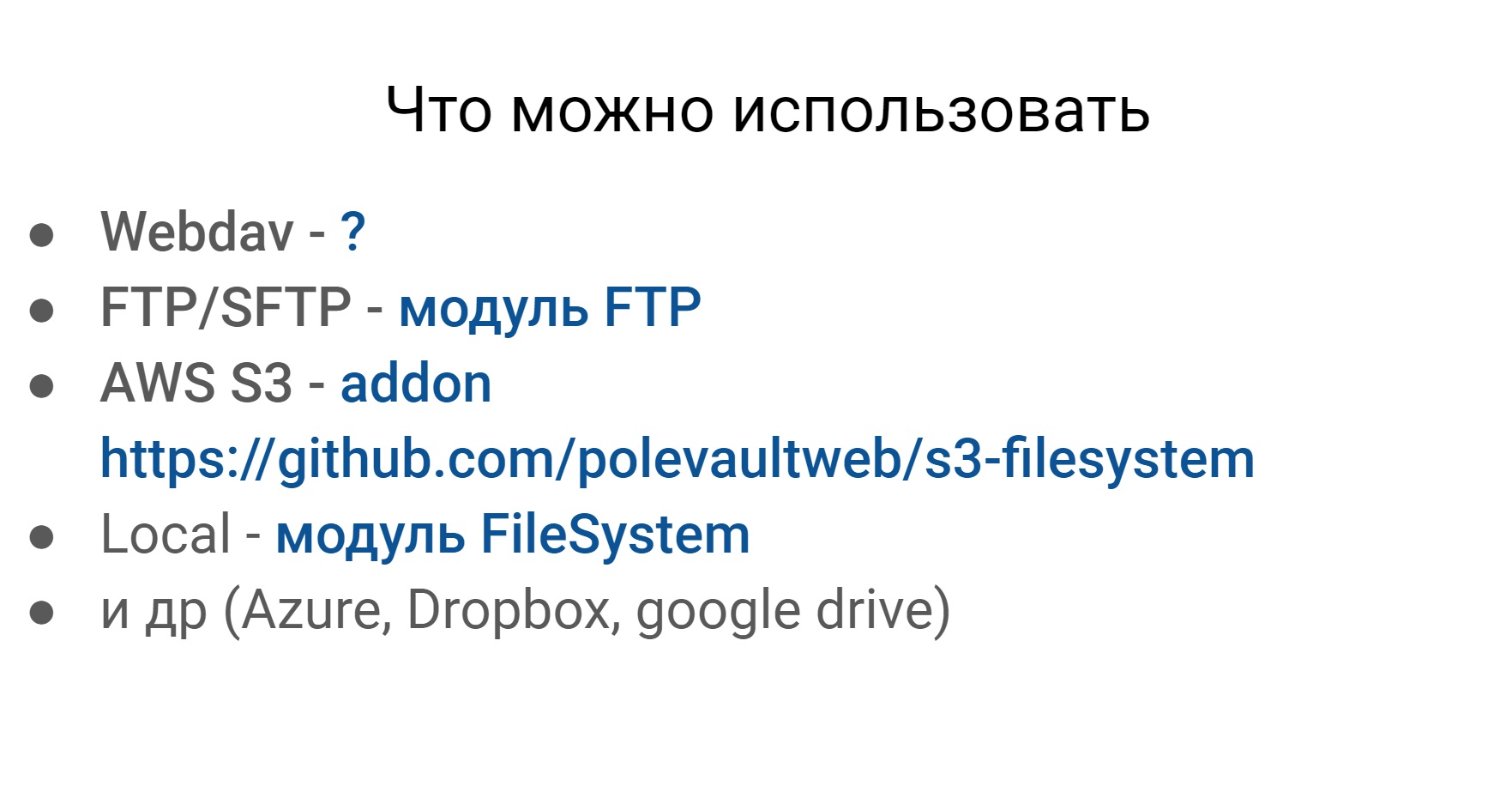
La seule chose que je n'ai pas trouvée est pour Webdav. Mais ces systèmes de fichiers, plus ou moins, sont les mêmes en termes de travail externe avec eux, et nous voulons travailler avec eux de la même manière.
Nous avons écrit notre module appelé Flysystem. Il se trouve sur
Github dans le domaine public et prend en charge 2 systèmes de fichiers - SFTP et Webdav - et vous permet de travailler avec les deux en utilisant la même API.

