Dans les articles précédents, nous avons discuté du
moteur d'indexation PostgreSQL, de l'interface des méthodes d'accès et des méthodes suivantes:
index de hachage ,
arbres B ,
GiST ,
SP-GiST ,
GIN et
RUM . Le sujet de cet article est les index BRIN.
Brin
Concept général
Contrairement aux index avec lesquels nous avons déjà été rassemblés, l'idée de BRIN est d'éviter de parcourir des lignes définitivement inadaptées plutôt que de trouver rapidement celles qui correspondent. Il s'agit toujours d'un index inexact: il ne contient pas du tout de TID de lignes de table.
Simplement, BRIN fonctionne bien pour les colonnes où les valeurs sont en corrélation avec leur emplacement physique dans le tableau. En d'autres termes, si une requête sans clause ORDER BY renvoie les valeurs de colonne virtuellement dans l'ordre croissant ou décroissant (et qu'il n'y a pas d'index sur cette colonne).
Cette méthode d'accès a été créée dans le cadre d'
Axle , le projet européen de très grandes bases de données analytiques, avec un œil sur des tables de plusieurs téraoctets ou des dizaines de téraoctets. Une caractéristique importante de BRIN qui nous permet de créer des index sur de telles tables est une petite taille et des frais généraux minimaux de maintenance.
Cela fonctionne comme suit. Le tableau est divisé en
plages de plusieurs pages (ou de plusieurs blocs, ce qui est le même) - d'où le nom: Block Range Index, BRIN. L'index stocke
des informations récapitulatives sur les données de chaque plage. En règle générale, ce sont les valeurs minimales et maximales, mais il se trouve qu'elles sont différentes, comme indiqué plus loin. Supposons qu'une requête soit exécutée contenant la condition d'une colonne; si les valeurs recherchées n'entrent pas dans l'intervalle, toute la plage peut être ignorée; mais s'ils obtiennent, toutes les lignes de tous les blocs devront être parcourues pour choisir celles qui correspondent entre elles.
Ce ne sera pas une erreur de traiter BRIN non pas comme un index, mais comme un accélérateur de balayage séquentiel. Nous pouvons considérer BRIN comme une alternative au partitionnement si nous considérons chaque plage comme une partition "virtuelle".
Voyons maintenant la structure de l'index plus en détail.
La structure
La première page (plus exactement, zéro) contient les métadonnées.
Les pages contenant les informations récapitulatives sont situées à un certain décalage par rapport aux métadonnées. Chaque ligne d'index de ces pages contient des informations récapitulatives sur une plage.
Entre la méta page et les données récapitulatives, des pages avec la
carte de plage inversée (abrégée en "revmap") sont localisées. En fait, il s'agit d'un tableau de pointeurs (TID) vers les lignes d'index correspondantes.
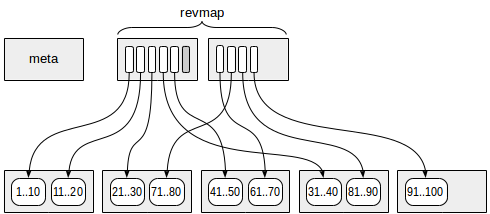
Pour certaines plages, le pointeur dans "revmap" peut conduire à aucune ligne d'index (une est marquée en gris sur la figure). Dans un tel cas, la plage est considérée comme n'ayant pas encore d'informations récapitulatives.
Numérisation de l'index
Comment l'index est-il utilisé s'il ne contient pas de références aux lignes de table? Cette méthode d'accès ne peut certainement pas renvoyer des lignes TID par TID, mais elle peut créer un bitmap. Il peut y avoir deux types de pages bitmap: précises, sur la ligne et inexactes, sur la page. C'est un bitmap inexact qui est utilisé.
L'algorithme est simple. La carte des plages est balayée séquentiellement (c'est-à-dire que les plages sont parcourues dans l'ordre de leur emplacement dans le tableau). Les pointeurs sont utilisés pour déterminer les lignes d'index avec des informations récapitulatives sur chaque plage. Si une plage ne contient pas la valeur recherchée, elle est ignorée et si elle peut contenir la valeur (ou si les informations récapitulatives ne sont pas disponibles), toutes les pages de la plage sont ajoutées au bitmap. Le bitmap résultant est ensuite utilisé comme d'habitude.
