
Salut! Dans cet article, je veux expliquer, en termes simples, comment le
vol apparaît dans les machines virtuelles et vous parler de certains des artefacts moins évidents que nous avons trouvés lors de recherches sur le sujet dans lequel j'étais impliqué en tant que CTO du
Mail. com Plateforme
Cloud Solutions . La plateforme exécute KVM.
Le temps de vol du processeur est le temps pendant lequel une machine virtuelle ne reçoit pas les ressources nécessaires pour fonctionner. Ce temps ne peut être calculé que dans un système d'exploitation invité dans des environnements de virtualisation. Il est extrêmement difficile de savoir où les ressources allouées sont perdues, tout comme dans des situations réelles. Cependant, nous avons décidé de le comprendre et nous avons même effectué une série de tests pour le faire. Cela ne veut pas dire que nous savons tout sur le
vol, mais il y a des choses fascinantes que nous aimerions partager avec vous.
1. Qu'est-ce que voler ?
Steal est une métrique qui indique un manque de temps CPU pour les processus VM. Comme décrit dans le
correctif du noyau KVM , le
vol est le temps qu'un hyperviseur passe à exécuter d'autres processus dans un système d'exploitation hôte, tandis que le processus VM est dans une file d'attente d'exécution. En d'autres termes, le
vol est calculé comme la différence entre le moment où un processus est prêt à s'exécuter et le moment où le temps CPU est alloué au processus.
Le noyau VM obtient la métrique de
vol de l'hyperviseur. L'hyperviseur ne spécifie pas les processus qu'il exécute. Il dit simplement: "Je suis occupé et je ne peux pas vous accorder de temps." Dans un KVM, le calcul de
vol est pris en charge dans les
correctifs . Il y a deux points principaux à ce sujet:
- Une machine virtuelle apprend à voler de l'hyperviseur. Cela signifie qu'en termes de pertes, le vol est une mesure indirecte qui peut être déformée de plusieurs manières.
- L'hyperviseur ne partage pas avec la machine virtuelle les informations sur ce qui la préoccupe. Le point le plus crucial est qu'il ne lui accorde pas de temps. La VM elle-même, par conséquent, ne peut pas détecter les distorsions dans la métrique de vol , qui pourraient être estimées par la nature des processus concurrents.
2. Qu'est-ce qui affecte le vol ?
2.1. Calcul du vol
Essentiellement, le
vol est calculé plus ou moins de la même manière que le temps d'utilisation du processeur. Il n'y a pas beaucoup d'informations sur la façon dont l'utilisation est calculée. C'est probablement parce que la plupart des professionnels pensent que c'est évident. Cependant, il y a quelques pièges. Le processus est décrit dans
un article de Brendann Gregg . Il discute d'une multitude de nuances concernant la façon de calculer l'utilisation et les scénarios dans lesquels le calcul sera erroné:
- Surchauffe et limitation du processeur.
- Activer / désactiver Turbo Boost, entraînant une modification de la fréquence d'horloge du processeur.
- Changement de tranche de temps qui se produit lorsque des technologies d'économie d'énergie du processeur, par exemple SpeedStep, sont utilisées.
- Problèmes liés au calcul des moyennes: mesurer l'utilisation pendant une minute à 80% de la puissance pourrait masquer un coup de pouce à court terme de 100%.
- Un verrou tournant qui se traduit par un scénario dans lequel le processeur est utilisé, mais le processus utilisateur ne progresse pas. Par conséquent, l'utilisation calculée du processeur sera de 100%, mais le processus ne consommera pas réellement de temps processeur.