Obtenez une liste de fichiers, nettoyez le répertoire, écrivez un fichier, etc. Si vous y ajoutez également le système de fichiers Amazon, nos besoins seront certainement couverts.
Le point suivant, je pense, est très important pour les autotests, en particulier au niveau du système, c'est de travailler avec des bases de données. En général, je veux que ce soit, comme dans l'image, - VZHUH et tout démarre, cela fonctionne, et ces bases de données devraient être moins prises en charge dans les tests.

Quelles sont les principales tâches que je vois ici:
- Comment déployer la base de données de la structure souhaitée - Db
- Comment remplir la base de données avec des données de test - Db, Fixtures
- Comment faire des sélections et des contrôles - Db
Pour les 3 tâches de Codeception, il y a 2 modules - Db, dont j'ai déjà parlé, un autre est appelé Fixtures.
De ces 2 modules et 3 tâches, nous utilisons uniquement DB pour la troisième tâche.
Pour la première tâche, vous pouvez utiliser DB. Là, vous pouvez configurer le vidage SQL à partir duquel la base de données sera déployée, eh bien, le module avec des accessoires, je pense que c'est clair pourquoi il est nécessaire.
Il y aura des appareils sous forme de tableaux qui peuvent être conservés dans la base de données.
Comme je l'ai dit, les 2 premières tâches que nous résolvons un peu différemment, maintenant je vais vous dire comment nous le faisons.
Déploiement de la base de données- Relever un conteneur avec PostgreSQL ou MySQL
- Nous roulons toutes les migrations avec des migrations de doctrine
Le premier concerne le déploiement d'une base de données. Comment cela se produit-il dans les tests. Nous élevons le conteneur avec la base de données souhaitée - PostgreSQL ou MySQL, puis effectuons toutes les migrations nécessaires à l'aide des
migrations de doctrine . Tout, la base de données de la structure souhaitée est prête, elle peut être utilisée dans des tests.
Pourquoi nous n'utilisons pas d'amortisseurs - car alors il n'a pas besoin d'être pris en charge. Il s'agit d'une sorte de vidage qui réside dans les tests, qui doit être constamment mis à jour si quelque chose change dans la base de données. Il y a des migrations - pas besoin de maintenir un vidage.
Le deuxième point est la création de données de test. Nous n'utilisons pas le module Fixtures de Codeception, nous utilisons le bundle
Symfony pour les fixtures.

