Chaque jour, des dizaines de milliers d'employés de plusieurs milliers d'organisations à travers le monde travaillent chez Pyrus. Nous considérons la réactivité du service (la rapidité de traitement des demandes) comme un avantage concurrentiel important, car il affecte directement l'expérience utilisateur. La mesure clé pour nous est le «pourcentage de requêtes lentes». En étudiant son comportement, nous avons remarqué qu'une fois par minute sur les serveurs d'applications, il y a des pauses d'environ 1000 ms. À ces intervalles, le serveur ne répond pas et une file d'attente de plusieurs dizaines de requêtes apparaît. La recherche des causes et l'élimination des goulots d'étranglement provoqués par la collecte des ordures dans l'application sera discutée dans cet article.

Les langages de programmation modernes peuvent être divisés en deux groupes. Dans des langages comme C / C ++ ou Rust, la gestion manuelle de la mémoire est utilisée, donc les programmeurs passent plus de temps à écrire du code, à gérer la durée de vie des objets, puis à déboguer. Dans le même temps, les bogues dus à une mauvaise utilisation de la mémoire sont parmi les plus difficiles à déboguer, de sorte que la plupart des développements modernes sont effectués dans des langages avec gestion automatique de la mémoire. Ceux-ci incluent, par exemple, Java, C #, Python, Ruby, Go, PHP, JavaScript, etc. Les programmeurs économisent du temps de développement, mais vous devez payer le temps d'exécution supplémentaire que le programme consacre régulièrement à la récupération de place - libérant ainsi de la mémoire occupée par des objets vers lesquels il n'y a plus de lien dans le programme. Dans les petits programmes, ce temps est négligeable, mais à mesure que le nombre d'objets augmente et l'intensité de leur création, la récupération de place commence à apporter une contribution notable au temps d'exécution total du programme.
Les serveurs Web Pyrus fonctionnent sur la plate-forme .NET, qui utilise la gestion automatique de la mémoire. La plupart des collectes d'ordures sont `` arrêter le monde '', c'est-à-dire au moment de leur travail, ils arrêtent tous les threads de l'application. Les assemblys non bloquants (en arrière-plan) arrêtent également tous les threads, mais pendant une très courte période. Pendant le blocage des threads, le serveur ne traite pas les demandes, les demandes existantes se bloquent, de nouvelles sont ajoutées à la file d'attente. Par conséquent, les demandes qui ont été traitées au moment de la récupération de place sont directement ralenties et les demandes sont traitées plus lentement immédiatement après la fin de la récupération de place en raison des files d'attente accumulées. Cela aggrave la métrique «pourcentage de requêtes lentes».
Armés du livre
Konrad Kokosa: Pro .NET Memory Management récemment publié (sur la façon dont nous avons apporté son premier exemplaire en Russie en 2 jours, vous pouvez écrire un article séparé), entièrement consacré au sujet de la gestion de la mémoire dans .NET, nous avons commencé à étudier le problème.
Mesure
Pour profiler le serveur Web Pyrus, nous avons utilisé l'utilitaire PerfView (
https://github.com/Microsoft/perfview ), optimisé pour le profilage des applications .NET. L'utilitaire est basé sur le moteur ETW (Event Tracing for Windows) et a un impact minimal sur les performances de l'application profilée, ce qui lui permet d'être utilisé sur un serveur de combat. De plus, l'impact sur les performances dépend des types d'événements et des informations que nous collectons. Nous ne collectons rien - l'application fonctionne comme d'habitude. De plus, PerfView ne nécessite ni recompilation ni redémarrage de l'application.
Exécutez la trace PerfView avec le paramètre / GCCollectOnly (temps de trace 1,5 heures). Dans ce mode, il collecte uniquement les événements de récupération de place et a un impact minimal sur les performances. Examinons le rapport de trace Memory Group / GCStats, et un résumé des événements du garbage collector:
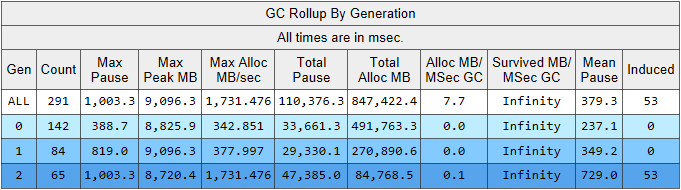
Ici, nous voyons plusieurs indicateurs intéressants à la fois:
- Le temps de pause de construction moyen dans la 2e génération est de 700 millisecondes et la pause maximale est d'environ une seconde. Cette figure montre l'heure à laquelle tous les threads de l'application .NET s'arrêtent, en particulier, cette pause sera ajoutée à toutes les demandes traitées.
