Bonjour, Habr! Je vous présente la traduction de l'article " Classification de la couverture terrestre avec eo-learn: Part 1 " par Matic Lubej.
2e partie
3e partie
Préface
Il y a environ six mois, la première validation a été effectuée dans le référentiel eo-learn sur GitHub. Aujourd'hui, eo-learn est devenu une merveilleuse bibliothèque open source, prête à être utilisée par toute personne intéressée par les données EO (Earth Observation - etc. trans.). Tout le monde dans l'équipe Sinergise attendait le moment de la transition de l'étape de construction des outils nécessaires à l'étape de leur utilisation pour l'apprentissage automatique. Il est temps de vous présenter une série d'articles concernant la classification de la couverture terrestre à l'aide d' eo-learn
eo-learn est une bibliothèque Python open source qui agit comme un pont reliant l'observation de la Terre / télédétection à l'écosystème des bibliothèques d'apprentissage automatique Python. Nous avons déjà écrit un article séparé sur notre blog , que nous vous recommandons de vous familiariser avec. La bibliothèque utilise des primitives des bibliothèques numpy et numpy pour stocker et manipuler les données des satellites. Pour le moment, il est disponible dans le référentiel GitHub , et la documentation est disponible sur le lien approprié vers ReadTheDocs .

Image satellite Sentinel-2 et masque NDVI d'une petite zone en Slovénie en hiver
Pour démontrer les capacités de l' eo-learn , nous avons décidé d'utiliser notre convoyeur multi-temporel pour classer la couverture du territoire de la République de Slovénie (le pays où nous vivons), en utilisant les données de 2017. La procédure complète pouvant être trop compliquée pour un article, nous avons décidé de la diviser en trois parties. Grâce à cela, il n'est pas nécessaire de sauter les étapes et de passer immédiatement à l'apprentissage automatique - nous devons d'abord comprendre vraiment les données avec lesquelles nous travaillons. Chaque article sera accompagné d'un exemple de cahier Jupyter. De plus, pour les personnes intéressées, nous avons déjà préparé un exemple complet couvrant toutes les étapes.
- Dans le premier article, nous vous guiderons à travers la procédure de sélection / division d'une zone d'intérêt (ci-après - AOI, zone d'intérêt) et l'obtention des informations nécessaires, telles que les données des capteurs satellites et des masques de nuages. Nous montrons également un exemple de la façon de créer un masque raster de données sur la couverture réelle d'un territoire à partir de données vectorielles. Toutes ces étapes sont nécessaires pour obtenir un résultat fiable.
- Dans la deuxième partie, nous plongons tête baissée dans la préparation des données pour la procédure d'apprentissage automatique. Ce processus comprend le prélèvement d'échantillons aléatoires pour la formation \ la validation des pixels, la suppression d'images de nuages, l'interpolation de données temporelles pour remplir des «trous», etc.
- Dans la troisième partie, nous considérerons la formation et la validation du classificateur, ainsi que, bien sûr, de beaux graphismes!

Image satellite Sentinel-2 et masque NDVI d'une petite zone en Slovénie en été
Zone d'intérêt? Choisissez!
