Salut
Saviez-vous que les plates-formes publicitaires copient souvent le contenu de concurrents pour augmenter le nombre d'annonces qu'elles hébergent? Ils le font de cette façon: ils appellent les vendeurs et leur proposent de s'installer sur leur plateforme. Et parfois, ils copient complètement les annonces sans autorisation de l'utilisateur. Avito est un lieu populaire, et nous rencontrons souvent une telle concurrence déloyale. Lisez comment nous combattons ce phénomène, lisez sous la coupe.

Le problème
La copie de contenu d'Avito vers d'autres plateformes existe dans plusieurs catégories de produits et services. Cet article se concentrera uniquement sur les voitures. Dans un post précédent, j'ai expliqué comment nous masquions automatiquement les numéros sur les voitures.

Mais il s'est avéré (à en juger par les résultats de recherche d'autres plateformes) que nous avons lancé cette fonctionnalité tout de suite sur trois sites d'annonces.

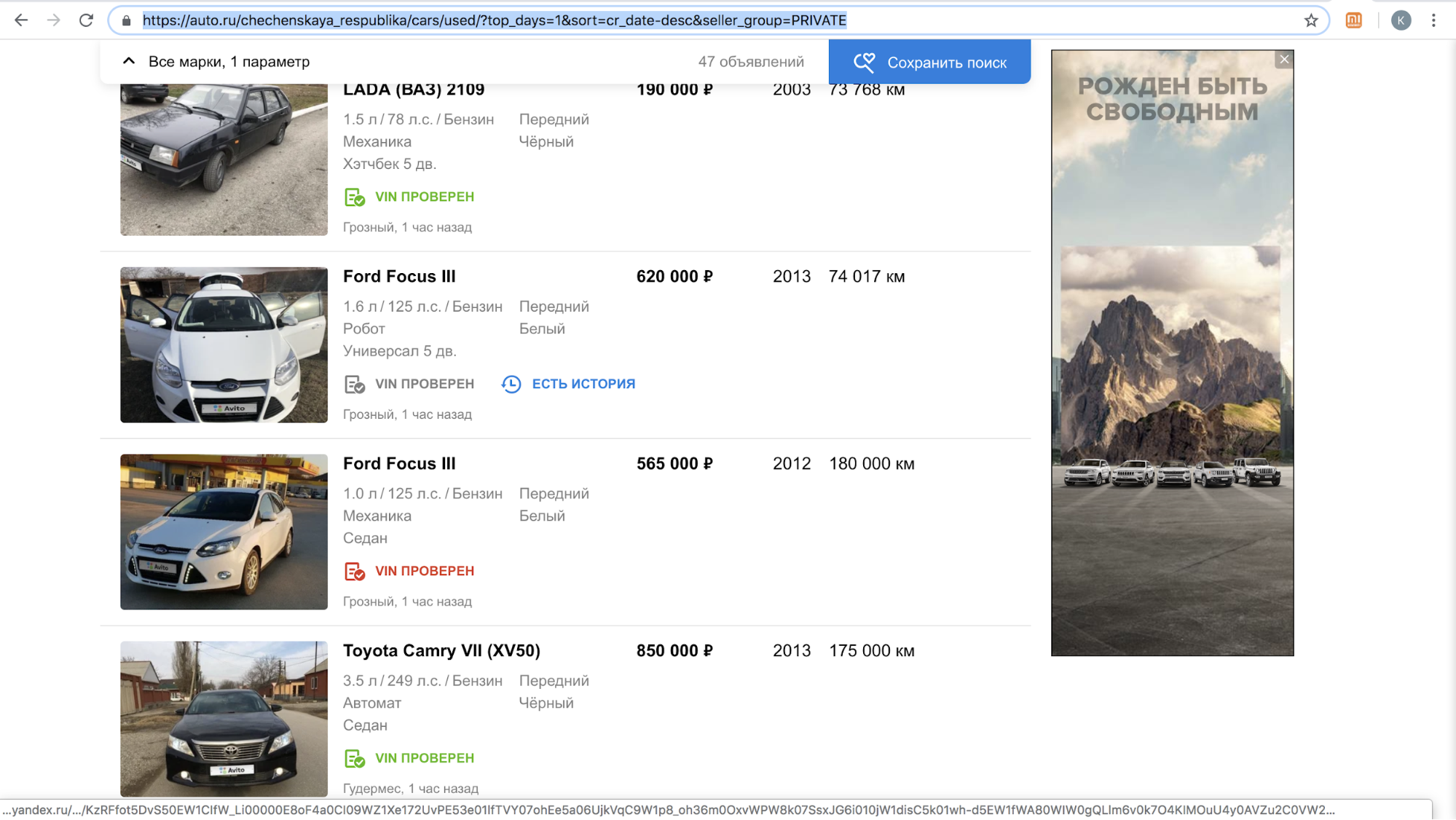
Après le lancement d'une fonctionnalité, l'un de ces sites a temporairement suspendu l'appel de nos utilisateurs avec des offres pour copier l'annonce sur leur plateforme: il y avait trop de contenu avec le logo Avito sur leur site, en novembre 2018 seulement, il y avait plus de 70000 annonces. Par exemple, voici à quoi ressemblaient leurs résultats de recherche par jour en République tchétchène.
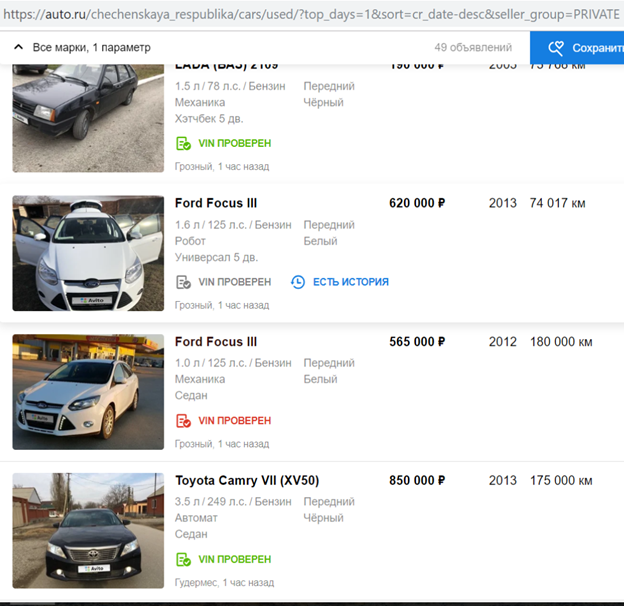
Après avoir terminé leur algorithme pour masquer les plaques d'immatriculation afin qu'il détecte et ferme automatiquement le logo Avito, ils ont repris le processus.