- Le nombre d'assemblages de la 2ème génération est comparable à la 1ère génération et est légèrement inférieur au nombre d'assemblages de la 0ème génération.
- La colonne Induite répertorie 53 assemblages de la 2e génération. L'assemblage induit est le résultat d'un appel explicite à GC.Collect (). Dans notre code, nous n'avons trouvé aucun appel à cette méthode, ce qui signifie que certaines des bibliothèques utilisées par notre application sont à blâmer.
Expliquons l'observation sur le nombre de ramasse-miettes. L'idée de diviser les objets par leur durée de vie repose sur l'
hypothèse générationnelle : une partie importante des objets créés meurt rapidement, et la plupart des autres vivent longtemps (en d'autres termes, peu d'objets avec une durée de vie «moyenne»). C'est sous ce mode que le garbage collector .NET est emprisonné, et dans ce mode, les assemblys de deuxième génération doivent être beaucoup plus petits que la génération 0. Autrement dit, pour le fonctionnement optimal du ramasse-miettes, nous devons adapter le travail de notre application à l'hypothèse générationnelle. Formulons la règle comme suit: les objets doivent soit mourir rapidement, sans survivre à l'ancienne génération, soit y vivre et y vivre éternellement. Cette règle s'applique également à d'autres plates-formes qui utilisent la gestion automatique de la mémoire avec séparation générationnelle, comme Java.
Les données qui nous intéressent peuvent être extraites d'un autre tableau du rapport GCStats:

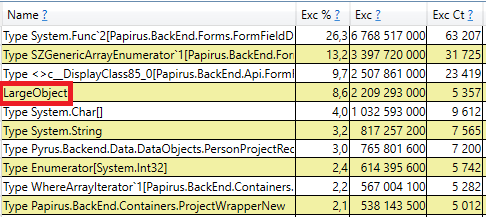
Voici quelques cas où une application essaie de créer un grand objet (dans les objets .NET Framework d'une taille> 85 000 octets sont créés dans le LOH - Large Object Heap), et elle doit attendre la fin de l'assemblage de 2e génération, qui se produit en parallèle en arrière-plan. Ces pauses de l'allocateur ne sont pas aussi critiques que les pauses du garbage collector, car elles n'affectent qu'un seul thread. Avant cela, nous utilisions le .NET Framework version 4.6.1, et dans la version 4.7.1 Microsoft a finalisé le garbage collector, maintenant il vous permet d'allouer de la mémoire dans le grand tas d'objets lors de la génération en arrière-plan de la 2e génération:
https://docs.microsoft.com / ru-ru / dotnet / framework / whats-new / # common-language-runtime-clrPar conséquent, nous avons effectué la mise à niveau vers la dernière version 4.7.2 à ce moment-là.
