Bonjour collègues!
Peut-être que le titre de la publication d'aujourd'hui aurait été meilleur avec un point d'interrogation - c'est difficile à dire. Dans tous les cas, nous voulons aujourd'hui vous offrir une brève visite qui vous présentera la bibliothèque
Dask , conçue pour paralléliser les tâches en Python. Nous espérons revenir plus en détail sur ce sujet à l'avenir.
 Photo prise à
Photo prise àDask est, sans exagération, l'outil de traitement de données le plus révolutionnaire que j'ai rencontré. Si vous aimez
Pandas et Numpy , mais parfois vous ne pouvez pas gérer des données qui ne tiennent pas dans la RAM, alors Dask est exactement ce dont vous avez besoin. Dask prend en charge le cadre de données Pandas et les structures de données Numpy (tableaux). Dask peut être exécuté sur l'ordinateur local ou mis à l'échelle, puis exécuté dans le cluster. En substance, vous écrivez le code une seule fois, puis choisissez de l'utiliser sur la machine locale ou de le déployer dans un cluster de nombreux nœuds en utilisant la syntaxe Python la plus courante pour tout cela. La fonctionnalité elle-même est excellente, mais j'ai décidé d'écrire cet article juste pour souligner: chaque Data Scientist (au moins en utilisant Python) devrait utiliser Dask. De mon point de vue, la magie de Dask est qu'en minimisant le code, vous pouvez le paralléliser en utilisant la puissance de calcul qui est déjà disponible, par exemple, sur mon ordinateur portable. Avec le traitement parallèle des données, le programme s'exécute plus rapidement, vous devez attendre moins et, par conséquent, il reste plus de temps pour l'analyse. En particulier, dans cet article, nous parlerons de l'objet
dask.delayed et de son
dask.delayed dans le flux de tâches de science des données.
Présentation de Dask
En guise d'introduction à Dask, voici quelques exemples juste pour vous donner une idée de sa syntaxe complètement discrète et naturelle. La conclusion la plus importante que je veux suggérer dans ce cas est que les connaissances que vous avez déjà seront suffisantes pour fonctionner; Vous n'avez pas besoin d'apprendre un nouvel outil de Big Data comme Hadoop ou Spark.
Dask propose 3 collections parallèles dans lesquelles vous pouvez stocker des données dépassant la taille de la RAM, à savoir les trames de données, les sacs et les tableaux. Dans chacun de ces types de collections, vous pouvez stocker des données en les segmentant entre la RAM et le disque dur, ainsi que distribuer des données sur plusieurs nœuds d'un cluster.
Un Dask DataFrame se compose de trames de données déchiquetées, telles que celles de Pandas, de sorte qu'il vous permet d'utiliser un sous-ensemble des fonctionnalités de la syntaxe de requête Pandas. Voici un exemple de code qui télécharge tous les fichiers csv pour 2018, analyse un champ avec un horodatage et lance une demande Pandas:
import dask.dataframe as dd df = dd.read_csv('logs/2018-*.*.csv', parse_dates=['timestamp']) df.groupby(df.timestamp.dt.hour).value.mean().compute()
Exemple de trame de données DaskDans Dask Bag, vous pouvez stocker et traiter des collections d'objets pythoniques qui ne tiennent pas en mémoire. Dask Bag est idéal pour le traitement des journaux et des collections de documents au format json. Dans cet exemple de code, tous les fichiers json pour 2018 sont chargés dans la structure de données Dask Bag, chaque enregistrement json est analysé et les données utilisateur sont filtrées à l'aide de la fonction lambda:
import dask.bag as db import json records = db.read_text('data/2018-*-*.json').map(json.loads) records.filter(lambda d: d['username'] == 'Aneesha').pluck('id').frequencies()
Exemple de sac DaskLa structure de données de Dask Arrays prend en charge les tranches de style Numpy. Dans l'exemple suivant, un ensemble de données HDF5 est divisé en blocs de dimension (5000, 5000):
import h5py f = h5py.File('myhdf5file.hdf5') dset = f['/data/path'] import dask.array as da x = da.from_array(dset, chunks=(5000, 5000))
Exemple de tableau DaskTraitement parallèle dans Dask
Un autre titre tout aussi précis pour cette section serait «Mort d'un cycle séquentiel». De temps en temps, je rencontre un modèle commun: parcourir la liste des éléments, puis exécuter la méthode Python avec chaque élément, mais avec des arguments d'entrée différents. Les scénarios courants de traitement des données incluent le calcul d'agrégats de fonctionnalités pour chaque client ou l'agrégation d'événements à partir du journal pour chaque étudiant. Au lieu d'appliquer une fonction à chaque argument d'une boucle séquentielle, l'objet Dask Delayed vous permet de traiter de nombreux éléments en parallèle. Lorsque vous travaillez avec Dask Delayed, tous les appels de fonction sont mis en file d'attente, placés dans le graphique d'exécution, après quoi ils doivent être traités.
