
Si vous administrez une infrastructure virtuelle basée sur VMware vSphere (ou toute autre pile technologique), vous entendez probablement souvent des plaintes des utilisateurs: "La machine virtuelle est lente!". Dans cette série d'articles, j'analyserai les indicateurs de performance et expliquerai pourquoi et pourquoi cela «ralentit» et comment m'assurer qu'il ne «ralentit» pas.
J'examinerai les aspects suivants des performances des machines virtuelles:
Je vais commencer par le CPU.
Pour l'analyse des performances, nous avons besoin de:
- Les compteurs de performances vCenter sont des compteurs de performances dont les graphiques peuvent être affichés via vSphere Client. Les informations sur ces compteurs sont disponibles dans n'importe quelle version client (client "épais" en C #, client web sur Flex et client web sur HTML5). Dans ces articles, nous utiliserons des captures d'écran du client C #, uniquement parce qu'elles sont plus belles en miniature :)
- ESXTOP est un utilitaire qui s'exécute à partir de la ligne de commande ESXi. Avec son aide, vous pouvez obtenir les valeurs des compteurs de performances en temps réel ou télécharger ces valeurs pendant une certaine période dans un fichier .csv pour une analyse plus approfondie. Ensuite, je vais vous en dire plus sur cet outil et vous fournir des liens utiles vers la documentation et les articles associés.
Un peu de théorie
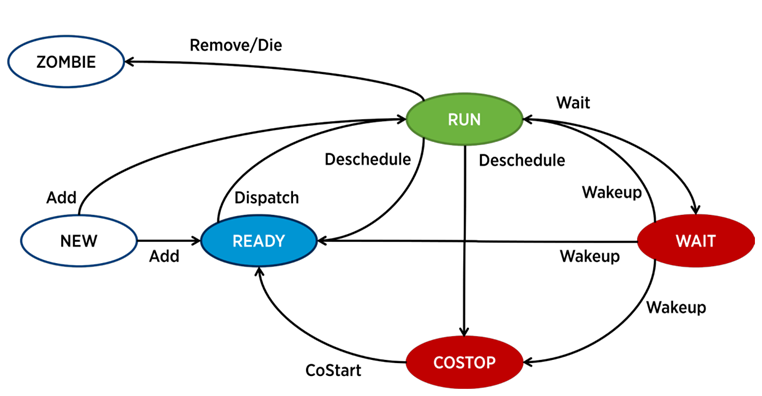
Dans ESXi, un processus distinct est responsable du fonctionnement de chaque vCPU (noyau de machine virtuelle) - le monde de la terminologie VMware. Il existe également des processus de service, mais du point de vue de l'analyse des performances des VM, ils sont moins intéressants.
Un processus dans ESXi peut être dans l'un des quatre états suivants:
- Exécuter - le processus fait un travail utile.
- Attendre - le processus ne fait aucun travail (inactif) ou attend une entrée / sortie.
- Costop est une condition qui se produit dans les machines virtuelles multicœurs. Cela se produit lorsque le planificateur de CPU de l'hyperviseur (ESXi CPU Scheduler) ne peut pas planifier tous les cœurs actifs de la machine virtuelle pour s'exécuter simultanément sur les cœurs du serveur physique. Dans le monde physique, tous les cœurs de processeur fonctionnent en parallèle, le système d'exploitation invité à l'intérieur de la machine virtuelle attend un comportement similaire, donc l'hyperviseur doit ralentir les cœurs de machine virtuelle, qui ont la capacité de terminer le rythme plus rapidement. Dans les versions modernes d'ESXi, le planificateur du processeur utilise un mécanisme appelé co-planification détendue: l'hyperviseur considère l'écart entre le cœur de machine virtuelle le plus rapide et le plus lent (skew). Si l'écart dépasse un certain seuil, le cœur rapide passe à l'état costop Si les cœurs de machine virtuelle passent beaucoup de temps dans cet état, cela peut entraîner des problèmes de performances.
- Prêt - le processus passe dans cet état lorsque l'hyperviseur n'a pas la capacité d'allouer des ressources pour son exécution. Des valeurs élevées prêtes peuvent entraîner des problèmes de performances des machines virtuelles.
Compteurs de performances CPU de base d'une machine virtuelle
Utilisation du processeur,%. Affiche le pourcentage d'utilisation du processeur pour une période donnée.
