Bonjour
Mon nom est Marat Gayanov, je veux partager avec vous ma solution au problème du concours
Best Reverser , pour montrer comment faire keygen pour ce cas.
La description
Dans ce concours, les participants reçoivent des jeux ROM pour Sega Mega Drive (
best_reverser_phd9_rom_v4.bin ).
Tâche: récupérer une telle clé qui, avec l'adresse e-mail du participant, sera reconnue comme valide.
Alors la solution ...
Les outils
Vérification de la longueur des clés
Le programme n'accepte pas toutes les clés: vous devez remplir tout le champ, ce sont 16 caractères. Si la clé est plus courte, vous verrez un message: «Mauvaise longueur! Réessayez ... ".
Essayons de trouver cette ligne dans le programme, pour lequel nous utiliserons la recherche binaire (Alt-B). Que trouverons-nous?
Nous trouverons non seulement cela, mais aussi les autres lignes de services à proximité: «Mauvaise clé! Essayez encore ... »et« VOUS ÊTES LE MEILLEUR INVERSEUR! ».
J'ai défini les
WRONG_LENGTH_MSG ,
YOU_ARE_THE_BEST_MSG et
WRONG_KEY_MSG pour plus de commodité.
Mettez une pause dans la lecture de l'adresse
0x0000FDFA - découvrez qui travaille avec le message "Longueur incorrecte! Réessayez ... ". Et exécutez le débogueur (il s'arrêtera plusieurs fois avant que la clé ne puisse être entrée, appuyez simplement sur F9 à chaque arrêt). Saisissez votre adresse e-mail, saisissez
ABCD .
Le débogueur conduit à
0x00006FF0 tst.b (a1)+ :
Il n'y a rien d'intéressant dans le bloc lui-même. Il est beaucoup plus intéressant de savoir qui transfère le contrôle ici. Nous regardons la pile d'appels:
Cliquez et obtenez ici - à l'instruction
0x00001D2A jsr (sub_6FC0).l :
Nous voyons que tous les messages possibles ont été trouvés au même endroit. Mais voyons où le contrôle est transféré dans le bloc
WRONG_KEY_LEN_CASE_1D1C . Nous ne définirons pas de coupures, il suffit de déplacer le curseur sur la flèche allant au bloc. L'appelant est situé à
0x000017DE loc_17DE (que je renommerai en
CHECK_KEY_LEN ):
Mettez une pause sur l'adresse
0x000017EC cmpi.b 0x20 (a0, d0.l) (l'instruction dans ce contexte cherche à voir s'il y a un caractère vide à la fin du tableau de caractères de clé), redémarrez, entrez à nouveau le courrier et la clé
ABCD . Le débogueur s'arrête et montre que la clé entrée se trouve à l'adresse
0x00FF01C7 (stockée à ce moment dans le registre
a0 ):
C'est une bonne trouvaille, grâce à elle, nous saisirons tout. Mais d'abord, marquez les octets clés pour plus de commodité:
En remontant de cet endroit, nous voyons que le courrier est stocké à côté de la clé:
Nous plongeons de plus en plus profondément, et il est temps de trouver un critère pour l'exactitude de la clé. Plutôt, la première moitié de la clé.
Le critère de correction pour la première moitié de la clé
Calculs préliminaires
Il est logique de supposer qu'immédiatement après avoir vérifié la longueur, d'autres opérations avec la clé suivront. Considérez le bloc immédiatement après la vérification:
Ce bloc est en cours de travaux préliminaires. La fonction
get_hash_2b (dans l'original était
sub_1526 ) est appelée deux fois. Tout d'abord, l'adresse du premier octet de la clé lui est transmise (le registre
a0 contient l'adresse
KEY_BYTE_0 ), la deuxième fois - la cinquième (
KEY_BYTE_4 ).
J'ai nommé la fonction comme ceci car elle considère quelque chose comme un hachage de 2 octets. C'est le nom le plus compréhensible que j'ai choisi.
