
Contexte
Il se trouve que le serveur a été attaqué par un virus rançongiciel qui, par un "coup de chance", a partiellement mis de côté les fichiers .ibd (fichiers de données brutes des tables innodb), mais a complètement chiffré les fichiers .fpm (fichiers de structure). En même temps, .idb pourrait être divisé en:
- sous réserve de récupération au moyen d'outils et de guides standard. Pour de tels cas, il y a un excellent article ;
- tables partiellement cryptées. La plupart du temps, ce sont de grandes tables sur lesquelles (si j'ai bien compris), les attaquants n'avaient pas assez de RAM pour un cryptage complet;
- Eh bien, des tables entièrement cryptées qui ne peuvent pas être récupérées.
Il a été possible de déterminer à quelle option appartiennent les tables en ouvrant dans n'importe quel éditeur de texte sous l'encodage souhaité (dans mon cas c'est UTF8) et en regardant simplement le fichier pour la présence de champs de texte, par exemple:
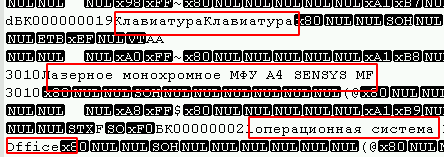
De plus, au début du fichier, vous pouvez observer un grand nombre de 0 octets, et les virus qui utilisent l'algorithme de chiffrement par blocs (le plus courant) les affectent généralement.

Dans mon cas, les attaquants à la fin de chaque fichier chiffré ont laissé une chaîne de 4 octets (1, 0, 0, 0), ce qui a simplifié la tâche. Un script était suffisant pour rechercher des fichiers non infectés:
def opened(path): files = os.listdir(path) for f in files: if os.path.isfile(path + f): yield path + f for full_path in opened("C:\\some\\path"): file = open(full_path, "rb") last_string = "" for line in file: last_string = line file.close() if (last_string[len(last_string) -4:len(last_string)]) != (1, 0, 0, 0): print(full_path)
Il s'est donc avéré trouver des fichiers appartenant au premier type. Le second implique un manuel long, mais déjà trouvé suffisait. Tout irait bien, mais vous devez connaître la structure absolument exacte et (bien sûr) il y avait un tel cas que je devais travailler avec une table qui changeait fréquemment. Personne ne se souvenait si le type de champ changeait ou si une nouvelle colonne était ajoutée.
Malheureusement, Debri City n'a pas pu aider avec cette affaire, donc cet article est en cours de rédaction.
Aller droit au but
Il y a une structure de table d'il y a 3 mois qui ne coïncide pas avec celle actuelle (peut-être un champ, mais peut-être plus). Structure du tableau:
CREATE TABLE `table_1` ( `id` INT (11), `date` DATETIME , `description` TEXT , `id_point` INT (11), `id_user` INT (11), `date_start` DATETIME , `date_finish` DATETIME , `photo` INT (1), `id_client` INT (11), `status` INT (1), `lead__time` TIME , `sendstatus` TINYINT (4) );
dans ce cas, vous devez extraire:
id_point INT (11);id_user INT (11);date_start DATETIME;date_finish DATETIME.
Pour la récupération, une analyse d'octets du fichier .ibd est utilisée, suivie de leur traduction sous une forme plus lisible. Étant donné que pour trouver ce qui est nécessaire, il nous suffit d'analyser des types de données tels que int et datatime, seuls ils seront décrits dans l'article, mais parfois ils se référeront également à d'autres types de données, ce qui peut aider dans d'autres incidents similaires.
Problème 1 : les champs avec les types DATETIME et TEXT avaient une valeur NULL, et ils sont simplement ignorés dans le fichier, pour cette raison, il n'a pas été possible de déterminer la structure de récupération dans mon cas. Dans les nouvelles colonnes, la valeur par défaut était nulle et certaines des transactions pouvaient être perdues en raison du paramètre innodb_flush_log_at_trx_commit = 0, donc du temps supplémentaire devait être consacré à déterminer la structure.
