Bonjour, chers lecteurs de Habr. Je m'appelle Rustem et je suis le développeur principal de la société informatique kazakhe DAR. Dans cet article, je vais vous dire ce que vous devez savoir avant de passer aux modèles Event Sourcing et CQRS à l'aide de la boîte à outils Akka.
Vers 2015, nous avons commencé à concevoir notre écosystème. Après analyse et sur la base de l'expérience avec Scala et Akka, nous avons décidé de nous arrêter à la boîte à outils Akka. Nous avons réussi à implémenter des modèles Event Sourcing avec CQRS et non. L'accumulation d'expertise dans ce domaine, que je souhaite partager avec les lecteurs. Nous verrons comment Akka implémente ces modèles, ainsi que les outils disponibles et parlerons des pièges d'Akka. J'espère qu'après avoir lu cet article, vous comprendrez mieux les risques de passer à la boîte à outils Akka.
Sur les sujets du CQRS et Event Sourcing, de nombreux articles sur Habré et sur d'autres ressources ont été écrits. Cet article est destiné aux lecteurs qui comprennent déjà ce que sont le CQRS et Event Sourcing. Dans l'article, je veux me concentrer sur Akka.
Conception pilotée par domaine
De nombreux documents ont été écrits sur la conception pilotée par domaine (DDD). Il y a à la fois des opposants et des partisans de cette approche. Je veux ajouter par moi-même que si vous décidez de passer à Event Sourcing et CQRS, alors il ne sera pas superflu d'étudier DDD. De plus, la philosophie DDD se ressent dans tous les outils Akka.
En fait, Event Sourcing et CQRS ne sont qu'une petite partie de la grande image appelée Domain-Driven Design. Lors de la conception et du développement, vous pouvez vous poser de nombreuses questions sur la façon de mettre en œuvre correctement ces modèles et de les intégrer dans l'écosystème, et connaître DDD vous facilitera la vie.
Dans cet article, le terme entité (entité par DDD) signifiera un acteur de persistance qui a un identifiant unique.
Pourquoi Scala?
On nous demande souvent pourquoi Scala, et non Java. Une des raisons est Akka. Le framework lui-même, écrit en langage Scala avec prise en charge du langage Java. Ici, je dois dire qu'il existe également une implémentation sur .NET , mais c'est un autre sujet. Afin de ne pas provoquer de discussion, je n'écrirai pas pourquoi Scala est meilleur ou pire que Java. Je vais juste vous donner quelques exemples qui, à mon avis, Scala a un avantage sur Java lorsque vous travaillez avec Akka:
- Objets immuables. En Java, vous devez écrire vous-même des objets immuables. Croyez-moi, ce n'est pas facile et pas très pratique d'écrire constamment les paramètres finaux. Dans Scala
case class déjà immuable avec la fonction de copy intégrée - Style de codage. Une fois implémenté en Java, vous écrirez toujours dans le style Scala, c'est-à-dire fonctionnellement.
Voici un exemple d'implémentation d'acteur en Scala et Java:
Scala:
object DemoActor { def props(magicNumber: Int): Props = Props(new DemoActor(magicNumber)) } class DemoActor(magicNumber: Int) extends Actor { def receive = { case x: Int => sender() ! (x + magicNumber) } } class SomeOtherActor extends Actor { context.actorOf(DemoActor.props(42), "demo")
Java:
static class DemoActor extends AbstractActor { static Props props(Integer magicNumber) { return Props.create(DemoActor.class, () -> new DemoActor(magicNumber)); } private final Integer magicNumber; public DemoActor(Integer magicNumber) { this.magicNumber = magicNumber; } @Override public Receive createReceive() { return receiveBuilder() .match( Integer.class, i -> { getSender().tell(i + magicNumber, getSelf()); }) .build(); } } static class SomeOtherActor extends AbstractActor { ActorRef demoActor = getContext().actorOf(DemoActor.props(42), "demo");
(Exemple tiré d' ici )
Faites attention à l'implémentation de la méthode createReceive() utilisant l'exemple du langage Java. En interne, via la fabrique ReceiveBuilder , la correspondance de modèle est implémentée. receiveBuilder() est une méthode d'Akka pour prendre en charge les expressions lambda, à savoir la correspondance de modèles en Java. Dans Scala, cela est implémenté nativement. D'accord, le code dans Scala est plus court et plus facile à lire.
