
Il y a quelque temps, une histoire désagréable m'est arrivée, qui a servi de déclencheur à un petit projet sur le github et a abouti à cet article.
Une journée typique, une sortie régulière: toutes les tâches sont contrôlées de haut en bas par notre ingénieur QA, donc avec le calme de la vache sacrée nous «roulons» sur la scène. L'application se comporte bien, dans les journaux - silence. On décide de faire du switch (stage <-> prod). Nous changeons, regardons les appareils ...
Cela prend quelques minutes, le vol est stable. L'ingénieur QA fait un test de fumée, remarque que l'application ralentit d'une manière ou d'une autre anormalement. Nous radions pour réchauffer les caches.
Quelques minutes s'écoulent, première plainte de la première ligne: les données sont téléchargées depuis très longtemps des clients, l'application ralentit, il faut beaucoup de temps pour répondre, etc. On commence à s'inquiéter ... on regarde les logs, on cherche les raisons possibles.
Quelques minutes plus tard, une lettre arrive des administrateurs de la DB. Ils écrivent que le temps d'exécution des requêtes vers la base de données (ci-après dénommée la base de données) a franchi toutes les limites possibles et tend vers l'infini.
J'ouvre la surveillance (j'utilise
JavaMelody ), je trouve ces requêtes. Je lance PGAdmin, je reproduis. Vraiment long. J'ajoute "expliquer", je regarde le plan d'exécution ... ça l'est, on a oublié les index.
Pourquoi la révision du code ne suffit-elle pas?
Cet incident m'a beaucoup appris. Oui, j'ai «éteint le feu» pendant une heure, créant en quelque sorte le bon index directement sur la prod (n'oubliez pas l'option CONCURRENTLY):
CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_pets_name ON pets_table (name_column);
D'accord, cela équivalait à un déploiement avec des temps d'arrêt. Pour l'application sur laquelle je travaille, c'est inacceptable.
J'ai fait des conclusions et ajouté un point gras spécial à la liste de contrôle pour la révision du code: si je vois que pendant le processus de développement une des classes de référentiel a été ajoutée / modifiée - je vérifie les migrations sql pour la présence d'un script qui crée et modifie l'index là. S'il n'est pas là, j'écris à l'auteur une question: est-il sûr que l'index n'est pas nécessaire ici?
Il est probable qu'un index ne soit pas nécessaire s'il y a peu de données, mais si nous travaillons avec une table dans laquelle le nombre de lignes est compté en millions, une erreur d'index peut devenir fatale et conduire à l'histoire présentée au début de l'article.
Dans ce cas, je demande à l'auteur de la pull request (ci-après PR) d'être sûr à 100% que la requête qu'il a écrite en HQL est au moins partiellement couverte par l'index (Index Scan est utilisé). Pour cela, le développeur:
- lance l'application
- recherche d'une requête convertie (HQL -> SQL) dans les journaux
- ouvre PGAdmin ou un autre outil d'administration de base de données
- génère dans la base de données locale, afin de ne déranger personne avec ses expériences, une quantité de données acceptables pour les tests (minimum 10K - 20K enregistrements)
- répond à la demande
- demande un plan d'exécution
- l'étudie attentivement et tire des conclusions appropriées
- ajoute / modifie l'index, s'assurant que le plan d'exécution lui convient
- se désabonne dans PR que la couverture de la demande a vérifiée
- évaluer de manière experte les risques et la gravité de la demande, je peux revérifier ses actions
Beaucoup d'actions de routine et le facteur humain, mais pendant un certain temps j'étais satisfait et j'ai vécu avec ça.
Sur le chemin du retour
Ils disent qu'il est très utile au moins parfois d'aller du travail sans écouter de la musique / des podcasts en cours de route. En ce moment, rien qu'en pensant à la vie, vous pouvez arriver à des conclusions et des idées intéressantes.
Un jour, je suis rentré chez moi et j'ai réfléchi à ce qui s'était passé ce jour-là. Il y a eu quelques critiques, j'ai vérifié chacune avec une liste de contrôle et j'ai fait une série d'actions décrites ci-dessus. Je me suis tellement fatigué cette fois-là, je me suis dit, qu'est-ce que c'est? Est-il impossible de le faire automatiquement? .. J'ai fait un pas rapide, voulant «couper» rapidement cette idée.
Énoncé du problème
Qu'est-ce qui est le plus important pour le développeur dans le plan d'exécution?
Bien sûr, seq scan sur de grandes quantités de données causées par l'absence d'index.
Ainsi, il était nécessaire de faire un test qui:
- Réalisé sur une base de données avec une configuration similaire à la prod
- Intercepte une requête de base de données effectuée par un référentiel JPA (Hibernate)
- Obtient un plan d'exécution
- Analyser le plan d'exécution, le disposer dans une structure de données pratique pour les vérifications
- À l'aide d'un ensemble pratique de méthodes Assert, vérifie les attentes. Par exemple, ce scan seq n'est pas utilisé.
Il a fallu tester rapidement cette hypothèse en réalisant un prototype.