De notre point de vue, copier le contenu des concurrents, l'utiliser à des fins commerciales est contraire à l'éthique et inacceptable. Nous recevons des plaintes de nos utilisateurs, qui ne sont pas satisfaits de cela, dans notre support. Et voici un exemple de réaction dans l'une des histoires.
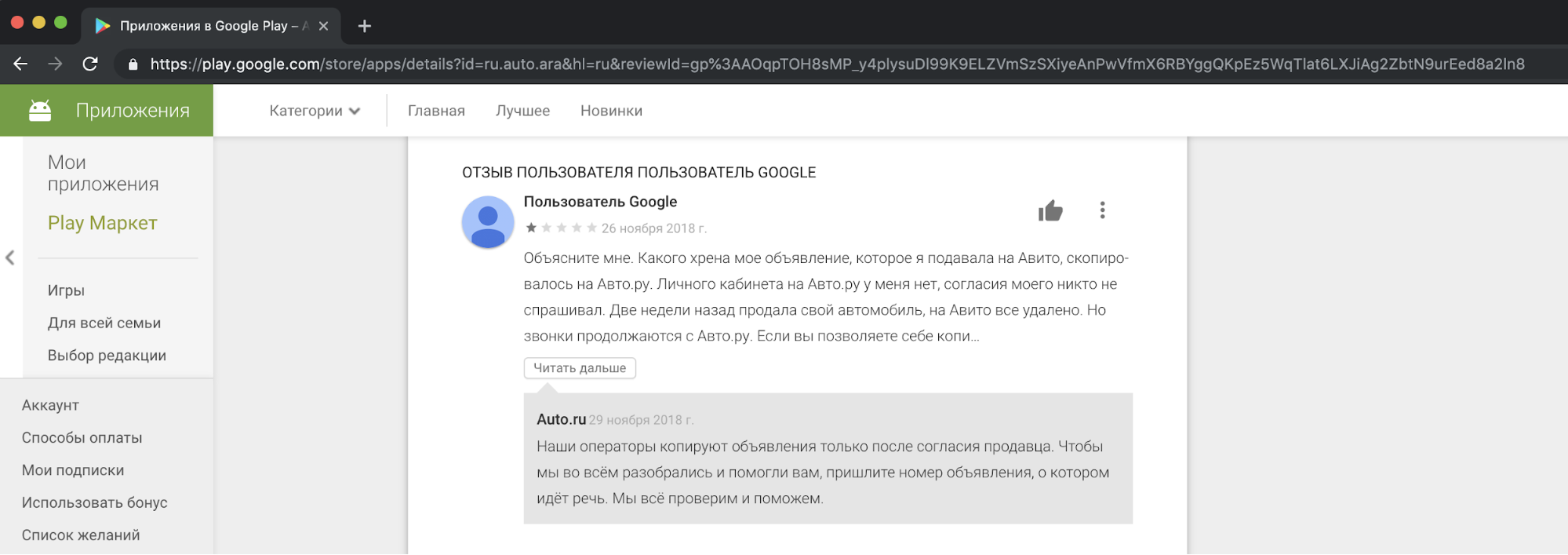
Je dois dire que la demande de consentement des gens pour copier des publicités ne justifie pas de telles actions. Il s'agit d'une violation des lois "Sur la publicité" et "Sur les données personnelles", les règles Avito, les droits de marque et la base de données d'annonces.
Nous ne pouvions pas nous mettre d'accord pacifiquement avec un concurrent, mais nous ne voulions pas laisser la situation telle quelle.
Façons de résoudre le problème
La première méthode est légale. Des précédents similaires existent déjà dans d'autres pays. Par exemple, le célèbre classificateur américain Craigslist a saisi de grosses sommes d'argent sur des sites copiant du contenu.
La deuxième façon de résoudre le problème de copie consiste à ajouter un grand filigrane à l'image afin qu'elle ne puisse pas être recadrée.
La troisième méthode est technologique. Nous pouvons compliquer le processus de copie de notre contenu. Il est logique de supposer qu'un modèle cherche à cacher le logo Avito à ses concurrents. Il est également connu que de nombreux modèles sont sujets à des «attaques» qui les empêchent de fonctionner correctement. Cet article portera uniquement sur eux.
Attaque contradictoire

