Bonjour, citoyens Habrovsk!
Le cours de développeur de Golang commence déjà à OTUS aujourd'hui
, et nous considérons que c'est une excellente occasion de partager un autre article utile sur le sujet. Aujourd'hui, parlons de l'approche de Go face aux erreurs. Commençons!

Maîtriser la gestion pragmatique des erreurs dans votre code Go
 Cet article fait partie de la série Avant de commencer, où nous explorons le monde de Golang, partageons des conseils et des idées que vous devez savoir lors de l'écriture de code dans Go afin que vous n'ayez pas à remplir vos propres bosses.
Cet article fait partie de la série Avant de commencer, où nous explorons le monde de Golang, partageons des conseils et des idées que vous devez savoir lors de l'écriture de code dans Go afin que vous n'ayez pas à remplir vos propres bosses.Je suppose que vous avez déjà au moins une expérience de base avec Go, mais si vous sentez qu'à un moment donné vous êtes tombé sur un matériau inconnu en discussion, n'hésitez pas à faire une pause, à explorer le sujet et à revenir.
Maintenant que nous avons frayé notre chemin, allons-y!
L'approche de Go à la gestion des erreurs est l'une des fonctionnalités les plus controversées et les plus mal utilisées. Dans cet article, vous apprendrez l'approche de Go face aux erreurs et comprendrez comment elles fonctionnent «sous le capot». Vous apprendrez quelques approches différentes, examinerez le code source de Go et la bibliothèque standard pour savoir comment les erreurs sont gérées et comment les utiliser. Vous apprendrez pourquoi les assertions de type jouent un rôle important dans leur traitement et vous verrez les modifications à venir au traitement des erreurs que vous prévoyez d'introduire dans Go 2.

Entrée
Tout d'abord: les erreurs dans Go ne font pas exception.
Dave Cheney a écrit un
blog épique à ce sujet, donc je vous y réfère et résume: dans d'autres langues, vous ne pouvez pas être sûr qu'une fonction peut lever ou non une exception. Au lieu de lever des exceptions, les fonctions Go prennent
en charge
plusieurs valeurs de retour , et par convention, cette fonction est généralement utilisée pour renvoyer le résultat d'une fonction avec une variable d'erreur.

Si, pour une raison quelconque, votre fonction échoue, vous devriez probablement en renvoyer le type d'
error précédemment déclaré. Par convention, le retour d'une erreur signale à l'appelant le problème et le retour de zéro n'est pas considéré comme une erreur. Ainsi, vous ferez comprendre à l'appelant qu'un problème est survenu et qu'il doit y faire face: quiconque appelle votre fonction, il sait qu'il ne doit pas se fier au résultat avant de rechercher une erreur. Si l'erreur n'est pas nulle, il est obligé de la vérifier et de la traiter (consigner, retourner, maintenir, appeler une sorte de mécanisme de nouvelle tentative / nettoyage, etc.).
 (3 // gestion des erreurs
(3 // gestion des erreurs
5 // suite)Ces extraits sont très courants dans Go, et certains les considèrent comme du code passe-partout. Le compilateur traite les variables inutilisées comme des erreurs de compilation, donc si vous n'allez pas vérifier les erreurs, vous devez les affecter à
un identifiant vide . Mais aussi pratique que cela puisse être, les erreurs ne doivent pas être ignorées.
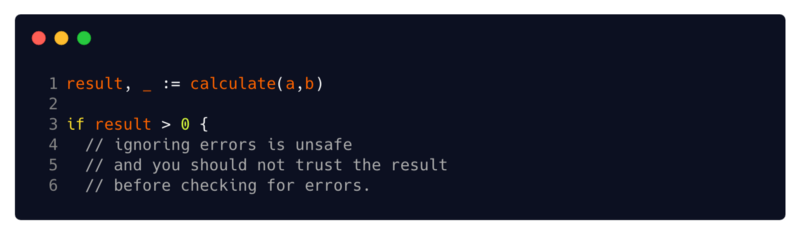 (4 // ignorer les erreurs n'est pas sûr, et vous ne devez pas vous fier au résultat avant de vérifier les erreurs)le résultat ne peut pas être approuvé tant qu'il n'a pas vérifié les erreurs
(4 // ignorer les erreurs n'est pas sûr, et vous ne devez pas vous fier au résultat avant de vérifier les erreurs)le résultat ne peut pas être approuvé tant qu'il n'a pas vérifié les erreursLe retour d'erreur avec les résultats, ainsi que le système de type Go strict, compliquent grandement l'écriture de code balisé. Vous devez toujours supposer que la valeur d'une fonction est corrompue, sauf si vous avez vérifié l'erreur qu'elle a renvoyée, et en affectant l'erreur à un identificateur vide, vous ignorez explicitement que la valeur de votre fonction peut être corrompue.