Constructions de 2e génération
Pourquoi avons-nous autant de versions de l'ancienne génération? La première hypothèse est que nous avons une fuite de mémoire. Pour tester cette hypothèse, regardons la taille de la deuxième génération (nous avons mis en place une surveillance des compteurs de performances correspondants dans Zabbix). À partir des graphiques de la taille de 2e génération pour 2 serveurs Pyrus, on peut voir que sa taille augmente d'abord (principalement en raison du remplissage des caches), puis se stabilise (gros échecs sur le graphique - redémarrage régulier du service web pour mettre à jour la version):
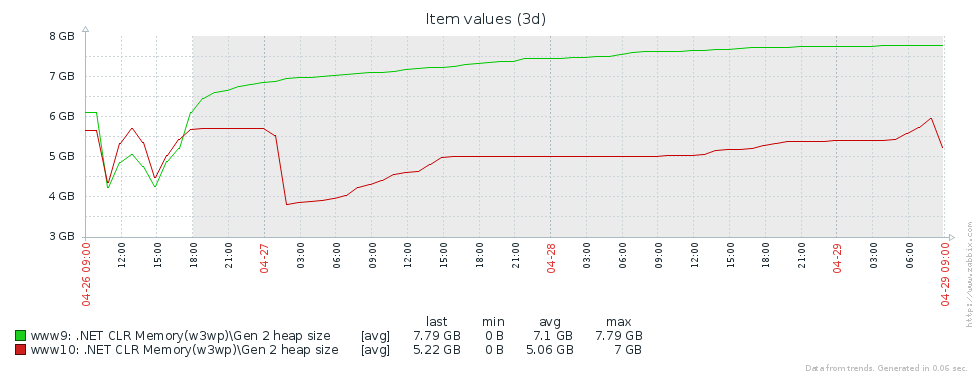
Cela signifie qu'il n'y a aucune fuite de mémoire notable, c'est-à-dire qu'un grand nombre d'assemblages de 2e génération se produisent pour une autre raison. L'hypothèse suivante est qu'il y a beaucoup de trafic mémoire, c'est-à-dire que de nombreux objets tombent dans la 2e génération et que de nombreux objets y meurent. PerfView dispose d'un mode / GCOnly pour rechercher de tels objets. À partir des rapports de trace, prêtons attention aux piles `` Décès d'objets de deuxième génération (échantillonnage grossier) '', qui contiennent une sélection d'objets qui meurent à la 2e génération, ainsi que des piles d'appels des endroits où ces objets ont été créés. Ici, nous voyons les résultats suivants:
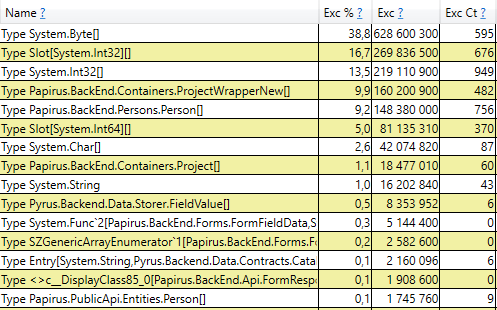
Après avoir ouvert la ligne, à l'intérieur, nous voyons une pile d'appels de ces endroits dans le code qui créent des objets à la hauteur de la 2e génération. Parmi eux:
- System.Byte [] Si vous regardez à l'intérieur, nous verrons que plus de la moitié sont des tampons pour la sérialisation en JSON:
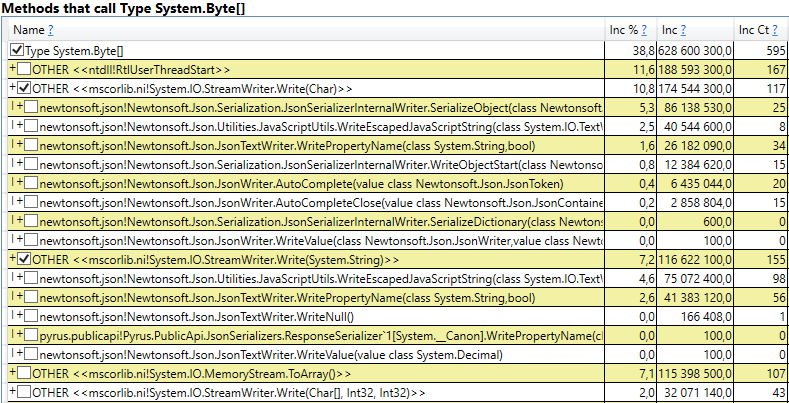
- Slot [System.Int32] [] (cela fait partie de l'implémentation de HashSet), System.Int32 [], etc. Voici notre code qui calcule les caches clients - les répertoires, formulaires, listes, amis, etc. que cet utilisateur voit et qui sont mis en cache dans son navigateur ou son application mobile:

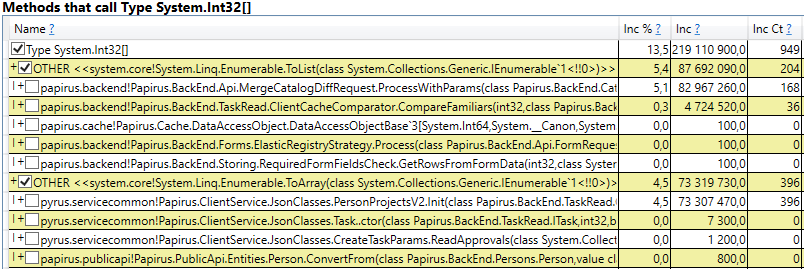
Fait intéressant, les tampons pour JSON et pour les caches de clients informatiques sont tous des objets temporaires qui vivent sur la même demande. Pourquoi vivent-ils jusqu'à la 2e génération? Notez que tous ces objets sont des tableaux d'une taille assez grande. Et à une taille> 85000 octets, la mémoire pour eux est allouée dans le grand tas d'objets, qui n'est collecté qu'avec la 2e génération.
