Le titre de l'article peut sembler étrange et pour une bonne raison - il est beau précisément parce qu'il n'a pas été écrit par moi, mais par le réseau de neurones LSTM (ou plutôt, sa partie avant le «ou»).
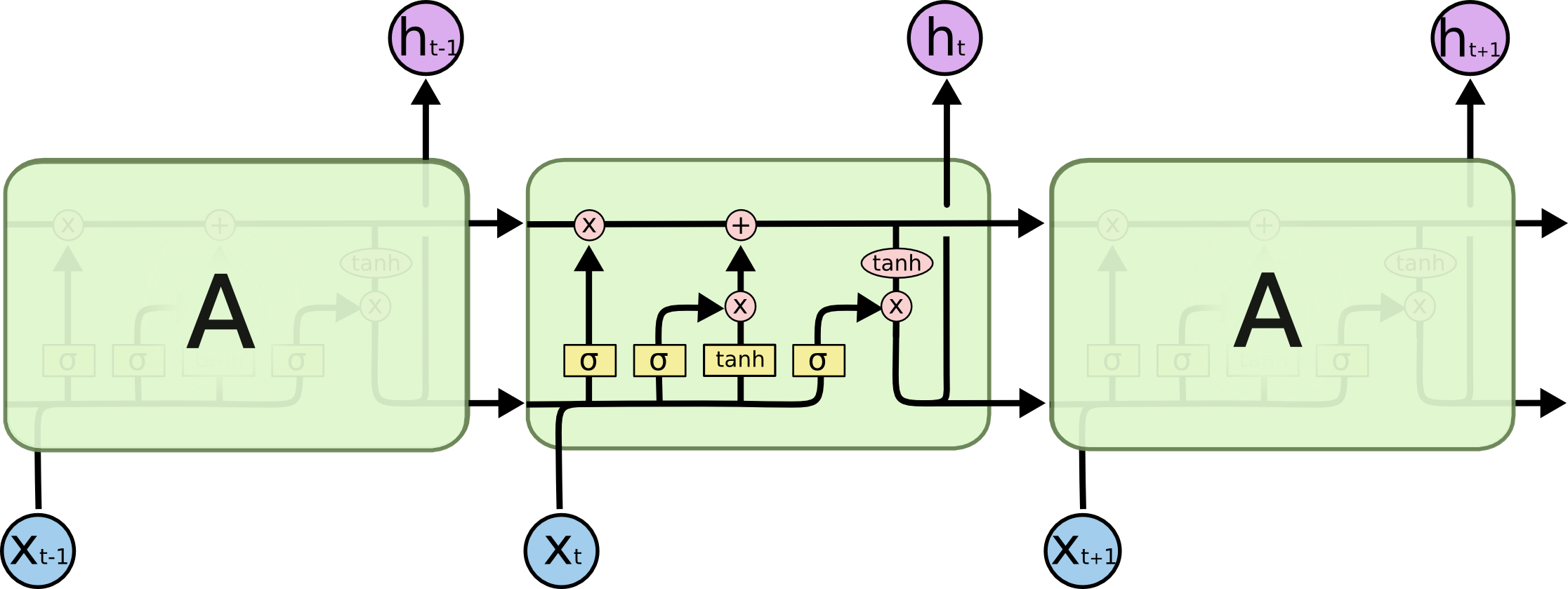
(Schéma LSTM tiré de Comprendre les réseaux LSTM )
Et aujourd'hui, nous allons voir comment vous pouvez générer les titres des articles de Habr (et, en principe, le texte lui-même peut être généré par la même neuro-architecture). Tout le code est disponible pour s'exécuter en ligne dans les blocs-notes de Google. Les données, comme toujours, sont ouvertes sur github .
Et ici, vous pouvez exécuter le modèle déjà formé sur le GPU de Google (gratuitement et sans SMS) et générer des en-têtes.
Liens clés
La théorie et la description des réseaux de neurones (en particulier LSTM) dans cet article sont basées sur
Description des données
Au total, environ 40 000 titres d'articles ont été collectés: chaque titre a été complété par deux caractères spéciaux <START_CHAR> et <END_CHAR> au début et à la fin, ainsi que <PADDING_CHAR> après <END_CHAR> à la taille maximale du titre.
