Le cours complet de russe se trouve sur
ce lien .
Le cours d'anglais original est disponible sur
ce lien .
 De nouvelles conférences sont prévues tous les 2-3 jours.
De nouvelles conférences sont prévues tous les 2-3 jours.Entretien avec Sebastian Trun, PDG Udacity
"Donc, nous sommes toujours avec toi et avec nous, comme avant, Sebastian." Nous voulons juste discuter des couches entièrement connectées, ces mêmes couches denses. Avant cela, je voudrais poser une question. Quelles sont les limites et quels sont les principaux obstacles qui entraveront l'apprentissage en profondeur et auront le plus grand impact sur celui-ci au cours des 10 prochaines années? Tout change si vite! Selon vous, quelle sera la toute prochaine «grande chose»?
- Je dirais deux choses. Le premier est l'IA générale pour plus d'une tâche. C'est super! Les gens peuvent résoudre plus d'un problème et ne devraient jamais faire la même chose. La seconde consiste à mettre la technologie sur le marché. Pour moi, la particularité de l'apprentissage automatique est qu'il fournit aux ordinateurs la capacité d'observer et de trouver des modèles dans les données, aidant les gens à devenir meilleurs dans le domaine - au niveau expert! L'apprentissage automatique peut être utilisé en droit, en médecine, dans les voitures autonomes. Développer de telles applications car elles peuvent rapporter énormément d'argent, mais surtout, vous avez la possibilité de faire du monde un bien meilleur endroit.
- J'aime vraiment la façon dont vous dites tout dans une seule image de l'apprentissage en profondeur et de son application - ce n'est qu'un outil qui peut vous aider à résoudre un certain problème.
- Oui, exactement! Outil incroyable, non?
- Oui, oui, je suis entièrement d'accord avec toi!
"Presque comme un cerveau humain!"
- Vous avez mentionné les applications médicales dans notre première interview, dans la première partie du cours vidéo. Dans quelles applications, à votre avis, l'utilisation du deep learning suscite le plus de plaisir et de surprise?
- Beaucoup! Très! La médecine est sur la courte liste des domaines qui utilisent activement l'apprentissage en profondeur. J'ai perdu ma sœur il y a quelques mois, elle était malade d'un cancer, ce qui est très triste. Je pense que de nombreuses maladies pourraient être détectées plus tôt - aux premiers stades, ce qui permet de les guérir ou de ralentir le processus de leur développement. L'idée, en fait, est de transférer certains outils à la maison (maison intelligente), afin qu'il soit possible de détecter de tels écarts de santé bien avant le moment où la personne elle-même les voit. J'ajouterais également - tout est répété, tout travail de bureau, où vous effectuez le même type d'actions encore et encore, par exemple, la comptabilité. Même moi, en tant que PDG, je fais beaucoup d'actions répétitives. Ce serait formidable de les automatiser, même de travailler avec la correspondance par courrier!
- Je ne peux pas être en désaccord avec toi! Dans cette leçon, nous présenterons aux étudiants un cours avec une couche de réseau de neurones appelée couche dense. Pourriez-vous nous dire plus en détail ce que vous pensez des couches entièrement connectées?
- Commençons donc par le fait que chaque réseau peut être connecté de différentes manières. Certains d'entre eux peuvent avoir une connectivité très étroite, ce qui vous permet d'obtenir des avantages en matière de mise à l'échelle et de «gagner» contre les grands réseaux. Parfois, vous ne savez pas combien de connexions vous avez besoin, alors vous connectez tout avec tout - c'est ce qu'on appelle une couche entièrement connectée. J'ajoute que cette approche a beaucoup plus de pouvoir et de potentiel que quelque chose de plus structuré.
- Je suis complètement d'accord avec toi! Merci de nous avoir aidés à en savoir un peu plus sur les couches entièrement connectées. J'attends avec impatience le moment où nous commencerons enfin à les implémenter et à écrire du code.
- Amuse toi bien! Ce sera vraiment amusant!
Présentation
- Bon retour! Dans la dernière leçon, vous avez compris comment construire votre premier réseau neuronal à l'aide de TensorFlow et Keras, comment fonctionnent les réseaux neuronaux et comment fonctionne le processus de formation (formation). En particulier, nous avons vu comment entraîner le modèle à convertir les degrés Celsius en degrés Fahrenheit.

- Nous avons également pris connaissance du concept de couches entièrement connectées (couches denses), la couche la plus importante des réseaux de neurones. Mais dans cette leçon, nous ferons des choses beaucoup plus cool! Dans cette leçon, nous développerons un réseau de neurones capable de reconnaître les éléments vestimentaires et les images. Comme nous l'avons mentionné précédemment, l'apprentissage automatique utilise une entrée appelée «fonctionnalités» et une sortie appelée «étiquettes», par laquelle le modèle apprend et trouve un algorithme de transformation. Par conséquent, premièrement, nous aurons besoin de nombreux exemples pour entraîner le réseau neuronal à reconnaître divers éléments des vêtements. Permettez-moi de vous rappeler qu'un exemple pour la formation est une paire de valeurs - une caractéristique d'entrée et une étiquette de sortie, qui sont alimentées à l'entrée d'un réseau neuronal. Dans notre nouvel exemple, l'image sera utilisée comme entrée et l'étiquette de sortie devrait être la catégorie de vêtements à laquelle appartient l'article vestimentaire illustré. Heureusement, un tel ensemble de données existe déjà. Il s'appelle Fashion MNIST. Nous examinerons de plus près cet ensemble de données dans la partie suivante.
Fashion MNIST Dataset
Bienvenue dans le monde de l'ensemble de données MNIST! Ainsi, notre ensemble se compose d'images 28x28, dont chaque pixel représente une nuance de gris.

L'ensemble de données contient des images de T-shirts, hauts, sandales et même des bottes. Voici une liste complète de ce que contient notre ensemble de données MNIST:
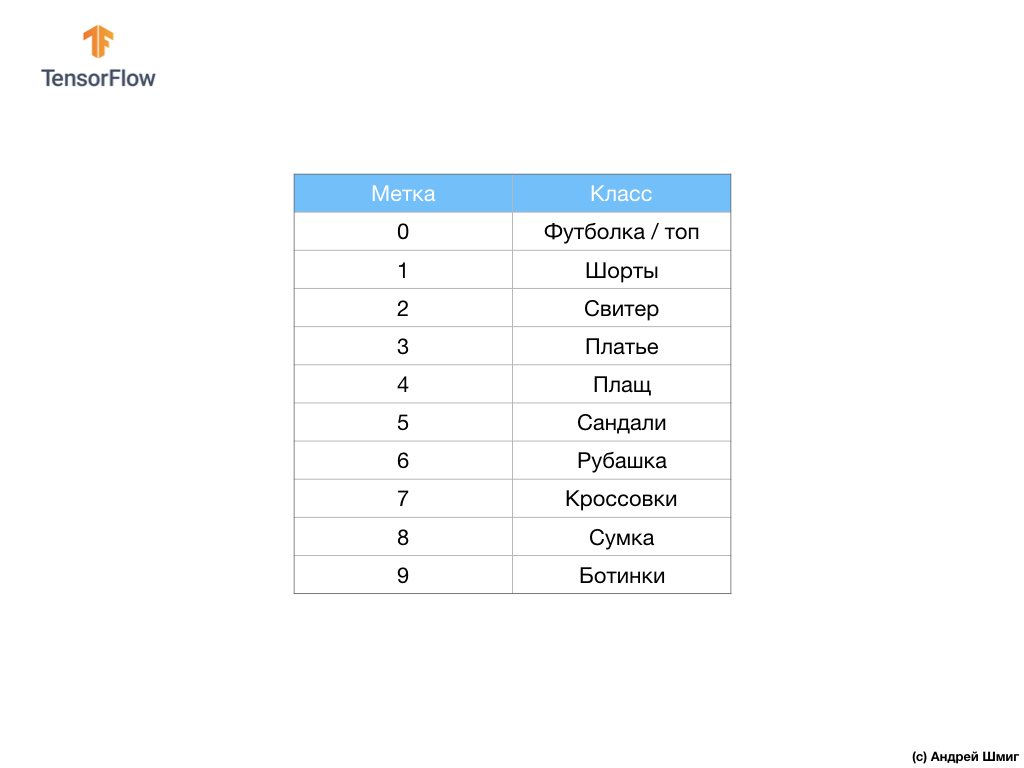
Chaque image d'entrée correspond à l'une des étiquettes ci-dessus. L'ensemble de données Fashion MNIST contient 70 000 images, nous avons donc un endroit pour commencer et travailler avec. Sur ces 70 000, nous en utiliserons 60 000 pour former le réseau neuronal.