Je n'ai trouvé aucun article décrivant de tels calculs de
vol (si vous en connaissez, veuillez les partager dans la section commentaires). Comme vous pouvez le voir dans le code source, le mécanisme de calcul est le même que pour l'utilisation. La seule différence est qu'un autre compteur est ajouté spécifiquement pour le processus KVM (processus VM), qui calcule la durée pendant laquelle le processus KVM attend le temps CPU. Le compteur prend les données sur le CPU à partir de ses spécifications et vérifie si tous ses ticks sont utilisés par le processus VM. Si tous les ticks sont utilisés, alors le CPU n'était occupé que par le processus VM. Sinon, nous savons que le CPU faisait autre chose et le
vol apparaît.
Le processus par lequel le
vol est calculé est soumis aux mêmes problèmes que le calcul régulier de l'utilisation. Ces problèmes ne sont pas si courants, mais ils peuvent sembler assez déroutants.
2.2. Types de virtualisation KVM
En général, il existe trois types de virtualisation, et ils sont tous pris en charge par un KVM. Le mécanisme par lequel le
vol se produit peut dépendre du type de virtualisation.
La traduction Dans ce cas, le VM OS fonctionnera avec les périphériques d'hyperviseur physique de la manière suivante:
- L'OS invité envoie une commande à son appareil invité.
- Le pilote de périphérique invité accepte la commande, crée une demande de périphérique BIOS et envoie la commande à l'hyperviseur.
- Le processus de l'hyperviseur traduit la commande en une commande de périphérique physique, ce qui la rend plus sécurisée, entre autres.
- Le pilote de périphérique physique accepte la commande modifiée et la transmet au périphérique physique lui-même.
- Les résultats d'exécution de la commande retournent en suivant le même chemin.
L'avantage de la traduction est qu'elle nous permet d'émuler n'importe quel appareil et ne nécessite aucune préparation spéciale du noyau du système d'exploitation. Mais cela se fait au détriment des performances.
Virtualisation matérielle. Dans ce cas, un appareil reçoit des commandes du système d'exploitation au niveau matériel. C'est la méthode la plus rapide et la meilleure dans l'ensemble. Malheureusement, tous les appareils physiques, hyperviseurs et systèmes d'exploitation invités ne le prennent pas en charge. Pour l'instant, les principaux appareils prenant en charge la virtualisation matérielle sont les processeurs.
Paravirtualisation. L'option la plus courante pour la virtualisation de périphériques sur un KVM et le type de virtualisation le plus répandu pour les systèmes d'exploitation invités. Sa principale caractéristique est qu'il fonctionne avec certains sous-systèmes d'hyperviseur (par exemple, réseau ou pile de lecteurs) et alloue des pages de mémoire à l'aide d'une API d'hyperviseur sans traduire les commandes de bas niveau. L'inconvénient de cette méthode de virtualisation est la nécessité de modifier le noyau du système d'exploitation invité pour permettre l'interaction avec l'hyperviseur à l'aide de la même API. La solution la plus courante à ce problème consiste à installer des pilotes spéciaux dans le système d'exploitation invité. Dans un KVM, cette API est appelée une
API virtio .
Lorsque la paravirtualisation est utilisée, le chemin vers le périphérique physique est beaucoup plus court que dans les cas où la traduction est utilisée, car les commandes sont envoyées directement de la machine virtuelle au processus d'hyperviseur de l'hôte. Cela accélère l'exécution de toutes les instructions au sein de la machine virtuelle. Dans un KVM, une API virtio en est responsable. Cela ne fonctionne que pour certains appareils comme le réseau et les adaptateurs de lecteur. C'est pourquoi les pilotes virtio sont installés sur les machines virtuelles.
Le revers d'une telle accélération est que tous les processus exécutés dans une machine virtuelle ne restent pas dans la machine virtuelle. Il en résulte un certain nombre d'effets, qui peuvent provoquer un
vol . Si vous souhaitez en savoir plus, commencez par
une API pour les E / S virtuelles: virtio .
2.3. Planification équitable
Une VM sur un hyperviseur est, en fait, un processus régulier, qui est soumis à des lois d'ordonnancement (répartition des ressources entre les processus) dans un noyau Linux. Examinons cela de plus près.
