
Récemment, plusieurs articles ont critiqué ImageNet, peut-être l'ensemble d'images le plus célèbre utilisé pour entraîner les réseaux de neurones.
Dans le premier article, Approximation des CNN avec des modèles de caractéristiques de sac local fonctionne étonnamment bien sur ImageNet, les auteurs prennent un modèle similaire à un sac de mots et utilisent des fragments de l'image comme «mots». Ces fragments peuvent mesurer jusqu'à 9x9 pixels. Et en même temps, sur un tel modèle, où toute information sur la disposition spatiale de ces fragments est complètement absente, les auteurs obtiennent une précision de 70 à 86% (par exemple, la précision d'un ResNet-50 régulier est de ~ 93%).
Dans le deuxième article des CNN formés par ImageNet sont biaisés vers la texture, les auteurs concluent que l'ensemble de données ImageNet lui-même et la façon dont les personnes et les réseaux de neurones perçoivent les images en sont coupables et suggèrent d'utiliser un nouvel ensemble de données - Stylized-ImageNet.
Plus en détail sur ce que les gens voient sur les images et sur les réseaux de neurones
ImageNet
L'ensemble de données ImageNet a commencé à être créé en 2006 par les efforts du professeur Fei-Fei Li et continue d'évoluer à ce jour. À l'heure actuelle, il contient environ 14 millions d'images appartenant à plus de 20 000 catégories différentes.
Depuis 2010, un sous-ensemble de cet ensemble de données, connu sous le nom d'ImageNet 1K avec environ 1 million d'images et des milliers de classes, a été utilisé dans le cadre du défi de reconnaissance visuelle à grande échelle d'ImageNet (ILSVRC). Dans ce concours, en 2012, AlexNet, un réseau de neurones à convolution, a tiré avec une précision de 60% dans le top 1 et de 80% dans le top 5.
C'est sur ce sous-ensemble de l'ensemble de données que les personnes du milieu universitaire mesurent leur SOTA lorsqu'elles proposent de nouvelles architectures de réseau.
Un peu sur le processus d'apprentissage sur cet ensemble de données. Nous parlerons du protocole de formation sur ImageNet en milieu académique. Autrement dit, lorsque les résultats d'un réseau SE block, ResNeXt ou DenseNet nous sont présentés dans l'article, le processus ressemble à ceci: le réseau apprend pendant 90 époques, la vitesse d'apprentissage diminue des 30e et 60e époques, toutes les 10 fois, en tant qu'optimiseur un SGD ordinaire avec une petite décroissance de poids est sélectionné, seuls RandomCrop et HorizontalFlip sont utilisés à partir des augmentations, l'image est généralement redimensionnée à 224x224 pixels.
Voici un exemple de script pytorch pour la formation sur ImageNet.
BagNet
Revenons aux articles mentionnés précédemment. Dans le premier d'entre eux, les auteurs voulaient un modèle plus facile à interpréter que les réseaux profonds ordinaires. Inspirés par l'idée des modèles de sac de fonctionnalité, ils créent leur propre famille de modèles - BagNets. En utilisant comme base le réseau ResNet-50 habituel.
Remplaçant certaines convolutions 3x3 par 1x1 dans ResNet-50, ils garantissent que le champ récepteur des neurones sur la dernière couche convolutionnelle est considérablement réduit, jusqu'à 9x9 pixels. Ainsi, ils limitent les informations disponibles à un neurone individuel à un très petit fragment de l'image entière - un patch de plusieurs pixels. Il convient de noter que pour le ResNet-50 vierge, la taille du champ récepteur est supérieure à 400 pixels, ce qui recouvre complètement l'image, qui est généralement redimensionnée à 224x224 pixels.
Ce patch est le fragment maximum de l'image à partir duquel le modèle pourrait extraire des données spatiales. À la fin du modèle, toutes les données étaient simplement résumées et le modèle ne pouvait en aucun cas savoir où se trouvait chaque patch par rapport aux autres patchs.
Au total, trois variantes de réseaux à champ récepteur 9x9, 17x17 et 33x33 ont été testées. Et, malgré le manque total d'informations spatiales, ces modèles ont pu obtenir une bonne précision dans la classification sur ImageNet. La précision du Top 5 pour les patchs 9x9 était de 70%, pour 17x17 - 80%, pour 33x33 - 86%. A titre de comparaison, la précision ResNet-50 top-5 est d'environ 93%.