Je ne considérerai pas la fonction elle-même, mais je l'écrirai immédiatement en python. Elle fait des choses simples, mais sa description avec des captures d'écran prendra beaucoup de place.
La chose la plus importante à dire à ce sujet: l'adresse d'entrée est fournie à l'entrée, et le travail se fait sur 4 octets à partir de cette adresse. Autrement dit, ils ont envoyé le premier octet de la clé à l'entrée, et la fonction fonctionnera avec le 1,2,3,4e. Classé cinquième, la fonction fonctionne avec le 5,6,7,8e. En d'autres termes, dans ce bloc, il y a des calculs sur la première moitié de la clé. Le résultat est écrit dans le registre
d0 .
Ainsi, la fonction
get_hash_2b :
Écrivez immédiatement une fonction de décodage de hachage:
Je n'ai pas trouvé de meilleure fonction de décodage, et ce n'est pas tout à fait correct. Par conséquent, je vais le vérifier comme ça (pas maintenant, mais bien plus tard):
key_4s == decode_hash_4s(get_hash_2b(key_4s))
Vérifiez le fonctionnement de
get_hash_2b . Nous nous intéressons à l'état du registre
d0 après l'exécution de la fonction. Nous
0x000017FE pauses sur
0x000017FE ,
0x00001808 , la clé que nous entrons
ABCDEFGHIJKLMNOP .
Les valeurs
0xABCD ,
0xEF01 sont entrées dans le registre
d0 . Et que donnera
get_hash_2b ?
>>> first_hash = get_hash_2b("ABCD") >>> hex(first_hash) 0xabcd >>> second_hash = get_hash_2b("EFGH") >>> hex(second_hash) 0xef01
La vérification a réussi.
Puis
xor eor.w d0, d5 produit, le résultat est entré dans
d5 :
>>> hex(0xabcd ^ 0xef01) 0x44cc
L'obtention d'un tel hachage est
0x44CC et consiste en des calculs préliminaires. De plus, tout devient plus compliqué.
Où va le hachage
Nous ne pouvons pas aller plus loin si nous ne savons pas comment le programme fonctionne avec le hachage. Certes, il passe de
d5 à la mémoire, car Le registre est utile ailleurs. On peut retrouver un tel événement à travers la trace (regarder
d5 ), mais pas manuel, mais automatique. Le script suivant vous aidera:
#include <idc.idc> static main() { auto d5_val; auto i; for(;;) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); d5_val = GetRegValue("d5"); // d5 if (d5_val != 0xFFFF44CC){ break; } } }
Permettez-moi de vous rappeler que nous sommes maintenant sur la dernière pause
0x00001808 eor.w d0, d5 . Collez le script (
Shift-F2 ), cliquez sur
RunLe script s'arrêtera à l'instruction
0x00001C94 move.b (a0, a1.l), d5 , mais à ce moment,
d5 a déjà été effacé. Cependant, nous voyons que la valeur de
d5 déplacée par l'instruction
0x00001C56 move.w d5,a6 : elle est écrite en mémoire à l'adresse
0x00FF0D46 (2 octets).
N'oubliez pas: le hachage est stocké à 0x00FF0D46 .Nous interceptons les instructions qui sont lues à partir de
0x00FF0D46-0x00FF0D47 (nous avons défini une pause pour la lecture). Pris 4 blocs:




Comment choisir les bons / bons?
Revenez au début:
Ce bloc détermine si le programme ira à
LOSER_CASE ou à
WINNER_CASE :
On voit que dans le registre
d1 doit être nul pour gagner.
Où est mis à zéro? Faites simplement défiler vers le haut:
Si la
loc_1EEC est satisfaite dans le bloc
loc_1EEC :
*(a6 + 0x24) == *(a6 + 0x22)
on obtient alors zéro en
d5 .
Si nous mettons une pause sur l'instruction
0x00001F16 beq.w loc_20EA , nous verrons que
a6 + 0x24 = 0x00FF0D6A et la valeur
0x4840 sont stockés. Et dans
a6 + 0x22 = 0x00FF0D68 est stocké.
