
Connaissez-vous une situation dans laquelle vous passez énormément de temps à choisir un film comparable à la période pendant laquelle vous l'avez regardé? Pour les utilisateurs de cinémas en ligne, c'est un problème commun, et pour les cinémas eux-mêmes - des pertes de profits.
Heureusement, nous avons Rekko - un système de recommandations personnelles qui aide avec succès les utilisateurs d'Okko depuis un an à choisir des films et des séries parmi plus de dix mille unités de contenu. Dans l'article, je vais vous dire comment il est organisé du point de vue algorithmique et technique, comment nous abordons son développement et comment nous évaluons les résultats. Eh bien, je vais également vous parler des résultats du test A / B annuel.
Tout d'abord, un peu d'histoire. Okko a commencé son existence en 2011 dans le cadre d'Iota, en commençant sous le nom de Yota Play.
Déjà en 2011, les utilisateurs ont accepté avec enthousiasme l'idée de regarder un film légalement sur Internet Yota Play était un service unique pour son époque: il était étroitement intégré aux réseaux sociaux et utilisait des informations sur les films visionnés et évalués par des amis dans de nombreuses parties du service, y compris des recommandations.

En 2012, il a été décidé de compléter les recommandations sociales par des recommandations algorithmiques. C'est ainsi qu'apparut «Oracle» - le premier système de recommandation du cinéma en ligne Okko. Voici quelques extraits de son document de conception:
Une approche similaire a été utilisée dans le système mis en place de recommandations personnelles. L'échelle des niveaux est utilisée de «rien» (vide, absence) à «tout» (complètement, au maximum). Dans l'intervalle [127 .. + 127] 0 - est le milieu ou la «norme». Sur cette échelle, le degré de sympathie pour le personnage principal et le prix subjectif du produit et le degré de couleur «rouge» sont également évalués. Par exemple, la taille de l'univers est estimée à +127 (sur l'échelle des dimensions), et l'obscurité est estimée à 127 (sur l'échelle de l'intensité lumineuse).
Lors de la formulation de recommandations, il est important non seulement le contexte, mais également la nature de l'utilisateur particulier. Le profil personnel contient également 4 échelles de types de personnages (selon K. Leonhard - démonstratif, pédant, coincé, excitable).
Les limites physiologiques du cerveau ne dépendent pas des propriétés du caractère d'une personne ni de son amabilité et de sa sociabilité. Selon le professeur, des restrictions existent dans le néocortex, le département responsable des pensées et de la parole conscientes. Cette restriction est également prise en compte dans le système mis en œuvre, en particulier lors de l'élaboration de recommandations pour un type de personnage pédant et lors de la formation d'un échantillon de ces utilisateurs parmi les connexions sociales.

Comme vous l'avez déjà compris, les temps étaient sauvages, les limites physiologiques du cerveau n'étaient pas limitées à rien, et le néocortex overclocké lui-même pouvait générer des recommandations personnelles à la vitesse de la lumière. Par conséquent, le modèle a été décidé de passer immédiatement en production.
Autant que l'on puisse en juger par les artefacts survivants de la civilisation ancienne, "Oracle" était un mélange sauvage d'algorithmes de filtrage collaboratifs, généreusement assaisonnés de règles commerciales.

À la mi-2013, tout le monde a commencé à lâcher un peu et il a finalement été décidé de vérifier la qualité de la machine de recommandation. Pour ce faire, un éditeur spécialement formé a rempli les principales sections de l'application et le test A / B a été lancé: la moitié des utilisateurs ont vu la sortie de l'algorithme, la moitié - le choix de l'éditeur.
C'est maintenant que nous lisons des articles sur les prochaines victoires de l'intelligence artificielle et imaginons avec horreur le jour où il perdra notre travail. Puis, en 2013, la situation était différente: une personne a héroïquement vaincu la voiture, créant encore plus d'emplois dans le département du contenu. L'Oracle a été désactivé et n'a jamais été réactivé. Bientôt, tous les jetons sociaux ont disparu et Yota Play est devenu Okko.
La période de 2013 à 2016 a été marquée par «l'hiver» de l'intelligence artificielle et la règle totalitaire du département contenu: il n'y avait pas de recommandations personnelles dans le service.
À la mi-2017, il est devenu clair que vous ne pouvez pas vivre comme ça. Les succès de Netflix étaient bien connus de tous et l'ensemble de l'industrie évoluait rapidement vers la personnalisation. Les utilisateurs n'étaient plus intéressés par les services statiques «stupides», ils commençaient déjà à s'habituer aux interfaces «intelligentes», à les comprendre parfaitement et à prévoir tous leurs désirs.
Lors de la première itération, nous avons décidé de nous intégrer à deux grands fournisseurs russes de recommandations. Une fois par jour, les deux services prenaient les données nécessaires à Okko, bruissaient avec leurs boîtes noires sur des serveurs distants et téléchargeaient les résultats.
Selon les résultats du test A / B de six mois, aucune différence statistiquement significative n'a été trouvée dans les groupes témoin et test.
Juste à la fin de ce test A / B, je suis venu à Okko pour commencer à rendre le service vraiment personnel avec le chef de l'analyse, Mikhail Alekseev ( malekseev ). Moins d'un an plus tard, Danil Kazakov ( xaph ) nous a rejoint, formant finalement l'équipe actuelle.
Considérations générales
Lorsqu'un problème commercial étudié depuis longtemps par la communauté internationale se pose devant vous et qui, en outre, doit être résolu rapidement, il est tentant de prendre la première solution populaire de réseau de neurones profonds que vous avez, enfoncez-y les données avec une pelle, enfoncez-les et jetez-les dans le produit.

L'essentiel est de ne pas succomber à cette tentation. La tâche de la communauté scientifique - atteindre une vitesse maximale sur des ensembles de données pourris et synthétiques - ne coïncide souvent pas avec la tâche commerciale - gagner plus d'argent tout en dépensant moins de ressources.

Non, cela ne signifie pas que vous n'avez pas besoin de réseaux récurrents et que vous pouvez ratisser des milliards en utilisant la méthode k des voisins les plus proches. Il se peut que la décomposition matricielle classique vous permette de gagner 100 millions supplémentaires conditionnels par an et des réseaux récurrents - 105 millions par an. Dans le même temps, la maintenance d'un rack de serveurs avec des cartes vidéo pour ces mêmes réseaux coûtera 10 millions par an et nécessitera plusieurs mois supplémentaires pour se développer et mettre en œuvre, et la simple intégration d'une décomposition matricielle prête à l'emploi dans une autre section du service et de la liste de diffusion nécessitera un mois d'améliorations et donnera 100 millions supplémentaires conditionnels par an.
Par conséquent, il est important de commencer par les bases - des méthodes de base éprouvées - et de passer à des approches toujours plus modernes, assurez-vous de mesurer et de prédire l'effet de chaque nouvelle méthode sur l'entreprise, combien cela coûtera et combien cela vous permettra de gagner.
Okko peut bien mesurer. Littéralement, chaque nouvelle fonctionnalité, chaque innovation que nous avons passe par un test A / B, est examinée dans le contexte d'une variété de groupes d'utilisateurs, les effets sont vérifiés pour la signification statistique et seulement après qu'une décision est prise d'accepter ou de rejeter la nouvelle fonctionnalité.

