Partie 1
3e partie
Passer des données aux résultats sans quitter votre ordinateur

Une pile d'images d'une petite zone en Slovénie, et une carte avec une couverture terrestre classée obtenue en utilisant les méthodes décrites dans l'article.
Préface
La deuxième partie d'une série d'articles sur la classification de la couverture terrestre à l'aide de la bibliothèque eo-learn. Nous vous rappelons que le premier article a démontré ce qui suit:
- Diviser AOI (zone d'intérêt) en fragments appelés EOPatch
- Réception d'images et de masques de nuages provenant des satellites Sentinel-2
- Calcul d'informations supplémentaires telles que NDWI , NDVI
- Créer un masque de référence et l'ajouter aux données source
De plus, nous avons mené une étude de surface des données, ce qui est une étape extrêmement importante avant de commencer une plongée dans l'apprentissage automatique. Les tâches ci-dessus ont été complétées par un exemple sous la forme d'un cahier Jupyter , qui contient désormais des éléments de cet article.
Dans cet article, nous terminerons la préparation des données et construirons également le premier modèle de construction de cartes d'occupation du sol pour la Slovénie en 2017.
Préparation des données
La quantité de code directement liée à l'apprentissage automatique est assez faible par rapport au programme complet. La part du lion du travail consiste à effacer les données, à les manipuler de manière à garantir une utilisation transparente avec le classificateur. Cette partie du travail sera décrite ci-dessous.

Un diagramme de pipeline d'apprentissage automatique qui montre que le code lui-même en utilisant ML est une petite fraction de l'ensemble du processus. Source
Filtrage d'images dans le cloud
Les nuages sont des entités qui apparaissent généralement à une échelle dépassant notre EOPatch moyen (1000x1000 pixels, résolution 10m). Cela signifie que tout site peut être complètement couvert de nuages à des dates aléatoires. Ces images ne contiennent pas d'informations utiles et ne consomment que des ressources, nous les ignorons donc en fonction du rapport des pixels valides au nombre total et fixons un seuil. Nous pouvons appeler valides tous les pixels qui ne sont pas classés comme des nuages et qui sont situés à l'intérieur d'une image satellite. Notez également que nous n'utilisons pas les masques fournis avec les images Sentinel-2, car ils sont calculés au niveau des images complètes (la taille de l'image S2 complète est de 10980 × 10980 pixels, environ 110 × 110 km), ce qui signifie que, pour la plupart, il n'est pas nécessaire pour notre AOI. Pour déterminer les nuages, nous utiliserons l'algorithme du paquet s2cloudless pour obtenir un masque de pixels de nuage.
Dans notre bloc-notes, le seuil est fixé à 0,8, nous sélectionnons donc uniquement les images remplies de données normales à 80%. Cela peut sembler une valeur assez élevée, mais comme les nuages ne sont pas un problème trop important pour notre AOI, nous pouvons nous le permettre. Il convient de noter que cette approche ne peut être appliquée sans réfléchir à aucun point de la planète, car la zone que vous avez choisie peut être couverte de nuages pendant une partie importante de l'année.
Interpolation temporelle
En raison du fait que des images peuvent être ignorées à certaines dates, ainsi qu'en raison de dates d'acquisition d'AOI incohérentes, le manque de données est un phénomène très courant dans le domaine de l'observation de la Terre. Une façon de résoudre ce problème est d'imposer un masque de validité de pixel (à partir de l'étape précédente) et d'interpoler les valeurs pour "remplir les trous". À la suite du processus d'interpolation, les valeurs de pixels manquantes peuvent être calculées pour créer un EOPatch qui contient des instantanés sur des jours uniformément répartis. Dans cet exemple, nous avons utilisé l'interpolation linéaire, mais il existe d'autres méthodes, dont certaines sont déjà implémentées dans eo-learn.

Sur la gauche se trouve une pile d'images Sentinel-2 à partir d'un AOI sélectionné au hasard. Les pixels transparents signifient des données manquantes en raison des nuages. L'image de droite montre la pile après interpolation, en tenant compte des masques de nuages.
Les informations temporelles sont extrêmement importantes dans la classification de la couverture, et encore plus importantes dans la tâche d'identification d'une culture de germination. Tout cela est dû au fait qu'une grande quantité d'informations sur la couverture terrestre est cachée dans la façon dont la parcelle change tout au long de l'année. Par exemple, lorsque vous affichez les valeurs NDVI interpolées, vous pouvez voir que les valeurs dans les forêts et les champs atteignent leurs maximums au printemps / été et chutent fortement en automne / hiver, tandis que l'eau et les surfaces artificielles maintiennent ces valeurs à peu près constantes tout au long de l'année. Les surfaces artificielles ont des valeurs NDVI légèrement plus élevées par rapport à l'eau et répètent partiellement le développement des forêts et des champs, car dans les villes, vous pouvez souvent trouver des parcs et d'autres végétaux. Vous devez également prendre en compte les limites associées à la résolution des images - souvent dans la zone couverte par un pixel, vous pouvez observer plusieurs types de couverture en même temps.