Architecture de la solution
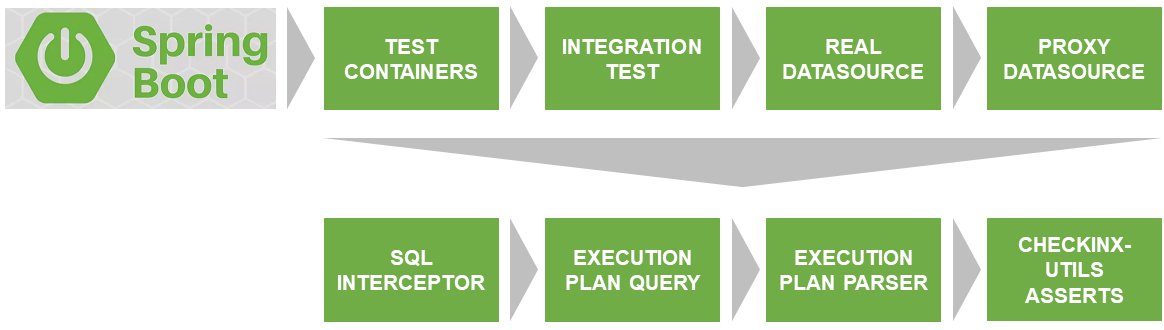
Le premier problème qui devait être résolu était le lancement du test sur une vraie base de données qui correspond à la version et aux paramètres avec ceux utilisés sur le prod.
Grâce à
Docker & TestContainers , ils résolvent ce problème.
SqlInterceptor, ExecutionPlanQuery, ExecutionPlanParse et AssertService sont les interfaces que j'ai actuellement implémentées pour Postgres. Les plans sont à mettre en œuvre pour d'autres bases de données. Si vous souhaitez participer - bienvenue. Le code est écrit en Kotlin.
Tout cela ensemble, j'ai posté sur GitHub et appelé
checkinx-utils . Vous n'avez pas besoin de répéter cela, connectez simplement la dépendance à checkinx dans maven / gradle et utilisez des assertions pratiques. Comment faire cela, je décrirai plus en détail ci-dessous.
Description de l'interaction des composants CheckInx
ProxyDataSource
Le premier problème à résoudre était l'interception des requêtes de base de données prêtes à être exécutées. Déjà avec les paramètres établis, sans questions, etc.
Pour ce faire, la véritable source de données doit être enveloppée dans un certain proxy, ce qui lui permettrait d'être intégré dans le pipeline d'exécution des requêtes et, en conséquence, de les intercepter.
Un tel ProxyDataSource a déjà été implémenté par beaucoup. J'ai utilisé la solution
ttddyy prête à l'emploi, qui me permet d'installer mon écouteur interceptant la demande dont j'ai besoin.
Je remplace le DataSource source à l'aide de la classe DataSourceWrapper (BeanPostProcessor).
SqlInterceptor
En fait, sa méthode start () définit son écouteur dans proxyDataSource et commence à intercepter les requêtes, en les stockant dans la liste des instructions internes. La méthode stop (), respectivement, supprime l'écouteur installé.
ExecutionPlanQuery
Ici, la demande d'origine est transformée en demande de plan d'exécution. Dans le cas de Postgres, il s'agit d'un ajout au mot clé de requête "EXPLAIN".
De plus, cette requête est exécutée sur la même base de données à partir de testcontainders et un plan d'exécution «brut» (liste de lignes) est retourné.
ExecutionPlanParser
Il n'est pas pratique de travailler avec un plan d'exécution brut. Par conséquent, je l'analyser dans un arbre composé de nœuds (PlanNode).
Analysons les champs PlanNode à l'aide d'un exemple d'un véritable ExecutionPlan:
Index Scan using ix_pets_age on pets (cost=0.29..8.77 rows=1 width=36) Index Cond: (age < 10) Filter: ((name)::text = 'Jack'::text)
AssertService
Il est déjà possible de travailler normalement avec la structure de données renvoyée par l'analyseur. CheckInxAssertService est un ensemble de vérifications de l'arborescence PlanNode décrite ci-dessus. Il vous permet de définir vos propres lambdas de chèques ou d'utiliser les prédéfinis, à mon avis, les plus populaires. Par exemple, pour que votre requête ne dispose pas de Seq Scan, ou si vous souhaitez vous assurer qu'un index spécifique est utilisé / non utilisé.
Niveau de couverture
Enum très important, je vais le décrire séparément:
Ensuite, nous allons examiner quelques exemples d'utilisation.
Exemples de tests utilisant CheckInx
J'ai fait un projet distinct sur GitHub
checkinx-demo , où j'ai implémenté un référentiel JPA pour la table pets et des tests pour ce référentiel en vérifiant la couverture, les index, etc. Il sera utile de s'y référer comme point de départ.