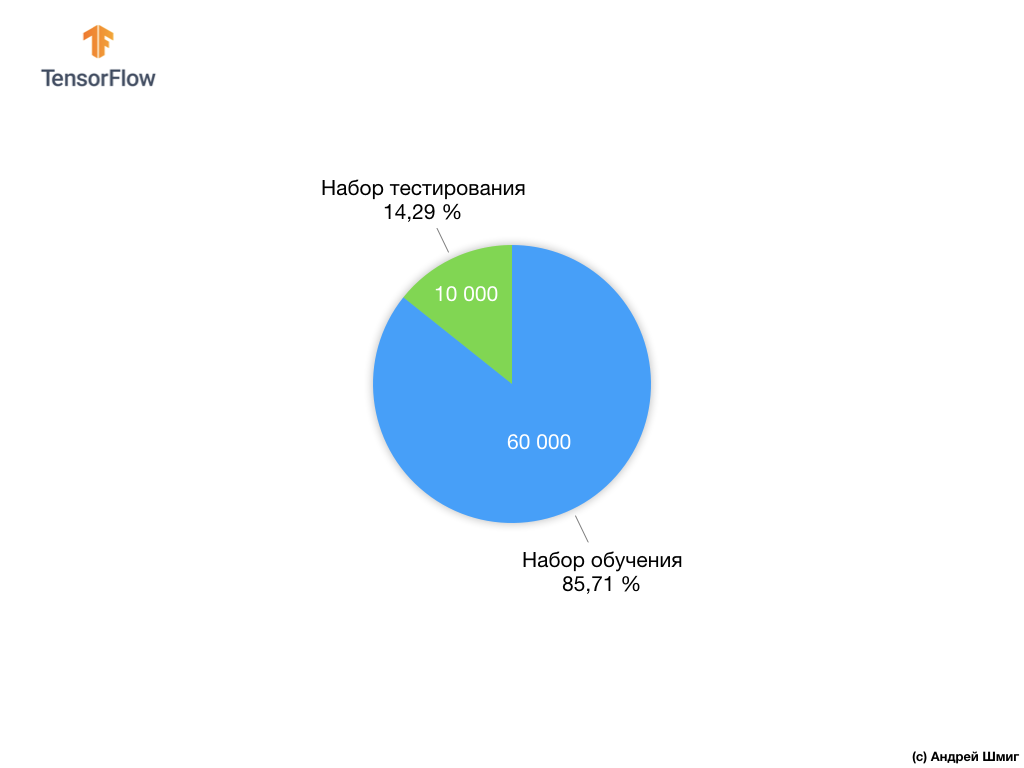
Et nous utiliserons les 10 000 éléments restants pour vérifier dans quelle mesure notre réseau de neurones a appris à reconnaître les éléments des vêtements. Plus tard, nous expliquerons pourquoi nous avons divisé l'ensemble de données en un ensemble de formation et un ensemble de test.
Voici donc notre jeu de données Fashion MNIST.
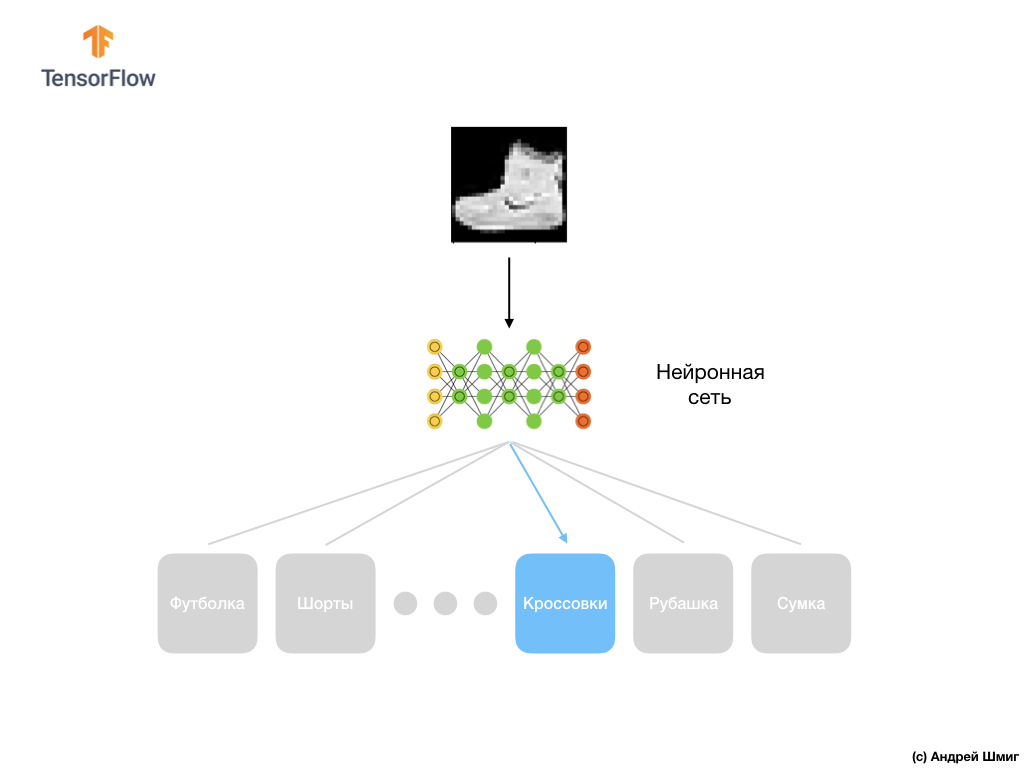
N'oubliez pas que chaque image du jeu de données est une image de taille 28x28 en nuances de gris, ce qui signifie que chaque image fait 784 octets. Notre tâche est de créer un réseau neuronal, qui reçoit ces 784 octets en entrée, et en sortie renvoie à quelle catégorie de vêtements sur 10 disponibles, l'élément appliqué en entrée appartient.
Réseau de neurones
Dans cette leçon, nous utiliserons un réseau neuronal profond qui apprend à classer les images de l'ensemble de données Fashion MNIST.
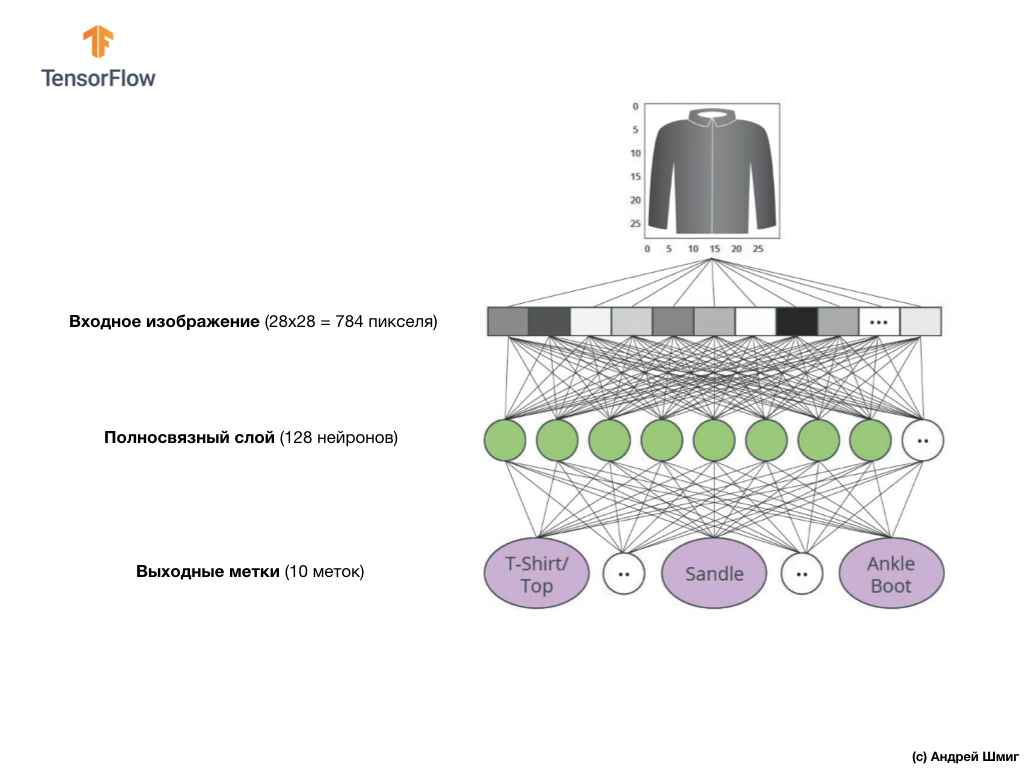
L'image ci-dessus montre à quoi ressemblera notre réseau de neurones. Examinons-le plus en détail.