Le tableau de bord Rekko actuel, par exemple, compare les groupes de contrôle et de test pour plus de 50 mesures, y compris les revenus, le temps passé dans le service, le temps pour choisir un film, le nombre de vues par abonnement, la conversion en achat et le renouvellement automatique, et bien d'autres. Et oui, nous gardons toujours un petit groupe d'utilisateurs qui n'ont jamais reçu de recommandations personnalisées (désolé).

À propos des systèmes de recommandation
Pour commencer, une petite introduction aux systèmes de recommandation.
L'objectif du système de recommandation est que pour chaque utilisateur sur son histoire d'interagir avec des éléments pour construire une relation d'ordre sur l'ensemble de tous les éléments. Cela signifie ceci: quels que soient les deux éléments arbitraires que nous prenons, nous pouvons toujours dire lequel est le plus préférable pour l'utilisateur et lequel l'est moins.
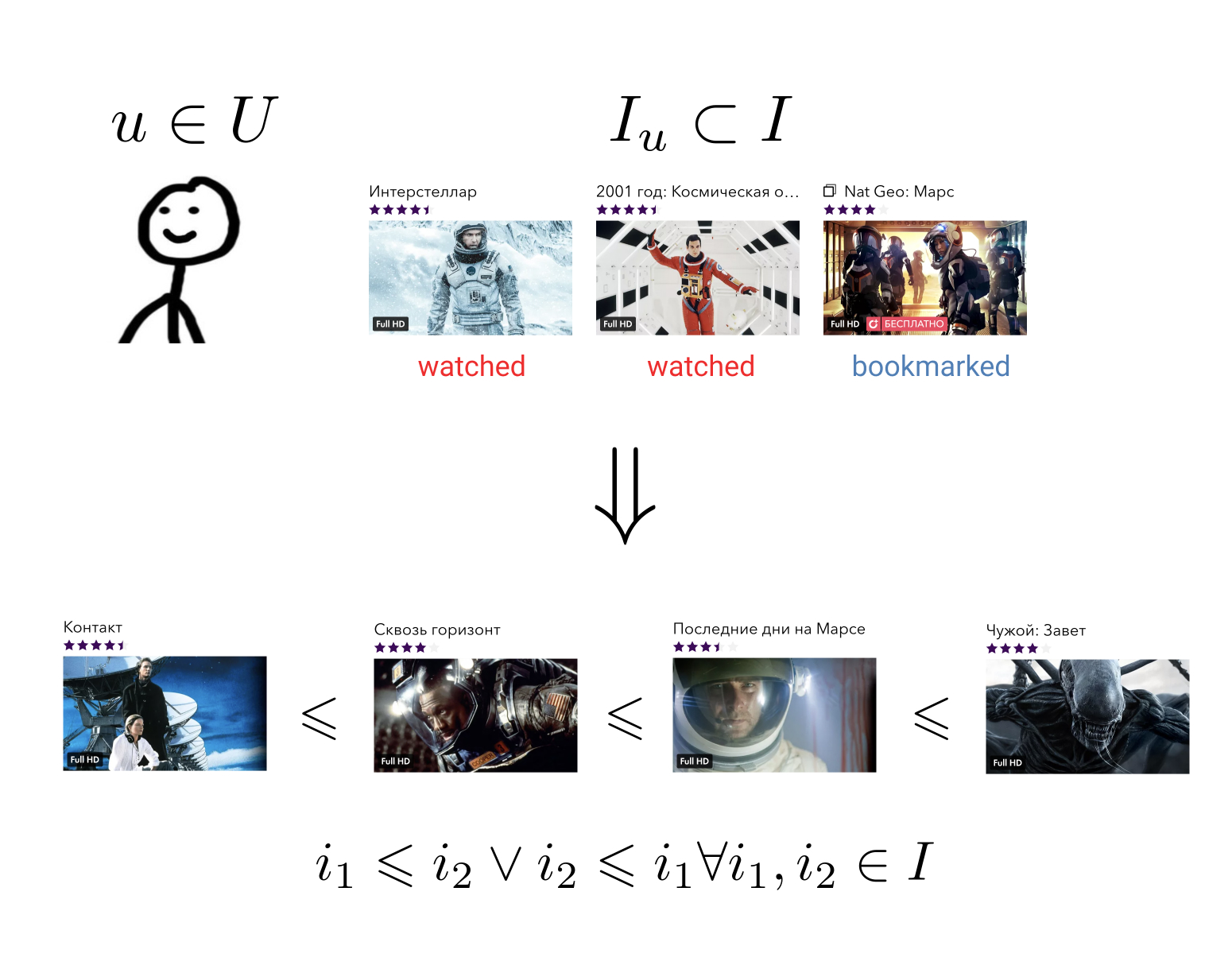
Cette tâche assez générale peut être réduite à une tâche plus simple: mapper des éléments à un ensemble sur lequel une relation d'ordre est déjà définie. Par exemple, sur un ensemble de nombres réels. Dans ce cas, il est nécessaire que chaque utilisateur et chaque élément puisse prédire une certaine valeur - combien cet utilisateur préfère-t-il cet élément.

Ayant une relation de commande sur nos éléments, nous sommes en mesure de résoudre de nombreux problèmes commerciaux, par exemple, choisir parmi tous les éléments N les plus pertinents pour l'utilisateur ou trier les résultats de la recherche selon ses préférences.
Idéalement, nous avons besoin de toute une famille de relations d'ordre contextuelles. Si l'utilisateur est entré dans la collection «Fighters», il préférera très probablement le film «Destroyer» au film «Oscar», mais dans la collection «Films with Sylvester Stallone», la préférence pourrait bien être le contraire. Des exemples similaires peuvent être donnés pour le jour de la semaine, l'heure ou l'appareil à partir duquel l'utilisateur est entré dans le service.

