QlikView et son jeune frère QlikSense sont de merveilleux outils de BI assez populaires dans notre pays et à l'étranger. Très souvent, ces systèmes enregistrent les résultats «intermédiaires» de leur travail - des données qui visualisent leurs «tableaux de bord» - dans ce qu'on appelle des «fichiers QVD». Les fichiers QVD sont souvent utilisés comme stockage principal dans les processus ETL à plusieurs étapes construits sur la base de Qlik. Et puis certains (par exemple, je - je m'occupe de l'ingénierie des données dans l'entreprise) ont une question - est-il possible et comment utiliser ces données sans QlikView / QlikSense? Ou un autre - et qu'y a-t-il et est-il exact qu'il a été compté?
QVD est un format de fichier optimisé pour QlikView / QlikSense (la lecture des informations d'écriture par ces applications dans des fichiers de ce format est beaucoup plus rapide que dans des fichiers de tout autre format). La structure de ce fichier est non documentée et recouverte d'une "morosité de propriété", il n'y a pratiquement aucune application capable de travailler avec de tels fichiers (en lecture et plus encore en écriture). Dans cette série d'articles, je partagerai mon expérience et mes connaissances pratiques acquises: je sais comment QVD fonctionne, je peux y lire et écrire directement et rapidement.
Qui sera intéressé par ces informations: tout d'abord, ceux qui travaillent avec QlikView / QlikSense, ainsi que ceux qui (comme moi) souhaitent utiliser les données stockées dans les fichiers QVD. Et, bien sûr, à tout le monde curieux.
Tout ce qui est écrit dans cette série est basé sur mon expérience personnelle, qui, bien sûr, n'est pas une «documentation» ou une «garantie» (que vos fichiers seront exactement les mêmes que ceux que j'ai décrits. Ou que ce sera pour toujours ) Je ne peux pas non plus garantir que j'ai compris tous les cas - il est certain que certains fichiers contiendront quelque chose que je n'ai pas décrit (ne serait-ce que parce que je n'ai pas trouvé de telles options). Cependant, je dois noter que les informations sont vérifiées sur un grand (plusieurs centaines) ensemble de fichiers créés par différentes personnes de différents systèmes utilisant différentes versions de QlikView / QlikSense.
Et un peu sur la façon dont je l'ai fait: j'ai commencé avec un simple - un petit exemple en ligne enregistré dans QVD. Plus loin - l'analyse du fichier binaire, les efforts du cerveau, les tests et les erreurs. Pour l'avenir (je vais en parler plus en détail dans la conclusion de la série), j'ai pu lire et écrire des fichiers QVD de taille moyenne (des centaines de gigaoctets) assez efficacement. Le point de départ de mon voyage dans le monde QVD a été ce GitHub , merci beaucoup à l'auteur (a essayé de le contacter - ne répond pas).
Quel était mon objectif (outre la curiosité et le désir de vérifier l'exactitude des données avec lesquelles QlikView / QlikSense fonctionne), j'avais besoin de lire le contenu du fichier QVD, c'est-à-dire recréer une table relationnelle basée sur elle. À l'inverse, téléchargez les données de la table relationnelle dans QVD afin que QlikView puisse les charger correctement.
Comment je vois cette série d'articles
- introduction, structure de fichiers, métadonnées (cet article)
- stockage des informations de colonne
- stockage des informations de ligne, réalisations, plans
Structure des fichiers
Le fichier QVD est créé par le script QlikView / QlikSense dans le processus de chargement des données dans la mémoire de l'application (résultat de la commande STORE) et correspond à une table (relationnelle) QlikView / QlikSense. Il se compose de deux parties
- textuel (métadonnées) et
- binaire (colonnes et lignes)
Les métadonnées sont présentées au format XML (un exemple sera donné ci-dessous), la partie binaire commence immédiatement après le texte et se compose de deux blocs
- valeurs uniques de toutes les colonnes (table source)
- lignes (table source) qui font référence à des valeurs de colonne uniques
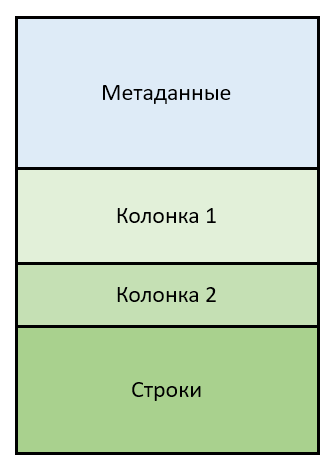
Ainsi, pour une table de N colonnes, le fichier contiendra N + 1 blocs binaires. Toutes les parties du dossier sont «étroitement collées» et se succèdent sans aucun remplissage ni «queue».