La valeur d'entrée de notre réseau de neurones est un tableau unidimensionnel d'une longueur de 784, un tableau exactement de cette longueur pour la raison que chaque image fait 28x28 pixels (= 784 pixels au total dans l'image), que nous convertirons en un tableau unidimensionnel. Le processus de conversion d'une image 2D en vecteur est appelé aplatissement et est mis en œuvre via une couche de lissage - une couche d'aplatissement.
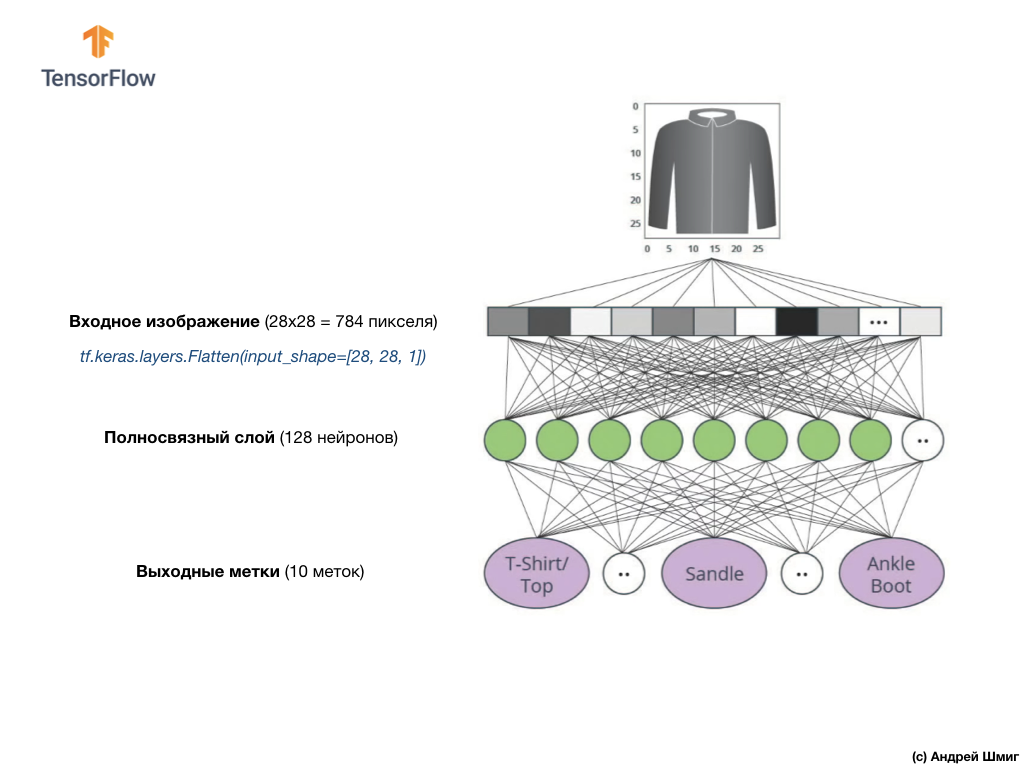
Vous pouvez effectuer un lissage en créant le calque approprié:
tf.keras.layers.Flatten(input_shape=[28, 28, 1])
Cette couche convertit une image 2D de 28 x 28 pixels (1 octet pour les niveaux de gris par pixel) en un tableau 1D de 784 pixels.
Les valeurs d'entrée seront entièrement associées à notre première couche de réseau
dense , dont la taille que nous avons choisie est égale à 128 neurones.
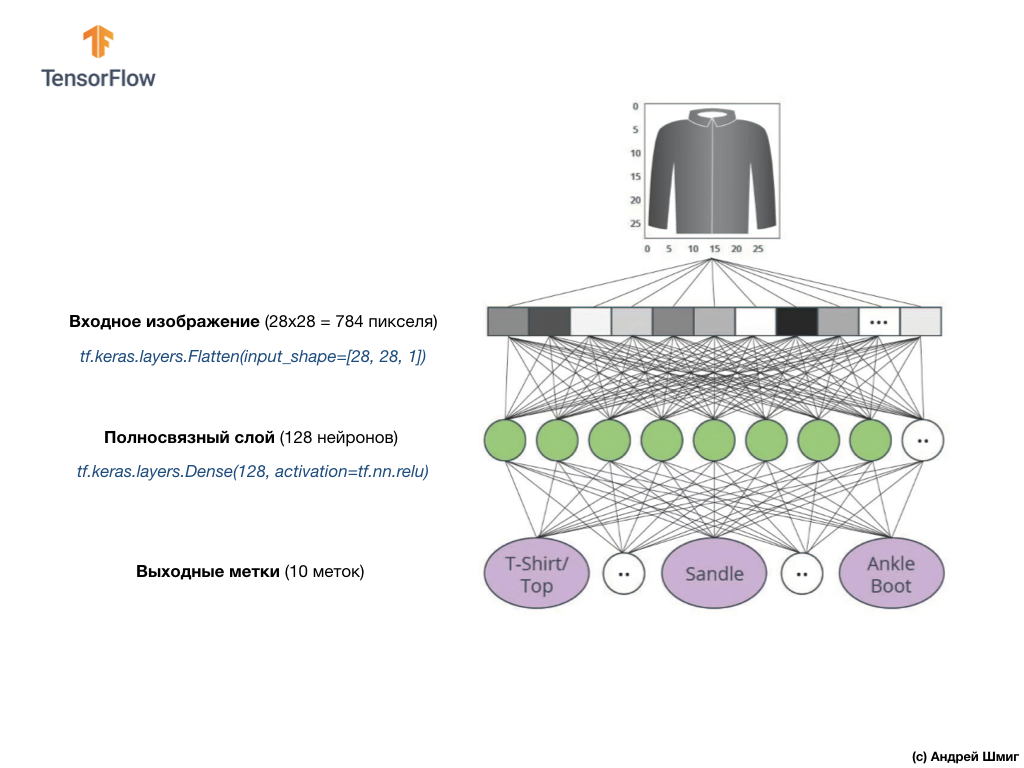
Voici à quoi ressemblera la création de cette couche dans le code:
tf.keras.layers.Dense(128, activation=tf.nn.relu)
Arrête ça! Qu'est-ce que
tf.nn.relu ? Nous ne l'avons pas utilisé dans notre exemple de réseau de neurones précédent lors de la conversion des degrés Celsius en degrés Fahrenheit! L'essentiel est que la tâche actuelle est beaucoup plus compliquée que celle qui a été utilisée comme exemple d'orientation - convertir les degrés Celsius en degrés Fahrenheit.
ReLU est une fonction mathématique que nous ajoutons à notre couche entièrement connectée et qui donne plus de puissance à notre réseau. En fait, il s'agit d'une petite extension de notre couche entièrement connectée, qui permet à notre réseau de neurones de résoudre des problèmes plus complexes. Nous n'entrerons pas dans les détails, mais des informations un peu plus détaillées peuvent être trouvées ci-dessous.
Enfin, notre dernière couche, également connue sous le nom de couche de sortie, se compose de 10 neurones. Il se compose de 10 neurones car notre jeu de données Fashion MNIST contient 10 catégories de vêtements. Chacune de ces 10 valeurs de sortie représentera la probabilité que l'image d'entrée soit dans cette catégorie de vêtements. En d'autres termes, ces valeurs reflètent la «confiance» du modèle dans l'exactitude de la prédiction et la corrélation de l'image déposée avec une catégorie de vêtements spécifique sur 10 à la sortie. Par exemple, quelle est la probabilité que l'image montre une robe, des baskets, des chaussures, etc.
