
Bonjour, Habr! Je vous présente la traduction adaptée du premier chapitre de "
Node.js Best Practices " de Yoni Goldberg. Une sélection de recommandations sur Node.js est publiée sur github, compte près de 30 tonnes d'étoiles, mais n'a jusqu'à présent pas été mentionnée sur Habr. Je suppose que cette information sera utile, au moins pour les débutants.
1. Conseils sur la structure du projet
1.1 Structurez votre projet par composant
La pire erreur des grandes applications est l'architecture monolithique sous la forme d'une énorme base de code avec un grand nombre de dépendances (code spaghetti), cette structure ralentit considérablement le développement, notamment l'introduction de nouvelles fonctions. Astuce - séparez votre code en composants séparés, pour chaque composant, sélectionnez votre propre dossier pour les modules de composants. Il est important que chaque module reste petit et simple. Dans la section "Détails", vous pouvez voir des exemples de la structure correcte des projets.
Sinon: il sera difficile pour les développeurs de développer le produit - l'ajout de nouvelles fonctionnalités et la modification du code seront lents et auront de fortes chances de casser d'autres composants dépendants. On pense que si les unités commerciales ne sont pas divisées, il peut y avoir des problèmes avec la mise à l'échelle de l'application.
DétailsExplication d'un paragraphePour les applications de taille moyenne et plus, les monolithes sont vraiment mauvais - un grand programme avec de nombreuses dépendances est tout simplement difficile à comprendre et conduit souvent à du code spaghetti. Même les programmeurs expérimentés qui savent «préparer correctement les modules» consacrent beaucoup d'efforts à la conception architecturale et essaient d'évaluer soigneusement les conséquences de chaque changement dans les relations entre les objets. La meilleure option est une architecture basée sur un ensemble de programmes de petits composants: divisez le programme en composants séparés qui ne partagent leurs fichiers avec personne, chaque composant doit être composé d'un petit nombre de modules (par exemple, modules: API, service, accès à la base de données, tests etc.), de sorte que la structure et la composition du composant soient évidentes. Certains peuvent appeler cette architecture «microservice», mais il est important de comprendre que les microservices ne sont pas une spécification que vous devez suivre, mais plutôt un ensemble de principes. À votre demande, vous pouvez adopter à la fois chacun de ces principes et tous les principes de l'architecture de microservices. Les deux méthodes sont bonnes si vous gardez la complexité du code faible.
Le moins que vous ayez à faire est de définir les limites entre les composants: attribuez un dossier à la racine de votre projet pour chacun d'eux et rendez-les autonomes. L'accès à la fonctionnalité du composant doit être implémenté uniquement via une interface publique ou une API. C'est la base pour garder la simplicité de vos composants, éviter «l'enfer des dépendances» et permettre à votre application d'évoluer vers des microservices à part entière.
Citation du blog: "La mise à l'échelle nécessite la mise à l'échelle de l'application entière"Du blog MartinFowler.com
Les applications monolithiques peuvent réussir, mais les gens en sont de plus en plus frustrés, surtout lorsqu'ils envisagent de déployer sur le cloud. Toute modification, même minime, de l'application nécessite l'assemblage et le redéploiement de l'ensemble du monolithe. Il est souvent difficile de maintenir constamment une bonne structure modulaire dans laquelle les modifications d'un module n'affectent pas les autres. La mise à l'échelle nécessite de mettre à l'échelle l'ensemble de l'application, et pas seulement ses parties individuelles, bien sûr, cette approche nécessite plus d'efforts.
Citation du blog: "De quoi parle l'architecture de votre application?"Du blog d'
oncle-bob... si vous êtes allé à la bibliothèque, vous représentez son architecture: l'entrée principale, les bureaux d'accueil, les salles de lecture, les salles de conférence et de nombreuses salles avec des étagères. L'architecture elle-même dira: ce bâtiment est une bibliothèque.
De quoi parle donc l'architecture de votre application? Lorsque vous regardez la structure de répertoires de niveau supérieur et les fichiers de modules qui s'y trouvent, ils disent: je suis une boutique en ligne, je suis comptable, je suis un système de gestion de la production? Ou crient-ils: je suis Rails, je suis Spring / Hibernate, je suis ASP?
