
Aujourd'hui, une haute disponibilité des services est requise partout et toujours, pas seulement dans les grands projets coûteux. Les sites temporairement indisponibles avec le message "Désolé, la maintenance est en cours" se produisent toujours, mais provoquent généralement un sourire condescendant. Ajoutez à cela la vie dans les nuages, quand pour démarrer un serveur supplémentaire, vous n'avez besoin que d'un seul appel à l'API, et vous n'avez pas besoin de penser à une opération de «repassage». Et il n'y a plus d'excuse pour laquelle le système critique n'a pas été fabriqué de manière fiable à l'aide des technologies de cluster et de la redondance.
Nous vous indiquerons les solutions que nous avons envisagées pour garantir la fiabilité des bases de données de nos services et ce à quoi nous sommes parvenus. Plus une démo avec des conclusions de grande envergure.
Héritage dans l'architecture à haute disponibilité
Ceci est encore mieux vu dans le contexte du développement de divers systèmes open source. Les anciennes solutions ont été forcées d'ajouter des technologies à haute disponibilité à mesure que la demande augmentait. Et leur qualité était différente. Les solutions de nouvelle génération placent la haute disponibilité au cœur de leur architecture. Par exemple, MongoDB positionne le cluster comme cas d'utilisation principal. Le cluster évolue horizontalement, ce qui constitue un fort avantage concurrentiel de ce SGBD.
Revenons à PostgreSQL. Il s'agit de l'un des plus anciens projets open source populaires, dont la première version a eu lieu au cours de la 95e année du siècle dernier. Pendant longtemps, l'équipe du projet n'a pas considéré la haute disponibilité comme une tâche qui devait être traitée par le système. Par conséquent, la technologie de réplication pour créer des copies de données n'a été intégrée qu'à la version 8.2 en 2006, mais elle a été archivée (envoi de journaux). En 2010, la réplication en streaming est apparue dans la version 9.0 et constitue la base de la création d'une grande variété de clusters. En fait, cela est très surprenant pour les personnes qui découvrent PostgreSQL après Enterprise SQL ou NoSQL moderne - la solution standard de la communauté n'est qu'un couple de répliques maîtres avec réplication synchrone ou asynchrone. Dans le même temps, l'assistant est commuté manuellement dans le drain, et le problème du changement de client est également proposé pour être résolu indépendamment.
Comment nous avons décidé de rendre PostgreSQL fiable et ce que nous avons choisi pour cela
Cependant, PostgreSQL ne serait pas devenu si populaire s'il n'y avait pas un grand nombre de projets et d'outils qui aident à créer une solution tolérante aux pannes qui ne nécessite pas une attention constante. Depuis le lancement de DBaaS, des serveurs PostgreSQL uniques et des paires de répliques maîtres avec réplication asynchrone sont disponibles dans
Mail.ru Cloud Solutions (MCS).
Naturellement, nous voulions simplifier la vie de chacun et rendre disponible l'installation de PostgreSQL, qui pourrait servir de base à des services hautement accessibles que vous n'auriez pas à surveiller en permanence et à vous réveiller la nuit pour effectuer le changement. Dans ce segment, il existe à la fois d'anciennes solutions éprouvées et une génération de nouveaux utilitaires qui utilisent les derniers développements.
Aujourd'hui, le problème de la haute disponibilité ne repose pas sur la redondance (il va sans dire), mais sur le consensus - un algorithme pour choisir un leader (élection du leader). Le plus souvent, des accidents majeurs ne surviennent pas à cause d'un manque de serveurs, mais à cause de problèmes de consensus: un nouveau leader n'est pas sorti, deux leaders sont apparus dans différents centres de données, etc. Un exemple est un crash sur le cluster Github MySQL - ils ont écrit un
post mortem détaillé .