Un exemple des données collectées:
Google IT . Now it's official
Théorie LSTM
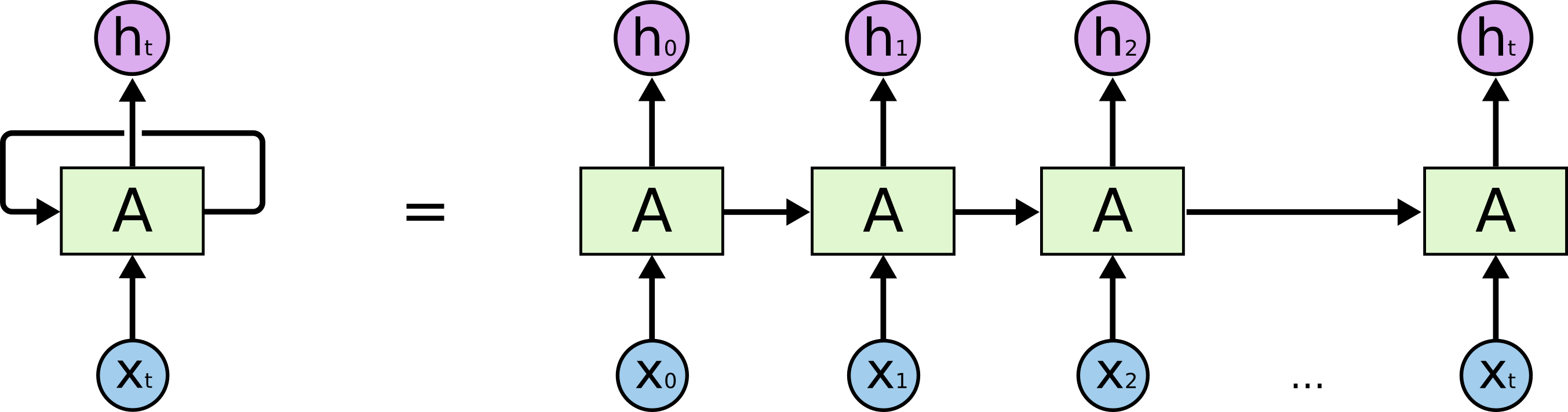
Commençons par la tâche réelle que nous résolvons: nous voulons prédire la (N + 1) ème ligne en N caractères, illustrativement du point de vue du modèle LSTM, cela ressemble à l'image ci-dessous: X ci-dessous - données d'entrée; h i ci-dessus sont les week-ends; entre eux se trouve l'état interne du réseau. Dans un peu plus de détails - l'image à gauche avec une boucle de rétroaction, équivalente à une chaîne détaillée à droite.
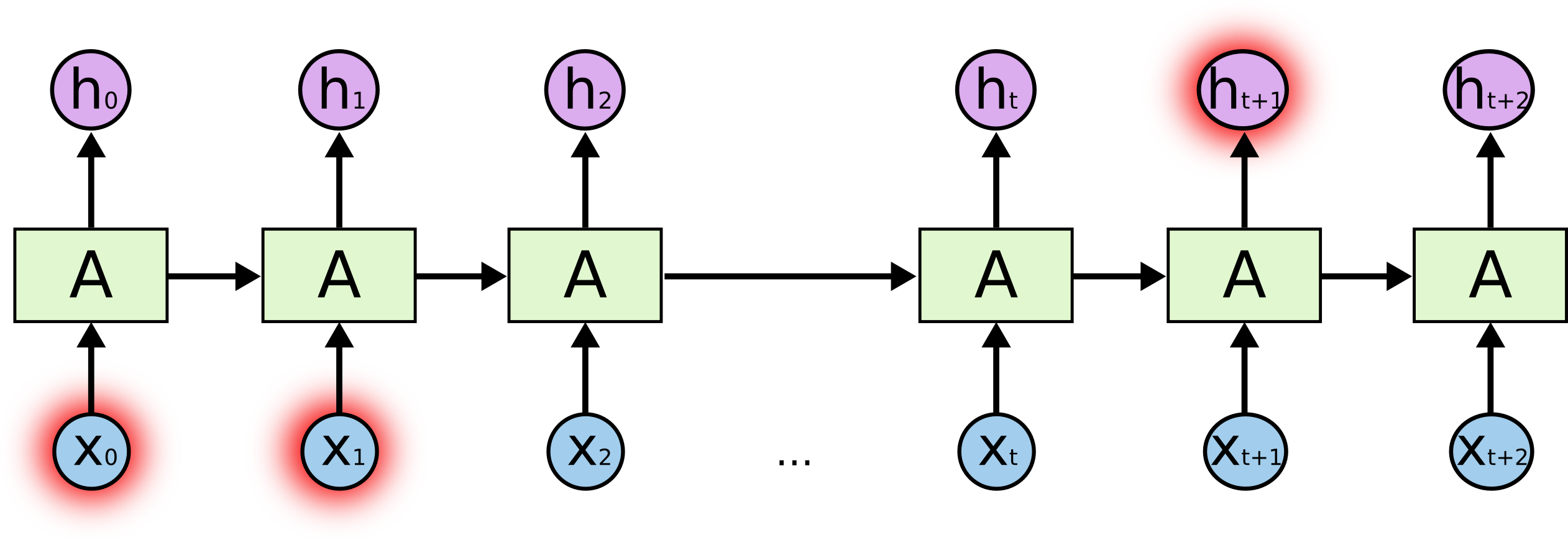
Qu'est-ce que le sel? En prédisant un caractère en surbrillance à la fin, les caractères en surbrillance au début peuvent jouer un rôle clé - d'où le terme dépendances à long terme. Il est clair que souvent les personnages immédiatement à côté d'eux jouent un rôle important - de telles dépendances sont appelées dépendances à court terme.
Internes des cellules LSTM:
La cellule entière contient quatre éléments de base.
- Portes de l'oubli - un élément décide qu'il sortira de la mémoire
- Porte entrante - elle crée un ensemble de "valeurs candidates" que nous pouvons utiliser pour écrire et mettre à jour la mémoire
- Mémoire - un élément décide de ce qui est réellement et comment nous économisons
- Élément de sortie - définit la sortie du modèle
Désignations:

Porte de l'oubli
Si nous essayons de prédire la fin d'un mot - il est important de connaître le sexe du nom actuel, si nous avons vu un nouveau nom - cela vaut la peine d'oublier le sens précédent:

Porte entrante
Ensuite, nous calculons i t , qui déterminera quelles valeurs de la cellule mémoire nous voulons mettre à jour, et