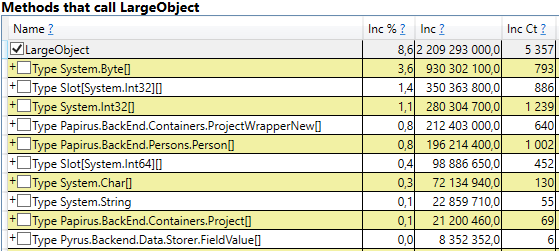
Pour vérifier, ouvrez la section «Piles GC Heap Alloc Ignore Free (Coarse Sampling) stacks» dans les résultats perfview / GCOnly. Là, nous voyons la ligne LargeObject, dans laquelle PerfView regroupe la création de gros objets, et à l'intérieur, nous voyons tous les mêmes tableaux que nous avons vu dans l'analyse précédente. Nous reconnaissons la cause première des problèmes avec le ramasse-miettes: nous créons de nombreux objets volumineux temporaires.
Changements dans le système Pyrus
Sur la base des résultats de mesure, nous avons identifié les principaux domaines de travaux ultérieurs: la lutte contre les gros objets lors du calcul des caches clients et de la sérialisation en JSON. Il existe plusieurs solutions à ce problème:
- Le plus simple est de ne pas créer de gros objets. Par exemple, si un grand tampon B est utilisé dans les transformations de données séquentielles A-> B-> C, alors parfois ces transformations peuvent être combinées en les transformant en A-> C et en éliminant la création de l'objet B. Cette option n'est pas toujours applicable, mais elle le plus simple et le plus efficace.
- Piscine d'objets. Au lieu de créer constamment de nouveaux objets et de les jeter, de charger le garbage collector, nous pouvons stocker une collection d'objets gratuits. Dans le cas le plus simple, lorsque nous avons besoin d'un nouvel objet, nous le prenons dans le pool ou en créons un nouveau si le pool est vide. Lorsque nous n'avons plus besoin de l'objet, nous le renvoyons à la piscine. Un bon exemple est ArrayPool dans .NET Core, qui est également disponible dans le .NET Framework dans le cadre du package System.Buffers Nuget.
- Utilisez de petits objets au lieu de gros.
Considérons séparément les deux cas d'objets volumineux - calcul des caches clients et sérialisation en JSON.
Calcul du cache client
Le client Web et les applications mobiles Pyrus mettent en cache les données disponibles pour l'utilisateur (projets, formulaires, utilisateurs, etc.) La mise en cache est utilisée pour accélérer le travail, elle est également nécessaire pour travailler en mode hors ligne. Les caches sont calculés sur le serveur et transférés au client. Ils sont individuels pour chaque utilisateur, car ils dépendent de leurs droits d'accès, et sont souvent mis à jour, par exemple, lors du changement de répertoires auxquels il a accès.
Ainsi, de nombreux calculs de cache client sont régulièrement effectués sur le serveur et de nombreux objets temporaires de courte durée sont créés. Si l'utilisateur est une grande organisation, il peut accéder à de nombreux objets, respectivement, les caches clients pour lui seront volumineux. C'est pourquoi nous avons vu l'allocation de mémoire pour les grands tableaux temporaires dans le grand tas d'objets.
Analysons les options proposées pour se débarrasser de la création de gros objets:
- Élimination complète des gros objets. Cette approche n'est pas applicable, car les algorithmes de préparation des données utilisent, entre autres, le tri et l'union des ensembles, et ils nécessitent des tampons temporaires.
- Utilisation d'un pool d'objets. Cette approche présente des difficultés:
- La variété des collections utilisées et les types d'éléments qu'elles contiennent: HashSet, List et Array sont utilisés (les 2 derniers peuvent être combinés). Int32, Int64, ainsi que toutes sortes de classes de données sont stockées dans des collections. Pour chaque type utilisé, vous aurez besoin de votre propre pool, qui stockera également des collections de différentes tailles.
