Un autre utilisateur souhaite écrire une nouvelle donnée sur le disque dur, mais il n'a pas assez d'espace libre pour cela. Je ne veux rien supprimer non plus, car "tout est très important et nécessaire". Et qu'en ferons-nous?
Il n'a pas un tel problème. Des téraoctets d'informations reposent sur nos disques durs, et cette quantité n'a pas tendance à diminuer. Mais est-ce unique? En fin de compte, après tout, tous les fichiers ne sont que des ensembles de bits d'une certaine longueur et, très probablement, le nouveau n'est pas très différent de celui qui est déjà stocké.
Il est clair que rechercher des informations déjà stockées sur le disque dur est une tâche, sinon un échec, du moins pas efficace. D'un autre côté, parce que si la différence est petite, alors vous pouvez en ajuster un peu ...

TL; DR - la deuxième tentative de parler d'une étrange méthode d'optimisation des données à l'aide de fichiers JPEG, maintenant sous une forme plus compréhensible.
À propos des bits et de la différence
Si nous prenons deux données complètement aléatoires, alors en moyenne la moitié des bits contenus y coïncident. En effet, parmi les dispositions possibles pour chaque paire ('00, 01, 10, 11 '), exactement la moitié ont les mêmes valeurs, tout est simple ici.
Mais bien sûr, si nous prenons simplement deux fichiers et en ajustons un sous le second, nous en perdrons un. Si nous conservons les modifications, nous réinventerons simplement le codage delta , qui même sans nous existe parfaitement, bien qu'il ne soit généralement pas utilisé dans le même but. Vous pouvez essayer d'incorporer une séquence plus petite dans une plus grande, mais même ainsi, nous risquons de perdre des segments de données critiques lorsqu'ils sont utilisés de manière imprudente avec tout.
Entre quoi et quoi alors la différence peut-elle être éliminée? Eh bien, c'est-à-dire qu'un nouveau fichier enregistré par l'utilisateur n'est qu'une séquence de bits avec laquelle nous ne pouvons rien faire par lui-même. Ensuite, il vous suffit de trouver ces bits sur le disque dur afin qu'ils puissent être modifiés sans avoir à stocker la différence, afin que vous puissiez survivre à leur perte sans conséquences graves. Oui, et il est logique de modifier non seulement le fichier lui-même sur le FS, mais aussi certaines informations moins sensibles à l'intérieur. Mais lequel et comment?
Méthodes d'ajustement
Les fichiers compressés avec perte viennent à la rescousse. Tous ces fichiers jpeg, mp3 et autres, bien qu'ils soient à compression avec perte, contiennent un tas de bits disponibles pour un changement en toute sécurité. Vous pouvez utiliser des techniques avancées en modifiant discrètement leurs composants dans différents domaines de codage. Attends un instant. Techniques avancées ... modification discrète ... de quelques morceaux à d'autres ... oui c'est presque de la stéganographie !
En effet, l'intégration d'une information dans une autre ressemble à ses méthodes, quoi qu'il arrive. Il impressionne également l'invisibilité des changements apportés aux sens humains. C’est là que les chemins divergent - c’est un secret: notre tâche est d’ajouter des informations supplémentaires sur le disque dur de l’utilisateur, cela ne fera que le blesser. Oubliez plus.
Par conséquent, bien que nous puissions les utiliser, nous devons apporter quelques modifications. Et puis je vais les raconter et les montrer sur l'exemple d'une des méthodes existantes et du format de fichier commun.
À propos des chacals
Si vous compressez, alors le plus compressible du monde. Nous parlons bien sûr des fichiers JPEG. Non seulement il y a une tonne d'outils et de méthodes existantes pour y incorporer des données, mais c'est le format graphique le plus populaire sur cette planète.