Idéalement, l'exemple contradictoire pour le réseau ressemble à un bruit qui ne peut pas être distingué par l'œil humain, mais pour le classificateur, il ajoute un signal suffisant à la classe qui n'est pas dans l'image. Par conséquent, une image, par exemple, avec un panda, est classée avec une grande confiance comme un gibbon. La création de bruit contradictoire est possible non seulement pour les réseaux de classification d'images, mais aussi pour la segmentation, la détection. Un exemple intéressant est un travail récent de Keen Labs: ils ont trompé un pilote automatique Tesla avec des points sur le trottoir et un détecteur de pluie en affichant exactement un tel bruit contradictoire . Il y a aussi des attaques pour d'autres domaines, par exemple le son: l'attaque bien connue sur Amazon Alexa et d'autres assistants vocaux consistait à jouer des équipes indiscernables par l'oreille humaine (des crackers proposaient d'acheter quelque chose sur Amazon).
La création de bruit contradictoire pour les modèles d'analyse d'images est possible en raison de l'utilisation non standard du gradient nécessaire à la formation du modèle. Habituellement, dans la méthode de rétro-propagation des erreurs, en utilisant le gradient calculé de la fonction objectif, seuls les poids des couches de réseau sont modifiés de manière à ce qu'il soit moins trompé sur l'ensemble de données d'apprentissage. Tout comme pour les couches réseau, vous pouvez calculer le gradient de la fonction objectif à partir de l'image d'entrée et le modifier. La modification de l'image d'entrée à l'aide d'un gradient a été utilisée pour divers algorithmes bien connus. Rappelez-vous Deepdream ?

Si nous calculons de manière itérative le gradient de la fonction objectif à partir de l'image d'entrée et y ajoutons ce gradient, plus d'informations sur la classe dominante d'ImageNet apparaissent dans l'image: plus de visages de chiens apparaissent, grâce à quoi la valeur de la fonction de perte diminue et le modèle devient plus confiant dans la classe des chiens. Pourquoi le chien est-il dans l'exemple? Juste dans ImageNet de 1000 classes - 120 classes de chiens . Une approche similaire de la modification d'image a été utilisée dans l'algorithme de transfert de style, connu principalement en raison de l'application Prisma.
Pour créer un exemple contradictoire, vous pouvez également utiliser la méthode itérative de modification de l'image d'entrée.
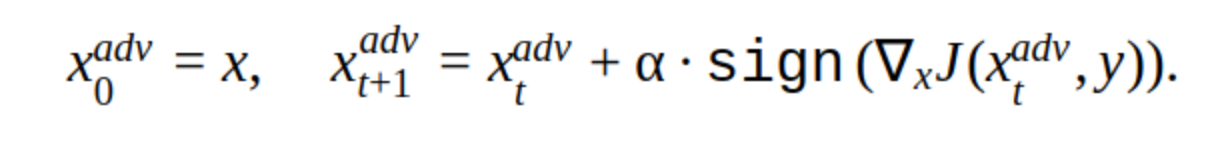
Il y a plusieurs modifications à cette méthode, mais l'idée de base est simple: l'image originale est décalée itérativement dans le sens du gradient de la perte de la fonction classifieur J (car seul le signe est utilisé) à l'étape α. «y» est la classe qui est représentée dans l'image pour réduire la confiance du réseau dans la bonne réponse. Une telle attaque est dite non ciblée. Vous pouvez choisir l'étape et le nombre d'itérations optimaux de sorte que le changement dans l'image d'entrée ne puisse pas être distingué de l'habituel pour une personne. Mais du point de vue des coûts de temps, une telle attaque ne nous convient pas. 5-10 itérations pour une image dans la prod, c'est long.
Une alternative aux méthodes itératives est la méthode FGSM.

