Bonjour à tous. Je m'appelle Danila, je travaille dans une équipe qui développe une infrastructure analytique à Avito. Les tests A / B sont au cœur de cette infrastructure.
Les expériences A / B sont un outil décisionnel clé dans Avito. Dans notre cycle de développement de produits, un test A / B est indispensable. Nous testons chaque hypothèse et déployons uniquement des changements positifs.
Nous collectons des centaines de métriques et sommes en mesure de les explorer jusqu'aux sections commerciales: verticales, régions, utilisateurs autorisés, etc. Nous le faisons automatiquement en utilisant une seule plate-forme pour les expériences. Dans l'article, je vais vous expliquer en détail comment la plateforme est organisée et nous allons plonger dans quelques détails techniques intéressants.

Les principales fonctions de la plateforme A / B sont formulées comme suit.
- Vous aide à exécuter rapidement des expériences
- Contrôle les intersections d'expériences indésirables
- Compte les métriques, stat. teste, visualise les résultats
En d'autres termes, la plateforme permet de prendre des décisions sans erreur plus rapidement.
Si nous omettons le processus de développement des fonctionnalités qui sont envoyées pour les tests, le cycle complet de l'expérience ressemble à ceci:

- Le client (analyste ou chef de produit) configure les paramètres de l'expérience via le panneau d'administration.
- Le service divisé, en fonction de ces paramètres, distribue le groupe A / B nécessaire à l'appareil client.
- Les actions des utilisateurs sont collectées dans des journaux bruts qui passent par l'agrégation et se transforment en métriques.
- Les métriques sont exécutées à travers des tests statistiques.
- Les résultats sont visualisés sur le portail interne le lendemain du lancement.
Tout le transport de données dans un cycle prend une journée. En règle générale, les expériences durent une semaine, mais le client reçoit chaque jour un incrément de résultats.
Plongeons-nous maintenant dans les détails.
Gestion des expériences
Le panneau d'administration utilise le format YAML pour configurer les expériences.

C'est une solution pratique pour une petite équipe: finaliser les capacités de la configuration se fait sans front. L'utilisation de configurations de texte simplifie le travail de l'utilisateur: vous devez effectuer moins de clics avec la souris. Une solution similaire est utilisée par le framework Airbnb A / B.
Pour diviser le trafic en groupes, nous utilisons la technique courante de hachage du sel.
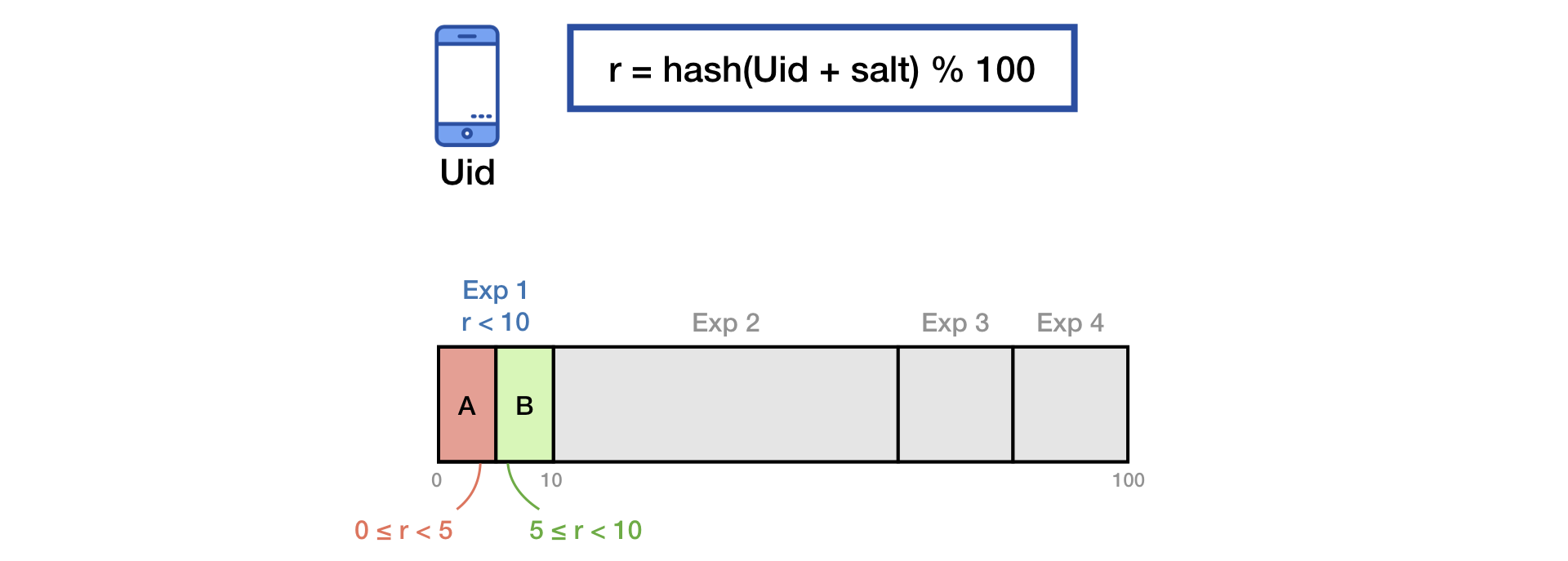
Pour éliminer l'effet de "mémoire" des utilisateurs, lors du démarrage d'une nouvelle expérience, nous effectuons un mélange supplémentaire avec le second sel:

Le même principe est décrit dans la présentation de Yandex .
