Présentation
Lorsque vous effectuez une analyse CWT à l'aide de la bibliothèque PyWavelets (un logiciel open source gratuit publié sous la licence MIT), il y a des problèmes avec la visualisation du résultat. Le
programme de test de visualisation proposé par les développeurs est présenté dans la liste suivante:
Annonceimport pywt import numpy as np import matplotlib.pyplot as plt t = np.linspace(-1, 1, 200, endpoint=False) sig = np.cos(2 * np.pi * 7 * t) + np.real(np.exp(-7*(t-0.4)**2)*np.exp(1j*2*np.pi*2*(t-0.4))) widths = np.arange(1, 31) cwtmatr, freqs = pywt.cwt(sig, widths, 'cmor1-1.5') plt.imshow(cwtmatr, extent=[-1, 1, 1, 31], cmap='PRGn', aspect='auto', vmax=abs(cwtmatr).max(), vmin=-abs(cwtmatr).max())
Lorsque vous travaillez avec des ondelettes complexes, par exemple avec 'cmor1-1.5', le programme génère une erreur:
File"C:\Users\User\AppData\Local\Programs\Python\Python36\lib\site-packages\matplotlib\image.py", line 642, in set_data raise TypeError("Image data cannot be converted to float") TypeError: Image data cannot be converted to float
Cette erreur, ainsi que les difficultés à choisir l'échelle (largeurs) pour fournir la résolution de temps nécessaire, rendent difficile, en particulier pour les utilisateurs novices, d'étudier l'analyse CWT, ce qui m'a incité à écrire cet article à caractère pédagogique.
Le but de cette publication est d'envisager l'utilisation du nouveau
module de visualisation de
scalogrammes pour l'analyse de signaux simples et spéciaux, ainsi que lors de l'utilisation de méthodes de normalisation, de mise à l'échelle logarithmique et de synthèse, qui fournissent des informations supplémentaires dans l'analyse des séries chronologiques.
L'article utilisait des informations de la publication
«Une douce introduction aux ondelettes pour l'analyse des données» . Dans les listes d'exemples données dans la publication, les erreurs sont corrigées et chaque liste de l'exemple est ramenée à sa forme finale, ce qui permet de l'utiliser sans se familiariser avec les précédentes. Pour l'analyse en ondelettes de signaux spéciaux, les données de la base de données d'
échantillons PyWavelets ont été utilisées.
Un scalogramme en ondelettes est une représentation bidimensionnelle de données unidimensionnelles. Le temps est tracé sur l'axe X, et une échelle est affichée sur l'axe Y - le résultat de la transformation en ondelettes du signal correspondant à l'amplitude du signal au temps X. La valeur analytique d'un tel affichage graphique du signal est que la résolution temporelle est affichée sur l'axe Y, ce qui donne des informations supplémentaires sur les propriétés dynamiques du signal.
Ondelette - Scalogrammes de signaux simples
1. Onde cosinus avec une enveloppe gaussienne (remplacement des ondelettes. Vous pouvez étudier la dépendance de la résolution temporelle sur l'échelle):
Annonce from numpy import* from pylab import* import scaleogram as scg import pywt
Fonction ondelettes pour la conversion du signal: cmor1-1.5 (ondelettes Morlet complexes)


Le signal périodique apparaît désormais sous la forme d'une bande continue horizontale au point Y = p1, dont l'intensité varie en fonction de l'amplitude du signal périodique.
Il y a un certain flou dans la détection, car la bande passante n'est pas égale à zéro, cela est dû au fait que les ondelettes ne détectent pas une fréquence, mais plutôt une bande. Cet effet est associé à la largeur de bande des ondelettes.