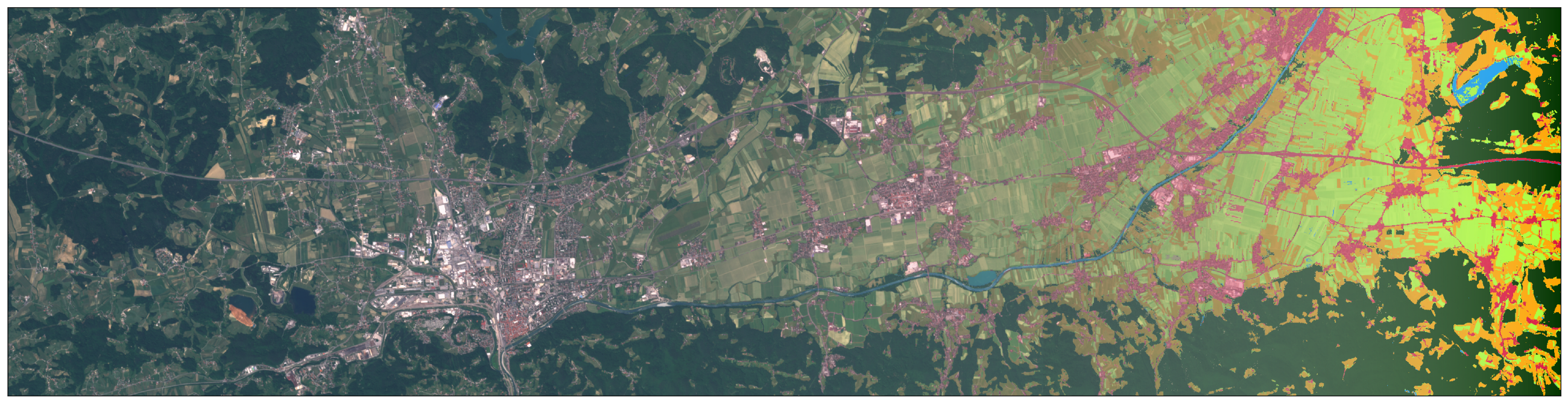
La bibliothèque eo-learn vous permet de diviser AOI en petits fragments qui peuvent être traités dans des conditions de ressources informatiques limitées. Dans cet exemple, la frontière slovène a été prise de la Terre naturelle , cependant, vous pouvez sélectionner une zone de n'importe quelle taille. Nous avons également ajouté un tampon à la frontière, après quoi la dimension AOI était d'environ 250x170 km. En utilisant la magie des geopandas et des bibliothèques geopandas , nous avons créé un outil pour briser l'AOI. Dans ce cas, nous avons divisé le territoire en 25x17 carrés de la même taille, à la suite de quoi nous avons reçu ~ 300 fragments de 1000x1000 pixels, dans une résolution de 10m. La décision de diviser en fragments est prise en fonction de la puissance de calcul disponible. À la suite de cette étape, nous obtenons une liste de carrés couvrant l'AOI.

AOI (territoire de la Slovénie) est divisé en petits carrés d'une taille d'environ 1000x1000 pixels dans une résolution de 10m.
Réception de données des satellites Sentinel
Après avoir déterminé les carrés, eo-learn vous permet de télécharger automatiquement les données des satellites Sentinel. Dans cet exemple, nous obtenons toutes les images Sentinel-2 L1C qui ont été prises en 2017. Il convient de noter que les produits Sentinel-2 L2A, ainsi que des sources de données supplémentaires (Landsat-8, Sentinel-1) peuvent être ajoutés au pipeline de la même manière. Il convient également de noter que l'utilisation de produits L2A peut améliorer les résultats de classification, mais nous avons décidé d'utiliser L1C pour la polyvalence de la solution. Cela a été fait en utilisant sentinelhub-py , une bibliothèque qui fonctionne comme un wrapper sur les services Sentinel-Hub. L'utilisation de ces services est gratuite pour les instituts de recherche et les start-ups, mais dans d'autres cas, il est nécessaire de s'abonner.

Images en couleur d'un fragment à différents jours. Certaines images sont nuageuses, ce qui signifie qu'un détecteur de nuages est nécessaire.
En plus des données Sentinel, eo-learn vous permet d'accéder en toute transparence au cloud et aux données de probabilité de cloud grâce à la bibliothèque s2cloudless . Cette bibliothèque fournit des outils pour détecter automatiquement les nuages pixel par pixel . Les détails peuvent être lus ici .