Linux utilise le soi-disant CFS, Completely Fair Scheduler, qui est devenu la valeur par défaut avec le noyau 2.6.23. Pour vous familiariser avec cet algorithme, lisez Architecture du noyau Linux ou le code source. L'essence de CFS réside dans la répartition du temps CPU entre les processus, en fonction de leur temps d'exécution. Plus un processus nécessite de temps CPU, moins il obtient de temps CPU. Cela garantit l'exécution «équitable» de tous les processus et permet d'éviter qu'un processus ne prenne tout le temps tous les processeurs et permette à d'autres processus de s'exécuter également.
Parfois, ce paradigme se traduit par des artefacts intéressants. Les utilisateurs de longue date de Linux se souviendront sans aucun doute de la façon dont un éditeur de texte normal sur le bureau se figerait lors de l'exécution d'applications gourmandes en ressources comme un compilateur. Cela est dû au fait que les tâches allégées en ressources, telles que les applications de bureau, étaient en concurrence avec des tâches utilisant de nombreuses ressources, comme un compilateur. CFS considère que cela est injuste et arrête donc l'éditeur de texte de temps en temps et laisse le processeur traiter les tâches du compilateur. Ce
problème a été résolu à l'aide du mécanisme
sched_autogroup ; il existe cependant de nombreuses autres particularités de la distribution du temps CPU. Cet article ne traite pas vraiment de la gravité du SFC. C'est plutôt une tentative pour attirer l'attention sur le fait que la distribution "équitable" du temps CPU n'est pas la tâche la plus triviale.
Un autre aspect important d'un planificateur est la préemption. Cela est nécessaire pour débarrasser le processeur de tous les processus exagérés et permettre aux autres de fonctionner également. C'est ce qu'on appelle le
changement de contexte . L'ensemble du contexte de tâche est conservé: état de la pile, registres, etc., après quoi le processus est laissé en attente et est remplacé par un autre processus. Il s'agit d'une opération coûteuse pour un système d'exploitation. Il est rarement utilisé, mais ce n'est pas mal du tout. Un changement de contexte fréquent peut être un indicateur d'un problème de système d'exploitation, mais il se produit généralement en continu et n'est pas le signe d'un problème en particulier.
Ce long discours était nécessaire pour expliquer un fait: dans un ordonnanceur Linux équitable, plus le processus consomme de ressources CPU, plus il sera arrêté rapidement pour permettre à d'autres processus de fonctionner. Que ce soit correct ou non est une question complexe, et la solution est différente selon la charge. Jusqu'à récemment, le planificateur Windows donnait la priorité aux applications de bureau, ce qui ralentissait les processus d'arrière-plan. Dans Sun Solaris, il y avait cinq classes d'ordonnanceur différentes. Lorsque la virtualisation a été introduite, ils en ont ajouté un autre,
Fair share scheduler , car les autres ne fonctionnaient pas correctement avec la virtualisation Solaris Zones. Pour approfondir cela, je recommande de commencer avec
Solaris Internals: Solaris 10 et OpenSolaris Kernel Architecture ou
Comprendre le noyau Linux .