2. Trois impulsions sont ajoutées séquentiellement avec une période croissante (pour considérer les variations périodiques à différentes échelles: analyse multi-résolution):
Annonce from numpy import* import pandas as pd from pylab import* import scaleogram as scg

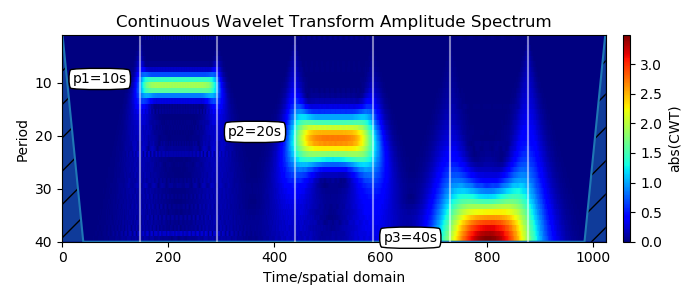
Des impulsions apparaissent à l'endroit attendu Y, correspondant à leur périodicité, elles sont localisées en fréquence et en temps. Le début de la bande et la fin correspondent à l'élan.
La bande passante évolue avec la longueur de la période. C'est une propriété bien connue de la transformée en ondelettes: lorsque l'échelle augmente, la résolution temporelle diminue. Ceci est également connu comme le compromis entre le temps et la fréquence. Lorsque vous regardez un spectrogramme de ce type, vous faites beaucoup d'analyses de résolution.
3. Trois oscillations périodiques de fréquences différentes en même temps (Wavelet - l'analyse est capable de distinguer les composantes du signal par fréquence, si leurs différences sont significatives):
Annonce from numpy import* import pandas as pd from pylab import* import scaleogram as scg scg.set_default_wavelet('cmor1-1.5')


4. Un signal périodique non sinusoïdal (La différence dans les transformations en ondelettes d'un signal d'onde triangulaire avec une période de 30 secondes par rapport à celles précédemment considérées est considérée):
Annonce from numpy import* from pylab import* import scipy.signal import scaleogram as scg scg.set_default_wavelet('cmor1-1.5')

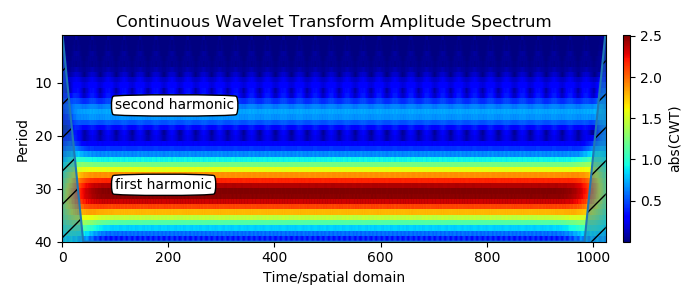
Une large bande est la première harmonique. La deuxième harmonique est visible exactement à la moitié de la valeur de la période de la première harmonique. C'est le résultat attendu pour les signaux périodiques non sinusoïdaux. Des éléments verticaux flous apparaissent autour de la deuxième harmonique, qui est plus faible et a une amplitude de 1/4 de la première pour une forme d'onde triangulaire.
5. Les impulsions lisses (gaussiennes) sont similaires aux structures de données réelles. (Cet exemple montre comment utiliser l'analyse en ondelettes pour détecter les changements de signal localisés au fil du temps):
Une série d'impulsions lisses avec différentes valeurs sigma:
Largeur d'impulsion:
Annonce from numpy import* from pylab import* import scaleogram as scg scg.set_default_wavelet('cmor1-1.5')

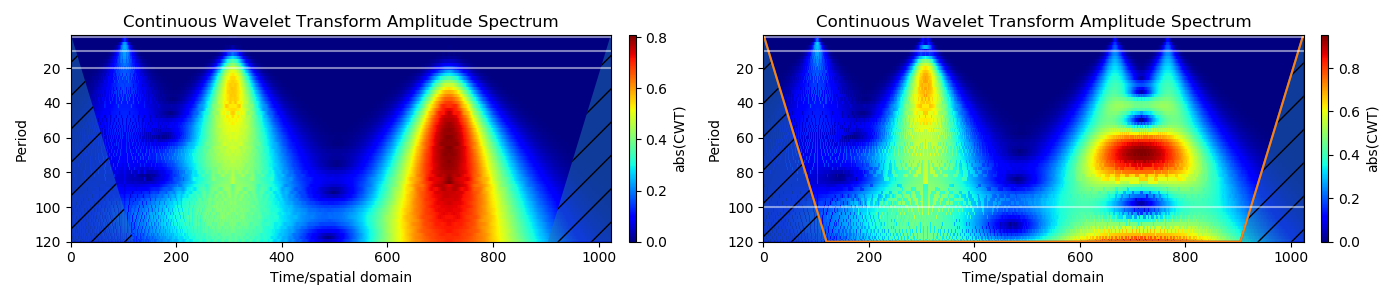
Des impulsions discrètes créent des structures coniques sur le sialogramme, également connues sous le nom de cône d'influence. Les impulsions lisses (gaussiennes) sont similaires aux structures de données réelles et créent des cônes s'étendant vers de grandes échelles. Les lignes de guidage horizontales correspondent approximativement à des périodes de temps (2 s, 10 s, 20 s). Par conséquent, l'impulsion est similaire à un signal périodique avec une période.