- Durée de vie difficile des collections. Pour bénéficier de la piscine, les objets qu'elle contient devront être restitués après utilisation. Cela peut être fait si l'objet est utilisé dans une méthode. Mais dans notre cas, la situation est plus compliquée, car de nombreux objets volumineux voyagent entre les méthodes, sont placés dans des structures de données, sont transférés vers d'autres structures, etc.
- Mise en œuvre. Il y a ArrayPool de Microsoft, mais nous avons toujours besoin de List et HashSet. Nous n'avons trouvé aucune bibliothèque appropriée, nous devions donc implémenter les classes nous-mêmes.
- Utilisation de petits objets. Un grand tableau peut être divisé en plusieurs petits morceaux, que je ne chargerai pas le grand tas d'objets, mais sera créé à la 0e génération, puis suivra le chemin standard dans la 1ère et la 2ème. Nous espérons qu'ils ne seront pas à la hauteur de la 2e, mais seront récupérés par le ramasse-miettes au 0e, ou dans les cas extrêmes à la 1re génération. L'avantage de cette approche est que les modifications apportées au code existant sont minimes. Difficultés:
- Mise en œuvre. Nous n'avons trouvé aucune bibliothèque appropriée, nous devions donc écrire les classes nous-mêmes. Le manque de bibliothèques est compréhensible, car le scénario «collections qui ne chargent pas le tas d'objets volumineux» est d'une portée très étroite.
Nous avons décidé d'aller sur le 3ème chemin et d'
inventer notre vélo pour écrire List et HashSet, qui ne chargent pas le Large Object Heap.
Liste des pièces
Notre ChunkedList <T> implémente des interfaces standard, y compris IList <T>, qui nécessite des modifications minimes du code existant. Oui, et la bibliothèque Newtonsoft.Json que nous utilisons est automatiquement en mesure de la sérialiser, car elle implémente IEnumerable <T>:
public sealed class ChunkedList<T> : IList<T>, ICollection<T>, IEnumerable<T>, IEnumerable, IList, ICollection, IReadOnlyList<T>, IReadOnlyCollection<T> {
La liste standard <T> a les champs suivants: tableau pour les éléments et le nombre d'éléments remplis. Dans ChunkedList <T>, il y a un tableau de tableaux d'éléments, le nombre de tableaux complètement remplis, le nombre d'éléments dans le dernier tableau. Chacun des tableaux d'éléments de moins de 85 000 octets:

private T[][] chunks; private int currentChunk; private int currentChunkSize;
Comme la ChunkedList <T> est plutôt compliquée, nous avons écrit des tests détaillés dessus. Toute opération doit être testée dans au moins 2 modes: en "petit" lorsque la liste entière tient en une seule pièce jusqu'à 85 000 octets, et en "grande" lorsqu'elle se compose de plusieurs pièces. De plus, pour les méthodes qui changent la taille (par exemple, Ajouter), les scénarios sont encore plus grands: "petit" -> "petit", "petit" -> "grand", "grand" -> "grand", "grand" -> " petit. " Il y a ici quelques cas limites confus que les tests unitaires réussissent bien.
La situation est simplifiée par le fait que certaines des méthodes de l'interface IList ne sont pas utilisées et peuvent être omises (telles que Insert, Remove). Leur mise en œuvre et leurs tests seraient assez lourds. De plus, l'écriture de tests unitaires est simplifiée par le fait que nous n'avons pas besoin de proposer de nouvelles fonctionnalités, ChunkedList <T> devrait se comporter de la même manière que List <T>. Autrement dit, tous les tests sont organisés comme suit: créez une liste <T> et ChunkedList <T>, effectuez les mêmes opérations sur eux et comparez les résultats.
