Présentation
Attention, ce n'est pas un autre article «Hello world» sur la façon de faire clignoter une LED ou d'entrer dans sa première interruption sur STM32. Cependant, j'ai essayé de donner des explications complètes sur toutes les questions soulevées, donc l'article sera utile non seulement à de nombreux professionnels et rêvant de devenir de tels développeurs (comme j'espère), mais aussi aux programmeurs de microcontrôleurs débutants, car ce sujet pour une raison quelconque se déplace sur d'innombrables sites / blogs "Enseignants de programmation MK."
Pourquoi ai-je décidé d'écrire ceci?
Bien que j'aie exagéré, ayant dit plus tôt que le regroupement des bits matériels de la famille Cortex-M n'est pas décrit dans les ressources spécialisées, il existe encore des endroits où cette fonctionnalité est couverte (et a même rencontré un article ici), mais ce sujet doit clairement être complété et modernisé. Je note que cela s'applique également aux ressources de langue anglaise. Dans la section suivante, je vais expliquer pourquoi cette fonctionnalité du noyau peut être extrêmement importante.
Théorie
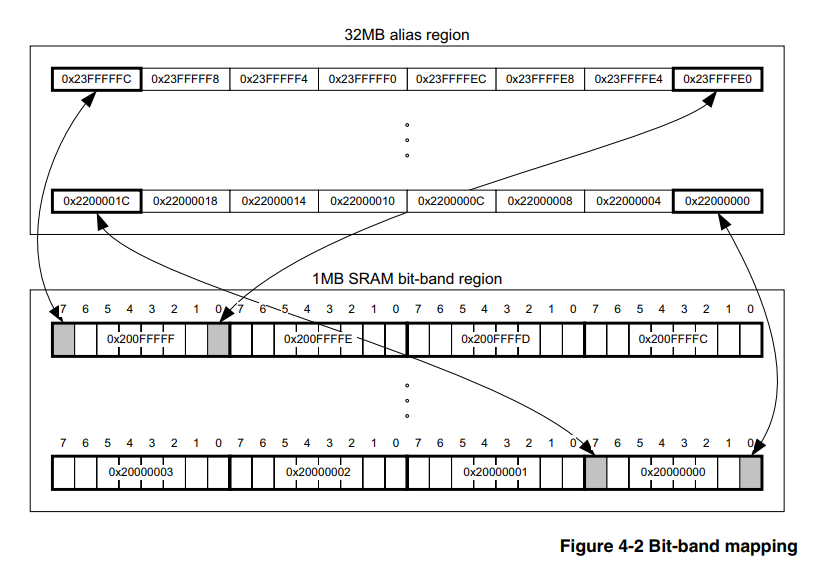
(et ceux qui la connaissent peuvent se mettre immédiatement à la pratique)La bande de bits matérielle est une caractéristique du cœur lui-même, et ne dépend donc pas de la famille et de la société du fabricant de microcontrôleurs, l'essentiel est que le cœur soit adapté. Dans notre cas, que ce soit Cortex-M3. Par conséquent, des informations sur cette question doivent être recherchées dans un document officiel sur le noyau lui-même, et il existe un tel document, le
voici , la section 4.2 décrit en détail comment utiliser cet outil.
Ici, je voudrais faire une petite digression technique pour les programmeurs qui ne sont pas familiers avec l'assembleur, dont la majorité est maintenant, en raison de la complexité propagée et de l'inutilité de l'assembleur pour des microcontrôleurs 32 bits "sérieux" comme STM32, LPC, etc. De plus, on peut souvent rencontrer des tentatives censure pour l'utilisation d'assembleur dans ce domaine, même sur le Habr. Dans cette section, je veux décrire brièvement le mécanisme d'écriture dans la mémoire MK, qui devrait clarifier les avantages de la bande de bits.
Je vais expliquer un exemple simple et spécifique pour la plupart des STM32. Supposons que je doive transformer PB0 en une sortie à usage général. Une solution typique ressemblerait à ceci:
GPIOB->MODER |= GPIO_MODER_MODER0_0;
Évidemment, nous utilisons le «OU» au niveau du bit afin de ne pas écraser les bits restants du registre.
