
Cet article décrit les outils de sauvegarde qui sauvegardent en créant des archives sur un serveur de sauvegarde.
Parmi ceux qui satisfont aux exigences sont la duplicité (à laquelle il existe une belle interface sous la forme de deja dup) et les duplicati.
Un autre outil de sauvegarde très remarquable est Dar, mais comme il possède une liste très étendue d'options - la méthodologie de test couvre à peine 10% de ses capacités - nous ne le testons pas dans le cycle actuel.
Résultats attendus
Étant donné que les deux candidats créent des archives d'une manière ou d'une autre, vous pouvez utiliser le tar ordinaire comme ligne directrice.
De plus, nous estimons à quel point le stockage des données sur le serveur de stockage est optimisé en créant des sauvegardes contenant uniquement la différence entre la copie complète et l'état actuel des fichiers, ou entre les archives passées et actuelles (incrémentielles, décrémentielles, etc.).
Comportement de sauvegarde:
- Un nombre relativement faible de fichiers sur le serveur de stockage de sauvegarde (comparable au nombre de sauvegardes ou à la taille des données en Go), mais leur taille est assez importante (des dizaines à des centaines de mégaoctets).
- La taille du référentiel n'inclura que les modifications - les doublons ne seront pas stockés, donc la taille du référentiel sera plus petite que lors de l'exécution d'un logiciel basé sur rsync.
- Une lourde charge sur le processeur est attendue lors de l'utilisation de la compression et / ou du chiffrement, et aussi, probablement, une charge suffisamment importante sur le réseau et le sous-système de disque si le processus d'archivage et / ou de chiffrement fonctionne sur le serveur de stockage de sauvegarde.
En tant que valeur de référence, exécutez la commande suivante:
cd /src/dir; tar -cf - * | ssh backup_server "cat > /backup/dir/archive.tar"
Les résultats de l'exécution ont été les suivants:

Durée 3m12s. On peut voir que la vitesse reposait sur le sous-système de disque du serveur de stockage de sauvegarde, comme dans l'exemple rsync . Un peu plus vite, car l'enregistrement va dans un fichier.
De plus, pour évaluer la compression, nous exécuterons la même option, mais activer la compression côté serveur de la sauvegarde:
cd /src/dir; tar -cf - * | ssh backup_server "gzip > /backup/dir/archive.tgz"
Les résultats sont les suivants:
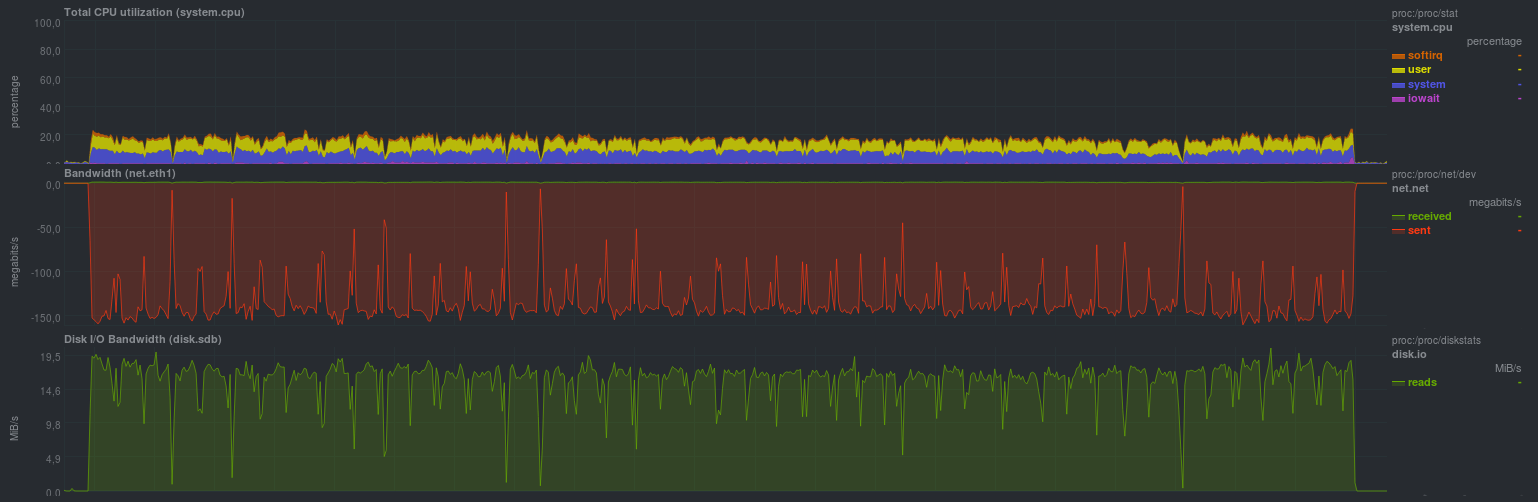
Le délai est de 10m11s. Le goulot d'étranglement est très probablement un compresseur à un seul fil du côté de la réception.