La base mathématique en la matière est très sérieuse. D'une part, il existe un
théorème CAP , qui impose des restrictions théoriques sur la possibilité de construire des solutions HA, et d'autre part, des algorithmes de détermination de consensus mathématiquement éprouvés tels que
Paxos et
Raft . Sur cette base, il existe des DCS (systèmes de consensus décentralisés) assez populaires - Zookeeper, etcd, Consul. Par conséquent, si le système de prise de décision fonctionne sur certains de ses propres algorithmes, écrits indépendamment, vous devez être extrêmement prudent à ce sujet. Après avoir analysé un grand nombre de systèmes, nous nous sommes installés sur Patroni - un système open source, principalement développé par Zalando.
En tant que digression lyrique, je dirai que nous avons également envisagé des solutions multi-maîtres, c'est-à-dire des clusters qui peuvent être mis à l'échelle horizontalement pour l'enregistrement. Cependant, pour deux raisons principales, ils ont décidé de ne pas constituer un tel cluster. Premièrement, ces solutions présentent une complexité élevée et, par conséquent, davantage de vulnérabilités. Il sera difficile de prendre une décision stable pour tous les cas. Deuxièmement, dans ce cas, PostgreSQL cesse d'être pur (natif), certaines fonctions ne seront pas disponibles, certaines applications peuvent rencontrer des bogues cachés lorsqu'elles fonctionnent.
Patroni
Alors, comment fonctionne Patroni? Les développeurs n'ont pas réinventé la roue et ont suggéré d'utiliser une des solutions DCS éprouvées comme base. Tous les problèmes de synchronisation des configurations, de choix d'un leader et de quorum lui sont donnés. Nous avons choisi etcd pour cela.
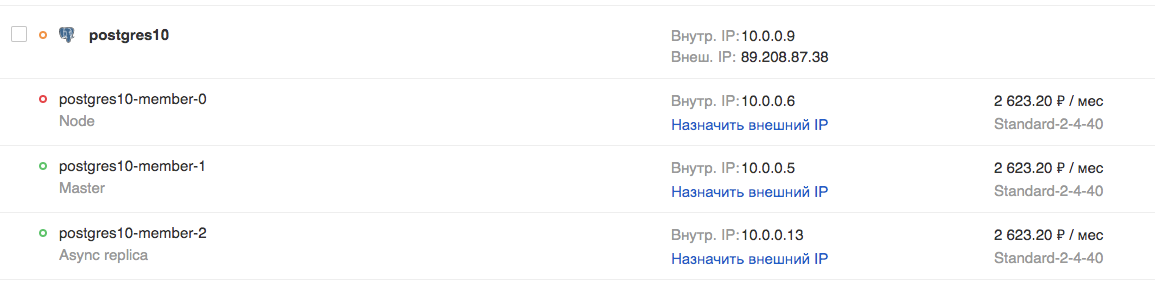
Ensuite, Patroni s'occupe de l'application correcte de tous les paramètres de PostgreSQL et des paramètres de réplication, ainsi que de l'exécution des commandes de basculement et de basculement (c'est-à-dire des assistants de commutation standard et non standard). Plus précisément, dans le cloud MCS, vous pouvez créer un cluster à partir d'un assistant, d'une réplique synchrone et d'une ou plusieurs répliques asynchrones. La présence d'une réplique synchrone garantit la sécurité des données sur au moins 2 serveurs, et cette réplique sera le principal «candidat pour le maître».
Étant donné que etcd est déployé sur les mêmes serveurs, il est recommandé que le nombre de serveurs soit de 3 ou 5, pour la valeur de quorum optimale. Un tel cluster est mis à l'échelle horizontalement pour la lecture (j'ai écrit sur la mise à l'échelle pour écrire ci-dessus). Néanmoins, il convient de garder à l'esprit que les répliques asynchrones sont à la traîne, en particulier à des charges élevées.
L'utilisation de ces réplicas en attente de lecture est justifiée pour les tâches de génération de rapports ou d'analyse et décharge le serveur maître.
Si vous souhaitez créer un tel cluster vous-même, vous aurez besoin de:
- préparer 3 serveurs ou plus, configurer l'adressage IP et les règles de pare-feu entre eux;
- installer des packages pour les services etcd, Patroni, PostgreSQL;
- configurer le cluster etcd;
- configurer le service patroni pour fonctionner avec PostgreSQL.