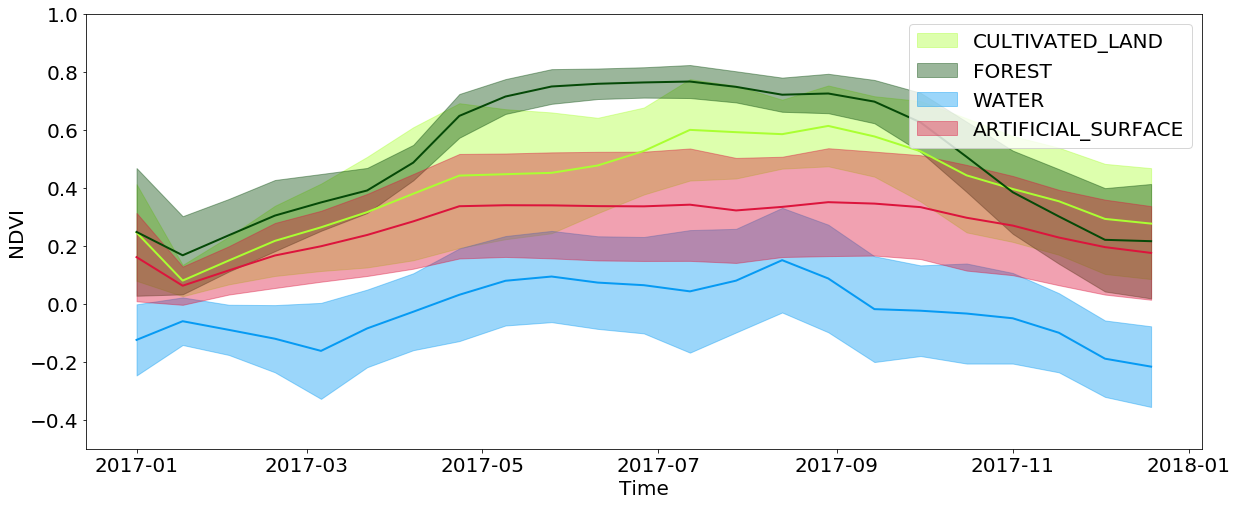
Développement temporel des valeurs NDVI pour les pixels de types spécifiques de couverture terrestre tout au long de l'année
Mise en mémoire tampon négative
Bien qu'une résolution d'image de 10 m soit suffisante pour un très large éventail de tâches, les effets secondaires des petits objets sont assez importants. Ces objets sont situés à la frontière entre différents types de couverture, et ces pixels se voient attribuer les valeurs d'un seul des types. Pour cette raison, lors de la formation du classificateur, un bruit excessif est présent dans les données d'entrée, ce qui aggrave le résultat. De plus, des routes et d'autres objets d'une largeur de 1 pixel sont présents sur la carte d'origine, bien qu'ils soient extrêmement difficiles à identifier à partir des images. Nous appliquons une mise en mémoire tampon négative de 1 pixel à la carte de référence, supprimant presque toutes les zones problématiques de l'entrée.
Carte de référence AOI avant (gauche) et après (droite) mise en mémoire tampon négative
Sélection aléatoire des données
Comme mentionné dans un article précédent, l'AOI complet est divisé en environ 300 fragments, chacun composé de ~ 1 million de pixels. Il s'agit d'une quantité assez impressionnante de ces mêmes pixels, nous prenons donc environ 40 000 pixels pour chaque EOPatch pour obtenir un ensemble de données de 12 millions de copies. Étant donné que les pixels sont pris uniformément, un grand nombre n'a pas d'importance sur la carte de référence, car ces données sont inconnues (ou ont été perdues après l'étape précédente). Il est logique de filtrer ces données afin de simplifier la formation du classificateur, car nous n'avons pas besoin de lui apprendre à définir l'étiquette «pas de données». La même procédure est répétée pour l'ensemble de test, car ces données dégradent artificiellement les indicateurs de qualité des prédictions du classificateur.
Nous avons divisé les données d'entrée en ensembles de formation / test à un ratio de 80/20%, respectivement, au niveau d'EOPatch, ce qui nous garantit que ces ensembles ne se coupent pas. Nous divisons également les pixels de l'ensemble pour la formation en ensembles pour les tests et la validation croisée de la même manière. Après la séparation, nous obtenons un tableau numpy.ndarray de dimension (p,t,w,h,d) , où:
p est le nombre d' EOPatch dans l'ensemble de données
t - le nombre d'images interpolées pour chaque EOPatch
* w, h, d - largeur, hauteur et nombre de couches dans les images, respectivement.