La même commande, mais avec le transfert de la compression vers le serveur avec les données sources pour tester l'hypothèse que le goulot d'étranglement est un compresseur monofil.
cd /src/dir; tar -czf - * | ssh backup_server "cat > /backup/dir/archive.tgz"
Il s'est avéré comme ceci:
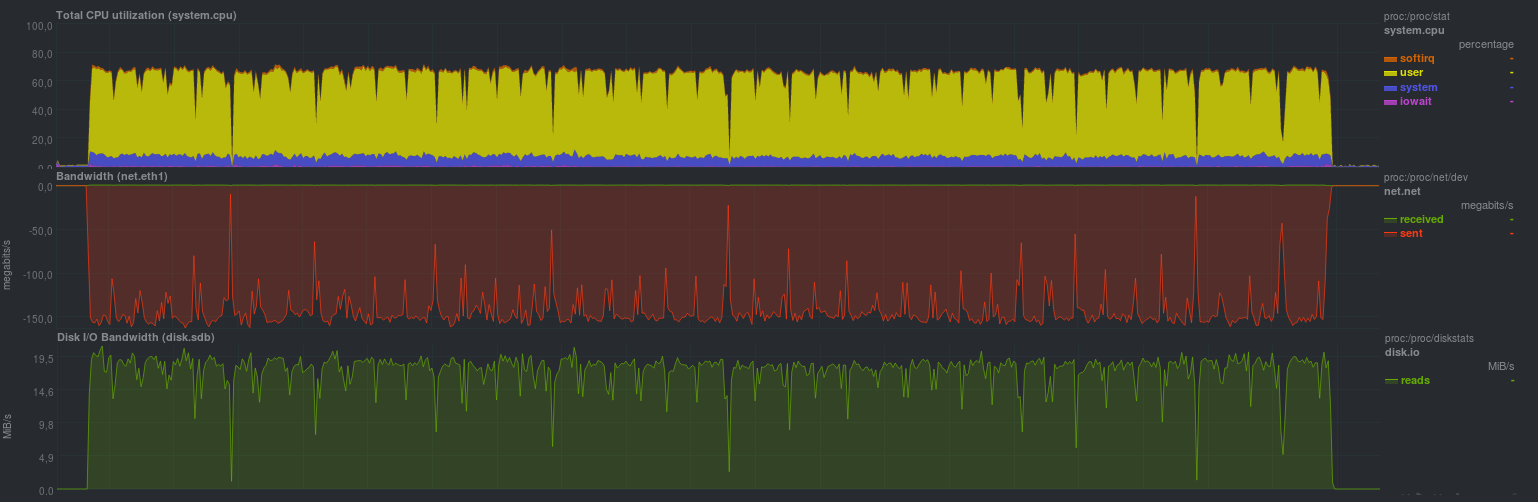
Le délai était de 9 min 37 s. La charge d'un noyau par le compresseur est clairement visible, comme la vitesse de transmission du réseau et la charge sur le sous-système de disque de la source sont similaires.
Pour évaluer le cryptage, vous pouvez utiliser openssl ou gpg en connectant la commande openssl ou gpg facultative au canal. Pour référence, il y aura une telle commande:
cd /src/dir; tar -cf - * | ssh backup_server "gzip | openssl enc -e -aes256 -pass pass:somepassword -out /backup/dir/archive.tgz.enc"
Les résultats sont les suivants:

Le temps d'exécution s'est avéré être de 10m30, puisque 2 processus ont été lancés du côté de la réception - le goulot d'étranglement était à nouveau un compresseur à filetage unique, plus une petite surcharge de cryptage.