6. Bruit (afficher le bruit sur le sialogramme):
Annonce from numpy import* from pylab import* import scaleogram as scg import random scg.set_default_wavelet('cmor1-1.5')


Le bruit est généralement affiché sous la forme d'un ensemble d'éléments et certaines irrégularités peuvent ressembler à des objets de données réelles.Par conséquent, lorsque vous utilisez des données réelles, vous devez être prudent et, si nécessaire, vérifier le niveau de bruit. L'horaire supérieur sera différent à chaque démarrage du programme.
Formes d'onde spéciales du signal ondelette
La base de données PyWavelets contient vingt signaux spéciaux de transformée en ondelettes qui seront utiles à la fois pour l'étude et le développement. Par conséquent, je vais donner une liste qui vous permet d'effectuer une analyse en ondelettes des vingt signaux:
Je ne donnerai qu'un seul résultat de la transformée en ondelettes du signal Doppler:
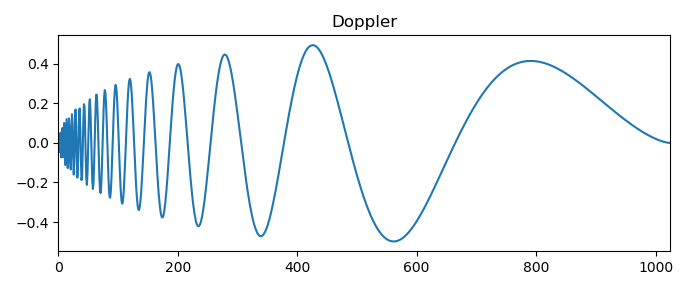

Les variétés les plus courantes de signaux simples et spéciaux sont considérées, ce qui nous permet de passer à l'utilisation d'un scalogramme pour résoudre certains problèmes d'analyse de séries chronologiques.
Scalogrammes de chronologie d'ondelettes
1. Données de fécondité des CDC aux États-Unis 1969-2008 (les données de fécondité contiennent des caractéristiques périodiques, à la fois sur une échelle annuelle et sur une échelle plus petite):
Annonce import pandas as pd import numpy as np from pylab import* import scaleogram as scg from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()


Une ligne horizontale apparaît avec une fréquence d'environ 7 jours. Des valeurs élevées apparaissent près des bordures de l'échelle, ce qui est le comportement normal du traitement en ondelettes. Ces effets sont bien connus comme un cône d'influence, c'est pourquoi un masque (facultatif) recouvre cette zone.