Afin d'éviter les intersections potentiellement dangereuses d'expériences, nous utilisons une logique similaire aux «couches» dans Google .
Collection de métriques
Nous plaçons les journaux bruts dans Vertica et les agrégons dans des tableaux de préparation avec la structure:

Les observations sont généralement de simples compteurs d'événements. Les observations sont utilisées comme composants dans la formule de calcul métrique.
La formule de calcul de toute métrique est une fraction, au numérateur et au dénominateur, qui est la somme des observations:
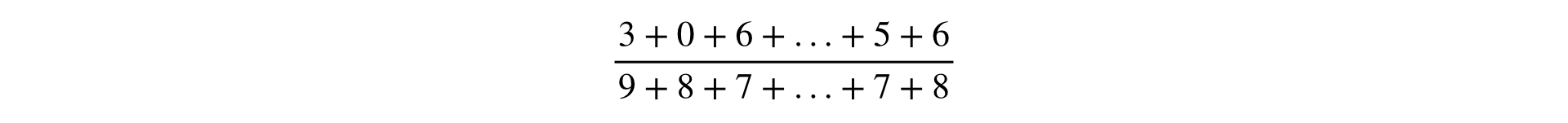
Dans l'un des rapports de Yandex, les mesures étaient divisées en deux types: par utilisateurs et par rapport. Cela a un sens commercial, mais dans l'infrastructure, il est plus pratique de considérer toutes les mesures de la même manière que Ratio. Cette généralisation est valable, car la métrique "posyuzerny" est évidemment représentable comme une fraction:
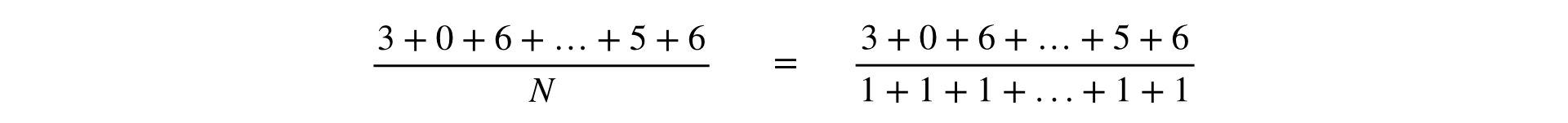
Nous résumons les observations au numérateur et au dénominateur de la métrique de deux manières.
Simple:
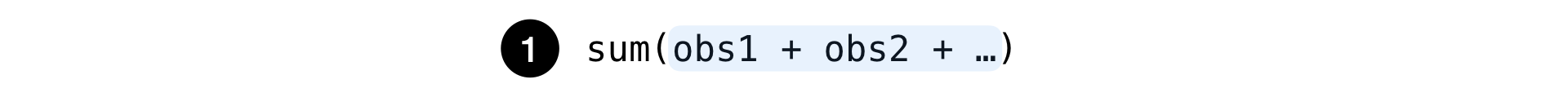
C'est le montant habituel de tout ensemble d'observations: le nombre de recherches, les clics sur les publicités, etc.
Et plus compliqué:

Un nombre unique de clés, dans le groupe par lequel le total des observations est supérieur à un seuil donné.
Ces formules sont facilement définies à l'aide de la configuration YAML:

Les paramètres groupby et seuil sont facultatifs. Ils déterminent simplement la deuxième méthode de sommation.
Les normes décrites vous permettent de configurer presque toutes les mesures en ligne auxquelles vous pouvez penser. En même temps, une logique simple est préservée qui n'impose pas une charge excessive à l'infrastructure.
Critère statistique
Nous mesurons l'importance des écarts par des métriques en utilisant les méthodes classiques: test T , test U de Mann-Whitney . La principale condition nécessaire à l'application de ces critères est que les observations de l'échantillon ne doivent pas dépendre les unes des autres. Dans presque toutes nos expériences, nous pensons que les utilisateurs (Uid) remplissent cette condition.

Maintenant, la question se pose: comment effectuer le test T et le test MW pour les métriques Ratio? Pour le test T, vous devez être en mesure de lire la variance de l'échantillon, et pour MW, l'échantillon doit être «défini par l'utilisateur».
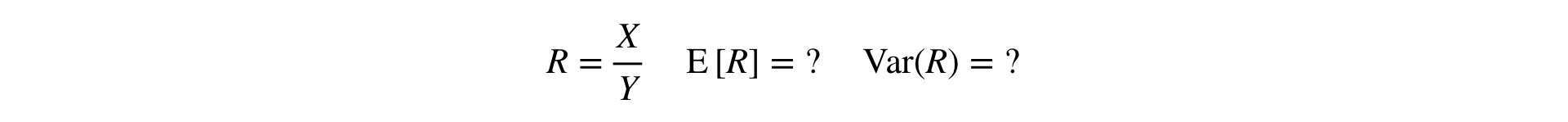
Réponse: vous devez étendre le rapport d'une série Taylor au premier ordre à un moment donné :
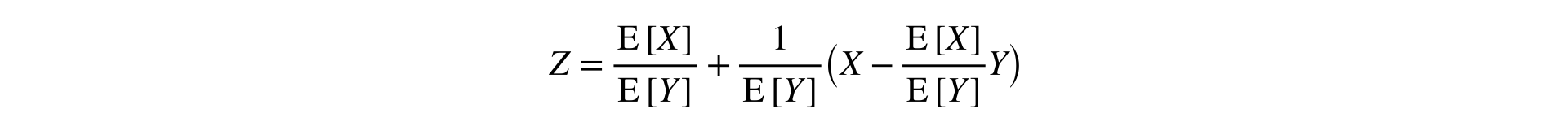
Cette formule convertit deux échantillons (numérateur et dénominateur) en un seul, en préservant la moyenne et la variance (asymptotiquement), ce qui permet d'utiliser des statistiques classiques. tests.
