Nous comparons les caractéristiques des microservices et de l'architecture monolithique, leurs avantages et leurs inconvénients. L'article a été préparé pour Habr sur la base des documents de notre méta
Hot Backend , qui s'est tenu à Samara le 9 février 2019. Nous considérons les facteurs du choix de l'architecture en fonction de la tâche spécifique.
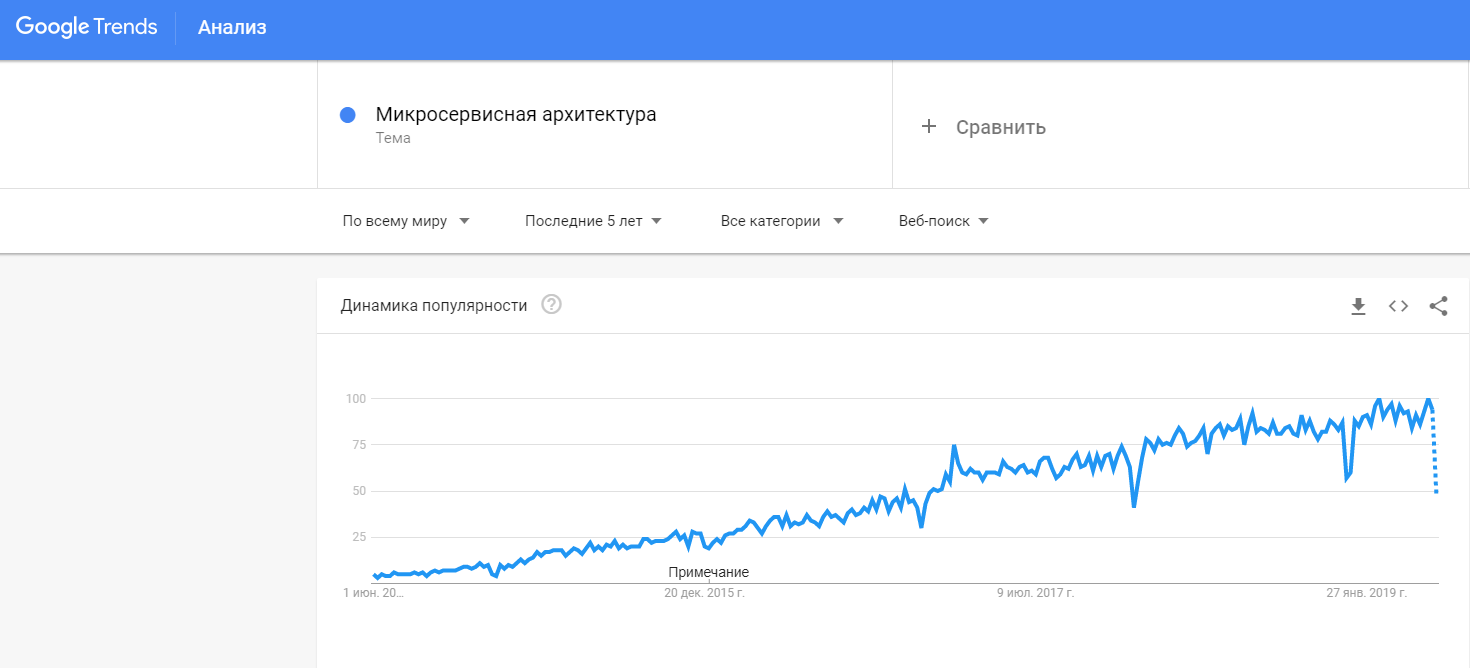
Il y a encore 5 ans, personne n'avait entendu parler des microservices. Cependant, leur popularité augmente d'année en année, selon les
statistiques de Google Trends.