2. Normalisation (la suppression de la valeur moyenne -
births_normed = births-births.mean () est obligatoire, sinon les limites des données sont considérées comme des étapes qui créent beaucoup de fausses détections en forme de cône):
Annonce import pandas as pd import numpy as np from pylab import* import scaleogram as scg from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()
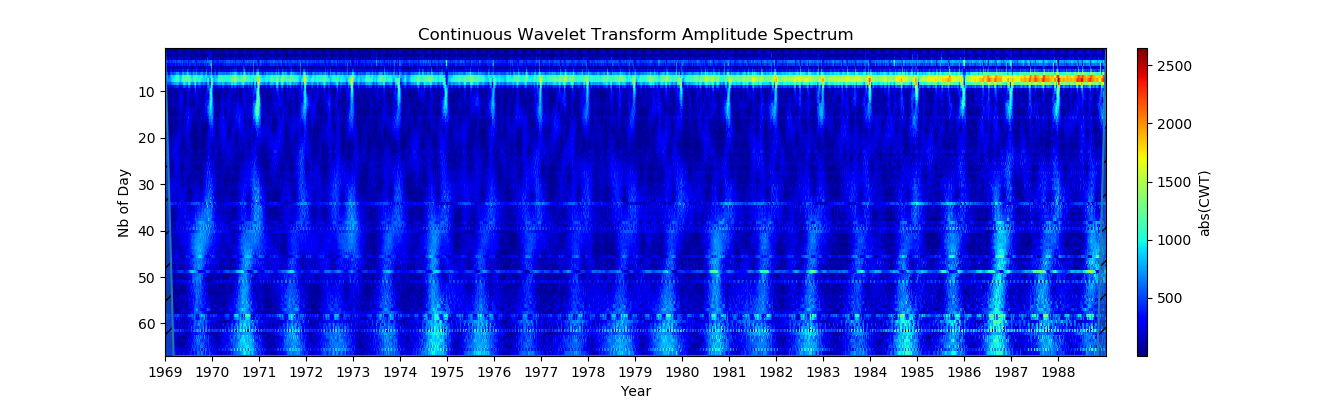
3. Changement d'échelle d'amplitude (pour voir les objets annuels, en utilisant
period2scales () l' échelle le long de l'axe Y est spécifiée).
Annonce import pandas as pd import numpy as np from pylab import* import scaleogram as scg from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()
La plage d'amplitude de la carte des couleurs (axe Y) est désormais définie par clim = (0,2500). La valeur exacte de l'amplitude d'oscillation dépend de l'ondelette, mais restera proche de l'ordre de la valeur réelle. C'est bien mieux, maintenant on voit très bien la variation annuelle, ainsi qu'environ 6 mois!
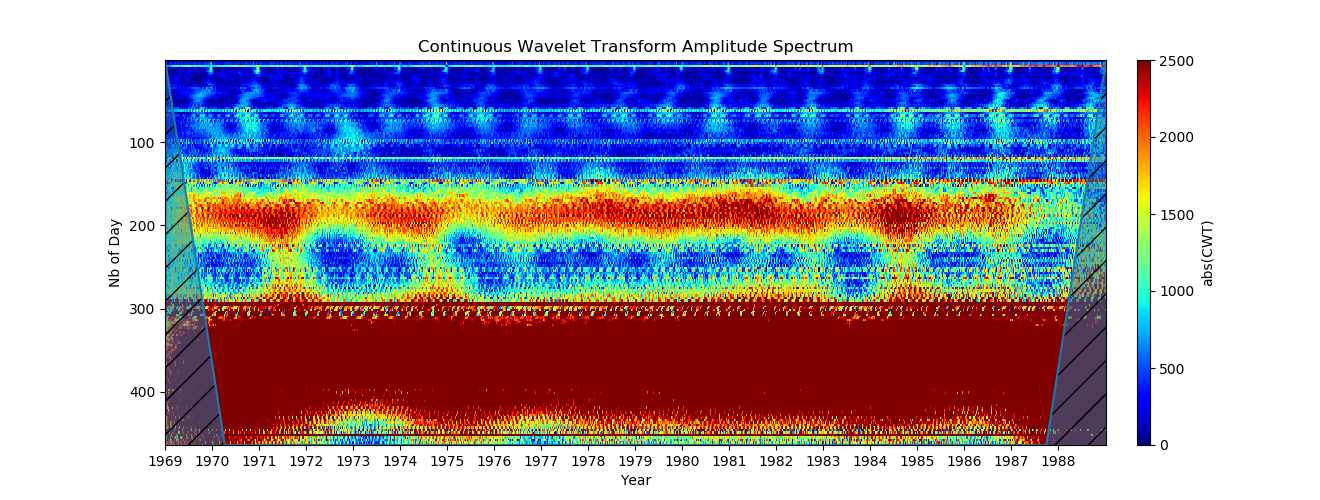
4. Utilisation de l'échelle logarithmique (Afin de pouvoir voir des périodes petites et grandes en même temps, il est préférable d'utiliser l'échelle logarithmique sur l'axe Y. Ceci est réalisé en utilisant l'option xscale = log.)
