Bonjour encore! Nous partageons une publication, dont la traduction a été préparée spécialement pour les étudiants du cours
"Réseaux de neurones en Python" .

Aujourd'hui, nous parlerons du premier événement important dans l'histoire du développement de DeepMind, pour montrer comment la recherche utilisant l'intelligence artificielle peut stimuler l'émergence de découvertes scientifiques. En raison de la nature interdisciplinaire de notre travail, DeepMind a réuni des experts des domaines de la biologie structurale, de la physique et de l'apprentissage automatique pour utiliser des méthodes avancées pour prédire la structure tridimensionnelle d'une protéine basée uniquement sur sa séquence génétique.
Le système AlphaFold sur lequel nous avons travaillé au cours des deux dernières années est basé sur de nombreuses années d'expérience en recherche utilisant des données génomiques étendues pour prédire la structure des protéines. Les modèles protéiques tridimensionnels générés par AlphaFold sont beaucoup plus précis que ceux obtenus précédemment. Cela a marqué des progrès significatifs dans l'une des principales tâches de la biologie.
Quel est le problème du repliement des protéines?
Les protéines sont des molécules grandes et complexes nécessaires à la vie. Presque toutes les fonctions de notre corps, que ce soit la contraction musculaire, la perception de la lumière ou la conversion des aliments en énergie, peuvent être attribuées à une ou plusieurs protéines et comment elles se déplacent et changent. Les recettes de ces protéines, appelées gènes, sont codées dans notre ADN.
Les propriétés d'une protéine dépendent de sa structure tridimensionnelle unique. Par exemple, les protéines d'anticorps qui composent notre système immunitaire sont en forme de «Y» et ressemblent à des crochets spéciaux. S'accrochant aux virus et aux bactéries, les protéines d'anticorps sont capables de détecter et d'étiqueter les agents pathogènes pour une destruction ultérieure. De même, les protéines de collagène se présentent sous la forme de cordes qui transmettent la tension entre le cartilage, les ligaments, les os et la peau. D'autres types de protéines incluent Cas9, qui, guidé par les séquences CRISPR, agit comme des ciseaux qui coupent l'ADN et insèrent de nouveaux sites. Protéines antigel, dont la structure tridimensionnelle leur permet de se lier aux cristaux de glace et d'empêcher le gel des organismes; et les ribosomes, qui agissent comme un convoyeur programmé impliqué dans la construction des protéines.
Déterminer la structure tridimensionnelle d'une protéine uniquement à partir de sa séquence génétique est une tâche difficile avec laquelle les scientifiques se battent depuis des décennies. Le problème est que l'ADN ne contient que des informations sur la séquence des blocs de construction d'une protéine appelée résidus d'acides aminés qui forment de longues chaînes. Prédire comment ces chaînes formeront une structure protéique 3D complexe est connu comme le «problème de repliement des protéines».
Plus la protéine est grosse, plus elle est difficile à modéliser, car plus de liaisons se forment entre les acides aminés qui doivent être pris en compte. Comme il résulte du
paradoxe de Levintal , pour répertorier toutes les configurations possibles d'une protéine ordinaire, avant que sa structure tridimensionnelle correcte soit atteinte, cela prendra plus de temps que l'Univers n'existe.

Pourquoi le repliement des protéines est-il important?
La capacité de prédire la forme de la protéine est extrêmement utile car elle est fondamentale pour comprendre le rôle de la protéine dans le corps, ainsi que le diagnostic et le traitement de maladies telles que la maladie d'Alzheimer, la
maladie de Parkinson , la
maladie de Huntington et
la fibrose kystique , qui, selon les médecins, sont causées par des protéines mal repliées.
Nous sommes particulièrement heureux que la capacité de prédire la forme d'une protéine puisse améliorer la compréhension du fonctionnement de notre corps, ce qui nous permettra de développer efficacement de nouveaux médicaments. Au fur et à mesure que nous obtenons plus d'informations sur les formes de protéines et leur fonctionnement grâce à la modélisation, de nouvelles opportunités de création de médicaments s'ouvrent, ainsi que la baisse du coût des expériences. À terme, ces découvertes amélioreront la qualité de vie de millions de patients dans le monde.