calcule les valeurs candidates pour la mise à jour.
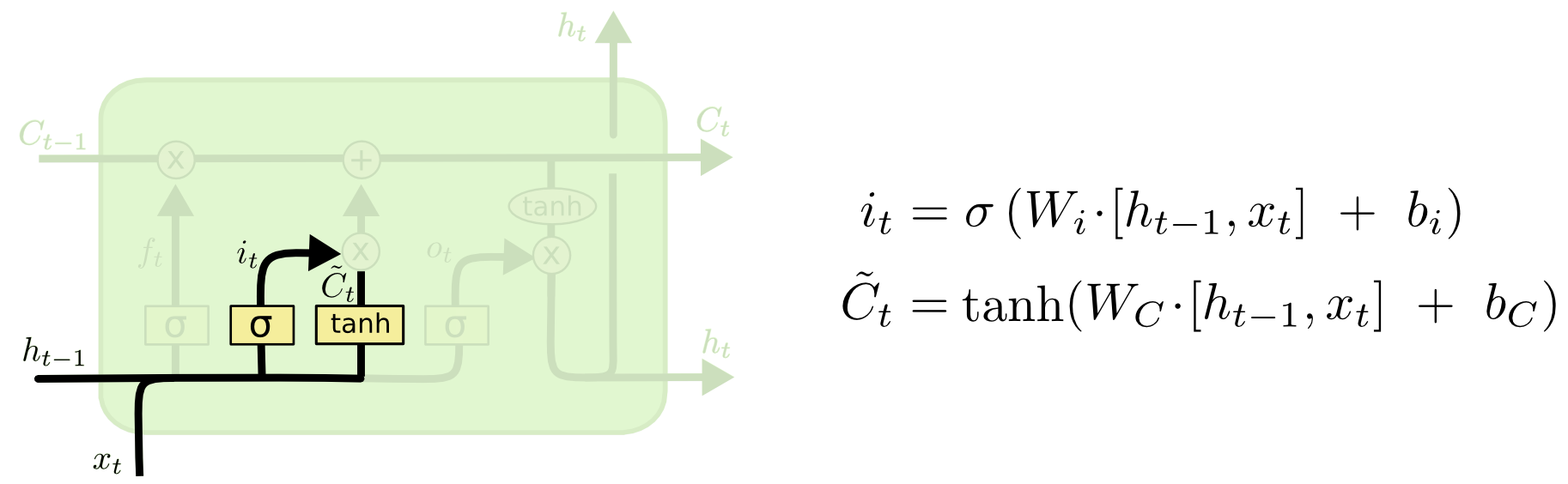
Cellule mémoire
Ensuite, les valeurs de la mémoire sont une superposition de ce que nous avons oublié dans l'état actuel et de ce que nous avons ajouté

Sortie du modèle
Qu'est-ce que l'inférence de modèle - une combinaison de trois choses: le symbole d'entrée actuel, la prédiction précédente et la mémoire du modèle

Code
La logique de base du modèle est présentée ci-dessous, en règle générale - cela représente environ 5 à 10% du code entier, tout le code restant est le nettoyage, la préparation et le traitement des données, ainsi que la sortie sous une forme lisible par l'homme.
Ici, vous pouvez exécuter le code avec un modèle déjà formé.
model = Sequential()
Exemples d'en-têtes créés
Échantillonnage personnel:
python powershell
(les références aléatoires du modèle au Dr Strangelove sont particulièrement agréables)
Quelle est la température (dans le contexte de DL)
En sortie, le modèle génère les poids x w des mots w - nous avons des options pour transformer ces poids en probabilités p (w), par exemple, en utilisant la formule:
Où T est un paramètre libre (en physique, c'est ainsi que la température est déterminée statistiquement - d'où le nom), plus la température est basse - plus l'exposant est élevé et les poids plus élevés enlèveront toute la probabilité, c'est-à-dire que le modèle ne prédira que quelques mots avec le maximum poids, si la température est élevée, alors la distribution se déplacera vers un uniforme et plus "créatif". Cela nous donne la possibilité de contrôler l'équilibre entre le suivi précis des données disponibles et la créativité conditionnelle du modèle.