Vous pourriez avoir un test comme celui-ci:
@Test fun testFindByLocation() {
Le plan de mise en œuvre pourrait être le suivant:
Index Scan using ix_pets_location on pets pet0_ (cost=0.29..4.30 rows=1 width=46) Index Cond: ((location)::text = 'Moscow'::text)
... ou comme ça si on oublie l'index (les tests deviennent rouges):
Seq Scan on pets pet0_ (cost=0.00..19.00 rows=4 width=84) Filter: ((location)::text = 'Moscow'::text)
Dans mon projet, j'utilise principalement l'assertion la plus simple, qui dit qu'il n'y a pas de Seq Scan dans le plan d'exécution:
checkInxAssertService.assertCoverage(CoverageLevel.HALF, sqlInterceptor.statements[0])
La présence d'un tel test suggère que j'ai au moins étudié le plan de mise en œuvre.
Cela rend également la gestion de projet plus explicite, et la documentabilité et la prévisibilité du code augmentent.
Mode expérimentéJe recommande d'utiliser CheckInxAssertService, mais si nécessaire, vous pouvez contourner vous-même l'arborescence analysée (ExecutionPlanParser) ou, en général, analyser le plan d'exécution brut (le résultat de l'exécution d'ExecutionPlanQuery).
@Test fun testFindByLocation() {
Connexion au projet
Dans mon projet, j'ai alloué ces tests à un groupe distinct, ce que j'ai appelé des tests d'intégration intensive.
Se connecter et commencer à utiliser checkinx-utils est assez simple. Commençons par le script de construction.
Connectez d'abord le référentiel. Un jour, je téléchargerai checkinx sur maven, mais maintenant vous ne pouvez télécharger d'artefact que depuis GitHub via jitpack.
repositories { // ... maven { url 'https://jitpack.io' } }
Ensuite, ajoutez la dépendance:
dependencies { // ... implementation 'com.github.tinkoffcreditsystems:checkinx-utils:0.2.0' }
Nous terminons la connexion en ajoutant la configuration. Seul Postgres est actuellement pris en charge.
@Profile("test") @ImportAutoConfiguration(classes = [PostgresConfig::class]) @Configuration open class CheckInxConfig
Faites attention au profil de test. Sinon, vous trouverez ProxyDataSource dans votre prod.
PostgresConfig connecte plusieurs beans:
- DataSourceWrapper
- PostgresInterceptor
- PostgresExecutionPlanParser
- PostgresExecutionPlanQuery
- CheckInxAssertServiceImpl
Si vous avez besoin d'une sorte de personnalisation que l'API actuelle ne fournit pas, vous pouvez toujours remplacer l'un des beans par votre implémentation.
Problèmes connus
Parfois, un DataSourceWrapper ne parvient pas à remplacer le dataSource d'origine en raison du proxy Spring CGLIB. Dans ce cas, pas un DataSource ne vient à BeanPostProcessor, mais ScopedProxyFactoryBean et il y a des problèmes avec la vérification de type.
La solution la plus simple serait de créer manuellement HikariDataSource pour les tests. Ensuite, votre configuration sera la suivante:
@Profile("test") @ImportAutoConfiguration(classes = [PostgresConfig::class]) @Configuration open class CheckInxConfig { @Primary @Bean @ConfigurationProperties("spring.datasource") open fun dataSource(): DataSource { return DataSourceBuilder.create() .type(HikariDataSource::class.<i>java</i>) .build() } @Bean @ConfigurationProperties("spring.datasource.configuration") open fun dataSource(properties: DataSourceProperties): HikariDataSource { return properties.initializeDataSourceBuilder() .type(HikariDataSource::class.<i>java</i>) .build() } }
Plans de développement
- J'aimerais comprendre si quelqu'un d'autre que moi en a besoin? Pour ce faire, créez une enquête. Je serai heureux de répondre honnêtement.
- Voyez ce dont vous avez vraiment besoin et développez la liste standard des méthodes d'assertion.
- Écrire des implémentations pour d'autres bases de données.
- La construction de sqlInterceptor.statements [0] ne semble pas très évidente, je veux l'améliorer.
Je serais ravi si quelqu'un veut se joindre à nous et gagner du crédit en pratiquant à Kotlin.
Conclusion
Je suis sûr qu'il y aura des commentaires:
il est impossible de prédire comment le planificateur de requêtes se comportera sur le prod, tout dépend des statistiques collectées .
En effet, un planificateur. En utilisant les statistiques collectées précédemment, il peut construire un plan différent de celui testé. Le sens est un peu différent.
La tâche du planificateur est d'améliorer et non d'aggraver la demande. Par conséquent, sans raison apparente, il n'utilisera pas soudainement Seq Scan, mais vous pouvez le faire sans le savoir.
Vous avez besoin de CheckInx pour que lors de l'écriture d'un test, n'oubliez pas d'étudier le plan d'exécution des requêtes et d'envisager la possibilité de créer un index, ou vice versa, montrez clairement avec un test qu'aucun index n'est nécessaire ici et que vous êtes satisfait de Seq Scan. Cela vous éviterait des questions inutiles sur la révision du code.
Les références
- https://github.com/TinkoffCreditSystems/checkinx-utils
- https://github.com/dsemyriazhko/checkinx-demo
- https://github.com/ttddyy/datasource-proxy
- https://mvnrepository.com/artifact/org.testcontainers/postgresql
- https://github.com/javamelody/javamelody/wiki