Il s'agit d'une méthode unique, c'est-à-dire Pour l'utiliser, vous devez calculer une fois le gradient de la fonction de perte pour l'image d'entrée, et le bruit contradictoire est prêt à être ajouté à l'image. Cette méthode est évidemment plus productive. Il peut être utilisé en production.
Créer des exemples contradictoires
Nous avons décidé de commencer par pirater notre propre modèle.
C'est l'image qui réduit la probabilité de trouver une plaque d'immatriculation pour notre modèle.

Il est évident que cette méthode a un inconvénient: les changements qu'elle ajoute à l'image sont visibles à l'œil nu. Cette méthode n'est pas non plus ciblée, mais elle peut être modifiée pour effectuer une attaque dirigée. Ensuite, le modèle prédira l'emplacement de la plaque d'immatriculation à un autre endroit. Il s'agit de la méthode T-FGSM.
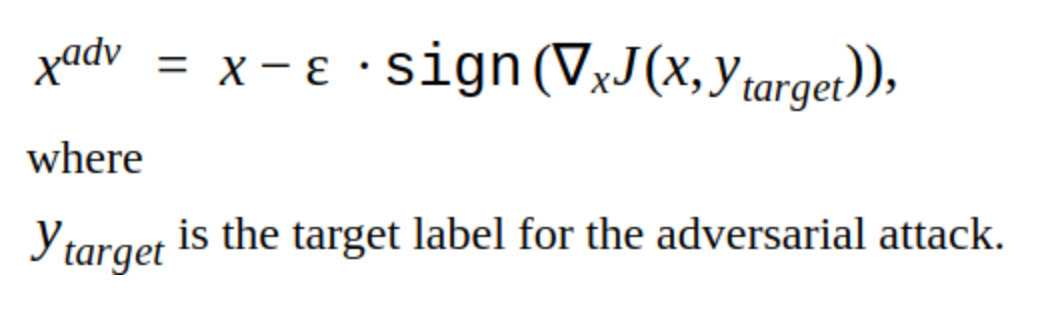
Afin de casser notre modèle avec cette méthode, vous devez changer l'image d'entrée un peu plus sensiblement.

Il n'est pas encore possible de dire que les résultats sont idéaux, mais au moins l'efficacité des méthodes a été vérifiée. Nous avons également essayé des bibliothèques prêtes à l'emploi pour le piratage des réseaux Foolbox, CleverHans et ART-IBM, mais avec leur aide, il n'a pas été possible de casser notre réseau pour la détection. Les méthodes qui y sont données sont meilleures pour les réseaux de classification. Il s'agit d'une tendance générale dans le piratage de réseau: il est plus difficile de rendre une attaque plus difficile pour la détection d'objets, en particulier lorsqu'il s'agit de modèles complexes, par exemple, Mask RCNN.
Test d'attaque
Tout ce qui a été décrit jusqu'à présent ne va pas au-delà de nos expériences internes, mais il est nécessaire de comprendre comment tester les attaques contre les détecteurs d'autres plateformes publicitaires.
Il s'avère que lors de la demande pour l'une des plates-formes, la plaque d'immatriculation est détectée automatiquement, vous pouvez donc télécharger des photos plusieurs fois et vérifier comment l'algorithme de détection fait face au nouvel exemple contradictoire.
C'est super! Mais ...
Aucune des attaques qui ont fonctionné sur notre modèle n'a fonctionné lors des tests sur une autre plate-forme. Pourquoi est-ce arrivé? Ceci est une conséquence des différences de modèles et de la façon dont les attaques faiblement contradictoires se généralisent à différentes architectures de réseau. En raison de la complexité de la reproduction des attaques, elles sont divisées en deux groupes: boîte blanche et boîte noire.