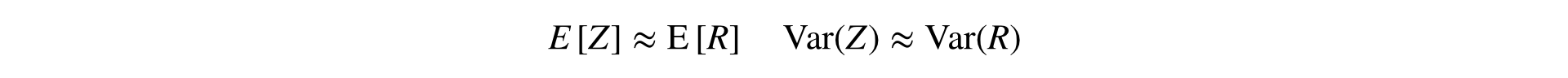
Une idée similaire est appelée par les collègues de Yandex la méthode de linéarisation Ratio (apparitions uniques et doubles ).
Mise à l'échelle des performances
Utilisation rapide pour les statistiques du processeur. critères permet de réaliser des millions d'itérations (comparaisons traitement vs contrôle) en quelques minutes sur un serveur tout à fait ordinaire à 56 cœurs. Mais dans le cas de gros volumes de données, les performances reposent tout d'abord sur le stockage et le temps de lecture à partir du disque.
Le calcul des métriques Uid génère quotidiennement des échantillons d'une taille totale de centaines de milliards de valeurs (en raison du grand nombre d'expériences simultanées, de centaines de métriques et d'une accumulation cumulée). Il est trop problématique d'extraire de tels volumes du disque tous les jours (malgré le grand cluster de la base de colonne Vertica). Par conséquent, nous sommes obligés de réduire la cardinalité des données. Mais nous le faisons presque sans perte d'informations sur la variance en utilisant une technique appelée «Bucket».
L'idée est simple: on hache les Uid et, selon le reste de la division, on les "disperse" en plusieurs seaux (on note leur nombre par B):
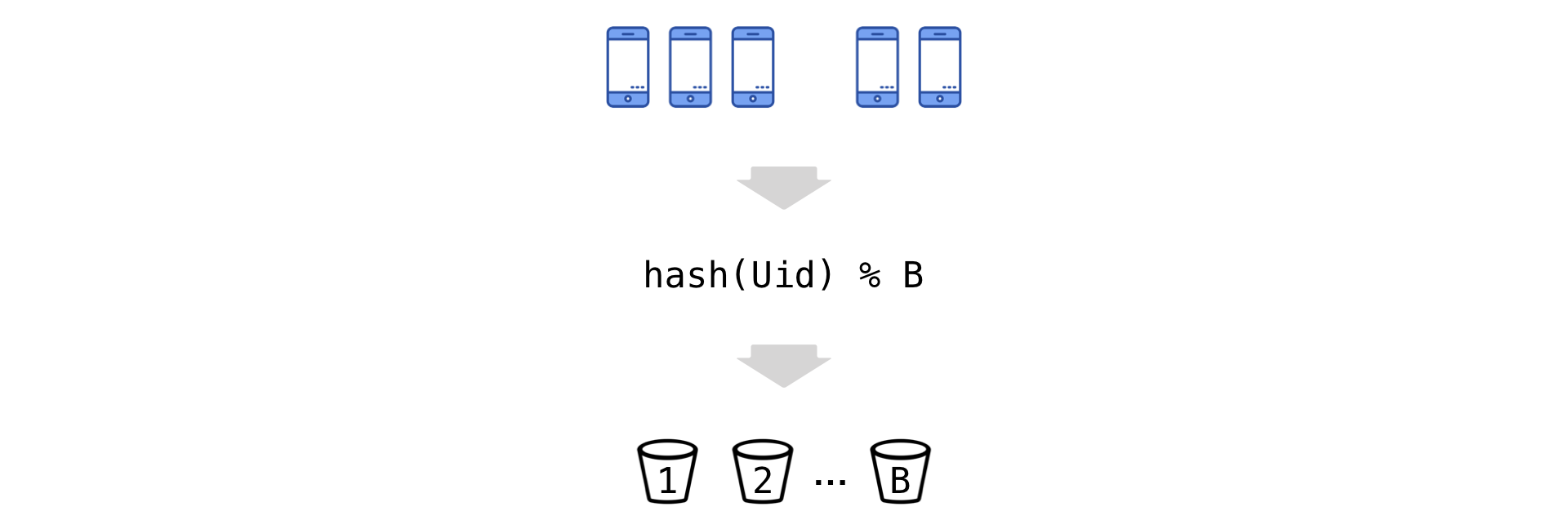
Nous passons maintenant à la nouvelle unité expérimentale - le seau. Nous résumons les observations dans le seau (le numérateur et le dénominateur sont indépendants):

Avec cette transformation, la condition d'indépendance des observations est remplie, la valeur métrique ne change pas et il est facile de vérifier que la variance de la métrique (moyenne sur l'échantillon d'observations) est préservée:

Plus il y a de bucket, moins les informations sont perdues et plus l'erreur d'égalité est petite. Dans Avito, nous prenons B = 200.
La densité de distribution métrique après la conversion du compartiment devient toujours similaire à la normale.