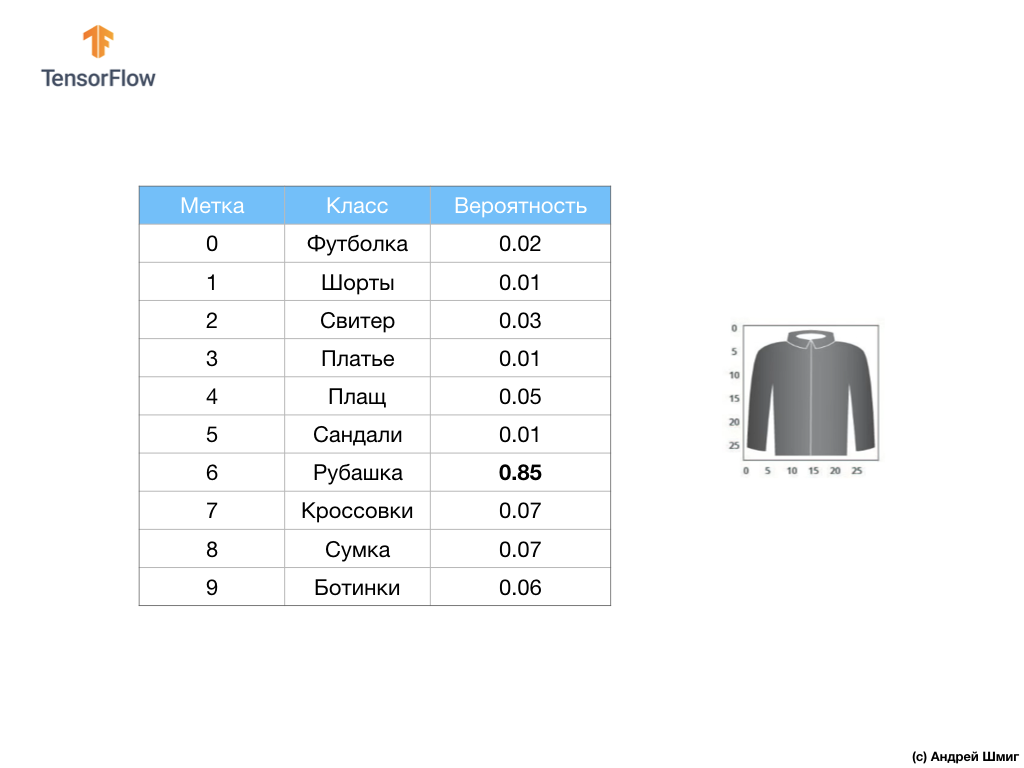
Par exemple, si une image de chemise est envoyée à l'entrée de notre réseau neuronal, le modèle peut nous donner des résultats comme ceux que vous voyez dans l'image ci-dessus - la probabilité que l'image d'entrée corresponde à l'étiquette de sortie.
Si vous faites attention, vous remarquerez que la plus grande probabilité - 0,85 se réfère à la balise 6, qui correspond à la chemise. Le modèle est sûr à 85% que l'image sur la chemise. Habituellement, les choses qui ressemblent à des chemises auront également une cote de probabilité élevée, et les choses moins similaires auront une cote de probabilité inférieure.
Étant donné que les 10 valeurs de sortie correspondent aux probabilités, lorsque nous additionnons toutes ces valeurs, nous obtenons 1. Ces 10 valeurs sont également appelées la distribution de probabilité.
Nous avons maintenant besoin d'une couche de sortie pour calculer les probabilités mêmes pour chaque étiquette.

Et nous le ferons avec la commande suivante:
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
En fait, chaque fois que nous créons des réseaux de neurones qui résolvent des problèmes de classification, nous utilisons toujours une couche entièrement connectée comme dernière couche d'un réseau de neurones. La dernière couche du réseau neuronal doit contenir le nombre de neurones égal au nombre de classes, auquel nous déterminons l'
softmax et utilisons la fonction d'activation softmax.
ReLU - fonction d'activation des neurones
Dans cette leçon, nous avons parlé de
ReLU comme quelque chose qui étend les capacités de notre réseau neuronal et lui donne une puissance supplémentaire.
ReLU est une fonction mathématique qui ressemble à ceci:
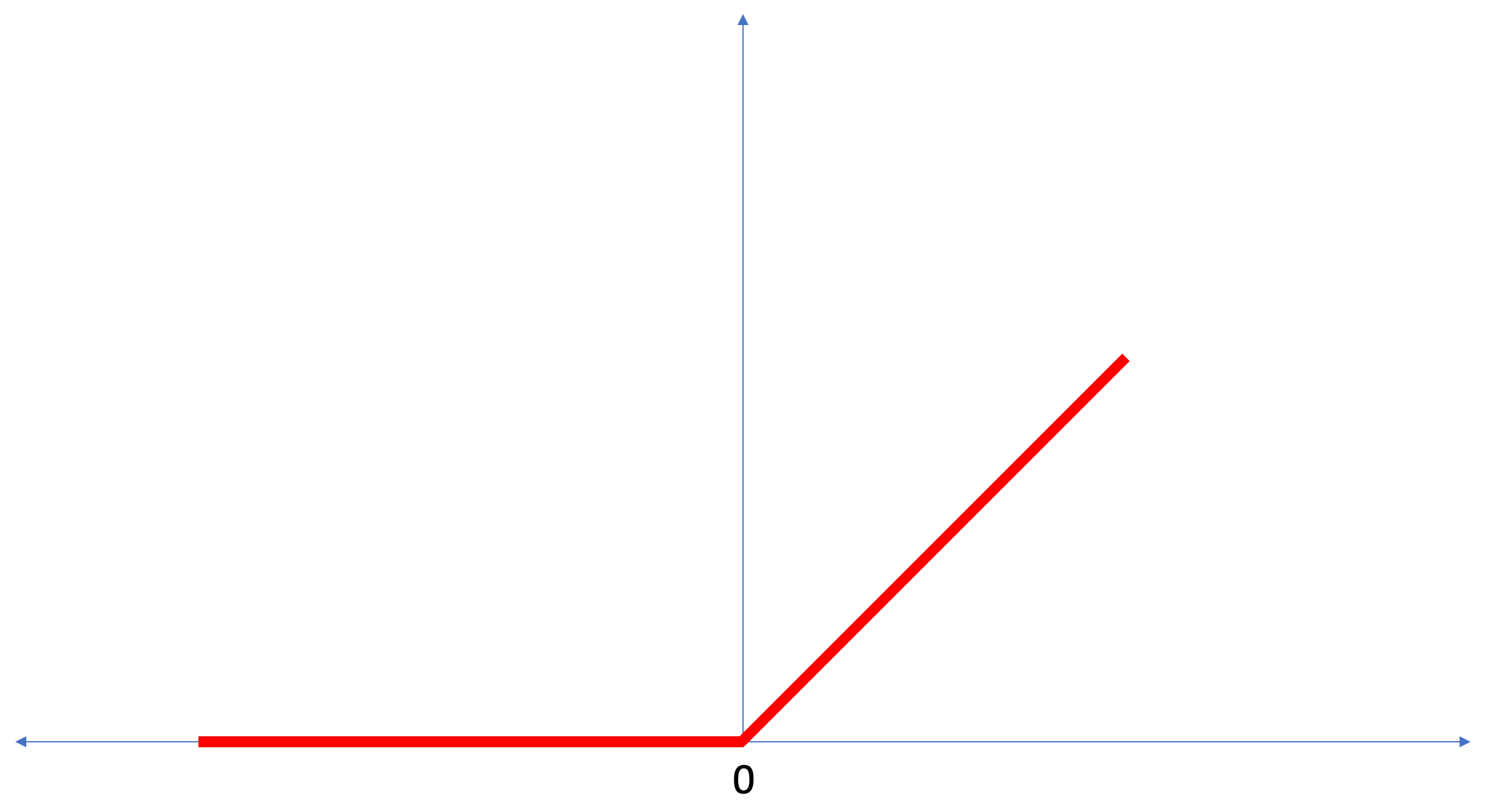
La fonction
ReLU renvoie 0 si la valeur d'entrée était une valeur négative ou zéro, dans tous les autres cas, la fonction renverra la valeur d'entrée d'origine.
ReLU permet de résoudre des problèmes non linéaires.
La conversion des degrés Celsius en degrés Fahrenheit est une tâche linéaire, car l'expression
f = 1.8*c + 32 est l'équation de la ligne -
y = m*x + b . Mais la plupart des tâches que nous voulons résoudre sont non linéaires. Dans de tels cas, l'ajout de la fonction d'activation ReLU à notre couche entièrement connectée peut aider à faire face à de telles tâches.
ReLU n'est qu'un type de fonction d'activation. Il existe des fonctions d'activation telles que sigmoïde, ReLU, ELU, tanh, cependant, c'est
ReLU qui
ReLU plus souvent utilisé comme fonction d'activation par défaut. Pour créer et utiliser des modèles qui incluent ReLU, vous n'avez pas besoin de comprendre comment cela fonctionne en interne. Si vous souhaitez toujours mieux comprendre, nous vous recommandons
cet article .
