
La technologie d'Harry Potter a survécu à ce jour. Maintenant, pour créer une vidéo à part entière d'une personne, une seule de ses photos ou photos suffit. Des chercheurs en apprentissage automatique de Skolkovo et du Samsung AI Center de Moscou ont publié leurs travaux sur la création d'un tel système, ainsi qu'un certain nombre de vidéos de célébrités et d'objets d'art qui ont reçu une nouvelle vie.

Le texte des travaux scientifiques peut être lu ici . Tout y est assez intéressant, avec beaucoup de formules, mais le sens est simple: leur système est guidé par des "repères", des vues du visage, comme un nez, deux yeux, deux sourcils et la ligne du menton. Elle saisit donc instantanément ce qu'est une personne. Et puis, il peut transférer tout le reste (couleur, texture du visage, moustache, chaume, etc.) vers la vidéo de toute autre personne. Adapter l'ancien visage à de nouvelles situations.
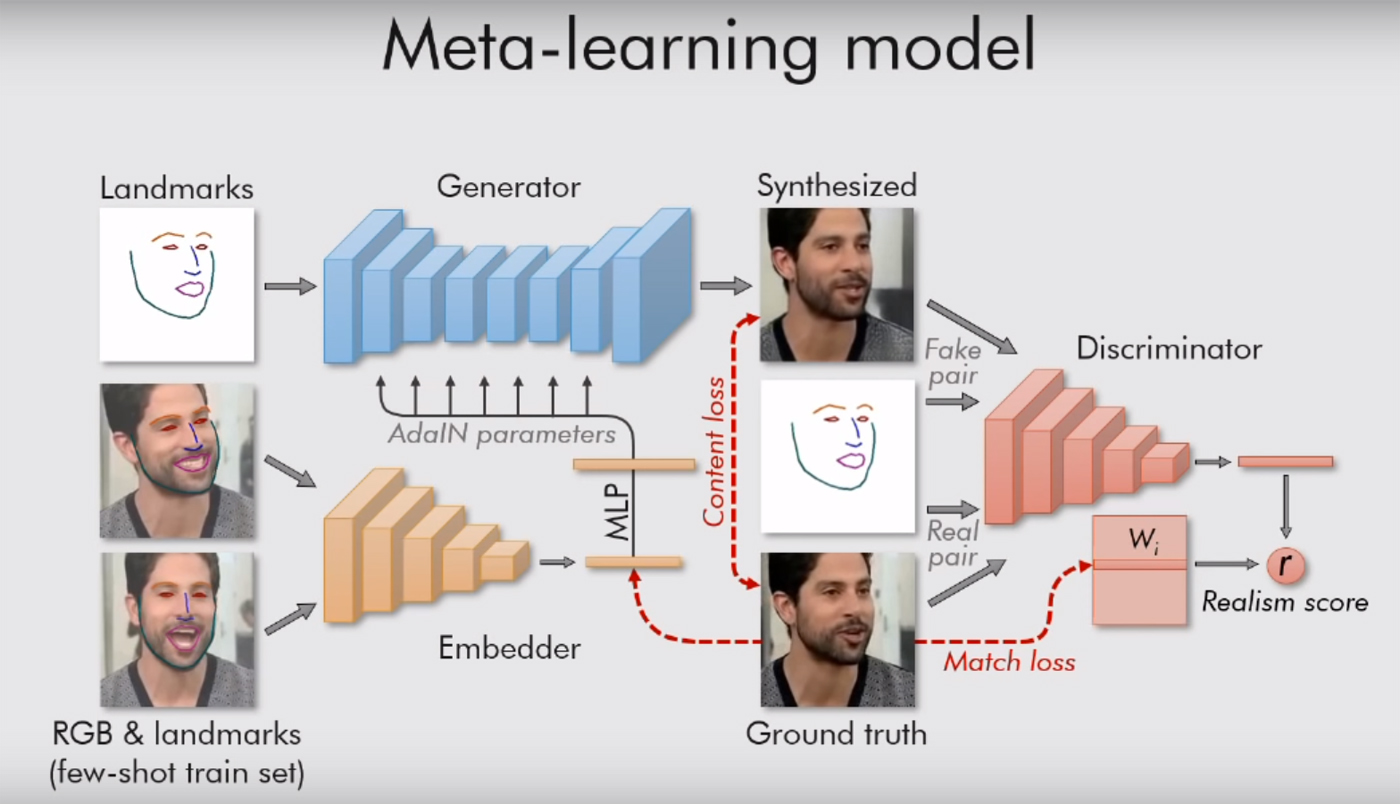
Bien sûr, cela ne fonctionne que sur les portraits. Le modèle n'a besoin que d'une seule personne, le visage tourné vers nous, pour qu'il puisse au moins voir les deux yeux. Ensuite, le système peut tout faire avec, lui transmettre toutes les expressions faciales. Il suffit de lui donner une vidéo appropriée (avec une autre personne avec la tête à peu près dans la même position).
Plus tôt, AI avait déjà appris à faire des diphasés, et les internautes se moquaient noblement des célébrités en insérant leur visage dans le porno et en créant des mèmes avec Nicholas Cage. Mais pour cela, ils ont dû former les algorithmes en mégaoctets (ou mieux - gigaoctets) de données, pour trouver autant d'images et de vidéos avec des visages de célébrités que possible afin de produire un résultat plus ou moins décent. Le créateur de Deepfakes lui-même a déclaré qu'il fallait 8 à 12 heures pour compiler une courte vidéo. Le nouveau système génère le résultat instantanément et à l'entrée, il n'a besoin que d'une seule image.
Avec le système précédent, nous ne pourrions jamais regarder la Joconde vivante, nous n'avons qu'un seul angle. Maintenant, avec les algorithmes de benchmarking, cela devient possible. L'idéal n'est pas atteint, mais quelque chose est déjà proche.

Les chercheurs moscovites utilisent également un réseau génératif-contradictoire. Deux modèles de l'algorithme se battent. Chacune essaie de tromper l'adversaire et lui prouve que la vidéo qu'elle crée est réelle. De cette manière, un certain réalisme est atteint: une image d'un visage humain n'est pas rendue «dans la lumière» si le modèle critique n'est pas à plus de 90% sûr de son authenticité. Comme le disent les auteurs dans leur travail, des dizaines de millions de paramètres sont régulés dans les images, mais grâce à un tel système, le travail bout très vite.

S'il y a plusieurs images, le résultat s'améliore. Encore une fois, la façon la plus simple est de travailler avec des célébrités qui sont déjà prises sous tous les angles possibles. Pour atteindre le «réalisme idéal», 32 plans sont nécessaires. Dans ce cas, les photos AI générées en basse résolution ne se distingueront pas des vraies photos humaines. Les personnes non formées à ce stade ne sont plus en mesure d'identifier un faux - peut-être que les chances restent avec des experts ou des proches parents de «l'expérimental» de toutes ces images.
S'il n'y a qu'une seule photo ou image, le résultat n'est pas toujours le meilleur. Vous pouvez voir des artefacts sur la vidéo lorsque la tête est en mouvement sans aucun problème. Les chercheurs eux-mêmes disent que leur point faible est le regard. Le modèle basé sur les repères du visage ne comprend pas encore toujours comment et où une personne doit regarder.