Nous avons mesuré les performances à l'aide de la bibliothèque BenchmarkDotNet pour nous assurer que nous n'avons pas beaucoup ralenti notre code lors du passage de List <T> à ChunkedList <T>. Testons, par exemple, l'ajout d'éléments à la liste:
[Benchmark] public ChunkedList<int> ChunkedList() { var list = new ChunkedList<int>(); for (int i = 0; i < N; i++) list.Add(i); return list; }
Et le même test en utilisant List <T> pour comparaison. Résultats lors de l'ajout de 500 éléments (tout tient dans un seul tableau):
Résultats lors de l'ajout de 50 000 éléments (répartis en plusieurs tableaux):
Description détaillée des colonnes dans les résultats BenchmarkDotNet=v0.11.4, OS=Windows 10.0.17763.379 (1809/October2018Update/Redstone5) Intel Core i7-8700K CPU 3.70GHz (Coffee Lake), 1 CPU, 12 logical and 6 physical cores [Host] : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0 DefaultJob : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0
Si vous regardez la colonne "Moyenne", qui affiche le temps d'exécution moyen des tests, vous pouvez voir que notre implémentation n'est que 2 à 2,5 fois plus lente que la norme. Étant donné que dans le code réel, les opérations avec des listes ne sont qu'une petite partie de toutes les actions effectuées, cette différence devient insignifiante. Mais la colonne `` Gen 2 / 1k op '' (le nombre d'assemblages de la 2e génération pour 1000 tests) montre que nous avons atteint l'objectif: avec un grand nombre d'éléments, ChunkedList ne crée pas de déchets dans la 2e génération, ce qui était notre tâche.
Ensemble de pièces
De même, ChunkedHashSet <T> implémente l'interface ISet <T>. Lors de l'écriture du ChunkedHashSet <T>, nous avons réutilisé la logique des petits morceaux déjà implémentée dans la ChunkedList. Pour ce faire, nous avons pris une implémentation prête à l'emploi de HashSet <T> à partir de la source de référence .NET, disponible sous la licence MIT, et remplacé les tableaux par ChunkedLists.
Dans les tests unitaires, nous utilisons également la même astuce que pour les listes: nous comparerons le comportement de ChunkedHashSet <T> avec la référence HashSet <T>.
Enfin, des tests de performances. L'opération principale que nous utilisons est l'union des ensembles, c'est pourquoi nous la testons:
public ChunkedHashSet<int> ChunkedHashSet(int[][] source) { var set = new ChunkedHashSet<int>(); foreach (var arr in source) set.UnionWith(arr); return set; }
Et exactement le même test pour le HashSet standard. Premier test pour les petits ensembles:
var source = new int[][] { Enumerable.Range(0, 300).ToArray(), Enumerable.Range(100, 600).ToArray(), Enumerable.Range(300, 1000).ToArray(), }
Le deuxième test pour les grands ensembles qui a causé un problème avec un tas de gros objets:
var source = new int[][] { Enumerable.Range(0, 30000).ToArray(), Enumerable.Range(10000, 60000).ToArray(), Enumerable.Range(30000, 100000).ToArray(), }
Les résultats sont similaires aux listes. ChunkedHashSet est plus lent de 2 à 2,5 fois, mais en même temps sur les grands ensembles, il charge moins les ordres de grandeur de 2e génération 2.
Sérialisation en JSON
Le serveur Web Pyrus fournit plusieurs API qui utilisent une sérialisation différente. Nous avons découvert la création de gros objets dans l'API utilisée par les bots et l'utilitaire de synchronisation (ci-après dénommée API publique). Notez que l'API utilise essentiellement sa propre sérialisation, qui n'est pas affectée par ce problème. Nous avons écrit à ce sujet dans l'article
https://habr.com/en/post/227595/ , dans la section "2. Vous ne savez pas où se trouve le goulot d'étranglement de votre application. " Autrement dit, l'API principale fonctionne déjà bien et le problème est apparu dans l'API publique à mesure que le nombre de demandes et la quantité de données dans les réponses augmentaient.
Optimisons l'API publique. En utilisant l'exemple de l'API principale, nous savons que vous pouvez renvoyer une réponse à l'utilisateur en mode streaming. Autrement dit, vous n'avez pas besoin de créer de tampons intermédiaires contenant la réponse entière, mais écrivez la réponse immédiatement dans le flux.