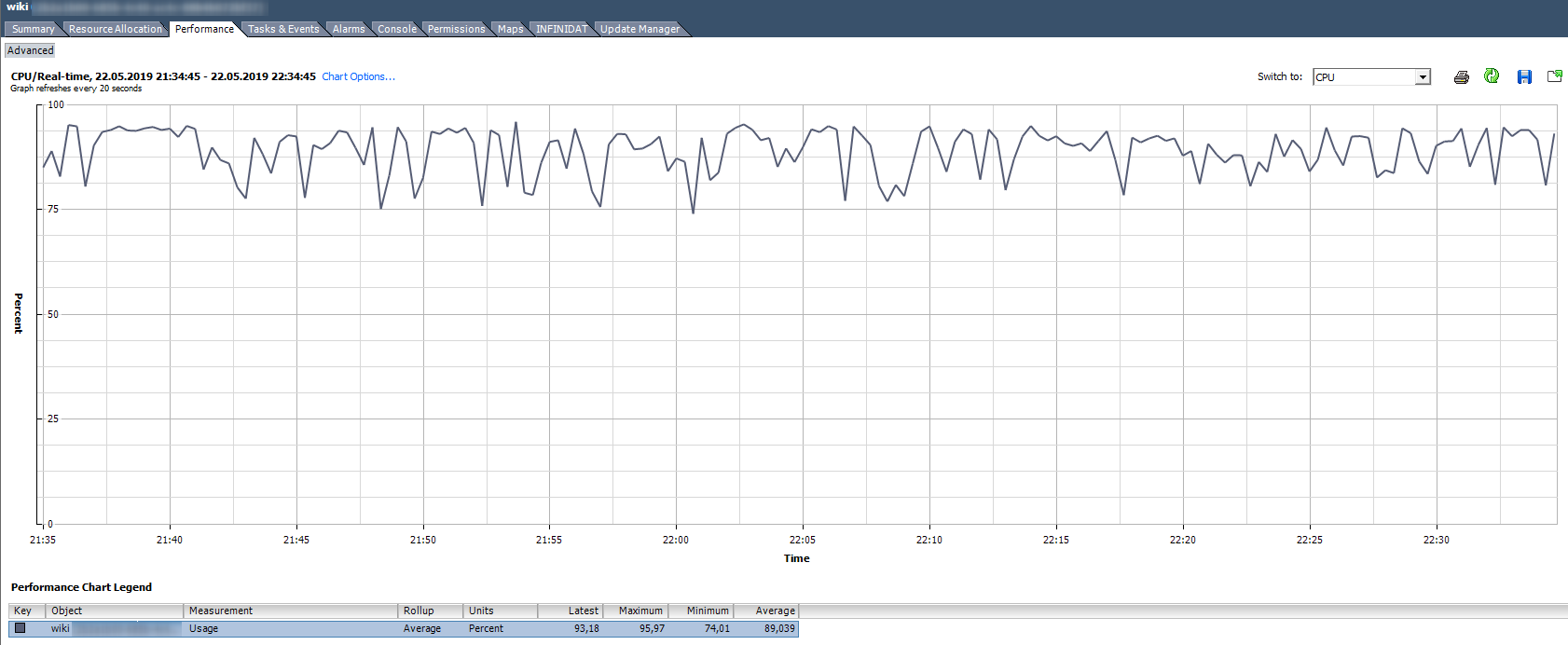 Comment analyser?
Comment analyser? Si la VM utilise le CPU de manière stable à 90% ou s'il y a des pics jusqu'à 100%, nous avons des problèmes. Les problèmes peuvent s'exprimer non seulement dans le fonctionnement «lent» de l'application à l'intérieur de la VM, mais aussi dans l'inaccessibilité de la VM sur le réseau. Si le système de surveillance montre que la machine virtuelle tombe périodiquement, faites attention aux pics dans le graphique d'utilisation du processeur.
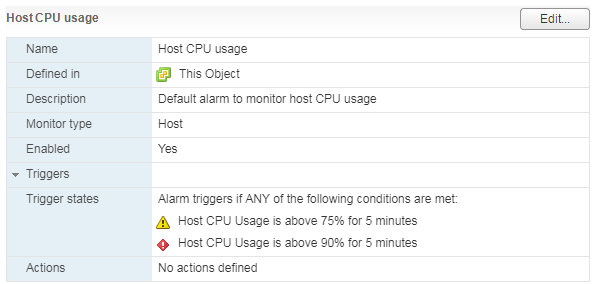
Il existe une alarme standard, qui indique la charge CPU de la machine virtuelle:
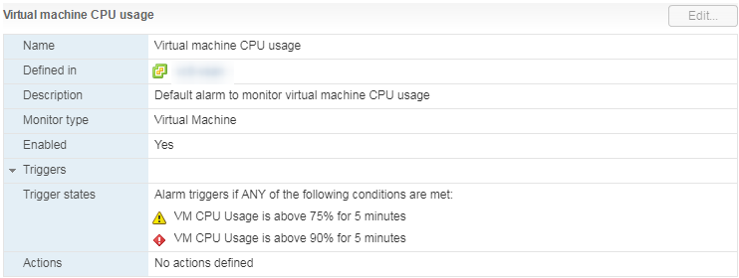 Que faire
Que faire Si l'utilisation du CPU écrase constamment la machine virtuelle, vous pouvez penser à augmenter le nombre de vCPU (malheureusement, cela n'aide pas toujours) ou à déplacer la machine virtuelle vers un serveur avec des processeurs plus efficaces.
Utilisation du processeur en MHz
Dans les graphiques d'utilisation de vCenter en%, vous ne pouvez voir que la machine virtuelle entière, il n'y a pas de graphiques pour les cœurs individuels (Esxtop a des valeurs en% pour les cœurs). Pour chaque cœur, vous pouvez voir l'utilisation en MHz.