Le fichier QVD contient beaucoup de métadonnées - "données sur les données". C'est presque autosuffisant, jugez par vous-même, voici une courte liste de ce qui est dans les métadonnées (je les décrirai plus en détail ci-dessous):
- version du logiciel qui a généré le fichier
- date et heure de création du fichier
- Fichier QlikView / QlikSense, dont le script a conduit à la création du fichier
- code source de script qui a généré le fichier QVD
- nom de table
- informations sur la colonne (noms, types, quantités de valeurs uniques)
- nombre de lignes
Les métadonnées sont stockées dans un fichier sous forme de texte et peuvent être vues dans n'importe quel programme qui peut afficher le fichier sous forme de texte (enfin presque n'importe quoi ... dans un qui n'a pas peur des gros fichiers). Personnellement, je regarde les méta-informations avec plus - c'est assez pratique.
Dans la présentation suivante, j'utiliserai la table de test (j'utilise la syntaxe QlikView, mais je pense qu'elle sera facile à conjecturer):
SET NULLINTERPRET =<sym>; tab1: LOAD * INLINE [ ID, NAME 123.12,"Pete" 124,12/31/2018 -2,"Vasya" 1,"John" <sym>,"None" ];
Je vais donner comme exemple les métadonnées de cette plaque
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <QvdTableHeader> <QvBuildNo>7314</QvBuildNo> <CreatorDoc></CreatorDoc> <CreateUtcTime>2019-04-03 06:24:33</CreateUtcTime> <SourceCreateUtcTime></SourceCreateUtcTime> <SourceFileUtcTime></SourceFileUtcTime> <SourceFileSize>-1</SourceFileSize> <StaleUtcTime></StaleUtcTime> <TableName>tab1</TableName> <Fields> <QvdFieldHeader> <FieldName>ID</FieldName> <BitOffset>0</BitOffset> <BitWidth>3</BitWidth> <Bias>-2</Bias> <NumberFormat> <Type>0</Type> <nDec>0</nDec> <UseThou>0</UseThou> <Fmt></Fmt> <Dec></Dec> <Thou></Thou> </NumberFormat> <NoOfSymbols>4</NoOfSymbols> <Offset>0</Offset> <Length>40</Length> </QvdFieldHeader> <QvdFieldHeader> <FieldName>NAME</FieldName> <BitOffset>3</BitOffset> <BitWidth>5</BitWidth> <Bias>0</Bias> <NumberFormat> <Type>0</Type> <nDec>0</nDec> <UseThou>0</UseThou> <Fmt></Fmt> <Dec></Dec> <Thou></Thou> </NumberFormat> <NoOfSymbols>5</NoOfSymbols> <Offset>40</Offset> <Length>37</Length> </QvdFieldHeader> </Fields> <Compression></Compression> <RecordByteSize>1</RecordByteSize> <NoOfRecords>5</NoOfRecords> <Offset>77</Offset> <Length>5</Length> </QvdTableHeader>
Mon expérience avec QVD montre que la structure XML ne change pas d'un fichier à l'autre.
Je commenterai les éléments de métadonnées les plus importants.
QvBuildNo
Numéro de build de l'application QlikView / QlikSense qui a généré le fichier QVD.
Creatordoc
En règle générale, il contient le nom du fichier QVW, dont le script a généré le fichier QVD. Cet exemple est vide, peut-être parce que l'édition personnelle a été utilisée.
CreateUtcTime
Heure de création du fichier QVD.
SourceCreateUtcTime, SourceFileUtcTime, SourceFileSize, StaleUtcTime
Je n'ai pas vu les fichiers dans lesquels ces champs seraient remplis - à un esprit curieux: peut-être que certains paramètres sont manquants?
Tablename
Le nom de la table dans QlikView (voir l'exemple ci-dessus).
Soit dit en passant, les mots "champ" et "colonne" sont des synonymes pour moi, ne vous inquiétez pas si je les utilise tous les deux (j'essaierai de ne pas le faire, mais quand même ...).
Les informations sur chaque champ sont stockées dans QVD sur
Nom de champ
Le nom du champ (toujours en termes de QlikView, c'est-à-dire en tenant compte de "AS")
BitOffset, BitWidth, Bias
Pour l'instant, sautons - ce sont des informations pour "décoder des chaînes", nous considérerons dans la troisième partie quand il traitera des chaînes.
