Comme vous le savez, le code est lu beaucoup plus souvent qu'il n'est écrit. Pour qu'au moins quelqu'un d'autre que l'auteur puisse le lire, et il existe des guides de style. Pour R, il peut s'agir, par exemple, du manuel Hadley.
Un guide de style n'est pas seulement un accord tacite entre développeurs - de nombreuses règles ont un arrière-plan curieux. Pourquoi la flèche
<- meilleure que le signe égal
= , pourquoi les anciens R n'aiment pas les traits de soulignement, comment la longueur de ligne recommandée est associée à une carte perforée, et bien plus encore.
Avis de non-responsabilité: R Style GuidesContrairement à Python, R n'a pas de standard unique. En conséquence, il n'y a pas de guide unique. En plus du
guide Hadley (ou de sa version étendue de
tidyverse ), il y en a d'autres, comme
Google ou
Bioconductor .
Cependant, le guide Hadley peut être considéré comme le plus courant (comme la
vérification RStudio
intégrée , par exemple), ce qui est grandement facilité par la popularité des bibliothèques créées par Hadley lui-même (dplyr, ggplot, tidyr et d'autres de la collection tidyverse).
1. Opérateur d'affectation: <- vs =
Tous les guides disponibles recommandent d'utiliser l'opérateur non standard
<- , mais pas le signe égal
= , qui est courant pour les autres langues modernes. Trois autres opérateurs (
<<- ,
-> ,
->> ) ne sont même pas mentionnés (comme celui qui existait dans les versions antérieures
:= ). Il semblerait, pourquoi avons-nous besoin de cette flèche non standard?
L'histoire nous révèle les cartes: dans R, la flèche venait de S, qui à son tour l'a héritée de l'APL. En APL, cela nous a permis de distinguer l'affectation de l'égalité. Dans R, l'opérateur d'égalité est standard, donc la différence est différente. Si la flèche était initialement un opérateur d'affectation, le signe égal n'affectait des valeurs
qu'aux paramètres nommés. En 2001, le signe égal est devenu l'opérateur d'affectation, mais n'est jamais devenu synonyme de flèche.
Qu'est-ce qui nous permet d'envisager
= remplacement complet de la flèche? Tout d'abord,
= comment l'opérateur d'affectation ne fonctionne qu'au niveau supérieur. Par exemple, à l'intérieur de la fonction, tout fonctionnera comme avant:
mean(x = 1:5)
Ici
= ne définit que le paramètre de la fonction, tandis que
<- affecte également la valeur à la variable x. Nous pouvons obtenir le même effet en plaçant l'opération d'affectation entre parenthèses
(non, ce n'est toujours pas Lisp) :
mean ((x = 1:5))
... ou entre accolades:
mean ({x = 1:5})
De plus, la flèche a priorité sur le signe égal:
x <- y <- 1
La dernière expression a échoué car elle est équivalente à
(x <- y) = 4 , et l'analyseur l'interprète comme
`<-<-`(x, y = 4, value = 4)
En d'autres termes, nous essayons d'effectuer une opération incorrecte: nous assignons d'abord x à y, puis nous essayons d'affecter x et y à 4. L'expression sera traitée sans erreur uniquement si vous modifiez la priorité des opérations entre parenthèses:
x <- (y = 4) .
2. Espacement
Le guide recommande de mettre des espaces entre les opérateurs (sauf, bien sûr, les crochets,:, :: et :: :), ainsi qu'avant le crochet ouvrant. Évidemment, cela fait partie des normes de codage GNU. Cependant, cette clause est étroitement liée à l'utilisation de
<- comme opérateur d'assignation. Par exemple
x <-1
Qu'est ce que c'est X est inférieur à -1? Ou définissez x sur 1?
Cependant, l'espace supplémentaire n'est pas meilleur que celui manquant, par exemple:
x <- 0 ifelse(x <-1, T, F)
Dans le premier cas, il n'y a pas d'espace entre
< et
- , ce qui crée un opérateur d'affectation.