Pour le compilateur, cela se traduit par l'ensemble suivant de 4 instructions:
- Téléchargez GPIOB-> MODER dans le registre à usage général (RON)
- Téléchargez les valeurs dans l'autre RON à l'adresse indiquée dans le RON de l'élément 1
- Effectuez un OU au niveau du bit de cette valeur avec GPIO_MODER_MODER0_0.
- Téléchargez le résultat dans GPIOB-> MODER.
De plus, il ne faut pas oublier que ce noyau utilise le jeu d'instructions thumb2, ce qui signifie qu'ils peuvent être différents en volume. Je note également que partout nous parlons du niveau d'optimisation O3.
En langage d'assemblage, cela ressemble à ceci:

On peut voir que la toute première instruction n'est rien de plus qu'une pseudo-instruction avec un décalage, on retrouve l'adresse du registre à l'adresse PC (compte tenu de la bande transporteuse) + 0x58.
Il s'avère que nous avons 4 étapes (et plus de cycles d'horloge) et 14 octets de mémoire occupée par opération.
Si vous voulez en savoir plus à ce sujet, je recommande le livre [2], soit dit en passant, il y en a aussi en russe.
Nous passons à la méthode bit_banding.
L'essentiel, selon le paysan, est que le processeur dispose d'une zone mémoire spécialement allouée, écrivant les valeurs dans lesquelles nous ne modifions pas les autres bits du registre périphérique ou de la RAM. Autrement dit, nous n'avons pas besoin de remplir les points 2) et 3) décrits ci-dessus, et pour cela il suffit de recompter l'adresse selon les formules de [1].

Nous essayons de faire une opération similaire, son assembleur:

Adresse recalculée:

Ici, nous avons ajouté une instruction d'écriture n ° 1 dans le RON, mais de toute façon, le résultat est de 10 octets, au lieu de 14, et quelques cycles d'horloge de moins.
Mais que faire si la différence est ridicule?
D'une part, les économies ne sont pas importantes, en particulier dans les cycles où il est déjà habituel d'overclocker le contrôleur à 168 MHz. Dans un projet moyen, les moments où vous pouvez appliquer cette méthode seront respectivement de 40 à 80 octets, les économies pouvant atteindre 250 octets si les adresses diffèrent. Et si nous considérons que la programmation de MK directement sur les registres est maintenant considérée comme «zashkvar», et qu'il est «cool» d'utiliser toutes sortes de dés, alors les économies peuvent être bien plus importantes.
En outre, le chiffre de 250 octets est déformé par le fait que les bibliothèques de haut niveau sont activement utilisées dans la communauté, le micrologiciel se gonflant à des tailles indécentes. Lors d'une programmation à bas niveau, cela représente au moins 2 à 5% du volume logiciel pour un projet moyen, avec une architecture compétente et une optimisation O3.
Encore une fois, je ne veux pas dire que c'est une sorte d'outil super super-duper-méga que tout programmeur MK qui se respecte devrait utiliser. Mais si je peux réduire les coûts même avec une si petite pièce, alors pourquoi pas?Implémentation
Toutes les options ne seront données que pour configurer les périphériques, car je ne suis pas tombé sur une situation où cela serait nécessaire pour la RAM. À strictement parler, pour la RAM, la formule est similaire, il suffit de changer les adresses de base pour le calcul. Alors, comment implémentez-vous cela?
Assembleur
Allons du bas, de mon bien-aimé assembleur.
Sur les projets d'assembleur, j'alloue généralement quelques RON de 2 octets (selon les instructions qui fonctionnent avec eux) sous # 0 et # 1 pour l'ensemble du projet, et les utilise également dans les macros, ce qui me réduit encore 2 octets sur une base continue. Remarque, je n'ai pas trouvé CMSIS dans Assembler for STM, car j'ai tout de suite mis le numéro de bit dans la macro, et non sa valeur de registre.