2.4. Comment surveiller le vol ?
Comme pour toute autre mesure du processeur, il est facile de surveiller le
vol dans une machine virtuelle. Vous pouvez utiliser n'importe quel outil de mesure métrique CPU. L'essentiel est que la VM doit être sous Linux. Pour une raison quelconque, Windows ne fournit pas ces informations à l'utilisateur. :(
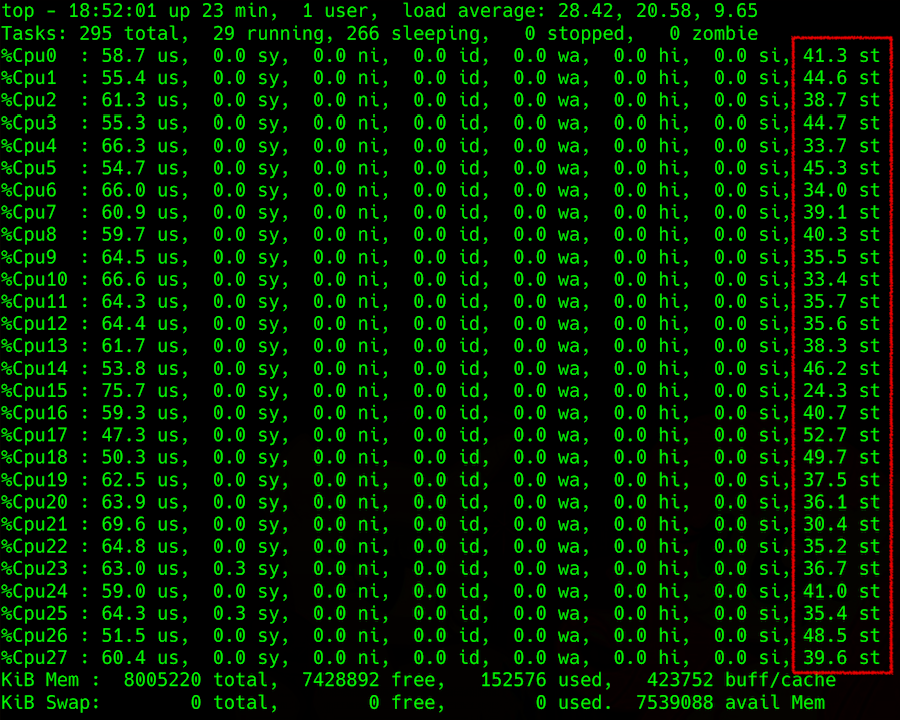 sortie supérieure: spécification de la charge du processeur avec vol dans la colonne de droite
sortie supérieure: spécification de la charge du processeur avec vol dans la colonne de droiteLes choses se compliquent lorsqu'on essaie d'obtenir ces informations d'un hyperviseur. Vous pouvez essayer de prévoir le
vol sur une machine hôte, en utilisant Load Average (LA), par exemple. Il s'agit de la valeur moyenne du nombre de processus dans la file d'attente d'exécution. La méthode de calcul de ce paramètre n'est pas simple, mais en général, si un LA normalisé en fonction du nombre de threads CPU est supérieur à 1, cela signifie que le serveur Linux est surchargé.
Alors, qu'attendent tous ces processus? De toute évidence, le CPU. Cette réponse n'est cependant pas tout à fait exacte, car parfois le CPU est libre et le LA est beaucoup trop élevé. N'oubliez pas
que NFS tombe et LA augmente en même temps . Une situation similaire peut se produire avec le lecteur et d'autres périphériques d'entrée / sortie. En fait, les processus peuvent attendre la fin d'un verrou: physique (lié aux périphériques d'entrée / sortie) ou logique (un objet mutex, par exemple). Il en va de même pour les verrous de niveau matériel (par exemple, la réponse du disque) ou les verrous de niveau logique (appelés "primitives de verrouillage", qui comprennent un certain nombre d'entités, mutex adaptatif et spin, sémaphores, variables de condition, verrous rw, verrous ipc ...).
Une autre caractéristique de LA est qu'elle est calculée comme une valeur moyenne dans le système d'exploitation. Par exemple, si 100 processus sont en concurrence pour un fichier, le LA est 50. Ce grand nombre peut donner l'impression que c'est mauvais pour le système d'exploitation. Cependant, pour un code mal écrit, cela peut être normal. Seul ce code spécifique serait mauvais et le reste du système d'exploitation pourrait convenir.
