Chaque année, une conférence
Dialog se tient à Moscou, à laquelle participent des linguistes et des spécialistes de l'analyse des données. Ils discutent de ce qu'est le langage naturel, comment apprendre à une machine à le comprendre et à le traiter. La conférence a traditionnellement organisé des compétitions (pistes)
Dialogue Evaluation . Ils peuvent être suivis par des représentants de grandes entreprises qui créent des solutions dans le domaine du traitement du langage naturel (Natural Language Processing, NLP), ainsi que des chercheurs individuels. Il peut sembler que si vous êtes un simple étudiant, êtes-vous en concurrence avec les systèmes que les grands spécialistes des grandes entreprises créent depuis des années. Évaluation du dialogue - c'est exactement le cas lorsque, au classement final, un simple étudiant peut être supérieur à une entreprise célèbre.
Cette année sera la 9e consécutive lorsque l'évaluation du dialogue aura lieu au Dialogue. Chaque année, le nombre de compétitions est différent. Les tâches PNL telles que l'analyse des sentiments, l'induction du sens des mots, la correction orthographique automatique, la reconnaissance des entités nommées et d'autres sont déjà devenues des sujets pour les pistes.

Cette année, quatre groupes d'organisateurs ont préparé de tels morceaux:
- Génération de titres pour des articles de presse.
- Résolution de l'anaphore et de la coréférence.
- Analyse morphologique sur le matériel des langages à faibles ressources.
- Analyse automatique de l'un des types de points de suspension (espace).
Aujourd'hui, nous parlerons de la dernière d'entre elles: qu'est-ce qu'une ellipse et pourquoi enseigner à la voiture comment la restaurer dans le texte, comment nous avons créé un nouveau bâtiment sur lequel résoudre ce problème, comment les compétitions se sont déroulées et quels résultats les participants ont pu atteindre.
AGRR-2019 (résolution d'espacement automatique pour le russe)
À l'automne 2018, nous avons été confrontés à une tâche de recherche liée à une ellipse - une omission intentionnelle d'une chaîne de mots dans un texte qui peut être restaurée à partir du contexte. Comment trouver automatiquement un tel espace dans le texte et le remplir correctement? C'est facile pour un locuteur natif, mais enseigner cette voiture n'est pas facile. Assez rapidement, il est devenu clair que c'était un bon matériel pour la compétition, et nous nous sommes mis au travail.
L'organisation de concours sur un nouveau sujet a ses propres caractéristiques, et elles nous semblent être en grande partie des atouts. L'une des principales choses est la création du corpus (de nombreux textes avec balisage sur lesquels vous pouvez apprendre). À quoi devrait-il ressembler et combien devrait-il être? Pour de nombreuses tâches, il existe des normes de présentation des données sur lesquelles s'appuyer. Par exemple, pour la
tâche d'identification des entités nommées , des schémas de balisage IO / BIO / IOBES ont été développés, pour les tâches d'analyse syntaxique et morphologique, le format CONLL est traditionnellement utilisé, rien n'a besoin d'être inventé, mais les directives doivent être strictement suivies.
Dans notre cas, c'était à nous de rassembler les corps et de formuler la tâche.
Voici une telle tâche ...
Ici, nous devrons inévitablement faire une introduction linguistique populaire sur ce que les points de suspension sont en général et en écartant comme l'un de ses types.
Quelles que soient vos idées sur la langue, il est difficile d'affirmer que le niveau d'expression en surface (texte ou discours) n'est pas le seul. Cette phrase n'est que la pointe de l'iceberg. L'iceberg lui-même comprend une évaluation pragmatique, la construction d'une structure syntaxique, la sélection de matériel lexical, etc. L'ellipse est un phénomène qui relie magnifiquement le niveau de la surface avec la profondeur. Il s'agit de l'omission d'éléments de syntaxe en double. Si nous présentons la structure syntaxique d'une phrase sous la forme d'un arbre et que les mêmes sous-arbres peuvent être sélectionnés dans cet arbre, alors souvent (mais pas toujours), pour que la phrase soit naturelle, les éléments en double sont supprimés. Une telle suppression est appelée ellipse (exemple 1).
(1)
Ils ne m'ont pas rappelé et je ne comprends pas pourquoi ils ne m'ont pas rappelé .Les lacunes obtenues par des points de suspension peuvent être restaurées sans ambiguïté à partir du contexte linguistique. Comparez le premier exemple avec le second (2), où il y a une passe, mais ce qui manque exactement n'est pas clair. Ce cas n'est pas une ellipse.
(2)
L'écart est l'un des types de fréquence des points de suspension. Prenons l'exemple (3) et comprenez comment cela fonctionne.