Annonce import pandas as pd import numpy as np from pylab import* import scaleogram as scg from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()

Le résultat est bien meilleur, mais maintenant les pixels à de faibles valeurs de périodes sont allongés le long de l'axe Y.
5. Distribution uniforme sur une échelle logarithmique (Pour obtenir une distribution uniforme sur une échelle, les valeurs de période doivent être uniformément réparties puis converties en valeurs d'échelle, comme indiqué ci-dessous :):
Annonce import pandas as pd import numpy as np from pylab import* import scaleogram as scg from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()
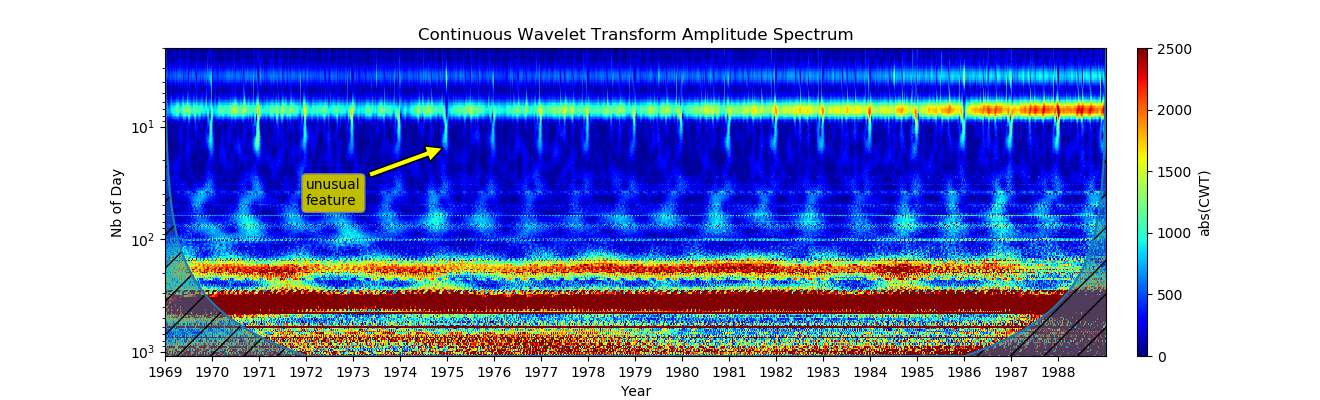
Nous pouvons voir des changements de signal à toutes les échelles. Le sialogramme montre chaque année en périodes égales.
6. Mise en évidence d'une partie de la chronologie (vérification des données intermédiaires entre les marques de chronologie à la recherche d'artefacts ou de données manquantes.):
Annonce import pandas as pd import numpy as np from pylab import* import scaleogram as scg import pywt from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()
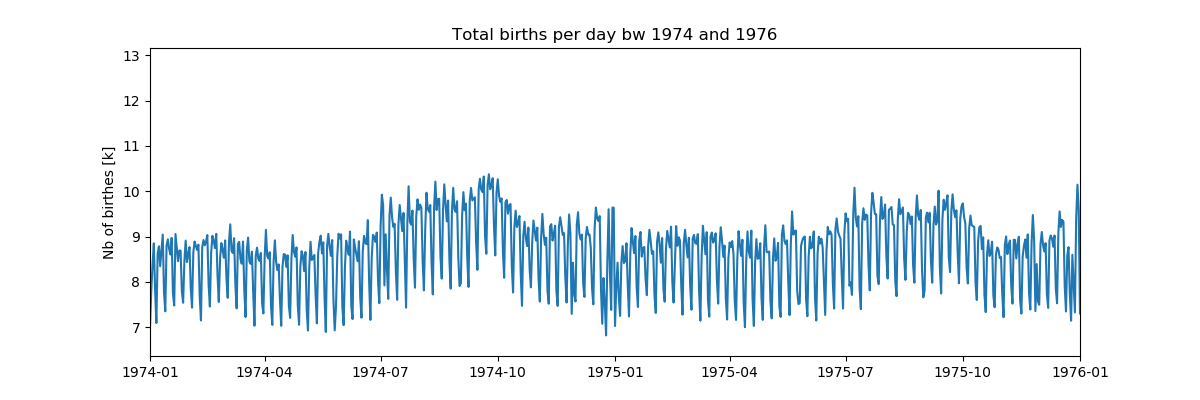
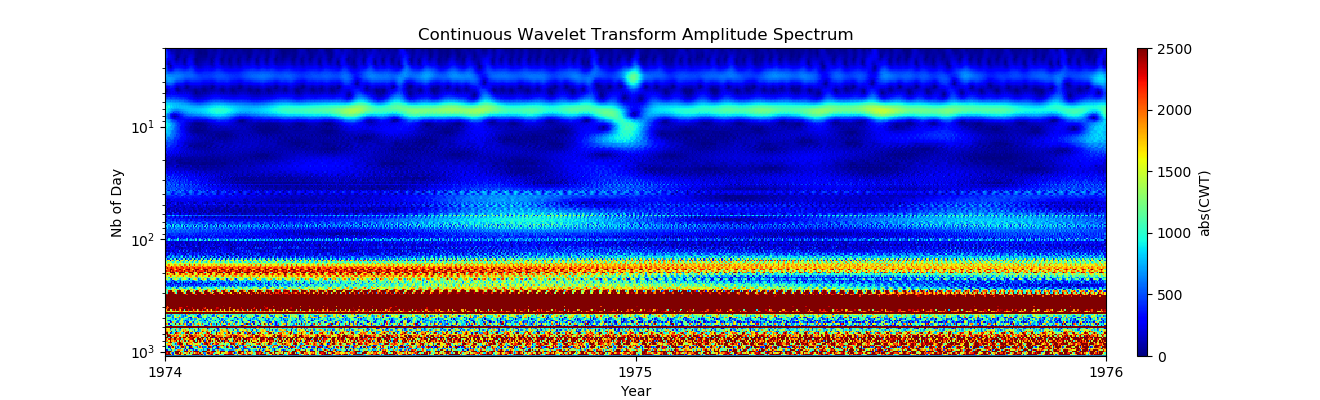 À première vue, les modèles hebdomadaires semblent très uniformes, mais quelque chose se passe le jour de Noël, regardons à nouveau cette période:
À première vue, les modèles hebdomadaires semblent très uniformes, mais quelque chose se passe le jour de Noël, regardons à nouveau cette période:Annonce import pandas as pd import numpy as np from pylab import* import scaleogram as scg import pywt from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()

 Maintenant, il est clair que c'est l'effet de la fin de l'année:
Maintenant, il est clair que c'est l'effet de la fin de l'année:- Noël: le 23/24/25 décembre montre un nombre anormalement bas de naissances, et ces jours s'écartent de l'horaire hebdomadaire;