Problème 2 : il convient de noter que les lignes supprimées via DELETE seront toutes exactement dans le fichier ibd, mais leur structure ne sera pas mise à jour avec ALTER TABLE. Par conséquent, la structure des données peut varier du début du fichier à sa fin. Si vous utilisez souvent OPTIMIZE TABLE, il est peu probable que vous rencontriez un problème similaire.
Veuillez noter que la version du SGBD affecte la façon dont les données sont stockées, et cet exemple peut ne pas fonctionner pour les autres versions principales. Dans mon cas, la version Windows mariadb 10.1.24 a été utilisée. De plus, bien que dans mariadb vous travailliez avec des tables InnoDB, il s'agit en fait de XtraDB , ce qui exclut l'applicabilité de la méthode avec InnoDB mysql.
Analyse de fichiers
En python, le type de données bytes () affiche les données en Unicode au lieu de l'ensemble habituel de nombres. Bien que vous puissiez considérer le fichier sous cette forme, mais pour plus de commodité, vous pouvez convertir les octets en une forme numérique en traduisant le tableau d'octets en un tableau normal (liste (exemple_arbre_array)). Dans tous les cas, les deux méthodes sont utiles pour l'analyse.
Après avoir consulté plusieurs fichiers ibd, vous pouvez trouver les éléments suivants:
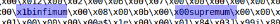
De plus, si vous divisez le fichier par ces mots-clés, vous obtiendrez principalement des blocs de données plats. Nous utiliserons infimum comme diviseur.
table = table.split("infimum".encode())
Une observation intéressante, pour les tables avec une petite quantité de données, entre infimum et supremum, il y a un pointeur sur le nombre de lignes dans le bloc.
 - table de test avec 1ère rangée
- table de test avec 1ère rangée
 - table de test avec 2 rangées
- table de test avec 2 rangées
Le tableau de la table de lignes [0] peut être ignoré. Après l'avoir regardé, je ne pouvais toujours pas trouver les données brutes des tableaux. Très probablement, ce bloc est utilisé pour stocker les index et les clés.
En commençant par le tableau [1] et en le traduisant en un tableau numérique, vous pouvez déjà remarquer certains modèles, à savoir:

Ce sont des valeurs int stockées dans une chaîne. Le premier octet indique si le nombre est positif ou négatif. Dans mon cas, tous les chiffres sont positifs. À partir des 3 octets restants, vous pouvez déterminer le nombre à l'aide de la fonction suivante. Script:
def find_int(val: str):
Par exemple, 128, 0, 0, 1 = 1 ou 128, 0, 75, 108 = 19308 .
La table avait une clé primaire avec incrémentation automatique, et ici vous pouvez également la trouver

En comparant les données des tables de test, il a été révélé que l'objet DATETIME se compose de 5 octets, en commençant par 153 (indiquant probablement des intervalles annuels). Étant donné que la plage DATTIME est de '1000-01-01' à '9999-12-31', je pense que le nombre d'octets peut varier, mais dans mon cas, les données tombent entre 2016 et 2019, nous supposons donc que 5 octets suffisent .