(3)
Je l'ai confondue avec un Italien et lui avec un Suédois.Dans tous les exemples, il y a plus de deux phrases (clauses), elles sont composées entre elles. Dans la première clause, il y a un verbe (les linguistes sont plus susceptibles de dire «prédicat») et ses participants l'ont
accepté :
moi ,
elle et l'
italien . Dans la deuxième clause, il n'y a pas de verbe exprimé, il n'y en a que des «restes» (ou restes) et
pour le Suédois qui ne sont pas liés syntaxiquement, mais nous comprenons comment la passe est restaurée.
Pour restaurer la passe, nous passons à la première clause et copions la structure entière à partir de celle-ci (exemple 4). Nous remplaçons uniquement les pièces pour lesquelles il existe des restes "parallèles" dans une clause incomplète. Nous avons copié le prédicat,
nous le remplaçons par
lui ,
pour l'italien nous le remplaçons par du reste
pour le suédois . Pour
moi, il n'y avait pas de vestige parallèle, ce qui signifie que nous le copions sans remplacement.
(4)
Je l'ai confondue avec l'italien et je l'ai confondue avec un Suédois.Il semble que pour rétablir l'écart, il nous suffit de déterminer s'il y a une lacune dans cette phrase, de trouver la clause incomplète et la clause entière qui lui est associée (à partir de laquelle le matériau à restaurer est prélevé), puis de comprendre ce que les "restes" (restes) sont dans la clause incomplète et ce qu'ils correspondent en totalité. Il semble que ces conditions soient suffisantes pour combler efficacement l'écart. Ainsi, nous essayons d'imiter le processus dans la tête d'une personne lisant ou entendant un texte dans lequel il peut y avoir des omissions.
Alors, pourquoi est-ce nécessaire?
Il est clair que pour une personne qui entend pour la première fois des points de suspension et les difficultés de traitement qui y sont associées, une question légitime peut se poser: «Pourquoi?» Les sceptiques aimeraient
inviter les pères de la science linguistique à
lire pour expliquer que si la solution d'un problème appliqué fournit du matériel qui peut être utile dans la recherche théorique, alors c'est déjà une réponse suffisante à la question sur le but d'une telle activité.
Les théoriciens étudient les ellipses dans différentes langues depuis environ 50 ans, décrivent les limites, mettent en évidence les schémas généraux dans différentes langues. En même temps, nous n'avons pas connaissance de l'existence d'un corpus illustrant tout type d'ellipses avec plus de quelques centaines d'exemples. Cela est dû en partie à la rareté du phénomène (par exemple, sur nos données, le grappin se trouve dans pas plus de 5 phrases sur 10 mille). La création d'un tel corps est donc déjà un résultat important.
Dans les systèmes d'application qui fonctionnent avec des données texte, la rareté du phénomène vous permet de simplement l'ignorer. L'incapacité de l'analyseur syntaxique à restaurer les lacunes manquantes n'apporte pas exactement beaucoup d'erreurs. Mais à partir d'événements rares, une périphérie linguistique étendue et bigarrée se forme. Il semble que l'expérience de la résolution d'un tel problème en soi devrait intéresser ceux qui veulent créer des systèmes qui fonctionnent non seulement sur des textes simples, courts et propres avec un vocabulaire commun, c'est-à-dire sur des textes sphériques dans un vide qui ne se produisent pratiquement pas dans la nature.
Peu d'analyseurs disposent d'un système efficace pour détecter et résoudre les points de suspension. Mais dans l'analyseur interne ABBYY, il existe un module responsable de la restauration des passes, et il est basé sur des règles écrites manuellement. Grâce à cette capacité de l'analyseur, nous avons pu créer un grand corps pour la compétition. L'avantage potentiel pour l'analyseur d'origine est de remplacer un module à exécution lente. De plus, tout en travaillant sur le cas, nous avons effectué une analyse détaillée des erreurs du système actuel.
Comment nous avons créé le corps
Notre bâtiment est principalement destiné à la formation de systèmes automatiques, ce qui signifie qu'il est extrêmement important qu'il soit volumineux et diversifié. Guidé par cela, nous avons construit le travail de collecte de données comme suit. Pour le corps, nous avons sélectionné des textes de différents genres: de la documentation technique aux brevets en passant par les actualités et les publications des réseaux sociaux. Tous ont été balisés par l'analyseur ABBYY. En un mois, nous avons distribué des données entre linguistes-scribers. Les marqueurs ont été invités, sans modifier le balisage, à l'évaluer sur une échelle:
0 - il n'y a pas de mappage dans la phrase, le balisage n'est pas pertinent.