C'est-à-dire qu'au total, vous devez composer correctement une douzaine de fichiers de configuration et ne faire aucune erreur nulle part. Pour ce faire, il vaut vraiment la peine d'utiliser un outil de gestion de configuration tel qu'Ansible, par exemple. Cependant, il n'existe toujours pas d'équilibreur TCP hautement disponible. Pour ce faire, c'est un travail distinct.
Pour ceux qui ont besoin d'un cluster prêt à l'emploi, mais ne veulent pas fouiner avec tout cela, nous avons essayé de simplifier notre vie et avons créé un cluster prêt à l'emploi sur Patroni dans notre cloud, il peut être testé gratuitement. En plus du cluster lui-même, nous avons fait:
- Équilibreur TCP sur différents ports, il pointe toujours vers le maître actuel, la réplique synchrone ou asynchrone, respectivement;
- API pour changer l'assistant Patroni actif.
Ils peuvent être connectés à la fois via l'API cloud MCS et la console Web.
Démo
Pour tester les capacités du cluster PostgreSQL dans le cloud MCS, voyons comment une application en direct se comporte en cas de problèmes avec le SGBD.
Voici le code d'une application qui enregistrera les événements artificiels et les signalera à l'écran. En cas d'erreurs, il le signalera et continuera son travail dans un cycle jusqu'à ce que nous l'arrêtions avec la combinaison Ctrl + C.
from __future__ import print_function from datetime import datetime from random import randint from time import sleep import psycopg2 def main(): try: connection = psycopg2.connect(user = "admin", password = "P@ssw0rd", host = "89.208.87.38", port = "5432", database = "myproddb") cursor = connection.cursor() cursor.execute("SELECT version();") record = cursor.fetchone() print("Connection opened to", record[0]) cursor.execute( "INSERT INTO log VALUES ({});".format(randint(1, 10000))) connection.commit() cursor.execute("SELECT COUNT(event_id) from log;") record = cursor.fetchone() print("Logged