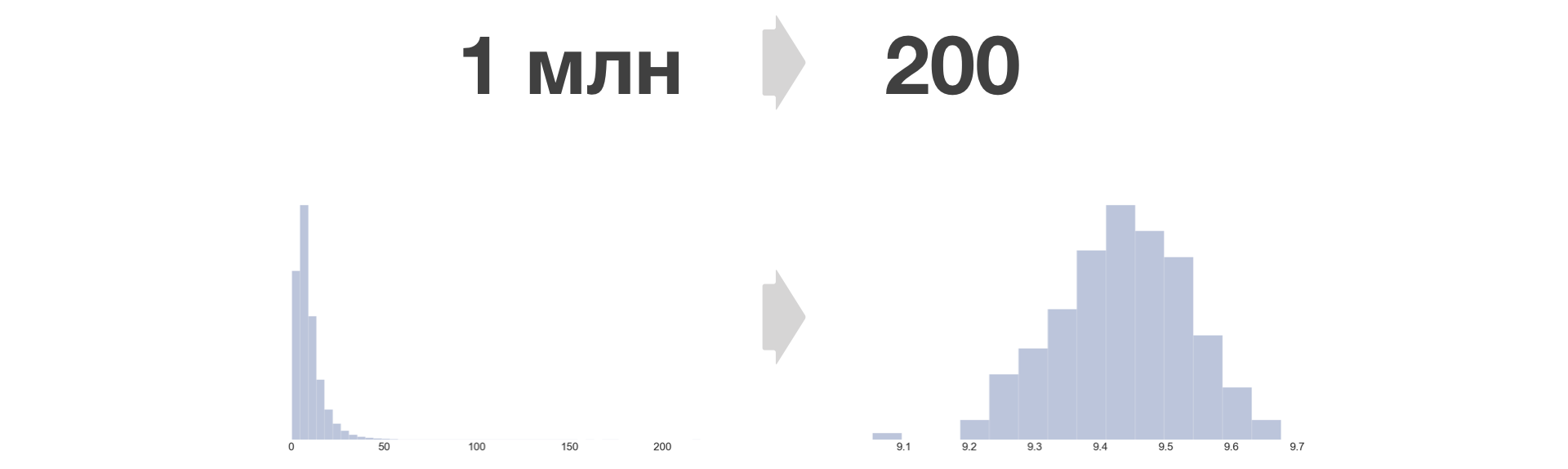
Autant de grands échantillons que vous le souhaitez peuvent être réduits à une taille fixe. La croissance de la quantité de données stockées dans ce cas ne dépend que linéairement du nombre d'expériences et de métriques.
Visualisation des résultats
En tant qu'outil de visualisation, nous utilisons Tableau et la vue Web sur Tableau Server. Chaque employé Avito y a accès. Il convient de noter que Tableau fait bien le travail. Mettre en œuvre une solution similaire en utilisant un développement arrière / frontal complet serait une tâche beaucoup plus gourmande en ressources.
Les résultats de chaque expérience sont une feuille de plusieurs milliers de nombres. La visualisation doit être de nature à minimiser les conclusions incorrectes dans le cas de la mise en œuvre d' erreurs du premier et du deuxième type , et en même temps à ne pas «manquer» les changements dans les métriques et sections importantes.
Tout d'abord, nous surveillons les mesures de «santé» des expériences. Autrement dit, nous répondons aux questions: "Est-il vrai que les participants ont été" déversés "dans chacun des groupes?", "Est-ce égal aux utilisateurs autorisés ou nouveaux?"
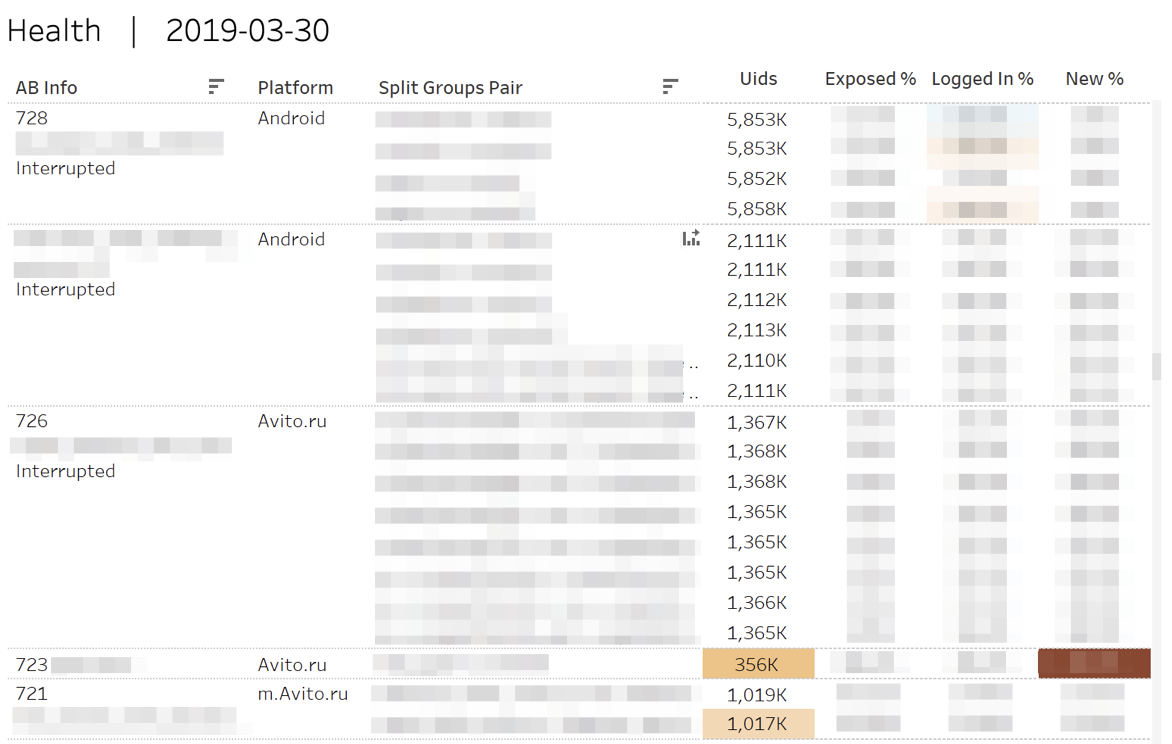
En cas d'écarts statistiquement significatifs, les cellules correspondantes sont mises en évidence. Lorsque vous survolez un nombre quelconque, la dynamique cumulée de la journée s'affiche.