1 - il existe un mappage et son balisage est correct.
2 - il y a un espace, mais quelque chose ne va pas avec le balisage.
3 - un cas délicat, est-ce une cartographie?
En conséquence, chacun des groupes a été utile. Les exemples de la catégorie 1 entraient dans la classe positive de notre ensemble de données. Nous ne voulions essentiellement pas rééchantillonner manuellement les exemples des catégories 2 et 3 afin de gagner du temps, mais ces exemples nous ont été utiles plus tard pour évaluer notre corpus résultant. À partir d'eux, on peut juger quels cas le système marque systématiquement de manière incorrecte, ce qui signifie qu'ils ne tombent pas dans notre corps. Et enfin, y compris dans les exemples de cas attribués par les marqueurs à la catégorie 0, nous avons donné aux systèmes l'occasion «d'apprendre des erreurs des autres», c'est-à-dire non seulement de simuler le comportement du système d'origine, mais de mieux fonctionner.
Chaque exemple a été évalué par deux marqueurs. Après cela, un peu plus de la moitié des propositions sont entrées dans le corps à partir des données sources. Toute la classe d'exemples positifs et une partie du négatif en sont constitués. Nous avons décidé de rendre la classe négative deux fois plus positive afin que, d'une part, les classes soient comparables en volume, et d'autre part, la prépondérance de la classe négative qui existe dans la langue soit préservée.
Pour respecter cette proportion, nous avons dû ajouter des exemples plus négatifs au cas, en plus des exemples décrits de catégorie 0. Donnons un exemple (5) de catégorie 0, qui peut confondre non seulement la voiture, mais aussi la personne.
(5)
Mais à ce moment-là, Jack était amoureux de Cindy Page, maintenant Mme Jack Svaytek.Dans la deuxième clause, elle ne se remet pas
en amour , parce que je veux dire que maintenant Cindy Page est devenue Mme Jack Svaytek parce qu'elle l'a épousé.
En général, pour un phénomène syntaxique relativement rare comme l’espacement, un exemple négatif est presque toute phrase aléatoire de la langue, car la probabilité qu’il y ait un petit espace dans une phrase aléatoire. Cependant, l'utilisation de tels exemples négatifs peut conduire à un recyclage sur les signes de ponctuation. Dans notre cas, des exemples pour la classe négative ont été obtenus selon des critères simples: la présence d'un verbe, la présence d'une virgule ou d'un tiret, la longueur de phrase minimale n'est pas inférieure à 6 jetons.
Pour le concours, nous avons sélectionné dans la partie développement du bâtiment de formation (dans un rapport de 1: 5), que les participants ont été invités à utiliser pour configurer leurs systèmes. Les versions finales des systèmes ont été formées sur les parties combinées train et dev. Nous avons étiqueté manuellement le cas de test (test) par nous-mêmes, en termes de volume, il s'agit de la 10ème partie de train + dev. Voici le nombre exact d'exemples de classe:
En plus des données d'entraînement vérifiées manuellement, nous avons ajouté un fichier de balisage brut reçu du système source. Il contient plus de 100 000 exemples et les participants pourraient éventuellement utiliser ces données pour compléter l'échantillon de formation. Pour l'avenir, nous disons qu'un seul participant a trouvé comment augmenter considérablement le bâtiment de formation en utilisant des données sales sans perdre en qualité.
Format de balisage
Nous avons délibérément refusé d'utiliser des analyseurs tiers et avons développé un balisage dans lequel tous les éléments qui nous intéressent sont marqués linéairement dans la ligne de texte. Nous avons utilisé deux types de balisage. Le premier, lisible par l'homme, est conçu pour fonctionner avec le balisage et il est pratique d'analyser les erreurs des systèmes résultants. Avec cette méthode, tous les éléments d'espacement sont marqués entre crochets à l'intérieur de la phrase. Chaque paire de crochets est marquée du nom de l'élément correspondant. Nous avons utilisé la notation suivante:

Nous donnons des exemples de phrases avec espace entre parenthèses.
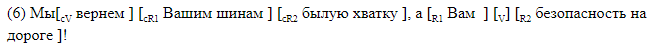
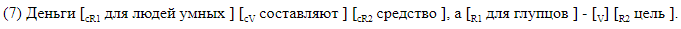

Le marquage du support convient à l'analyse des matériaux. Dans le cas, les données sont stockées dans un format différent, qui, si vous le souhaitez, peut être facilement converti en parenthèse. Une ligne correspond à une phrase. Les colonnes indiquent la présence d'un espace dans la phrase, et pour chaque étiquette possible dans sa colonne, des décalages symboliques du début et de la fin du segment correspondant à l'élément sont donnés. Voici à quoi ressemble le balisage de décalage, correspondant au balisage du crochet entre ().