a value, overall count: {}".format(record[0])) except Exception as error: print ("Error while connecting to PostgreSQL", error) finally: if connection: cursor.close() connection.close() print("Connection closed") if __name__ == '__main__': try: while True: try: print(datetime.now()) main() sleep(3) except Exception as e: print("Caught error:\n", e) sleep(1) except KeyboardInterrupt: print("exit")
Une application a besoin de PostgreSQL pour fonctionner. Créez un cluster dans le cloud MCS à l'aide de l'API. Dans un terminal normal, où la variable OS_TOKEN contient un jeton pour accéder à l'API (vous pouvez l'obtenir avec la commande d'émission de jeton openstack), nous tapons les commandes:
Créez un cluster:
cat <<EF > pgc10.json {"cluster":{"name":"postgres10","allow_remote_access":true,"datastore":{"type":"postgresql","version":"10"},"databases":[{"name":"myproddb"}],"users":[{"databases":[{"name":"myproddb"}],"name":"admin","password":"P@ssw0rd"}],"instances":[{"key_name":"shared","availability_zone":"DP1","flavorRef":"d659fa16-c7fb-42cf-8a5e-9bcbe80a7538","nics":[{"net-id":"b91eafed-12b1-4a46-b000-3984c7e01599"}],"volume":{"size":50,"type":"DP1"}},{"key_name":"shared","availability_zone":"DP1","flavorRef":"d659fa16-c7fb-42cf-8a5e-9bcbe80a7538","nics":[{"net-id":"b91eafed-12b1-4a46-b000-3984c7e01599"}],"volume":{"size":50,"type":"DP1"}},{"key_name":"shared","availability_zone":"DP1","flavorRef":"d659fa16-c7fb-42cf-8a5e-9bcbe80a7538","nics":[{"net-id":"b91eafed-12b1-4a46-b000-3984c7e01599"}],"volume":{"size":50,"type":"DP1"}}]}} EOF curl -s -H "X-Auth-Token: $OS_TOKEN" \ -H 'Accept: application/json' \ -H 'Content-Type: application/json' \ -d @pgc10.json https://infra.mail.ru:8779/v1.0/ce2a41bbd1434013b85bdf0ba07c770f/clusters
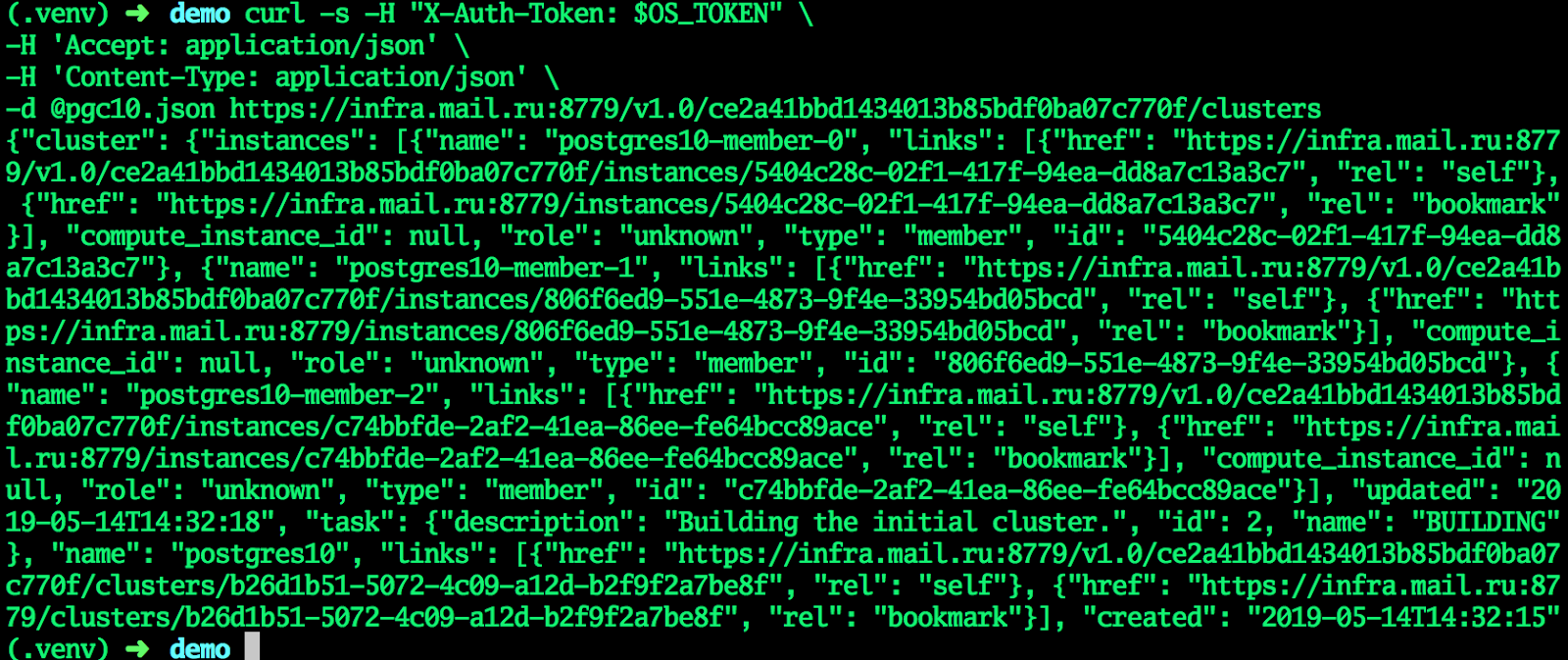
Lorsque le cluster entre dans l'état ACTIF, tous les champs recevront les valeurs actuelles - le cluster est prêt.