3. Noms des fonctions et des variables
Les guides de style ne sont pas d'accord sur la question des noms: le guide Hadley recommande des soulignés pour tous les noms; Guide Google - séparation par points pour les variables et le style camel avec le premier minuscule pour les fonctions; Bioconductor recommande lowerCamel pour les fonctions et les variables. Il n'y a pas d'unité dans la communauté R sur cette question, et tous les styles possibles peuvent être trouvés:
lowerCamel period.separation lower_case_with_underscores allowercase UpperCamel
Il n'y a pas de style uniforme même pour les noms de base R (par exemple, les noms de dossier et les noms de ligne sont des fonctions différentes!). Si vous ne tenez pas compte de la majuscule illisible (seuls les utilisateurs de Matlab peuvent l'adorer), il existe trois styles les plus populaires: lowerCamel, minuscule avec _ et minuscule avec séparation de points.
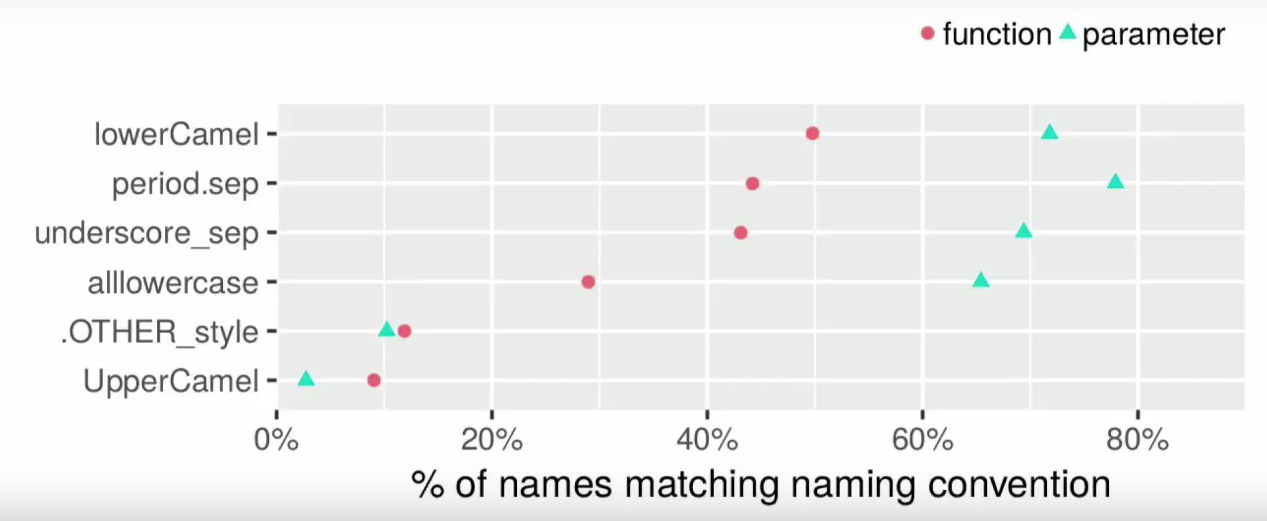
La popularité de différents styles pour les noms de fonction et les paramètres (un nom peut correspondre à différents styles). Source: Rasmus Bååth
performance sur useR! 2017.
La séparation point à point rappelle de manière inquiétante l'utilisation de méthodes dans la programmation orientée objet, mais est historiquement courante. Il est si courant que ce style particulier peut être considéré comme vraiment R'vsky. Par exemple, la plupart des fonctions de base l'utilisent spécifiquement (et tout le monde vient de rencontrer data.table et as.factor).
Mais la séparation _ est l'un des styles les moins populaires (et ici Hadley va à l'encontre de la majorité). Pour de nombreux utilisateurs de R, les traits de soulignement seront gênants: dans l'extension Emacs Speaks Statistics, il est remplacé par défaut par l'opérateur d'affectation
<- . Et les paramètres par défaut, bien sûr,
presque personne ne change.