Après avoir sélectionné les sous-ensembles, la largeur w correspond au nombre de pixels sélectionnés (par exemple, 40 000), tandis que la dimension h est 1. La différence de forme du tableau ne change rien, cette procédure n'est nécessaire que pour simplifier le travail avec les images.
Les données des capteurs et du masque d dans n'importe quelle image t déterminent les données d'entrée pour la formation, où de telles instances totalisent p*w*h . Afin de convertir les données en un formulaire digestible pour le classifieur, nous devons réduire la dimension du tableau de 5 à la matrice du formulaire (p*w*h, d*t) . C'est facile à faire en utilisant le code suivant:
import numpy as np p, t, w, h, d = features_array.shape
Une telle procédure permettra de faire une prédiction sur de nouvelles données de même forme, puis de les reconvertir et de les visualiser par des moyens standards.
Création d'un modèle d'apprentissage automatique
Le choix optimal du classificateur dépend fortement de la tâche spécifique, et même avec le bon choix, nous ne devons pas oublier les paramètres d'un modèle spécifique, qui doit être changé d'une tâche à l'autre. Il est généralement nécessaire de mener de nombreuses expériences avec différents ensembles de paramètres afin de dire avec précision ce qui est nécessaire dans une situation particulière.
Dans cette série d'articles, nous utilisons le package LightGBM , car il s'agit d'un cadre intuitif, rapide, distribué et productif pour la création de modèles basés sur des arbres de décision. Pour sélectionner des hyperparamètres de classifieur, on peut utiliser différentes approches, telles que la recherche de grille , qui doivent être testées sur un ensemble de tests. Par souci de simplicité, nous allons ignorer cette étape et utiliser les paramètres par défaut.
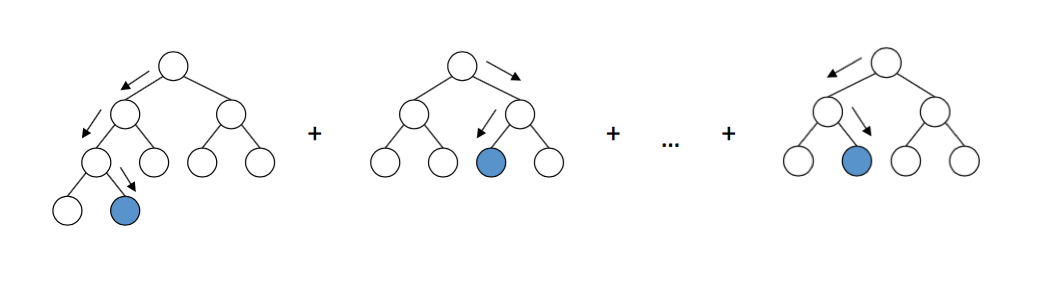
Le schéma de travail des arbres de décision dans LightGBM. Source
La mise en œuvre du modèle est assez simple, et puisque les données se présentent déjà sous la forme d'une matrice, nous alimentons simplement ces données à l'entrée du modèle et attendons. Félicitations! Maintenant, vous pouvez dire à tout le monde que vous êtes engagé dans l'apprentissage automatique et que vous serez le gars le plus à la mode lors d'une fête, tandis que votre mère sera inquiète de la rébellion des robots et de la mort de l'humanité.
Validation du modèle
La formation de modèles d'apprentissage automatique est facile. La difficulté est de bien les former. Pour cela, nous avons besoin d'un algorithme adapté, d'une carte de référence fiable et d'une quantité suffisante de ressources informatiques. Mais même dans ce cas, les résultats peuvent ne pas être ce que vous vouliez, donc vérifier le classificateur avec des matrices d'erreur et d'autres mesures est absolument nécessaire pour au moins une certaine confiance dans les résultats de votre travail.