Passons en revue les nouveaux termes introduits dans cette leçon:
- Lissage - processus de conversion d'une image 2D en un vecteur 1D;
- ReLU est une fonction d'activation qui permet au modèle de résoudre des problèmes non linéaires;
- Softmax - une fonction qui calcule les probabilités pour chaque classe de sortie possible;
- Classification - une classe de tâches d'apprentissage automatique utilisée pour déterminer les différences entre deux ou plusieurs catégories (classes).
Formation et tests
Lors de la formation d'un modèle, tout modèle d'apprentissage automatique, il est toujours nécessaire de diviser l'ensemble de données en au moins deux ensembles différents - l'ensemble de données utilisé pour la formation et l'ensemble de données utilisé pour les tests. Dans cette partie, nous comprendrons pourquoi cela vaut la peine de le faire.
Rappelons-nous comment nous avons distribué notre ensemble de données de Fashion MNIST composé de 70 000 exemplaires.
Nous avons proposé de diviser 70 000 en deux parties - dans la première partie, laissez 60 000 pour la formation et dans la seconde 10 000 pour les tests. La nécessité d'une telle approche est due au fait suivant: après que le modèle a été formé sur 60000 exemplaires, il est nécessaire de vérifier les résultats et l'efficacité de son travail sur des exemples qui ne figuraient pas encore dans l'ensemble de données sur lequel le modèle a été formé.
À sa manière, cela ressemble à la réussite d'un examen à l'école. Avant de réussir l'examen, vous êtes diligemment engagé dans la résolution des problèmes d'une classe particulière. Ensuite, à l'examen, vous rencontrez la même classe de problèmes, mais avec des données d'entrée différentes. Cela n'a aucun sens de soumettre les mêmes données que lors de la formation, sinon la tâche sera réduite à se souvenir des décisions et à ne pas chercher de modèle de solution. C'est pourquoi, aux examens, vous êtes confronté à des tâches qui ne figuraient pas auparavant dans le programme. Ce n'est que de cette manière que nous pouvons vérifier si le modèle a appris la solution générale ou non.
La même chose se produit avec l'apprentissage automatique. Vous montrez des données qui représentent une certaine classe de tâches que vous souhaitez apprendre à résoudre. Dans notre cas, avec un ensemble de données de Fashion MNIST, nous voulons que le réseau neuronal puisse déterminer la catégorie à laquelle appartient l'élément vestimentaire de l'image. C'est pourquoi nous formons notre modèle sur 60 000 exemplaires qui contiennent toutes les catégories d'articles vestimentaires. Après la formation, nous voulons vérifier l'efficacité du modèle, nous nourrissons donc les 10 000 vêtements restants que le modèle n'a pas encore «vus». Si nous décidions de ne pas le faire, de ne pas tester avec 10000 exemples, nous ne serions pas en mesure de dire avec certitude si notre modèle a été réellement formé pour déterminer la classe de l'habillement ou si elle se souvenait de toutes les paires de valeurs d'entrée + sortie.
C'est pourquoi dans l'apprentissage automatique, nous avons toujours un ensemble de données pour la formation et un ensemble de données pour les tests.
TensorFlow est une collection de données de formation prêtes à l'emploi.
Les ensembles de données sont généralement divisés en plusieurs blocs, chacun étant utilisé à un certain stade de la formation et du test de l'efficacité du réseau neuronal. Dans cette partie, nous parlons de:
- ensemble de données d'apprentissage : ensemble de données destiné à former un réseau de neurones;
- ensemble de données de test : ensemble de données conçu pour vérifier l'efficacité d'un réseau neuronal;
Prenons un autre ensemble de données, que j'appelle un ensemble de données de validation. Cet ensemble de données n'est pas utilisé
pour former le modèle, uniquement
pendant la formation. Ainsi, après que notre modèle a subi plusieurs cycles de formation, nous lui fournissons notre ensemble de données de test et examinons les résultats. Par exemple, si pendant la formation, la valeur de la fonction de perte diminue et que la précision se détériore sur l'ensemble de données de test, cela signifie que notre modèle se souvient simplement de paires de valeurs d'entrée-sortie.
L'ensemble de données de vérification est réutilisé à la toute fin de la formation pour mesurer la précision finale des prédictions du modèle.
Pour plus d'
informations sur les ensembles de données de formation et de test, consultez le cours Google Crash .
Partie pratique dans CoLab
Lien vers le CoLab original en anglais et un
lien vers le CoLab russe .
Classification des images d'articles vestimentaires
Dans cette partie de la leçon, nous allons construire et former un réseau neuronal pour classer les images des éléments vestimentaires, tels que les robes, les baskets, les chemises, les t-shirts, etc.
Tout va bien si certains moments ne sont pas clairs. Le but de ce cours est de vous présenter TensorFlow et en même temps d'expliquer les algorithmes de son travail et de développer une compréhension commune des projets utilisant TensorFlow, plutôt que de vous plonger dans les détails de la mise en œuvre.
Dans cette partie, nous utilisons
tf.keras , une API de haut niveau pour la construction et la formation de modèles dans TensorFlow.
Installation et importation de dépendances
Nous aurons besoin d'
un ensemble de données TensorFlow , une API qui simplifie le chargement et l'accès aux ensembles de données fournis par plusieurs services. Nous aurons également besoin de quelques bibliothèques auxiliaires.
!pip install -U tensorflow_datasets
from __future__ import absolute_import, division, print_function, unicode_literals
Importer le jeu de données Fashion MNIST
Cet exemple utilise l'ensemble de données Fashion MNIST, qui contient 70 000 images d'articles vestimentaires dans 10 catégories en niveaux de gris. Les images contiennent des vêtements en basse résolution (28x28 pixels), comme indiqué ci-dessous:

Fashion MNIST est utilisé en remplacement du jeu de données MNIST classique - le plus souvent utilisé comme «Bonjour, monde!» dans l'apprentissage automatique et la vision par ordinateur. Le jeu de données MNIST contient des images de nombres écrits à la main (0, 1, 2, etc.) dans le même format que les vêtements de notre exemple.
Dans notre exemple, nous utilisons Fashion MNIST en raison de la variété et parce que cette tâche est plus intéressante du point de vue de la mise en œuvre que de résoudre un problème typique sur l'ensemble de données MNIST. Les deux ensembles de données sont suffisamment petits, par conséquent, ils sont utilisés pour vérifier le bon fonctionnement de l'algorithme. Grands ensembles de données pour commencer à apprendre le machine learning, tester et déboguer du code.
Nous utiliserons 60 000 images pour former le réseau et 10 000 images pour tester la précision de la formation et la classification des images. Vous pouvez accéder directement à l'ensemble de données Fashion MNIST via TensorFlow à l'aide de l'API:
dataset, metadata = tfds.load('fashion_mnist', as_supervised=True, with_info=True) train_dataset, test_dataset = dataset['train'], dataset['test']
En chargeant un ensemble de données, nous obtenons des métadonnées, un ensemble de données d'apprentissage et un ensemble de données de test.
- Le modèle est formé sur un ensemble de données de `train_dataset`
- Le modèle est testé sur un ensemble de données de `test_dataset`
Les images sont des tableaux bidimensionnels
2828 , où les valeurs dans chaque cellule peuvent être dans l'intervalle
[0, 255] . Étiquettes - un tableau d'entiers, où chaque valeur est dans l'intervalle
[0, 9] . Ces étiquettes correspondent à la classe d'image de sortie comme suit:
Chaque image appartient à une balise. Étant donné que les noms de classe ne sont pas contenus dans l'ensemble de données d'origine, enregistrons-les pour une utilisation future lorsque nous dessinerons les images:
class_names = [' / ', "", "", "", "", "", "", "", "", ""]
Nous recherchons des données
Étudions le format et la structure des données présentées dans l'ensemble de formation avant de former le modèle. Le code suivant montrera que 60 000 images se trouvent dans le jeu de données d'apprentissage et 10 000 images dans le jeu de données de test:
num_train_examples = metadata.splits['train'].num_examples num_test_examples = metadata.splits['test'].num_examples print(' : {}'.format(num_train_examples)) print(' : {}'.format(num_test_examples))
Prétraitement des données
La valeur de chaque pixel de l'image est dans la plage
[0,255] . Pour que le modèle fonctionne correctement, ces valeurs doivent être normalisées - réduites à des valeurs dans l'intervalle
[0,1] . Par conséquent, un peu plus bas, nous déclarons et implémentons la fonction de normalisation, puis l'appliquons à chaque image dans les ensembles de données d'apprentissage et de test.
def normalize(images, labels): images = tf.cast(images, tf.float32) images /= 255 return images, labels
Nous étudions les données traitées
Dessinons une image pour la regarder:
Nous affichons les 25 premières images de l'ensemble de données d'entraînement et sous chaque image, nous indiquons à quelle classe il appartient.