Si nous entrons différentes clés, e-mails, nous verrons que
0xCB4C - .
La première moitié de la clé ne sera acceptée que si dans 0x00FF0D6A aura également 0xCB4C . Il s'agit du critère de correction de la première moitié de la clé.Nous découvrons quels blocs sont écrits en
0x00FF0D6A - mettez une pause dans l'enregistrement, entrez à nouveau le courrier et la clé.
Et nous trouverons ce bloc
loc_EAC (il y en a en fait 3, mais les deux premiers ne font que sortir
0x00FF0D6A ):
Ce bloc appartient à la fonction
sub_E3E .
Grâce à la pile d'appels, nous découvrons que la fonction
sub_E3E appelée dans les blocs
loc_1F94 ,
loc_203E :
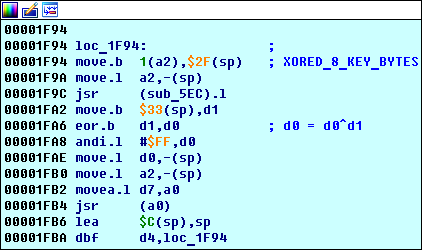

Rappelez-vous que nous avons trouvé 4 blocs plus tôt?
loc_1F94 nous avons vu là-bas - c'est le début de l'algorithme de traitement des clés principales.
Première boucle importante loc_1F94
Le fait que
loc_1F94 est un cycle est visible dans le code: il est exécuté
d4 fois (voir instruction
0x00001FBA d4,loc_1F94 ):
Que rechercher:
- Il existe une fonction
sub_5EC . - L'instruction 0x00001FB4 jsr (a0) appelle la fonction sub_E3E (cela peut être vu avec une trace simple).
Que se passe-t-il ici:
- La fonction
sub_5EC écrit le résultat de son exécution dans le registre d0 (ceci est discuté dans une section séparée ci-dessous). - L'octet à l'adresse
sp+0x33 ( 0x00FFFF79 , nous dit le débogueur) est stocké dans le registre d1 , il est égal au deuxième octet de l'adresse de hachage de clé ( 0x00FF0D47 ). C'est facile à prouver si vous mettez une pause dans l'enregistrement à 0x00FFFF79 : cela fonctionnera sur les instructions 0x00001F94 move.b 1(a2), 0x2F(sp) . Le registre a2 à ce moment stocke l'adresse 0x00FF0D46 - l'adresse de hachage, c'est-à-dire 0x1(a2) = 0x00FF0D46 + 1 - l'adresse du deuxième octet du hachage. - Le registre
d0 s'écrit d0^d1 .
- Le résultat xor'a résultant est donné à la fonction
sub_E3E , dont le comportement dépend de ses calculs précédents (voir ci-dessous). - Répétez.
Combien de fois ce cycle s'exécute-t-il?
Découvrez ça. Exécutez le script suivant:
#include <idc.idc> static main() { auto pc_val, d4_val, counter=0; while(pc_val != 0x00001F16) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); pc_val = GetRegValue("pc"); if (pc_val == 0x00001F92){ counter++; d4_val = GetRegValue("d4"); print(d4_val); } } print(counter); }
0x00001F92 subq.l 0x1,d4 - ici, il est déterminé ce qui se passera en
d4 immédiatement avant la boucle:
Nous traitons de la fonction sub_5EC.
sub_5EC
Morceau de code important:
où
0x2c(a2) toujours
0x00FF1D74 .
Cette pièce peut être réécrite comme ceci en pseudo-code:
d0 = a2 + 0x2C *(a2+0x2C) = *(a2+0x2C) + 1 #*(0x00FF1D74) = *(0x00FF1D74) + 1 result = *(d0) & 0xFF
Autrement dit, 4 octets de
0x00FF1D74 sont l'adresse, car ils sont traités comme un pointeur.
Comment réécrire la fonction
sub_5EC en python?