Matrice d'erreur
Les matrices d'erreur sont les premières choses à considérer lors de l'évaluation de la qualité des classificateurs. Ils indiquent le nombre d'étiquettes correctement et incorrectement prédites pour chaque étiquette de la carte de référence et vice versa. Habituellement, une matrice normalisée est utilisée, où toutes les valeurs des lignes sont divisées par le montant total. Cela montre si le classificateur n'a pas un biais vers un certain type de couverture par rapport à un autre
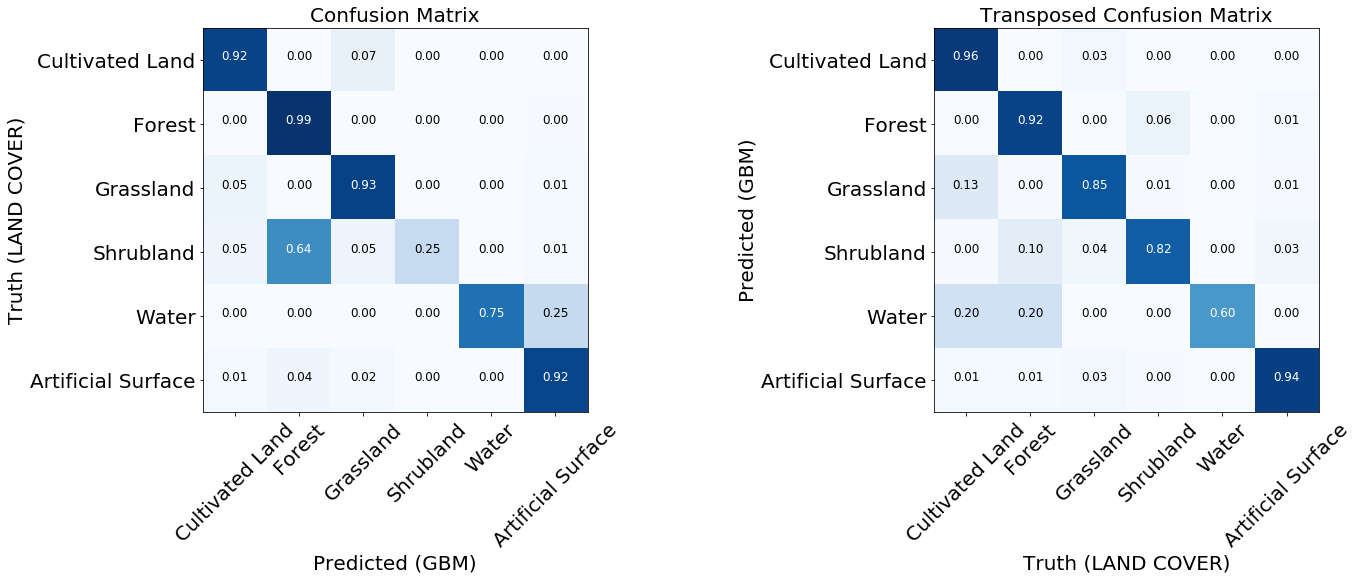
Deux matrices d'erreur normalisées du modèle entraîné.
Pour la plupart des classes, le modèle montre de bons résultats. Pour certaines classes, des erreurs se produisent en raison d'un déséquilibre dans les données d'entrée. Nous voyons que le problème est, par exemple, les buissons et l'eau, pour lesquels le modèle confond souvent les étiquettes de pixels et les identifie de manière incorrecte. En revanche, ce qui est marqué comme buisson ou eau correspond assez bien à la carte de référence. À partir de l'image suivante, nous pouvons remarquer que des problèmes surviennent pour les classes qui ont un petit nombre d'instances de formation - cela est principalement dû à la petite quantité de données dans notre exemple, mais ce problème peut se produire dans n'importe quelle tâche réelle.
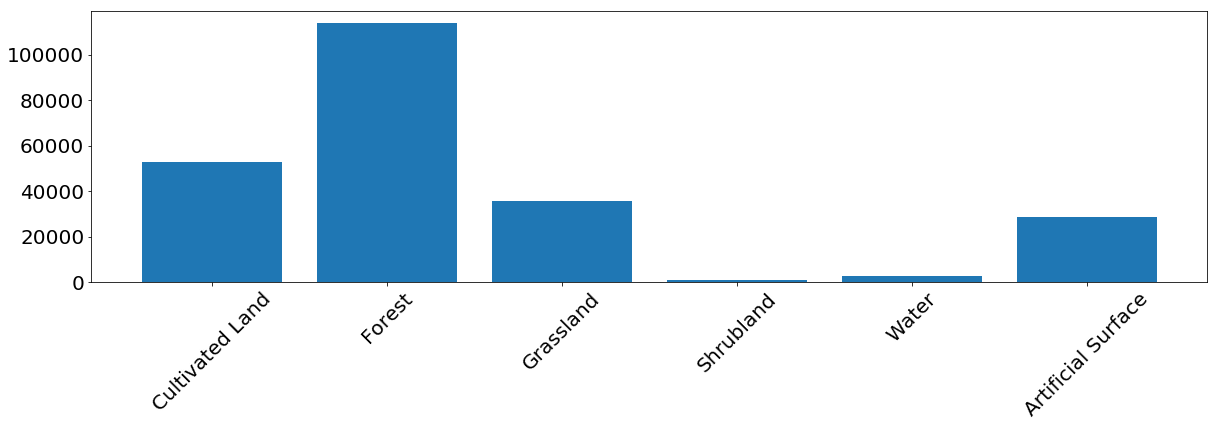
La fréquence d'apparition des pixels de chaque classe dans l'ensemble d'apprentissage.