Type, nDec, UseThou, Fmt, Dec, Thou
Bien conçu (à en juger par les noms), mais absolument inutile du point de vue de la réalisation de mon objectif d'information (pour plus de détails, voir la deuxième partie, où nous parlerons de colonnes). Pourquoi est-ce inutile? - la balise "Type" ne correspond pas au type de données stockées dans la partie binaire. Il est impossible d'en restaurer le type de colonne (il semblerait que cela pourrait être plus facile, il y a une balise Type!) Dans 90% des cas, la valeur de cette balise sera la chaîne UNKNOWN ...
Dans les métadonnées sur les colonnes, il y a encore de telles données (dans les métadonnées de l'exemple, ce n'est apparemment pas en raison de la petite taille)
<Comment></Comment> <Tags> <String>$numeric</String> <String>$integer</String> </Tags>
Le commentaire n'a pas besoin de commentaires (au fait, les fichiers avec lesquels j'ai travaillé sont 100% vides ...).
Les balises sont également inutiles (du point de vue de la restauration de la structure de la table). Mais à partir de là, vous pouvez approximativement deviner quel type d'informations est stocké dans la colonne. Je vais aborder la saisie plus en détail dans la deuxième partie - quand je parlerai des colonnes: c'est important. Mais un peu plus compliqué que je ne le souhaiterais.
NoOfSymbols
Le nombre d'entrées dans la partie binaire liées à cette colonne. Comme nous le voyons, dans notre exemple, il s'agit de 5. Informations très importantes pour le décryptage.
Décalage
Décalage du bloc de données de cette colonne en octets par rapport au début de la partie binaire du fichier. Aussi très important.
La longueur
La longueur de l'ensemble du bloc de données de cette colonne en octets. Notez que la représentation binaire d'un élément de colonne (cellule de tableau) a généralement une longueur variable (ligne, par exemple), de sorte que la longueur ne peut pas être calculée, vous ne pouvez la prendre qu'à partir de cette balise (sourire).
La compression
Jamais renseigné (dans les données avec lesquelles j'ai travaillé). Peut-être que nous n'utilisons pas cette option ...
RecordByteSize
Taille de l'entrée de ligne en octets. Toutes les chaînes sont représentées dans le bloc binaire de chaînes sous la forme d'un index binaire (plus d'informations à ce sujet dans la troisième partie), un index binaire se compose de lignes de même longueur.
NoOfRecords
Le nombre de lignes (dans l'index de bits et dans la table source).
Décalage
Décalage de l'index binaire (bloc contenant des informations de chaîne) en octets par rapport au début de la partie binaire du fichier.
La longueur
La longueur de l'index de bits en octets.
Dans les métadonnées sur les chaînes, il y a encore de telles données (encore une fois - un court exemple ne vous permet pas de tout voir, mais il vous permet de comprendre le complexe)
<Lineage> <LineageInfo> <Discriminator>Provider=OraOLEDB.Oracle.1;Persist Security Info=True;Data Source=XXXX;Extended Properties=""</Discriminator> <Statement>LinkTable: LOAD SOURCE_NAME & '_' & SOURCE_ID as SYSKEY, HID_PARTY;SQL SELECT * FROM UNITED_VIEW</Statement> </LineageInfo> <LineageInfo> <Discriminator>Provider=OraOLEDB.Oracle.1;Persist Security Info=True;Data Source=XXXX;Extended Properties=""</Discriminator> <Statement>SQL SELECT * FROM UNITED_VIEW</Statement> </LineageInfo> <LineageInfo> <Discriminator>STORE - \\xxx.ru\mfs\SPECIAL\Qlikview\QVData\LinkTable.qvd (qvd)</Discriminator> <Statement></Statement> </LineageInfo> </Lineage> <Comment></Comment>
Je n'entrerai pas dans le vif du sujet, c'est assez compréhensible (les SELECT d'origine qui ont généré la table dans QlikView), je ne l'ai toujours pas encore compris (parfois ils doublent) ... (sauf pour un - 100% pas de commentaires (sourire)) .
Pour résumer
- Le fichier QVD est autonome (c'est-à-dire qu'il peut être analysé indépendamment des autres données)
- Le fichier QVD se compose de parties de texte (métadonnées) et binaires (colonnes et index binaires)
- les métadonnées sont XML avec une sémantique claire
Un lecteur curieux a le droit de demander ici: "Jusqu'à présent, rien de nouveau n'a été dit, tout ce qui précède peut être pris et visualisé dans l'en-tête XML du fichier QVD ... Cela a déjà été écrit à plusieurs reprises sur différents Internet, quelle est la nouveauté?" C'est vrai - la première partie est presque entièrement consacrée aux métadonnées. Mais ce n'est pas la fin.
Que faire ensuite - dans la partie suivante, nous examinerons en détail la structure de la partie binaire du fichier QVD contenant des informations sur les colonnes (valeurs uniques de toutes les colonnes du tableau).