Dans l'interface graphique:
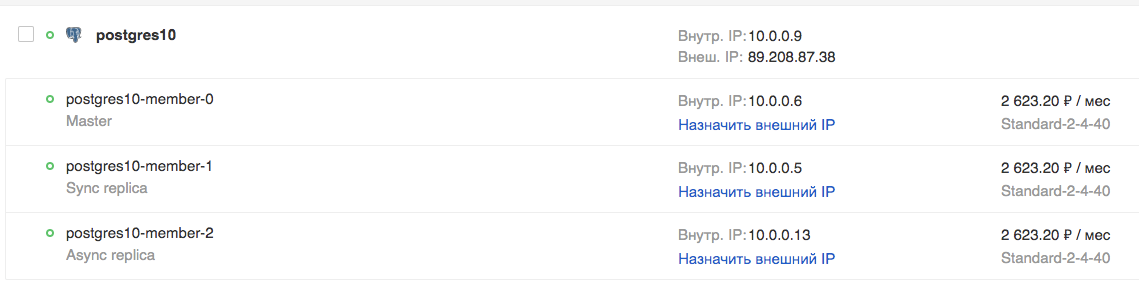
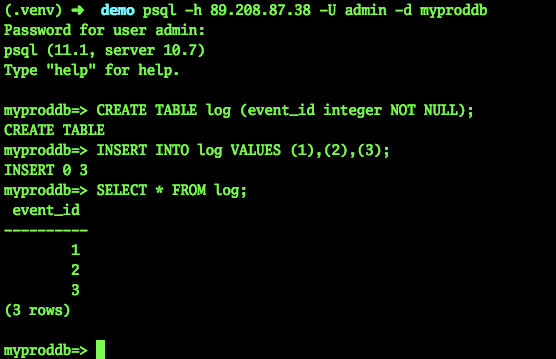
Essayons de nous connecter et de créer une table:
psql -h 89.208.87.38 -U admin -d myproddb Password for user admin: psql (11.1, server 10.7) Type "help" for help. myproddb=> CREATE TABLE log (event_id integer NOT NULL); CREATE TABLE myproddb=> INSERT INTO log VALUES (1),(2),(3); INSERT 0 3 myproddb=> SELECT * FROM log; event_id ---------- 1 2 3 (3 rows) myproddb=>
Dans l'application, nous indiquons les paramètres actuels de connexion à PostgreSQL. Nous allons spécifier l'adresse du TCP-balancer, éliminant ainsi le besoin de basculer manuellement vers l'adresse de l'assistant. Lancez-le. Comme vous pouvez le voir, les événements sont correctement enregistrés dans la base de données.

Interrupteur principal programmé
Nous allons maintenant tester le fonctionnement de notre application lors du basculement prévu de l'assistant:
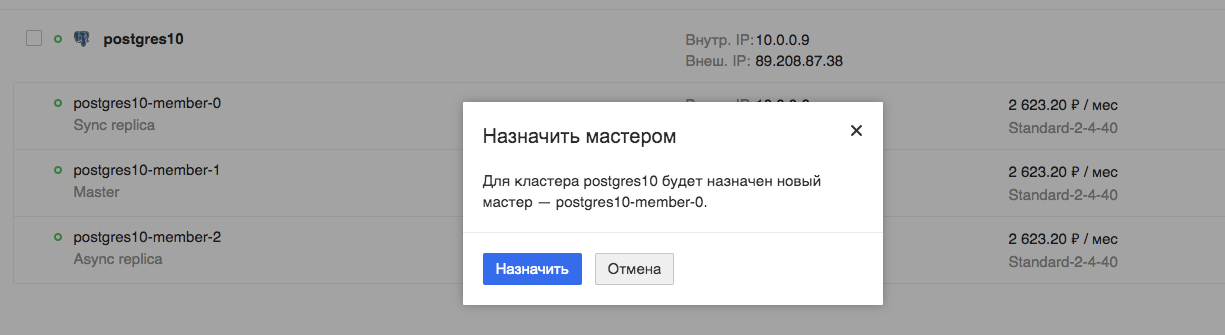
Nous regardons l'application. On voit que l'application est vraiment interrompue, mais cela ne prend que quelques secondes, dans ce cas particulier, un maximum de 9.