En raison de cette moyenne (pendant moins d'une minute), déterminer quoi que ce soit à l'aide d'un LA n'est pas la meilleure idée, car cela peut donner des résultats extrêmement ambigus dans certains cas. Si vous essayez d'en savoir plus à ce sujet, vous constaterez que Wikipedia et d'autres ressources disponibles ne décrivent que les cas les plus simples, et le processus n'est pas décrit en détail. Si cela vous intéresse, visitez à nouveau
Brendann Gregg et suivez les liens.
3. Effets spéciaux
Passons maintenant aux principaux cas de
vol que nous avons rencontrés. Permettez-moi d'expliquer comment ils résultent de ce qui précède et comment ils sont en corrélation avec les mesures de l'hyperviseur.
Surutilisation. Le cas le plus simple et le plus courant: l'hyperviseur est surutilisé. En effet, avec de nombreuses machines virtuelles en cours d'exécution et consommant beaucoup de ressources CPU, la concurrence est élevée et l'utilisation selon la LA est supérieure à 1 (normalisée selon les threads CPU). Tout est en retard dans toutes les machines virtuelles.
Le vol envoyé par l'hyperviseur se développe également. Vous devez redistribuer la charge ou éteindre quelque chose. Dans l'ensemble, tout cela est logique et simple.
Paravirtualisation vs instances uniques. Il n'y a qu'une seule machine virtuelle sur un hyperviseur. La machine virtuelle en consomme une petite partie, mais fournit une charge d'entrée / sortie élevée, par exemple, pour un lecteur. De façon inattendue, un petit
vol de moins de 10% apparaît (comme le montrent certains des tests que nous avons effectués).
Ceci est un cas curieux. Ici, le
vol apparaît à cause des verrous au niveau des appareils paravirtualisés. À l'intérieur de la machine virtuelle, un point d'arrêt est créé. Ceci est traité par le pilote et va à l'hyperviseur. En raison du traitement des points d'arrêt sur l'hyperviseur, la machine virtuelle considère cela comme une demande envoyée. Il est prêt à fonctionner et attend le CPU, mais ne reçoit pas de temps CPU. La VM pense que le temps a été volé.
Cela se produit lorsque le tampon est envoyé. Il va dans l'espace noyau de l'hyperviseur et nous l'attendons. Du point de vue de la VM, elle devrait revenir immédiatement. Par conséquent, selon notre algorithme de calcul de
vol , ce temps est considéré comme volé. Il est probable que d'autres mécanismes soient impliqués dans cela (par exemple le traitement d'autres
appels système ), mais ils ne devraient pas différer de manière significative.
Planificateur vs machines virtuelles très chargées. Lorsqu'une machine virtuelle souffre de
voler plus que les autres, cela est directement connecté au planificateur. Plus la charge qu'un processus met sur un processeur est importante, plus un ordonnanceur le rejettera rapidement, afin de permettre aux autres processus de fonctionner. Si la machine virtuelle consomme peu, elle ne subira presque aucun
vol. Son processus vient d’être assis et d’attendre, et il lui faut plus de temps. Si la machine virtuelle met une charge maximale sur tous les cœurs, le processus est jeté plus souvent et la machine virtuelle dispose de moins de temps.
C'est encore pire lorsque les processus au sein de la machine virtuelle essaient d'obtenir plus de CPU, car ils ne peuvent pas traiter les données. Ensuite, le système d'exploitation sur l'hyperviseur fournira moins de temps processeur en raison de l'optimisation équitable. Ce processus fait boule de neige et
vole des montées en flèche, tandis que d'autres machines virtuelles peuvent même ne pas le remarquer. Plus il y a de cœurs, pire c'est pour la malheureuse VM. En bref, les machines virtuelles très chargées avec de nombreux cœurs souffrent le plus.
Faible LA mais le
vol est présent. Si la LA est d'environ 0,7 (ce qui signifie que l'hyperviseur semble sous-chargé), mais il y a du
vol dans certaines machines virtuelles:
- L'exemple de paravirtualisation susmentionné s'applique. La machine virtuelle peut recevoir des métriques qui indiquent un vol , tandis que l'hyperviseur n'a aucun problème. Selon les résultats de nos tests, un tel vol ne dépasse généralement pas 10% et n'a pas d'impact significatif sur les performances des applications au sein de la machine virtuelle.