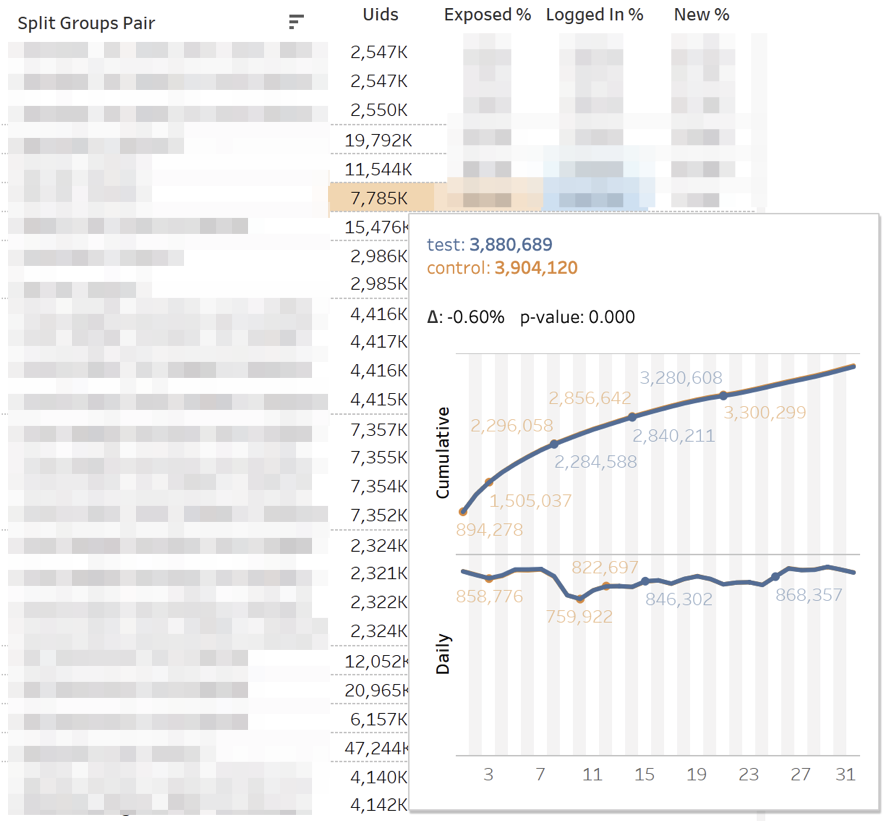
Le tableau de bord principal avec des mesures ressemble à ceci:
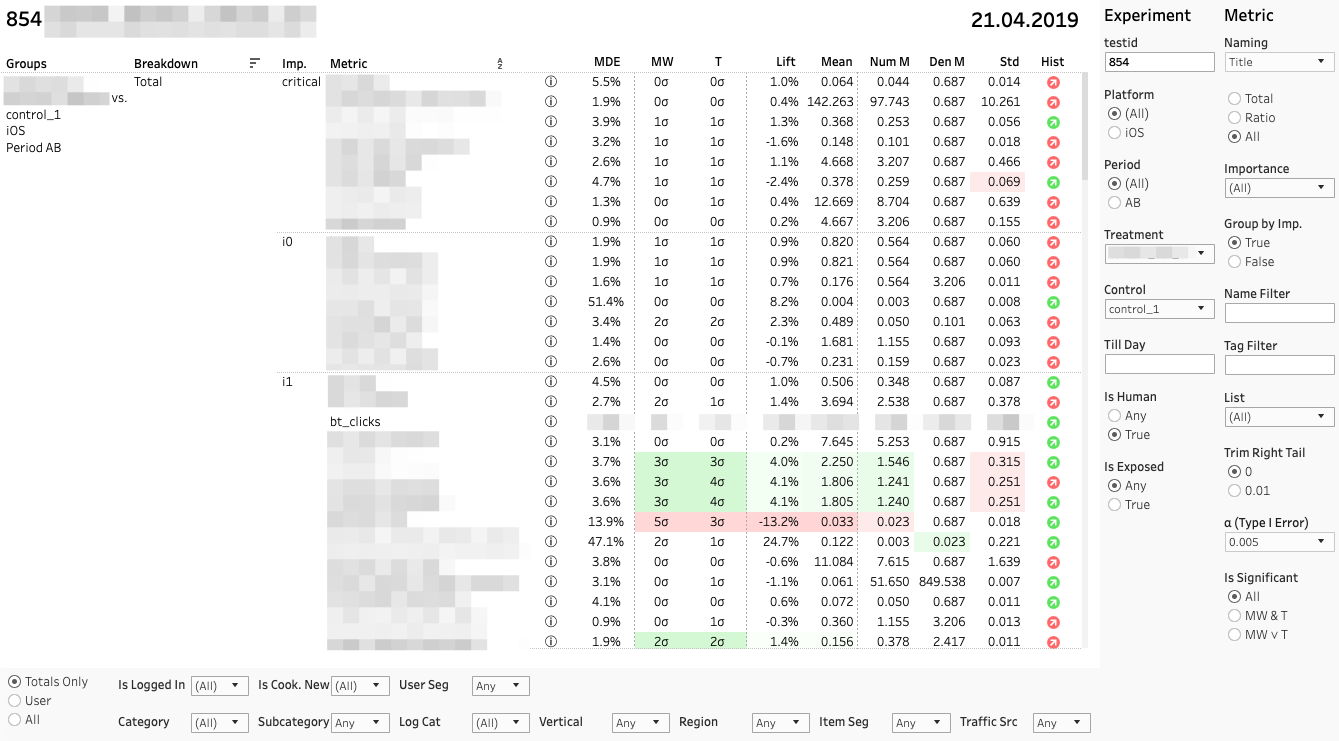
Chaque ligne est une comparaison de groupes par une métrique spécifique dans une section spécifique. À droite, un panneau avec des filtres pour les expériences et les mesures. Panneau filtrant de section inférieure.