Cependant, l'influence d'Emacs ESS est toujours une explication de la catégorie des «queues remue le chien». Il y a une raison plus ancienne: dans les versions antérieures de R, le trait de soulignement était synonyme de la flèche
<- . Par exemple, en 2000, vous pourriez
rencontrer ceci:
Ici, au lieu de créer la variable
c_mean R a attribué la valeur 3 d'abord à la moyenne des variables, puis à la variable c. Dans le R moderne, de telles métamorphoses, bien sûr, ne se produiront pas.
En raison de l'impopularité, les fonctions _ de ce style ne sont presque pas trouvées parmi les fonctions de base:
Enfin, le style LowerCamel est mal lisible lors de l'utilisation de noms longs:
Ainsi, en termes de noms, les recommandations du guide ne peuvent être considérées comme sans ambiguïté; après tout, c'est une question de goût (tant qu'il y a de la cohérence).
4. Bretelles
Selon le guide, une nouvelle ligne doit suivre l'accolade ouvrante et la fermeture doit être sur une ligne distincte (sauf indication contraire). C'est-à-dire quelque chose comme ça:
if (x >= 0) { log(x) } else { message("Not applicable!") }
Tout ici n'est pas très intéressant: c'est le style d'indentation standard de K&R, qui remonte au langage C et au célèbre livre de Kernigan et Ritchie «The C Programming Language» (ou K&R par les noms des auteurs).
Les origines de ce style sont également assez évidentes: il vous permet de sauvegarder des lignes, tout en conservant la lisibilité. Pour les premiers ordinateurs, l'espace vertical était trop un luxe. Par exemple, C a été développé sur PDP-11, dans le terminal duquel il n'y avait que 24 lignes. Et lors de l'impression d'un livre K&R, ce style économise du papier!
5. Chaîne de 80 caractères
La longueur de ligne recommandée selon le guide est de 80 caractères. Le nombre magique 80 se trouve non seulement dans R, mais aussi dans un grand nombre d'autres langages (Java, Perl, PHP, etc., etc.). Et pas seulement les langues: même la ligne de commande Windows se compose de 80 caractères.
Pour la première fois en programmation, ce nombre est apparu en 1928 au lieu de la carte perforée IBM standard, où il y avait exactement 80 colonnes de données. Une question beaucoup plus intéressante est pourquoi une telle norme a été choisie? Après tout, des cartes perforées d'une longueur différente (pour 24 ou 45 colonnes) étaient auparavant utilisées.

La réponse la plus populaire fait le lien entre la longueur d'une carte perforée et la longueur de ligne des machines à écrire. Les premières machines ont été conçues pour le papier standard américain 8½ x 11 pouces, et ont permis d'imprimer de 72 à 90 caractères, selon la taille des marges. Par conséquent, la version de 80 caractères par ligne semble tout à fait plausible, bien que ce ne soit pas vrai en dernier ressort. Il est possible que 80 caractères ne soient que le juste milieu en termes d'ergonomie.
6. Retrait de ligne: espaces vs tabulations
Le style recommandé par le guide est deux espaces, pas un onglet. Le refus de tabuler est tout à fait compréhensible: la longueur de la tabulation varie selon les éditeurs de texte (elle peut aller de 2 à 8 espaces). En les refusant, nous obtenons deux avantages à la fois: premièrement, le code sera exactement le même que nous l'avons tapé; deuxièmement, il n'y aura pas de violation accidentelle de la longueur de chaîne recommandée. Dans ce cas, bien sûr, nous augmentons la taille du fichier (qui veut faire face à de telles microoptimisations en 2k19?)
Les espaces de litige vs onglets ont une longue histoire et peuvent être assimilés à des espaces religieux (tels que Win vs Linux, Android vs iOS, etc.). Cependant, nous savons déjà qui l'a gagné: selon l'
étude Stack Overflow, les développeurs qui utilisent des espaces gagnent plus que ceux qui utilisent des tabulations. Un argument plus puissant que les règles d'un guide de style, non?
Au lieu d'une conclusion: les règles des guides de style peuvent sembler étranges et illogiques. En effet, pourquoi la flèche
<- s'il y a un opérateur standard
= ? Mais si vous creusez plus profondément, derrière chaque règle il y a une logique, souvent déjà oubliée.