Mise à jour de l'index
Il est plus intéressant de savoir comment l'index est mis à jour lorsque la table est modifiée.
Lors de l'
ajout d' une nouvelle version d'une ligne à une page de table, nous déterminons dans quelle plage elle est contenue et utilisons la carte des plages pour trouver la ligne d'index avec les informations récapitulatives. Ce sont toutes de simples opérations arithmétiques. Soit, par exemple, la taille d'une plage de quatre et à la page 13, une version de ligne avec la valeur 42 se produit. Le numéro de la plage (commençant par zéro) est 13/4 = 3, par conséquent, dans "revmap", nous prenons le pointeur avec le décalage de 3 (son numéro d'ordre est quatre).
La valeur minimale pour cette plage est 31, et la valeur maximale est 40. Puisque la nouvelle valeur de 42 est hors de l'intervalle, nous mettons à jour la valeur maximale (voir la figure). Mais si la nouvelle valeur est toujours dans les limites stockées, l'index n'a pas besoin d'être mis à jour.

Tout cela concerne la situation où la nouvelle version de la page se produit dans une plage pour laquelle les informations récapitulatives sont disponibles. Lorsque l'index est créé, les informations récapitulatives sont calculées pour toutes les plages disponibles, mais tandis que le tableau est davantage développé, de nouvelles pages peuvent apparaître qui sortent des limites. Deux options sont disponibles ici:
- Généralement, l'index n'est pas mis à jour immédiatement. Ce n'est pas un gros problème: comme déjà mentionné, lors de la numérisation de l'index, toute la plage sera examinée. La mise à jour réelle est effectuée pendant le "vide", ou elle peut être effectuée manuellement en appelant la fonction "brin_summarize_new_values".
- Si nous créons l'index avec le paramètre "autosummarize", la mise à jour se fera immédiatement. Mais lorsque les pages de la plage sont remplies de nouvelles valeurs, les mises à jour peuvent se produire trop souvent, par conséquent, ce paramètre est désactivé par défaut.
Lorsque de nouvelles plages se produisent, la taille de "revmap" peut augmenter. Chaque fois que la carte, située entre la méta-page et les données récapitulatives, doit être étendue d'une autre page, les versions de lignes existantes sont déplacées vers d'autres pages. Ainsi, la carte des plages est toujours située entre la méta-page et les données récapitulatives.
Lorsqu'une ligne est
supprimée , ... rien ne se passe. On peut remarquer que parfois la valeur minimale ou maximale sera supprimée, auquel cas l'intervalle pourrait être réduit. Mais pour détecter cela, il faudrait lire toutes les valeurs de la plage, ce qui est coûteux.
L'exactitude de l'index n'est pas affectée, mais la recherche peut nécessiter de parcourir plus de plages que ce qui est réellement nécessaire. En général, les informations récapitulatives peuvent être recalculées manuellement pour une telle zone (en appelant les fonctions "brin_desummarize_range" et "brin_summarize_new_values"), mais comment détecter un tel besoin? Quoi qu'il en soit, aucune procédure conventionnelle n'est disponible à cette fin.
Enfin, la
mise à jour d'une ligne est simplement une suppression de la version obsolète et l'ajout d'une nouvelle.
Exemple
Essayons de construire notre propre mini-entrepôt de données pour les données des tables de la
base de données de démonstration . Supposons que, aux fins du reporting BI, un tableau dénormalisé soit nécessaire pour refléter les vols au départ d'un aéroport ou atterris à l'aéroport avec la précision d'un siège en cabine. Les données de chaque aéroport seront ajoutées au tableau une fois par jour, quand il est minuit dans le fuseau horaire approprié. Les données ne seront ni mises à jour ni supprimées.
Le tableau se présente comme suit:
demo=# create table flights_bi( airport_code char(3), airport_coord point,
Nous pouvons simuler la procédure de chargement des données à l'aide de boucles imbriquées: une externe par jours (nous considérerons
une grande base de données , donc 365 jours), et une boucle interne - par fuseaux horaires (de UTC + 02 à UTC + 12) . La requête est assez longue et n'a pas d'intérêt particulier, je vais donc la cacher sous le spoiler.