Traditionnellement, toutes les méthodes de construction de recommandations personnelles sont divisées en trois grands groupes: filtrage collaboratif (CF), modèles de contenu (modèles de contenu, CM) et modèles hybrides qui combinent les deux premières approches.
Les méthodes de filtrage collaboratif utilisent des informations sur les interactions de tous les utilisateurs et de tous les éléments. Ces informations, en règle générale, sont présentées sous la forme d'une matrice clairsemée, où les lignes correspondent aux utilisateurs, les colonnes aux éléments, et l'utilisateur et l'élément contiennent la valeur caractérisant l'interaction entre eux, ou un écart s'il n'y avait pas une telle interaction. La tâche de construire une relation d'ordre se réduit ici à la tâche de remplir les éléments de matrice manquants.
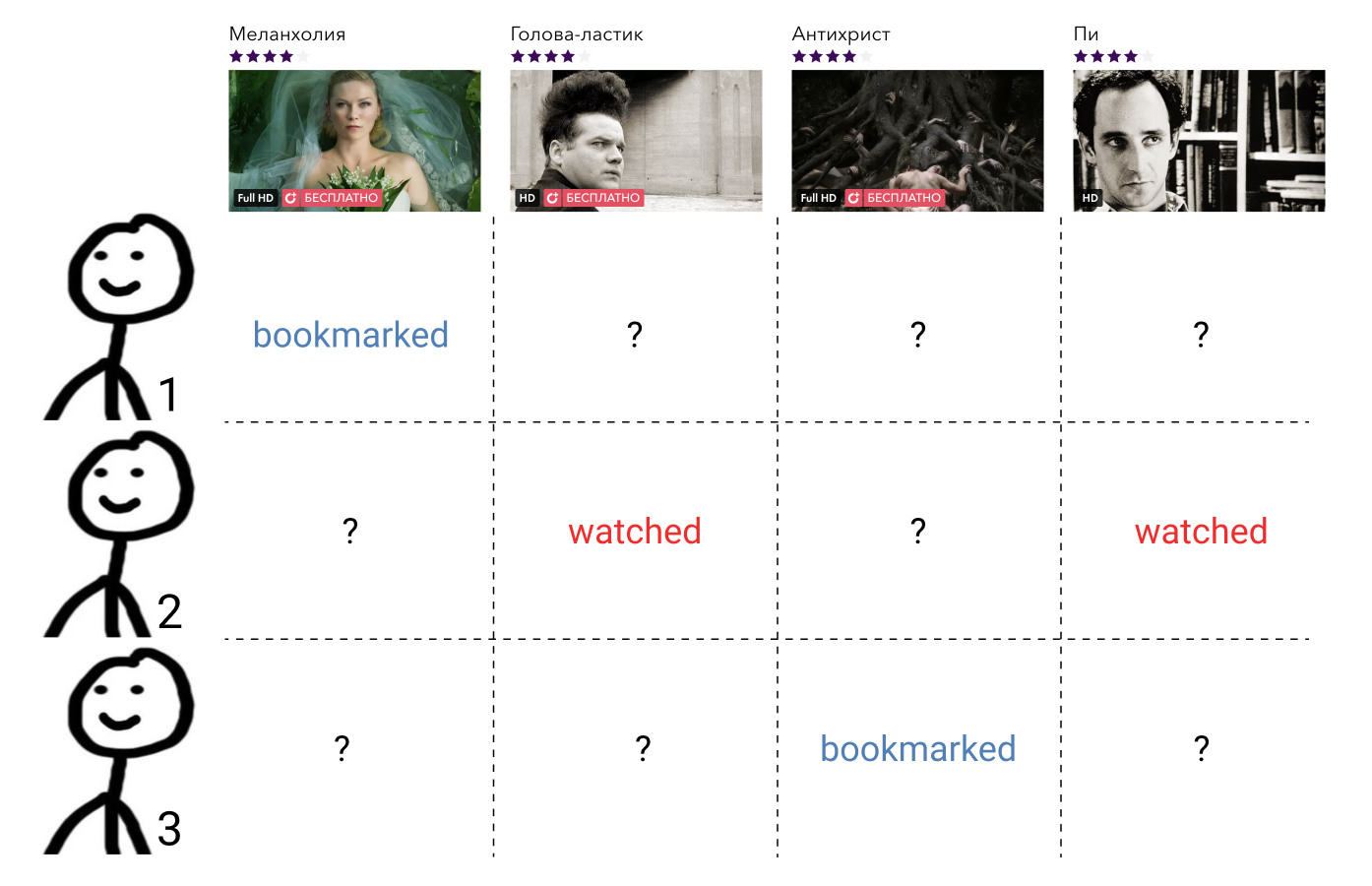
Ces méthodes, en règle générale, sont faciles à comprendre et à mettre en œuvre, rapides, mais ne montrent pas le meilleur résultat.
Modèles de contenu - méthodes d'apprentissage automatique arbitraires pour résoudre les problèmes de classification ou de régression, paramétrées par un certain ensemble de paramètres . À l'entrée, ils acceptent les attributs de l'utilisateur et les attributs de l'élément, et la sortie est le degré de pertinence de l'élément donné pour cet utilisateur. Ces modèles ne sont pas enseignés sur les interactions de tous les utilisateurs et de tous les éléments, tels que les méthodes de filtrage collaboratif, mais uniquement sur des précédents individuels.

De tels modèles, en règle générale, sont beaucoup plus précis que les méthodes de filtrage collaboratif, mais leur vitesse est beaucoup plus lente. Imaginez que si nous avons une fonction d'une forme générale qui accepte les signes d'utilisateurs et d'éléments en entrée, elle doit être appelée pour chaque paire . Dans le cas d'un millier d'utilisateurs et de dix mille éléments, cela représente un million d'appels.
Les modèles hybrides combinent les forces des deux approches, offrant des recommandations de qualité dans un délai raisonnable.
L'approche hybride la plus populaire aujourd'hui est une architecture à deux niveaux, où un modèle de filtrage collaboratif sélectionne un petit nombre (100 - 1000) de candidats parmi tous les éléments possibles, qui sont ensuite classés par un modèle de contenu beaucoup plus puissant. Parfois, il peut y avoir plusieurs de ces étapes de sélection des candidats et un modèle de plus en plus complexe est utilisé à chaque nouveau niveau.

Une telle architecture présente de nombreux avantages:
- Les parties collaboratives et de contenu ne sont pas interconnectées et peuvent être entraînées séparément avec différentes fréquences;
- La qualité est toujours meilleure que celle d'un modèle collaboratif séparément;
- La vitesse est beaucoup plus élevée que celle du modèle de contenu séparément;
- «Gratuit», nous obtenons des vecteurs à partir d'un modèle collaboratif, qui peuvent ensuite être utilisés pour résoudre des problèmes connexes.
Si nous parlons de technologies spécifiques, il existe de nombreuses combinaisons possibles.
En tant que partie collaborative, vous pouvez prendre des abonnements utilisateur, du contenu populaire, du contenu populaire parmi les amis de l'utilisateur, vous pouvez appliquer une factorisation matricielle ou tensorielle, entraîner DSSM ou toute autre méthode avec une prédiction assez rapide.
En tant que modèle de contenu, toute approche peut être utilisée en général, de la régression linéaire aux grilles profondes.
Chez Okko, nous nous concentrons actuellement sur une combinaison de factorisation matricielle avec perte de WARP et accentuation du gradient sur les arbres, dont je vais maintenant discuter en détail.
Première étape: sélection des candidats
Je pense que je ne mens pas si je dis que les algorithmes de factorisation matricielle sont de loin les méthodes les plus populaires de filtrage collaboratif. L'essence de la méthode ressort clairement du nom: nous essayons de présenter la matrice déjà mentionnée des interactions des utilisateurs avec le contenu par le produit de deux matrices de rang inférieur, dont l'une sera une «matrice d'utilisateur» et l'autre une «matrice d'éléments». Avec cette décomposition, nous pouvons restaurer la matrice d'origine avec toutes les valeurs manquantes.

Dans ce cas, bien entendu, nous sommes libres de choisir un critère de similitude des matrices disponibles et restaurées. Le critère le plus simple est l'écart type.
Soit - ligne de matrice utilisateur correspondant à l'utilisateur et - colonne de la matrice d'élément correspondant à l'élément . Ensuite, lors de la multiplication des matrices, leur produit signifiera l'ampleur de l'interaction prévue entre l'utilisateur donné et l'élément. Calculons maintenant l'écart type entre cette quantité et la valeur connue a priori de l'interaction pour toutes les paires d'utilisateurs et d'éléments en interaction , nous obtenons une fonction de perte qui peut être minimisée.
En règle générale, la régularisation y est toujours ajoutée.
Un tel problème n'est pas convexe et NP-complexe. Cependant, il est facile de remarquer que lors de la fixation de l'une des matrices, la tâche se transforme en régression linéaire par rapport à la deuxième matrice, ce qui signifie que nous pouvons rechercher une solution de manière itérative, en gelant alternativement la matrice utilisateur ou la matrice d'éléments. Cette approche est appelée Alternating Least Squares (ALS).