La structure du modèle est illustrée dans la figure ci-dessus. Chaque patch de qxqx3 pixels découpés dans l'image est transformé en vecteur 2048 par le réseau. Ensuite, ce vecteur est alimenté à l'entrée d'un classificateur linéaire, qui produit des scores pour chacune des 1000 classes. En collectant les scores de chaque patch dans un tableau 2D, vous pouvez obtenir une carte thermique pour chaque classe et chaque pixel de l'image d'origine. Les notes finales pour l'image ont été obtenues en additionnant la carte thermique de chaque classe.
Exemples de cartes thermiques pour certaines classes:

Comme vous pouvez le voir, la plus grande contribution au bénéfice d'une classe particulière est apportée par les correctifs situés sur les bords des objets. Les correctifs de l'arrière-plan sont presque ignorés. Jusqu'à présent, tout va bien.
Regardons les correctifs les plus informatifs:

Par exemple, les auteurs ont suivi quatre cours. Pour chacun d'eux, 2x7 patchs les plus significatifs ont été sélectionnés (c'est-à-dire les patchs où le score de cette classe était le plus élevé). La rangée supérieure de 7 patchs est extraite des images de la classe correspondante uniquement, celle du bas - de l'échantillon entier d'images.
Ce que l'on peut voir sur ces photos est remarquable. Par exemple, pour la classe des tanches (tanche, poisson), les doigts sont une caractéristique. Oui, des doigts humains ordinaires sur fond vert. Et tout cela parce qu'il y a un pêcheur dans presque toutes les images avec cette classe, qui, en fait, tient ce poisson dans ses mains, exhibant un trophée.
Pour les ordinateurs portables, les touches de lettre sont une caractéristique. Les clés de machine à écrire comptent également pour cette classe.
Une caractéristique d'une couverture de livre est constituée de lettres sur fond coloré. Que ce soit même une inscription sur un T-shirt ou sur un sac.
Il semblerait que ce problème ne devrait pas nous déranger. Puisqu'il n'est inhérent qu'à une classe étroite de réseaux avec un champ récepteur très limité. Mais en outre, les auteurs ont calculé la corrélation entre les logits (sorties réseau avant le softmax final) attribués à chaque classe BagNet avec un champ récepteur différent, et les logits de VGG-16, qui a un champ récepteur assez important. Et ils l'ont trouvée assez élevée.
Corrélation entre BagNets et VGG-16 Les auteurs se sont demandé si BagNet contient des indices sur la façon dont les autres réseaux prennent des décisions.
Pour l'un des tests, ils ont utilisé une technique comme le brouillage d'image. Ce qui a consisté à utiliser un générateur de texture basé sur des matrices de gramme pour composer une image où les textures sont enregistrées, mais les informations spatiales manquent.