Simulation de chargement des données dans le stockage DO $$ <<local>> DECLARE curdate date := (SELECT min(scheduled_departure) FROM flights); utc_offset interval; BEGIN WHILE (curdate <= bookings.now()::date) LOOP utc_offset := interval '12 hours'; WHILE (utc_offset >= interval '2 hours') LOOP INSERT INTO flights_bi WITH flight ( airport_code, airport_coord, flight_id, flight_no, scheduled_time, actual_time, aircraft_code, flight_type ) AS ( ;
demo=# select count(*) from flights_bi;
count ---------- 30517076 (1 row)
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi'));
pg_size_pretty ---------------- 4127 MB (1 row)
Nous obtenons 30 millions de lignes et 4 Go. Pas si grand, mais assez bon pour un ordinateur portable: le balayage séquentiel m'a pris environ 10 secondes.
Sur quelles colonnes devons-nous créer l'index?
Étant donné que les index BRIN ont une petite taille et des frais généraux modérés et que les mises à jour se produisent rarement, le cas échéant, une occasion rare se présente de créer de nombreux index «au cas où», par exemple, sur tous les domaines sur lesquels les utilisateurs analystes peuvent créer leurs requêtes ad hoc. . Cela ne sera pas utile - tant pis, mais même un index qui n'est pas très efficace fonctionnera mieux que le scan séquentiel. Bien sûr, il y a des champs sur lesquels il est absolument inutile de construire un index; le pur bon sens les incitera.
Mais il devrait être étrange de se limiter à ce conseil, essayons donc d'énoncer un critère plus précis.
Nous avons déjà mentionné que les données doivent quelque peu correspondre à leur emplacement physique. Ici, il est logique de se rappeler que PostgreSQL collecte des statistiques de colonne de table, qui incluent la valeur de corrélation. Le planificateur utilise cette valeur pour choisir entre un scan d'index normal et un scan bitmap, et nous pouvons l'utiliser pour estimer l'applicabilité de l'index BRIN.
Dans l'exemple ci-dessus, les données sont évidemment ordonnées par jours (par "horaire_programmé", ainsi que par "heure_réelle" - il n'y a pas beaucoup de différence). En effet, lorsque des lignes sont ajoutées à la table (sans suppressions ni mises à jour), elles sont disposées l'une après l'autre dans le fichier. Dans la simulation du chargement des données, nous n'avons même pas utilisé la clause ORDER BY, par conséquent, les dates dans une journée peuvent généralement être mélangées de manière arbitraire, mais l'ordre doit être en place. Vérifions ceci:
demo=# analyze flights_bi; demo=# select attname, correlation from pg_stats where tablename='flights_bi' order by correlation desc nulls last;
attname | correlation --------------------+------------- scheduled_time | 0.999994 actual_time | 0.999994 fare_conditions | 0.796719 flight_type | 0.495937 airport_utc_offset | 0.438443 aircraft_code | 0.172262 airport_code | 0.0543143 flight_no | 0.0121366 seat_no | 0.00568042 passenger_name | 0.0046387 passenger_id | -0.00281272 airport_coord | (12 rows)
La valeur qui n'est pas trop proche de zéro (idéalement, près de plus-moins un, comme dans ce cas), nous indique que l'indice BRIN sera approprié.
La classe de voyage "fare_condition" (la colonne contient trois valeurs uniques) et le type de vol "flight_type" (deux valeurs uniques) semblaient être inopinément aux deuxième et troisième places. C'est une illusion: formellement, la corrélation est élevée, alors qu'en réalité sur plusieurs pages successives toutes les valeurs possibles seront rencontrées à coup sûr, ce qui signifie que BRIN ne fera aucun bien.
Le fuseau horaire "airport_utc_offset" va ensuite: dans l'exemple considéré, dans un cycle de jour, les aéroports sont classés par fuseaux horaires "par construction".
Ce sont ces deux domaines, le temps et le fuseau horaire, que nous allons approfondir avec.
Affaiblissement possible de la corrélation
La corrélation qui se fait "par construction" peut être facilement affaiblie lorsque les données sont modifiées. Et le problème ici n'est pas dans une modification d'une valeur particulière, mais dans la structure du contrôle d'accès simultané multiversion: la version de ligne obsolète est supprimée sur une page, mais une nouvelle version peut être insérée partout où de l'espace libre est disponible. Pour cette raison, des lignes entières se mélangent lors des mises à jour.