Chaque comparaison de métriques se compose de plusieurs métriques. Analysons leurs valeurs de gauche à droite:
1. MDE. Effet détectable minimum

⍺ et β sont des probabilités d'erreur présélectionnées du premier et du deuxième type. MDE est très important si le changement n'est pas statistiquement significatif. Lors de la prise de décision, le client doit se rappeler que le manque de stat. la signification n'est pas sans effet. De manière assez fiable, nous pouvons seulement dire que l'effet possible n'est rien de plus que MDE.
2. MW | Résultats des tests U et T de T. Mann-Whitney
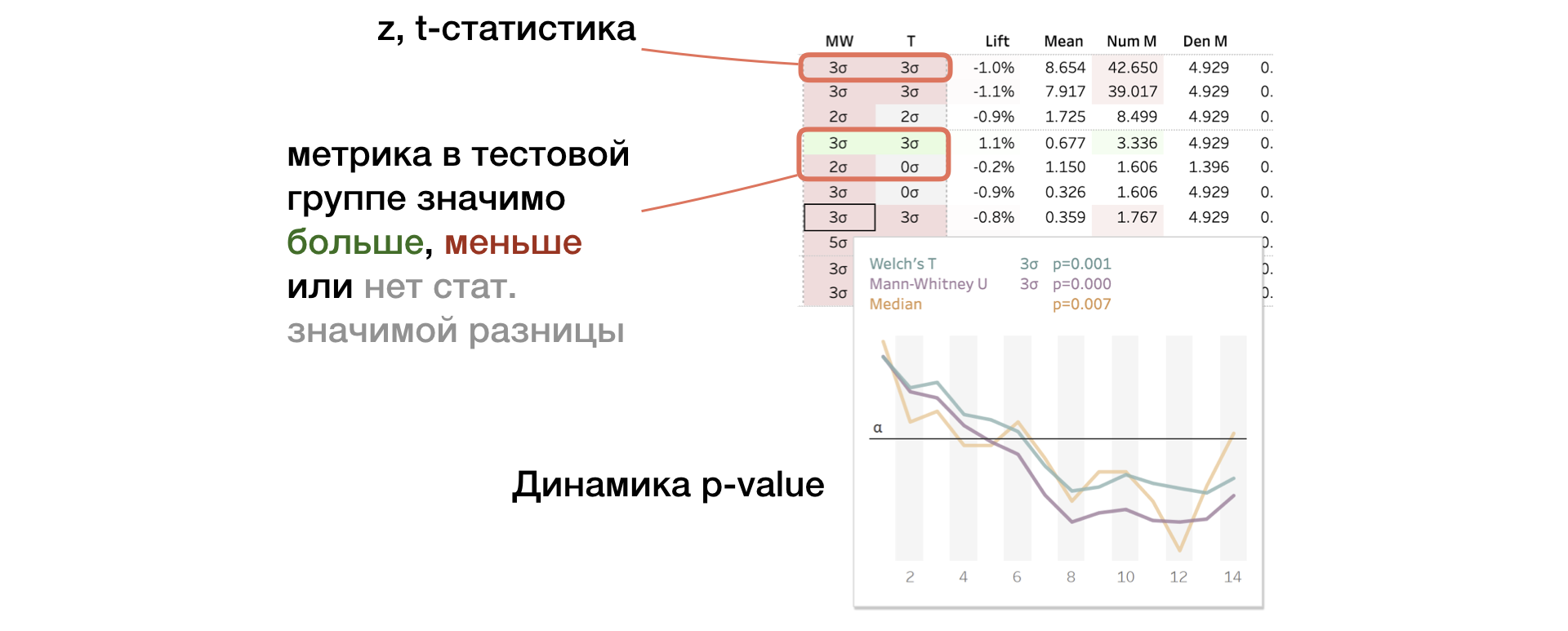
Le panneau affiche la valeur des statistiques z et t (pour MW et T, respectivement). Dans une info-bulle - dynamique de la valeur p. Si le changement est significatif, la cellule est surlignée en rouge ou vert, selon le signe de la différence entre les groupes. Dans ce cas, nous disons que la métrique est «colorée».