UPD: A la demande de bliznezz, j'ajoute des tests avec pigz. Si vous n'utilisez que le compresseur - il s'est avéré pour 6m30s, si vous ajoutez également le cryptage - environ 7m. L'échec dans le graphique du bas est un cache disque non alloué:
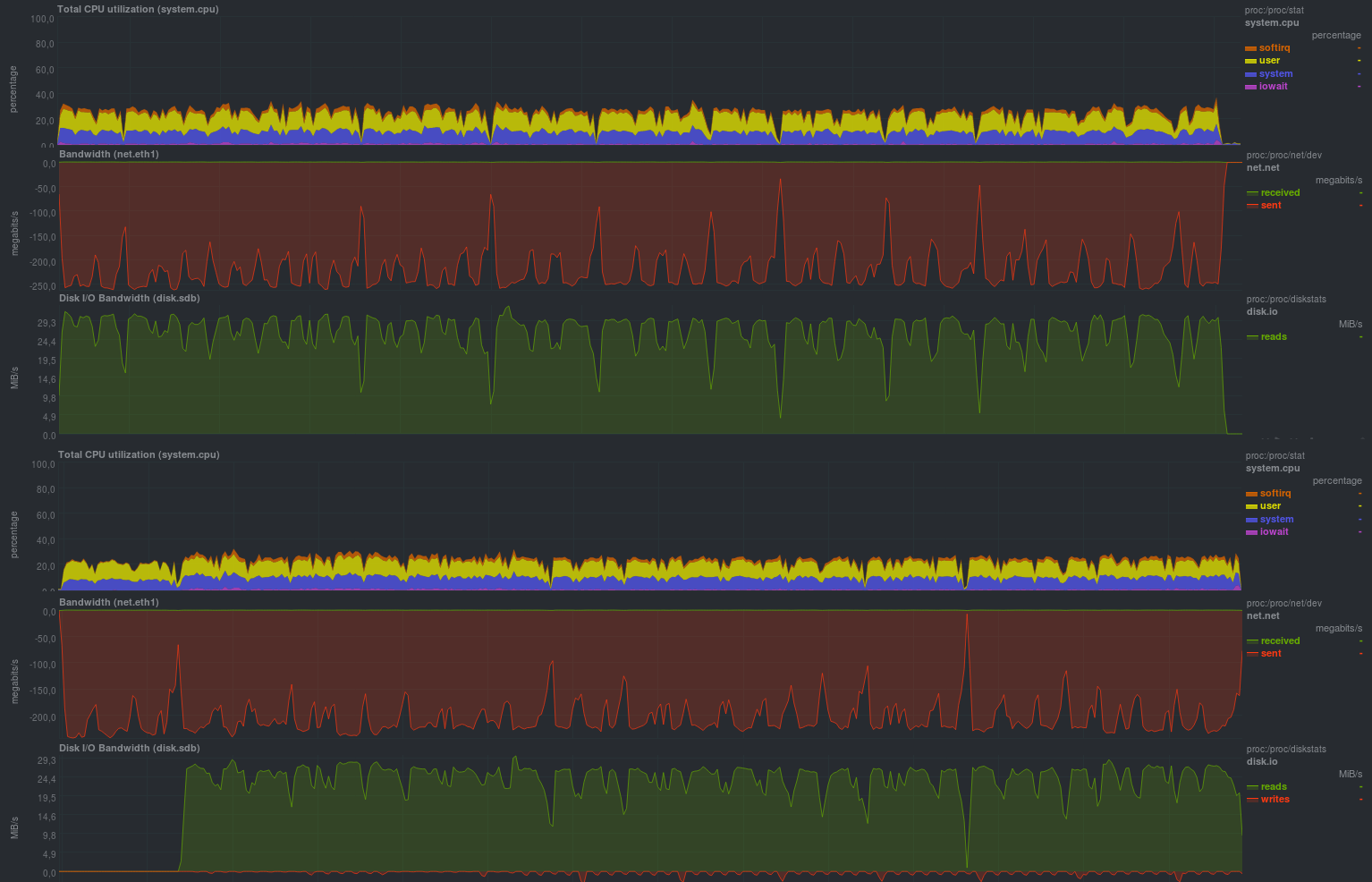
Tester la duplicité
Duplicity est un logiciel de sauvegarde python en créant des archives tar chiffrées.