Ces attaques que nous avons faites sur notre modèle - c'était une boîte blanche. Nous avons besoin d'une boîte noire avec des restrictions supplémentaires sur l'inférence: il n'y a pas d'API, tout ce que vous pouvez faire est de télécharger manuellement des photos et de vérifier les attaques. S'il y avait une API, alors vous pourriez faire un modèle de remplacement.

L'idée est de créer un jeu de données d'images d'entrée et de réponses du modèle de boîte noire, sur lequel vous pouvez former plusieurs modèles d'architectures différentes, afin d'approximer le modèle de boîte noire. Ensuite, vous pouvez effectuer une attaque de boîte blanche sur ces modèles et ils sont plus susceptibles de fonctionner sur une boîte noire. Dans notre cas, cela implique beaucoup de travail manuel, donc cette option ne nous convenait pas.
Sortir de l'impasse
À la recherche d'ouvrages intéressants sur le thème des attaques de boîte noire, un article a été trouvé ShapeShifter: attaque physique robuste contre le détecteur d'objet R-CNN plus rapide
Les auteurs de l'article ont attaqué la détection d'objets d'un réseau de machines autonomes en ajoutant de manière itérative des images autres que la vraie classe à l'arrière-plan du panneau d'arrêt.


Une telle attaque est clairement visible à l'œil humain, cependant, elle brise avec succès le travail du réseau de détection d'objets, ce dont nous avons besoin. Par conséquent, nous avons décidé de négliger l'invisibilité souhaitée de l'attaque pour des raisons de capacité de travail.
Nous voulions vérifier combien le modèle de détection a été recyclé, utilise-t-il des informations sur la voiture ou est-ce seulement la plaque Avito qui est nécessaire?
Pour ce faire, créez l'image suivante:

Nous l'avons téléchargé en tant que machine sur une plate-forme publicitaire avec un modèle de boîte noire. Reçu:

Cela signifie que vous ne pouvez changer que la plaque Avito, le reste des informations dans l'image d'entrée n'est pas nécessaire pour la détection du modèle de boîte noire.
Après plusieurs tentatives, l'idée est venue d'ajouter à la plaque Avito un bruit contradictoire obtenu par la méthode FGSM, qui a cassé notre propre modèle, mais avec un coefficient ε assez important. Il s'est avéré comme ceci:

En voiture, ça ressemble à ça:

Nous avons téléchargé une photo sur la plateforme avec un modèle de boîte noire. Le résultat est réussi.

En appliquant cette méthode à plusieurs autres photos, nous avons découvert qu'elle ne fonctionne pas souvent. Puis, après plusieurs tentatives, nous avons décidé de nous concentrer sur l'autre partie la plus visible du problème - la frontière. On sait que les couches convolutives initiales du réseau ont des activations sur des objets simples comme des lignes, des angles. En «cassant» la frontière, nous pouvons empêcher le réseau de détecter correctement la zone du numéro. Cela peut être fait, par exemple, en ajoutant du bruit sous la forme de carrés blancs de taille aléatoire sur toute la bordure de la pièce.

En téléchargeant une telle image sur une plate-forme avec un modèle de boîte noire, nous avons obtenu un exemple contradictoire réussi.

Après avoir essayé cette approche sur un ensemble d'autres images, nous avons découvert que le modèle de boîte noire ne peut plus détecter la plaque Avito (l'ensemble a été assemblé manuellement, il y a moins d'une centaine de photos, et ce n'est bien sûr pas représentatif, mais cela prend beaucoup de temps pour en faire plus). Une observation intéressante: l'attaque n'est réussie qu'en combinant du bruit dans les lettres Avito et des carrés blancs aléatoires dans un cadre, l'utilisation de ces méthodes séparément ne donne pas un résultat réussi.
En conséquence, nous avons déployé cet algorithme dans la prod, et voici ce qui en est ressorti :)
Plusieurs annonces trouvées


Quelque chose de plus frais:
Nous sommes même entrés dans la plateforme publicitaire:
Total
En conséquence, nous avons réussi à lancer une attaque contradictoire qui, dans notre mise en œuvre, n'augmente pas le temps de traitement des images. Le temps que nous avons consacré à la création de l'attaque est de deux semaines avant le nouvel an. S'il n'avait pas été possible de le faire pendant cette période, ils auraient placé un filigrane. Désormais, la plaque d'immatriculation contradictoire est désactivée, car un concurrent appelle désormais les utilisateurs, leur propose de télécharger eux-mêmes des photos dans l'annonce ou de remplacer les photos de la voiture par des photos stockées sur Internet.