Implémentation pour GNU Assembler @ . MOVW R0, 0x0000 MOVW R1, 0x0001 @ .macro PeriphBitSet PerReg, BitNum LDR R3, =(BIT_BAND_ALIAS+(((\PerReg) - BIT_BAND_REGION) * 32) + ((\BitNum) * 4)) STR R1, [R3] .endm @ .macro PeriphBitReset PerReg, BitNum LDR R3, =(BIT_BAND_ALIAS+((\PerReg - BIT_BAND_REGION) * 32) + (\BitNum * 4)) STR R0, [R3] .endm
Exemples:
Exemples d'assembleurs PeriphSet TIM2_CCR2, 0 PeriphBitReset USART1_SR, 5
L'avantage incontestable de cette option est que nous avons un contrôle total, ce qui ne peut pas être dit sur d'autres options. Et comme le montre la dernière section de l'article, en plus celle-ci est
très importante.
Cependant, personne n'a besoin de projets pour MK dans Assembler, à partir de la fin du zéro, ce qui signifie que vous devez passer en SI.
Plaine c
Honnêtement, une simple option Sishny a été trouvée par moi au début du chemin, quelque part dans le vaste réseau. À cette époque, j'avais déjà implémenté le regroupement de bits dans Assembler, et suis tombé accidentellement sur un fichier C, cela a immédiatement fonctionné et j'ai décidé de ne rien inventer.
Implémentation pour plain C #define MASK_TO_BIT31(A) (A==0x80000000)? 31 : 0 #define MASK_TO_BIT30(A) (A==0x40000000)? 30 : MASK_TO_BIT31(A) #define MASK_TO_BIT29(A) (A==0x20000000)? 29 : MASK_TO_BIT30(A) #define MASK_TO_BIT28(A) (A==0x10000000)? 28 : MASK_TO_BIT29(A) #define MASK_TO_BIT27(A) (A==0x08000000)? 27 : MASK_TO_BIT28(A) #define MASK_TO_BIT26(A) (A==0x04000000)? 26 : MASK_TO_BIT27(A) #define MASK_TO_BIT25(A) (A==0x02000000)? 25 : MASK_TO_BIT26(A) #define MASK_TO_BIT24(A) (A==0x01000000)? 24 : MASK_TO_BIT25(A) #define MASK_TO_BIT23(A) (A==0x00800000)? 23 : MASK_TO_BIT24(A) #define MASK_TO_BIT22(A) (A==0x00400000)? 22 : MASK_TO_BIT23(A) #define MASK_TO_BIT21(A) (A==0x00200000)? 21 : MASK_TO_BIT22(A) #define MASK_TO_BIT20(A) (A==0x00100000)? 20 : MASK_TO_BIT21(A) #define MASK_TO_BIT19(A) (A==0x00080000)? 19 : MASK_TO_BIT20(A) #define MASK_TO_BIT18(A) (A==0x00040000)? 18 : MASK_TO_BIT19(A) #define MASK_TO_BIT17(A) (A==0x00020000)? 17 : MASK_TO_BIT18(A) #define MASK_TO_BIT16(A) (A==0x00010000)? 16 : MASK_TO_BIT17(A) #define MASK_TO_BIT15(A) (A==0x00008000)? 15 : MASK_TO_BIT16(A) #define MASK_TO_BIT14(A) (A==0x00004000)? 14 : MASK_TO_BIT15(A) #define MASK_TO_BIT13(A) (A==0x00002000)? 13 : MASK_TO_BIT14(A) #define MASK_TO_BIT12(A) (A==0x00001000)? 12 : MASK_TO_BIT13(A) #define MASK_TO_BIT11(A) (A==0x00000800)? 11 : MASK_TO_BIT12(A) #define MASK_TO_BIT10(A) (A==0x00000400)? 10 : MASK_TO_BIT11(A) #define MASK_TO_BIT09(A) (A==0x00000200)? 9 : MASK_TO_BIT10(A) #define MASK_TO_BIT08(A) (A==0x00000100)? 8 : MASK_TO_BIT09(A) #define MASK_TO_BIT07(A) (A==0x00000080)? 7 : MASK_TO_BIT08(A) #define MASK_TO_BIT06(A) (A==0x00000040)? 6 : MASK_TO_BIT07(A) #define MASK_TO_BIT05(A) (A==0x00000020)? 5 : MASK_TO_BIT06(A) #define MASK_TO_BIT04(A) (A==0x00000010)? 4 : MASK_TO_BIT05(A) #define MASK_TO_BIT03(A) (A==0x00000008)? 3 : MASK_TO_BIT04(A) #define MASK_TO_BIT02(A) (A==0x00000004)? 2 : MASK_TO_BIT03(A) #define MASK_TO_BIT01(A) (A==0x00000002)? 1 : MASK_TO_BIT02(A) #define MASK_TO_BIT(A) (A==0x00000001)? 0 : MASK_TO_BIT01(A) #define BIT_BAND_PER(reg, reg_val) (*(volatile uint32_t*)(PERIPH_BB_BASE+32*((uint32_t)(&(reg))-PERIPH_BASE)+4*((uint32_t)(MASK_TO_BIT(reg_val)))))
Comme vous pouvez le voir, un morceau de code très simple et direct écrit dans le langage du processeur. Le travail principal ici est la traduction des valeurs CMSIS en un nombre de bits, qui n'était pas nécessaire pour une version d'assembleur.