 L'identifiant vide est sombre et plein d'horreurs.
L'identifiant vide est sombre et plein d'horreurs.Go a
panic mécanismes de
panic et de
recover , qui sont également décrits dans
un autre article détaillé du blog Go . Mais ils ne sont pas destinés à simuler des exceptions. Selon Dave,
"Quand vous paniquez dans Go, vous paniquez vraiment: ce n'est pas le problème de quelqu'un d'autre, c'est déjà un joueur." Ils sont mortels et entraînent un crash dans votre programme. Rob Pike a inventé le dicton «Ne paniquez pas», qui parle de lui-même: vous devriez probablement éviter ces mécanismes et renvoyer des erreurs à la place.
"Les erreurs sont les significations."
"Ne vous contentez pas de vérifier les erreurs, mais gérez-les avec élégance."
"Ne paniquez pas"
toutes les paroles de Rob Pike
Sous le capot
Interface d'erreurSous le capot, le type d'erreur est une
interface simple avec une seule méthode , et si vous ne la connaissez pas, je vous recommande fortement de consulter
ce post sur le blog officiel de Go.
 interface d'erreur de la source
interface d'erreur de la sourceFaire ses propres erreurs n'est pas difficile. Il existe différentes approches des structures utilisateur qui implémentent la méthode de
string Error() . Toute structure qui implémente cette méthode unique est considérée comme une valeur d'erreur valide et peut être renvoyée comme telle.
Examinons quelques-unes de ces approches.
Structure errorString intégrée
L'implémentation la plus courante et la plus répandue de l'interface d'erreur est la structure
errorString . C'est l'implémentation la plus simple à laquelle vous pouvez penser.
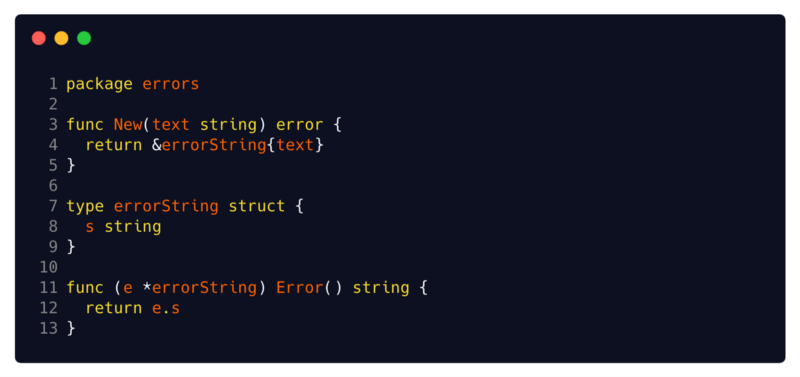
Source:
code source GoVous pouvez voir sa mise en œuvre simplifiée
ici . Il ne contient qu'une
string et cette chaîne est renvoyée par la méthode
Error . Cette erreur de chaîne peut être formatée par nous sur la base de certaines données, par exemple, en utilisant
fmt.Sprintf . Mais à part cela, il ne contient aucune autre fonctionnalité. Si vous avez appliqué des
erreurs.Nouveau ou
fmt.Errorf , alors vous l'avez déjà
utilisé .
 (13 // sortie :)essayer
(13 // sortie :)essayergithub.com/pkg/errors
Un autre exemple simple est le paquetage
pkg / errors . À ne pas confondre avec le package d'
errors intégré que vous avez découvert plus tôt, ce package fournit des fonctionnalités importantes supplémentaires, telles que l'encapsulation d'erreurs, l'expansion, le formatage et l'enregistrement de trace de pile. Vous pouvez installer le package en exécutant
go get github.com/pkg/errors .

Dans les cas où vous devez attacher la trace de pile ou les informations de débogage nécessaires à vos erreurs, l'utilisation des fonctions
New ou
Errorf ce package fournit des erreurs qui sont déjà écrites dans votre trace de pile, et vous pouvez également attacher des métadonnées simples en l'utilisant capacités de formatage.
Errorf implémente l'interface
fmt.Formatter , c'est-à-dire que vous pouvez la formater en utilisant les runes du package
fmt (
%s ,
%v ,
%+v , etc.).
 (// 6 ou alternative)
(// 6 ou alternative)Ce package présente également les fonctions
errors.Wrap et
errors.Wrapf . Ces fonctions ajoutent du contexte à l'erreur à l'aide d'un message et d'une trace de pile à l'endroit où elles ont été appelées. Ainsi, au lieu de simplement renvoyer l'erreur, vous pouvez l'envelopper avec du contexte et des données de débogage importantes.