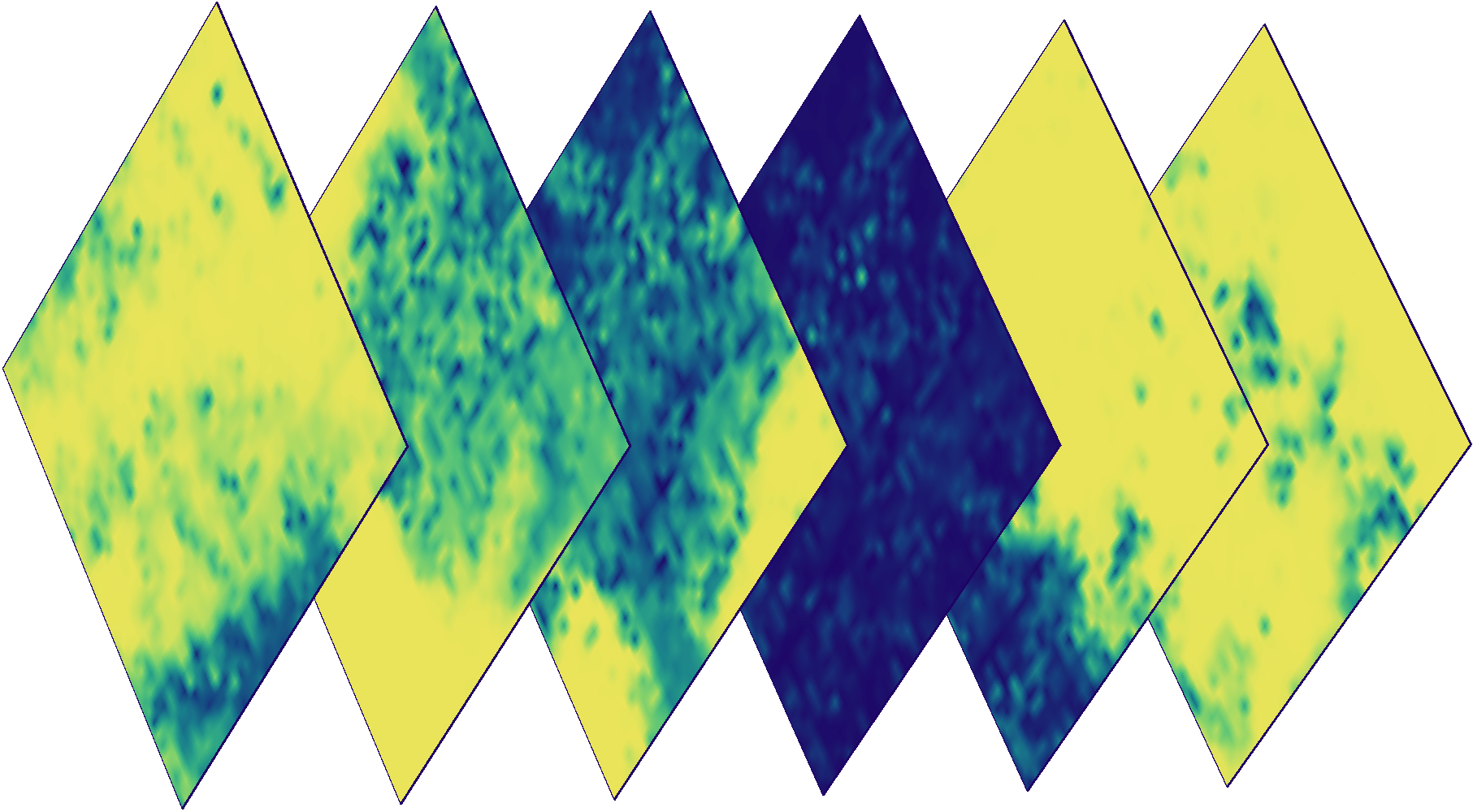
Masques de nuage pour les images ci-dessus. La couleur indique la probabilité de trouble d'un pixel spécifique (bleu - faible probabilité, jaune - élevé).
Ajout de données réelles
Enseigner avec un enseignant nécessite une carte avec des données réelles ou de la vérité . Le dernier terme ne doit pas être pris à la lettre, car en réalité, les données ne sont qu'une approximation de ce qui est en surface. Malheureusement, le comportement du classificateur dépend fortement de la qualité de cette carte ( cependant, comme pour la plupart des autres tâches de l'apprentissage automatique ). Les cartes étiquetées sont le plus souvent disponibles sous forme de données vectorielles au format shapefile (par exemple, fournies par l'État ou la communauté ). eo-learn contient des outils pour rasteriser des données vectorielles sous la forme d'un masque raster.

Processus de pixellisation des données en masques à l'aide de l'exemple d'un carré. Les polygones dans un fichier vectoriel sont affichés sur l'image de gauche, les masques raster pour chaque étiquette sont affichés au milieu - les couleurs noir et blanc indiquent la présence et l'absence d'un attribut spécifique, respectivement. L'image de droite montre un masque raster combiné dans lequel différentes couleurs indiquent différentes étiquettes.
