Dans un article précédent, nous avons examiné l'approche que nous avons appliquée à la question du traitement informatique (agrégation) des données pour la visualisation sur des tableaux de bord interactifs. L'article a abordé le stade de la transmission d'informations des sources primaires aux utilisateurs dans le cadre de cas analytiques, qui permettent de faire pivoter le cube d'informations. Le modèle de conversion de données présenté à la volée crée une abstraction, fournissant un format de requête unique et un constructeur pour décrire les calculs, l'agrégation et l'intégration de tous les types de sources connectés - tables de base de données, services et fichiers .
Les sources répertoriées sont plus susceptibles d'être structurées, ce qui implique la prévisibilité du format des données et l'unicité des procédures pour leur traitement et leur visualisation. Mais pour l'analyste, les données non structurées n'en sont pas moins intéressantes, qui lorsque les premiers résultats apparaissent, surestiment parfois les attentes de tels systèmes. L'appétit s'accompagne de manger, et la perte de prudence peut exactement répéter l'histoire ...
- Plus! Plus d'or!
Mais sa respiration sifflante était à peine audible et l'horreur apparut dans ses yeux
(conte de fées "Antilope d'or")

Sous la coupe, l'article décrit les fonctionnalités clés et la conception d'un cluster multi-rôles et d'un robot comportemental par des utilisateurs virtuels qui automatisent la routine de collecte d'informations à partir de ressources Internet complexes. Et seule la question de la limite de tels systèmes se pose.
Lors de l'examen des méthodes d'exploration, toute ressource Internet hypothétique à partir de laquelle nous devons extraire des informations peut être placée sur une échelle à deux extrêmes - des simples ressources statiques et API aux sites interactifs dynamiques qui nécessitent une forte implication des utilisateurs. Les premiers incluent l'ancienne génération de robots de recherche (les modernes, au moins, ont appris à traiter JavaScript ), les seconds incluent des systèmes avec des batteries de navigateurs et des algorithmes qui simulent le travail de l'utilisateur ou l'attirent lors de la collecte d'informations.
En d'autres termes, les technologies d'exploration peuvent être placées sur une échelle de complexité:

D'une part, la complexité de la source peut être comprise comme une chaîne d'actions nécessaires pour obtenir des informations primaires, et d'autre part, des technologies qui doivent être appliquées pour obtenir des données lisibles par machine adaptées à l'analyse.
Même l'extraction apparemment simple de textes à partir de pages statiques n'est pas toujours triviale dans la pratique - il est nécessaire de développer et de maintenir des règles de planarisation HTML pour tous les types de pages, ou d'automatiser et d'inventer des heuristiques et des solutions complexes. Dans une certaine mesure, la structuration est simplifiée par le développement du micro-balisage ( en particulier, Schema.org , RDFa , Linked Data ), mais uniquement dans des cas particuliers étroits, pour télécharger des cartes d'entreprise, des produits, des cartes de visite et d'autres produits d'optimisation de moteur de recherche et des données ouvertes.
Ci-dessous, nous allons délibérément restreindre la portée et nous concentrer sur la composante technologique d'un sous-ensemble de robots d'exploration conçus pour télécharger des informations à partir de sites complexes, en particulier les réseaux sociaux - c'est exactement le cas lorsque d'autres méthodes d'exploration simples ne fonctionnent pas.
Envisagez une approche qui réduit la tâche de collecte d'informations à partir des réseaux sociaux à la formation d'une bande de chronologie des informations - une collection mise à jour ou un flux d'objets avec des attributs et des horodatages. La liste des types d'objets et de leurs attributs est différente, modifiable et extensible, par exemple: les publications, les likes, les commentaires, les référentiels et autres entités qui sont ajoutés au système par les développeurs et les opérateurs analytiques, et chargés par les robots.
La bande étant un flux d'objets structurés, la question se pose de son remplissage. Nous avons pris en charge deux types de bandes:
- une simple bande remplie de contenu provenant de sources fixes;
- un fil de discussion rempli de contenu en fonction de mots clés, d'expressions et de termes de recherche.
Un exemple de flux simple avec des sources fixes (des listes d'URL pour les profils et les pages sont définies ):