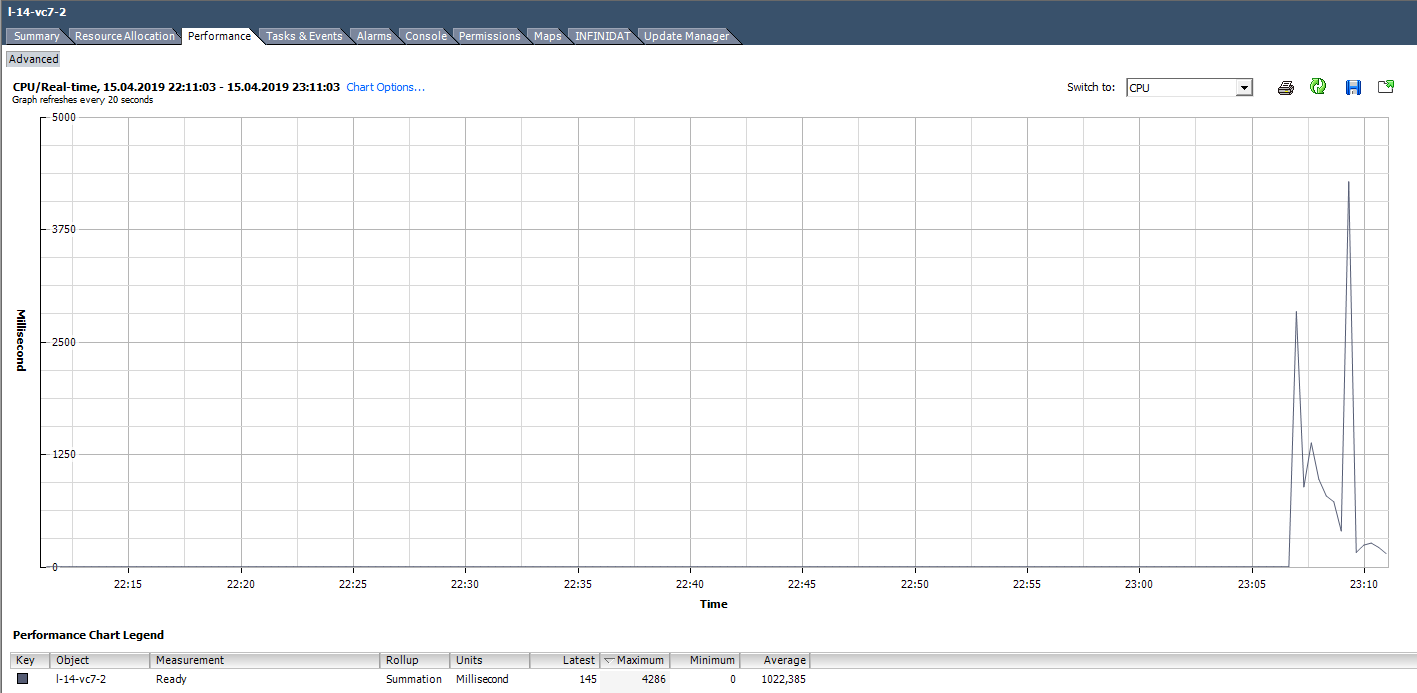
Comment analyser? Il arrive que l'application ne soit pas optimisée pour une architecture multicœur: elle utilise à 100% un seul cœur et les autres sont inactives sans charge. Par exemple, avec les paramètres de sauvegarde par défaut, MS SQL démarre le processus sur un seul cœur. En conséquence, la sauvegarde est ralentie non pas à cause de la vitesse lente du disque (c'est ce dont l'utilisateur s'est plaint au départ), mais parce que le processeur ne peut pas y faire face. Le problème a été résolu en modifiant les paramètres: la sauvegarde a commencé à s'exécuter en parallèle dans plusieurs fichiers (respectivement, dans plusieurs processus).