Monolith et microservices: exemples
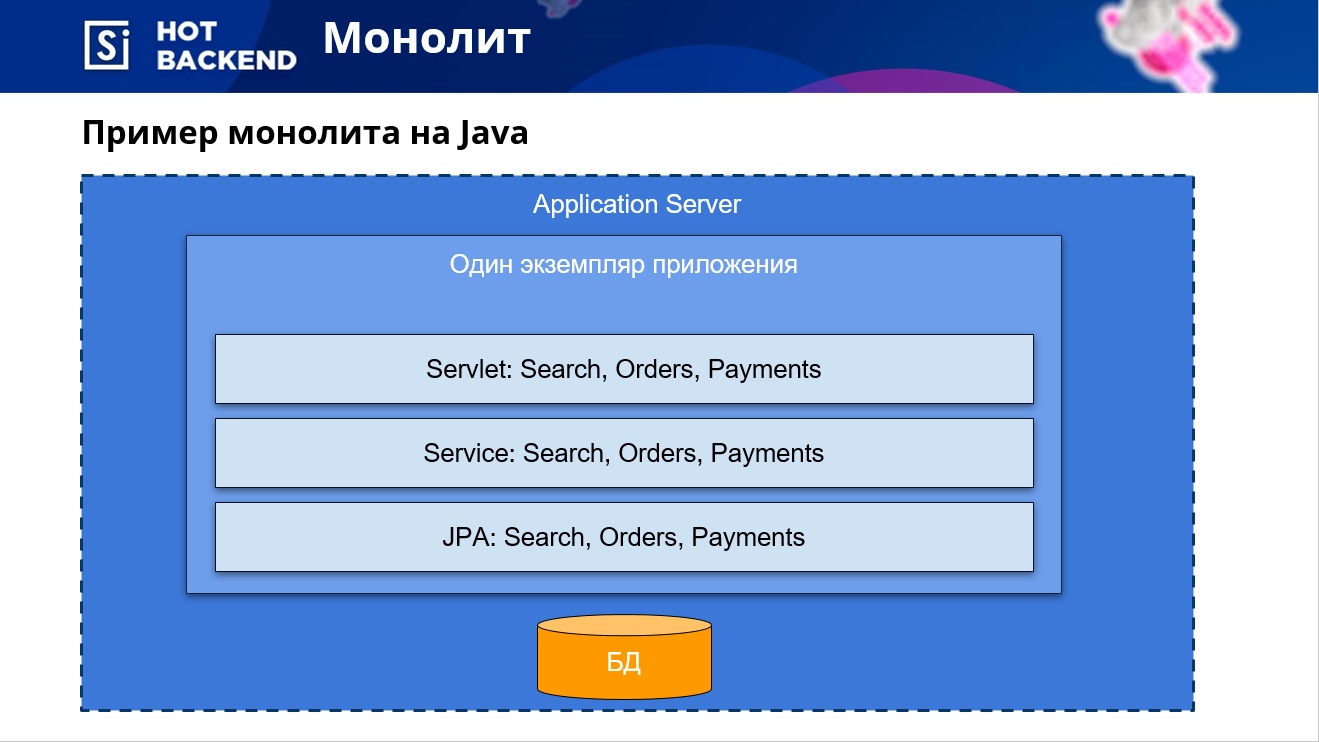
Si le projet utilise une architecture monolithique, le développeur n'a qu'une seule application, dont tous les composants et modules fonctionnent avec une seule base.
L'architecture de microservice implique la décomposition en modules qui s'exécutent en tant que processus distincts et peuvent avoir des serveurs distincts. Chaque microservice fonctionne avec sa propre base de données et tous ces services peuvent communiquer entre eux de manière synchrone (http) et asynchrone. De plus, pour optimiser l'architecture, il est souhaitable de minimiser la relation entre les services.
Le schéma ci-dessous est simplifié, il reflète tout d'abord les composantes métiers.

Microservices: avantages
L'architecture de microservices présente au moins quatre avantages:
Mise à l'échelle et déploiement indépendantsUn déploiement indépendant est fourni pour chaque microservice, ce qui est pratique lors de la mise à jour de modules individuels. Si la charge sur le module augmente, le microservice correspondant peut être mis à l'échelle sans affecter les autres. Cela vous permet de répartir la charge de manière flexible et d'économiser des ressources.
Développement indépendantChaque microservice (par exemple, un module de mémoire) peut être développé par une équipe pour augmenter la vitesse de création d'un produit logiciel.
DurabilitéLa défaillance d'un microservice n'affecte pas les performances des autres modules.