Un type simple de bande implique l'exploration périodique de ces profils et pages sur divers réseaux sociaux avec une profondeur d'exploration donnée et le chargement d'objets sélectionnés par l'utilisateur. Au fur et à mesure qu'elle se remplit, la bande devient disponible pour la visualisation, l'analyse et le téléchargement des données:

La bande de rubrique est une extension simple, elle fournit une recherche en texte intégral et un filtrage des objets chargés dans la bande. Le système contrôle automatiquement l'ensemble des sources de bande et la profondeur de leur contournement, analysant la pertinence et les relations des sources. Cette caractéristique de l'implémentation est due à l'absence ou au travail "étrange" de la recherche intégrée de mots-clés dans les réseaux sociaux. Même lorsqu'une telle fonction est disponible, le plus souvent, les résultats ne sont pas complètement générés et selon certains algorithmes internes, ce qui est complètement incompatible avec les exigences du robot.
Un mécanisme spécial avec une certaine heuristique est responsable de la gestion de la bande dans le système - il analyse les données et l'historique, ajoute des sources pertinentes (profil et flux communautaires), sur lesquelles soit des expressions spécifiées sont mentionnées, soit elles sont en quelque sorte liées à elles, et supprime celles qui ne sont pas pertinentes.
Un exemple de bande thématique:

À l'avenir, les bandes seront utilisées comme source dans les transformations analytiques avec une visualisation ultérieure des résultats, par exemple sous la forme d'un graphique:

Dans certains cas, le traitement en continu des objets entrants est effectué avec enregistrement dans des collections cibles spécialisées ou téléchargement via l'API REST afin d'utiliser le contenu collecté dans des systèmes tiers ( exemple ). Dans d'autres, un traitement de bloc par minuterie est effectué. L'opérateur décrit le script de traitement avec un script ou construit un processus avec des signaux de contrôle et des blocs fonctionnels, par exemple:

Pool de tâches
Les bandes actives définissent le pool de tâches principal, chacune constituant des tâches associées. Par exemple, une tâche de parcours de profil unique peut générer de nombreuses sous-tâches connexes - contourner les amis, les abonnés, ou télécharger de nouveaux messages et des informations détaillées, etc. Il existe également une étape de prétraitement des nouveaux objets de la bande thématique, qui forme également des tâches liées aux nouvelles sources pertinentes.
En conséquence, nous obtenons un grand nombre de types de tâches différents les uns par rapport aux autres, ayant des priorités, du temps et des conditions d'exécution - tout ce zoo doit être géré correctement afin qu'il n'y ait pas de situations dans lesquelles certaines tâches entraîneraient toutes les ressources du cluster pour elles-mêmes au détriment des tâches d'autres bandes .
Pour résoudre les incohérences, le système met en œuvre des ressources virtuelles partagées et un mécanisme de priorisation dynamique, qui prennent en compte les types de tâches, l'heure actuelle et la probabilité de lancement sous forme de "dôme". En termes généraux - la priorité à un certain point devient maximale, mais disparaît rapidement, la tâche "aigre", mais dans certaines circonstances, elle peut se développer à nouveau.
La formule d'un tel dôme tient compte de plusieurs facteurs, en particulier: la priorité des tâches parentes, la pertinence de la source associée et l'heure de la dernière tentative (avec des analyses répétées pour suivre les changements ou lorsqu'une erreur se produit).
Utilisateurs virtuels
Au sens large, un utilisateur virtuel peut être compris comme l'imitation maximale des actions humaines, en termes pratiques - un ensemble de propriétés qu'un robot doit avoir:
- exécuter le code de la page en utilisant les mêmes outils que l'utilisateur - OS, navigateur, UserAgent, plugins, jeux de polices et plus;
- interagir avec la page, simulant le travail d'une personne avec un clavier et une souris - déplacez le curseur sur la page, faites des mouvements aléatoires, faites des pauses, appuyez sur les touches lors de l'impression de texte et plus encore ( n'oubliez pas les appareils mobiles );
- interagir avec un centre de décision qui prend en compte le contexte et le contenu de la page:
- prendre en compte les doublons, la pertinence des objets sur la page, la profondeur de l'analyse, les délais et plus encore;
- répondre à des situations inhabituelles - en cas de captcha ou d'erreur, formuler une demande et attendre une solution en utilisant un service tiers ou avec la participation d'un opérateur de système;
- avoir une légende crédible - enregistrez votre historique de navigation et les cookies (profil du navigateur), utilisez certaines adresses IP, tenez compte des périodes de la plupart des activités (par exemple, matin-soir ou déjeuner-soir).
Dans une vue idéalisée, un utilisateur virtuel peut avoir plusieurs comptes, utiliser plusieurs navigateurs à différentes périodes et être connecté à d'autres utilisateurs virtuels, ainsi que posséder le comportement et les habitudes de navigation sur Internet qui sont caractéristiques d'une personne.
Par exemple, imaginez une telle situation - virtuelle utilise un navigateur et une IP comme au travail (la même IP peut être utilisée par des "collègues"), un autre navigateur et une IP comme à la maison (les "voisins" les utilisent), et de temps en temps téléphone portable. Avec cette vision du problème, la lutte contre la collecte automatisée par les services Internet semble être une tâche non triviale et, éventuellement, peu pratique.
Dans la pratique, tout est beaucoup plus simple - la lutte contre les robots est comme une vague et comprend un petit ensemble de techniques: modération manuelle, analyse du comportement des utilisateurs (fréquence et uniformité des actions) et affichage du captcha. Claruler, possédant au moins dans une certaine mesure les propriétés de la liste ci-dessus, met pleinement en œuvre le concept d'utilisateurs virtuels et, avec l'attention requise de l'opérateur, peut remplir sa fonction pendant longtemps, en restant " insaisissable Joe ".
Mais qu'en est-il du côté éthique et juridique de l'utilisation des utilisateurs virtuels?
Afin de ne pas jouer avec les notions de données publiques et personnelles, chacune des parties a ses propres arguments de poids, nous n'aborderons que les points fondamentaux.
La publication automatisée de contenu, l'envoi de pourriels, l'enregistrement de comptes et d'autres activités "actives" d'utilisateurs virtuels peuvent facilement être considérés comme illégaux ou affectant les intérêts de tiers. À cet égard, le système met en œuvre une approche dans laquelle les utilisateurs virtuels ne sont que des observateurs curieux représentant l'utilisateur (leur opérateur) et exécutant une routine pour collecter des informations à la place.
Gestion partagée des ressources virtuelles
Comme décrit ci-dessus, un utilisateur virtuel est une entité collective qui utilise plusieurs ressources système et virtuelles dans le processus. Certaines ressources sont utilisées seules, tandis que d'autres sont partagées et utilisées par plusieurs utilisateurs virtuels, par exemple:
- adresse du nœud de sortie (IP externe) - associée à un ou plusieurs utilisateurs virtuels;
- profil de navigateur - associé à un seul utilisateur virtuel;
- ressource informatique - connectée au serveur, définit les limites du serveur dans son ensemble et pour chaque type de tâche;
- écran virtuel - définit les restrictions du serveur, mais est utilisé par l'utilisateur virtuel.
Chaque ressource virtuelle a un type et un groupe d'instances appelés emplacements. Sur chaque nœud du cluster, la configuration des ressources et des emplacements virtuels est définie, qui sont ajoutés au pool de ressources virtuelles et sont accessibles à tous les nœuds du cluster. De plus, pour un type de ressource virtuelle, un nombre fixe et un nombre variable d'emplacements peuvent être ajoutés.
Chaque emplacement peut avoir des attributs qui seront utilisés comme conditions lors de la liaison et de l'allocation des ressources. Par exemple, nous pouvons associer chaque utilisateur virtuel à certains types de tâches, serveurs, adresses IP, comptes, périodes de la plus grande activité d'exploration et autres attributs arbitraires.
Dans le cas général, le cycle de vie d'une ressource se compose de certaines étapes:
- Lorsqu'un nœud de cluster est lancé dans le pool partagé de ressources virtuelles, des emplacements ouverts supplémentaires sont enregistrés, ainsi que des liens entre les ressources;
- Lorsqu'une tâche est lancée par un répartiteur à partir d'un pool de ressources virtuelles, un emplacement libre approprié est sélectionné et bloqué. À son tour, le blocage de la ressource parent entraîne le blocage des ressources associées et, en l'absence de créneaux libres, une défaillance est générée;
- Une fois la tâche terminée, l'emplacement de ressource principal et ses emplacements associés sont libérés.
En plus de celles spécifiées dans la configuration du nœud, il existe également des ressources virtuelles utilisateur - des entités avec lesquelles l'opérateur système travaille. En particulier, l'opérateur utilise l'interface de registre d'utilisateurs virtuel, qui prend en charge plusieurs fonctions utiles à la fois:
- gestion des détails et des attributs supplémentaires indiquant les spécificités d'utilisation, en particulier, les utilisateurs virtuels peuvent être divisés en groupes et utilisés à des fins différentes;
- suivre le statut et les statistiques des utilisateurs virtuels;
- connexion à l'écran virtuel - suivi du travail en temps réel, exécution d'actions dans le navigateur au lieu de l'utilisateur virtuel (widget de bureau à distance).
Exemple de registre de ressources virtuelles utilisateur:

Cool case qui n'a pas pris racine
En plus des bandes d'informations en tant que «fitchi tueur», nous avons développé un graphique de recherche prototype pour effectuer des recherches complexes et mener des enquêtes en ligne. L'idée principale est de construire un graphique visuel dans lequel les nœuds sont les modèles d'objets (personnes, organisations, groupes, publications, likes, etc.), et les liens sont les modèles de connexions entre les objets trouvés.
Un exemple d'un simple graphique de recherche de personnes et des relations entre elles:

Cette approche suppose que la recherche commence par un minimum d'informations connues. Après la recherche initiale, l'utilisateur examine les résultats et ajoute progressivement des conditions supplémentaires au graphique de recherche, en réduisant la sélection et en augmentant la profondeur et la précision de l'analyse du résultat. En fin de compte, le graphique prend la forme dans laquelle chacun des nœuds est un flux d'informations distinct avec les résultats. Cette bande peut également être utilisée comme source pour une analyse et une visualisation supplémentaires sur les tableaux de bord et les widgets.

Par exemple ...À titre d'exemple, nous pouvons considérer quelques cas simples:
- trouver tous les amis de la personne portant le prénom;
- Trouvez tous les messages d'amis d'une personne avec un prénom et d'autres attributs;
- trouver tous les abonnés aux pages où les phrases clés spécifiées sont mentionnées, ou rassembler l'environnement autour de certains articles ou auteurs;
- ou trouver des intersections - auteurs de commentaires sur tous les articles rédigés par des auteurs qui ont déjà publié des articles sur des sujets spécifiques.
Lorsque nous avons annoncé le développement d'un tel ajustement, nos clients et partenaires ont chaleureusement soutenu cette idée, elle semblait être exactement ce qui manquait beaucoup dans les solutions similaires existantes. Mais une fois le prototype fonctionnel achevé, il s'est avéré que les clients n'étaient pas prêts à modifier leurs processus internes, et les enquêtes Internet étaient plutôt considérées comme quelque chose qui pourrait être utile s'ils en avaient soudainement besoin. Dans le même temps, du point de vue technologique, la fonctionnalité est sérieuse et nécessite un raffinement et un support supplémentaires. En conséquence, en raison du manque de demande et d'intérêt pratique de nos partenaires, ce fitch a dû être temporairement gelé jusqu'à des temps meilleurs.
Réincarnation
Compte tenu du vecteur actuel de développement de nos solutions, cette fonctionnalité semble toujours pertinente, mais d'un point de vue technique, elle est déjà vue différemment. Il s'agit plutôt d'une extension des fonctionnalités de Cubisio, à savoir l'éditeur du modèle de domaine et l'éditeur des processus de traitement des données, qui ont jusqu'à présent été mis en œuvre en tant que prototype, mais prévoient une approche similaire sous une forme généralisée.
Un exemple du modèle ontologique du domaine "Réseaux sociaux" (en cliquant sur l'image de l'éditeur s'ouvre):