Nous pouvons contrôler partiellement cet effet en réduisant la valeur du paramètre de stockage "fillfactor" et en laissant ainsi de l'espace libre sur une page pour les futures mises à jour. Mais voulons-nous augmenter la taille d'une table déjà énorme? En outre, cela ne résout pas le problème des suppressions: ils "définissent également des interruptions" pour les nouvelles lignes en libérant de l'espace quelque part à l'intérieur des pages existantes. Pour cette raison, les lignes qui autrement arriveraient à la fin du fichier seront insérées à un endroit arbitraire.
Soit dit en passant, c'est un fait curieux. Étant donné que l'index BRIN ne contient pas de références aux lignes de table, sa disponibilité ne devrait pas du tout entraver les mises à jour HOT, mais c'est le cas.
Ainsi, BRIN est principalement conçu pour des tables de grandes et même de grandes tailles qui ne sont pas du tout mises à jour ou très légèrement mises à jour. Cependant, il s'adapte parfaitement à l'ajout de nouvelles lignes (à la fin du tableau). Cela n'est pas surprenant puisque cette méthode d'accès a été créée en vue des entrepôts de données et des rapports analytiques.
Quelle taille de gamme devons-nous sélectionner?
Si nous traitons une table de téraoctets, notre principale préoccupation lors du choix de la taille d'une plage sera probablement de ne pas rendre l'index BRIN trop grand. Cependant, dans notre situation, nous pouvons nous permettre d'analyser les données plus précisément.
Pour ce faire, nous pouvons sélectionner des valeurs uniques d'une colonne et voir sur combien de pages elles apparaissent. La localisation des valeurs augmente les chances de succès dans l'application de l'indice BRIN. De plus, le nombre de pages trouvé demandera la taille d'une plage. Mais si la valeur est "répartie" sur toutes les pages, BRIN est inutile.
Bien sûr, nous devons utiliser cette technique en gardant un œil vigilant sur la structure interne des données. Par exemple, cela n'a aucun sens de considérer chaque date (plus exactement, un horodatage, y compris l'heure) comme une valeur unique - nous devons l'arrondir aux jours.
Techniquement, cette analyse peut être effectuée en regardant la valeur de la colonne "ctid" cachée, qui fournit le pointeur vers une version de ligne (TID): le numéro de la page et le numéro de la ligne à l'intérieur de la page. Malheureusement, il n'y a pas de technique conventionnelle pour décomposer le TID en ses deux composants, par conséquent, nous devons transtyper les types à travers la représentation textuelle:
demo=# select min(numblk), round(avg(numblk)) avg, max(numblk) from ( select count(distinct (ctid::text::point)[0]) numblk from flights_bi group by scheduled_time::date ) t;
min | avg | max ------+------+------ 1192 | 1500 | 1796 (1 row)
demo=# select relpages from pg_class where relname = 'flights_bi';
relpages ---------- 528172 (1 row)
Nous pouvons voir que chaque jour est réparti de manière assez uniforme sur les pages et que les jours sont légèrement mélangés les uns aux autres (1500 et 365 fois = 547500, ce qui n'est que légèrement supérieur au nombre de pages du tableau 528172). C'est en fait clair "par construction" de toute façon.
Des informations précieuses ici sont un nombre spécifique de pages. Avec une taille de plage conventionnelle de 128 pages, chaque jour remplira 9 à 14 plages. Cela semble réaliste: avec une requête pour un jour spécifique, on peut s'attendre à une erreur autour de 10%.
Essayons:
demo=# create index on flights_bi using brin(scheduled_time);
La taille de l'index est aussi petite que 184 Ko:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_idx'));
pg_size_pretty ---------------- 184 kB (1 row)
Dans ce cas, il n'est guère logique d'augmenter la taille d'une plage au prix de perdre la précision. Mais nous pouvons réduire la taille si nécessaire, et la précision augmentera, au contraire (avec la taille de l'index).