Comprendre le processus de repliement des protéines peut également aider à développer un type de protéines qui apportera une contribution significative à la réalité environnante. Par exemple, les progrès réalisés grâce au développement de protéines dans des enzymes biodégradables peuvent aider à faire face aux contaminants tels que le plastique et l'huile, aidant à décomposer les déchets sans endommager l'environnement. En fait, les chercheurs ont déjà commencé à
concevoir des bactéries qui sécrètent des protéines qui rendent les déchets biodégradables et facilitent leur manipulation.
Afin de stimuler la recherche et d'évaluer les progrès dans le domaine des méthodes les plus récentes pour améliorer la précision des prévisions, un concours à grande échelle de deux ans a été
lancé en 1994 appelé
Expérience communautaire sur l'évaluation critique des méthodes de prévision de la structure des protéines (CASP), qui est devenu la référence en matière de méthodes d'évaluation.
Comment l'IA fera-t-elle la différence?
Au cours des cinq dernières décennies, les scientifiques ont pu reconnaître les formes de protéines en laboratoire en utilisant des méthodes expérimentales telles que
la microscopie cryoélectronique ,
la résonance magnétique nucléaire ou la
diffraction des rayons X , mais chaque méthode a été déduite par de nombreux essais et erreurs qui ont pris des années et coûté des dizaines de milliers de dollars. C'est pourquoi les biologistes se tournent maintenant vers les méthodes de l'IA comme alternative au long et laborieux processus de recherche de protéines complexes.
Heureusement, le domaine de la génomique dispose de suffisamment de données en raison de la réduction rapide du coût du séquençage génétique. En conséquence, au cours des dernières années, les
approches du problème de la prévision utilisant l'apprentissage en profondeur et basées sur les données du génome sont devenues de plus en plus populaires. Le travail de DeepMind sur cette question a conduit à l'apparition d'AlphaFold, que nous avons présenté à CASP cette année. Nous sommes fiers de faire partie des progrès que les experts de l'ACPS ont qualifiés de «progrès sans précédent dans la capacité des méthodes de calcul à prédire la structure d'une protéine». En conséquence, nous avons
pris la première place dans le classement des équipes (nous sommes A7D).
Notre équipe s'est concentrée précisément sur la tâche de modélisation de formes cibles à partir de zéro, sans utiliser de protéines préalablement résolues comme modèles. Nous avons atteint un haut degré de précision dans la prédiction des propriétés physiques de la structure protéique, puis avons utilisé deux méthodes différentes pour prédire les structures protéiques complètes.
Utilisation de réseaux de neurones pour prédire les propriétés physiques
Ces deux méthodes ont utilisé des réseaux de neurones profonds qui sont entraînés à prédire les propriétés d'une protéine par sa séquence génétique. Les propriétés que le réseau prédit sont: (a) la distance entre les paires d'acides aminés et (b) les angles entre les liaisons chimiques qui relient ces acides aminés. Le premier développement a été une réelle avancée dans l'utilisation des méthodes populaires qui déterminent si les paires d'acides aminés sont côte à côte.
Nous avons formé le réseau neuronal pour prédire une distribution distincte des distances entre chaque paire de résidus protéiques. Ces probabilités ont ensuite été combinées en une estimation qui montre à quel point la structure protéique est bien conçue. Nous avons également formé un autre réseau de neurones qui utilise toutes les distances au total pour évaluer la proximité de la structure proposée avec la bonne réponse.