Oh oui, utilisez cette option comme ceci:
Exemples pour C simple BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = 0;
Cependant, les tendances modernes (massivement, selon mes observations, approximativement à partir de 2015) sont en faveur du remplacement de C par C ++ même pour MK. Et les macros ne sont pas l'outil le plus fiable, donc la prochaine version était destinée à naître.
Cpp03
Ici, un très intéressant et discuté, mais peu utilisé au vu de sa complexité, avec un exemple farfelu de factorielle, un outil - la métaprogrammation arrive.
Après tout, la tâche de traduire la valeur d'une variable en un nombre de bits est idéale (il existe déjà des valeurs dans CMSIS), et dans ce cas, elle est pratique pour le temps de compilation.
J'ai implémenté cela comme suit en utilisant des modèles:
Implémentation pour C ++ 03 template<uint32_t val, uint32_t comp_val, uint32_t cur_bit_num> struct bit_num_from_value { enum { bit_num = (val == comp_val) ? cur_bit_num : bit_num_from_value<val, 2 * comp_val, cur_bit_num + 1>::bit_num }; }; template<uint32_t val> struct bit_num_from_value<val, static_cast<uint32_t>(0x80000000), static_cast<uint32_t>(31)> { enum { bit_num = 31 }; }; #define BIT_BAND_PER(reg, reg_val) *(reinterpret_cast<volatile uint32_t *>(PERIPH_BB_BASE + 32 * (reinterpret_cast<uint32_t>(&(reg)) - PERIPH_BASE) + 4 * (bit_num_from_value<static_cast<uint32_t>(reg_val), static_cast<uint32_t>(0x01), static_cast<uint32_t>(0)>::bit_num)))
Vous pouvez l'utiliser de la même manière:
Exemples pour C ++ 03 BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = false;
Et pourquoi la macro est-elle restée? Le fait est que je ne connais pas d'autre moyen d'insérer cette opération sans passer par une autre zone du code du programme. Je serais très heureux s'ils m'ont incité dans les commentaires. Ni les modèles ni les fonctions en ligne n'offrent une telle garantie. Oui, et la macro ici remplit parfaitement sa tâche, il ne sert à rien de la changer simplement parce que quelqu'un de
conformiste considère cela comme «non sûr».
Étonnamment, le temps ne s'est pas arrêté, les compilateurs ont de plus en plus pris en charge le C ++ 14 / C ++ 17, pourquoi ne pas profiter des innovations, rendant le code plus compréhensible.