Chute de voiture
Essayons maintenant de simuler la chute d'une machine virtuelle, le maître actuel. Il serait possible de simplement éteindre la machine virtuelle via l'interface Horizon, seulement ce sera un arrêt régulier. Un tel changement sera traité par tous les services, y compris Patroni.
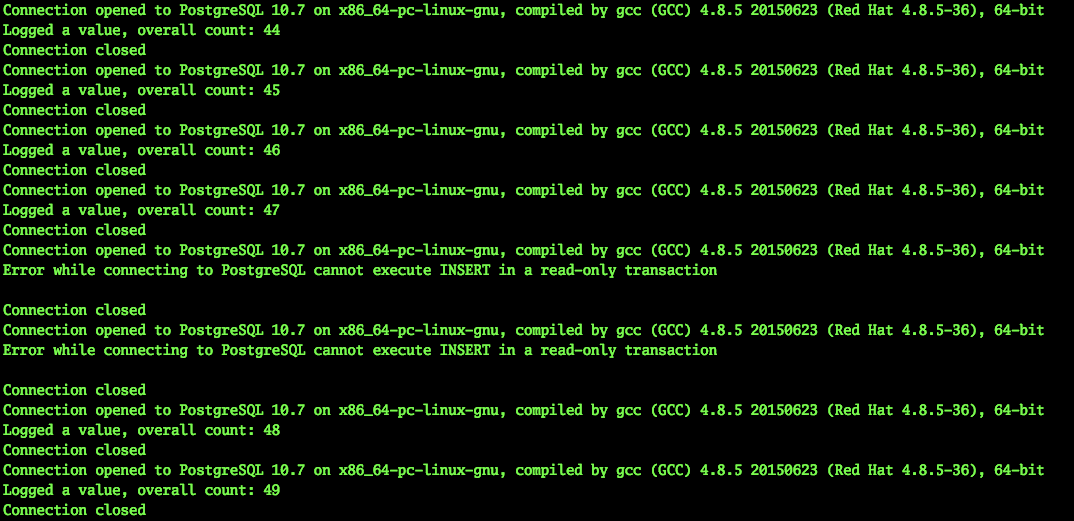
Nous avons besoin d'un arrêt imprévisible. Par conséquent, j'ai demandé à nos administrateurs à des fins de test de désactiver la machine virtuelle - le maître actuel - de manière anormale.
Dans le même temps, notre application a continué de fonctionner. Naturellement, un tel interrupteur d'urgence du maître ne peut passer inaperçu.
2019-03-29 10:45:56.071234 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 453 Connection closed 2019-03-29 10:45:59.205463 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 454 Connection closed 2019-03-29 10:46:02.661440 Error while connecting to PostgreSQL server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. Caught error: local variable 'connection' referenced before assignment ……………………………………………………….. - - 2019-03-29 10:46:30.930445 Error while connecting to PostgreSQL server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. Caught error: local variable 'connection' referenced before assignment 2019-03-29 10:46:31.954399 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 455 Connection closed 2019-03-29 10:46:35.409800 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 456 Connection closed ^Cexit
Comme vous pouvez le voir, l'application a pu continuer son travail en moins de 30 secondes. Oui, un certain nombre d'utilisateurs du service auront le temps de remarquer des problèmes. Cependant, il s'agit d'une grave défaillance du serveur, cela ne se produit pas si souvent. Dans le même temps, la personne (administrateur) n'aurait guère réussi à réagir aussi rapidement, à moins d'être assise dans la console prête avec un script de commutation.
Conclusion
Il me semble qu'un tel cluster offre un énorme avantage aux administrateurs. En effet, de graves pannes et dysfonctionnements des serveurs de base de données ne seront pas perceptibles pour l'application et, par conséquent, pour l'utilisateur. Vous n'aurez pas à réparer quelque chose à la hâte et à passer à des configurations temporaires, des serveurs, etc. Et si vous utilisez cette solution sous la forme d'un service prêt à l'emploi dans le cloud, vous n'aurez pas à perdre de temps à la préparer. Il sera possible de faire quelque chose de plus intéressant.