3. Soulevez. Différence en pourcentage entre les groupes
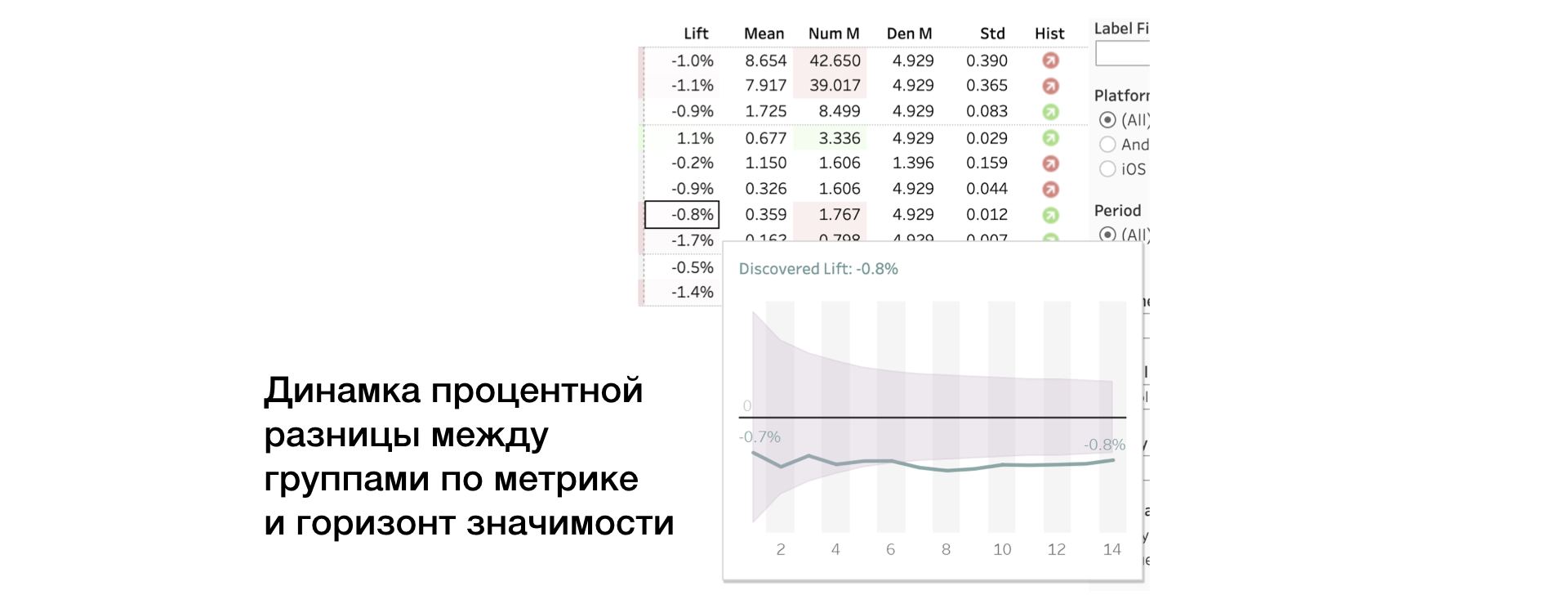
4. Moyenne | Num | Den Valeur métrique, ainsi que numérateur et dénominateur séparément
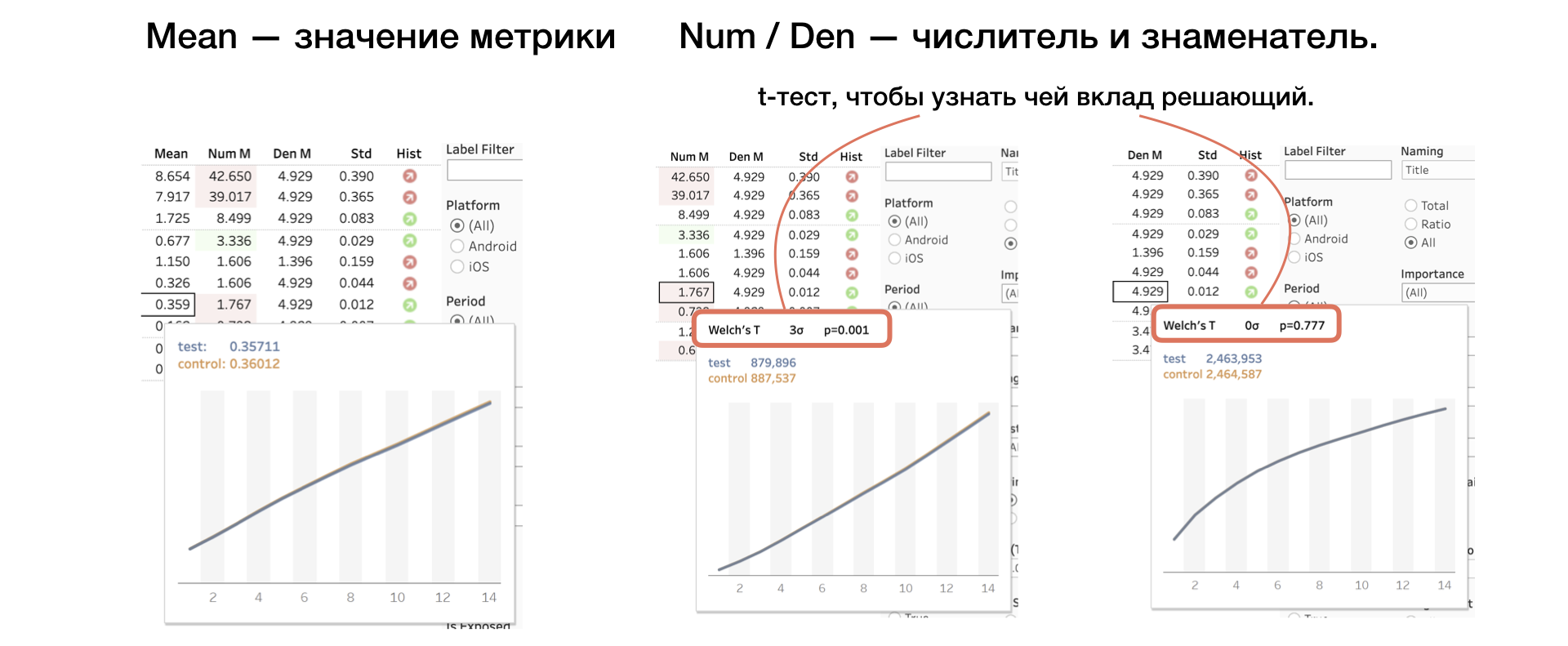
Nous appliquons un autre test T au numérateur et au dénominateur, ce qui aide à comprendre dont la contribution est décisive.