Néanmoins, afin de ne pas vous engager dans l'élevage de chiens, vous devez limiter votre champ d'activité dans des fichiers de ce format. Personne n'aime les carrés monochromes dus à une compression excessive, vous devez donc vous limiter à travailler avec un fichier déjà compressé, en évitant le transcodage . Plus précisément, avec des coefficients entiers qui subsistent après les opérations responsables de la perte de données - DCT et quantification, qui sont parfaitement affichés sur le schéma de codage (grâce au wiki de la Bibliothèque Nationale Bauman):

Il existe de nombreuses méthodes d'optimisation possibles pour les fichiers JPEG. Il y a une optimisation sans perte (jpegtran), il y a une optimisation sans perte , qui contribue en fait toujours, mais cela ne nous dérange pas. En effet, si un utilisateur est prêt à intégrer une information dans une autre dans le but d'augmenter l'espace disque libre, il a soit optimisé ses images pendant une longue période, soit ne souhaite pas du tout le faire par crainte d'une perte de qualité.
F5
Dans de telles conditions, toute une famille d'algorithmes convient, que l'on retrouve dans cette bonne présentation . Le plus avancé d'entre eux est l'algorithme F5 , rédigé par Andreas Westfeld, qui travaille avec les coefficients de la composante de luminosité, car l'œil humain est le moins sensible à ses changements. De plus, il utilise une technique d'intégration basée sur l'encodage matriciel, qui permet de faire moins de changements lors de l'intégration de la même quantité d'informations, plus la taille du conteneur utilisé est grande.
Les changements eux-mêmes se résument à une diminution de la valeur absolue des coefficients par unité dans certaines conditions (c'est-à-dire pas toujours), ce qui permet d'utiliser F5 pour optimiser le stockage des données sur le disque dur. Le fait est que le coefficient après un tel changement occupera probablement un plus petit nombre de bits après le codage Huffman en raison de la distribution statistique des valeurs en JPEG, et les nouveaux zéros bénéficieront de leur codage en utilisant RLE.
Les modifications nécessaires sont réduites à l'élimination de la partie responsable du secret (permutation de mot de passe), ce qui permet d'économiser des ressources et du temps d'exécution, et d'ajouter un mécanisme pour travailler avec de nombreux fichiers au lieu d'un à la fois. Plus en détail, le processus de changement de lecteur est peu susceptible d'être intéressant, nous nous tournons donc vers la description de l'implémentation.
Haute technologie
Pour démontrer le travail de cette approche, j'ai implémenté la méthode en C pur et effectué un certain nombre d'optimisations à la fois en termes de vitesse et de mémoire (vous ne pouvez pas imaginer combien ces images pèsent sans compression avant même DCT). Les performances multiplateformes sont obtenues en utilisant une combinaison des bibliothèques libjpeg , pcre et tinydir , pour lesquelles je les remercie. Tout cela va être fait par make, donc les utilisateurs de Windows veulent installer Cygwin pour évaluation, ou gérer Visual Studio et les bibliothèques par eux-mêmes.
L'implémentation est disponible sous la forme d'un utilitaire de console et d'une bibliothèque. Plus d'informations sur l'utilisation de ce dernier peuvent être trouvées dans le fichier Lisez-moi dans le référentiel sur le github, un lien auquel je joindrai à la fin de l'article.
Comment utiliser?
Avec prudence. Les images utilisées pour l'empaquetage sont sélectionnées par recherche d'expressions régulières dans le répertoire racine spécifié. À la fin du fichier, vous pouvez déplacer, renommer et copier comme vous le souhaitez, modifier le fichier et les systèmes d'exploitation, etc. Cependant, vous devez être extrêmement prudent et ne pas modifier le contenu immédiat. La perte de la valeur d'un seul bit peut entraîner l'impossibilité de restaurer les informations.
À la fin du travail, l'utilitaire laisse un fichier d'archive spécial contenant toutes les informations nécessaires pour le déballage, y compris les données sur les images utilisées. En soi, il pèse de l'ordre de quelques kilo-octets et n'a pas d'effet significatif sur l'espace disque occupé.