- Ou faites un vidage de mémoire et travaillez avec.
- Ou notez simplement toutes les valeurs renvoyées.
La deuxième méthode que j'aime plus, mais que se passe-t-il si, avec des données d'autorisation différentes, les valeurs renvoyées sont différentes? Regardez ça.
Le script vous y aidera:
#include <idc.idc> static main() { auto pc_val=0, d0_val; while(pc_val != 0x00001F16){ pc_val = GetRegValue("pc"); if (pc_val == 0x00001F9C) StepInto(); else StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); if (pc_val == 0x00000674){ d0_val = GetRegValue("d0") & 0xFF; print(d0_val); } } }
Je viens de comparer les sorties à la console avec différentes touches, mails.
En
sub_5EC le script plusieurs fois avec différentes clés, nous verrons que la fonction
sub_5EC renvoie toujours la valeur suivante du tableau:
def sub_5EC_gen(): dump = [0x92, 0x8A, 0xDC, 0xDC, 0x94, 0x3B, 0xE4, 0xE4, 0xFC, 0xB3, 0xDC, 0xEE, 0xF4, 0xB4, 0xDC, 0xDE, 0xFE, 0x68, 0x4A, 0xBD, 0x91, 0xD5, 0x0A, 0x27, 0xED, 0xFF, 0xC2, 0xA5, 0xD6, 0xBF, 0xDE, 0xFA, 0xA6, 0x72, 0xBF, 0x1A, 0xF6, 0xFA, 0xE4, 0xE7, 0xFA, 0xF7, 0xF6, 0xD6, 0x91, 0xB4, 0xB4, 0xB5, 0xB4, 0xF4, 0xA4, 0xF4, 0xF4, 0xB7, 0xF6, 0x09, 0x20, 0xB7, 0x86, 0xF6, 0xE6, 0xF4, 0xE4, 0xC6, 0xFE, 0xF6, 0x9D, 0x11, 0xD4, 0xFF, 0xB5, 0x68, 0x4A, 0xB8, 0xD4, 0xF7, 0xAE, 0xFF, 0x1C, 0xB7, 0x4C, 0xBF, 0xAD, 0x72, 0x4B, 0xBF, 0xAA, 0x3D, 0xB5, 0x7D, 0xB5, 0x3D, 0xB9, 0x7D, 0xD9, 0x7D, 0xB1, 0x13, 0xE1, 0xE1, 0x02, 0x15, 0xB3, 0xA3, 0xB3, 0x88, 0x9E, 0x2C, 0xB0, 0x8F] l = len(dump) offset = 0 while offset < l: yield dump[offset] offset += 1
Donc,
sub_5EC est prêt.
sub_E3E ligne suivante est
sub_E3E .
sub_E3E
Morceau de code important:
Déchiffrer:
, d2, . a2 0xFF0D46, a2 + 0x34 = 0xFF0D7A d0 = *(a2 + 0x34) *(a2 + 0x34) = *(a2 + 0x34) + 1 , a0 a0 = d0 *(a0) = d2 offset, d2. a2 0xFF0D46, a2 + 0x24 = 0xFF0D6A - , (. ) 0x00000000, d0 = *(a2 + 0x24) d2 = d0 ^ d2 d2 = d2 & 0xFF d2 = d2 + d2 - 2 0x00011FC0 + d2, ROM, 0x00011FC0 + d2 a0 = 0x00011FC0 d2 = *(a0 + d2) 8 d0 = d0 >> 8 d2 = d0 ^ d2 *(a2 + 0x24) = d2
La fonction
sub_E3E résume à ces étapes:
- Enregistrez l'argument d'entrée dans un tableau.
- Calculez le décalage de décalage.
- Tirez 2 octets à l'adresse
0x00011FC0 + offset (ROM). - Résultat =
( >> 8) ^ (2 0x00011FC0 + offset) .