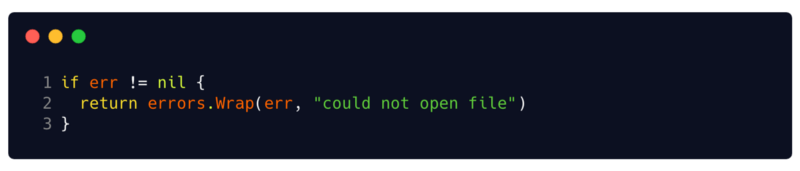
Les wrappers d'erreur par d'autres erreurs prennent en charge la méthode d'
Cause() error , qui renvoie leur erreur interne. En outre, ils peuvent être utilisés avec des
errors.Cause(err error) error fonction d'
errors.Cause(err error) error , qui extrait la principale erreur interne dans l'erreur d'enrubannage.
Gestion des erreurs
Homologation de type
Les assertions de
type jouent un rôle important dans le traitement des erreurs. Vous les utiliserez pour extraire des informations de la valeur d'interface, et comme la gestion des erreurs est associée aux implémentations utilisateur de l'interface d'
error , l'implémentation des instructions d'
error est un outil très pratique.
Sa syntaxe est la même pour toutes ses applications -
x.(T) si
x a un type d'interface.
x.(T) indique que
x pas
nil et que la valeur stockée dans
x est de type
T Dans les sections suivantes, nous examinerons deux façons d'utiliser les instructions de type - avec un type spécifique
T et avec une interface de type
T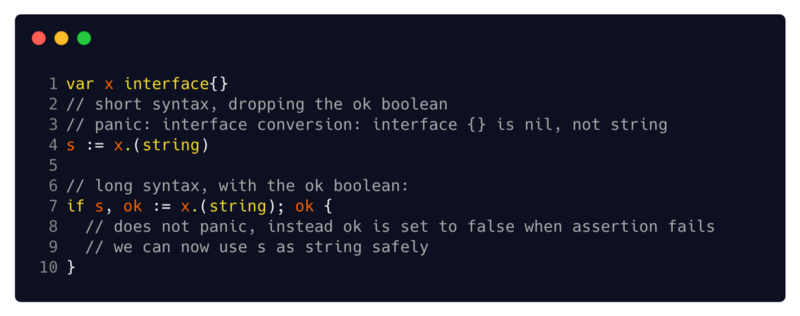 (2 // syntaxe abrégée en sautant la variable booléenne ok
(2 // syntaxe abrégée en sautant la variable booléenne ok
3 // panique: conversion d'interface: l'interface {} est nulle, pas une chaîne
6 // syntaxe étendue avec booléen ok
8 // ne panique pas, définit à la place ok false lorsque l'instruction est fausse
9 // maintenant nous pouvons utiliser s comme chaîne en toute sécurité)sandbox: panique avec une syntaxe raccourcie, syntaxe étendue sûreRemarque supplémentaire sur la syntaxe: une assertion de type peut être utilisée avec une syntaxe raccourcie (qui panique lorsqu'une instruction échoue) ou une syntaxe étendue (qui utilise la valeur logique OK pour indiquer le succès ou l'échec). Je recommande toujours de prendre allongé au lieu de raccourci, car je préfère vérifier la variable OK et ne pas gérer la panique.
Homologation de type T
Une instruction de type
x.(T) avec une interface de type
T confirme que
x implémente l'interface de
T Ainsi, vous pouvez garantir que la valeur d'interface implémente l'interface, et seulement si c'est le cas, vous pouvez utiliser ses méthodes.
 (5 ... // affirme que x implémente l'interface du résolveur
(5 ... // affirme que x implémente l'interface du résolveur
6 ... // ici, nous pouvons déjà utiliser cette méthode en toute sécurité)Pour comprendre comment cela peut être utilisé, examinons à nouveau
pkg/errors . Vous connaissez déjà ce paquet d'erreurs, alors
errors.Cause(err error) error la
errors.Cause(err error) error .
Cette fonction reçoit une erreur et extrait l'erreur la plus profonde dont elle souffre (celle qui ne sert plus de wrapper pour une autre erreur). Cela peut sembler primitif, mais il y a beaucoup de grandes choses que vous pouvez apprendre de cette implémentation:

source:
pkg / erreursLa fonction reçoit la valeur d'erreur et ne peut pas supposer que l'argument
err qu'elle reçoit est une erreur d'encapsuleur (prise en charge par la méthode
Cause ). Par conséquent, avant d'appeler la méthode
Cause , vous devez vous assurer que vous avez affaire à une erreur qui implémente cette méthode. En effectuant une instruction de type à chaque itération de la boucle for, vous pouvez vous assurer que la variable
cause prend en charge la méthode
Cause et pouvez en extraire des erreurs internes jusqu'à ce que vous trouviez une erreur qui n'a pas
Cause .
