SDSM est terminé, mais le désir incontrôlé d'écrire demeure.

Pendant de nombreuses années, notre frère a souffert de l'exécution de travaux de routine, a croisé les doigts avant de s'engager et a manqué de sommeil à cause des retours de nuit.
Mais les temps sombres arrivent à leur fin.
Avec cet article, je vais commencer une série sur la façon dont
je vois l'automatisation.
Dans le processus, nous traiterons des étapes de l'automatisation, du stockage des variables, de la formalisation de la conception, avec RestAPI, NETCONF, YANG, YDK et nous programmerons beaucoup.
Cela signifie pour
moi que a) ce n'est pas une vérité objective, b) pas inconditionnellement la meilleure approche c) mon opinion peut changer même pendant le passage du premier au dernier article - pour être honnête, du stade du projet à la publication, j'ai tout réécrit deux fois.
Table des matières
- Buts
- Le réseau est comme un seul organisme
- Test de configuration
- Versioning
- Services de surveillance et d'autoguérison
- Moyens
- Système d'inventaire
- Système de gestion d'espace IP
- Système de description des services réseau
- Mécanisme d'initialisation de l'appareil
- Modèle de configuration indépendant du fournisseur
- Pilote spécifique au fournisseur
- Le mécanisme de livraison de la configuration à l'appareil
- CI / CD
- Mécanisme de sauvegarde et de déviation
- Système de surveillance
- Conclusion
Je vais essayer de garder l'ADSM dans un format légèrement différent du SDSM. De grands articles numérotés et détaillés continueront d'apparaître, et entre eux, je publierai de petites notes sur l'expérience quotidienne. Je vais essayer de combattre le perfectionnisme ici et de ne pas les lécher.
Comme c'est drôle que la deuxième fois, vous devez suivre le même chemin.
Tout d'abord, j'ai dû écrire des articles sur le réseau lui-même, car ils n'étaient pas dans RuNet.
Maintenant, je ne pouvais pas trouver un document complet qui systématiserait les approches de l'automatisation et utiliserait des exemples pratiques simples pour analyser les technologies ci-dessus.
Je me trompe donc peut-être en jetant des liens vers des ressources appropriées. Cependant, cela ne changera pas ma détermination à écrire, car l'objectif principal est d'apprendre moi-même quelque chose et de faciliter la vie de mon voisin est un bonus agréable qui caresse le gène de la diffusion de l'expérience.
Nous essaierons de prendre un centre de données LAN DC de taille moyenne et d'élaborer l'ensemble du schéma d'automatisation.
Je ferai certaines choses presque la première fois avec vous.
Dans les idées et outils décrits ici, je ne serai pas original. Dmitry Figol a une excellente chaîne avec des flux sur ce sujet .
Les articles sous de nombreux aspects se chevaucheront avec eux.
Le LAN DC dispose de 4 DC, d'environ 250 commutateurs, d'une demi-douzaine de routeurs et de quelques pare-feu.
Pas Facebook, mais assez pour réfléchir profondément à l'automatisation.
Il y a cependant l'opinion que si vous avez plus d'un appareil, vous avez déjà besoin d'une automatisation.
En fait, il est difficile d'imaginer que quelqu'un puisse désormais vivre sans au moins un tas de scripts à hauteur de genou.
Bien que j'aie entendu dire qu'il existe de tels bureaux où les adresses IP sont conservées dans Excel, et chacun des milliers de périphériques réseau est configuré manuellement et possède sa propre configuration unique. Bien sûr, cela peut être considéré comme de l'art contemporain, mais les sentiments de l'ingénieur seront certainement offensés.
Buts
Nous allons maintenant fixer les objectifs les plus abstraits:
- Le réseau est comme un seul organisme
- Test de configuration
- Versionnage de l'état du réseau
- Services de surveillance et d'autoguérison
Plus loin dans cet article, nous analyserons les moyens que nous utiliserons, et dans la suite, les objectifs et les moyens en détail.
Le réseau est comme un seul organisme
La phrase qui définit le cycle, même si à première vue elle peut ne pas sembler si significative:
nous allons configurer le réseau, pas les appareils individuels .
