
Beaucoup de gens sont habitués à évaluer un film sur KinoPoisk ou imdb après l'avoir vu, et les sections «Également acheté avec ce produit» et «Produits populaires» se trouvent dans n'importe quelle boutique en ligne. Mais il existe des types de recommandations moins familiers. Dans cet article, je parlerai des tâches recommandées par les systèmes de recommandation, où exécuter et quoi google.
Que recommandons-nous?
Et si nous voulons recommander un
itinéraire confortable pour l'utilisateur ? Différents aspects du voyage sont importants pour différents utilisateurs: la disponibilité des sièges, le temps de trajet, la circulation, la climatisation, une belle vue depuis la fenêtre. Une tâche inhabituelle, mais il est assez clair comment construire un tel système.
Et si nous recommandons les
nouvelles ? Les nouvelles deviennent rapidement obsolètes - vous devez montrer aux utilisateurs les derniers articles pendant qu'ils sont toujours pertinents. Il est nécessaire de comprendre le contenu de l'article. Déjà plus difficile.
Et si nous recommandons des
restaurants basés sur des critiques? Mais nous recommandons non seulement le restaurant, mais aussi des plats spécifiques qui valent la peine d'être essayés. Vous pouvez également donner des recommandations aux restaurants sur ce qui mérite d'être amélioré.
Et si nous
élargissons la tâche et essayons de répondre à la question: "Quel produit intéressera le plus grand groupe de personnes?" Cela devient très inhabituel et on ne sait pas immédiatement comment résoudre ce problème.
En fait, il existe de nombreuses variantes de la tâche de recommandations et chacune a ses propres nuances. Vous pouvez recommander des choses complètement inattendues. Mon exemple préféré est de recommander des
aperçus sur Netflix .

Tâche plus étroite
Prenez la tâche familière et familière de recommander de la musique. Que voulons-nous recommander exactement?

Sur ce collage, vous pouvez trouver des exemples de diverses recommandations de Spotify, Google et Yandex.
- Mise en évidence d'intérêts homogènes dans le Daily Mix
- Communiqué de presse Radar personnalisé, nouvelles versions recommandées, Premiere
- Sélection personnelle de ce que vous aimez - Playlist du jour
- Sélection personnelle de titres que l'utilisateur n'a pas encore entendus - Discover Weekly, Dejavu
- Une combinaison des deux points précédents avec un biais dans de nouveaux morceaux - I'm Feeling Lucky
- Situé dans la bibliothèque, mais pas encore entendu - Cache
- Vos meilleurs morceaux 2018
- Les morceaux que vous avez écoutés à 14 ans et qui ont façonné vos goûts - Your Time Capsule
- Des pistes que vous aimerez peut-être, mais qui diffèrent de ce que l'utilisateur écoute habituellement - Briseurs de goût
- Pistes d'artistes qui se produisent dans votre ville
- Collections de styles
- Sélections d'activités et d'humeur
Et c'est sûr que vous pouvez trouver autre chose. Même si nous sommes absolument en mesure de prédire les pistes que l'utilisateur aime, la question demeure sous quelle forme et dans quelle disposition ils doivent être émis.
Mise en scène classique
Dans l'énoncé classique du problème, tout ce que nous avons est une matrice de notation utilisateur-article. Elle est très clairsemée et notre tâche consiste à remplir les valeurs manquantes. Habituellement, le RMSE de la note prédite est utilisé comme une mesure, mais
il y a une opinion que cela n'est pas entièrement correct et que les caractéristiques de la recommandation dans son ensemble devraient être prises en compte, et non l'exactitude de la prédiction d'un nombre spécifique.
Comment évaluer la qualité?
Évaluation en ligne
La façon la plus préférable d'évaluer la qualité du système est la vérification directe sur les utilisateurs dans le contexte des mesures commerciales. Il peut s'agir du CTR, du temps passé dans le système ou du nombre d'achats. Mais les expériences sur les utilisateurs coûtent cher, et je ne veux pas déployer un mauvais algorithme même pour un petit groupe d'utilisateurs, ils utilisent donc des mesures de qualité hors ligne avant les tests en ligne.
Évaluation hors ligne
Les métriques de classement, telles que MAP @ k et nDCG @ k, sont généralement utilisées comme métriques de qualité.
Relevance dans le contexte de
MAP@k est une valeur binaire, et dans le contexte de
nDCG@k peut
nDCG@k avoir une échelle de notation.
Mais, en plus de l'exactitude de la prédiction, nous pouvons être intéressés par d'autres choses:
- overage - la part des biens qui est émise par le recommandataire,
- personnalisation - dans quelle mesure les recommandations diffèrent-elles entre les utilisateurs,
- diversité - la diversité des produits dans la recommandation.