Pour les archives incrémentielles, librsync est utilisé, vous pouvez donc vous attendre au comportement décrit dans la note de boucle précédente .
Les sauvegardes peuvent être chiffrées et signées à l'aide de gnupg, ce qui est important lorsque vous utilisez différents fournisseurs pour stocker des sauvegardes (s3, backblaze, gdrive, etc.)
Voyons quels seront les résultats:
Ce sont les résultats obtenus lors du démarrage sans chiffrementspoiler
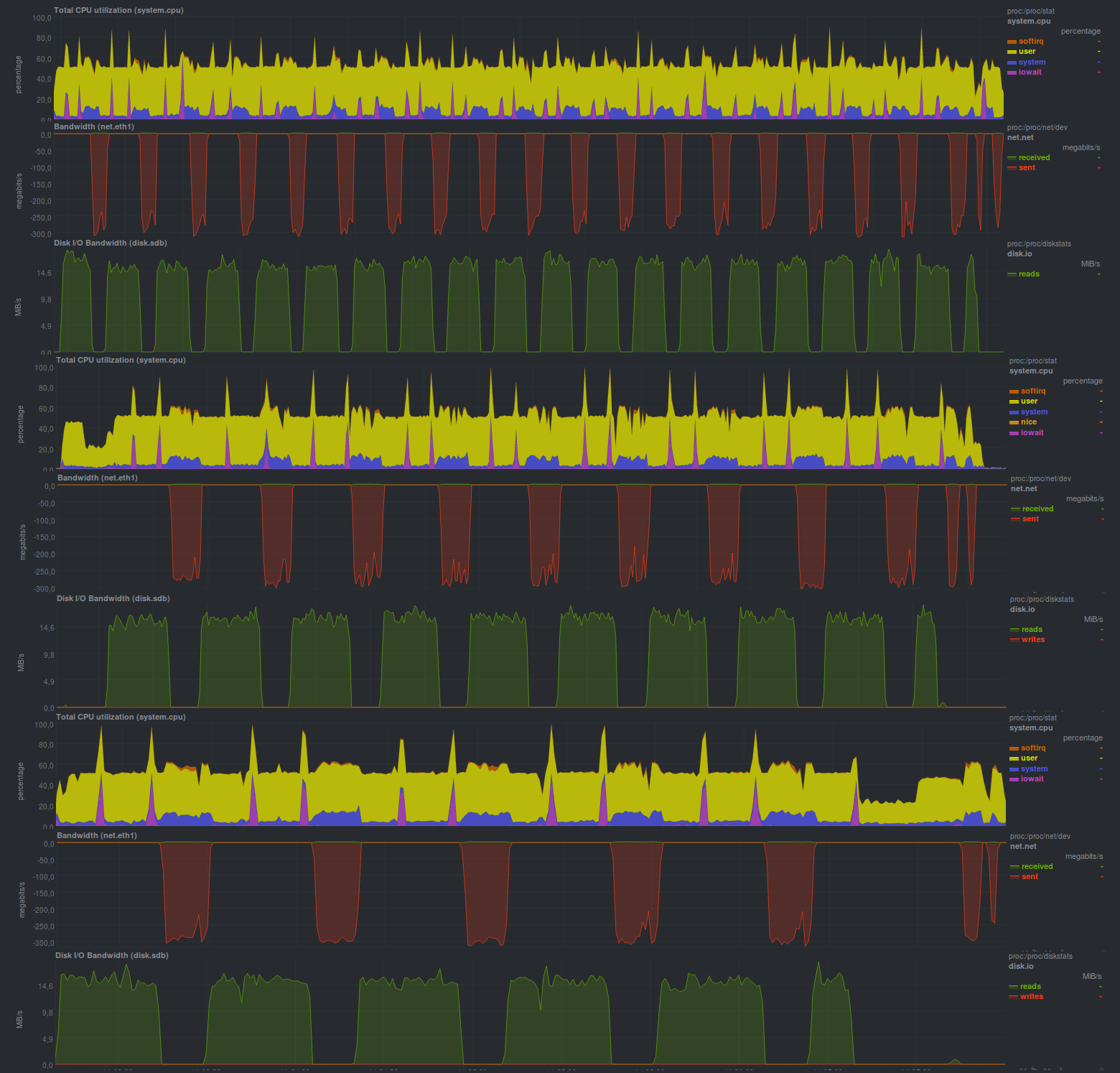