Au cours des dernières années, nous avons observé un changement d'orientation vers le traitement du réseau comme une entité unique, d'où la
mise en réseau définie par logiciel , les
réseaux axés sur l'intention et
les réseaux
autonomes entrant dans nos vies.
Après tout, ce dont les applications du réseau ont globalement besoin: connectivité entre les points A et B (enfin, parfois + B-Z) et isolation des autres applications et utilisateurs.

Et donc, notre tâche dans cette série est de
construire un système qui prend en charge la configuration actuelle de l'
ensemble du réseau , qui est déjà décomposé dans la configuration actuelle sur chaque appareil en fonction de son rôle et de son emplacement.
Le système de gestion de réseau implique que pour apporter des modifications, nous nous tournons vers lui et, à son tour, calcule l'état souhaité pour chaque périphérique et le configure.
De cette façon, nous minimisons l'utilisation de l'interface CLI entre nos mains à presque zéro - tout changement dans les paramètres de l'appareil ou la conception du réseau doit être formalisé et documenté - et ensuite uniquement déployé sur les éléments de réseau nécessaires.
C'est-à-dire, par exemple, si nous décidions qu'à partir de maintenant les commutateurs montés en rack à Kazan devraient annoncer deux réseaux au lieu d'un, nous
- Nous documentons d'abord les changements dans les systèmes
- Nous générons la configuration cible de tous les périphériques réseau
- Nous démarrons le programme de mise à jour de la configuration du réseau, qui calcule ce qui doit être supprimé sur chaque nœud, ce qu'il faut ajouter et amène les nœuds à l'état souhaité.
Dans le même temps, avec nos mains, nous n'apportons des modifications qu'à la première étape.
Test de configuration
Il est connu que 80% des problèmes surviennent lors des changements de configuration - une preuve indirecte de cela est que pendant les vacances du Nouvel An, tout est généralement calme.
J'ai personnellement été témoin de dizaines de temps d'arrêt mondiaux en raison d'une erreur humaine: la mauvaise commande, la configuration a été exécutée dans la mauvaise branche, la communauté a oublié, démoli MPLS globalement sur le routeur, configuré cinq morceaux de fer et n'a pas remarqué la sixième erreur, a commis les anciennes modifications apportées par une autre personne . Scénario l'obscurité est sombre.
L'automatisation nous permettra de faire moins d'erreurs, mais à plus grande échelle. Vous pouvez donc regrouper non pas un seul appareil, mais l'ensemble du réseau à la fois.
Depuis des temps immémoriaux, nos grands-pères ont vérifié l'exactitude des changements effectués avec un œil pointu, des œufs en acier et l'efficacité du réseau après les avoir déployés.
Ces grands-pères, dont le travail a entraîné des temps d'arrêt et des pertes catastrophiques, ont laissé moins de descendants et devraient s'éteindre avec le temps, mais l'évolution est un processus lent, et donc tout le monde ne vérifie pas les changements au laboratoire à l'avance.
Cependant, à l'avant-garde de ceux qui ont automatisé le processus de test de la configuration et de son application ultérieure au réseau. En d'autres termes, j'ai emprunté la procédure CI / CD (
Intégration Continue, Déploiement Continu ) aux développeurs.
Dans une partie, nous verrons comment implémenter cela en utilisant un système de contrôle de version, probablement un github.
Dès que vous vous habituez à l'idée de réseau CI / CD, du jour au lendemain, la méthode de vérification de la configuration en l'appliquant au réseau de travail vous semblera une ignorance médiévale précoce. Comment marteler une ogive avec un marteau.
Une continuation organique des idées sur
le système de gestion de réseau et CI / CD est la version complète de la configuration.
Versioning
Nous supposerons qu'avec tous les changements, même les plus mineurs, même sur un appareil discret, le réseau entier passe d'un état à un autre.
Et nous n'exécutons pas toujours la commande sur l'appareil, nous changeons l'état du réseau.
Maintenant, obtenons ces états et appelons-les des versions?
Disons que la version actuelle est 1.0.0.