- Il existe des données pour décembre, ce qui est cohérent avec la présence d'une certaine valeur pour les dates concernées les 1er et 2 janvier, ces dates sont généralement inférieures aux événements personnels
7. Synthèse (un sialogramme est construit à partir de données normalisées, avec une meilleure lisibilité pour toutes les échelles):Annonce import pandas as pd import numpy as np from pylab import* import scaleogram as scg import pywt from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()
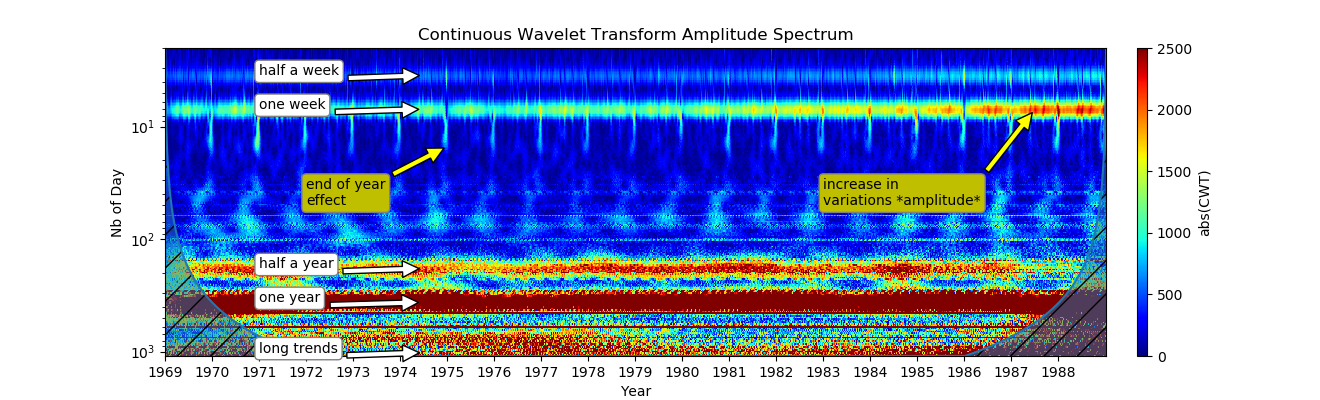 CWT révèle beaucoup d'informations en peu de temps:une variation hebdomadaire montrant les habitudes hospitalières est présente depuis plusieurs décennies;Dans les années 80, l'indicateur hebdomadaire a augmenté, ce qui peut être dû à un changement des habitudes de travail des hôpitaux, à un changement de la fécondité ou à un simple changement de population;La deuxième bande semestrielle est clairement la deuxième harmonique. Des motifs flous apparaissent dans la zone de 3 à 1 mois, ce qui peut être dû à la troisième harmonique, car les fluctuations annuelles sont si fortes. Elle peut également être causée par l'effet des vacances sur la fertilité et peut nécessiter un complément d'étude;L'effet de fin d'année a été constaté à Noël et au 1er janvier. Celui-ci peut être resté invisible avec une autre méthode de fréquence.
CWT révèle beaucoup d'informations en peu de temps:une variation hebdomadaire montrant les habitudes hospitalières est présente depuis plusieurs décennies;Dans les années 80, l'indicateur hebdomadaire a augmenté, ce qui peut être dû à un changement des habitudes de travail des hôpitaux, à un changement de la fécondité ou à un simple changement de population;La deuxième bande semestrielle est clairement la deuxième harmonique. Des motifs flous apparaissent dans la zone de 3 à 1 mois, ce qui peut être dû à la troisième harmonique, car les fluctuations annuelles sont si fortes. Elle peut également être causée par l'effet des vacances sur la fertilité et peut nécessiter un complément d'étude;L'effet de fin d'année a été constaté à Noël et au 1er janvier. Celui-ci peut être resté invisible avec une autre méthode de fréquence.Conclusions:
Dans cette publication, nous avons vu comment la forme de base des variations de signal se traduit par un scalogramme. Un exemple d'ensemble de données ordonné dans le temps a ensuite été utilisé pour montrer étape par étape comment CWT est appliqué aux données standard.La technique ci-dessus peut être étendue pour analyser le trafic réseau et détecter le comportement inhabituel des objets. CWT est un outil puissant qui est de plus en plus utilisé comme entrée pour les réseaux de neurones et peut être utilisé pour créer de nouvelles fonctions pour classer ou détecter les anomalies.Chaque exemple est implémenté comme un programme indépendant, ce qui vous permet de choisir un exemple pour votre tâche, sans plonger dans les exemples précédents et suivants. L'utilisateur peut essayer n'importe quelle fonction ondelette de la liste donnée au début de chaque programme, par exemple, mexh ou gaus5. Par exemple 1, respectivement:
 PS Pour l'utilisation pratique des listes, je donnerai les versions des modules utilisés:
PS Pour l'utilisation pratique des listes, je donnerai les versions des modules utilisés: >>> import scaleogram; print(scaleogram .__version__) 0.9.5 >>> import pandas; print(pandas .__version__) 0.24.1 >>> import numpy; print(numpy .__version__) 1.16.1 >>> import matplotlib; print(matplotlib .__version__) 3.0.2
Pour un ensemble indépendant de données dans le fichier * .csv, j'apporte la structure des données (dans une colonne):année, mois, jour, sexe, naissances1969,1,1, F, 40461969,1,1, M, 44401969,1,2 , F, 44541969.1.2, M, 4548...
Pour les pandas de la version 0.24.1, vous devrez enregistrer explicitement les convertisseurs matplotlib.Pour enregistrer des convertisseurs: from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()