En général, les mesures sont bien examinées. À
quel point votre système de recommandation est-il bon? Une enquête sur les évaluations en recommandation . Un exemple de formalisation des métriques de nouveauté peut être trouvé dans
Classement et pertinence dans les métriques de nouveauté et de diversité pour les systèmes de recommandation .
Les données
Rétroaction explicite
La matrice de notation est un exemple de données explicites. Aime, n'aime pas, note - l'utilisateur lui-même a clairement exprimé le degré de son intérêt pour l'article. Ces données sont généralement rares. Par exemple, dans le
Rekko Challenge dans les données de test, seulement 34% des utilisateurs ont au moins une note.
Rétroaction implicite
Il y a beaucoup plus d'informations sur les préférences implicites - vues, clics, bookmarking, configuration des notifications. Mais si l'utilisateur a regardé le film - cela signifie seulement qu'avant de regarder le film lui semblait assez intéressant. Nous ne pouvons pas tirer de conclusions directes quant à savoir si le film a été aimé ou non.
Fonctions de perte pour l'apprentissage
Pour utiliser la rétroaction implicite, nous avons trouvé des méthodes d'enseignement appropriées.
Classement personnalisé bayésien
Article d'origine .
On sait avec quels éléments l'utilisateur a interagi. Nous supposons que ce sont des exemples positifs qu'il a aimés. Il existe encore de nombreux éléments avec lesquels l'utilisateur n'a pas interagi. Nous ne savons pas lesquels d'entre eux intéresseront l'utilisateur et lesquels ne le seront pas, mais nous savons certainement que tous ces exemples ne se révéleront pas positifs. Nous faisons une généralisation grossière et considérons l'absence d'interaction comme un exemple négatif.
Nous échantillonnerons des triplets {utilisateur, élément positif, élément négatif} et affinerons le modèle si un exemple négatif est mieux noté qu'un exemple positif.
Rang approximatif pondéré par paire
Ajoutez à l'idée précédente le taux d'apprentissage adaptatif. Nous évaluerons la formation du système en fonction du nombre d'échantillons que nous avons dû examiner pour trouver un exemple négatif pour la paire donnée {utilisateur, exemple positif}, que le système a notée plus élevée que positive.
Si nous avons trouvé un tel exemple la première fois, alors l'amende devrait être grande. Si vous avez dû chercher longtemps, alors le système fonctionne déjà bien et vous n'avez pas besoin de beaucoup d'amende.
À quoi d'autre vaut-il la peine de penser?
Démarrage à froid
Dès que nous avons appris à faire des prédictions pour les utilisateurs et produits existants, deux questions se posent: - "Comment recommander un produit que personne n'a encore vu?" et "Que dois-je recommander à un utilisateur qui n'a pas encore de note unique?". Pour résoudre ce problème, ils essaient d'extraire des informations d'autres sources. Il peut s'agir de données sur un utilisateur d'autres services, d'un questionnaire lors de l'inscription, d'informations sur un article à partir de son contenu.
Dans ce cas, il existe des tâches pour lesquelles l'état d'un démarrage à froid est constant. Dans les recommandations basées sur la session, vous devez avoir le temps de comprendre quelque chose sur l'utilisateur pendant qu'il est sur le site. De nouveaux articles apparaissent constamment dans les recommandateurs de produits d'actualité ou de mode, tandis que les anciens articles deviennent rapidement obsolètes.