L'adresse IP de l'interface Loopback a-t-elle changé sur l'un des ToR? Ceci est une version mineure - obtenez le numéro 1.0.1.
Examiné les politiques d'importation d'itinéraire dans BGP - un peu plus sérieux - déjà 1.1.0
Nous avons décidé de nous débarrasser d'IGP et de passer uniquement à BGP - il s'agit d'un changement de conception radical - 2.0.0.
En même temps, différents contrôleurs de domaine peuvent avoir des versions différentes - le réseau se développe, de nouveaux équipements sont installés, quelque part de nouveaux niveaux de colonne vertébrale sont ajoutés, quelque part - non, etc.
Nous parlerons du
versioning sémantique dans un article séparé.
Je le répète - tout changement (à l'exception des commandes de débogage) est une mise à jour de la version. Les administrateurs doivent être informés de tout écart par rapport à la version actuelle.
Il en va de même pour la restauration des modifications - ce n'est pas l'abolition des dernières commandes, ce n'est pas une restauration par le système d'exploitation de l'appareil - cela amène l'ensemble du réseau vers une nouvelle (ancienne) version.
Services de surveillance et d'autoguérison
Cette tâche évidente dans les réseaux modernes atteint un nouveau niveau.
Souvent, les grands fournisseurs de services pratiquent l'approche selon laquelle un service tombé en panne doit être rapidement terminé et un nouveau levé, au lieu de comprendre ce qui s'est passé.
«Très» signifie que de tous les côtés, il est nécessaire d'étaler abondamment la surveillance, qui en quelques secondes détectera les moindres écarts par rapport à la norme.
Et ici, il n'y a pas assez de mesures familières, telles que le chargement d'une interface ou l'accessibilité d'un nœud. Pas assez et suivi manuel de l'officier de garde pour eux.
Pour beaucoup de choses, il devrait généralement y avoir une
auto-guérison - les commandes allumées en rouge et se sont éteintes du plantain elles-mêmes, là où ça fait mal.
Et ici, nous surveillons également non seulement les appareils individuels, mais aussi la santé du réseau dans son ensemble, à la fois la whitebox, qui est relativement claire, et la blackbox, qui est déjà plus compliquée.
De quoi avons-nous besoin pour mettre en œuvre des plans aussi ambitieux?
- Ayez une liste de tous les appareils sur le réseau, leur emplacement, leurs rôles, leurs modèles, leurs versions logicielles.
kazan-leaf-1.lmu.net, Kazan, feuille, Juniper QFX 5120, R18.3.
- Avoir un système pour décrire les services réseau.
IGP, BGP, L2 / 3VPN, stratégie, ACL, NTP, SSH. - Pouvoir initialiser l'appareil.
Nom d'hôte, Mgmt IP, Mgmt Route, Users, RSA-Keys, LLDP, NETCONF - Configurez l'appareil et amenez la configuration à la version souhaitée (y compris l'ancienne).
- Configuration de test
- Vérifiez périodiquement l'état de tous les appareils pour les écarts par rapport à celui actuel et dites qui devrait le faire.
La nuit, quelqu'un a discrètement ajouté une règle à l'ACL . - Surveillez les performances.