Imaginez la fonction
sub_E3E sous cette forme:
def sub_E3E(prev_sub_E3E_result, d2, d2_storage): def calc_offset(): return 2 * ((prev_sub_E3E_result ^ d2) & 0xff) d2_storage.append(d2) offset = calc_offset() with open("dump_00011FC0", 'rb') as f: dump_00011FC0_4096b = f.read() some = dump_00011FC0_4096b[offset:offset + 2] some = int.from_bytes(some, byteorder="big") prev_sub_E3E_result = prev_sub_E3E_result >> 8 return prev_sub_E3E_result ^ some
dump_00011FC0 est juste un fichier où j'ai enregistré 4096 octets à partir de
[0x00011FC0:00011FC0+4096] .
Activité autour de 1FC4
Nous n'avons pas encore vu l'adresse
0x00001FC4 , mais elle est facile à trouver, car le bloc passe presque immédiatement après le premier cycle.
Ce bloc change le contenu à l'adresse
0x00FF0D46 (registre
a2 ), et c'est là que le hachage de clé est stocké, donc nous étudions maintenant ce bloc. Voyons ce qui se passe ici.
- La condition qui détermine si la branche gauche ou droite est sélectionnée est:
( ) & 0b1 != 0 . Autrement dit, le premier bit du hachage est vérifié. - Si vous regardez les deux branches, vous verrez:
- Dans les deux cas, un décalage vers la droite d'un bit se produit.
- Dans la branche gauche, l'opération de hachage est effectuée
0x8000 . - Dans les deux cas, la valeur de hachage traitée est écrite à l'adresse
0x00FF0D46 , c'est-à-dire que le hachage est remplacé par une nouvelle valeur. - D'autres calculs ne sont pas critiques, car, en gros, il n'y a pas d'opérations d'écriture dans
(a2) (il n'y a aucune instruction où le deuxième opérande serait (a2) ).
Imaginez un bloc comme celui-ci:
def transform(hash_2b): new = hash_2b >> 1 if hash_2b & 0b1 != 0: new = new | 0x8000 return new
La deuxième boucle importante est loc_203E
loc_203E - boucle, car
0x0000206C bne.s loc_203E .
Ce cycle calcule le hachage et voici sa principale caractéristique:
jsr (a0) est un appel à la fonction
sub_E3E que nous avons déjà examiné - il s'appuie sur le résultat précédent de son propre travail et sur un argument d'entrée (il a été passé par le registre
d2 ci-dessus, et ici par
d0 )
Voyons ce qui lui est transmis via le registre
d0 .
Nous avons déjà rencontré la construction
0x34(a2) - la fonction
sub_E3E sauvegarde l'argument passé. Cela signifie que les arguments passés précédemment sont utilisés dans cette boucle. Mais pas tous.
Déchiffrez la partie du code:
2 a2+0x1C move.w 0x1C(a2), d0 neg.l d0 a0 sub_E3E movea.l 0x34(a2), a0 , d0 2 a0-d0( d0 ) move.b (a0, d0.l), d0
La ligne de fond est une action simple: à chaque itération, prenez
d0 argument stocké à la fin du tableau. Autrement dit, si 4 est stocké dans
d0 , alors nous prenons le quatrième élément de la fin.
Si oui, que prend exactement
d0 ? Ici, je l'ai fait sans scripts, mais je les ai simplement écrits, mettant une pause au début de ce bloc. Les voici:
0x04, 0x04, 0x04, 0x1C, 0x1A, 0x1A, 0x06, 0x42, 0x02 .
Nous avons maintenant tout pour écrire une fonction de calcul de hachage de clé complète.
Fonction de calcul de hachage complet
def finish_hash(hash_2b):
Bilan de santé
- Dans le débogueur, nous avons défini une interruption à l'adresse
0x0000180A move.l 0x1000,(sp) (immédiatement après le calcul du hachage). 0x00001F16 beq.w loc_20EA à l'adresse 0x00001F16 beq.w loc_20EA (comparaison du hachage final avec la constante 0xCB4C ).- Dans le programme, entrez la clé
ABCDEFGHIJKLMNOP , appuyez sur Enter . - Le débogueur s'arrête à
0x0000180A , et nous voyons que la valeur 0xFFFF44CC est 0x44CC registre d5 , 0x44CC est le premier hachage. - Nous démarrons le débogueur plus loin.