Le principal avantage de la SLA est la vitesse et la capacité de se paralléliser facilement. Pour cela, il est tellement aimé à Yandex.Zen et Vkontakte, où les utilisateurs et les éléments se comptent par dizaines de millions.
Cependant, si nous parlons de la quantité de données qui tient sur une machine, ALS ne résiste pas aux critiques. Son principal problème est qu'il optimise la mauvaise fonction de perte. N'oubliez pas la formulation de la tâche de construction d'un système de recommandation. Nous voulons obtenir la relation d'ordre sur l'ensemble, et optimiser à la place l'écart type.
Il est facile de donner un exemple de matrice pour laquelle l'écart-type sera minime, mais l'ordre des éléments est désespérément détruit.
Voyons ce que nous pouvons y faire. Dans la tête de l'utilisateur, tous les éléments avec lesquels il a interagi sont classés dans un certain ordre. Par exemple, il sait avec certitude qu'Interstellar est meilleur que Gravity, Gravity et Alien sont des films tout aussi bons, et ils sont tous un peu pires que Terminator. Dans le même temps, il éprouve également une certaine attitude envers les films que l'utilisateur n'a pas encore regardés, et la même chose pour tout le monde. Il peut croire que de tels films sont a priori pires que les films qu'il a regardés. Ou il peut considérer que, par exemple, Prométhée est un mauvais film, et tout film qu'il n'a pas encore regardé sera meilleur que lui.
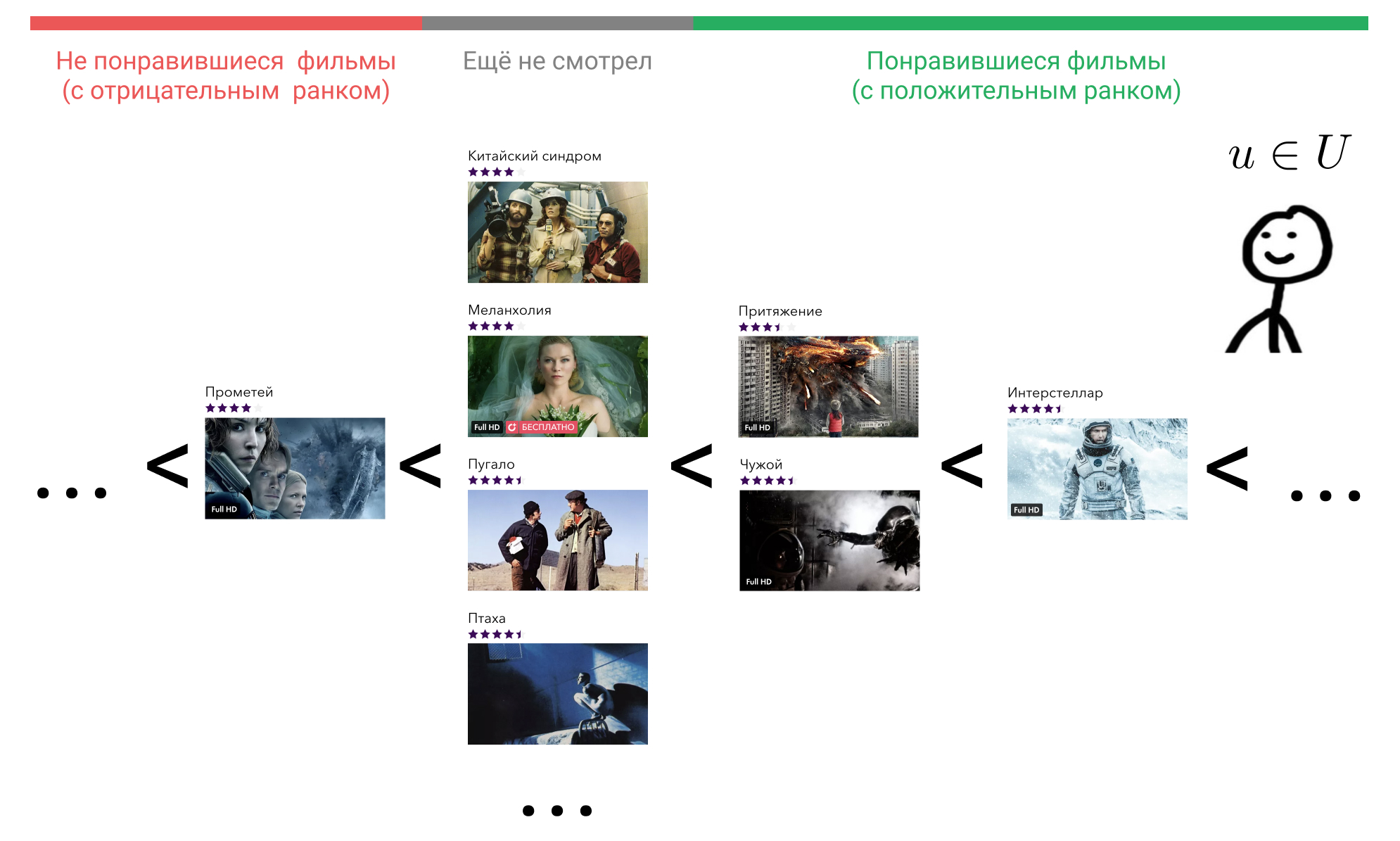
Imaginez que selon certains signes de comportement des utilisateurs dans le service, nous pouvons restaurer cet ordre en affichant l'élément avec lequel il a interagi, dans un entier en utilisant la fonction . Beaucoup de films avec lesquels l'utilisateur interagi, désignent comme . Nous convenons que si l'utilisateur n'a pas interagi avec le film c'est . Ainsi, si l'utilisateur considère que le film est mauvais, alors et si c'est bon, alors .

Maintenant, nous pouvons entrer le rang .
désigne ici la fonction d'indicateur et est égal à l'unité si vrai et zéro sinon.
Arrêtons-nous une minute et réfléchissons à la signification d'un tel rang.
Nous réparons l'utilisateur , il s'agit d'un utilisateur spécifique, lequel - nous ne sommes pas intéressés. En conséquence, son vecteur sera corrigé.
Prenez maintenant n'importe quel film qu'il a regardé, par exemple Interstellar. Dans la formule, ce . Ensuite, nous trouvons un film que l'utilisateur considère comme pire qu'Interstellar. Nous pouvons choisir parmi "Attraction", "Alien", "Prométhée", ou tout film qu'il n'a pas encore regardé.