Moyens
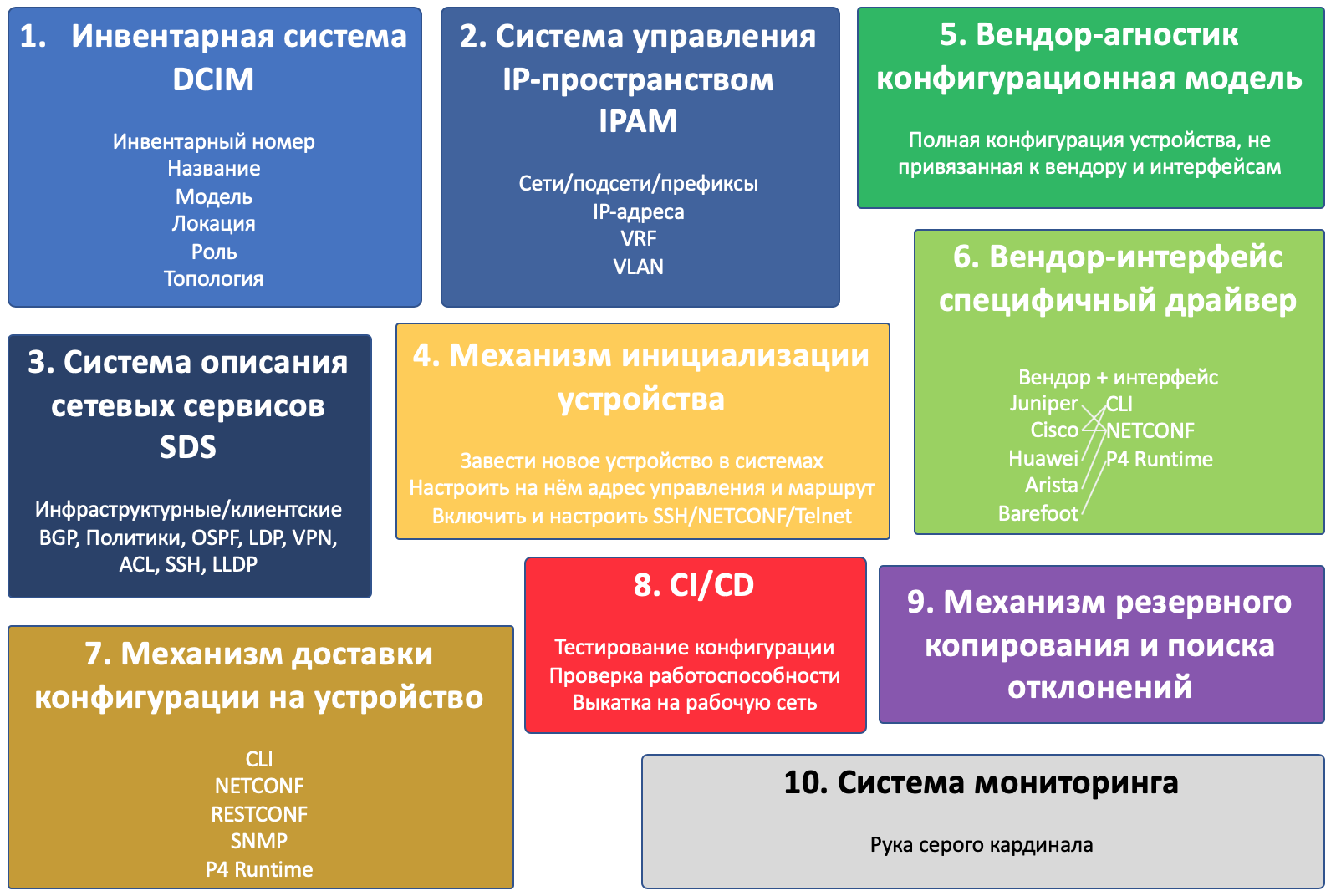
Cela semble assez compliqué pour commencer à décomposer un projet en composants.
Et il y en aura dix:
- Système d'inventaire
- Système de gestion d'espace IP
- Système de description des services réseau
- Mécanisme d'initialisation de l'appareil
- Modèle de configuration indépendant du fournisseur
- Pilote spécifique au fournisseur
- Le mécanisme de livraison de la configuration à l'appareil
- CI / CD
- Mécanisme de sauvegarde et de déviation
- Système de surveillance
Ceci, soit dit en passant, est un exemple de la façon dont la vue sur les objectifs du cycle a changé - il y avait 4 composants dans le projet de composants.

Dans l'illustration, j'ai représenté tous les composants et l'appareil lui-même.
Les composants qui se croisent interagissent les uns avec les autres.
Plus le bloc est grand, plus vous devez prêter attention à ce composant.
Composante 1. Système d'inventaire
Évidemment, nous voulons savoir à quel équipement, où il se trouve, à quoi il est connecté.
Le système d'inventaire fait partie intégrante de toute entreprise.
Le plus souvent, pour les périphériques réseau, l'entreprise dispose d'un système d'inventaire distinct qui résout des tâches plus spécifiques.