Voyons maintenant les fuseaux horaires. Ici, nous ne pouvons pas non plus utiliser une approche par force brute. Toutes les valeurs doivent plutôt être divisées par le nombre de cycles journaliers, car la distribution est répétée chaque jour. De plus, comme il n'y a que peu de fuseaux horaires, nous pouvons regarder toute la distribution:
demo=# select airport_utc_offset, count(distinct (ctid::text::point)[0])/365 numblk from flights_bi group by airport_utc_offset order by 2;
airport_utc_offset | numblk --------------------+-------- 12:00:00 | 6 06:00:00 | 8 02:00:00 | 10 11:00:00 | 13 08:00:00 | 28 09:00:00 | 29 10:00:00 | 40 04:00:00 | 47 07:00:00 | 110 05:00:00 | 231 03:00:00 | 932 (11 rows)
En moyenne, les données pour chaque fuseau horaire peuplent 133 pages par jour, mais la distribution est très non uniforme: Petropavlovsk-Kamchatskiy et Anadyr ne comptent que six pages, tandis que Moscou et ses environs en nécessitent des centaines. La taille par défaut d'une plage n'est pas bonne ici; Par exemple, définissons-le sur quatre pages.
demo=# create index on flights_bi using brin(airport_utc_offset) with (pages_per_range=4); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_airport_utc_offset_idx'));
pg_size_pretty ---------------- 6528 kB (1 row)
Plan d'exécution
Voyons comment fonctionnent nos index. Sélectionnons un jour, disons, il y a une semaine (dans la base de données de démonstration, "aujourd'hui" est déterminé par la fonction "booking.now"):
demo=# \set d 'bookings.now()::date - interval \'7 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=10.282..94.328 rows=83954 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 12045 Heap Blocks: lossy=1664 -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=3.013..3.013 rows=16640 loops=1) Index Cond: ... Planning time: 0.375 ms Execution time: 97.805 ms
Comme nous pouvons le voir, le planificateur a utilisé l'index créé. Quelle est sa précision? Le rapport entre le nombre de lignes qui remplissent les conditions de requête ("lignes" du nœud Bitmap Heap Scan) et le nombre total de lignes renvoyées à l'aide de l'index (la même valeur plus les lignes supprimées par la vérification de l'index) nous en dit long. Dans ce cas 83954 / (83954 + 12045), ce qui représente environ 90%, comme prévu (cette valeur changera d'un jour à l'autre).
D'où vient le numéro 16640 dans les "lignes réelles" du nœud Bitmap Index Scan? Le fait est que ce nœud du plan crée un bitmap inexact (page par page) et ignore complètement le nombre de lignes que le bitmap touchera, tandis que quelque chose doit être affiché. Par conséquent, au désespoir, une page est censée contenir 10 lignes. Le bitmap contient 1664 pages au total (cette valeur est indiquée dans "Heap Blocks: lossy = 1664"); nous obtenons donc 16640. Au total, il s'agit d'un nombre insensé auquel nous ne devons pas prêter attention.
Et les aéroports? Par exemple, prenons le fuseau horaire de Vladivostok, qui remplit 28 pages par jour:
demo=# explain (costs off,analyze) select * from flights_bi where airport_utc_offset = interval '8 hours';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=75.151..192.210 rows=587353 loops=1) Recheck Cond: (airport_utc_offset = '08:00:00'::interval) Rows Removed by Index Recheck: 191318 Heap Blocks: lossy=13380 -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=74.999..74.999 rows=133800 loops=1) Index Cond: (airport_utc_offset = '08:00:00'::interval) Planning time: 0.168 ms Execution time: 212.278 ms
Le planificateur utilise à nouveau l'index BRIN créé. La précision est pire (environ 75% dans ce cas), mais cela est attendu car la corrélation est plus faible.
Plusieurs index BRIN (comme tous les autres) peuvent certainement être joints au niveau du bitmap. Par exemple, voici les données sur le fuseau horaire sélectionné pour un mois (notez le nœud "BitmapAnd"):
demo=# \set d 'bookings.now()::date - interval \'60 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '30 days' and airport_utc_offset = interval '8 hours';
QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=62.046..113.849 rows=48154 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 18856 Heap Blocks: lossy=1152 -> BitmapAnd (actual time=61.777..61.777 rows=0 loops=1) -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=5.490..5.490 rows=435200 loops=1) Index Cond: ... -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=55.068..55.068 rows=133800 loops=1) Index Cond: ... Planning time: 0.408 ms Execution time: 115.475 ms
Comparaison avec b-tree
Et si nous créons un index B-tree régulier sur le même champ que BRIN?