Caractéristiques de fonctionnement du récepteur - Courbe ROC
Les classificateurs prédisent les étiquettes avec une certaine certitude, mais ce seuil pour une étiquette particulière peut être modifié. La courbe ROC montre la capacité du classificateur à faire des prédictions correctes lors de la modification du seuil de sensibilité. Habituellement, ce graphique est utilisé pour les systèmes binaires , mais il peut être utilisé dans notre cas si nous calculons la caractéristique «étiquette par rapport à toutes les autres» pour chaque classe. L'axe des abscisses montre des résultats faussement positifs (nous devons minimiser leur nombre), et l'axe des ordonnées montre des résultats vrais positifs (nous devons augmenter leur nombre) à différents seuils. Un bon classificateur peut être décrit par une courbe sous laquelle l'aire de la courbe est maximale. Cet indicateur est également connu sous le nom d'aire sous courbe, AUC. À partir des graphiques des courbes ROC, on peut tirer les mêmes conclusions sur un nombre insuffisant d'exemples de la classe des «buissons», bien que la courbe de l'eau soit bien meilleure - cela est dû au fait que visuellement l'eau est très différente des autres classes, même avec un nombre insuffisant d'exemples dans les données.

Courbes ROC du classificateur, sous la forme de "un contre tous" pour chaque classe. Les nombres entre parenthèses sont des valeurs AUC.
L'importance des symptômes
Si vous souhaitez approfondir les subtilités du classificateur, vous pouvez consulter le graphique d'importance des fonctionnalités, qui nous indique quels signes ont le plus influencé le résultat final. Certains algorithmes d'apprentissage automatique, tels que celui que nous avons utilisé dans cet article, renvoient ces valeurs. Pour les autres modèles, cette métrique doit être considérée par nous-mêmes.

La matrice d'importance des caractéristiques pour le classificateur de l'exemple
Bien que d'autres signes au printemps (NDVI) soient généralement plus importants, nous voyons qu'il existe une date exacte à laquelle l'un des signes (B2 - bleu) est le plus important. Si vous regardez les photos, il s'avère que l'AOI pendant cette période était couverte de neige. On peut conclure que la neige révèle des informations sur la couverture sous-jacente, ce qui aide grandement le classificateur à déterminer le type de surface. Il convient de rappeler qu'un tel phénomène est spécifique à l'AOI observé et en général, il ne peut être invoqué.

Pièce EOatch AOI 3x3 couverte de neige
Résultats de prédiction
Après validation, nous comprenons mieux les forces et les faiblesses de notre modèle. Si nous ne sommes pas satisfaits de la situation actuelle, vous pouvez apporter des modifications au pipeline et réessayer. Après avoir optimisé le modèle, nous définissons une EOTask simple qui accepte EOPatch et le modèle de classificateur, fait une prédiction et l'applique au fragment.
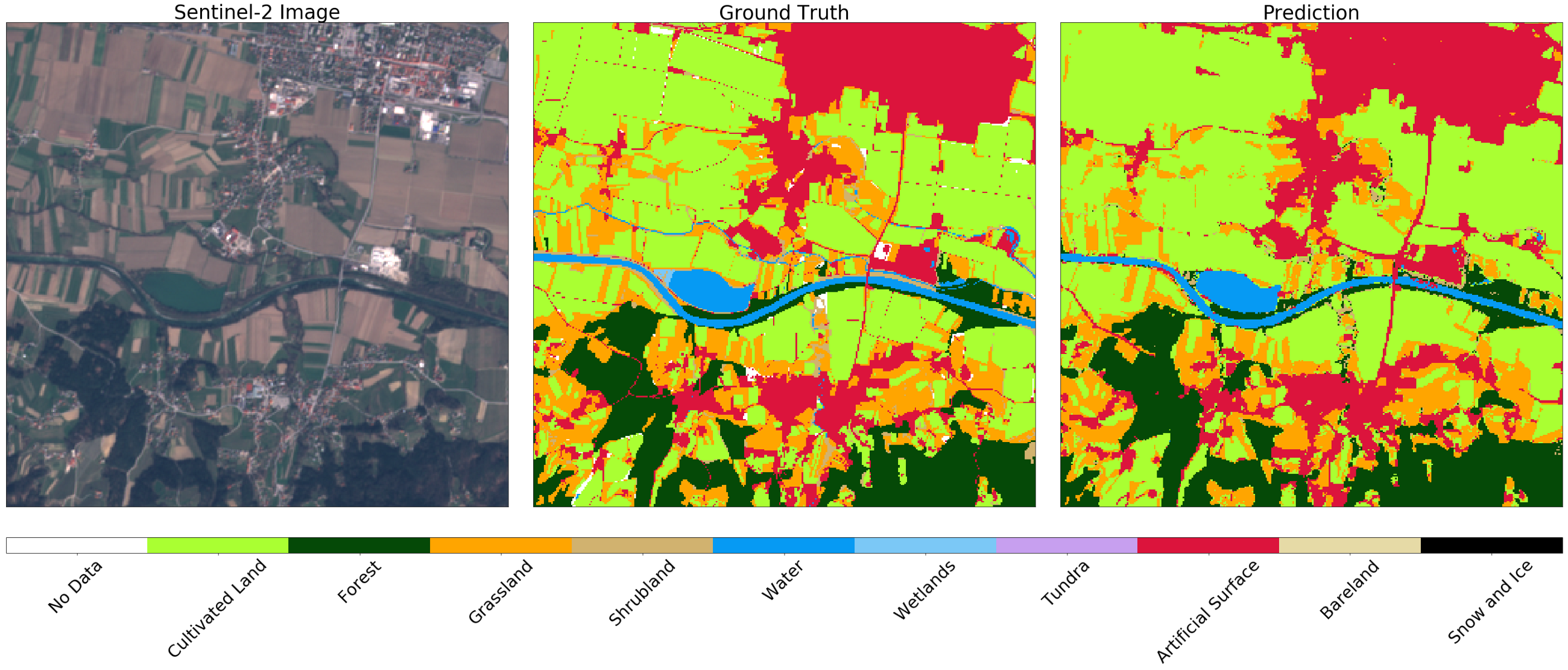
Image de Sentinel-2 (à gauche), vérité (au centre) et prédiction (à droite) pour un fragment aléatoire d'AOI. Vous pouvez remarquer des différences dans les images, qui peuvent s'expliquer par l'utilisation d'une mise en mémoire tampon négative sur la carte d'origine. En général, le résultat pour cet exemple est satisfaisant.