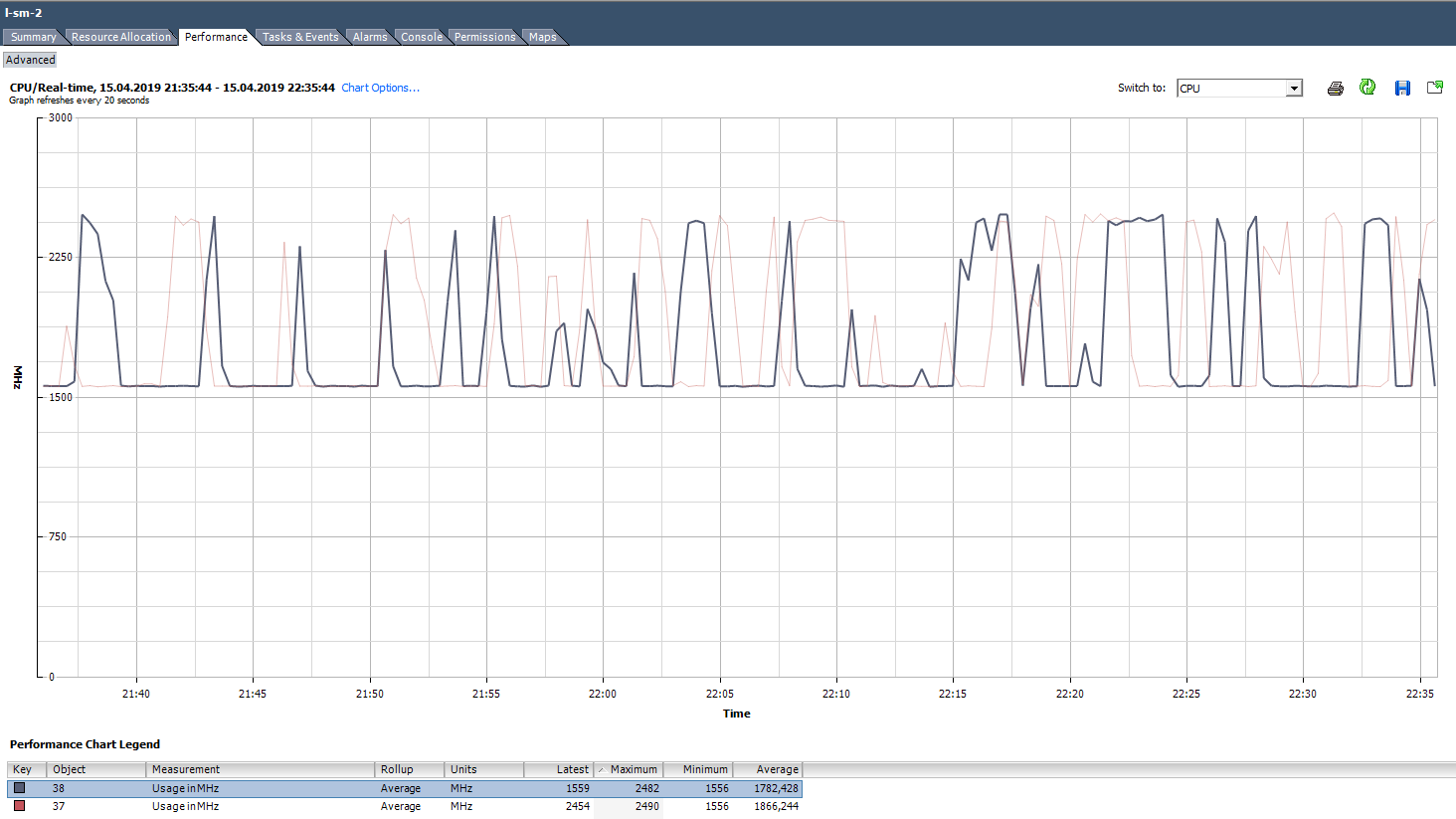 Un exemple d'une charge inégale de noyaux.
Un exemple d'une charge inégale de noyaux.Il existe également une situation (comme dans le graphique ci-dessus) lorsque les noyaux sont inégalement chargés et certains d'entre eux ont des pics de 100%. Comme pour le chargement d'un seul cœur, l'alarme sur l'utilisation du processeur ne fonctionnera pas (c'est sur l'ensemble de la machine virtuelle), mais il y aura des problèmes de performances.
Que faire Si le logiciel de la machine virtuelle charge les noyaux de manière inégale (n'utilise qu'un seul noyau ou partie des noyaux), il est inutile d'augmenter leur nombre. Dans ce cas, il est préférable de déplacer la machine virtuelle vers un serveur avec des processeurs plus efficaces.
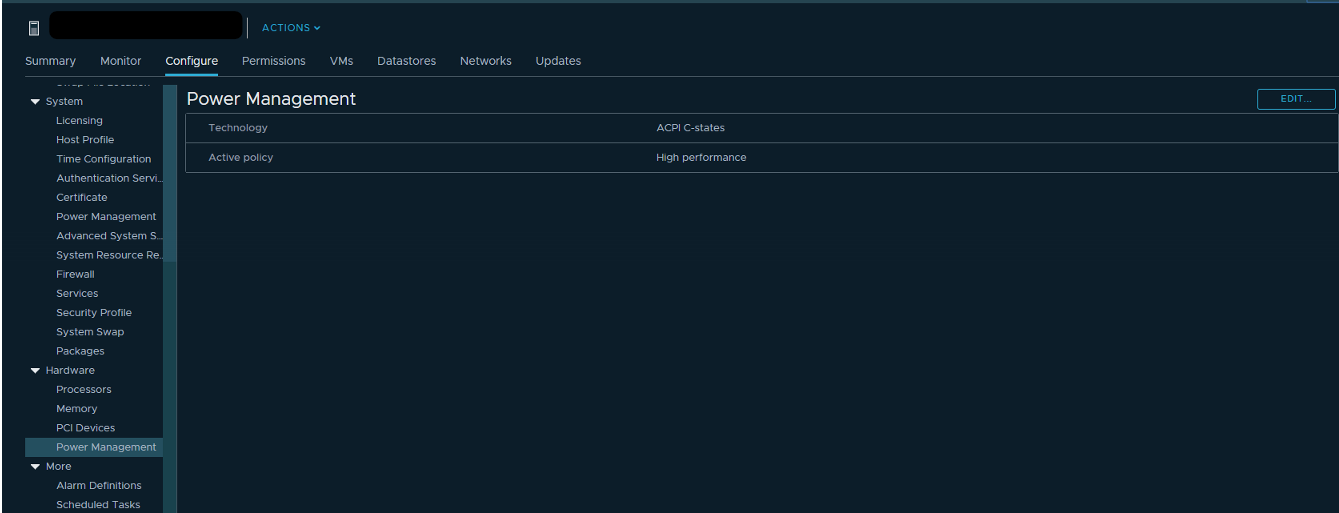
Vous pouvez également essayer de vérifier les paramètres d'alimentation dans le BIOS du serveur. De nombreux administrateurs activent le mode Haute performance dans le BIOS et désactivent ainsi les technologies d'économie d'énergie des états C et des états P. Les processeurs Intel modernes utilisent la technologie Turbo Boost, qui augmente la fréquence des cœurs de processeur individuels en raison d'autres cœurs. Mais cela ne fonctionne qu'avec les technologies d'économie d'énergie incluses. Si nous les désactivons, le processeur ne peut pas réduire la consommation d'énergie des noyaux qui ne sont pas chargés.