Prenez l '«attraction». Dans la formule, ce . , «» , , «» . . «», «» , .
, , «». , .
.
— , . , . , , .
. ? , , , , .
: . , , . ,
où — .
, , , .
WARP WSABIE: Scaling Up To Large Vocabulary Image Annotation . , , . 10%.
. Okko :
- ;
- ;
- ( );
- ;
- 0 10.
, , . 399 , , . , . -, .
— . , explicit : , . , , implicit .
, , . . , .
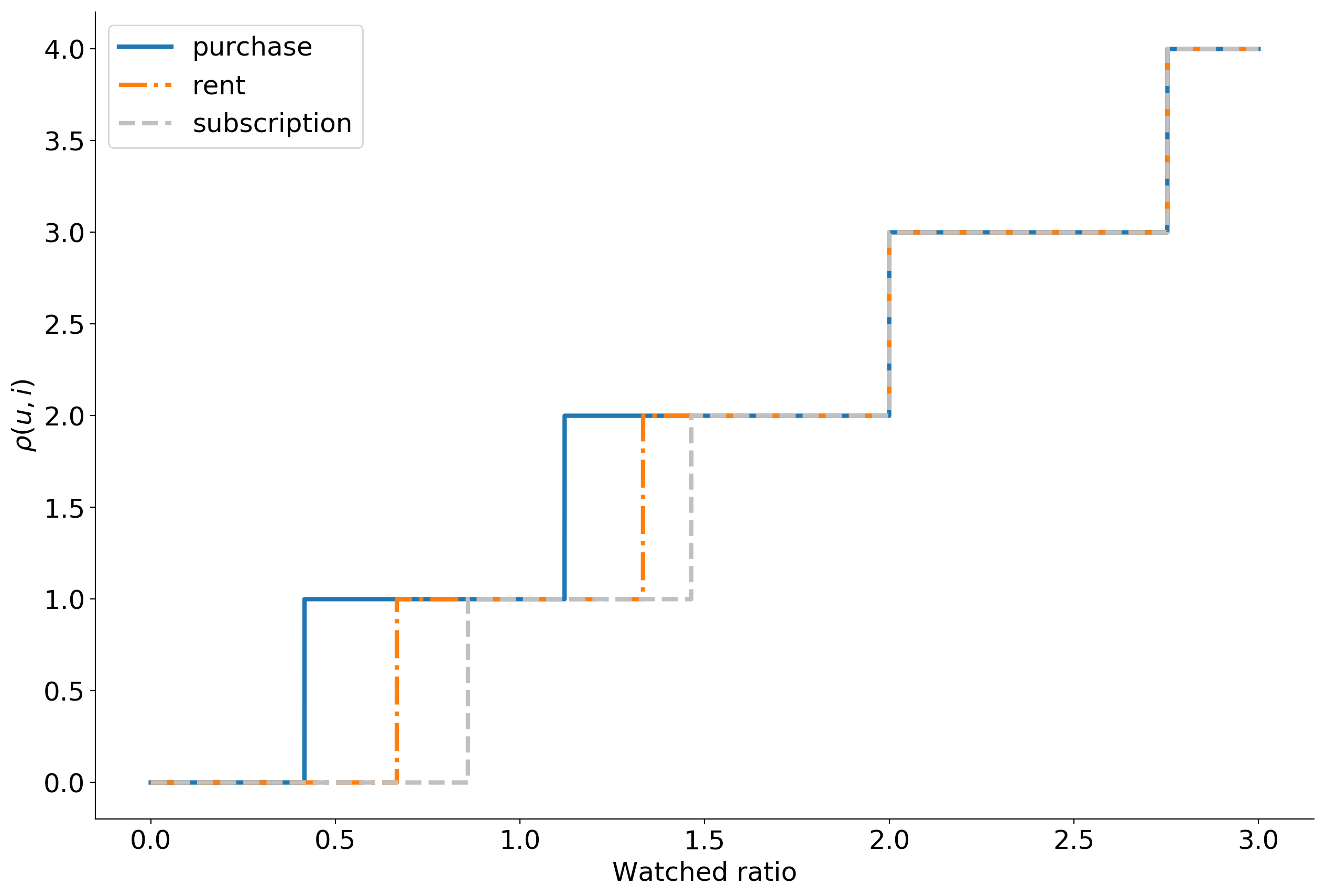
En même temps , , .
, Cython , LightFM .
:

, top-N : . , Approximate nearest neighbor algorithm based on navigable small world graphs .
, , , , . , - , . : , .
Ces problèmes sont évités par les modèles de contenu. Ils sont puissants, expressifs et vous pouvez y coller tous les signes, mais ils sont extrêmement lents. La solution consiste à exécuter le modèle de contenu non pas sur tous les éléments, mais sur des candidats issus de la décomposition matricielle. Il peut y avoir autant de candidats que vous parvenez à traiter, mais de préférence au moins deux fois plus que vous montrez aux utilisateurs. Dans notre cas, pour les 100 films recommandés, la meilleure solution était d'utiliser 400 candidats.