VGG-16, formé sur des images ordinaires à part entière, a plutôt bien géré ces images brouillées. Sa précision dans le top 5 est passée de 90% à 80%. C'est-à-dire que même les réseaux avec un champ récepteur assez large préfèrent toujours se souvenir des textures et ignorer les informations spatiales. Par conséquent, leur précision n'est pas tombée lourdement sur les images brouillées.
Les auteurs ont mené une série d'expériences où ils ont comparé les parties des images les plus importantes pour BagNet et d'autres réseaux (VGG-16, ResNet-50, ResNet-152 et DenseNet-169). Tout laissait entendre que d'autres réseaux, comme BagNet, s'appuient sur de petits fragments d'images et commettent à peu près les mêmes erreurs lors de la prise de décisions. Cela était particulièrement visible pour les réseaux peu profonds tels que VGG.
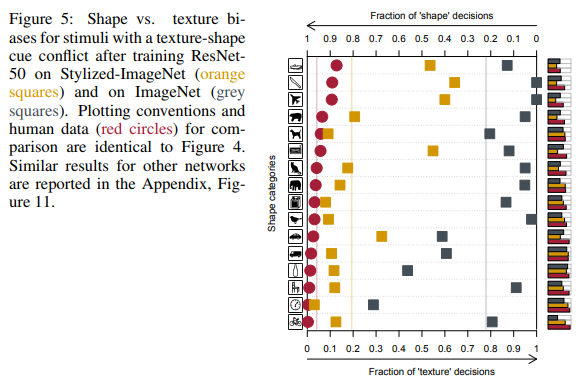
Cette tendance des réseaux à prendre des décisions basées sur les textures, contrairement à nous, les gens qui préfèrent la forme (voir la figure ci-dessous), a incité les auteurs du deuxième article à créer un nouvel ensemble de données basé sur ImageNet.
ImageNet stylisé
Tout d'abord, les auteurs de l'article utilisant le transfert de style ont créé un ensemble d'images où la forme (données spatiales) et les textures d'une image se contredisaient. Et nous avons comparé les résultats de personnes et de réseaux de convolution profonds de différentes architectures sur un ensemble de données synthétisées de 16 classes.

Dans l'extrême droite, les gens voient un chat, un réseau - un éléphant.

Comparaison des résultats des personnes et des réseaux de neurones.
Comme vous pouvez le voir, les gens lors de l'attribution d'un objet à une classe particulière se sont appuyés sur la forme des objets, les réseaux de neurones sur les textures. Dans la figure ci-dessus, les gens ont vu un chat, un réseau - un éléphant.
Oui, ici, vous pouvez trouver à redire au fait que les filets sont également un peu à droite et cela, par exemple, pourrait être un éléphant photographié de près avec le tatouage d'un chat bien-aimé. Mais le fait que les réseaux lors de la prise de décisions se comportent différemment des gens, les auteurs ont considéré le problème et ont commencé à chercher des moyens de le résoudre.
Comme mentionné ci-dessus, en s'appuyant uniquement sur les textures, le réseau est capable d'obtenir un bon résultat avec une précision de 86% dans le top 5. Et il ne s'agit pas de plusieurs classes, où les textures aident à classer correctement les images, mais de la plupart des classes.
Le problème est dans ImageNet lui-même, car il sera montré plus tard que le réseau est capable d'apprendre la forme, mais ne le fait pas, car les textures sont suffisantes pour cet ensemble de données et les neurones responsables des textures sont sur des couches peu profondes, qui sont beaucoup plus faciles à former.
En utilisant cette fois un mécanisme de transfert de style AdaIN légèrement différent, les auteurs ont créé un nouvel ensemble de données - Stylized ImageNet. La forme des objets a été tirée d'ImageNet, et l'ensemble des textures de ce concours sur Kaggle . Le script de génération est disponible sur le lien .