Cpp14 / cpp17
Implémentation pour C ++ 14 constexpr uint32_t bit_num_from_value_cpp14(uint32_t val, uint32_t comp_val, uint32_t bit_num) { return bit_num = (val == comp_val) ? bit_num : bit_num_from_value_cpp14(val, 2 * comp_val, bit_num + 1); } #define BIT_BAND_PER(reg, reg_val) *(reinterpret_cast<volatile uint32_t *>(PERIPH_BB_BASE + 32 * (reinterpret_cast<uint32_t>(&(reg)) - PERIPH_BASE) + 4 * (bit_num_from_value_cpp14(static_cast<uint32_t>(reg_val), static_cast<uint32_t>(0x01), static_cast<uint32_t>(0)))))
Comme vous pouvez le voir, je viens de remplacer les modèles par une fonction constexpr récursive, qui, à mon avis, est plus claire pour l'œil humain.
Utilisez de la même manière. À propos, en C ++ 17, en théorie, vous pouvez utiliser la fonction récursive lambda constexpr, mais je ne suis pas sûr que cela conduira à au moins quelques simplifications et ne compliquera pas non plus l'ordre des assembleurs.
En résumé, les trois implémentations C / Cpp donnent un ensemble d'instructions tout aussi correct, selon la section Théorie. Je travaille avec toutes les implémentations sur IAR ARM 8.30 et gcc 7.2.0 depuis longtemps.La pratique est une chienne
C'est tout, semble-t-il, arrivé. Les économies de mémoire ont été calculées, l'implémentation choisie, prête à améliorer les performances. Pas ici, c'était juste un cas de divergence de théorie et de pratique. Et quand était-ce différent?
Je ne l'aurais jamais publié si je ne l'avais pas testé, mais de façon réaliste, le volume occupé est réduit sur les projets. J'ai spécifiquement sur quelques anciens projets remplacé cette macro par une implémentation régulière sans masque, et regardé la différence. Le résultat surprend désagréablement.
Il s'est avéré que le volume reste pratiquement inchangé. J'ai spécifiquement choisi des projets où exactement 40 à 50 de ces instructions ont été utilisées. Selon la théorie, je devais bien économiser au moins 100 octets, et au plus 200. En pratique, la différence s'est avérée être de 24 à 32 octets. Mais pourquoi?
Habituellement, lorsque vous configurez des périphériques, vous configurez 5 à 10 registres presque d'affilée. Et à un niveau élevé d'optimisation, le compilateur n'organise pas les instructions exactement dans l'ordre des registres, mais organise les instructions comme il semble correct, les interférant parfois dans des endroits apparemment inextricables.
Je vois deux options (voici mes spéculations):
- Ou le compilateur est si intelligent qu'il sait pour vous comment il sera préférable d'optimiser l'ensemble des instructions
- Ou le compilateur n'est toujours pas plus intelligent qu'une personne, et se confond quand il rencontre de telles constructions
Autrement dit, il s'avère que cette méthode dans les langages «de haut niveau» à un niveau élevé d'optimisation ne fonctionne correctement que s'il n'y a pas d'opérations similaires à proximité d'une telle opération.
Soit dit en passant, au niveau O0, la théorie et la pratique convergent en tout cas, mais je ne suis pas intéressé par ce niveau d'optimisation.
Je résume
Un résultat négatif est également un résultat. Je pense que chacun tirera des conclusions pour lui-même. Personnellement, je continuerai à utiliser cette technique, elle n'en sera certainement pas pire.
J'espère que c'était intéressant et je veux exprimer un immense respect à ceux qui ont lu jusqu'au bout.
Liste de littérature
- «Manuel de référence technique Cortex-M3», section 4.2, ARM 2005.
- Le guide définitif de l'ARM Cortex-M3, Joseph Yiu.
PS J'ai dans mon sac une petite couverture des sujets liés au développement de l'électronique embarquée. Faites-moi savoir, si vous êtes intéressé, je vais les obtenir lentement.
PPS D'une manière ou d'une autre, il s'est avéré de manière tordue d'insérer des sections du code, veuillez me dire comment améliorer, si possible. En général, vous pouvez copier un morceau de code d'intérêt dans le bloc-notes et éviter les émotions désagréables dans l'analyse.
UPD:
À la demande des lecteurs, j'indique que l'opération de bande de bits elle-même est atomique, ce qui nous donne une certaine sécurité lorsque vous travaillez avec des registres. C'est l'une des caractéristiques les plus importantes de cette méthode.