Les attributs que nous soumettons au modèle de contenu peuvent être divisés en trois groupes: attributs utilisateur, attributs d'élément et signes d'interaction. Au total, environ 50 signes sont obtenus.
En tant que signes d'utilisateurs, nous utilisons des statistiques agrégées de leur comportement dans le service, par exemple:
- Pourcentage de vue d'abonnement
- distribution d'appareils à partir desquels l'utilisateur se connecte à l'application,
- durée de vie dans le service,
- etc.
Pour les films, nous utilisons presque toutes les méta-informations disponibles: genre, année de sortie, pays, acteur, réalisateur, limite d'âge, etc. Les mesures commerciales agrégées sont également utiles: pourcentage de visites sur la carte, nombre de vues, ajouts aux favoris, distribution par des méthodes de visualisation, des appareils, etc.
Les signes d'interaction incluent la vitesse de l'étape de sélection des candidats et des statistiques agrégées pour toutes les interactions précédentes avec les utilisateurs et les films avec la participation des mêmes acteurs, réalisateurs et scénaristes que le film en question.
La question la plus courante qui se pose lorsqu'il s'agit de classer les candidats avec un modèle de deuxième niveau est de savoir comment former ce modèle. Dans le cas de la factorisation matricielle seule, nous avions besoin de deux ensembles, séparés par le temps - formation et test. Dans le cas d'un système en deux étapes, nous en aurons besoin de trois - deux formations et un test.
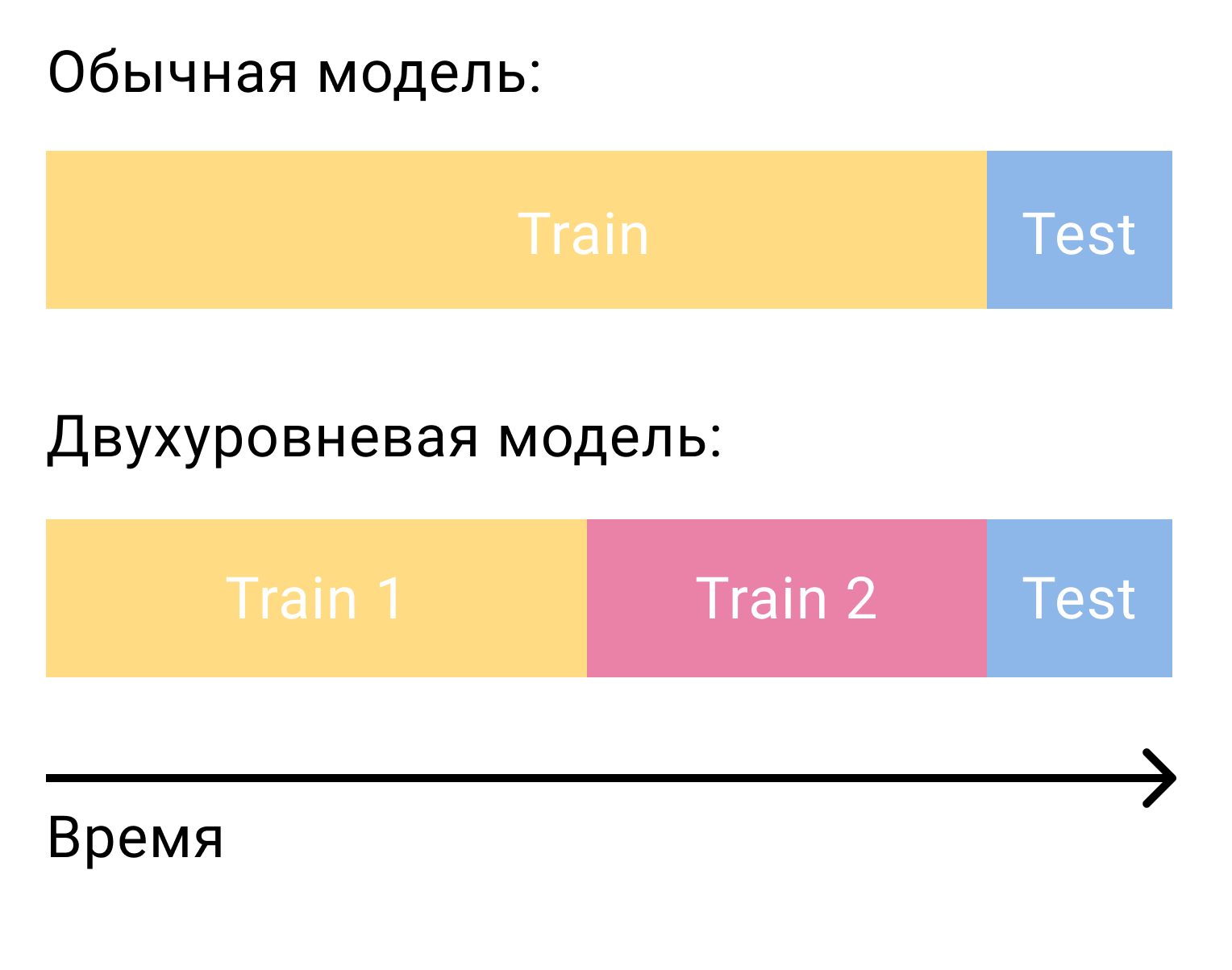
Lors de la première formation, nous formerons le modèle de premier niveau et formerons des candidats. Des candidats, il est important d'exclure les éléments avec lesquels l'utilisateur a interagi dans cet ensemble. Ensuite, nous verrons avec quels candidats l'utilisateur a interagi dans le deuxième ensemble de formation. Nous les appelons positifs et les candidats restants négatifs. Ce sera notre ensemble de formation pour le modèle de contenu.
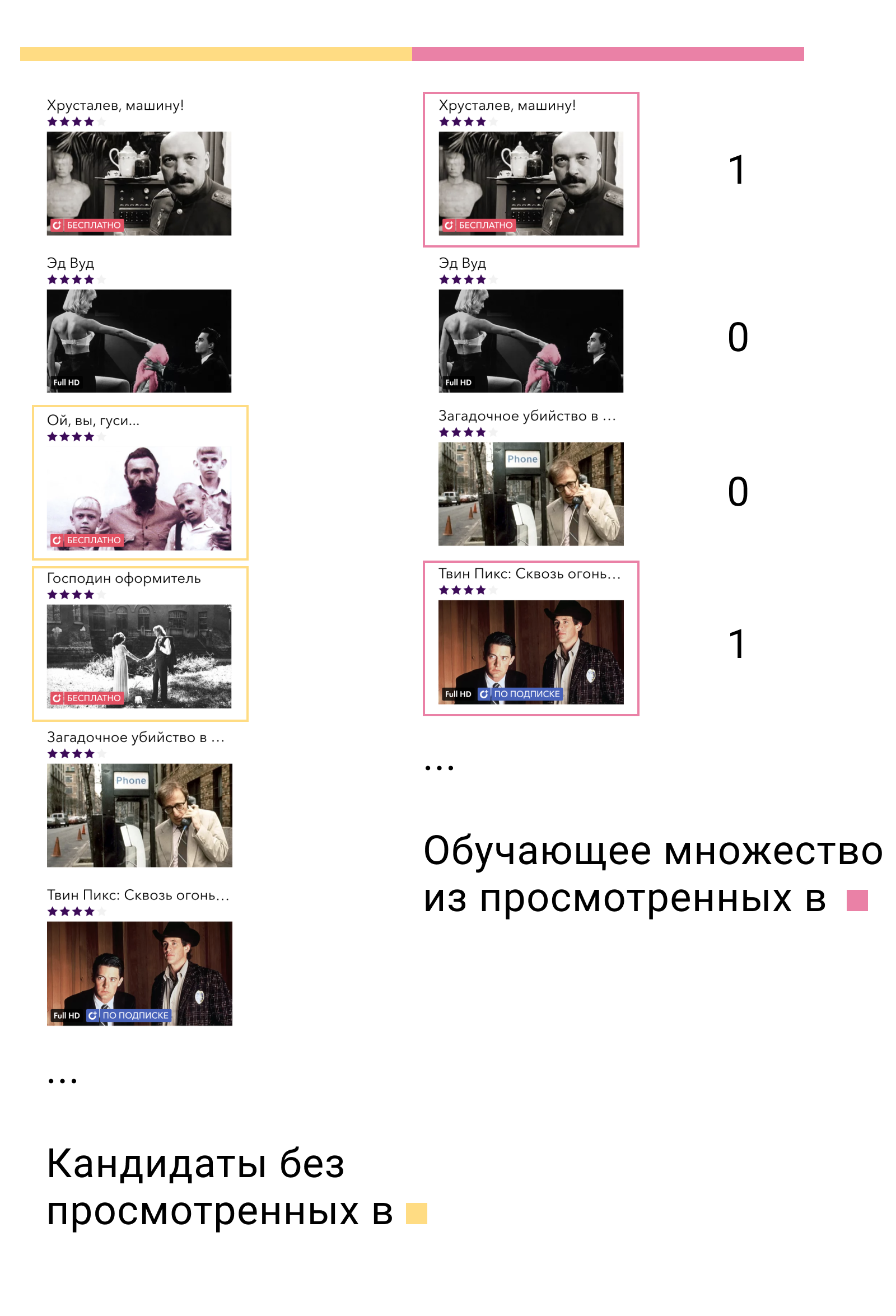
Pourquoi ça marche? Premièrement, nous formons le modèle exactement sur les données sur lesquelles il sera utilisé - la sortie du modèle de premier niveau. Deuxièmement, parmi tous les exemples négatifs possibles, nous prenons les plus complexes - ceux que le modèle de premier niveau considère comme pertinents pour l'utilisateur, mais ils ne le sont pas.
Et ensuite? La solution la plus simple et la plus évidente consiste à résoudre le problème de classification binaire, puis à trier les éléments par ordre décroissant de probabilité pour être un exemple positif. Mais nous pouvons à nouveau rappeler l'énoncé du problème de la construction d'un système de recommandation, comprendre que la classification binaire n'est pas le problème que nous résolvons et passer à nouveau au problème de classement.
Dans XGBoost et LightGBM, la fonction de perte principale pour les tâches de classement est LambdaMART. Si vous n'entrez pas dans les détails, l'intuition sous-jacente est assez simple. Si - sortie modèle par exemple , puis la probabilité que l'élément aura un rang supérieur à l'élément sera égal
La fonction de perte peut alors s'écrire comme suit.
voici la vraie probabilité de classement. Nous le définirons comme 1 si , 0 si et 0,5 dans le cas .
Un modèle à deux niveaux donne une augmentation de 50% des mesures par rapport à un modèle à un niveau. La fonction de perte de classement ajoute 10% supplémentaires.
Bonus: films liés
Rappelez-vous, dans les avantages de notre approche, j'ai mentionné les vecteurs «libres» de la factorisation matricielle qui peuvent être utilisés pour résoudre des problèmes connexes? Ainsi, l'une de ces tâches - la recherche de films similaires - nous avons décidé.
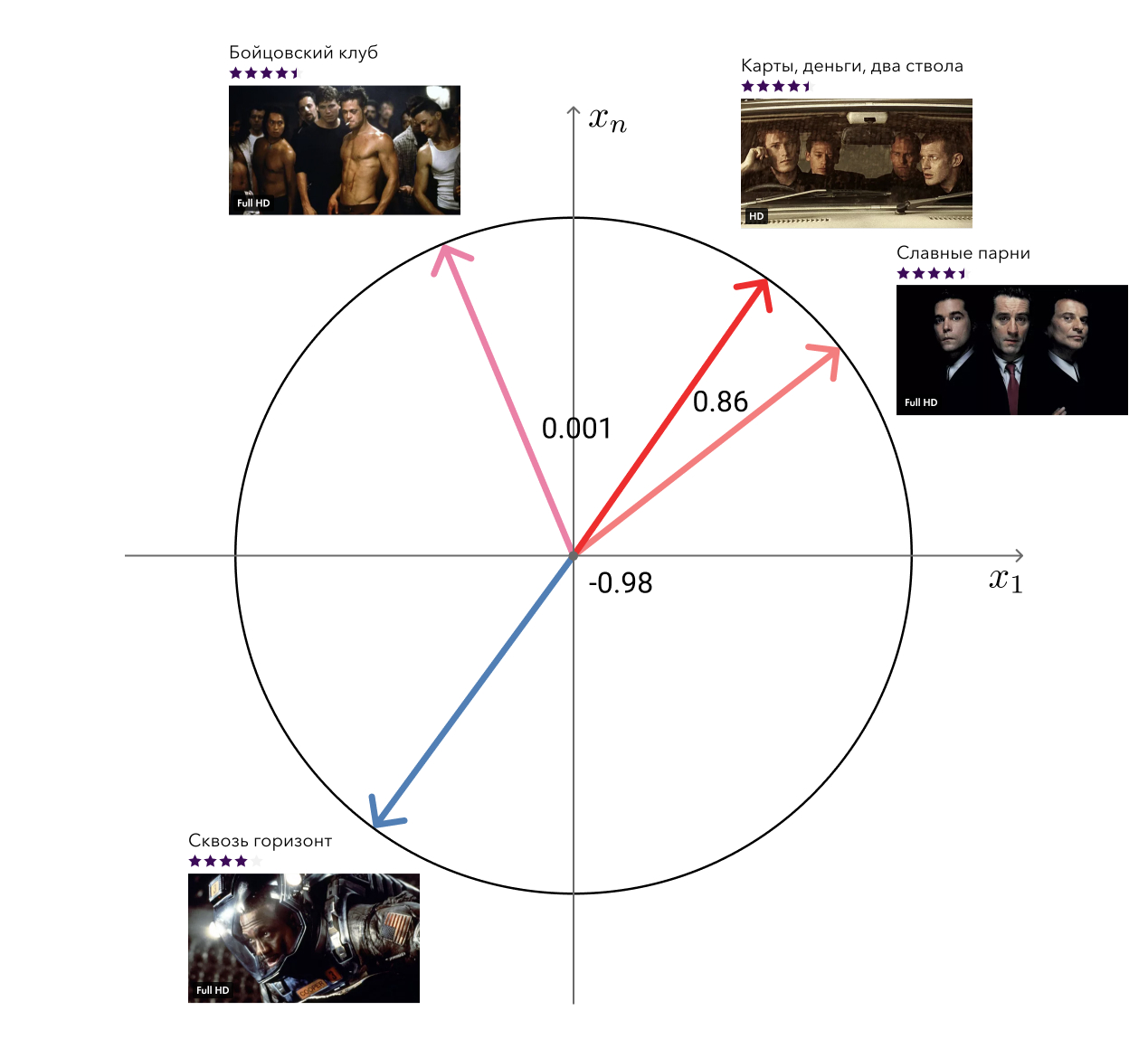
La solution à la honte est simple: pour chaque film, nous prenons son vecteur et recherchons les plus proches en cosinus. Il semble tout à fait adéquat à l'œil. Le niveau suivant consiste à ajouter des méta-informations et à utiliser des algorithmes graphiques.