- Documentation et exemples. Malgré le fait que dans la documentation officielle il y a des exemples en Java, sur Internet, presque tous les exemples sont en Scala. De plus, il vous sera plus facile de naviguer dans les sources de la bibliothèque Akka.
En termes de performances, il n'y aura pas de différence entre Scala et Java, car tout tourne autour de la JVM.
Stockage
Avant d'implémenter Event Sourcing avec Akka Persistence, je vous recommande de présélectionner une base de données pour le stockage permanent des données. Le choix de la base dépend des exigences du système, de vos envies et préférences. Les données peuvent être stockées à la fois dans NoSQL et RDBMS, et dans un système de fichiers, par exemple LevelDB de Google .
Il est important de noter qu'Akka Persistence n'est pas responsable de l'écriture et de la lecture des données de la base de données, mais le fait via un plug-in qui devrait implémenter l'API Akka Persistence.
Après avoir choisi un outil pour stocker des données, vous devez sélectionner un plugin dans la liste ou l'écrire vous-même. La deuxième option, je ne recommande pas pourquoi réinventer la roue.
Pour le stockage permanent des données, nous avons décidé de rester à Cassandra. Le fait est que nous avions besoin d'une base fiable, rapide et distribuée. De plus, Typesafe eux-mêmes accompagnent le plugin , qui implémente entièrement l' API Akka Persistence . Il est constamment mis à jour et en comparaison avec d'autres, le plugin Cassandra a écrit une documentation plus complète.
Il est à noter que le plugin a également plusieurs problèmes. Par exemple, il n'y a toujours pas de version stable (au moment d'écrire ces lignes, la dernière version est 0.97). Pour nous, la plus grande nuisance que nous avons rencontrée lors de l'utilisation de ce plugin était la perte d'événements lors de la lecture de la requête persistante pour certaines entités. Pour une image complète, voici le tableau du CQRS:
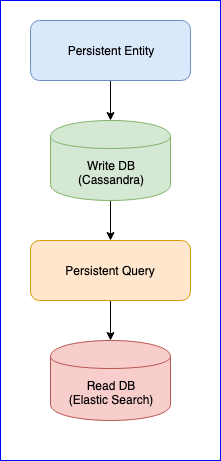
L'entité persistante distribue les événements d'entité dans des balises à l'aide de l'algorithme de hachage cohérent (par exemple, 10 fragments):
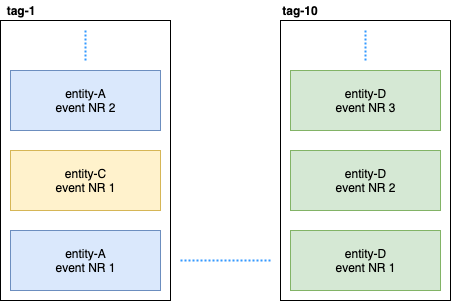
Ensuite, Persistent Query s'abonne à ces balises et lance un flux qui ajoute des données à Elastic Search. Étant donné que Cassandra est dans un cluster, les événements seront dispersés entre les nœuds. Certains nœuds peuvent s'affaisser et réagir plus lentement que d'autres. Il n'y a aucune garantie que vous recevrez les événements dans un ordre strict. Pour résoudre ce problème, le plugin est implémenté de sorte que s'il reçoit un événement non ordonné, par exemple, entity-A event NR 2 , il attend un certain temps pour l'événement initial et s'il ne le reçoit pas, il ignorera simplement tous les événements de cette entité. Même à ce sujet, il y a eu des discussions sur Gitter. Si quelqu'un est intéressé, vous pouvez lire la correspondance entre @kotdv et les développeurs du plugin: Gitter
Comment résoudre ce malentendu:
- Vous devez mettre à jour le plugin vers la dernière version. Dans les versions récentes, les développeurs de Typesafe ont résolu de nombreux problèmes liés à la cohérence éventuelle. Mais nous attendons toujours une version stable
- Des paramètres plus précis ont été ajoutés pour le composant responsable de la réception des événements. Vous pouvez essayer d'augmenter le délai d'expiration des événements non ordonnés pour un fonctionnement plus fiable du plugin: c
assandra-query-journal.events-by-tag.eventual-consistency.delay=10s - Configurez Cassandra comme recommandé par DataStax. Mettez le garbage collector G1 et allouez autant de mémoire que possible à Cassandra .