demo=# create index flights_bi_scheduled_time_btree on flights_bi(scheduled_time); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_btree'));
pg_size_pretty ---------------- 654 MB (1 row)
Il semblait être
plusieurs milliers de fois plus grand que notre BRIN! Cependant, la requête est effectuée un peu plus rapidement: le planificateur a utilisé des statistiques pour déterminer que les données sont physiquement ordonnées et qu'il n'est pas nécessaire de créer un bitmap et, principalement, que la condition d'index n'a pas besoin d'être revérifiée:
demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN ---------------------------------------------------------------- Index Scan using flights_bi_scheduled_time_btree on flights_bi (actual time=0.099..79.416 rows=83954 loops=1) Index Cond: ... Planning time: 0.500 ms Execution time: 85.044 ms
C'est ce qui est si merveilleux avec BRIN: nous sacrifions l'efficacité, mais gagnons beaucoup d'espace.
Classes d'opérateur
minmax
Pour les types de données dont les valeurs peuvent être comparées, les informations récapitulatives sont constituées des
valeurs minimale et maximale . Les noms des classes d'opérateurs correspondantes contiennent "minmax", par exemple, "date_minmax_ops". En fait, ce sont des types de données que nous envisagions jusqu'à présent, et la plupart des types sont de ce type.
inclus
Les opérateurs de comparaison ne sont pas définis pour tous les types de données. Par exemple, ils ne sont pas définis pour les points (type "point"), qui représentent les coordonnées géographiques des aéroports. Soit dit en passant, c'est pour cette raison que les statistiques ne montrent pas la corrélation pour cette colonne.
demo=# select attname, correlation from pg_stats where tablename='flights_bi' and attname = 'airport_coord';
attname | correlation ---------------+------------- airport_coord | (1 row)
Mais beaucoup de ces types nous permettent d'introduire un concept de "zone de délimitation", par exemple, un rectangle de délimitation pour les formes géométriques. Nous avons expliqué en détail comment l'index
GiST utilise cette fonctionnalité. De même, BRIN permet également de collecter des informations récapitulatives sur les colonnes ayant des types de données comme ceux-ci:
la zone de délimitation pour toutes les valeurs à l'intérieur d'une plage est juste la valeur récapitulative.
Contrairement à GiST, la valeur récapitulative pour BRIN doit être du même type que les valeurs indexées. Par conséquent, nous ne pouvons pas construire l'index des points, bien qu'il soit clair que les coordonnées pourraient fonctionner dans BRIN: la longitude est étroitement liée au fuseau horaire. Heureusement, rien n'empêche la création de l'index sur une expression après avoir transformé des points en rectangles dégénérés. Dans le même temps, nous allons définir la taille d'une plage sur une page, juste pour montrer le cas limite:
demo=# create index on flights_bi using brin (box(airport_coord)) with (pages_per_range=1);
La taille de l'indice est aussi petite que 30 Mo, même dans une situation aussi extrême:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_box_idx'));
pg_size_pretty ---------------- 30 MB (1 row)
Nous pouvons maintenant créer des requêtes qui limitent les aéroports par des coordonnées. Par exemple:
demo=# select airport_code, airport_name from airports where box(coordinates) <@ box '120,40,140,50';
airport_code | airport_name --------------+----------------- KHV | Khabarovsk-Novyi VVO | Vladivostok (2 rows)
Le planificateur refusera cependant d'utiliser notre index.
