Récemment, je suis tombé sur une tâche classique pour les entretiens: rechercher le nombre maximum de points se tenant sur une ligne droite (sur un plan, coordonnées entières). L'idée d'une recherche exhaustive m'est immédiatement venue à l'esprit, qui a une complexité temporelle évidente en O (n ^ 2), mais il me semblait qu'il devrait y avoir autre chose, au moins une alternative en O (n * log (n)) . Après une demi-heure, même quelque chose de mieux a été trouvé!
 Une description plus détaillée du problème avec des exemples d'entrée-sortie se trouve sur GeeksForGeeks et LeetCode
Une description plus détaillée du problème avec des exemples d'entrée-sortie se trouve sur GeeksForGeeks et LeetCodeAu début, j'ai remarqué que vous pouvez facilement résoudre le problème uniquement pour les lignes horizontales ou verticales, en ajoutant le X / Y de chaque point dans le dictionnaire. Et quelle est la différence entre les autres lignes? Juste une pente? .. Mais c'est réparable!
J'ai donc décidé qu'il était possible de faire le tour de toute la liste de points plusieurs fois en les faisant pivoter. Et la solution dans O (n) est obtenue! Bien qu'avec un grand coefficient. J'espère vraiment que je n'ai pas inventé un vélo :)
Visualisé, il ressemble à ceci:
mon premier GIF fait maison, ne gronde pas :)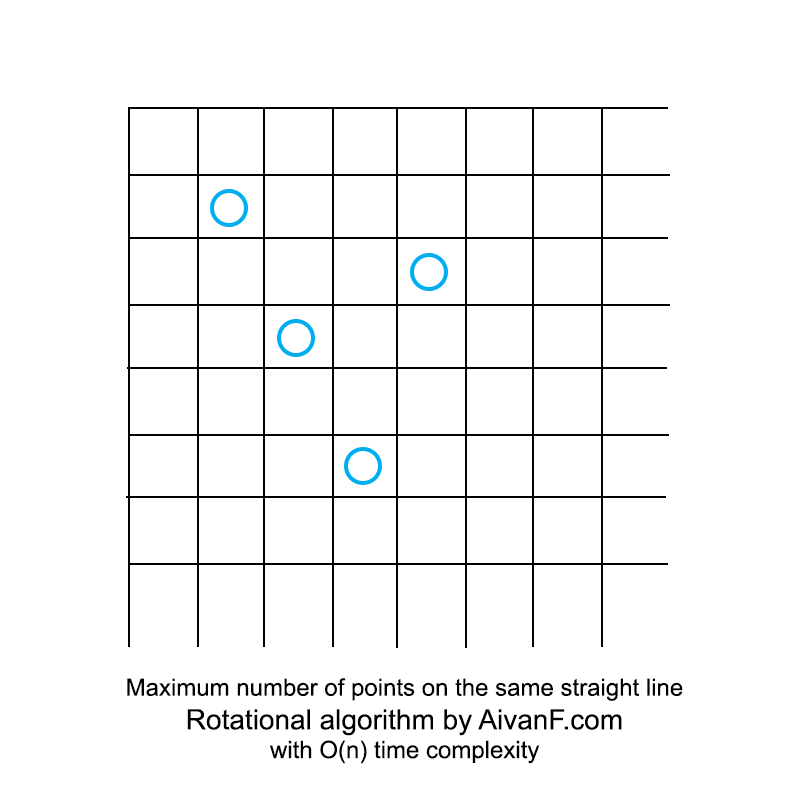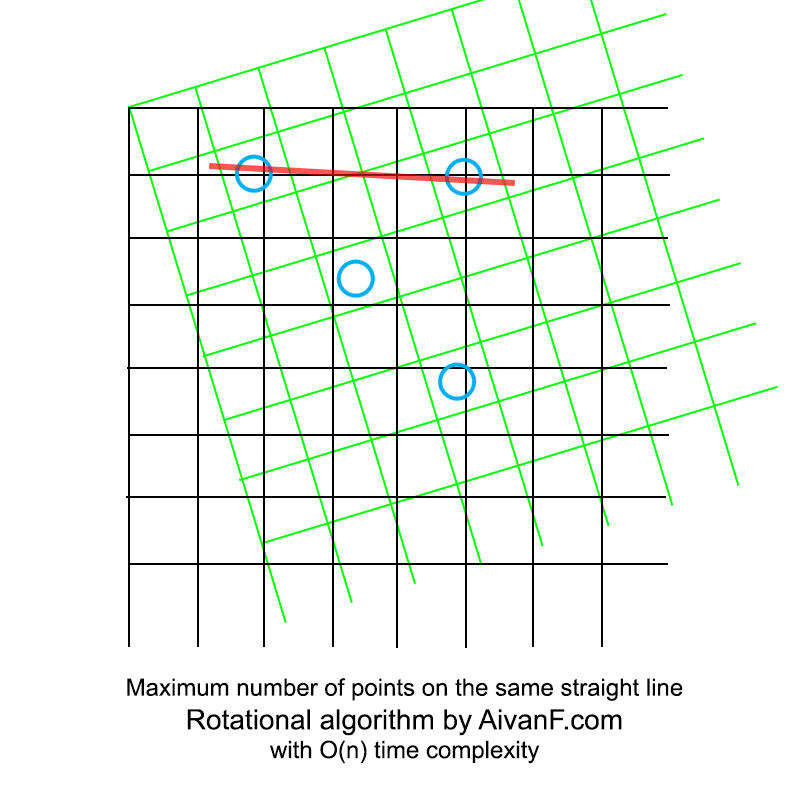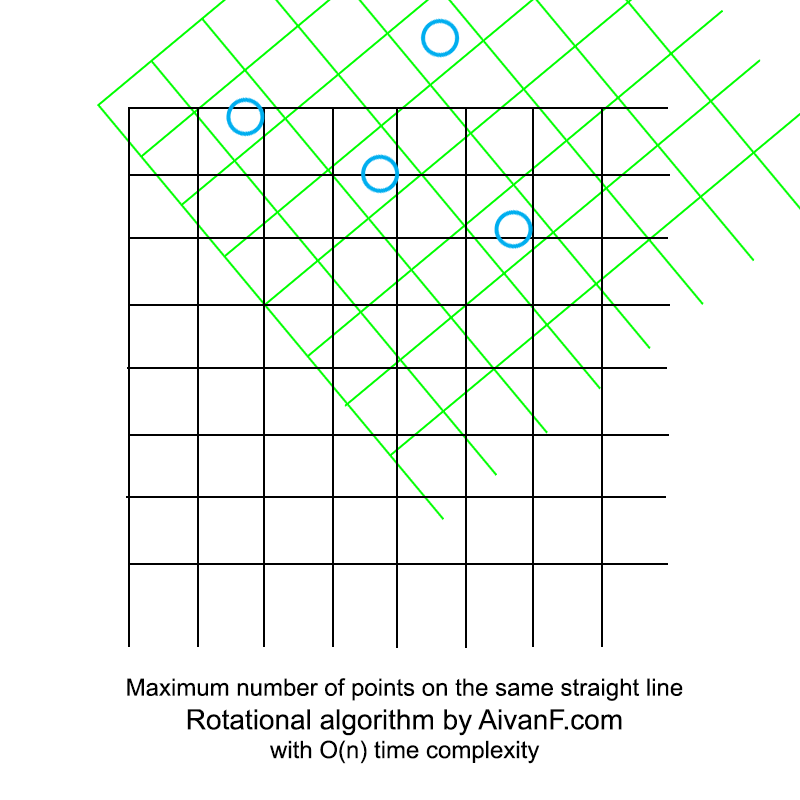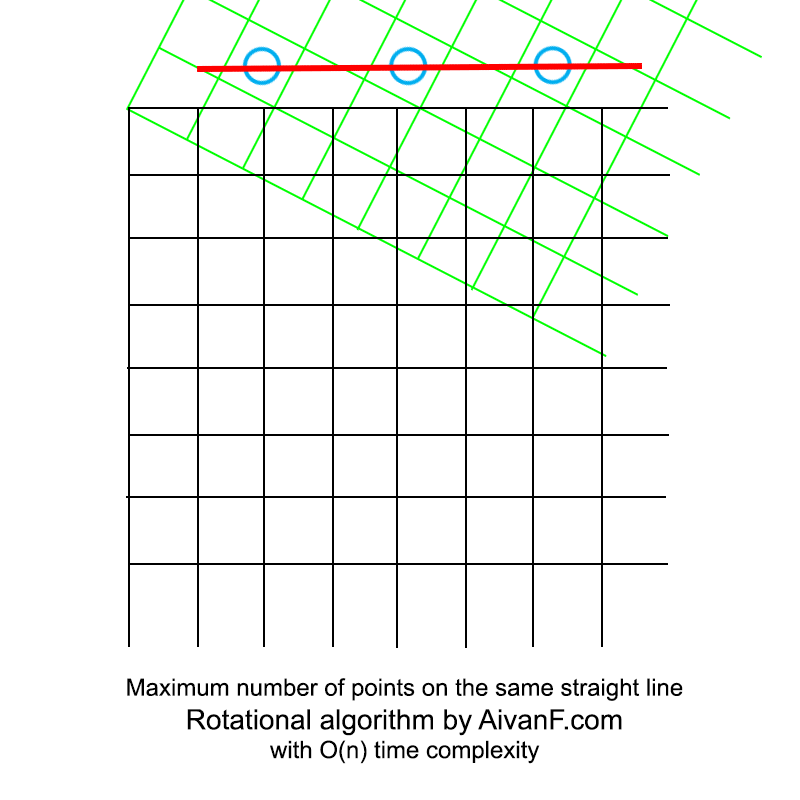
Il est intéressant de noter que la
mise en œuvre ultérieure
de la recherche exhaustive a pris plus de lignes de code.