VMware recommande de ne pas désactiver les technologies d'économie d'énergie sur les serveurs, mais de choisir des modes qui maximisent la gestion de l'énergie pour l'hyperviseur. Dans le même temps, dans les paramètres d'alimentation de l'hyperviseur, vous devez sélectionner Haute performance.
Si vous avez des machines virtuelles (ou des cœurs de machines virtuelles) distinctes dans votre infrastructure qui nécessitent une fréquence CPU accrue, la configuration correcte de la consommation d'énergie peut améliorer considérablement leurs performances.
Prêt pour le processeur (prêt)
Si le cœur de machine virtuelle (vCPU) est à l'état Prêt, il ne fait pas de travail utile. Cette condition se produit lorsque l'hyperviseur ne trouve pas de noyau physique libre auquel le processus vCPU de la machine virtuelle peut être affecté.
Comment analyser? En règle générale, si les cœurs de machine virtuelle sont à l'état Prêt pendant plus de 10% du temps, vous remarquerez des problèmes de performances. Autrement dit, plus de 10% du temps qu'une machine virtuelle attend la disponibilité des ressources physiques.
Dans vCenter, vous pouvez voir 2 compteurs associés au CPU Ready:
Les valeurs des deux compteurs peuvent être affichées à la fois sur l'ensemble de la machine virtuelle et pour les noyaux individuels.
La disponibilité indique la valeur immédiatement en pourcentage, mais uniquement en temps réel (données pour la dernière heure, intervalle de mesure 20 secondes). Ce compteur est mieux utilisé uniquement pour rechercher des problèmes "en poursuite".
Les valeurs de compteur prêtes peuvent également être consultées dans une perspective historique. Ceci est utile pour établir des modèles et pour une analyse plus approfondie du problème. Par exemple, si une machine virtuelle commence à avoir des problèmes de performances à un moment précis, vous pouvez comparer les intervalles de la valeur CPU Ready bloquée avec la charge totale sur le serveur sur lequel la machine virtuelle s'exécute et prendre des mesures pour réduire la charge (si DRS ne pouvait pas faire face).
Prêt, contrairement à l'état de préparation, n'est pas affiché en pourcentage, mais en millisecondes. Il s'agit d'un compteur de type Summation, c'est-à-dire qu'il indique la durée pendant laquelle le cœur de machine virtuelle était à l'état Prêt pendant la période de mesure. Vous pouvez traduire cette valeur en pourcentage par une formule simple:
(Valeur de sommation CPU ready / (intervalle de mise à jour par défaut du graphique en secondes * 1000)) * 100 = CPU ready%
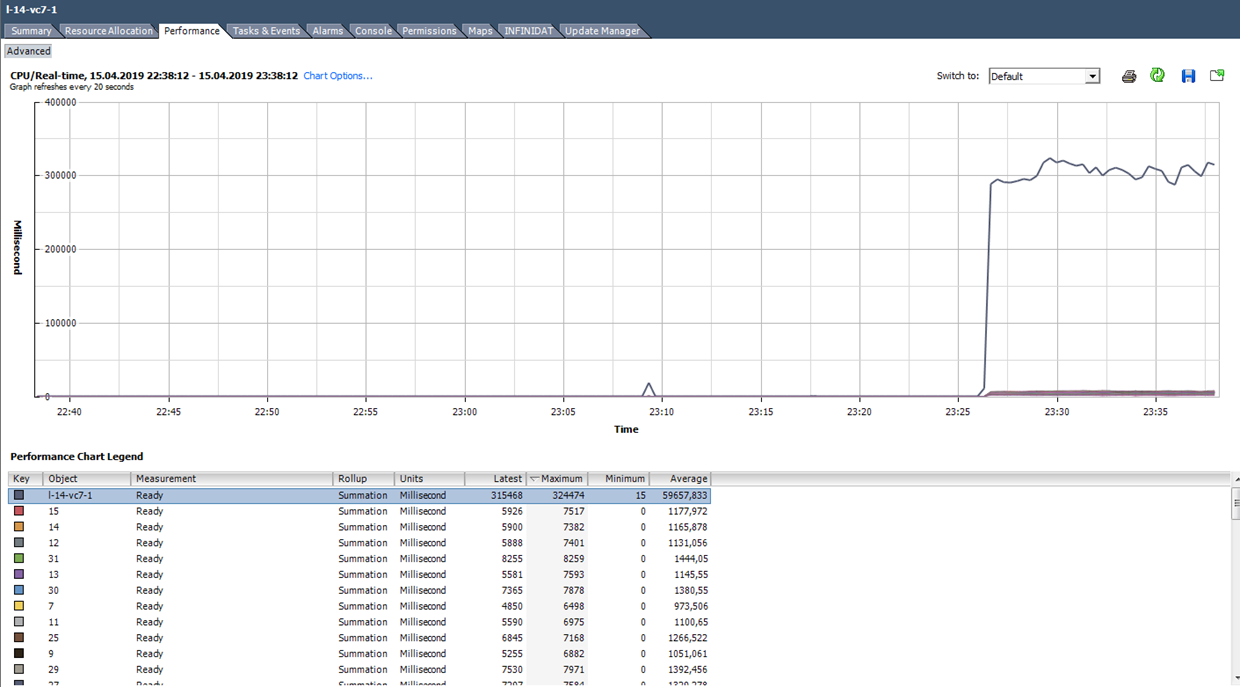
Par exemple, pour les machines virtuelles dans le graphique ci-dessous, la valeur maximale de Ready pour l'ensemble de la machine virtuelle est la suivante:
Lors du calcul de la valeur Ready en pourcentage, vous devez faire attention à deux points:
- La valeur de Ready sur l'ensemble de la machine virtuelle est la somme de Ready sur tous les cœurs.
- Intervalle de mesure. Pour le temps réel, c'est 20 secondes et, par exemple, sur les graphiques quotidiens, c'est 300 secondes.
Avec le dépannage actif, ces points simples peuvent être facilement manqués et un temps précieux peut être consacré à la résolution de problèmes inexistants.
Nous calculons Ready en fonction des données du graphique ci-dessous. (324474 / (20 * 1000)) * 100 = 1622% pour l'ensemble de la machine virtuelle. Si vous regardez les cœurs, cela ne sera pas si effrayant: 1622/64 = 25% par cœur. Dans ce cas, détecter une astuce est assez simple: la valeur Ready est irréaliste. Mais si nous parlons de 10 à 20% pour la VM entière avec plusieurs cœurs, alors pour chaque cœur, la valeur peut être dans la plage normale.
 Que faire
Que faire Une valeur élevée de Ready indique que le serveur ne dispose pas de suffisamment de ressources processeur pour le fonctionnement normal des machines virtuelles. Dans cette situation, il ne reste plus qu'à réduire la sursouscription sur le processeur (vCPU: pCPU). Évidemment, cela peut être réalisé en réduisant les paramètres des machines virtuelles existantes ou en migrant une partie de la machine virtuelle vers d'autres serveurs.
Co-stop
Comment analyser? Ce compteur a également le type Summation et se traduit par des pourcentages comme Ready:
(Valeur de sommation du co-stop du processeur / (intervalle de mise à jour du graphique en secondes * 1000)) * 100 = Co-stop du CPU%
Ici, vous devez également faire attention au nombre de cœurs par VM et à l'intervalle de mesure.
Dans l'état costop, le noyau ne fait pas de travail utile. Avec la sélection correcte de la taille de la machine virtuelle et de la charge normale sur le serveur, le compteur de co-stop doit être proche de zéro.
 Dans ce cas, la charge est clairement anormale :)Que faire
Dans ce cas, la charge est clairement anormale :)Que faire Si plusieurs VM avec un grand nombre de cœurs s'exécutent sur le même hyperviseur et qu'il y a sursouscription par CPU, alors le compteur de co-stop peut augmenter, ce qui entraînera des problèmes avec les performances de ces VM.
En outre, le co-stop augmentera si les threads sont utilisés pour les noyaux actifs d'une machine virtuelle sur le même cœur de serveur physique avec l'hypertreading activé. Une telle situation peut se produire, par exemple, si la machine virtuelle a plus de cœurs qu'elle n'en a physiquement sur le serveur où elle fonctionne, ou si le paramètre «preferHT» est activé pour la machine virtuelle. Vous pouvez en savoir plus sur ce paramètre
ici .
Pour éviter les problèmes de performances de VM dus à un co-stop élevé, sélectionnez la taille de VM conformément aux recommandations du fabricant du logiciel qui s'exécute sur cette VM et avec les capacités du serveur physique sur lequel la VM s'exécute.