demo=# analyze flights_bi; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN --------------------------------------------------------------------- Seq Scan on flights_bi (cost=0.00..985928.14 rows=30517 width=111) Filter: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Pourquoi? Désactivons le scan séquentiel et voyons ce qui se passe:
demo=# set enable_seqscan = off; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (cost=14079.67..1000007.81 rows=30517 width=111) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) -> Bitmap Index Scan on flights_bi_box_idx (cost=0.00..14072.04 rows=30517076 width=0) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Il semble que l'index
peut être utilisé, mais le planificateur suppose que le bitmap devra être construit sur toute la table (regardez les "lignes" du nœud Bitmap Index Scan), et il n'est pas étonnant que le planificateur choisisse le balayage séquentiel dans ce cas. Le problème ici est que pour les types géométriques, PostgreSQL ne collecte aucune statistique et le planificateur doit y aller aveuglément:
demo=# select * from pg_stats where tablename = 'flights_bi_box_idx' \gx
-[ RECORD 1 ]----------+------------------- schemaname | bookings tablename | flights_bi_box_idx attname | box inherited | f null_frac | 0 avg_width | 32 n_distinct | 0 most_common_vals | most_common_freqs | histogram_bounds | correlation | most_common_elems | most_common_elem_freqs | elem_count_histogram |
Hélas. Mais il n'y a rien à redire sur l'indice - il fonctionne et fonctionne bien:
demo=# explain (costs off,analyze) select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=158.142..315.445 rows=781790 loops=1) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Rows Removed by Index Recheck: 70726 Heap Blocks: lossy=14772 -> Bitmap Index Scan on flights_bi_box_idx (actual time=158.083..158.083 rows=147720 loops=1) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Planning time: 0.137 ms Execution time: 340.593 ms
La conclusion doit être la suivante: PostGIS est nécessaire si quelque chose de non trivial est requis de la géométrie. Il peut de toute façon recueillir des statistiques.
Internes
L'extension conventionnelle "pageinspect" nous permet de regarder à l'intérieur de l'index BRIN.
Tout d'abord, la métainformation nous demandera la taille d'une plage et le nombre de pages allouées pour "revmap":
demo=# select * from brin_metapage_info(get_raw_page('flights_bi_scheduled_time_idx',0));
magic | version | pagesperrange | lastrevmappage ------------+---------+---------------+---------------- 0xA8109CFA | 1 | 128 | 3 (1 row)
Les pages 1-3 ici sont allouées pour "revmap", tandis que les autres contiennent des données récapitulatives. De "revmap", nous pouvons obtenir des références aux données récapitulatives pour chaque plage. Disons que les informations sur la première gamme, comprenant les 128 premières pages, se trouvent ici:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) limit 1;
pages --------- (6,197) (1 row)
Et voici les données récapitulatives elles-mêmes:
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 197;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 02:45:00+03 .. 2016-08-15 17:15:00+03} (1 row)
Gamme suivante:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) offset 1 limit 1;
pages --------- (6,198) (1 row)
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 198;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 06:00:00+03 .. 2016-08-15 18:55:00+03} (1 row)
Et ainsi de suite.
Pour les classes "inclusion", le champ "valeur" affichera quelque chose comme
{(94.4005966186523,69.3110961914062),(77.6600036621,51.6693992614746) .. f .. f}
La première valeur est le rectangle d'intégration, et les lettres "f" à la fin indiquent qu'il manque des éléments vides (le premier) et des valeurs non fusionnables (le second). En fait, les seules valeurs non fusionnables sont les adresses "IPv4" et "IPv6" (type de données "inet").
Propriétés
Vous rappelant les requêtes qui
ont déjà été fournies .
Voici les propriétés de la méthode d'accès:
amname | name | pg_indexam_has_property --------+---------------+------------------------- brin | can_order | f brin | can_unique | f brin | can_multi_col | t brin | can_exclude | f
Les index peuvent être créés sur plusieurs colonnes. Dans ce cas, ses propres statistiques récapitulatives sont collectées pour chaque colonne, mais elles sont stockées ensemble pour chaque plage. Bien sûr, cet indice est logique si une seule et même taille de plage convient à toutes les colonnes.
Les propriétés de couche d'index suivantes sont disponibles:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | f bitmap_scan | t backward_scan | f
Évidemment, seul le scan bitmap est pris en charge.
Cependant, le manque de clustering peut sembler déroutant. Apparemment, puisque l'index BRIN est sensible à l'ordre physique des lignes, il serait logique de pouvoir regrouper les données en fonction de l'index. Mais ce n'est pas le cas. On ne peut que créer un index «régulier» (B-tree ou GiST, selon le type de données) et le clusterer en fonction de celui-ci. Soit dit en passant, souhaitez-vous regrouper une table supposée énorme en tenant compte des verrous exclusifs, du temps d'exécution et de la consommation d'espace disque lors de la reconstruction?
Les propriétés des couches de colonnes sont les suivantes:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | t
La seule propriété disponible est la possibilité de manipuler des valeurs NULL.
Continuez à lire .