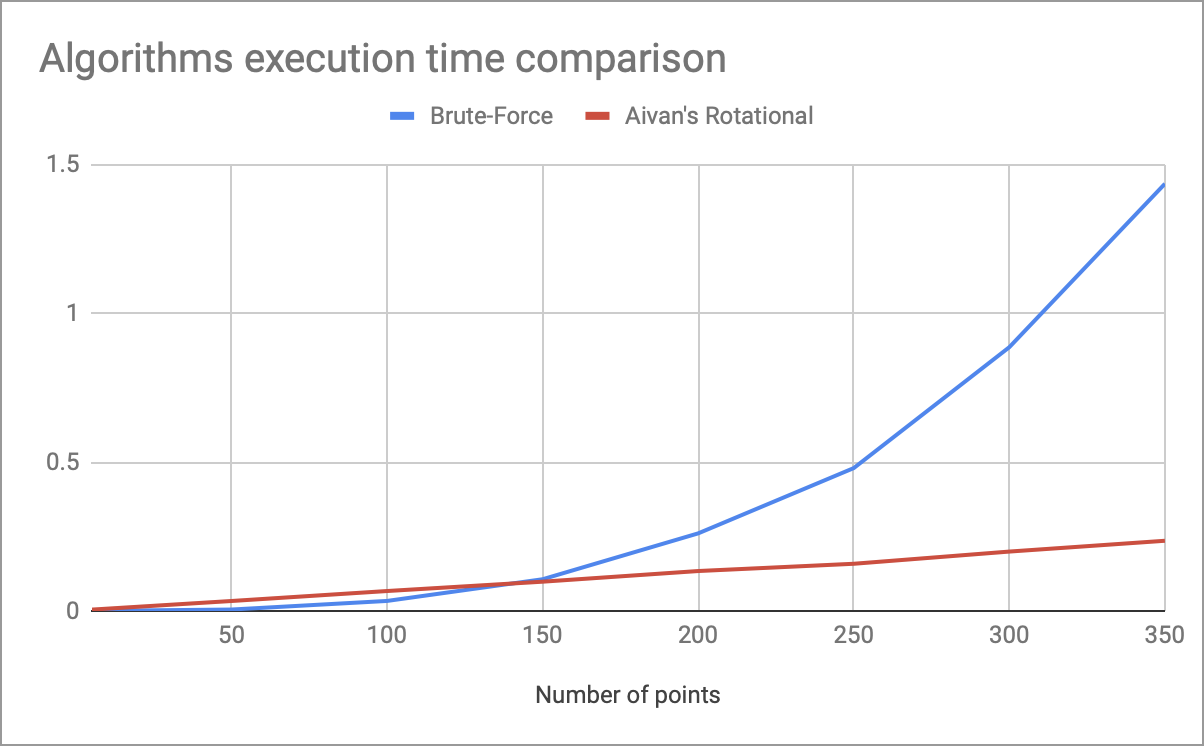
Le graphique avec les mesures de l'exécution de mon algorithme de rotation et l'énumération complète en fonction du nombre de points se trouve dans l'en-tête.
Environ 150 points montrent l'avantage de la complexité linéaire dans le temps (avec les coefficients utilisés dans le code ci-dessus). Par conséquent, cet algorithme présente les inconvénients suivants:
- La précision n'est pas absolue.
- Le temps d'exécution sur de petits ensembles de points est long.
En général, cela est facilement corrigé par une sélection compétente de coefficients: pour les ensembles simples, ROT_COUNT = 36 plutôt que 2000 est assez suffisant, ce qui accélère le code 50+ fois.
Et de tels avantages:
- Il fonctionne calmement avec des coordonnées fractionnaires.
- La complexité temporelle est linéaire, ce qui est visible sur les grands ensembles de données.
Un tableau des mesures
est disponible ici . Le code source entier du projet avec les deux algorithmes et divers contrôles
est sur le GitHub .
Mettre à jour Je veux encore une fois noter que cet algorithme a à la fois des avantages et des inconvénients, je ne le préconise pas comme un remplacement idéal pour la force brute, je viens de décrire une alternative intéressante intéressante, qui dans certains cas peut être plus appropriée.