La voie à suivre est claire. Il est nécessaire de répéter la procédure pour tous les fragments. Vous pouvez même les exporter au format GeoTIFF et les coller à l'aide de gdal_merge.py .
Nous avons téléchargé GeoTIFF collé sur notre portail GeoPedia, vous pouvez voir les résultats en détail ici
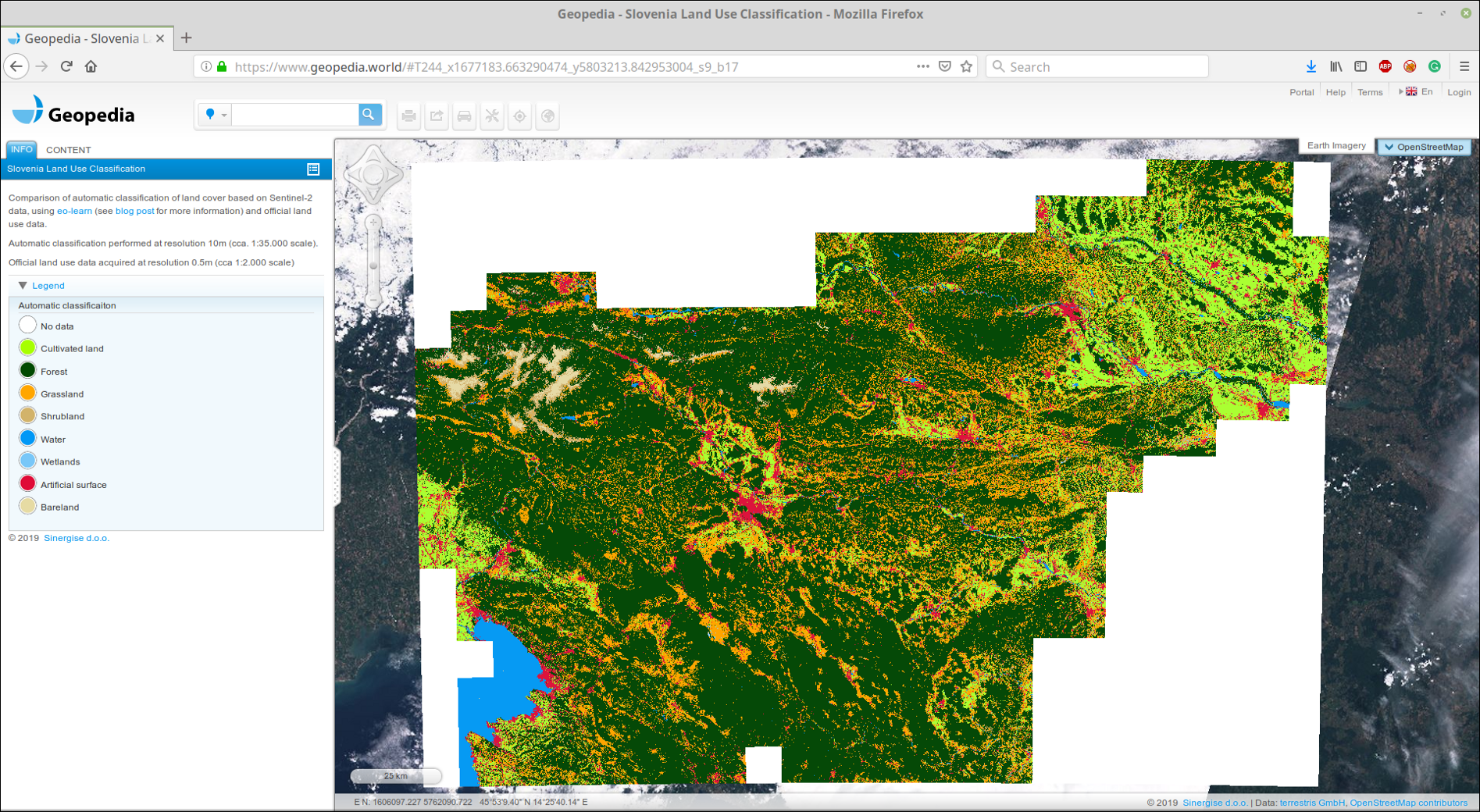
Capture d'écran de la prédiction de la couverture terrestre Slovénie 2017 en utilisant l'approche de ce post. Disponible dans un format interactif sur le lien ci-dessus
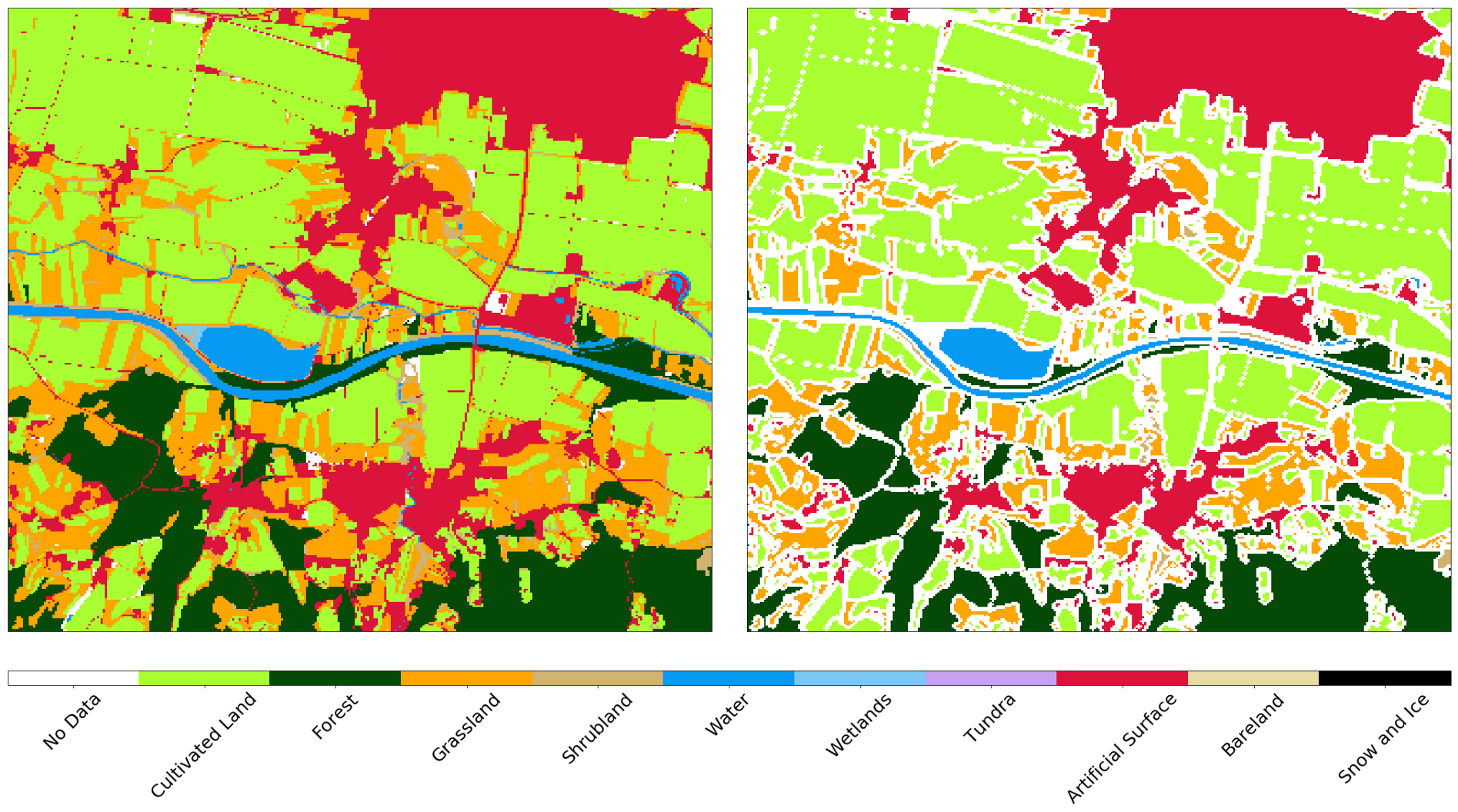
Vous pouvez également comparer les données officielles avec le résultat du classificateur. Faites attention à la différence entre les concepts d' utilisation des terres et de couverture des sols , que l'on retrouve souvent dans les tâches d'apprentissage automatique - il n'est pas toujours facile de mapper les données des registres officiels aux classes dans la nature. À titre d'exemple, nous montrons deux aéroports en Slovénie. Le premier est Levets, près de la ville de Celje . Cet aéroport est petit, principalement utilisé pour des jets privés, et est recouvert d'herbe. Officiellement, le territoire est marqué comme surface artificielle, bien que le classificateur soit capable d'identifier correctement le territoire comme herbe, voir ci-dessous.