En fin de compte, nous avons résolu le problème des événements manquants, mais il y a maintenant un délai de données stable du côté de la requête de persistance (de cinq à dix secondes). Il a été décidé de laisser l'approche pour les données utilisées pour l'analyse, et lorsque la vitesse est importante, nous publions manuellement les événements sur le bus. L'essentiel est de choisir le mécanisme approprié de traitement ou de publication des données: au moins une fois ou au plus une fois. Une bonne description d'Akka peut être trouvée ici . Il était important pour nous de maintenir la cohérence des données et, par conséquent, après avoir réussi à écrire des données dans la base de données, nous avons introduit un état de transition qui contrôle la publication réussie des données sur le bus. Voici un exemple de code:
object SomeEntity { sealed trait Event { def uuid: String } case class DidSomething(uuid: String) extends Event /** * , . */ case class LastEventPublished(uuid: String) extends Event /** * , . * @param unpublishedEvents – , . */ case class State(unpublishedEvents: Seq[Event]) object State { def updated(event: Event): State = event match { case evt: DidSomething => copy( unpublishedEvents = unpublishedEvents :+ evt ) case evt: LastEventPublished => copy( unpublishedEvents = unpublishedEvents.filter(_.uuid != evt.uuid) ) } } } class SomeEntity extends PersistentActor { … persist(newEvent) { evt => updateState(evt) publishToEventBus(evt) } … }
Si pour une raison quelconque, il n'a pas été possible de publier l'événement, au prochain démarrage de SomeEntity , il saura que l'événement DidSomething pas atteint le bus et tentera de republier les données à nouveau.
Sérialiseur
La sérialisation est un point tout aussi important dans l'utilisation d'Akka. Il a un module interne - Akka Serialization . Ce module est utilisé pour sérialiser les messages lors de leur échange entre acteurs et lors de leur stockage via l'API Persistence. Par défaut, le sérialiseur Java est utilisé, mais il est recommandé d'en utiliser un autre. Le problème est que le sérialiseur Java est lent et prend beaucoup de place. Il existe deux solutions populaires - ce sont JSON et Protobuf. JSON, bien que lent, est plus facile à implémenter et à maintenir. Si vous avez besoin de minimiser le coût de la sérialisation et du stockage des données, vous pouvez vous arrêter à Protobuf, mais le processus de développement sera plus lent. En plus du modèle de domaine, vous devez écrire un autre modèle de données. N'oubliez pas le versionnage des données. Soyez prêt à écrire constamment le mappage entre le modèle de domaine et le modèle de données.
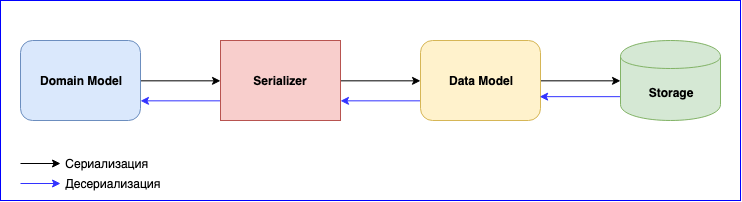
Ajout d'un nouvel événement - écriture du mappage. Modification de la structure des données - écrire une nouvelle version du modèle de données et changer la fonction de mappage. N'oubliez pas les tests pour les sérialiseurs. En général, il y aura beaucoup de travail, mais à la fin, vous obtenez des composants à couplage lâche.
Conclusions
- Étudiez soigneusement et choisissez une base et un plugin appropriés pour vous-même. Je recommande de choisir un plugin bien entretenu et qui ne cessera de se développer. Le domaine est relativement nouveau, il y a encore un tas de défauts qui n'ont pas encore été résolus
- Si vous sélectionnez le stockage distribué, vous devrez résoudre le problème avec un délai pouvant aller jusqu'à 10 secondes vous-même, ou le supporter
- La complexité de la sérialisation. Vous pouvez sacrifier la vitesse et vous arrêter sur JSON, ou choisir Protobuf et écrire de nombreux adaptateurs et les prendre en charge.
- Il y a des avantages à ce modèle, ce sont des composants faiblement couplés et des équipes de développement indépendantes qui construisent un grand système.