Dans le cadre d'une série d'articles, nous l'appellerons DCIM - Data Center Infrastructure Management. Bien que le terme DCIM lui-même, à proprement parler, en comprenne bien plus.
Pour nos tâches, nous stockons les informations suivantes sur l'appareil qu'il contient:
- Numéro d'inventaire
- Titre / Description
- Modèle ( Huawei CE12800, Juniper QFX5120, etc. )
- Paramètres typiques ( cartes, interfaces, etc. )
- Rôle ( Leaf, Spine, Border Router, etc. )
- Emplacement ( région, ville, centre de données, rack, unité )
- Interconnexions entre les appareils
- Topologie du réseau

Il est parfaitement clair que nous voulons nous-mêmes savoir tout cela.
Mais cela aidera-t-il à l'automatisation?
Bien sûr.
Par exemple, nous savons que dans ce centre de données sur les commutateurs Leaf, s'il s'agit de Huawei, des ACL pour filtrer certains trafics doivent être appliquées sur le VLAN, et s'il s'agit de Juniper, alors sur l'unité 0 de l'interface physique.
Ou vous devez déployer un nouveau serveur Syslog pour tous les pensionnaires de la région.
Nous y stockons des périphériques réseau virtuels, tels que des routeurs virtuels ou des réflecteurs racine. Nous pouvons ajouter un serveur DNS, NTP, Syslog et généralement tout ce qui se rapporte en quelque sorte au réseau.
Composant 2. Système de gestion de l'espace IP
Oui, et à notre époque, des équipes de personnes suivent les préfixes et les adresses IP dans un fichier Excel. Mais l'approche moderne est toujours une base de données, avec un frontend sur nginx / apache, une API et des fonctions étendues pour prendre en compte les adresses IP et les réseaux avec séparation en VRF.
IPAM - Gestion des adresses IP.
Pour nos tâches, nous y stockerons les informations suivantes:
- VLAN
- VRF
- Réseaux / Sous-réseaux
- Adresses IP
- Adresses de liaison aux appareils, réseaux aux emplacements et numéros de VLAN

Encore une fois, il est clair que nous voulons être sûrs qu'en allouant une nouvelle adresse IP pour le bouclage ToR, nous ne tomberons pas sur le fait qu'elle a déjà été attribuée à quelqu'un. Ou que nous avons utilisé deux fois le même préfixe à différentes extrémités du réseau.
Mais comment cela aide-t-il dans l'automatisation?
C'est facile.
Nous demandons un préfixe dans le système avec le rôle Loopbacks, dans lequel il y a des adresses IP disponibles pour l'allocation - si c'est le cas, sélectionnez l'adresse, sinon, nous demandons la création d'un nouveau préfixe.
Ou, lors de la création d'une configuration de périphérique, nous, du même système, pouvons découvrir dans quel VRF l'interface doit se trouver.
Et lorsque vous démarrez un nouveau serveur, le script entre dans le système, découvre dans quel serveur le commutateur, dans quel port et quel sous-réseau est affecté à l'interface - il sélectionnera l'adresse du serveur à partir de celui-ci.
Il supplie le désir de DCIM et IPAM de se combiner en un seul système afin de ne pas dupliquer les fonctions et de ne pas servir deux entités similaires.
Nous allons donc faire.
Composant 3. Système de description des services réseau
Si les deux premiers systèmes stockent des variables qui doivent encore être utilisées d'une manière ou d'une autre, le troisième décrit pour chaque rôle de périphérique comment il doit être configuré.
Il convient de souligner deux types de services réseau différents:
Les premiers sont conçus pour fournir une connectivité de base et une gestion des appareils. Il s'agit notamment de VTY, SNMP, NTP, Syslog, AAA, des protocoles de routage, CoPP, etc.
Les seconds organisent le service pour le client: MPLS L2 / L3VPN, GRE, VXLAN, VLAN, L2TP, etc.
Bien sûr, il y a aussi des cas limites - où inclure MPLS LDP, BGP? Oui, et les protocoles de routage peuvent être utilisés pour les clients. Mais ce n'est pas important.
