Dans le «Black Mirror», il y avait une série (S2E1), dans laquelle ils ont créé des robots similaires à des morts, en utilisant l'histoire de la correspondance sur les réseaux sociaux pour la formation. Je veux vous dire comment j'ai essayé de faire quelque chose de similaire et ce qui en est ressorti. Il n'y aura pas de théorie, seulement de la pratique.

L'idée était simple: reprendre l'historique de leurs conversations de Telegram et, sur leur base, former le réseau seq2seq, qui est capable de prédire son achèvement au début du dialogue. Un tel réseau peut fonctionner en trois modes:
- Prédire l'achèvement de la phrase utilisateur en fonction de l'historique des conversations
- Travailler en mode chatbot
- Synthétisez des journaux de conversation entiers
Voilà ce que j'ai
Le robot offre une complétion de phrase
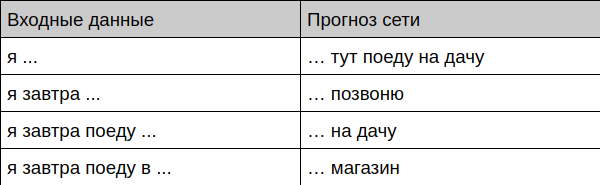
Le robot offre l'achèvement du dialogue
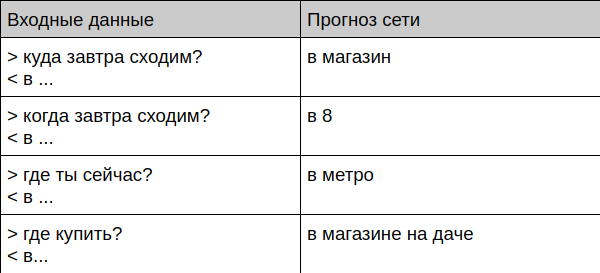
Le robot communique avec une personne vivante
User: Bot: User: ? Bot: User: ? Bot: User: ? Bot: User: ? Bot: User: ? Bot:
Ensuite, je vais vous expliquer comment préparer les données et entraîner vous-même un tel robot.
Comment vous apprendre
Préparation des données
Tout d'abord, vous devez obtenir beaucoup de conversations quelque part. J'ai pris toute ma correspondance dans Telegram, car le client pour le bureau permet de télécharger l'archive complète au format JSON. Ensuite, j'ai jeté tous les messages qui contiennent des citations, des liens et des fichiers, et j'ai transféré les textes restants en minuscules et jeté tous les caractères rares à partir de là, ne laissant qu'un simple ensemble de lettres, de chiffres et de signes de ponctuation - il est plus facile d'apprendre le réseau.
Ensuite, j'ai apporté les chats à ce formulaire:
=== > < > < ! === > ? <
Ici, les messages qui commencent par le symbole ">" sont une question pour moi, le symbole "<" marque ma réponse en conséquence et la ligne "===" sert à séparer les dialogues entre eux. Le fait qu'un dialogue se soit terminé et que l'autre a commencé, j'ai déterminé par le temps (si plus de 15 minutes se sont écoulées entre les messages, alors nous pensons que c'est une nouvelle conversation. Vous pouvez voir le script pour convertir l'histoire sur github .
Depuis que j'utilise activement les télégrammes depuis longtemps, il y a eu beaucoup de messages à la fin - il y avait 443 000 lignes dans le fichier final.
Sélection du modèle
J’ai promis qu’il n’y aurait pas de théorie aujourd’hui, je vais donc essayer de l’expliquer le plus brièvement possible sur mes doigts.
J'ai choisi le classique seq2seq basé sur GRU. Un tel modèle d'entrée reçoit le texte lettre par lettre et génère également une lettre à la fois. Le processus d'apprentissage est basé sur le fait que nous apprenons au réseau à prédire la dernière lettre du texte, par exemple, nous donnons «plomb» à l'entrée et attendons que «rivet» soit sorti.
Pour générer des textes longs, une astuce simple est utilisée - le résultat de la prédiction précédente est renvoyé au réseau et ainsi de suite jusqu'à ce que la longueur de texte nécessaire soit générée.
Les modules GRU peuvent être très, très simplifiés comme un "perceptron rusé avec de la mémoire et de l'attention", plus de détails à leur sujet peuvent être trouvés, par exemple, ici .
Le modèle était basé sur l' exemple bien connu de la tâche de générer des textes de Shakespeare.
La formation
Quiconque a déjà rencontré des réseaux de neurones sait probablement que les apprendre sur le CPU est très ennuyeux. Heureusement, Google vient à la rescousse avec son service Colab - vous pouvez y exécuter gratuitement votre code dans le cahier jupyter en utilisant un CPU, un GPU et même un TPU . Dans mon cas, la formation sur la carte vidéo tient en 30 minutes, bien que des résultats raisonnables soient disponibles après 10. L'essentiel est de se rappeler de changer le type de matériel (dans le menu Runtime -> Changer le type d'exécution).
Test
Après la formation, vous pouvez procéder à la vérification du modèle - j'ai écrit plusieurs exemples qui vous permettent d'accéder au modèle dans différents modes - de la génération de texte au chat en direct. Tous sont sur github .
La méthode pour générer du texte a un paramètre de température - plus il est élevé, plus le texte (et vide de sens) produira un bot. Ce paramètre est logique pour configurer les mains pour une tâche spécifique.
Utilisation ultérieure
Pourquoi un tel réseau peut-il être utilisé? La chose la plus évidente est de développer un bot (ou clavier intelligent) qui peut offrir à l'utilisateur des réponses toutes faites avant même qu'il ne les écrive. Une fonctionnalité similaire existe depuis longtemps dans Gmail et la plupart des claviers, mais elle ne prend pas en compte le contexte de la conversation et la façon dont un utilisateur particulier conduit la correspondance. Disons que le G-Keyboard me propose de manière stable des options complètement dénuées de sens, par exemple, "Je vais avec ... respect" à l'endroit où je voudrais obtenir l'option "Je vais de la datcha", que j'ai certainement utilisée à plusieurs reprises.
Le bot de chat a-t-il un avenir? Dans sa forme pure, il n'est définitivement pas là, il a trop de données personnelles, personne ne sait à quel moment il donnera à l'interlocuteur le numéro de votre carte bancaire que vous avez jeté une fois à un ami. De plus, un tel bot n'est pas du tout réglé, il est très difficile de le faire effectuer des tâches spécifiques ou de répondre correctement à une question spécifique. Au contraire, un tel chatbot pourrait fonctionner en conjonction avec d'autres types de bots, fournissant un dialogue plus connecté "sur rien" - il s'en sort bien. (Et pourtant, un expert externe en la personne de sa femme a dit que le style de communication du bot était très similaire à moi. Et les sujets qui l'intéressent sont clairement les mêmes - les bugs, les corrections, les commits et autres joies et chagrins du développeur apparaissent constamment dans les textes).
Quoi d'autre vous conseille d'essayer si ce sujet vous intéresse?
- Transfert d'apprentissage (pour vous entraîner sur un grand nombre de dialogues avec d'autres personnes, puis terminer par vous-même)
- Changer de modèle - augmenter, changer de type (par exemple, sur LSTM).
- Essayez de travailler avec TPU. Dans sa forme pure, ce modèle ne fonctionnera pas, mais il peut être adapté. L'accélération théorique de l'apprentissage devrait être dix fois supérieure.
- Portez vers une plate-forme mobile, par exemple en utilisant Tensorflow mobile.
Lien PS vers github