- Le paramètre LA a été calculé incorrectement. Plus précisément, il a été calculé correctement à un moment précis, mais lors de la moyenne, il est inférieur à ce qu'il devrait être pendant une minute. Par exemple, si une VM (un tiers de l'hyperviseur) consomme tous les processeurs pendant 30 secondes, la LA pendant une minute sera de 0,15. Quatre de ces machines virtuelles, fonctionnant en même temps, donneront une valeur de 0,6. Sur la base du LA, vous ne pourriez pas déduire que pendant 30 secondes pour chacun d'eux, le vol était de près de 25%.
- Encore une fois, cela s'est produit à cause de l'ordonnanceur, qui a décidé que quelqu'un «mangeait» trop et les a fait attendre. Pendant ce temps, il changera de contexte, traitera les points d'arrêt et s'occupera d'autres questions importantes du système. Par conséquent, certaines machines virtuelles ne rencontrent aucun problème et d'autres souffrent de pertes de performances importantes.
4. Autres distorsions
Il existe un million de raisons possibles pour la distorsion de l'allocation équitable du temps CPU sur une machine virtuelle. Par exemple, l'hyperthreading et NUMA ajoutent de la complexité aux calculs. Ils compliquent le choix du cœur utilisé pour exécuter un processus car un ordonnanceur utilise des coefficients; c'est-à-dire les poids, qui compliquent encore plus les calculs lors des changements de contextes.
Il existe des distorsions dues à des technologies telles que Turbo Boost ou son mode d'économie d'énergie opposé, qui pourraient augmenter ou diminuer artificiellement la vitesse du cœur du processeur et même la tranche de temps. L'activation de Turbo Boost diminue la productivité d'un thread CPU en raison d'une augmentation des performances dans un autre. À ce moment, les informations concernant la vitesse d'horloge actuelle du processeur ne sont pas envoyées à la machine virtuelle, qui pense que quelqu'un vole son temps (par exemple, il a demandé 2 GHz et a obtenu la moitié du temps).
En fait, il peut y avoir plusieurs raisons à la distorsion. Vous pouvez trouver autre chose entièrement dans un système donné. Je recommande de commencer par les livres liés ci-dessus et d'obtenir des statistiques de l'hyperviseur en utilisant des outils tels que perf, sysdig, systemtap et des
dizaines d'autres .
5. Conclusions
- Certains vols peuvent apparaître en raison de la paravirtualisation et cela peut être considéré comme normal. Des sources en ligne affirment que cette valeur peut être de 5 à 10%. Cela dépend de l'application dans une machine virtuelle et de la charge que la machine virtuelle place sur ses périphériques physiques. Il est important de faire attention à la façon dont les applications se sentent à l'intérieur d'une machine virtuelle.
- La corrélation entre la charge sur l'hyperviseur et le vol au sein d'une machine virtuelle n'est pas toujours certaine. Les deux calculs de vol peuvent être erronés dans certains cas et avec des charges différentes.
- Le planificateur ne favorise pas les processus qui demandent beaucoup de ressources. Il essaie de donner moins à ceux qui en demandent plus. Les grandes instances sont méchantes.
- Un petit vol peut également être normal sans paravirtualisation (en tenant compte de la charge au sein de la machine virtuelle, des particularités des charges des voisins, de la répartition de la charge entre les threads et d'autres facteurs).
- Si vous souhaitez calculer le vol dans un système particulier, recherchez les différentes possibilités, rassemblez des métriques, analysez-les soigneusement et réfléchissez à la façon de répartir la charge équitablement. Quoi qu'il en soit, il peut y avoir des écarts, qui doivent être vérifiés à l'aide de tests ou les afficher dans un débogueur du noyau.