Longue queue
Si pour chaque élément, nous calculons sa popularité sous la forme du nombre d'utilisateurs qui ont interagi avec lui ou ont donné une note positive, nous obtiendrons très souvent un graphique comme dans l'image:
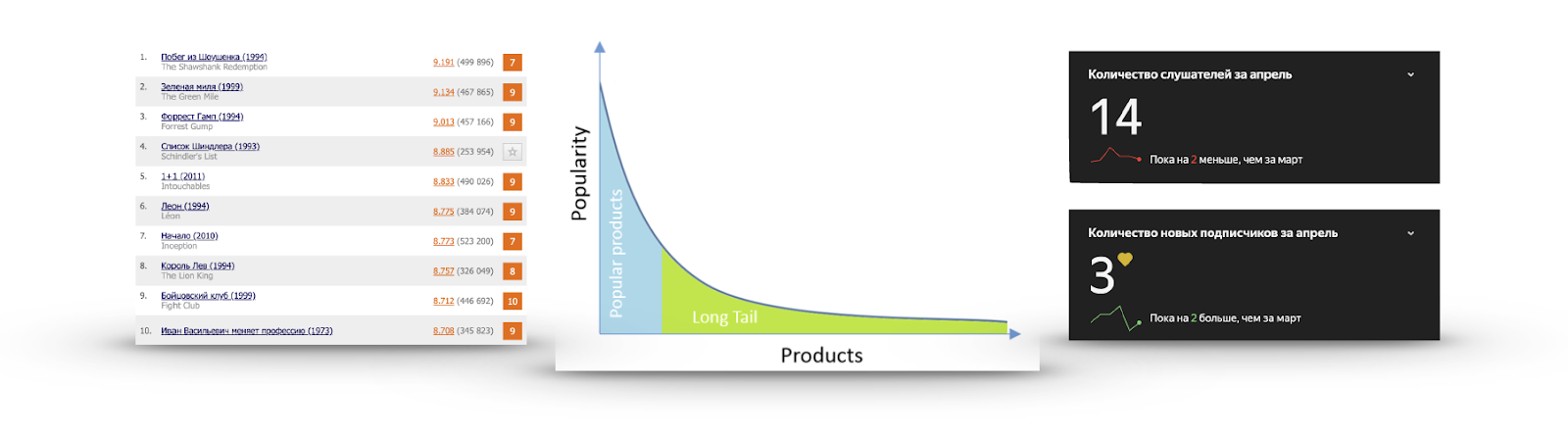
Il y a un très petit nombre d'articles que tout le monde connaît. Il est inutile de les recommander, car l'utilisateur les a probablement déjà vus et n'a tout simplement pas donné de note, soit les connaît et va les voir, soit a fermement décidé de ne pas regarder du tout. J'ai regardé la bande-annonce de Schindler’s List plus d'une fois, mais je n'allais pas la voir.
D'un autre côté, la popularité baisse très rapidement et presque personne n'a vu la grande majorité des articles. Faire des recommandations à partir de cette partie est plus utile: il existe un contenu intéressant que l'utilisateur est peu susceptible de se trouver. Par exemple, à droite, les statistiques d'écoute de l'un de mes groupes préférés sur Yandex.Music.
Exploration vs exploitation
Disons que nous savons exactement ce que l'utilisateur aime. Est-ce à dire que nous devrions recommander la même chose? On a le sentiment que de telles recommandations deviendront rapidement ennuyeuses et il vaut parfois la peine de montrer quelque chose de nouveau. Lorsque nous recommandons exactement ce que devrait être l'exploitation. Si nous essayons d'ajouter quelque chose de moins populaire aux recommandations ou de les diversifier, c'est de l'exploration. Je veux équilibrer ces choses.
Recommandations non personnalisées
L'option la plus simple est de recommander la même chose à tout le monde.
Trier par popularité
Score = (notes positives) - (notes négatives)
Vous pouvez soustraire les aversions de goûts et les trier. Mais dans ce cas, nous ne tenons pas compte de leur pourcentage. On a le sentiment que 200 likes de 50 aversions ne sont pas les mêmes que 1200 likes et 1050 aversions.
Score = (notes positives) / (notes totales)
Vous pouvez diviser le nombre de likes par le nombre de dégoûts, mais dans ce cas, nous ne prenons pas en compte le nombre de notes et un produit avec une note de 5 points sera classé plus haut qu'un produit très populaire avec une note moyenne de 4,8.
Comment
ne pas trier par note moyenne et considérer le nombre de notes? Calculez l'intervalle de confiance: "Sur la base des estimations disponibles, la probabilité d'une probabilité de 95% de la véritable part de notes positives est-elle au moins quoi?" La réponse à cette question a été donnée par Edwin Wilson en 1927.
- part observée des notations positives
- Quantile 1 alpha de la distribution normale
La compatibilité
La sélection d'ensembles de produits fréquemment rencontrés comprend tout un groupe de tâches d'exploration de modèles:
exploration de modèles périodiques, exploration de règles séquentielles, exploration de modèles séquentiels, extraction d'ensembles d'éléments de haute utilité ,
extraction fréquente d'ensembles d'éléments (analyse de panier) . Chaque tâche spécifique aura ses propres
méthodes , mais si elles sont grossièrement généralisées, les algorithmes de recherche d'ensembles fréquents effectuent une recherche abrégée en premier, en essayant de ne pas trier les options manifestement mauvaises.
Les ensembles rares sont coupés au niveau du support de frontière donné - le nombre ou la fréquence d'occurrence de l'ensemble dans les données.
Après avoir mis en évidence l'ensemble d'éléments fréquents, la qualité de leur dépendance est évaluée à l'aide des métriques Lift ou Confindence (a, b) / Confidence (! A, b). Ils visent à supprimer les fausses dépendances.