Exemple de sortie de modèle using temperature 0.03 python sql azure federations 2 temperature 0.04 devcon 2013 temperature 0.05 python temperature 0.06 jbreak 2 10 19 temperature 0.07 temperature 0.08 php 10 temperature 0.09 unix oracle temperature 0.1 php temperature 0.11 android android studio github vue js php ruby temperature 0.12 asp net temperature 0.13 google glass using temperature 0.14 android temperature 0.15 python android sql azure federations 2 temperature 0.16 windows python using temperature 0.17 scala apache solr 1 c, 2 3 temperature 0.18 python cpatext content security policy temperature 0.190 52 28 27 nes c 1 3 scanner temperature 0.2 google chrome ms ie
Conclusions
- L'architecture LSTM modélise les séquences correctement
- La grammaire et la logique souffrent souvent - des problèmes les plus probables à deux endroits: premièrement, le dispositif de mémoire est assez simple et ne peut pas saisir toutes les règles et le contexte; deuxièmement, la puissance de l'affaire - l'ensemble de données est assez petit et pas trop diversifié
- Il serait intéressant de jeter un coup d'œil à la version de Better Language Models et leurs implications dans le grand cas de la langue russe - pour comprendre si l'architecture et un cas plus puissant résolvent ces problèmes.
- Certains titres ont été incroyablement ridicules et ironiques, par exemple, "... et pourquoi le blâme pour cela"
- Nous voyons certaines régularités des rubriques Habr, par exemple, «nous avons fait \ créé \ construit», un indicateur clair que les gens aiment partager des histoires personnelles sur Habr