Assurez-vous que les données sont au bon format et nous sommes prêts à commencer à créer et à former le réseau.
plt.figure(figsize=(10,10)) i = 0 for (image, label) in test_dataset.take(25): image = image.numpy().reshape((28,28)) plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(image, cmap=plt.cm.binary) plt.xlabel(class_names[label]) i += 1 plt.show()

Construire un modèle
La construction d'un réseau neuronal nécessite des couches de réglage, puis l'assemblage d'un modèle avec des fonctions d'optimisation et de perte.
Personnaliser les calques
L'élément de base dans la construction d'un réseau neuronal est la couche. La couche extrait la vue des données entrées dans son entrée. Le résultat du travail de plusieurs couches connectées, nous obtenons une vue qui a du sens pour résoudre le problème.
La plupart du temps, en faisant un apprentissage en profondeur, vous créerez des liens entre de simples couches. La plupart des couches, par exemple, telles que tf.keras.layers.Dense, ont un ensemble de paramètres qui peuvent être «ajustés» pendant le processus d'apprentissage.
model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ])
Le réseau se compose de trois couches:
- input
tf.keras.layers.Flatten - cette couche convertit les images de 28x28 pixels en un tableau 1D de taille 784 (28 * 28). Sur cette couche, nous n'avons pas de paramètres pour la formation, car cette couche ne traite que de la conversion des données d'entrée. - couche cachée
tf.keras.layers.Dense - une couche étroitement connectée de 128 neurones. Chaque neurone (nœud) prend toutes les 784 valeurs de la couche précédente en entrée, modifie les valeurs d'entrée en fonction des poids internes et des déplacements pendant l'entraînement et renvoie une seule valeur à la couche suivante. - couche de sortie
ts.keras.layers.Dense - softmax compose de 10 neurones, chacun représentant une classe particulière d'éléments vestimentaires. Comme dans la couche précédente, chaque neurone reçoit les valeurs d'entrée des 128 neurones de la couche précédente. Les poids et les déplacements de chaque neurone sur cette couche changent pendant l'entraînement de sorte que la valeur résultante est dans l'intervalle [0,1] et représente la probabilité que l'image appartient à cette classe. La somme de toutes les valeurs de sortie de 10 neurones est 1.
Compiler le modèle
Avant de commencer à entraîner le modèle, cela vaut quelques réglages supplémentaires. Ces paramètres sont définis lors de l'assemblage du modèle lorsque la méthode de compilation est appelée:
- fonction de perte - un algorithme pour mesurer la distance entre la valeur souhaitée et la valeur prédite.
- fonction d'optimisation - un algorithme pour «ajuster» les paramètres internes (poids et décalages) du modèle afin de minimiser la fonction de perte;
- mesures - utilisées pour surveiller le processus de formation et les tests. L'exemple ci-dessous utilise des mesures telles que la
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Nous formons le modèle
Tout d'abord, nous déterminons la séquence d'actions lors de la formation sur un ensemble de données de formation:
- Répétez l'ensemble des données d'entrée un nombre infini de fois en utilisant la méthode
dataset.repeat() (le paramètre dataset.repeat() , décrit ci-dessous, détermine le nombre de toutes les itérations d'entraînement à effectuer) - La
dataset.shuffle(60000) toutes les images afin que l'apprentissage de notre modèle ne soit pas affecté par l'ordre de saisie des données. - La
dataset.batch(32) indique à la model.fit apprentissage model.fit utiliser des blocs de 32 images et des étiquettes model.fit fois que les variables internes du modèle sont mises à jour.
La formation se déroule en appelant la méthode
model.fit :
- Envoie
train_dataset à l'entrée du modèle. - Le modèle apprend à faire correspondre l'image d'entrée avec l'étiquette.
- Le paramètre
epochs=5 limite le nombre de sessions de formation à 5 itérations de formation complètes sur un ensemble de données, ce qui nous donne finalement une formation sur 5 * 60 000 = 300 000 exemples.
(vous pouvez ignorer le paramètre
steps_per_epoch , bientôt ce paramètre sera exclu de la méthode).
BATCH_SIZE = 32 train_dataset = train_dataset.repeat().shuffle(num_train_examples).batch(BATCH_SIZE) test_dataset = test_dataset.batch(BATCH_SIZE)
model.fit(train_dataset, epochs=5, steps_per_epoch=math.ceil(num_train_examples/BATCH_SIZE))
Et voici la conclusion:
Epoch 1/5
1875/1875 [==============================] - 26s 14ms/step - loss: 0.4921 - acc: 0.8267
Epoch 2/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3652 - acc: 0.8686
Epoch 3/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3341 - acc: 0.8782
Epoch 4/5
1875/1875 [==============================] - 19s 10ms/step - loss: 0.3111 - acc: 0.8858
Epoch 5/5
1875/1875 [==============================] - 16s 8ms/step - loss: 0.2911 - acc: 0.8922
Pendant l'apprentissage du modèle, la valeur de la fonction de perte et la métrique de précision sont affichées pour chaque itération d'apprentissage. Ce modèle atteint une précision d'environ 0,88 (88%) sur les données d'entraînement.
Vérifier la précision
Vérifions quelle précision le modèle produit sur les données de test. Nous utiliserons tous les exemples que nous avons dans l'ensemble de données de test pour vérifier la précision.
test_loss, test_accuracy = model.evaluate(test_dataset, steps=math.ceil(num_test_examples/BATCH_SIZE)) print(" : ", test_accuracy)
Conclusion:
313/313 [==============================] - 1s 5ms/step - loss: 0.3440 - acc: 0.8793
: 0.8793
Comme vous pouvez le voir, la précision de l'ensemble de données de test s'est avérée inférieure à la précision de l'ensemble de données d'entraînement. C'est tout à fait normal puisque le modèle a été formé sur les données train_dataset. Lorsqu'un modèle découvre des images qu'il n'a jamais vues auparavant (à partir de l'ensemble de données train_dataset), il est évident que l'efficacité de la classification diminuera.
Prédire et explorer
Nous pouvons utiliser le modèle entraîné pour obtenir des prédictions pour certaines images.
for test_images, test_labels in test_dataset.take(1): test_images = test_images.numpy() test_labels = test_labels.numpy() predictions = model.predict(test_images)
predictions.shape
Conclusion: Dans l'exemple ci-dessus, le modèle a prédit des étiquettes pour chaque image d'entrée de test. Regardons la première prédiction:(32, 10)
predictions[0]
Conclusion: array([3.1365351e-05, 9.0029374e-08, 5.0016739e-03, 6.3597057e-05, 6.8342477e-02, 1.0856857e-08, 9.2655218e-01, 1.8982398e-09, 8.4999456e-06, 1.0296091e-09], dtype=float32)
Rappelez-vous que les prédictions du modèle sont un tableau de 10 valeurs. Ces valeurs décrivent la «confiance» du modèle que l'image d'entrée appartient à une certaine classe (vêtement). Nous pouvons voir la valeur maximale comme suit: np.argmax(predictions[0])
Conclusion: 6
Cela signifie que le modèle était plus confiant que cette image appartient à la classe étiquetée 6 (class_names [6]). Nous pouvons vérifier et nous assurer que le résultat est vrai et correct: test_labels[0]
6
Nous pouvons afficher toutes les images d'entrée et les prévisions de modèle correspondantes pour 10 classes: def plot_image(i, predictions_array, true_labels, images): predictions_array, true_label, img = predictions_array[i], true_label[i], images[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img[...,0], cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100 * np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue')
Jetons un coup d'oeil à la 0ème image, le résultat de la prédiction du modèle et du tableau de prédictions. i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
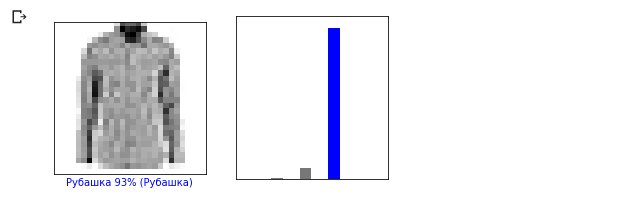
i = 12 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
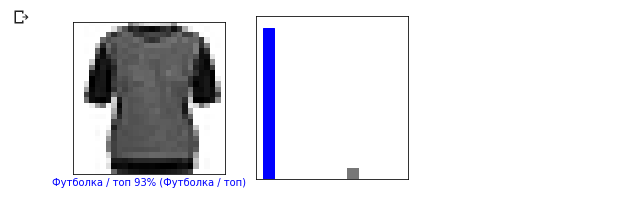 Voyons maintenant quelques images avec leurs prédictions respectives. Les prédictions correctes sont bleues, les prédictions incorrectes sont rouges. La valeur sous l'image reflète le pourcentage de confiance que l'image d'entrée correspond à cette classe. Veuillez noter que le résultat peut être incorrect même si la valeur de «confiance» est élevée.