HétérogénéitéChaque équipe est libre de choisir son propre langage et sa propre technologie pour la mise en œuvre des microservices, cependant, il est souhaitable qu’elles disposent d’interfaces compatibles.
Parmi les développeurs, vous pouvez entendre l'opinion selon laquelle l'architecture monolithique est obsolète, elle est difficile à maintenir et à mettre à l'échelle, elle se développe rapidement dans un «gros morceau de saleté» et est pratiquement sans motif, c'est-à-dire que sa présence dans le code n'est pas souhaitable. Les grandes entreprises, telles que Netflix, qui sont passées à l'architecture de microservices dans leurs projets, sont souvent citées comme preuve de cette opinion.
Voyons si tout le monde devrait vraiment passer d'un monolithe à des microservices à l'instar des plus grandes marques?
Passage aux microservices: difficultés possibles
Problème un: décompositionIdéalement, l'application doit être divisée en microservices afin qu'ils interagissent le moins possible les uns avec les autres, sinon l'application sera difficile à maintenir. Dans le même temps, la décomposition est difficile à mettre en œuvre au début du développement, lorsque les problèmes commerciaux et le domaine peuvent encore changer avec l'avènement de nouvelles exigences. Le refactoring coûte cher.
S'il devient nécessaire de transférer une partie des fonctions du service A vers le service B, alors des difficultés sont possibles ici: par exemple, les services sont exécutés dans différentes langues, les appels internes aux services deviennent réseau, d'autres bibliothèques doivent être connectées. Nous ne pouvons vérifier l'exactitude de la refactorisation qu'à l'aide de tests.
 Deuxième problème: les transactions
Deuxième problème: les transactionsUn autre problème est que les microservices n'ont pas le concept de transactions distribuées. Nous ne pouvons garantir l'intégrité architecturale d'une opération commerciale que dans un seul microservice. Si l'opération implique plusieurs microservices, différentes bases de données peuvent y être utilisées, et une telle transaction devra être abandonnée. Pour résoudre ce problème, il existe différentes méthodes utilisées en entreprise lorsque l'accessibilité est plus importante que l'intégrité. Dans le même temps, des mécanismes de compensation sont prévus en cas de problème. Par exemple, si les marchandises ne sont pas en stock, vous devez effectuer un remboursement sur le compte de l'acheteur.
Si un monolithe nous donne automatiquement l'intégrité architecturale, alors avec les microservices, vous devez créer votre propre mécanisme et utiliser des bibliothèques avec des solutions prêtes à l'emploi. Lors de la distribution d'une opération entre les services, il est préférable de demander des données de manière synchrone et d'effectuer les actions suivantes de manière asynchrone. S'il est impossible d'accéder à l'un des services, l'équipe sera mise en file d'attente dès qu'elle sera de nouveau disponible.
À cet égard, il est nécessaire de réviser l'approche de l'interface utilisateur. L'utilisateur doit être informé que certaines actions ne sont pas effectuées immédiatement, mais dans un certain délai. Lorsque la demande est traitée, il reçoit une invitation à voir les résultats.
 Troisième problème: rapports
Troisième problème: rapportsSi nous utilisons une architecture monolithique avec une seule base de données, pour créer un rapport complexe, vous pouvez écrire sélectionner et tirer plusieurs étiquettes de données: tôt ou tard, elles seront affichées. Cependant, sur les microservices, ces données peuvent être dispersées sur différentes bases.
Par exemple, nous devons répertorier les entreprises avec des mesures spécifiques. Avec une simple liste d'entreprises, tout fonctionne. Et si vous devez ajouter des mesures qui se trouvent dans une autre base de données? Oui, nous pouvons faire une demande supplémentaire et demander des mesures par TIN. Et si cette liste doit être filtrée et triée? La liste des entreprises peut être très longue, puis nous devons introduire un service supplémentaire avec sa propre base de données - des rapports.
 Quatrième problème: Complexité de développement élevée
Quatrième problème: Complexité de développement élevéeLe travail sur les services distribués est plus compliqué: toutes les demandes sont faites sur le réseau et peuvent être désactivées, vous devez fournir un mécanisme de rappel (refera-t-il l'appel? Combien de fois?). Ce sont les «briques» qui s'accumulent progressivement et contribuent à augmenter la complexité du projet.