J'ai toujours été un peu paresseux pour écrire mon propre moteur de thread ou utiliser asyncio, donc je ne vais même pas vous montrer d'exemples similaires pour la comparaison. Avec Dask, vous ne pouvez changer ni la syntaxe ni le style de programmation! Il vous suffit d'annoter ou de boucler la méthode, qui sera exécutée en parallèle avec
@dask.delayed et d'appeler la méthode de calcul après l'exécution du code de boucle.
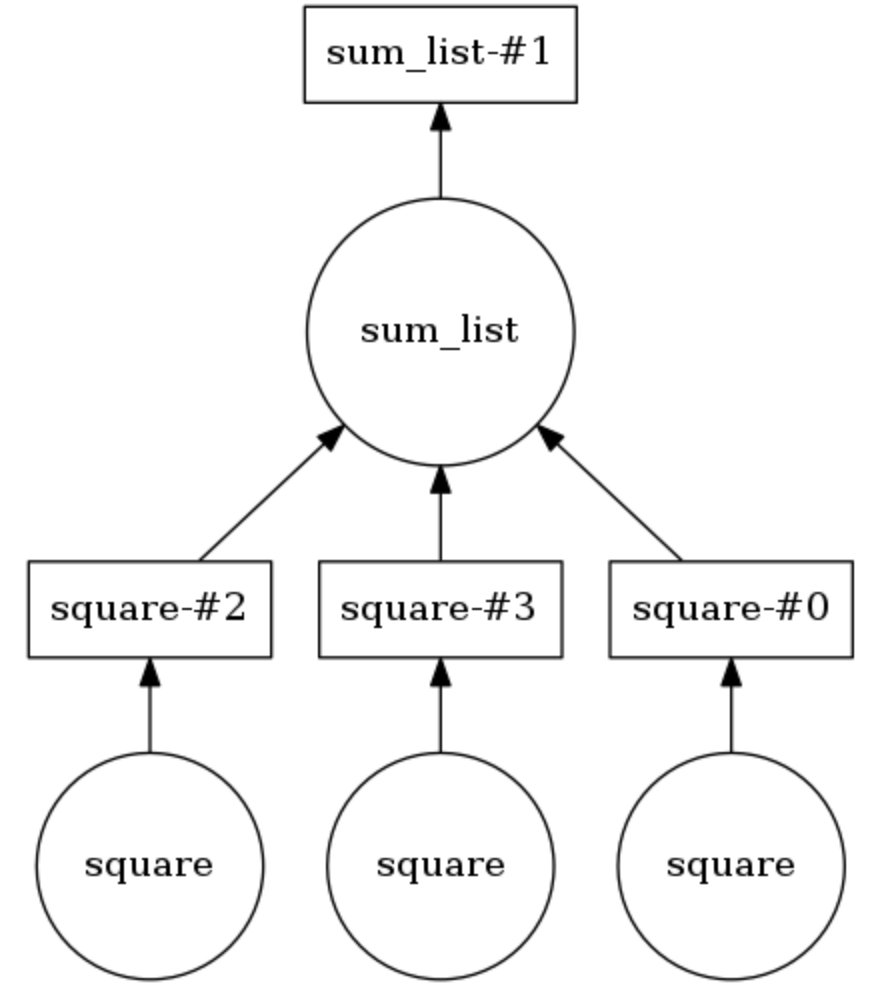
Exemple de graphique de calcul Dask
Dans l'exemple ci-dessous, les deux méthodes sont annotées
@dask.delayed . Trois nombres sont stockés dans une liste, ils doivent être mis au carré, puis additionnés ensemble. Dask construit un graphe de calcul qui fournit une exécution parallèle de la méthode de mise au carré, après quoi le résultat de cette opération est passé à la méthode
sum_list . Le graphique de calcul peut être affiché en appelant en
calling .visualize() .
Calling .compute() exécute le graphe de calcul. Comme il ressort de la
conclusion , les éléments de la liste ne sont pas traités dans l'ordre, mais en parallèle.
Le nombre de threads peut être défini (par exemple,
dask.set_options( pool=ThreadPool(10) ), et ils peuvent également être facilement échangés pour utiliser des processus sur votre ordinateur portable ou PC (par exemple,
dask.config.set( scheduler='processes' ) .
J'ai donc démontré combien il serait trivial d'ajouter un traitement parallèle de tâches à un projet du domaine de la science des données à l'aide de Dask. Peu de temps avant d'écrire cet article, j'ai utilisé Dask pour diviser les données sur les flux de clics des utilisateurs (historique des visites) en sessions de 40 minutes, puis agréger les attributs de chaque utilisateur pour un clustering plus poussé. Dites-nous comment vous avez utilisé Dask!