Les deux types de services sont décomposés en primitives de configuration:
- interfaces physiques et logiques (tag / anteg, mtu)
- Adresses IP et VRF (IP, IPv6, VRF)
- ACL et politiques de gestion du trafic
- Protocoles (IGP, BGP, MPLS)
- Politiques de routage (listes de préfixes, communauté, filtres ASN).
- Services de service (SSH, NTP, LLDP, Syslog ...)
- Etc.
Comment exactement nous allons faire cela, je ne vais pas encore y penser. Nous traiterons dans un article séparé.

Si un peu plus proche de la vie, nous pourrions décrire cela
Un commutateur feuille doit avoir des sessions BGP avec tous les commutateurs Spine connectés, importer des réseaux connectés dans le processus et accepter uniquement les réseaux d'un préfixe spécifique des commutateurs Spine. Limitez CoPP IPv6 ND à 10 pps, etc.
À leur tour, les spins tiennent des sessions avec tous les corsages connectés, agissant comme des réflecteurs de racine, et ne reçoivent d'eux que des itinéraires d'une certaine longueur et avec une certaine communauté.
Composant 4. Mécanisme d'initialisation du périphérique
Sous cette rubrique, je combine les nombreuses actions qui doivent se produire pour que l'appareil apparaisse sur les radars et soit accessible à distance.
- Démarrez l'appareil dans le système d'inventaire.
- Mettez en surbrillance l'adresse IP de gestion.
- Configurez l'accès de base à celui-ci:
Nom d'hôte, adresse IP de gestion, route vers le réseau de gestion, utilisateurs, clés SSH, protocoles - telnet / SSH / NETCONF
Il existe trois approches:
- Tout est complètement manuel. L'appareil est amené sur un stand où une personne organique ordinaire le conduira dans le système, se connectera à la console et configurera. Peut fonctionner sur de petits réseaux statiques.
- ZTP - Zero Touch Provisioning. Iron est venu, s'est levé, a reçu une adresse via DHCP, s'est rendu sur un serveur spécial et s'est configuré.
- Infrastructure des serveurs de console, où la configuration initiale s'effectue via le port de console en mode automatique.
Nous parlerons des trois dans un article séparé.

Composante 5. Modèle de configuration indépendant du fournisseur
Jusqu'à présent, tous les systèmes étaient des chiffons épars donnant des variables et une description déclarative de ce que nous aimerions voir sur le réseau. Mais tôt ou tard, vous devez faire face à des détails.
À ce stade, pour chaque périphérique particulier, les primitives, les services et les variables sont combinés dans un modèle de configuration qui décrit réellement la configuration complète d'un périphérique particulier, uniquement de manière indépendante du fournisseur.
Qu'est-ce qui donne cette étape? Pourquoi ne pas configurer immédiatement l'appareil, que vous pouvez simplement remplir?
En fait, cela nous permet de résoudre trois problèmes:
- Ne vous adaptez pas à une interface spécifique pour interagir avec l'appareil. Que ce soit CLI, NETCONF, RESTCONF, SNMP - le modèle sera le même.
- Ne gardez pas le nombre de modèles / scripts par le nombre de fournisseurs sur le réseau, et en cas de changement de conception, changez-le à plusieurs endroits.
- Téléchargez la configuration depuis l'appareil (sauvegarde), disposez-la exactement dans le même modèle et comparez directement la configuration cible et celle disponible pour calculer le delta et préparer le patch de configuration, qui ne changera que les parties nécessaires ou pour détecter les écarts.

À la suite de cette étape, nous obtenons une configuration indépendante du fournisseur.
Composant 6. Pilote spécifique à l'interface fournisseur
Ne vous consolez pas en espérant qu'une fois que vous pourrez configurer une tsiska, ce sera possible de la même manière qu'un cavalier, en leur envoyant exactement les mêmes appels. Malgré la popularité croissante des boîtes blanches et l'émergence de la prise en charge de NETCONF, RESTCONF, OpenConfig, le contenu spécifique que ces protocoles fournissent est différent du fournisseur au fournisseur, et c'est l'une de leurs différences concurrentielles qu'ils n'abandonneront tout simplement pas.