N'ajoutez pas de noyaux en réserve, cela peut entraîner des problèmes de performances non seulement de la machine virtuelle elle-même, mais également de ses voisins de serveur.
Autres mesures CPU utiles
Exécuter - combien de temps (ms) pour la période de mesure de vCPU était à l'état RUN, c'est-à-dire, a réellement effectué un travail utile.
Inactif - combien de temps (ms) pour la période de mesure de vCPU était inactive. Les valeurs d'inactivité élevées ne sont pas un problème, juste vCPU n'avait "rien à faire".
Wait - combien de temps (ms) pour la période de mesure du vCPU était à l'état Wait. Étant donné que IDLE est inclus dans ce compteur, les valeurs d'attente élevées n'indiquent pas non plus de problème. Mais si à l'attente élevée, l'inactivité est faible, la machine virtuelle attendait la fin des opérations d'E / S, ce qui, à son tour, peut indiquer un problème avec les performances du disque dur ou de certains périphériques de machine virtuelle.
Max limité - combien de temps (ms) pour la période de mesure du vCPU était à l'état Prêt en raison de la limite de ressources définie. Si les performances sont inexplicablement faibles, il est utile de vérifier la valeur de ce compteur et la limite du processeur dans les paramètres de la machine virtuelle. Les machines virtuelles peuvent en effet avoir des limites que vous ne connaissez pas. Par exemple, cela se produit lorsque la machine virtuelle a été inclinée à partir du modèle sur lequel la limite de processeur a été définie.
Swap wait - combien de temps le vCPU a attendu pour fonctionner avec VMkernel Swap pendant la période de mesure. Si les valeurs de ce compteur sont supérieures à zéro, la machine virtuelle a définitivement des problèmes de performances. Nous parlerons davantage de SWAP dans l'article sur les compteurs RAM.
ESXTOP
Si les compteurs de performances dans vCenter sont bons pour analyser les données historiques, alors l'analyse en ligne du problème est mieux effectuée dans ESXTOP. Ici, toutes les valeurs sont présentées sous forme finie (pas besoin de traduire quoi que ce soit), et la période de mesure minimale est de 2 secondes.
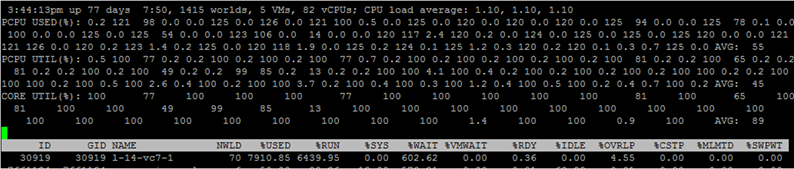
L'écran ESXTOP sur le CPU est appelé par la touche «c» et ressemble à ceci:

Pour plus de commodité, vous ne pouvez laisser que des processus de machine virtuelle en appuyant sur Maj-V.
Pour voir les métriques de chaque cœur de machine virtuelle, appuyez sur «e» et saisissez le GID de la machine virtuelle qui vous intéresse (30919 dans la capture d'écran ci-dessous):

Parcourez brièvement les colonnes présentées par défaut. Des colonnes supplémentaires peuvent être ajoutées en appuyant sur «f».
NWLD (Number of Worlds) - le nombre de processus dans le groupe. Pour étendre le groupe et voir les métriques de chaque processus (par exemple, pour chaque cœur d'une machine virtuelle multicœur), appuyez sur «e». Si un groupe a plusieurs processus, les valeurs des métriques pour le groupe sont égales à la somme des métriques pour les processus individuels.
% USED - combien de cycles le processeur du serveur utilise un processus ou un groupe de processus.
% RUN - combien de temps pendant la période de mesure le processus était à l'état RUN, c.-à-d. effectué un travail utile. Il diffère de% USED en ce qu'il ne prend pas en compte l'hyper-threading, la mise à l'échelle des fréquences et le temps passé sur les tâches système (% SYS).
% SYS - temps consacré aux tâches système, par exemple: gestion des interruptions, entrées / sorties, fonctionnement du réseau, etc. La valeur peut être élevée s'il y a beaucoup d'entrées / sorties sur la VM.
% OVRLP - combien de temps le noyau physique sur lequel le processus VM s'exécute a passé sur les tâches d'autres processus.
Ces mesures sont liées comme suit:
% USED =% RUN +% SYS -% OVRLP.
La mesure% USED est généralement plus informative.
% WAIT - combien de temps pendant la période de mesure le processus était en état d'attente. Comprend IDLE.
% IDLE - combien de temps le processus était en état IDLE pendant la période de mesure.
% SWPWT - combien de temps vCPU a-t-il attendu pour fonctionner avec VMkernel Swap pendant la période de mesure.
% VMWAIT - combien de temps le vCPU était dans l'état d'attente d'un événement (généralement des E / S) pendant la période de mesure. Il n'y a pas de compteur similaire dans vCenter. Des valeurs élevées indiquent des problèmes d'entrée / sortie sur la machine virtuelle.