Il y a un
lien vers celui-ci et un exemple de la façon dont vous pouvez créer des appareils dans la base de données.
Votre appareil sera alors créé en tant qu'objet du domaine, il pourra être stocké dans la base de données et les données de test seront prêtes.
Pourquoi DoctrineFixtureBundle?
- Plus facile de créer des chaînes d'objets associés.
- Moins de duplication des données si les appareils pour différents tests sont similaires.
- Moins de modifications lors du changement de la structure de la base de données.
- Les classes de fixtures sont beaucoup plus visuelles que les tableaux.
Pourquoi l'utilisons-nous? Oui, pour la même raison - ces appareils sont beaucoup plus faciles à entretenir que les appareils de Codeception. Il est plus facile de créer des chaînes d'objets liés, car tout est dans le bundle symfony. Moins de données doivent être dupliquées, car les appareils peuvent être hérités, ce sont des classes. Si la structure de la base de données change, ces tableaux doivent toujours être modifiés et les classes pas toujours. Les luminaires sous forme d'objets de domaine sont toujours plus visibles que les tableaux.
Nous avons parlé de bases de données, parlons un peu de moki.
Puisqu'il s'agit de tests d'un niveau suffisamment élevé pour tester l'ensemble du système et que nos systèmes sont fortement interconnectés, il est clair qu'il y a des échanges et des interactions. Nous allons maintenant parler des mokeys sur l'interaction entre les systèmes.
Règles pour mok- Pleurez toutes les interactions externes du service http
- Vérification non seulement des scénarios positifs, mais aussi négatifs
Les interactions sont des interactions REST ou SOAP http. Toutes ces interactions dans le cadre des tests que nous mouillons. Autrement dit, dans nos tests, il n'y a aucun appel réel aux systèmes externes nulle part. Cela rend les tests stables. Parce qu'un service externe peut fonctionner, peut ne pas fonctionner, peut répondre lentement, peut rapidement, en général, ne sait pas quel est son comportement. Par conséquent, nous couvrons tout cela avec des moks.
Nous avons également une telle règle. Nous mouillons non seulement les interactions positives, mais nous essayons également de vérifier certains cas négatifs. Par exemple, lorsqu'un service tiers répond avec une 500e erreur ou produit une erreur plus significative, nous essayons de tout vérifier.
Nous utilisons Wiremock pour les simulations, Codeception lui-même prend en charge ..., il a un tel complément officiel Httpmock, mais nous avons aimé Wiremock plus. Comment ça marche?
Wiremock se lève en tant que conteneur Docker distinct pendant les tests, et toutes les demandes qui doivent être envoyées au système externe sont envoyées à Wiremock.
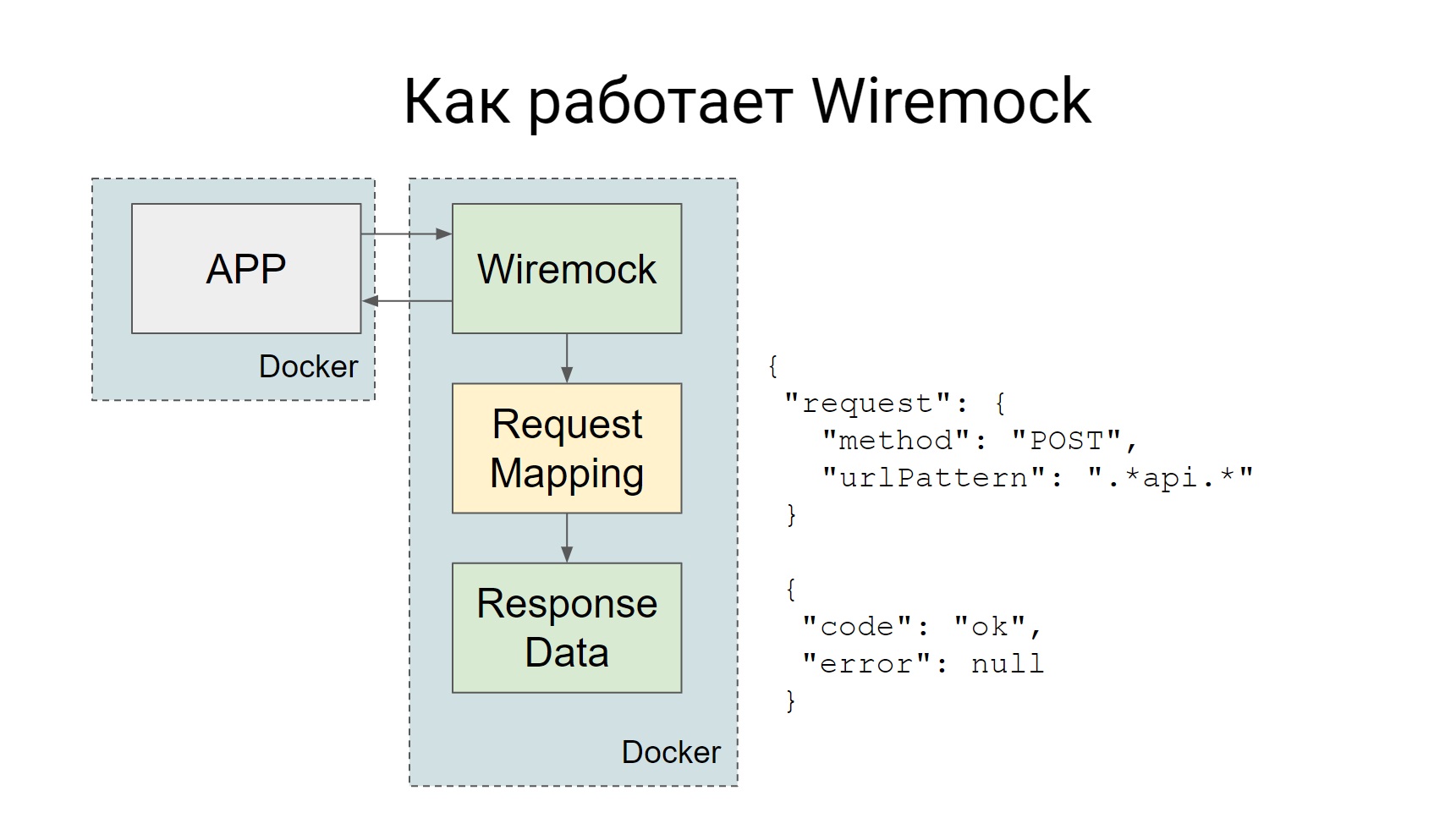
Wiremock, si vous regardez la diapositive - il y a une telle boîte, Request Mapping, elle a un ensemble de ces mappages qui disent que si une telle demande arrive, vous devez donner une telle réponse. Tout est très simple: une demande est venue - a reçu une maquette.
Les mocks peuvent être créés statiquement, puis le conteneur, quand déjà avec Wiremock monte, ces mocks seront disponibles, ils peuvent être utilisés dans les tests manuels. Vous pouvez créer dynamiquement, directement dans le code, dans une sorte de test.
Voici un exemple de la façon de créer dynamiquement une maquette, vous voyez, la description est assez déclarative, il est immédiatement clair à partir du code quel type de maquette que nous créons: une maquette pour la méthode GET qui vient à une telle URL, et, en fait, quoi retourner.