Le temps d'exécution de chaque test:
Et voici les résultats lorsque le cryptage gnupg est activé, avec une taille de clé de 2048 bits:
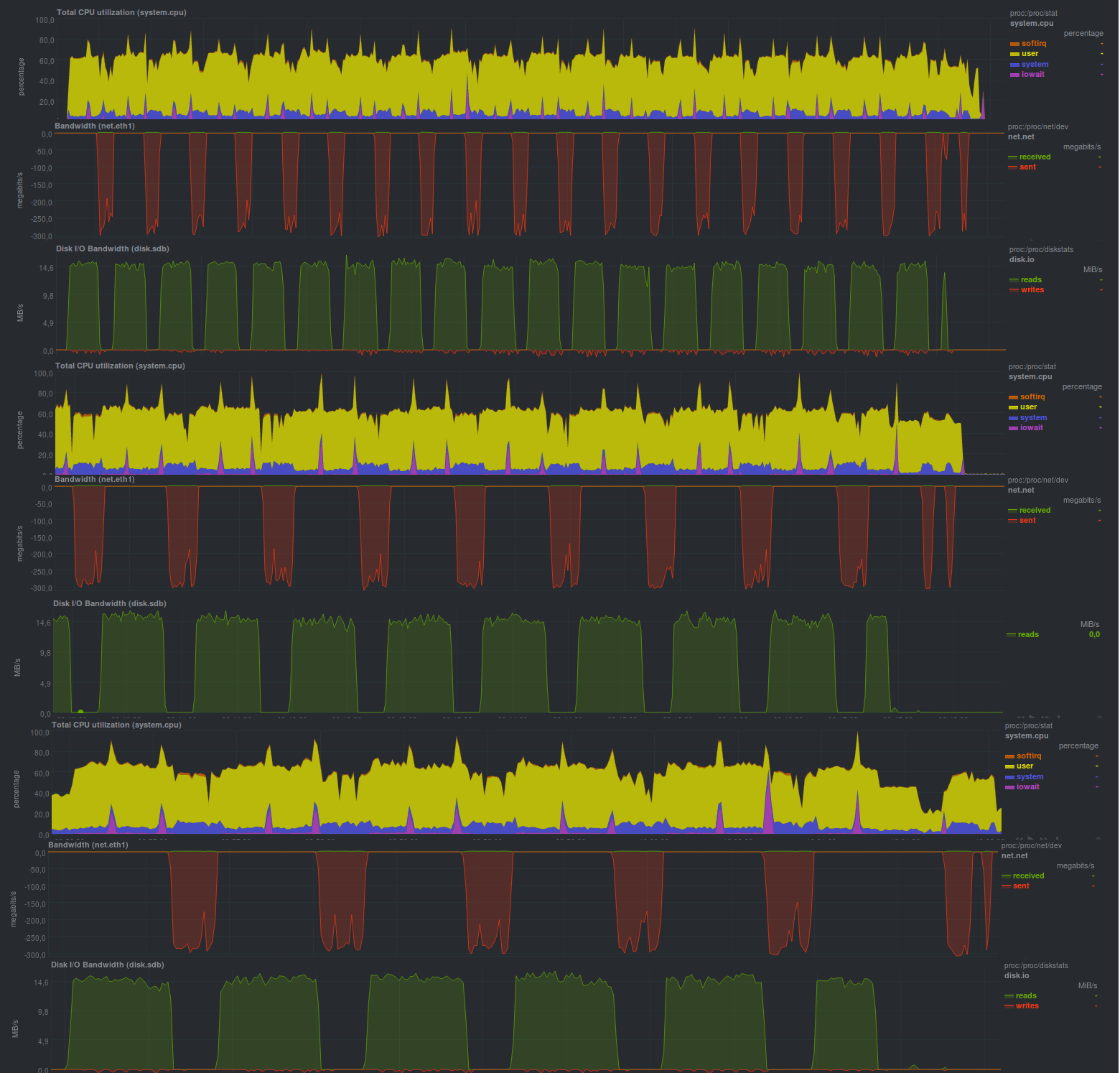
Temps de fonctionnement sur les mêmes données, avec cryptage:
La taille du bloc a été spécifiée - 512 mégaoctets, ce qui est clairement visible sur les graphiques; la charge du processeur est en fait maintenue au niveau de 50%, ce qui signifie que le programme n'utilise pas plus d'un cœur de processeur.