C'est à peu près la même chose qu'OpenContrail et OpenStack, qui ont RestAPI comme interface NorthBound, s'attendent à des appels complètement différents.
Ainsi, à la cinquième étape, le modèle indépendant du fournisseur devrait prendre la forme dans laquelle il ira au fer.
Et ici, tous les moyens sont bons (non): CLI, NETCONF, RESTCONF, SNMP dans une simple chute.
Par conséquent, nous avons besoin d'un pilote qui traduit le résultat de l'étape précédente dans le format souhaité pour un fournisseur particulier: un ensemble de commandes CLI, une structure XML.
Composant 7. Le mécanisme de livraison de la configuration à l'appareil
Nous avons généré la configuration, mais elle doit toujours être livrée aux appareils - et, évidemment, pas à la main.Premièrement , nous sommes confrontés à la question: quel type de transport utiliserons-nous? Et le choix aujourd'hui n'est plus petit:- CLI (telnet, ssh)
SNMP- NETCONF
- RESTCONF
- API REST
- OpenFlow (bien qu'il soit éliminé de la liste, car c'est un moyen de fournir FIB, pas de paramètres)
Parlons ici de e. CLI est hérité. SNMP ... hehe.RESTCONF est toujours un animal inconnu; l'API REST n'est prise en charge par presque personne. Par conséquent, nous nous concentrerons sur NETCONF dans une boucle.En fait, comme le lecteur l'a déjà compris, nous avions déjà décidé de l'interface à ce stade - le résultat de l'étape précédente était déjà présenté dans le format de l'interface qui avait été sélectionné.Deuxièmement , avec quels outils ferons-nous cela?Ici, le choix est également large:- Script ou plateforme auto-écrit. Nous nous armons de ncclient et d'asyncIO et faisons tout nous-mêmes. Combien cela nous coûte-t-il de construire un système de déploiement à partir de zéro?
- Ansible avec sa riche bibliothèque de modules réseau.
- Salt avec son maigre travail en réseau et son bundle avec Napalm.
- En fait Napalm, qui connaît quelques vendeurs et c'est tout, bye.
- Nornir est une autre bête que nous préparons pour l'avenir.
Il n'y a toujours pas de favori choisi - nous piétinerons.Quoi d'autre est important ici? Les conséquences de l'application de la configuration.Avec succès ou non. Accès resté au matériel ou non.Il semble que la validation aidera ici à la confirmation et à la validation de ce qui a été téléchargé sur l'appareil.Ceci, combiné à la mise en œuvre correcte de NETCONF, réduit considérablement la gamme d'appareils appropriés - peu de fabricants prennent en charge les validations normales. Mais ce n'est là qu'une des conditions préalables de la DP . En fin de compte, personne ne craint que pas un seul fournisseur russe ne passe sous la condition d'une interface 32 * 100GE. Ou des soucis?
Composant 8. CI / CD
À ce stade, nous sommes déjà prêts pour tous les périphériques réseau.J'écris «pour tout» car nous parlons de versionner l'état du réseau. Et même si vous devez modifier les paramètres d'un seul commutateur, les changements pour l'ensemble du réseau sont calculés. De toute évidence, ils peuvent être nuls pour la plupart des nœuds.Mais, comme déjà mentionné ci-dessus, nous ne sommes pas des barbares afin de tout rouler à la fois dans la prod.La configuration générée doit d'abord passer par le Pipeline CI / CD.CI / CD signifie intégration continue, déploiement continu. Il s'agit d'une approche dans laquelle l'équipe publie une version majeure majeure plus d'une fois tous les six mois, remplaçant complètement l'ancienne, et Deploment introduit régulièrement de nouvelles fonctionnalités par petits lots, chacune testant de manière exhaustive la compatibilité, la sécurité et les performances (intégration).
Pour ce faire, nous avons un système de contrôle de version qui surveille les changements de configuration, un laboratoire où nous vérifions si le service client est en panne, un système de surveillance qui vérifie ce fait, et la dernière étape consiste à déployer les modifications sur le réseau de production.À l'exception des équipes de débogage, tous les changements sur le réseau doivent passer par le pipeline CI / CD - c'est notre garantie d'une vie tranquille et d'une longue carrière heureuse.