En créant une interface locale simple contenant uniquement les méthodes dont vous avez besoin et en y appliquant une assertion, votre code est séparé des autres dépendances. L'argument que vous avez reçu ne doit pas nécessairement être une structure connue, il doit simplement s'agir d'une erreur. Tout type qui implémente les méthodes
Error et
Cause fera l'affaire. Ainsi, si vous implémentez la méthode
Cause dans votre type d'erreur, vous pouvez utiliser cette fonction avec elle sans ralentissements.
Cependant, il y a un petit défaut à garder à l'esprit: les interfaces sont sujettes à changement, vous devez donc maintenir soigneusement le code afin que vos déclarations ne soient pas violées. N'oubliez pas de définir vos interfaces là où vous les utilisez, de les garder fines et soignées, et tout ira bien.
Enfin, si vous n'avez besoin que d'une seule méthode, il est parfois plus pratique de faire une déclaration sur une interface anonyme contenant uniquement la méthode sur laquelle vous comptez, c'est-à-dire
v, ok := x.(interface{ F() (int, error) }) . L'utilisation d'interfaces anonymes peut vous aider à séparer votre code des dépendances possibles et à le protéger contre d'éventuelles modifications des interfaces.
Approbation de type T et de commutateur de type
Je préfère cette section en introduisant deux modèles de gestion des erreurs similaires qui souffrent de plusieurs défauts et pièges. Cela ne signifie pas qu'ils ne sont pas courants. Les deux peuvent être des outils pratiques dans les petits projets, mais ils ne s'adaptent pas bien.
La première est la deuxième version de l'assertion de type: une assertion de type
x.(T) avec un type
T spécifique est effectuée. Il prétend que la valeur de
x est de type
T , ou peut être convertie en type
T (2 // nous pouvons utiliser v comme mypkg.SomeErrorType)
(2 // nous pouvons utiliser v comme mypkg.SomeErrorType)Un autre est le
modèle de commutateur de type. Type Switch combine une instruction switch avec une instruction type à l'aide du mot-clé
type réservé. Ils sont particulièrement courants dans la gestion des erreurs, où la connaissance du type de base d'une erreur variable peut être très utile.
 (3 // traitement ...
(3 // traitement ...
5 // traitement ...)Le gros inconvénient des deux approches est qu'elles conduisent toutes deux à une liaison de code avec leurs dépendances. Les deux exemples doivent être familiers avec la structure
SomeErrorType (qui doit évidemment être exportée) et doivent importer le package
mypkg .
Dans les deux approches, lors de la gestion de vos erreurs, vous devez connaître le type et importer son package. La situation est aggravée lorsque vous traitez des erreurs dans les wrappers, où la cause de l'erreur peut être une erreur résultant d'une dépendance interne que vous ne connaissez pas et que vous ne devriez pas connaître.
 (7 // traitement ...
(7 // traitement ...
9 // traitement ...)Type Switch fait la distinction entre
*MyStruct et
MyStruct . Par conséquent, si vous n'êtes pas sûr d'avoir affaire à un pointeur ou à une instance réelle d'une structure, vous devrez fournir les deux options. De plus, comme dans le cas des commutateurs normaux, les cas dans Type Switch n'échouent pas, mais contrairement au Commutateur de type habituel, l'utilisation de la
fallthrough interdite dans Type Switch, vous devez donc utiliser une virgule et fournir les deux options, ce qui est facile à oublier.

Pour résumer
C'est tout! Vous connaissez maintenant les erreurs et devez être prêt à corriger toutes les erreurs que votre application Go peut renvoyer (ou réellement retourner) sur votre chemin!
Les deux packages d'
errors fournissent des approches simples mais importantes aux erreurs dans Go, et s'ils répondent à vos besoins, ils sont un excellent choix. Vous pouvez facilement implémenter vos propres structures d'erreur et profiter de la gestion des erreurs Go en les combinant avec
pkg/errors .
Lorsque vous mettez à l'échelle des erreurs simples, l'utilisation correcte des instructions de type peut être un excellent outil pour gérer diverses erreurs. Soit en utilisant Type Switch, soit en validant le comportement de l'erreur et en vérifiant les interfaces qu'il implémente.
Et ensuite?
La gestion des erreurs dans Go est désormais très pertinente. Maintenant que vous avez les bases, vous vous demandez peut-être ce qui nous attend pour gérer les erreurs Go!
La prochaine version de Go 2 y prête beaucoup d'attention, et vous pouvez déjà jeter un œil à la
version provisoire . De plus, au cours de
dotGo 2019, Marcel van Lojuizen a eu une excellente conversation sur un sujet que je ne peux que recommander -
«GO 2 error values today» .
De toute évidence, il existe de nombreuses autres approches, trucs et astuces, et je ne peux pas les inclure tous dans un seul article! Malgré cela, j'espère que cela vous a plu et je vous verrai dans le prochain épisode
de Avant de commencer !
Et maintenant, traditionnellement, attend vos commentaires.