Implémentation technique
En plus de la partie algorithmique, je veux parler un peu de l'implémentation. Rekko se compose de trois composants: lynch, rekko-tasks et rekko-service.
Lynch s'exécute sur une machine puissante, se réveille périodiquement, prépare les données pour le microservice et les place dans S3.
Les microservices rekko-tasks et rekko-service se trouvent dans l'environnement du produit Okko, ainsi que tous les autres microservices et bases de données. Le premier d'entre eux surveille constamment S3 pour les changements, le cas échéant, les télécharge et les met dans les bases d'épicerie. Le deuxième microservice utilise ces résultats calculés afin de répondre en temps réel aux demandes des utilisateurs et de calculer leurs recommandations.

Les microservices sont écrits en Python en utilisant Falcon, Gunicorn et Gevent et ne représentent rien d'intéressant, sauf pour la logique métier. Comme tous les autres microservices de l'environnement du produit Okko, ils sont fermés par l'équilibreur.
Lynch est beaucoup plus intéressant.
Que faut-il faire pour calculer la prochaine partie des recommandations pour les utilisateurs? Au moins:
- Téléchargez les nouvelles données apparues depuis le dernier recomptage;
- Traitez-les;
- Former la factorisation matricielle;
- Construire des candidats
- Réorganiser les candidats;
- Appliquer des règles métier
- Déchargez.
Il semble que cela ne semble pas effrayant, vous pouvez mettre chaque partie dans une fonction distincte et simplement les appeler à tour de rôle:
data = extract_data() data = transform_data(data) mf_model = train_mf_model(data) candidates = build_candidates(mf_model) predictions = build_predictions(content_model, candidates) upload_predictions(predictions)
Eh bien, tout a fait du bon travail, sommes-nous en désaccord? Pas vraiment. Mais que faire si toute la feuille tombe quelque part? Eh bien, par exemple, en raison d'un manque de mémoire. Nous devrons tout recommencer, même si nous avons déjà passé quelques heures à former le modèle et à construire des candidats.
Eh bien, sauvegardons tous les résultats intermédiaires dans des fichiers, et après la chute, vérifions ceux qui existent déjà, restaurons l'état et commençons les calculs au bon moment. En fait, cette idée est encore pire que la précédente. Un programme peut être interrompu au cours de l'écriture dans un fichier, et bien qu'il existe, il sera dans un état incorrect. Dans le meilleur des cas, tout le calcul tombera; dans le pire, il se terminera avec un mauvais résultat.
Ok, écrivons dans le fichier atomique. Et nous supprimons chaque fonction dans une entité distincte et indiquons les dépendances entre elles. Le résultat est une chaîne de calculs dont chaque élément peut être effectué ou non.