Les services peuvent être développés par plusieurs équipes différentes, et vous devez les documenter, maintenir la documentation à jour, avertir les autres équipes lors du changement de version. Ce sont des coûts de main-d'œuvre supplémentaires.
Si chaque équipe a un déploiement indépendant, vous devez conserver au moins la version précédente et la désactiver uniquement après que tous les consommateurs du service sont passés à la nouvelle API.
Bien sûr, nous pouvons intégrer toutes les API dans une sorte d'artefact qui sera accessible au public. Mais, premièrement, les services peuvent être écrits dans différentes langues, et deuxièmement, ce n'est pas recommandé. Par exemple, dans l'un de nos projets, nous l'avons refusé à la demande du client, pour des raisons de sécurité. Chaque microservice possède un référentiel distinct et le client ne leur donne pas accès.
Dans le processus de développement, tout peut fonctionner correctement, puis - non. Il arrive qu'en cas d'exceptions, l'application essaie à l'infini de les traiter, et cela donne une grosse charge - tout le système "se couche". Pour éviter de telles situations, vous devez tout configurer, par exemple pour limiter le nombre de tentatives, pour ne pas renvoyer cet appel à la file d'attente dans la même seconde, etc.

 Le cinquième problème: la complexité des tests, du traçage et du débogage
Le cinquième problème: la complexité des tests, du traçage et du débogagePour tester un problème, vous devez télécharger tous les microservices concernés. Le débogage devient une tâche non triviale et tous les journaux doivent être collectés quelque part en un seul endroit. Dans ce cas, vous avez besoin d'autant de journaux que possible pour comprendre ce qui s'est passé. Pour suivre le problème, vous devez comprendre tout le chemin parcouru par le message. Les tests unitaires ne suffisent pas ici, car des erreurs sont probables à la jonction des services. Lors des modifications, il est possible de vérifier l'opérabilité uniquement après avoir exécuté sur le support. Nous pouvons limiter chaque microservice à une certaine quantité de mémoire (par exemple, 500 mégaoctets), mais il y a des périodes de charge maximale quand cela prend jusqu'à deux gigaoctets. Il y a des moments où le système commence à ralentir. Par conséquent, les ressources peuvent être dépensées pour quelque chose qui n'appartient pas aux tâches immédiates du client: par exemple, il n'y a que deux microservices d'entreprise et la moitié des ressources sont dépensées pour trois microservices supplémentaires qui soutiennent le travail des autres.

Microservice ou monolithe: critères de sélection