En y regardant de plus près, nous avons découvert que lors du processus de sérialisation de la réponse, nous créons un tampon temporaire pour le résultat intermédiaire (le «contenu» est un tableau d'octets contenant du JSON dans le codage UTF-8):
var serializer = Newtonsoft.Json.JsonSerializer.Create(...); byte[] content; var sw = new StreamWriter(new MemoryStream(), new UTF8Encoding(false)); using (var writer = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(writer, result); writer.Flush(); content = ms.ToArray(); }
Voyons où le contenu est utilisé. Pour des raisons historiques, l'API publique est basée sur WCF, pour lequel XML est le format de demande et de réponse standard. Dans notre cas, la réponse XML a un seul élément «binaire», à l'intérieur duquel est écrit JSON encodé en Base64:
public class RawBodyWriter : BodyWriter { private readonly byte[] _content; public RawBodyWriter(byte[] content) : base(true) { _content = content; } protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { writer.WriteStartElement("Binary"); writer.WriteBase64(_content, 0, _content.Length); writer.WriteEndElement(); } }
Notez qu'un tampon temporaire n'est pas nécessaire ici. JSON peut être écrit immédiatement dans le tampon XmlWriter que WCF nous fournit, en le codant en Base64 à la volée. Ainsi, nous emprunterons la première voie en nous débarrassant de l'allocation de mémoire:
protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { var serializer = Newtonsoft.Json.JsonSerializer.Create(...); writer.WriteStartElement("Binary"); Stream stream = new Base64Writer(writer); Var sw = new StreamWriter(stream, new UTF8Encoding(false)); using (var jsonWriter = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(jsonWriter, _result); jsonWriter.Flush(); } writer.WriteEndElement(); }
Ici, Base64Writer est un simple wrapper sur XmlWriter qui implémente l'interface Stream, qui écrit dans XmlWriter en Base64. En même temps, à partir de toute l'interface, il suffit d'implémenter une seule méthode Write, qui est appelée dans StreamWriter:
public class Base64Writer : Stream { private readonly XmlWriter _writer; public Base64Writer(XmlWriter writer) { _writer = writer; } public override void Write(byte[] buffer, int offset, int count) { _writer.WriteBase64(buffer, offset, count); } <...> }
Gc induit
Essayons de faire face aux mystérieuses collectes de déchets induites. Nous avons revérifié notre code 10 fois pour les appels GC.Collect, mais cela a échoué. J'ai réussi à intercepter ces événements dans PerfView, mais la pile d'appels n'est pas très indicative (événement DotNETRuntime / GC / Triggered):
Il existe un petit indice - appelant RecycleLimitMonitor.RaiseRecycleLimitEvent avant la récupération de place induite. Voyons la pile d'appels à la méthode RaiseRecycleLimitEvent:
RecycleLimitMonitor.RaiseRecycleLimitEvent(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.AlertProxyMonitors(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.CollectInfrequently(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.PBytesMonitorThread(...)
Les noms des méthodes sont cohérents avec leurs fonctions:
- Dans le constructeur de RecycleLimitMonitor.RecycleLimitMonitorSingleton, un temporisateur est créé qui appelle PBytesMonitorThread à un certain intervalle.
- PBytesMonitorThread collecte des statistiques sur l'utilisation de la mémoire et, dans certaines conditions, appelle CollectInfrequently.
- CollectInfrequently appelle AlertProxyMonitors, obtient un bool en conséquence et appelle GC.Collect () si cela devient vrai. Il surveille également le temps écoulé depuis le dernier appel au ramasse-miettes et ne l'appelle pas trop souvent.
- AlertProxyMonitors parcourt la liste des applications Web IIS en cours d'exécution, pour chacune déclenche l'objet RecycleLimitMonitor correspondant et appelle RaiseRecycleLimitEvent.
- RaiseRecycleLimitEvent déclenche la liste IObserver <RecycleLimitInfo>. Les gestionnaires reçoivent comme paramètre RecycleLimitInfo, dans lequel ils peuvent définir l'indicateur RequestGC, qui revient à CollectInfrequently, provoquant un garbage collection induit.
Une enquête plus approfondie révèle que les gestionnaires IObserver <RecycleLimitInfo> sont ajoutés dans la méthode RecycleLimitMonitor.Subscribe (), qui est appelée dans la méthode AspNetMemoryMonitor.Subscribe (). En outre, le gestionnaire IObserver <RecycleLimitInfo> par défaut (la classe RecycleLimitObserver) est suspendu dans la classe AspNetMemoryMonitor, qui nettoie les caches ASP.NET et demande parfois une collecte de place.