5. Std. Écart type sélectif
6. Hist. Test de Shapiro-Wilk pour la normalité de la distribution «bucket».
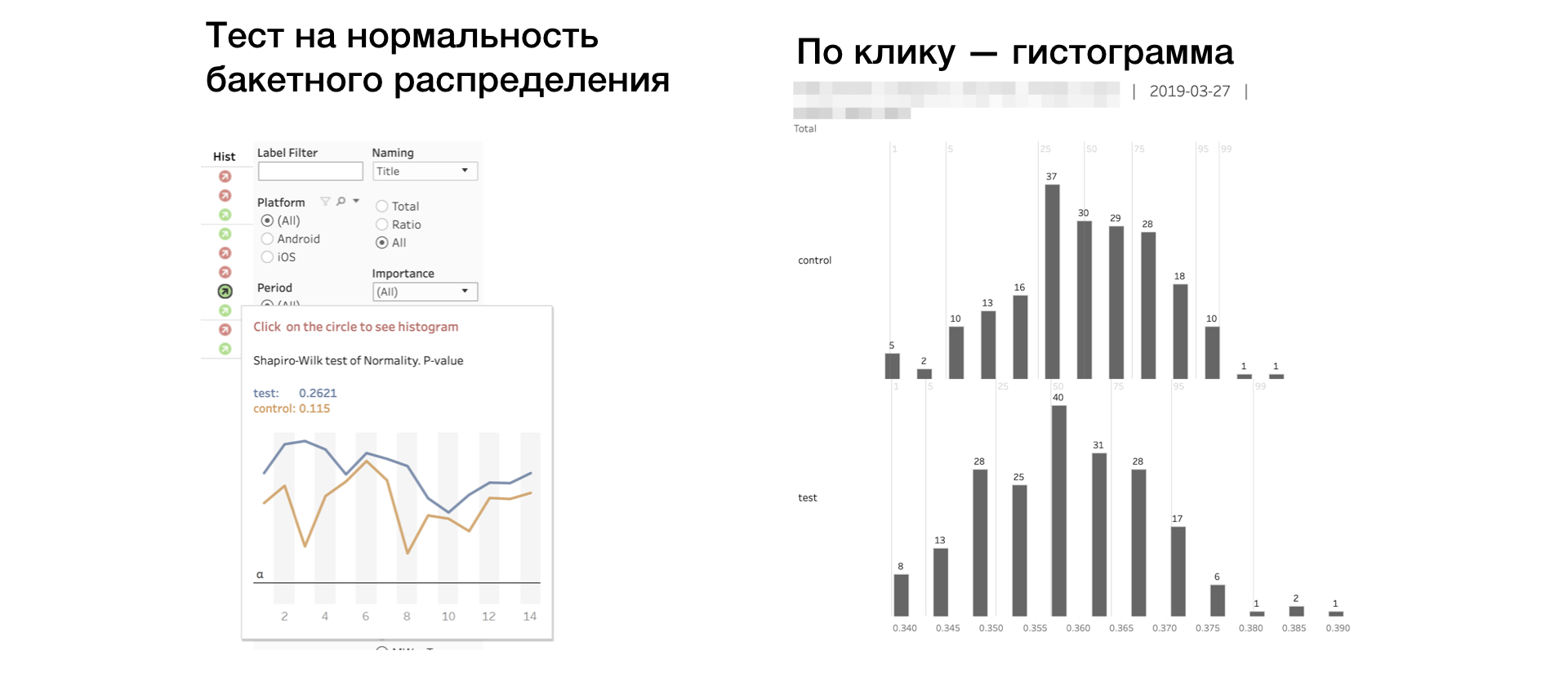
Si l'indicateur est rouge, alors l'échantillon peut avoir des valeurs aberrantes ou une queue anormalement longue. Dans ce cas, vous devez prendre le résultat selon cette métrique avec soin, ou pas du tout. Un clic sur l'indicateur ouvre l'histogramme de la métrique par groupe. L'histogramme montre clairement des anomalies - il est plus facile de tirer des conclusions.
Conclusion
L'émergence de la plateforme A / B à Avito est un tournant décisif lorsque notre produit a commencé à croître plus rapidement. Chaque jour, nous faisons des expériences vertes qui font payer l'équipe; et les «rouges», qui donnent matière à réflexion.
Nous avons réussi à construire un système efficace de tests et de métriques A / B. Souvent, nous avons résolu des problèmes complexes avec des méthodes simples. En raison de cette simplicité, l'infrastructure a une bonne marge de sécurité.
Je suis sûr que ceux qui vont construire la plate-forme A / B dans leur entreprise ont trouvé des informations intéressantes dans l'article. Je suis heureux de partager notre expérience avec vous.
Écrivez vos questions et commentaires - nous essaierons d'y répondre.