Vous pouvez analyser la capacité possible en utilisant l'indicateur '-a': './f5ar -a [dossier de recherche] [expression régulière compatible Perl]'. L'emballage se fait avec la commande './f5ar -p [dossier de recherche] [expression régulière compatible Perl] [fichier compressé] [nom d'archive]', et le décompactage avec './f5ar -u [fichier d'archive] [nom du fichier restauré]' ' .
Démonstration de travail
Pour montrer l'efficacité de la méthode, j'ai téléchargé une collection de 225 photos de chiens absolument gratuites du service Unsplash et déterré un grand pdf sur 45 mètres dans les documents du deuxième volume du Knut Programming Art .
La séquence est assez simple:
$ du -sh knuth.pdf dogs/ 44M knuth.pdf 633M dogs/ $ ./f5ar -p dogs/ .*jpg knuth.pdf dogs.f5ar Reading compressing file... ok Initializing the archive... ok Analysing library capacity... done in 17.0s Detected somewhat guaranteed capacity of 48439359 bytes Detected possible capacity of upto 102618787 bytes Compressing... done in 39.4s Saving the archive... ok $ ./f5ar -u dogs/dogs.f5ar knuth_unpacked.pdf Initializing the archive... ok Reading the archive file... ok Filling the archive with files... done in 1.4s Decompressing... done in 21.0s Writing extracted data... ok $ sha1sum knuth.pdf knuth_unpacked.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth_unpacked.pdf $ du -sh dogs/ 551M dogs/
Captures d'écran pour les fans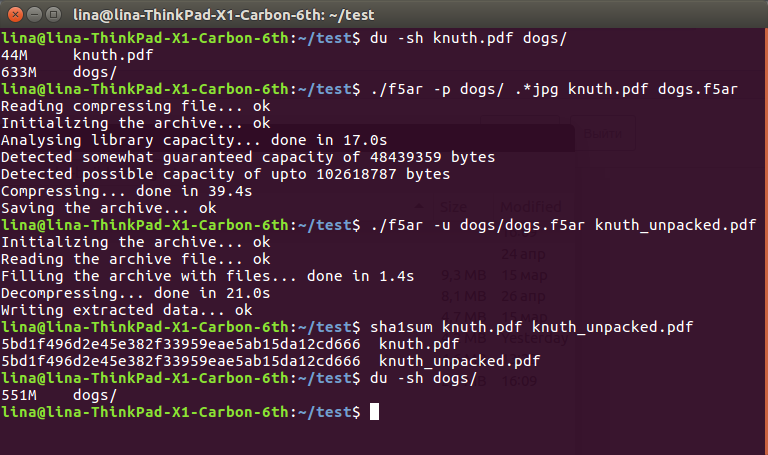
Le fichier décompressé est toujours possible et doit être lu:

Comme vous pouvez le voir, à partir des 633 + 36 == 669 mégaoctets de données d'origine sur le disque dur, nous sommes arrivés à un 551 plus agréable. Cette différence radicale s'explique par la diminution des valeurs de coefficient, qui affectent leur compression ultérieure sans perte: une diminution de seulement un par un peut calmement " couper "quelques octets du fichier résultant. Cependant, il s'agit toujours d'une perte de données, bien que extrêmement faible, que vous devez supporter.
Heureusement, ils ne sont pas complètement visibles à l'œil nu. Sous le spoiler (parce que habrastorage ne peut pas gérer de gros fichiers), le lecteur peut évaluer la différence à la fois par l'œil et leur intensité, obtenue en soustrayant les valeurs du composant modifié de l'original: l' original , avec les informations à l'intérieur , la différence (le gradateur de la couleur, la plus petite la différence dans le bloc )
Au lieu d'une conclusion
En regardant toutes ces difficultés, acheter un disque dur ou tout télécharger sur le cloud peut sembler une solution beaucoup plus simple au problème. Mais même si nous vivons maintenant dans une période aussi merveilleuse, rien ne garantit que demain, il sera toujours possible d'aller en ligne et de télécharger quelque part toutes vos données supplémentaires. Ou venez au magasin et achetez-vous un autre disque dur de mille téraoctets. Mais vous pouvez toujours utiliser des maisons déjà couchées.
-> github