Le principe de fonctionnement du programme est également assez clairement visible: ils ont pris une donnée, l'ont secouée, l'ont envoyée au serveur de stockage de sauvegarde, ce qui peut être assez lent.
Une autre caractéristique est le temps d'exécution prévisible du programme, qui ne dépend que de la taille des données modifiées.
L'activation du chiffrement n'a pas augmenté de manière significative la durée d'exécution du programme, mais a augmenté la charge du processeur d'environ 10%, ce qui peut être un très bon bonus.
Malheureusement, ce programme n'a pas pu détecter correctement la situation avec le changement de nom du répertoire, et la taille du référentiel résultante s'est avérée être égale à la taille des modifications (c'est-à-dire toutes les 18 Go), mais la possibilité d'utiliser un serveur non fiable pour la sauvegarde couvre définitivement ce comportement.
Tester les doublons
Ce logiciel est écrit en C #, est lancé en utilisant un ensemble de bibliothèques de Mono. Il existe une interface graphique ainsi qu'une version cli.
Un exemple de liste des principales fonctionnalités est proche de la duplicité, y compris divers fournisseurs de stockage de sauvegarde, mais contrairement à la duplicité, la plupart des fonctionnalités sont disponibles sans outils tiers. Plus ou moins - cela dépend du cas spécifique, cependant, pour les débutants, il est probablement plus facile d'avoir une liste de toutes les fonctionnalités à la fois avant d'installer les packages pour python, comme c'est le cas avec la duplicité.