Tâches des participants
Les participants à l'AGRR-2019 pourraient résoudre l'un des trois problèmes suivants:
- Classification binaire Il est nécessaire de déterminer s'il y a un espace dans la phrase.
- Permission d'espacement. Il est nécessaire de restaurer la position de la passe (V) et la position du contrôleur de verbe (cV).
- Balisage complet. Vous devez définir des décalages pour tous les éléments de l'écart.
Chaque tâche suivante doit en quelque sorte résoudre la précédente. Il est clair que tout balisage n'est possible que dans les phrases sur lesquelles la classification binaire affiche une classe positive (il existe un mappage), et le balisage complet comprend également la recherche des limites des prédicats manquants et le contrôle.
Mesures
Pour le problème de classification binaire, nous avons utilisé des métriques standard: précision et exhaustivité, et les résultats des participants ont été classés par f-mesure.
Pour les tâches de résolution de l'espacement et du balisage complet, nous avons décidé d'utiliser une f-mesure symbolique, car les textes sources n'étaient pas tokenisés et nous ne voulions pas que la différence dans les participants utilisant les tokenizers affecte les résultats. Les exemples véritablement négatifs n'ont pas contribué à la mesure f symbolique, pour chaque élément de majoration, sa propre mesure f a été prise en compte, le résultat final a été obtenu par macro-moyenne sur l'ensemble du corps. Grâce à un tel calcul de la métrique, les cas de faux positifs ont été considérablement condamnés à une amende, ce qui est important quand il y a plusieurs fois moins d'exemples positifs dans les données réelles que négatifs.
Cours de compétition
Parallèlement à l'assemblage du bâtiment, nous avons accepté les candidatures pour participer au concours. En conséquence, nous avons enregistré plus de 40 participants. Ensuite, nous avons aménagé le bâtiment d'entraînement et lancé le concours. Les participants avaient 4 semaines pour construire leurs modèles.
L'étape de l'évaluation des résultats a été la suivante: les participants ont reçu 20 000 offres sans majoration, à l'intérieur desquelles un cas de test a été impliqué. Les équipes ont dû marquer ces données avec leurs systèmes, après quoi nous avons évalué les résultats des marquages sur le bâtiment d'essai. Le mélange du test dans une grande quantité de données nous a garanti que, de toutes nos volontés, le cas ne pouvait pas être balisé manuellement dans les quelques jours qui avaient été donnés pour la course (marquage automatique).
Résultats du concours
Neuf équipes ont atteint la finale, dont des représentants de deux sociétés informatiques, des chercheurs de l'Université d'État de Moscou, l'Institut de physique et de technologie de Moscou, HSE et IPPI RAS.
Toutes les équipes sauf une ont participé aux trois compétitions. Selon les termes de l'AGRR-2019, toutes les équipes ont publié un code pour leurs décisions. Un tableau récapitulatif avec les résultats est donné dans
notre référentiel , où vous pouvez également trouver des liens vers les solutions présentées des équipes avec de brèves descriptions.
Presque tous ont montré de bons résultats. Voici les appréciations des décisions des équipes gagnantes:
Une description détaillée des meilleures solutions sera bientôt disponible dans les articles des participants de la collection Dialogue.
Ainsi, dans cet article, nous avons expliqué comment, en prenant comme base un phénomène linguistique rare, pour formuler une tâche, préparer un corps et mener des compétitions. Un tel travail présente également des avantages pour la communauté PNL, car les concours aident à comparer différentes architectures et approches sur du matériel spécifique, et les linguistes obtiennent le cas d'un phénomène rare avec la possibilité de le reconstituer (en utilisant les décisions des gagnants). Le corps assemblé est plusieurs fois plus important que les volumes du corps existant actuellement (de plus, pour les lacunes, le volume du corpus est d'un ordre de grandeur plus grand que les volumes du corps non seulement pour le russe, mais pour toutes les langues en général). Toutes les données et les liens vers les décisions des participants peuvent être trouvés dans notre github.
Le 30 mai, lors de la session spéciale du
Dialogue consacrée à l'analyse automatique des compétitions béantes, les résultats de l'AGRR-2019 seront résumés. Nous parlerons de l'organisation du concours et nous attarderons sur le contenu du bâtiment créé, et les participants présenteront l'architecture sélectionnée avec laquelle ils ont résolu le problème.
Groupe de recherche avancée PNL