Outre le fait que cette maquette peut être créée, Wiremock a alors la possibilité de vérifier quelle requête a été envoyée à cette maquette. Ceci est également très utile dans les tests.
À propos de Codeception lui-même, probablement, tout, et quelques mots sur la façon dont nos tests sont exécutés, et un peu d'infrastructure.
Qu'utilisons-nous?

Eh bien, tout d'abord, nous avons tous les services dans Docker, donc le lancement d'un environnement de test soulève les conteneurs nécessaires.
Make est utilisé pour les commandes internes, Bamboo est utilisé comme CI.
À quoi ressemble le test CI?

Tout d'abord, nous construisons la version souhaitée de l'application, puis nous élevons l'environnement - c'est l'application, tous les services dont elle a besoin, comme Kafka, Rabbit, la base de données, et nous roulons la migration vers la base de données.
Tout cet environnement est créé à l'aide de Docker Compose. C'est en CI, sur prod que tous les conteneurs tournent sous Kubernetes. Exécutez ensuite les tests et exécutez.
Combien de temps cela prend-il?
Tout dépend du service spécifique, mais, en règle générale, augmenter l'environnement avant d'exécuter les tests est de 5 à 10 minutes, les tests - de 6 à 30 minutes.

Je vais immédiatement avertir cette question pendant que tous les tests se poursuivent dans un seul fil.
Eh bien, une telle question. À quelle fréquence les tests doivent-ils être exécutés? Bien sûr, le plus souvent, le mieux. Plus tôt vous pouvez détecter un problème, plus vite vous pouvez le résoudre.
Nous avons 2 règles principales. Lorsqu'une tâche est soumise à des tests, tous les tests doivent réussir, à la fois les tests unitaires et non les tests unitaires. Si certains tests échouent, c'est l'occasion de transférer la tâche vers la correction.Naturellement, lorsque nous déployons la version. À la sortie, tous les tests doivent réussir.En fin de compte, je voudrais dire quelque chose d'inspirant - écrivez des tests, laissez-les être verts, utilisez Codeception, faites du moki. Je pense que vous comprenez tous parfaitement cela.