Voyons maintenant quelques images avec leurs prédictions respectives. Les prédictions correctes sont bleues, les prédictions incorrectes sont rouges. La valeur sous l'image reflète le pourcentage de confiance que l'image d'entrée correspond à cette classe. Veuillez noter que le résultat peut être incorrect même si la valeur de «confiance» est élevée. num_rows = 5 num_cols = 3 num_images = num_rows * num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i + 1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i + 2) plot_value_array(i, predictions, test_labels)
 Utilisez le modèle formé pour prédire l'étiquette d'une seule image:
Utilisez le modèle formé pour prédire l'étiquette d'une seule image: img = test_images[0] print(img.shape)
Conclusion: (28, 28, 1)
Les modèles sont tf.kerasoptimisés pour les prédictions par blocs (collections). Par conséquent, malgré le fait que nous utilisons un seul élément, vous devez l'ajouter à la liste: img = np.array([img]) print(img.shape)
Conclusion:(1, 28, 28, 1)Maintenant, nous allons prédire le résultat: predictions_single = model.predict(img) print(predictions_single)
Conclusion: [[3.1365438e-05 9.0029722e-08 5.0016833e-03 6.3597123e-05 6.8342514e-02 1.0856857e-08 9.2655218e-01 1.8982469e-09 8.4999692e-06 1.0296091e-09]]
plot_value_array(0, predictions_single, test_labels) _ = plt.xticks(range(10), class_names, rotation=45)
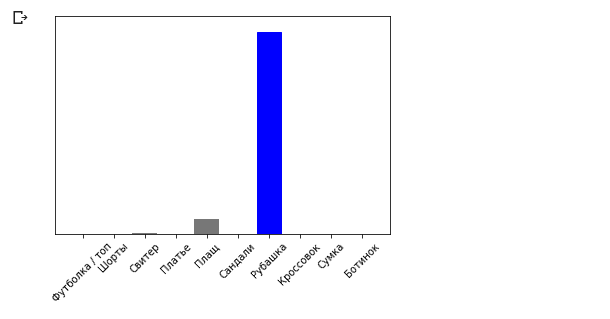 La méthode model.predict renvoie une liste de listes (un tableau de tableaux), chacune pour une image d'un bloc d'entrée. Nous obtenons le seul résultat pour notre image d'entrée unique:
La méthode model.predict renvoie une liste de listes (un tableau de tableaux), chacune pour une image d'un bloc d'entrée. Nous obtenons le seul résultat pour notre image d'entrée unique: np.argmax(predictions_single[0])
Conclusion: 6
Comme précédemment, le modèle prédit l'étiquette 6 (chemise).Exercices
Expérimentez avec différents modèles et voyez comment la précision changera. En particulier, essayez de modifier les paramètres suivants:- définissez le paramètre epochs sur 1;
- changer le nombre de neurones dans la couche cachée, par exemple, d'une valeur faible de 10 à 512 et voir comment la précision du modèle de prévision va changer;
- ajouter des couches supplémentaires entre la couche aplatie (couche de lissage) et la couche dense finale, expérimentez le nombre de neurones sur cette couche;
- ne normalisez pas les valeurs des pixels et ne voyez pas ce qui se passe.
N'oubliez pas d'activer le GPU pour que tous les calculs soient plus rapides ( Runtime -> Change runtime type -> Hardware accelertor -> GPU). De plus, si vous rencontrez des problèmes pendant l'opération, essayez de réinitialiser les paramètres d'environnement global:Edit -> Clear all outputsRuntime -> Reset all runtimes
Degrés Celsius VS MNIST
- A ce stade, nous avons déjà rencontré deux types de réseaux de neurones. Notre premier réseau neuronal a appris à convertir les degrés Celsius en degrés Frenheit, en renvoyant une valeur unique qui peut être dans une large gamme de valeurs numériques.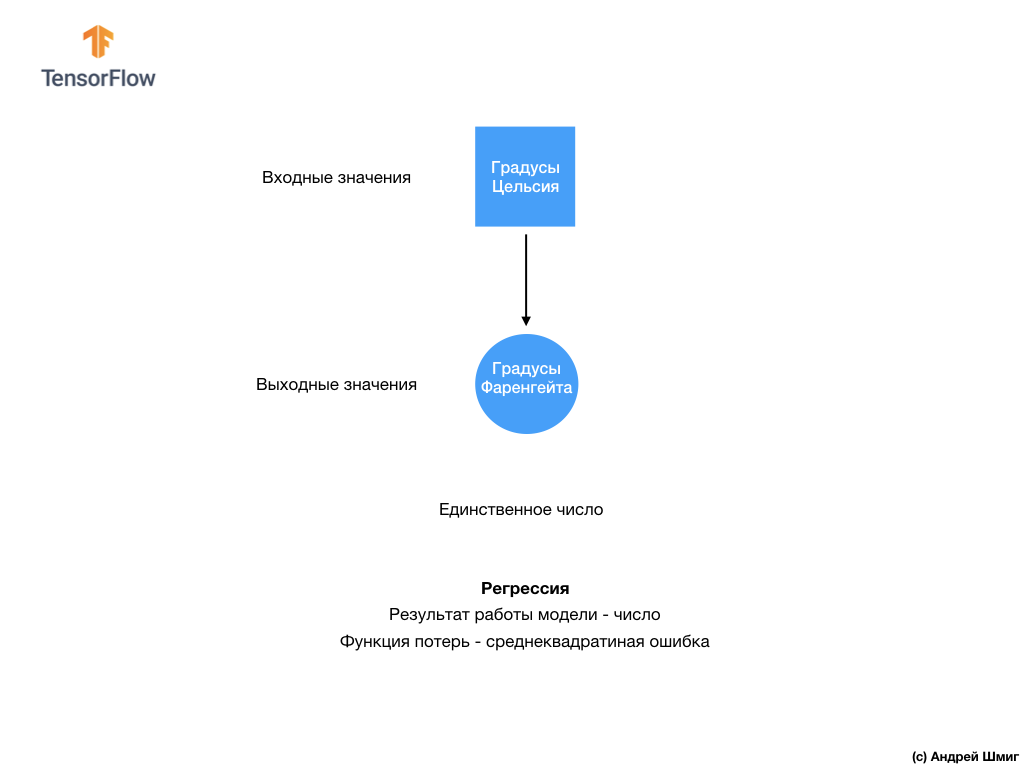 Notre deuxième réseau de neurones renvoie 10 valeurs de probabilité qui reflètent la confiance du réseau que l'image d'entrée correspond à une certaine classe.Les réseaux de neurones peuvent être utilisés pour résoudre divers problèmes.