Déjà pas mal. Mais en réalité, tous les calculs nécessaires ne seront guère décrits par une liste. L'apprentissage de la factorisation matricielle nécessitera non seulement des données de transaction, mais aussi des évaluations des utilisateurs, les candidats à la construction auront besoin d'une liste de films mémorisés pour les exclure, le calcul de films similaires nécessitera une factorisation matricielle et des méta-informations du catalogue, etc. Nos tâches ne sont plus construites dans une liste simplement connectée, mais dans un graphe orienté sans cycles (graphe acyclique dirigé, DAG).

DAG est une organisation informatique extrêmement populaire. Il existe deux principaux cadres pour la construction d'un DAG: Airflow et Luigi . Chez Okko, nous nous sommes installés sur ce dernier. Luigi est développé chez Spotify, se développe activement, est entièrement écrit en python, est facilement extensible et vous permet d'organiser les calculs de manière très flexible.
Une tâche dans Luigi est définie par une classe qui hérite de luigi.Task et implémente trois méthodes requises: luigi.Task , output et run . Voici à quoi ressemble une tâche typique:
Luigi s'assurera que les tâches sont exécutées dans le bon ordre sans dépasser la consommation des ressources disponibles. Si les tâches peuvent être effectuées en parallèle, il les exécutera en parallèle, maximisant l'utilisation du processeur et minimisant le temps d'exécution global. Si une tâche échoue, il la redémarrera plusieurs fois et en cas d'échec nous en informera. Dans ce cas, toutes les tâches pouvant être effectuées seront exécutées. Cela signifie, par exemple, qu'une erreur dans la tâche de classement des candidats n'empêche pas de compter et de télécharger une liste de films similaires.
Actuellement, Lynch se compose de 47 tâches uniques, produisant environ 100 de ses copies. Certains d'entre eux sont occupés à travailler directement, certains comptent les métriques et les envoient à notre outil Splunk BI. Lynch nous envoie également périodiquement des statistiques de base et des rapports sur son travail par télégramme. Il écrit également sur les erreurs, mais en PM.
Suivi, répartition et résultats

La première règle de la Data Science: Ne parlez à personne des salaires en Data Science. Deuxième règle de la Data Science: ce qui ne peut pas être mesuré ne peut pas être amélioré.
Nous essayons de garder une trace de tout. Tout d'abord, cela, bien sûr, le classement des métriques sur les données historiques. Ils aident même au stade de la recherche à choisir le meilleur modèle parmi plusieurs et à choisir des hyper paramètres pour celui-ci.
Pour les modèles travaillant en production, nous considérons également les métriques, mais déjà au jour le jour. De telles métriques sont assez volatiles, mais elles peuvent le dire si le modèle se dégrade soudainement pour une raison quelconque. Lorsqu'un nouveau modèle est lancé dans la prod, vous pouvez le laisser inactif pendant une semaine et vous assurer que les métriques ne s'affaissent pas. Après cela, vous pouvez l'activer pour certains utilisateurs, exécuter le test A / B et surveiller les mesures commerciales déjà.

De plus, nous considérons la distribution des recommandations par genre, pays, année, type, etc. Cela nous permet de comprendre la nature actuelle des préférences des utilisateurs, de les comparer avec des données de visualisation réelles et de détecter les erreurs dans les règles commerciales.

Il est également important de garder une trace de la distribution de tous les caractères utilisés. Un changement brutal peut être causé par une erreur dans la source de données et conduire à des résultats imprévisibles.
Mais, bien sûr, la chose la plus importante qui nécessite une attention particulière est les mesures commerciales. Dans le cadre du système de recommandations, les principales mesures commerciales pour nous sont:
- Revenus des modèles de consommation transactionnelle et d'abonnement (revenus TVOD / SVOD);
- Revenu moyen par visiteur (revenu moyen par visiteur, ARPV);
- Le chèque moyen (prix moyen par achat, APPP);
- Achats moyens par utilisateur (APPU);
- Conversion à l'achat (CR à l'achat);
- Conversion en vue par abonnement (CR à regarder);
- Conversion pendant la période d'essai (CR en essai).
Dans le même temps, nous examinons séparément les métriques des sections «Recommandations» et «Similaire» et les métriques de l'ensemble du service afin de prendre en compte l'effet de redistribution et de considérer la situation sous différents angles.
Cela peut ressembler à un tableau de bord comparant plusieurs modèles:

Comme je l'ai dit au début, nous comparons non seulement les modèles entre eux, mais aussi un groupe d'utilisateurs avec des recommandations par rapport à un groupe d'utilisateurs sans recommandations. Cela nous permet d'évaluer l'effet net de la mise en œuvre de Rekko et de comprendre où nous en sommes actuellement et quelle marge d'amélioration reste. Selon ce test A / B, nous avons actuellement:
- ARPV + 3,5%
- ARPV avec marge + 5%
- APPU + 4,3%
- CR à l'essai + 2,6%
- CR à surveiller + 2,5%
- APPP -1%
Les films d'un cinéma en ligne peuvent être divisés en deux groupes: les nouveaux éléments et les anciens contenus. Nous savons déjà comment vendre de bonnes nouvelles. Le but principal des recommandations personnelles est d'obtenir du contenu ancien pertinent pour les utilisateurs du catalogue. Cela conduit à une augmentation du nombre d'achats et de l'affaissement du chèque moyen, car un tel contenu est naturellement moins cher. Mais un tel contenu a également une marge élevée, ce qui compense l'affaissement du chèque et donne une augmentation des revenus.
Un contenu d'abonnement plus pertinent a entraîné une augmentation des conversions pendant la période d'essai et une visualisation par abonnement.
Défi Rekko
Du 18 février au 18 avril 2019, en collaboration avec la plateforme Boosters, nous avons organisé le Rekko Challenge, où nous avons invité les participants à créer un système de recommandation basé sur des données de produit anonymisées.

On s'attend à ce que les participants qui ont construit un système à deux niveaux semblable au nôtre soient parmi les premiers. Les gagnants qui ont pris les première et troisième places ont réussi à compléter l'ensemble RNN. Et le participant de la huitième place a réussi à grimper dessus en utilisant uniquement des modèles de filtrage collaboratif.
Evgeni Smirnov, qui a pris la deuxième place du concours, a écrit un article dans lequel il parlait de sa décision.
À l'heure actuelle, le concours est disponible sous la forme d'un bac à sable, de sorte que tous ceux qui sont intéressés par les systèmes de recommandation peuvent s'y essayer et acquérir une expérience utile.
Conclusion
Avec cet article, je voulais vous montrer que les systèmes de recommandation en production ne sont pas du tout difficiles, mais amusants et rentables. L'essentiel est de penser aux objectifs, pas aux moyens de les atteindre et de tout mesurer en permanence.
Dans de futurs articles, nous vous en dirons encore plus sur la cuisine intérieure Okko, alors n'oubliez pas de vous abonner et d'aimer.