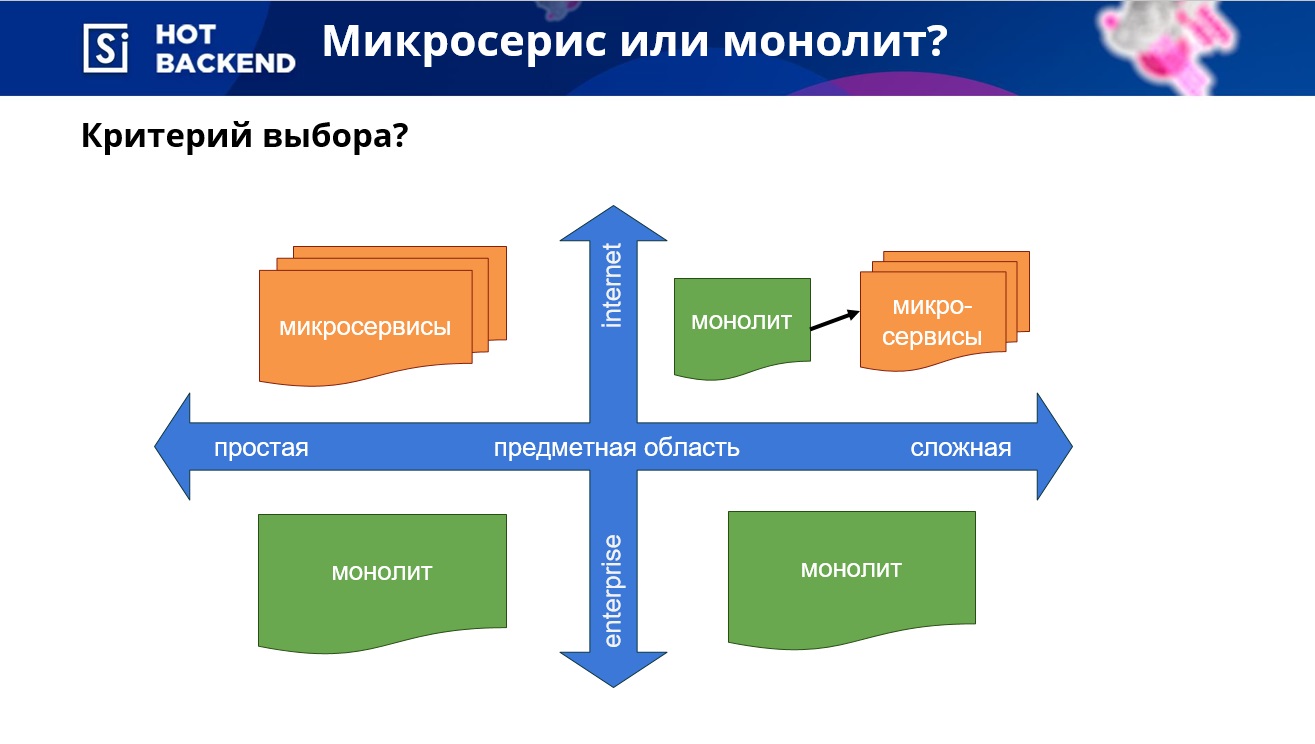
Lors du choix entre une architecture monolithique et microservice, vous devez tout d'abord partir de la complexité du domaine et du besoin de mise à l'échelle.
Si le sujet est simple, et qu'une augmentation globale du nombre d'utilisateurs n'est pas attendue, alors les microservices peuvent être utilisés sans aucun doute. Dans d'autres cas, il est préférable de démarrer le développement sur un monolithe et d'économiser des ressources si la mise à l'échelle n'est pas requise. Si le domaine est complexe, et au stade initial les exigences finales ne sont pas définies, il est également préférable de commencer par un monolithe - afin de ne pas refaire plusieurs fois les microservices. Avec le développement ultérieur du projet, il est possible de distinguer ses différentes parties dans des microservices.
Un plus est la présence de limites au début du projet, car cela aidera à ne pas les briser pendant le processus de développement. Il est également judicieux de commencer avec une seule base de données, mais de définir un schéma pour chaque module (par exemple, un schéma de paiement). Par la suite, cela contribuera à simplifier la division des modules en microservices. Dans ce cas, nous observons les limites des modules et pouvons utiliser des microservices.
Chaque module doit avoir sa propre API, afin que plus tard il puisse être alloué et faire du module un microservice.

Après avoir déterminé les limites des modules, vous pouvez procéder à la décomposition en microservices, si nécessaire. Dans environ 90% des cas, il sera possible de rester sur le monolithe, mais si nécessaire, il sera plus facile et moins coûteux de changer l'architecture.
Dans notre pratique de travail avec des monolithes et des microservices, nous sommes parvenus aux conclusions suivantes:
- Ne passez pas aux microservices simplement parce qu'ils sont utilisés par Netflix, Twitter, Facebook
- Commencez avec deux ou trois microservices qui interagissent les uns avec les autres, déterminez en détail toutes les exigences non fonctionnelles (sécurité, tolérance aux pannes, évolutivité, etc.) et passez ensuite à d'autres services
- Automatisez tout ce qui est possible
- Configurer la surveillance
- Écrire des autotests
- N'utilisez pas de transactions distribuées (mais ce n'est pas une raison pour refuser la garantie de l'intégrité des données).
- Si vous souhaitez utiliser une architecture de microservice, préparez-vous au fait que le développement peut vous coûter environ 3 fois plus cher que sur un monolithe. Cependant, les deux technologies ont leurs propres inconvénients et avantages; chacune a sa propre niche.