Tout mettre ensemble
Toutes ces tâches se comportent comme des blocs de construction qui peuvent être combinés en une séquence pratique d'actions exécutées pour chaque carré. En raison du nombre potentiellement extrêmement élevé de tels fragments, l'automatisation du pipeline est absolument nécessaire
Apprendre à connaître les données réelles est la première étape du travail avec des tâches de ce type. À l'aide de masques de nuages associés à des données de Sentinel-2, vous pouvez déterminer le nombre d'observations de qualité de tous les pixels, ainsi que la probabilité moyenne de nuages dans une zone particulière. Grâce à cela, vous pouvez mieux comprendre les données existantes et les utiliser lors du débogage d'autres problèmes.

Image en couleur (à gauche), masque du nombre de mesures de qualité pour 2017 (au centre) et probabilité moyenne de couverture nuageuse pour 2017 (à droite) pour un fragment aléatoire d'AOI.
Quelqu'un pourrait être intéressé par le NDVI moyen pour une zone arbitraire, ignorant les nuages. À l'aide de masques de nuage, vous pouvez calculer la valeur moyenne de n'importe quelle entité, en ignorant les pixels sans données. Ainsi, grâce aux masques, nous pouvons effacer les images du bruit pour presque toutes les fonctionnalités de nos données.
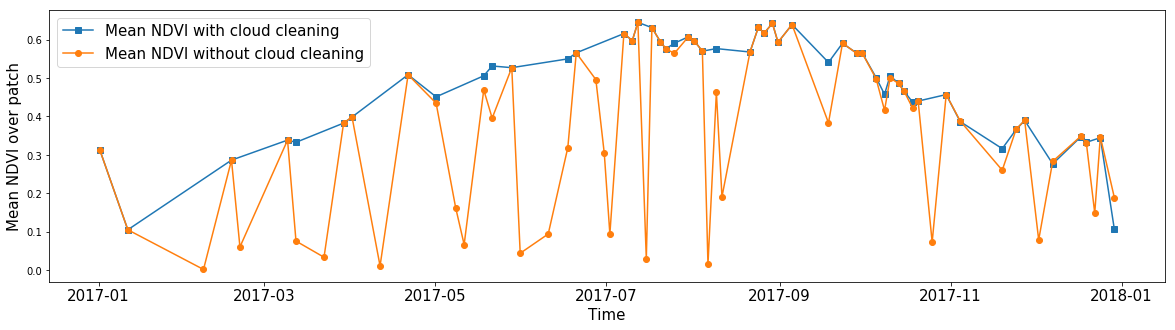
NDVI moyen de tous les pixels d'un fragment AOI aléatoire tout au long de l'année. La ligne bleue montre le résultat du calcul obtenu en ignorant les valeurs à l'intérieur des nuages. La ligne orange indique la valeur moyenne lorsque tous les pixels sont pris en compte.
"Mais qu'en est-il de la mise à l'échelle?"
Après avoir installé notre convoyeur en utilisant un exemple d'un fragment, tout ce qui reste à faire est de démarrer automatiquement une procédure similaire pour tous les fragments (en parallèle, si les ressources le permettent), pendant que vous vous détendez avec une tasse de café et pensez à la taille du patron qui sera agréablement surpris les résultats de votre travail. Après la fin du pipeline, vous pouvez exporter les données qui vous intéressent dans une seule image au format GeoTIFF. Le script gdal_merge.py reçoit les images et les combine, résultant en une image qui couvre tout le pays.