De plus, par souci de concision, ImageNet sera appelé IN , ImageNet stylisé SIN .
Les auteurs ont pris ResNet-50 et trois BagNet avec un champ récepteur différent et se sont entraînés sur un modèle distinct pour chacun des ensembles de données.
Et voici ce qu'ils ont fait:
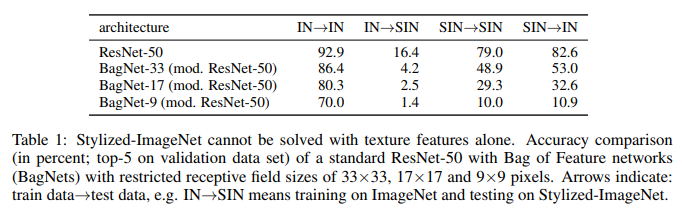
Ce que nous voyons ici. ResNet-50 formé sur IN est complètement inapte sur SIN. Ce qui confirme en partie que lors de l'entraînement sur IN, le réseau s'adapte aux textures et ignore la forme des objets. Dans le même temps, le ResNet-50 formé sur SIN fait parfaitement face à la fois à SIN et à IN. Autrement dit, s'il est privé d'un chemin simple, le réseau suit un chemin difficile - il enseigne la forme des objets.
BagNet a finalement commencé à se comporter comme prévu, en particulier sur les petits correctifs, car il n'a rien à quoi se raccrocher - les informations de texture manquent simplement dans le NAS.
Dans les seize classes mentionnées précédemment, ResNet-50, formé sur le NAS, a commencé à donner des réponses plus similaires à celles que les gens donnent:
En plus de simplement former ResNet-50 sur le SIN, les auteurs ont essayé de former le réseau sur un ensemble mixte de SIN et IN, y compris un réglage fin séparément sur le IN pur.

Comme vous pouvez le voir, lorsque vous utilisez SIN + IN pour la formation, les résultats se sont améliorés non seulement sur la tâche principale - la classification des images sur ImageNet, mais également sur la tâche de détection des objets sur le jeu de données PASCAL VOC 2007.
De plus, les réseaux formés au SIN sont devenus plus résistants à divers bruits dans les données.
Conclusion
Même maintenant, en 2019, après sept ans de succès avec AlexNet, lorsque les réseaux de neurones sont largement utilisés en vision par ordinateur, lorsque ImageNet 1K est devenu de facto la norme pour évaluer les performances des modèles dans l'environnement universitaire, le mécanisme de prise de décision des réseaux de neurones n'est pas tout à fait clair. . Et comment les ensembles de données sur lesquels ces réseaux ont été formés influencent cela.
Les auteurs du premier article ont tenté de faire la lumière sur la façon dont ces décisions sont prises dans les réseaux avec une architecture de sac de fonctionnalités avec un champ récepteur limité, ce qui est plus facile à interpréter. Et, en comparant les réponses de BagNet et les réseaux de neurones profonds habituels, nous sommes arrivés à la conclusion que les processus décisionnels en eux sont assez similaires.
Les auteurs du deuxième article ont comparé la façon dont les gens et les réseaux de neurones perçoivent les images dans lesquelles la forme et les textures se contredisent. Et ils ont suggéré d'utiliser un nouvel ensemble de données, Stylized ImageNet, pour réduire les différences de perception. Ayant reçu en prime une augmentation de la précision de la classification sur ImageNet et de la détection sur des ensembles de données tiers.
La principale conclusion peut être tirée comme suit: les réseaux qui étudient en images, ayant la capacité de se souvenir des propriétés spatiales de plus haut niveau des objets, préfèrent un moyen plus facile d'atteindre l'objectif - de s'ajuster aux textures. Si l'ensemble de données sur lequel ils s'entraînent le permet.
En plus de l'intérêt académique, le problème du sur-ajustement de la texture est important pour nous tous qui utilisons des modèles pré-formés pour transférer l'apprentissage dans leurs tâches.
Une conséquence importante de tout cela pour nous est que vous ne devriez pas faire confiance au poids des modèles qui sont généralement pré-formés sur ImageNet, car pour la plupart d'entre eux, des augmentations assez simples ont été utilisées qui ne contribuent pas à éliminer le sur-ajustement. Et il est préférable, si possible, d'avoir des modèles formés avec des augmentations plus sérieuses ou StylNet ImageNet + ImageNet dans le nid. Pour toujours pouvoir comparer celle qui convient le mieux à notre tâche actuelle.