Image de Sentinel-2 (à gauche), vraie (au centre) et prédiction (à droite) pour la zone autour du petit aéroport sportif. Le classificateur définit la piste comme de l'herbe, bien qu'elle soit marquée comme surface artificielle dans les données actuelles.
En revanche, dans le plus grand aéroport de Slovénie, Ljubljana , les zones marquées comme surface artificielle sur la carte sont des routes. Dans ce cas, le classificateur distingue les structures, tout en distinguant correctement l'herbe et les champs du territoire voisin.
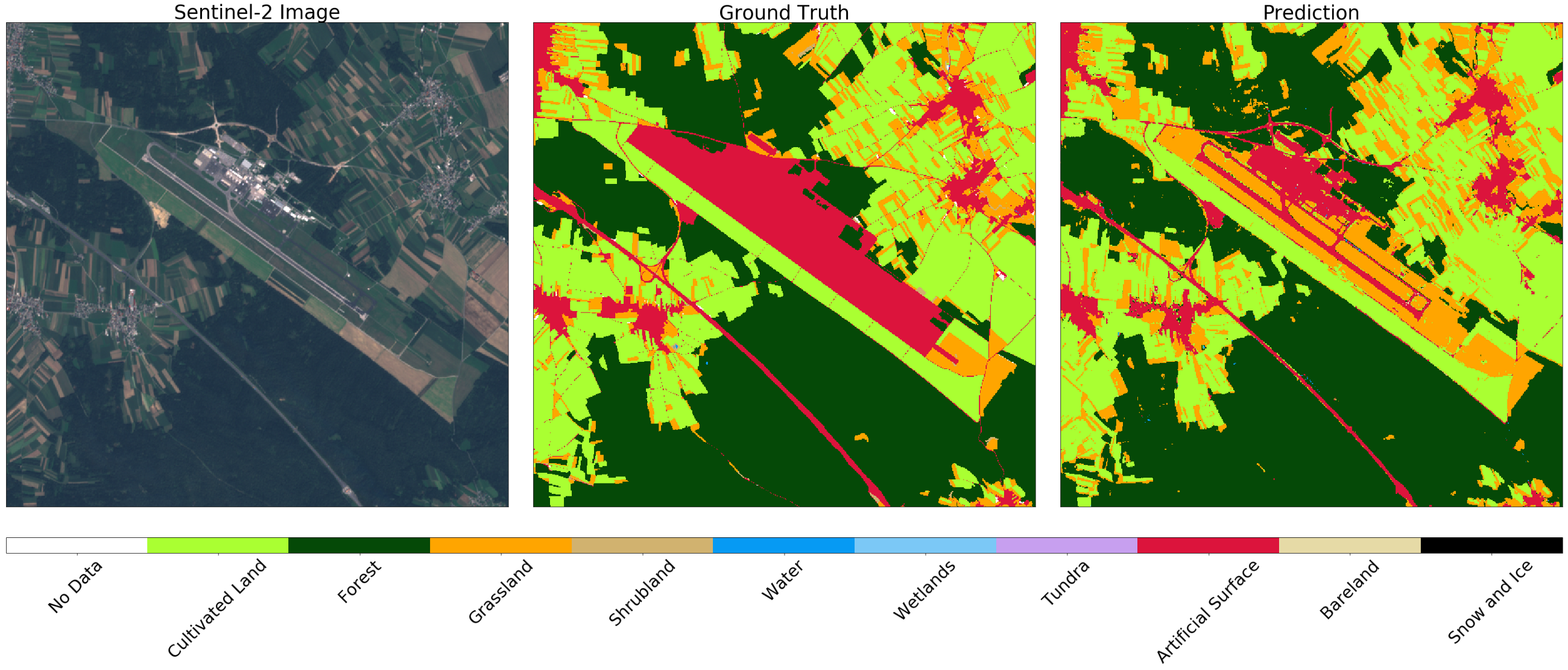
Image de Sentinel-2 (gauche), vérité (centre) et prédiction (droite) pour la zone autour de Ljubljana. Le classificateur détermine la piste et les routes, tout en distinguant correctement l'herbe et les champs dans le quartier
Voila!
Vous savez maintenant créer un modèle fiable à l'échelle nationale! N'oubliez pas d'ajouter cela à votre CV.