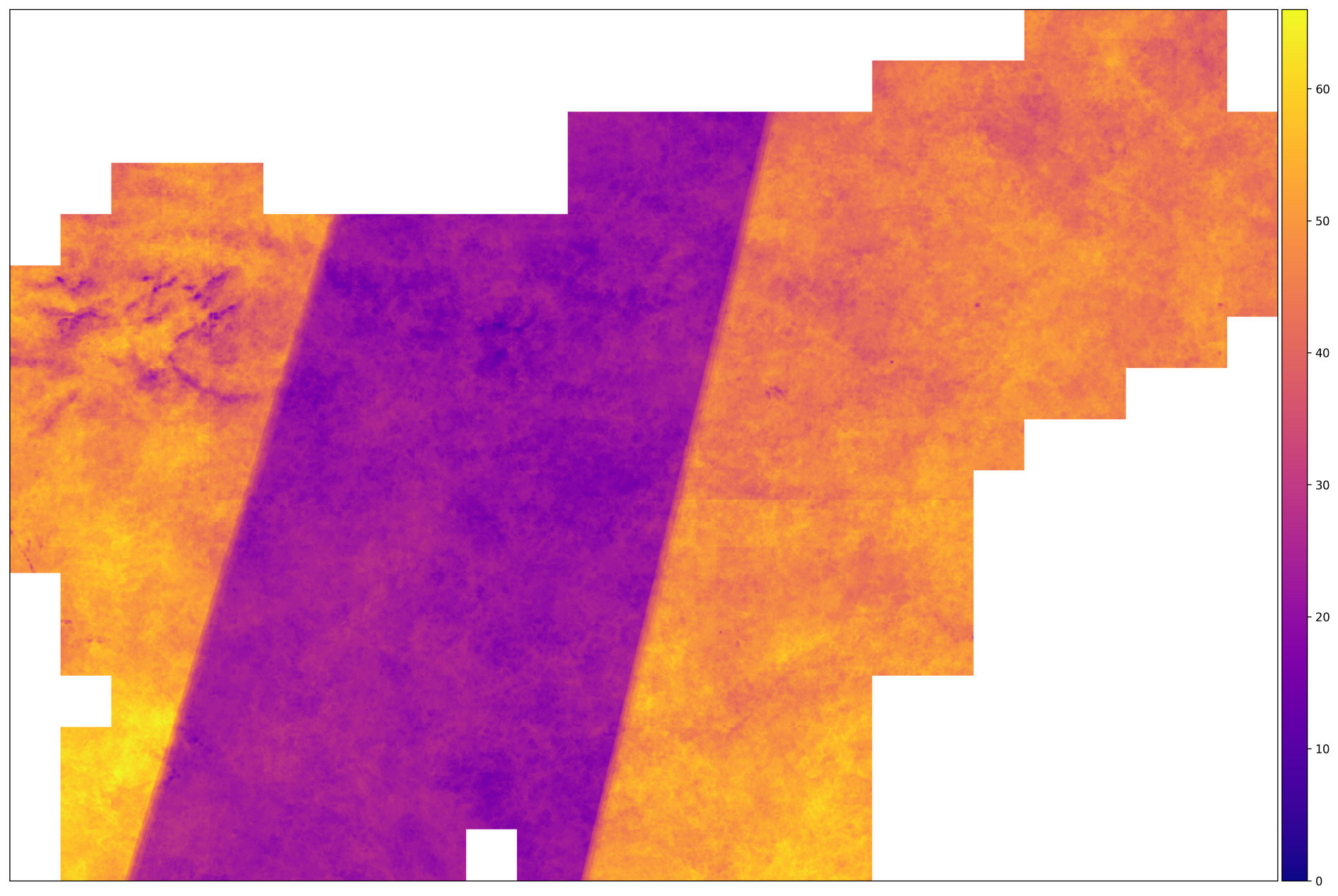
Le nombre de coups corrects pour AOI en 2017. Des régions avec un grand nombre d'images sont situées sur le territoire où se croisent la trajectoire des satellites Sentinel-2A et Sentinel-2B. Au milieu de cela ne se produit pas.
À partir de l'image ci-dessus, nous pouvons conclure que les données d'entrée sont hétérogènes - pour certains fragments, le nombre d'images est deux fois plus élevé que pour d'autres. Cela signifie que nous devons prendre des mesures pour normaliser les données - telles que l'interpolation le long de l'axe du temps.
L'exécution du pipeline spécifié prend environ 140 secondes pour un fragment, ce qui donne au total ~ 12 heures lors du démarrage du processus tout au long de la zone d'intérêt. La plupart du temps, il s'agit de télécharger des données satellite. Le fragment non compressé moyen avec la configuration décrite prend environ 3 Go, ce qui donne au total ~ 1 To d'espace pour l'ensemble de l'AOI.
Exemple dans un cahier Jupyter
Pour une introduction plus simple au code eo-learn , nous avons préparé un exemple couvrant les sujets abordés dans cet article. L'exemple est conçu comme un bloc-notes Jupyter, et vous pouvez le trouver dans le répertoire d' exemples du package eo-learn .