Notre deuxième réseau de neurones renvoie 10 valeurs de probabilité qui reflètent la confiance du réseau que l'image d'entrée correspond à une certaine classe.Les réseaux de neurones peuvent être utilisés pour résoudre divers problèmes.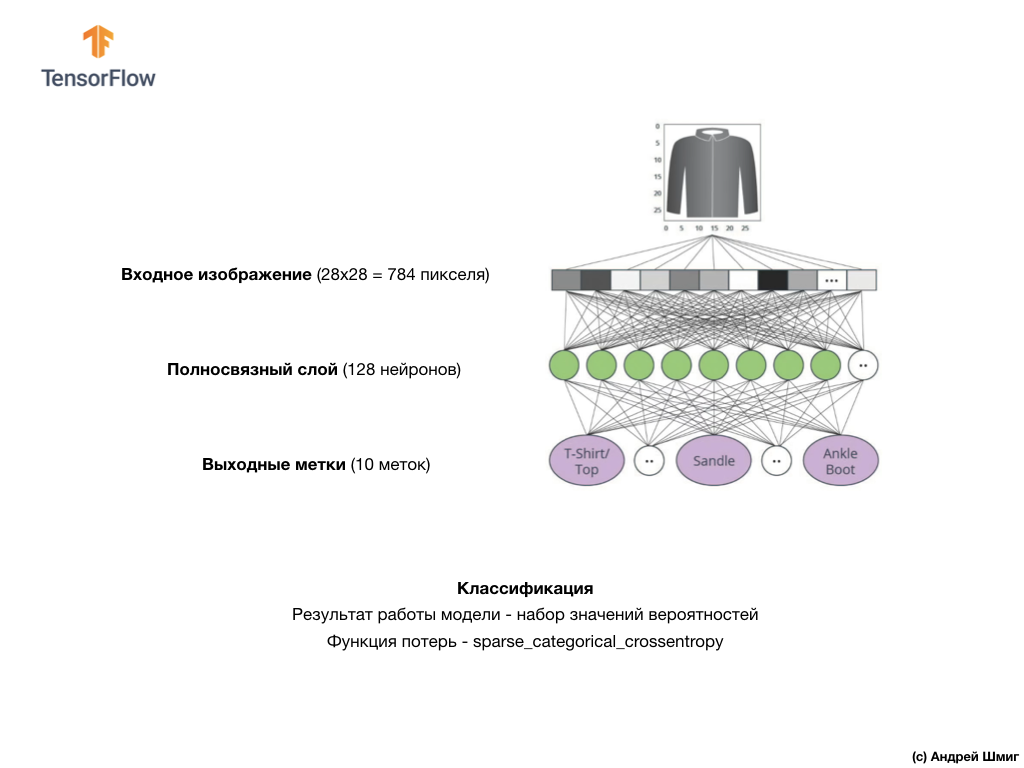 La première classe de problèmes que nous avons résolus avec la prédiction d'une valeur unique est appelée régression. La conversion des degrés Celsius en degrés Fahrenheit est un exemple de la tâche de cette classe. Un autre exemple de cette classe de tâches peut être la tâche de déterminer la valeur d'une maison en fonction du nombre de pièces, de la superficie totale, de l'emplacement et d'autres caractéristiques.La deuxième classe de tâches que nous avons examinées dans cette leçon classant les images en catégories disponibles est appelée classification . Selon les données d'entrée, le modèle renverra la distribution de probabilité (la «confiance» du modèle que la valeur d'entrée appartient à cette classe). Dans cette leçon, nous avons développé un réseau de neurones qui classait les éléments vestimentaires en 10 catégories, et dans la leçon suivante, nous apprendrons à déterminer qui est montré sur la photo - un chien ou un chat, cette tâche appartient également à la tâche de classification.Résumons et notons la différence entre ces deux classes de problèmes - régression et classification .
La première classe de problèmes que nous avons résolus avec la prédiction d'une valeur unique est appelée régression. La conversion des degrés Celsius en degrés Fahrenheit est un exemple de la tâche de cette classe. Un autre exemple de cette classe de tâches peut être la tâche de déterminer la valeur d'une maison en fonction du nombre de pièces, de la superficie totale, de l'emplacement et d'autres caractéristiques.La deuxième classe de tâches que nous avons examinées dans cette leçon classant les images en catégories disponibles est appelée classification . Selon les données d'entrée, le modèle renverra la distribution de probabilité (la «confiance» du modèle que la valeur d'entrée appartient à cette classe). Dans cette leçon, nous avons développé un réseau de neurones qui classait les éléments vestimentaires en 10 catégories, et dans la leçon suivante, nous apprendrons à déterminer qui est montré sur la photo - un chien ou un chat, cette tâche appartient également à la tâche de classification.Résumons et notons la différence entre ces deux classes de problèmes - régression et classification .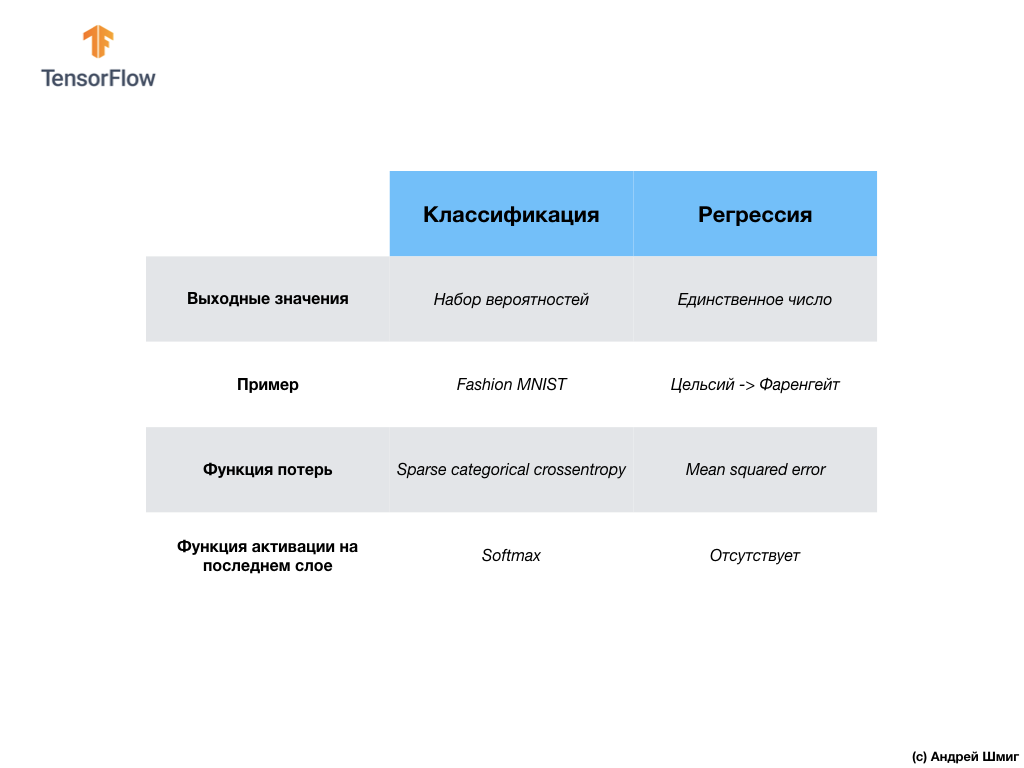 Félicitations, vous avez étudié deux types de réseaux de neurones! Préparez-vous pour la prochaine conférence, nous y étudierons un nouveau type de réseaux de neurones - les réseaux de neurones convolutifs (CNN).
Félicitations, vous avez étudié deux types de réseaux de neurones! Préparez-vous pour la prochaine conférence, nous y étudierons un nouveau type de réseaux de neurones - les réseaux de neurones convolutifs (CNN).Résumé
Dans cette leçon, nous avons formé le réseau neuronal à classer les images avec des éléments de vêtements. Pour ce faire, nous avons utilisé l'ensemble de données Fashion MNIST, qui contient 70 000 images d'articles vestimentaires. 60 000 dont nous avons utilisé pour former le réseau de neurones, et les 10 000 restants pour tester l'efficacité de son travail. Afin de soumettre ces images à l'entrée de notre réseau neuronal, nous devions les convertir (lisser) du format 2D 28x28 au format 1D de 784 éléments. Notre réseau était composé d'une couche entièrement connectée de 128 neurones et d'une couche de sortie de 10 neurones, correspondant au nombre d'étiquettes (classes, catégories d'articles vestimentaires). Ces 10 valeurs de sortie représentaient la distribution de probabilité pour chaque classe. Fonction d' activation Softmaxcompté la distribution de probabilité.Nous avons également appris les différences entre la régression et la classification .- Régression : modèle qui renvoie une valeur unique, telle que la valeur d'une maison.
- Classification : un modèle qui renvoie la distribution de probabilité entre plusieurs catégories. Par exemple, dans notre tâche avec Fashion MNIST, les valeurs de sortie étaient 10 valeurs de probabilité, dont chacune était associée à une classe particulière (catégorie de vêtements). Je vous rappelle que nous avons utilisé la fonction d'activation softmax juste pour obtenir une distribution de probabilité sur la dernière couche.
Version vidéo de l'articleLa vidéo sort quelques jours après sa publication et est ajoutée à l'article.
... et appel à l'action standard - inscrivez-vous, mettez un plus et partagez :)
YouTubeTélégrammeVKontakte