Une autre petite nuance est que le programme écrit activement la base de données sqlite locale au nom de l'utilisateur qui démarre la sauvegarde, vous devez donc en outre surveiller l'indication correcte de la base de données souhaitée chaque fois que le processus commence à utiliser cli. Lorsque vous travaillez via l'interface graphique ou WEBGUI, les détails seront cachés à l'utilisateur.
Voyons quels indicateurs cette solution peut donner:Si vous désactivez le chiffrement (et WEBGUI ne le recommande pas), les résultats sont les suivants:
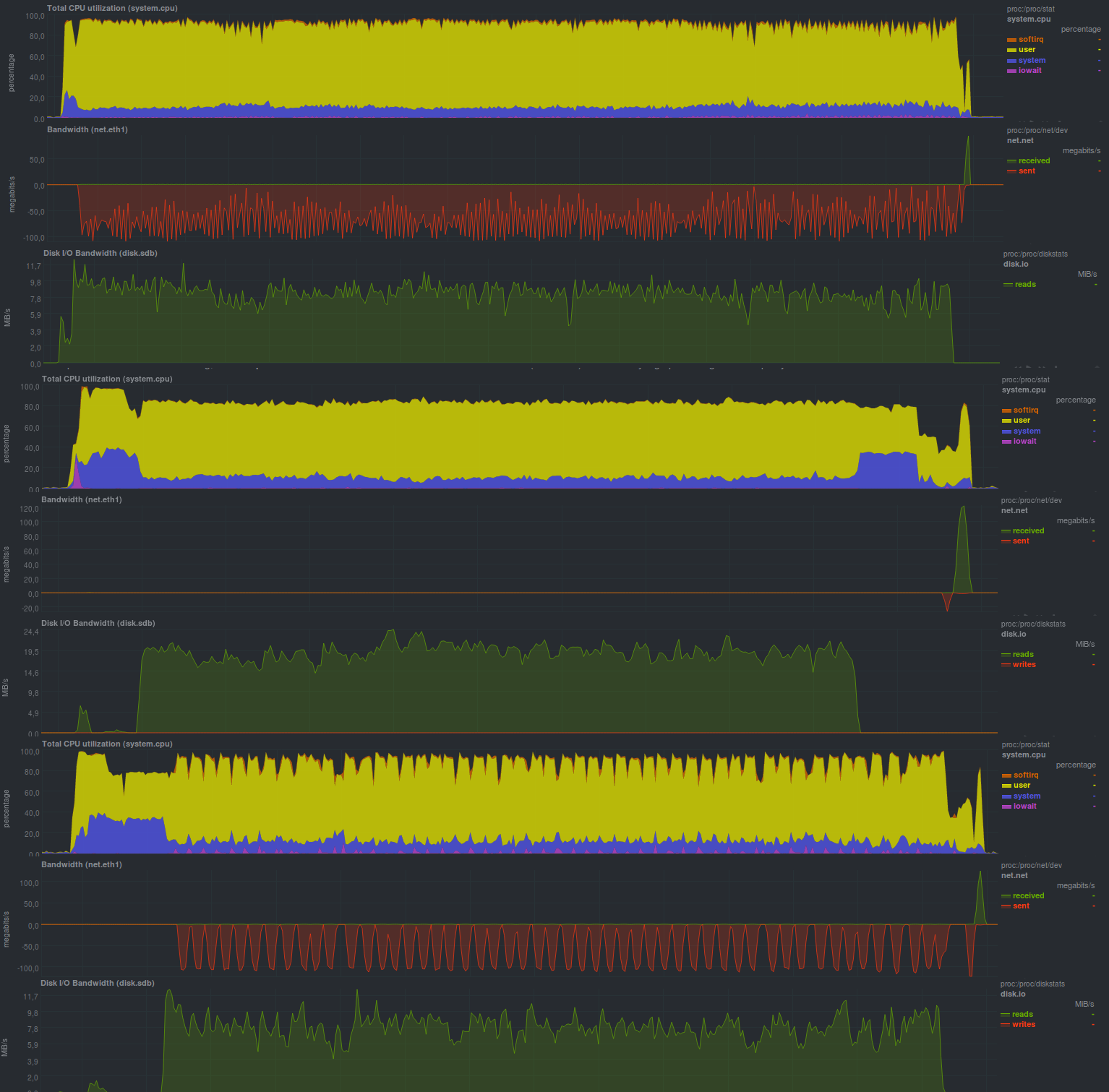
Temps de travail:
Avec le cryptage activé, en utilisant aes, il s'avère comme ceci:
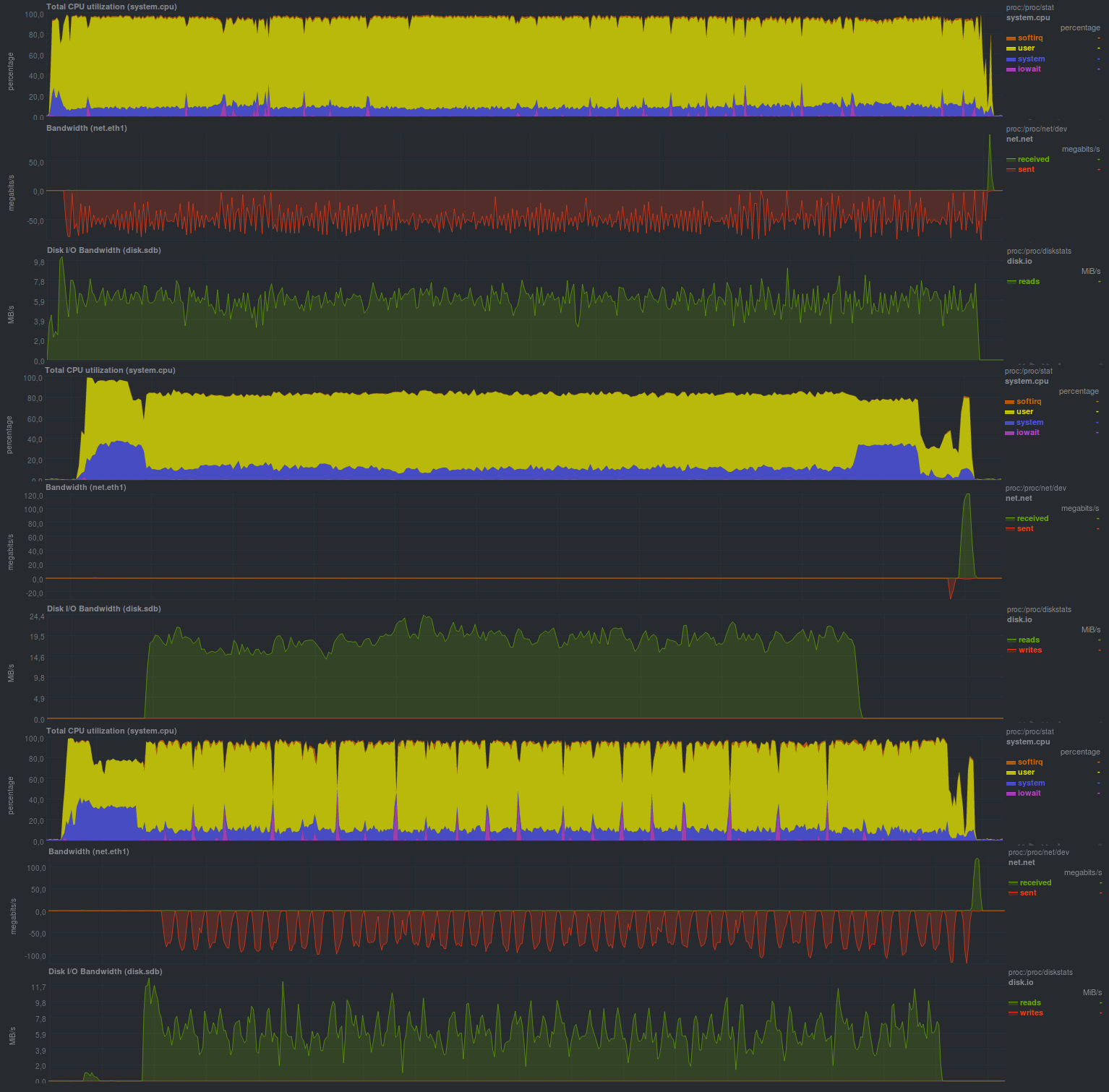
Temps de travail:
Et si vous utilisez le programme gnupg externe, vous obtenez les résultats suivants:

Comme vous pouvez le voir, le programme peut fonctionner dans plusieurs threads, mais ce n'est pas une solution plus productive, et si vous comparez le cryptage, il démarre un programme externe
s'est avéré plus rapide que l'utilisation de la bibliothèque de la suite Mono. Cela est peut-être dû au fait que le programme externe est plus optimisé.
Un moment agréable a également été le fait que la taille du référentiel prend exactement autant que les données réelles ont été modifiées, c'est-à-dire duplicati a détecté un renommage de répertoire et a correctement géré cette situation. Cela peut être vu lors de l'exécution du deuxième test.
En général, une impression assez positive du programme, y compris une convivialité suffisante pour les débutants.
Résultats