Pour déterminer le temps sans secondes, les fonctions suivantes ont été écrites. Script:
day_ = lambda x: x % 64 // 2
Pendant un an et un mois, il n'a pas été possible d'écrire une fonction de travail saine, j'ai donc dû coder en dur. Script:
ym_list = {'2016, 1': '153, 152, 64', '2016, 2': '153, 152, 128', '2016, 3': '153, 152, 192', '2016, 4': '153, 153, 0', '2016, 5': '153, 153, 64', '2016, 6': '153, 153, 128', '2016, 7': '153, 153, 192', '2016, 8': '153, 154, 0', '2016, 9': '153, 154, 64', '2016, 10': '153, 154, 128', '2016, 11': '153, 154, 192', '2016, 12': '153, 155, 0', '2017, 1': '153, 155, 128', '2017, 2': '153, 155, 192', '2017, 3': '153, 156, 0', '2017, 4': '153, 156, 64', '2017, 5': '153, 156, 128', '2017, 6': '153, 156, 192', '2017, 7': '153, 157, 0', '2017, 8': '153, 157, 64', '2017, 9': '153, 157, 128', '2017, 10': '153, 157, 192', '2017, 11': '153, 158, 0', '2017, 12': '153, 158, 64', '2018, 1': '153, 158, 192', '2018, 2': '153, 159, 0', '2018, 3': '153, 159, 64', '2018, 4': '153, 159, 128', '2018, 5': '153, 159, 192', '2018, 6': '153, 160, 0', '2018, 7': '153, 160, 64', '2018, 8': '153, 160, 128', '2018, 9': '153, 160, 192', '2018, 10': '153, 161, 0', '2018, 11': '153, 161, 64', '2018, 12': '153, 161, 128', '2019, 1': '153, 162, 0', '2019, 2': '153, 162, 64', '2019, 3': '153, 162, 128', '2019, 4': '153, 162, 192', '2019, 5': '153, 163, 0', '2019, 6': '153, 163, 64', '2019, 7': '153, 163, 128', '2019, 8': '153, 163, 192', '2019, 9': '153, 164, 0', '2019, 10': '153, 164, 64', '2019, 11': '153, 164, 128', '2019, 12': '153, 164, 192', '2020, 1': '153, 165, 64', '2020, 2': '153, 165, 128', '2020, 3': '153, 165, 192','2020, 4': '153, 166, 0', '2020, 5': '153, 166, 64', '2020, 6': '153, 1, 128', '2020, 7': '153, 166, 192', '2020, 8': '153, 167, 0', '2020, 9': '153, 167, 64','2020, 10': '153, 167, 128', '2020, 11': '153, 167, 192', '2020, 12': '153, 168, 0'} def year_month(x1, x2):
Je suis sûr que si vous passez n le nombre de fois, alors ce malentendu peut être corrigé.
Ensuite, la fonction renvoie un objet datetime à partir d'une chaîne. Script:
def find_data_time(val:str): val = [int(v) for v in val.split(", ")] day = day_(val[2]) hour = hour_(val[2], val[3]) minutes = min_(val[3], val[4]) year, month = year_month(val[1], val[2]) return datetime(year, month, day, hour, minutes)
Il était possible de détecter des valeurs fréquemment répétées de int, int, datetime, datetime 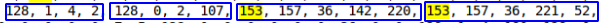 Il semble que c'est ce dont vous avez besoin. De plus, une telle séquence n'est pas répétée deux fois par ligne.
Il semble que c'est ce dont vous avez besoin. De plus, une telle séquence n'est pas répétée deux fois par ligne.
En utilisant une expression régulière, nous trouvons les données nécessaires:
fined = re.findall(r'128, \d*, \d*, \d*, 128, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*', int_array)
Veuillez noter que lors de la recherche de cette expression, il ne sera pas possible de déterminer des valeurs NULL dans les champs requis, mais dans mon cas, ce n'est pas critique. Après avoir parcouru le trouvé. Script:
result = [] for val in fined: pre_result = [] bd_int = re.findall(r"128, \d*, \d*, \d*", val) bd_date= re.findall(r"(153, 1[6,5,4,3]\d, \d*, \d*, \d*)", val) for it in bd_int: pre_result.append(find_int(bd_int[it])) for bd in bd_date: pre_result.append(find_data_time(bd)) result.append(pre_result)
En fait, tout, les données du tableau de résultats, ce sont les données dont nous avons besoin. ### PS. ###
Je comprends que cette méthode ne convient pas à tout le monde, mais l'objectif principal de l'article est d'inciter à l'action plutôt que de résoudre tous vos problèmes. Je pense que la solution la plus correcte serait de commencer à étudier le code source de mariadb lui-même, mais en raison du temps limité, la méthode actuelle semblait la plus rapide.
Dans certains cas, après avoir analysé le fichier, vous pouvez déterminer la structure approximative et restaurer l'une des méthodes standard à partir des liens ci-dessus. Ce sera beaucoup plus correct et causera moins de problèmes.