Un exemple de graphique analytique de recherche basé sur l'ontologie ci-dessus (cliquer sur l'image ouvre l'éditeur):

Pile de technologie de cluster

Le système décrit a été développé en collaboration avec la plate-forme (nous l'appelons dWires) il y a plusieurs années, il fonctionne et est toujours utilisé. Les principales solutions réussies ont naturellement migré vers nos nouveaux développements. En particulier, la plate-forme décrite représente la première génération du concepteur de systèmes d'information-analytique, à partir de laquelle la plate-forme jsBeans et nos autres développements sont nés.
En bref, le système est basé sur le cluster Akka, l'interpréteur Rhino et le serveur Web Jetty intégré. Certaines caractéristiques architecturales utiles peuvent être vues dans le diagramme ci-dessus. , , , JavaScript- , jsBeans .
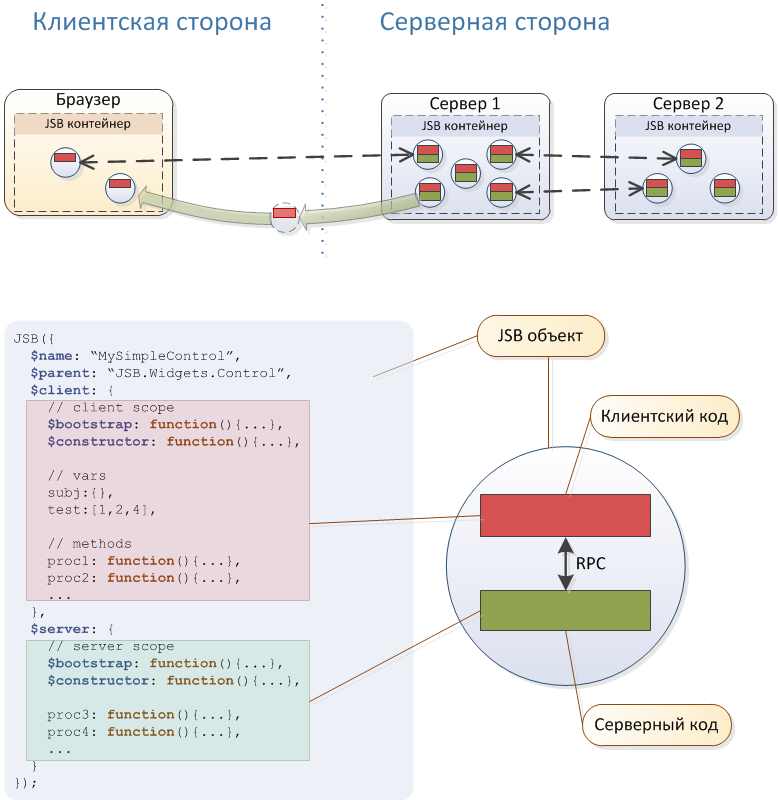
, – .
Java. , , – - JavaScript. JavaScript ( ), , , . – , , , , , - .
Akka - . - Akka Cluster , . , " " ( ) .
Selenium WebDriver , : , , API . WebDriver ( , IP ).
( ):
- , , Xvfb;
- VNC , , x11vnc;
- VNC Web Viewer , , noVNC -.
MongoDB, – . Elasticsearch, MongoDB. (H2, EhCache, Db4o).
" ", , bash , ( ). . , .
, .
. – . , " ".
, .
,
( « »)