Par exemple, les bananes peuvent souvent être trouvées dans le panier d'épicerie avec des produits en conserve. Mais le point n'est pas dans une connexion particulière, mais dans le fait que les bananes sont populaires par elles-mêmes, et cela devrait être pris en compte lors de la recherche de correspondances.
Recommandations personnalisées
Basé sur le contenu
L'idée d'une approche basée sur le contenu est de créer pour lui un vecteur de ses préférences dans l'espace des objets basé sur l'historique des actions des utilisateurs et de recommander des produits proches de ce vecteur.
Autrement dit, l'article doit avoir une description des caractéristiques. Par exemple, il peut s'agir de genres de films. L'histoire des goûts et des dégoûts des films est un vecteur de préférence,
mettant en évidence certains genres et en évitant d'autres. En comparant le vecteur utilisateur et le vecteur article, vous pouvez faire un classement et obtenir des recommandations.
Filtrage collaboratif

Le filtrage collaboratif suppose une matrice d'évaluation des éléments utilisateur. L'idée est de trouver les «voisins» les plus similaires pour chaque utilisateur et de combler les lacunes d'un utilisateur spécifique en pondérant la moyenne des notes des «voisins».
De même, vous pouvez examiner la similitude des articles, en croyant que des articles similaires sont appréciés par des personnes similaires. Techniquement, il s'agira simplement d'un examen de la matrice transposée d'estimations.
Les utilisateurs utilisent l'échelle d'évaluation différemment - quelqu'un ne la met jamais au-dessus de huit et quelqu'un utilise l'échelle entière. Ceci est utile à prendre en compte, et il est donc possible de prédire non pas la note elle-même, mais un écart par rapport à la note moyenne.
Ou vous pouvez normaliser les estimations à l'avance.
Factorisation matricielle
Des mathématiques,
nous savons que toute matrice peut être décomposée en le produit de trois matrices. Mais la matrice des notations est très clairsemée, 99% est monnaie courante. Et SVD ne sait pas quelles sont les lacunes. Les remplir avec une valeur moyenne n'est pas très souhaitable. Et en général, nous ne sommes pas très intéressés par la matrice des valeurs singulières - nous voulons juste obtenir une vue cachée des utilisateurs et des objets, qui, une fois multipliés, se rapprocheront de la vraie note. Vous pouvez immédiatement vous décomposer en deux matrices.
Que faire des passes? Marteau sur eux. Il s'est avéré que vous pouvez vous entraîner à des estimations approximatives par métrique RMSE en utilisant SGD ou ALS, en ignorant complètement les omissions. Le premier de ces algorithmes est
Funk SVD , qui a été inventé en 2006 dans le cadre de la résolution de la concurrence de Netflix.
Prix Netflix
Prix Netflix - un événement important qui a donné une forte impulsion au développement de systèmes de recommandation. L'objectif du concours est de dépasser de 10% le système de recommandation Cinematch RMSE existant. À cette fin, un grand ensemble de données contenant 100 millions de notes a été fourni à l'époque. La tâche peut ne pas sembler si difficile, mais pour atteindre la qualité requise, il a fallu redécouvrir le concours deux fois - une solution n'a été reçue que pendant 3 ans du concours. S'il avait été nécessaire d'obtenir une amélioration de 15%, cela n'aurait peut-être pas pu être réalisé sur la base des données fournies.
Pendant la compétition,
certaines caractéristiques
intéressantes ont été trouvées dans les données. Le graphique montre la note moyenne des films en fonction de la date de leur apparition dans le catalogue Netflix. L'écart apparent est lié au fait qu'à cette époque, Netflix est passé d'une échelle objective (un mauvais film, un bon film) à une échelle subjective (je ne l'aimais pas, je l'aimais vraiment). Les gens sont moins critiques lorsqu'ils expriment leur évaluation, plutôt que de caractériser un objet.
Ce graphique montre comment la note moyenne d'un film change après sa sortie. On peut voir que sur 2000 jours, le score augmente de 0,2. Autrement dit, après que le film a cessé d'être nouveau, ceux qui sont assez confiants qu'il aimera le film, ce qui augmente la cote, commencent à le regarder.
Le premier prix intermédiaire a été remporté par une équipe de spécialistes d'AT & T - Korbell. Après 2000 heures de travail et la compilation d'un ensemble de 107 algorithmes, ils ont réussi à obtenir une amélioration de 8,43%.