Composante 9. Système de sauvegarde et de rejet
Eh bien, je n'ai plus besoin de parler des sauvegardes.Nous les ajouterons simplement en fonction de la couronne ou du fait d'un changement de configuration dans le git.Mais la deuxième partie est plus intéressante - quelqu'un devrait garder un œil sur ces sauvegardes. Et dans certains cas, cette personne doit aller faire tourner tout comme elle était, et dans d'autres, miauler quelqu'un, que le trouble.Par exemple, s'il y a un nouvel utilisateur qui n'est pas enregistré dans les variables, vous devez le supprimer du hack. Et s'il vaut mieux ne pas toucher à la nouvelle règle de pare-feu, peut-être que quelqu'un vient d'activer le débogage, ou peut-être qu'un nouveau service, un gâchis, ne s'est pas inscrit selon les règles, mais les gens y sont déjà allés.Nous ne nous éloignerons toujours pas d’un certain petit delta à l’échelle de l’ensemble du réseau, malgré tous les systèmes d’automatisation et une main d’acier de gestion. Pour déboguer les problèmes de toute façon, personne n'apportera de configuration au système. De plus, ils peuvent même ne pas être prévus par le modèle de configuration.Par exemple, une règle de pare-feu pour compter le nombre de paquets sur une adresse IP spécifique, pour localiser le problème - une configuration temporaire tout à fait ordinaire.

Composante 10. Système de surveillance
Au début, je n'allais pas aborder le sujet de la surveillance - toujours un sujet volumineux, controversé et complexe. Mais en cours de route, il s'est avéré que cela fait partie intégrante de l'automatisation. Et vous ne pouvez pas le contourner même sans vous entraîner.Développer la pensée est une partie organique du processus CI / CD. Après avoir déployé la configuration sur le réseau, nous devons être en mesure de déterminer si tout va bien maintenant.Et ce n'est pas seulement et pas tellement sur les graphiques d'utilisation des interfaces ou de la disponibilité de l'hôte, mais sur des choses plus subtiles - la disponibilité des routes nécessaires, les attributs sur eux, le nombre de sessions BGP, les voisins OSPF, les services de disponibilité de bout en bout.Mais les journaux système sur le serveur externe ont-ils cessé de se plier, l'agent SFlow est-il tombé en panne, les baisses dans les files d'attente ont-elles commencé à augmenter et la connexion entre une paire de préfixes s'est-elle rompue?Dans un article séparé, nous y réfléchissons.
Conclusion
Comme base, j'ai choisi l'une des conceptions de réseaux de centres de données modernes - L3 Clos Fabric avec BGP comme protocole de routage.Cette fois, nous allons construire un réseau sur Juniper, car maintenant l'interface JunOs est un vanlav.Compliquons notre vie en utilisant uniquement des outils Open Source et un réseau multi-fournisseurs - donc, en dehors de Juniper, en cours de route, je choisirai un autre gars chanceux.Le plan pour les publications à venir est quelque chose comme ceci:Je vais d'abord parler des réseaux virtuels. Premièrement, parce que je le veux, et deuxièmement, parce que sans cela, la conception du réseau d'infrastructure ne sera pas très claire.Puis sur la conception du réseau lui-même: topologie, routage, politiques.Assemblons le stand de laboratoire.Réfléchissons et pratiquons peut-être l'initialisation de l'appareil sur le réseau.Et puis sur chaque composant dans les détails intimes.Et oui, je ne promets pas de terminer élégamment ce cycle avec une solution toute faite. :)
Liens utiles
- Avant de plonger dans la série, vous devriez lire le livre de Natasha Samoilenko Python pour les ingénieurs réseau . Et, peut-être, suivez un cours .
- Il sera également utile de lire le RFC sur la conception des usines de centres de données de Facebook pour la paternité de Peter Lapukhov.
- La documentation de l'architecture Tungsten Fabric (anciennement Open Contrail) vous donnera une idée du fonctionnement du Overlay SDN .
Merci
Gorges romaines. Pour commentaires et modifications.Artyom Chernobay. Pour KDPV.