Les deux candidats ont travaillé assez lentement, mais en général, par rapport au goudron habituel, il y a des progrès, du moins duplicati. Le prix de ces progrès est également compréhensible - un fardeau notable
le processeur. En général, il n'y a pas d'écarts particuliers dans la prévision des résultats.
Conclusions
Si vous n'avez pas besoin de vous dépêcher n'importe où, et qu'il y a également une marge sur le processeur, l'une des solutions envisagées fera, en tout cas, beaucoup de travail a été fait, qui ne devrait pas être répété en écrivant des scripts wrapper sur tar. La présence du chiffrement est une propriété très nécessaire si le serveur de stockage des sauvegardes ne peut pas être entièrement fiable.
Par rapport aux solutions basées sur rsync , les performances peuvent être plusieurs fois moins bonnes, malgré le fait que, sous sa forme pure, le tar fonctionnait plus rapidement que rsync de 20 à 30%.
Économiser sur la taille du référentiel est, mais uniquement pour les doublons.
Annonce
Sauvegarde, partie 1: Pourquoi avez-vous besoin d'une sauvegarde, un aperçu des méthodes, des technologies
Sauvegarde, Partie 2: Présentation et test des outils de sauvegarde basés sur rsync
Sauvegarde, Partie 3: Présentation et test de la duplicité, duplicati, deja dup
Sauvegarde, Partie 4: Présentation et test de zbackup, restic, borgbackup
Sauvegarde, Partie 5: Test de Bacula et Veeam Backup pour Linux
Sauvegarde: pièce demandée par les lecteurs: revue AMANDA, UrBackup, BackupPC
Sauvegarde, partie 6: comparaison des outils de sauvegarde
Sauvegarde, partie 7: Conclusions
Publié par Finnix