Parmi les modèles figurait une variation de SVD et RBM, qui fournissaient en eux-mêmes la plupart des données d'entrée. Les 105 algorithmes restants n'ont amélioré que le centième de la métrique. Netflix a adapté ces deux algorithmes pour ses volumes de données et les utilise toujours dans le cadre du système.
Au cours de la deuxième année du concours, les deux équipes ont fusionné et maintenant le prix a été remporté par Bellkor à BigChaos. Ils ont attaqué un total de 207 algorithmes et amélioré la précision d'un centième, atteignant une valeur de 0,8616. La qualité requise n'est toujours pas atteinte, mais il est déjà clair que l'année prochaine tout devrait s'arranger.
Troisième année. La combinaison avec une autre équipe, renommant le pragmatique chaos de Bellkor et obtenant la qualité requise, légèrement inférieure à l'Ensemble. Mais ce n'est que la partie publique de l'ensemble de données.
Du côté caché, il s'est avéré que la précision de ces équipes coïncide avec la quatrième décimale, donc le gagnant a été déterminé par une différence de commits de 20 minutes.
Netflix a payé le million promis aux gagnants, mais n'a jamais
utilisé la solution résultante . La mise en œuvre de l'ensemble s'est révélée trop coûteuse et ne présente pas beaucoup d'avantages - après tout, seuls deux algorithmes fournissent déjà la majeure partie de l'augmentation de la précision. Et le plus important - au moment de la fin du concours en 2009, Netflix avait déjà commencé à s'engager dans son service de streaming en plus de louer un DVD pour deux ans. Ils avaient de nombreuses autres tâches et données qu'ils pouvaient utiliser dans leur système. Cependant, leur service de location de courrier DVD
dessert 2,7 millions d'abonnés satisfaits .
Réseaux de neurones
Dans les systèmes de recommandation modernes, une question fréquente est de savoir comment prendre en compte diverses sources d'informations explicites et implicites. Il existe souvent des données supplémentaires sur l'utilisateur ou l'élément et vous souhaitez les utiliser. Les réseaux de neurones sont un bon moyen de rendre compte de ces informations.
Sur la question de l'utilisation des réseaux pour les recommandations, vous devriez prêter attention à l'examen du
système de recommandation basé sur le
Deep Learning: une enquête et de nouvelles perspectives . Il décrit des exemples d'utilisation d'un grand nombre d'architectures pour diverses tâches.
Il existe de nombreuses architectures et approches. L'un des noms répétés est
DSSM . Je voudrais également mentionner le
filtrage collaboratif attentif .
ACF propose d'introduire deux niveaux d'atténuation:
- Même avec les mêmes notes, certains éléments contribuent davantage à vos préférences que d'autres.
- Les objets ne sont pas atomiques, mais composés de composants. Certains ont un impact plus important sur l'évaluation que d'autres. Le film ne peut être intéressant qu'en raison de la présence d'un acteur préféré.
Les bandits à plusieurs bras sont l'un des sujets les plus populaires de ces derniers temps. Ce qui est des bandits multi-armés peut être lu dans un article sur
Habré ou sur le
Medium .
Lorsqu'elle est appliquée aux recommandations, la tâche Contextual-Bandit ressemblera à ceci: «Nous alimentons les vecteurs de contexte utilisateur et article à l'entrée du système, nous voulons maximiser la probabilité d'interaction (clics, achats) pour tous les utilisateurs au fil du temps, en mettant à jour fréquemment la politique de recommandation.» Cette formulation résout naturellement le problème de l'exploration vs l'exploitation et vous permet de déployer rapidement des stratégies optimales pour tous les utilisateurs.
Dans le sillage de la popularité de l'architecture des transformateurs, il existe également des tentatives pour les utiliser dans les recommandations.
Item suivant Recommandation avec auto-attention tente de combiner les préférences utilisateur à long terme et récentes pour améliorer les recommandations.
Les outils
Les recommandations ne sont pas un sujet aussi populaire que CV ou NLP, donc pour utiliser les dernières architectures de grille, vous devrez soit les implémenter vous-même, soit espérer que l'implémentation de l'auteur est assez pratique et compréhensible. Cependant, certains outils de base sont toujours là:
Conclusion
Les systèmes de recommandation sont allés loin de l'énoncé standard sur le remplissage de la matrice des évaluations, et chaque domaine spécifique aura ses propres nuances. Cela introduit des difficultés, mais ajoute également de l'intérêt. De plus, il peut être difficile de séparer le système de recommandation du produit dans son ensemble. En effet, non seulement la liste des articles est importante, mais aussi la méthode et le contexte de la soumission. Quoi, comment, à qui et quand recommander. Tout cela détermine l'impression d'interaction avec le service.