L'énigme du GC induit est presque résolue. Reste à savoir pourquoi ce garbage collection est appelé. RecycleLimitMonitor surveille l'utilisation de la mémoire IIS (plus précisément, le nombre d'octets privés), et lorsque son utilisation approche d'une certaine limite, il commence par un algorithme plutôt déroutant pour déclencher l'événement RaiseRecycleLimitEvent. La valeur d'AspNetMemoryMonitor.ProcessPrivateBytesLimit est utilisée comme limite de mémoire et, à son tour, elle contient la logique suivante:
- Si le pool d'applications dans IIS est défini sur «Limite de mémoire privée (Ko)», la valeur en kilo-octets est prise à partir de là
- Sinon, pour les systèmes 64 bits, 60% de la mémoire physique est utilisée (pour les systèmes 32 bits, la logique est plus compliquée).
La conclusion de l'enquête est la suivante: ASP.NET approche de sa limite de mémoire et commence à appeler régulièrement le garbage collection. La «limite de mémoire privée (Ko)» n'a pas été définie, donc ASP.NET était limité à 60% de la mémoire physique. Le problème était masqué par le fait que sur le serveur du Gestionnaire des tâches, il montrait beaucoup de mémoire libre et il semblait qu'il manquait. Nous avons augmenté la valeur «Private Memory Limit (KB)» dans les paramètres du pool d'applications dans IIS à 80% de la mémoire physique. Cela encourage ASP.NET à utiliser plus de mémoire disponible. Nous avons également ajouté la surveillance du compteur de performances '.NET CLR Memory / # Induced GC', afin de ne pas rater la prochaine fois qu'ASP.NET décide qu'il approche de la limite d'utilisation de la mémoire.
Mesures répétées
Voyons ce qui s'est passé avec la récupération de place après toutes ces modifications. Commençons par perfview / GCCollectOnly (temps de trace - 1 heure), rapport GCStats:
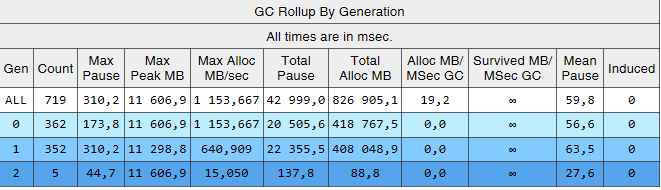
On peut voir que les assemblages de la 2e génération sont désormais de 2 ordres de grandeur plus petits que les 0e et 1er. De plus, le temps de ces assemblées a diminué. Les assemblages induits ne sont plus observés. Regardons la liste des assemblages de la 2ème génération:
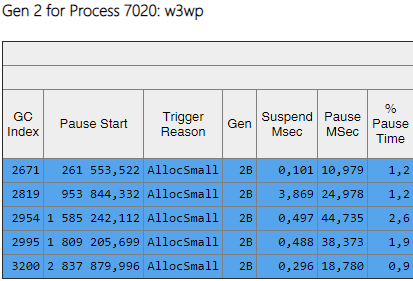
La colonne Gen montre que tous les assemblages de la 2e génération sont devenus l'arrière-plan («2B» signifie 2e génération, arrière-plan). Autrement dit, la plupart du travail est effectué en parallèle avec l'exécution de l'application, et tous les threads sont bloqués pendant une courte période (colonne «Pause MSec»). Regardons les pauses lors de la création de gros objets:

On peut voir que le nombre de telles pauses lors de la création de gros objets a considérablement diminué.
Résumé
Grâce aux modifications décrites dans l'article, il a été possible de réduire considérablement le nombre et la durée des assemblages de la 2e génération. J'ai réussi à trouver la cause des assemblages induits et à m'en débarrasser. Le nombre d'assemblages de la 0e et de la 1re génération a augmenté, mais leur durée moyenne a diminué (de ~ 200 ms à ~ 60 ms). La durée maximale d'assemblage de la 0e et de la 1re génération a diminué, mais pas de manière notable. Les assemblages de 2e génération sont devenus plus rapides, les longues pauses jusqu'à 1000 ms ont complètement disparu.
Quant à la mesure clé - «pourcentage de requêtes lentes», elle a diminué de 40% après toutes les modifications.
Grâce à notre travail, nous avons réalisé quels compteurs de performances sont nécessaires pour évaluer la situation avec la mémoire et la collecte des ordures, en les ajoutant à Zabbix pour une surveillance continue. Voici une liste des plus importantes auxquelles nous prêtons attention et en découvrons la raison (par exemple, un flux accru de requêtes, une grande quantité de données transmises, un bug dans l'application):