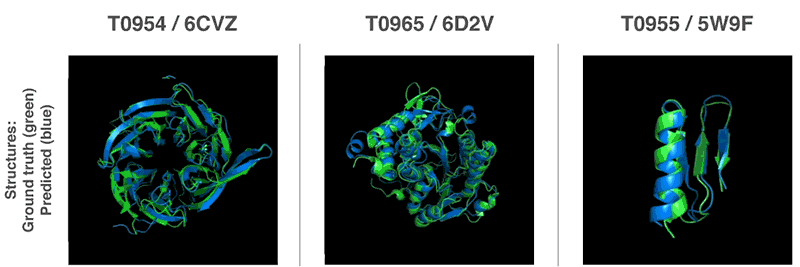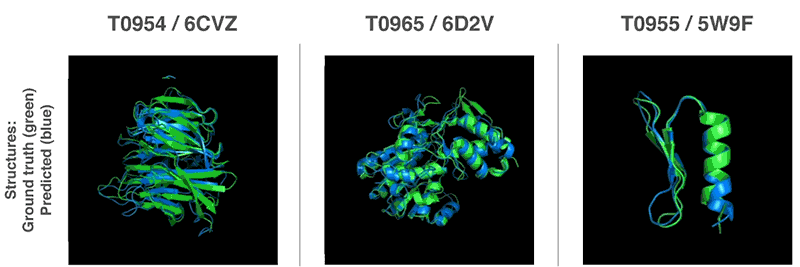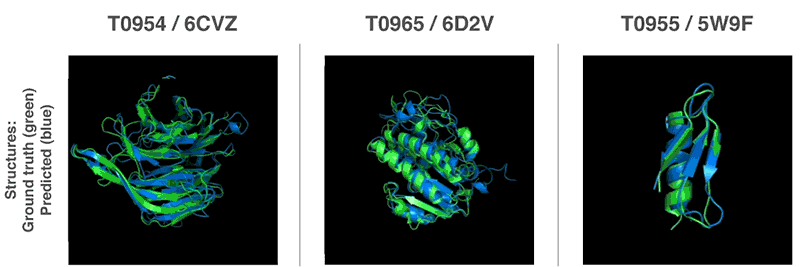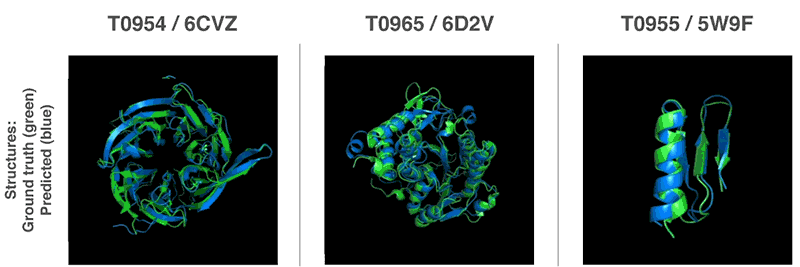
De nouvelles méthodes pour prédire les structures protéiques
Grâce à ces fonctions de valorisation, nous avons pu trouver des structures qui correspondent à nos prévisions. Notre première méthode est basée sur des méthodes largement utilisées en biologie structurale; elle a remplacé à plusieurs reprises des parties de la structure protéique par de nouveaux fragments. Nous avons formé le réseau neuronal compétitif génératif à proposer de nouveaux fragments qui sont utilisés pour améliorer en continu l'évaluation de la structure protéique proposée.

La deuxième méthode a optimisé les notes en utilisant la descente de gradient (une méthode mathématique couramment utilisée dans l'apprentissage automatique pour de petites améliorations incrémentales), ce qui a conduit à une grande précision des structures. Cette méthode a été appliquée à des chaînes de protéines entières, et non à des morceaux qui doivent être empilés séparément avant l'assemblage, ce qui réduit la complexité du processus de prédiction.
Et ensuite?
Le succès de notre test de stylo de coagulation des protéines montre que les systèmes d'apprentissage automatique peuvent intégrer plusieurs sources d'information pour aider les scientifiques à développer rapidement des solutions créatives à des problèmes complexes. Nous avons déjà vu comment l'IA aide les gens à maîtriser des jeux complexes grâce à des systèmes tels que
AlphaGo et
AlphaZero , nous espérons également qu'une fois que la percée de l'IA aidera l'humanité à résoudre des problèmes scientifiques fondamentaux.
Il est intéressant de voir les premiers progrès dans le repliement des protéines, démontrant l'utilité de l'IA pour faire des découvertes scientifiques. Même si nous avons encore beaucoup à faire, nous comprenons clairement que nous pourrons contribuer à la recherche de traitements pour diverses maladies, aider l'environnement et bien plus encore, car en fait le potentiel est énorme. Avec une équipe dédiée concentrée sur l'exploration de la façon dont l'apprentissage automatique peut faire avancer le monde de la science, nous explorerons les différentes manières et méthodes par lesquelles notre technologie peut influencer le monde qui nous entoure.