- Nous nous arrêtons à
0x00001F16 et voyons qu'à 0x00FF0D6A se trouve 0x4840 - le hachage final
- Découvrez maintenant notre fonction finish_hash (hash_2b):
>>> r = finish_hash(0x44CC) >>> print(hex(r)) 0x4840
Nous recherchons la bonne clé 1
La clé correcte est cette clé dont le hachage final est
0xCB4C (découvert ci-dessus). D'où la question: quel devrait être le premier hachage pour que la finale devienne
0xCB4C ?
Maintenant, il est facile de savoir:
def find_CB4C(): result = [] for hash_2b in range(0xFFFF+1): final_hash = finish_hash(hash_2b) if final_hash == 0xCB4C: result.append(hash_2b) return result >>> r = find_CB4C() >>> print(r)
La sortie du programme suggère qu'il n'y a qu'une seule option: le premier hachage devrait être
0xFEDC .
De quels caractères avons-nous besoin pour que leur premier hachage soit
0xFEDC ?
Puisque
0xFEDC = __4_ ^ __4_ , vous devez rechercher uniquement le
__4_ , car le
__4_ = __4_ ^ 0xFEDC . Et puis décode les deux hachages.
L'algorithme est le suivant:
def get_first_half(): from collections import deque from random import randint def get_pairs(): pairs = [] for i in range(0xFFFF + 1): pair = (i, i ^ 0xFEDC) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) pairs = get_pairs() for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1
Un tas d'options, choisissez-en une.
Nous recherchons la bonne clé 2
La première moitié de la clé est prête, qu'en est-il de la seconde?
C'est la partie la plus simple.
Le morceau de code responsable est situé à
0x00FF2012 , j'y suis arrivé par traçage manuel, en commençant par l'adresse
0x00001F16 beg.w loc_20EA (validation de la première moitié de la clé). Dans le registre
a0 est l'adresse e-mail,
loc_FF2012 est un cycle, car
bne.s loc_FF2012 . Il est exécuté tant qu'il y a
*(a0+d0) (le prochain octet de courrier).
Et l'
jsr (a3) appelle la fonction
get_hash_2b déjà familière, qui fonctionne maintenant avec la seconde moitié de la clé.
Rendons le code plus clair:
while(d1 != 0x20){ d2++ d1 = d1 & 0xFF d3 = d3 + d1 d0 = 0 d0 = d2 d1 = *(a0+d0) } d0 = get_hash_2b(key_byte_8) d3 = d0^d3 d0 = get_hash_2b(key_byte_12) d2 = d2 - 1 d2 = d2 << 8 d2 = d0^d2 if (d2 == d3) success_branch
Dans le registre
d2 -
( -1) << 8 . En
d3 , la somme des octets de caractères de courrier.
Le critère de correction est le suivant:
__ ^ d2 == ___2 ^ d3 .
Nous écrivons la fonction de sélection de la seconde moitié de la touche:
def get_second_half(email): from collections import deque from random import randint def get_koeff(): k1 = sum([ord(c) for c in email]) k2 = (len(email) - 1) << 8 return k1, k2 def get_pairs(k1, k2): pairs = [] for a in range(0xFFFF + 1): pair = (a, (a ^ k1) ^ k2) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) k1, k2 = get_koeff() pairs = get_pairs(k1, k2) for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1
Keygen
Le courrier doit être une capsule.
def keygen(email): first_half = get_first_half() second_half = get_second_half(email) return "".join(first_half) + "".join(second_half) >>> email = "M.GAYANOV@GMAIL.COM" >>> print(keygen(email)) 2A4FD493BA32AD75
Merci de votre attention! Tout le code est disponible
ici .