% WAIT =% VMWAIT +% IDLE +% SWPWT.
Si la machine virtuelle n'utilise pas VMkernel Swap, alors lors de l'analyse des problèmes de performances, il est conseillé de regarder% VMWAIT, car cette métrique ne prend pas en compte le moment où la machine virtuelle n'a rien fait (% IDLE).
% RDY - combien de temps le processus était à l'état Prêt pendant la période de mesure.
% CSTP - combien de temps le processus était dans l'état de post pendant la période de mesure.
% MLMTD - combien de temps pendant la période de mesure du vCPU était à l'état Prêt en raison de la limite de ressources définie.
% WAIT +% RDY +% CSTP +% RUN = 100% - le cœur de la VM est toujours dans l'un de ces quatre états.
CPU sur l'hyperviseur
Il existe également des compteurs de performances CPU pour l'hyperviseur dans vCenter, mais ils ne représentent rien d'intéressant - c'est juste la somme des compteurs pour toutes les VM sur le serveur.
La façon la plus pratique de voir l'état du CPU sur le serveur est sur l'onglet Résumé:

Pour le serveur, ainsi que pour la machine virtuelle, il existe une alarme standard:
Avec une charge élevée sur le processeur du serveur, les machines virtuelles exécutées sur celui-ci commencent à rencontrer des problèmes de performances.
Dans ESXTOP, les données d'utilisation du processeur du serveur sont présentées en haut de l'écran. En plus de la charge CPU standard, qui n'est pas informative pour les hyperviseurs, il existe trois autres mesures:
CORE UTIL (%) - chargement du cœur du serveur physique. Ce compteur montre combien de temps le noyau a effectué le travail pendant la période de mesure.
PCPU UTIL (%) - si l'hyper-threading est activé, il y a deux threads (PCPU) pour chaque noyau physique. Cette mesure montre combien de temps chaque thread a effectué le travail.
PCPU USED (%) est le même que PCPU UTIL (%), mais il prend en compte la mise à l'échelle de la fréquence (soit en abaissant la fréquence centrale pour économiser l'énergie ou en augmentant la fréquence centrale en raison de la technologie Turbo Boost) et l'hyper-threading.
PCPU_USED% = PCPU_UTIL% * fréquence de coeur effective / fréquence de coeur nominale.
 Dans cette capture d'écran, pour certains cœurs, en raison du fonctionnement de Turbo Boost, la valeur USED est supérieure à 100%, car la fréquence du cœur est supérieure à la valeur nominale.
Dans cette capture d'écran, pour certains cœurs, en raison du fonctionnement de Turbo Boost, la valeur USED est supérieure à 100%, car la fréquence du cœur est supérieure à la valeur nominale.Quelques mots sur la prise en compte de l'hyper-threading. Si les processus s'exécutent 100% du temps sur les deux threads du cœur physique du serveur, tandis que le cœur s'exécute à la fréquence nominale, alors:
- CORE UTIL pour le noyau sera de 100%,
- PCPU UTIL pour les deux threads sera de 100%,
- PCED USED pour les deux threads sera de 50%.
Si les deux threads n'ont pas fonctionné 100% du temps pendant la période de mesure, alors dans les périodes où les threads ont travaillé en parallèle, le PCPU UTILISÉ pour les cœurs est divisé en deux.
ESXTOP dispose également d'un écran avec les paramètres de consommation d'énergie du serveur CPU. Ici, vous pouvez voir si le serveur utilise des technologies d'économie d'énergie: états C et états P. Appelé par la touche p:

Problèmes courants de performances du processeur
Enfin, je vais passer en revue les raisons typiques des problèmes de performances de la machine virtuelle du processeur et donner quelques conseils pour les résoudre:
Pas assez de vitesse d'horloge de base. S'il n'y a aucun moyen de transférer des machines virtuelles vers des noyaux plus efficaces, vous pouvez essayer de modifier les paramètres d'énergie pour que Turbo Boost fonctionne plus efficacement.
Mauvais dimensionnement de la machine virtuelle (trop / peu de cœurs). Si vous mettez quelques cœurs, il y aura une charge élevée sur le CPU VM. Si beaucoup, attrapez un co-stop élevé.
Sursouscription importante sur le CPU du serveur. Si la machine virtuelle est prête élevée, réduisez la sursouscription sur le processeur.
Topologie NUMA incorrecte sur les grandes machines virtuelles. La topologie NUMA que la machine virtuelle voit (vNUMA) doit correspondre à la topologie du serveur NUMA (pNUMA). À propos des diagnostics et des solutions possibles à ce problème est écrit, par exemple, dans le livre
"VMware vSphere 6.5 Host Resources Deep Dive" . Si vous ne voulez pas aller plus loin et que vous n'avez pas de restrictions de licence sur le système d'exploitation installé sur la machine virtuelle, faites beaucoup de sockets virtuels sur la machine virtuelle sur un cœur. Vous ne perdrez pas grand-chose :)
C'est tout pour le CPU. Posez des questions. Dans la
partie suivante, je parlerai de la RAM.