(Note du traducteur, Rails, Spring / Hibernate, ASP sont des frameworks et des technologies web).
Structure de projet appropriée avec composants autonomes Structure de projet incorrecte avec regroupement des fichiers par objectif
Structure de projet incorrecte avec regroupement des fichiers par objectif
1.2 Séparez les couches de vos composants et ne les mélangez pas avec la structure de données Express
Chacun de vos composants doit avoir des «couches», par exemple, pour fonctionner avec le Web, la logique métier, l'accès à la base de données, ces couches doivent avoir leur propre format de données non mélangé avec le format de données des bibliothèques tierces. Cela permet non seulement de séparer clairement les problèmes, mais facilite également considérablement la vérification et les tests du système. Souvent, les développeurs d'API mélangent des couches en passant des objets de couche Web Express (comme req, res) à la couche logique et données métier - cela rend votre application dépendante et hautement connectée à Express.
Sinon: pour une application dans laquelle des objets de couche sont mélangés, il est plus difficile de fournir des tests de code, l'organisation de tâches CRON et d'autres appels non Express.
DétailsDivisez le code du composant en couches: Web, services et DALLe revers est de mélanger les couches dans une animation gif
1.3 Enveloppez vos utilitaires de base dans des packages npm
Dans une grande application composée de divers services avec leurs propres référentiels, des utilitaires universels tels qu'un enregistreur, un chiffrement, etc., doivent être emballés avec votre propre code et présentés comme des packages npm privés. Cela vous permet de les partager entre plusieurs bases de code et projets.
Sinon: vous devez inventer votre propre vélo pour partager ce code entre des bases de code distinctes.
DétailsExplication d'un paragrapheDès que le projet commence à croître et que vous avez différents composants sur différents serveurs utilisant les mêmes utilitaires, vous devez commencer à gérer les dépendances. Comment puis-je autoriser plusieurs composants à l'utiliser sans dupliquer le code de votre utilitaire entre les référentiels? Il existe un outil spécial pour cela, et il s'appelle npm .... Commencez par emballer les packages d'utilitaires tiers avec votre propre code afin de pouvoir le remplacer facilement à l'avenir, et publiez ce code en tant que package npm privé. Maintenant, votre base de code entière peut importer le code des utilitaires et utiliser toutes les fonctionnalités de gestion des dépendances npm. N'oubliez pas qu'il existe les façons suivantes de publier des packages npm pour un usage personnel sans les ouvrir pour l'accès public:
modules privés, registre privé ou
packages npm locaux .
Partage de vos propres utilitaires partagés dans différents environnements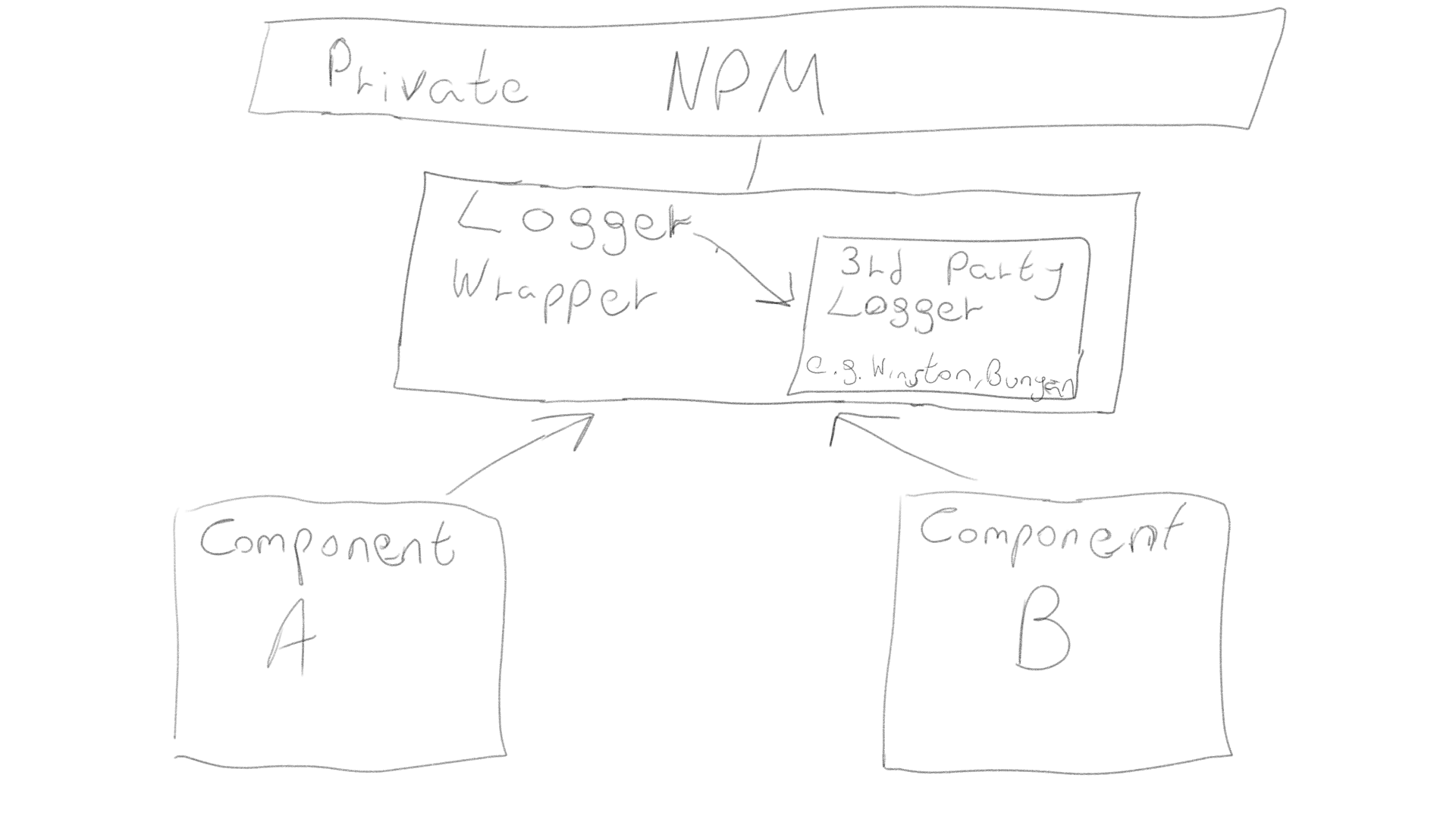
1.4 Séparez Express en «application» et «serveur»
Évitez l'habitude désagréable de définir l'intégralité de votre application Express dans un énorme fichier, divisez votre code 'Express' en au moins deux fichiers: une déclaration API (app.js) et un code de serveur www. Pour une structure encore meilleure, placez une déclaration API dans les modules de composants.
Sinon: votre API ne sera disponible que pour les tests via les appels HTTP (ce qui est plus lent et beaucoup plus difficile à générer des rapports de couverture). Pourtant, je suppose que ce n'est pas trop amusant de travailler avec des centaines de lignes de code dans un seul fichier.
DétailsExplication d'un paragrapheNous vous recommandons d'utiliser le générateur d'application Express et son approche de construction de la base de données d'application: la déclaration d'API est séparée de la configuration du serveur (données de port, protocole, etc.). Cela vous permet de tester l'API sans passer d'appels réseau, ce qui accélère les tests et facilite l'obtention des mesures de couverture de code. Il vous permet également de déployer de manière flexible la même API pour différents paramètres réseau du serveur. En prime, vous bénéficiez également d'une meilleure séparation des responsabilités et d'un code plus propre.
Exemple de code: déclaration API, doit être dans app.jsvar app = express(); app.use(bodyParser.json()); app.use("/api/events", events.API); app.use("/api/forms", forms);
Exemple de code: les paramètres réseau du serveur doivent être dans / bin / www var app = require('../app'); var http = require('http'); var port = normalizePort(process.env.PORT || '3000'); app.set('port', port); var server = http.createServer(app);
Exemple: tester notre API à l'aide de supertest (un package de test populaire) const app = express(); app.get('/user', function(req, res) { res.status(200).json({ name: 'tobi' }); }); request(app) .get('/user') .expect('Content-Type', /json/) .expect('Content-Length', '15') .expect(200) .end(function(err, res) { if (err) throw err; });
1.5 Utiliser une configuration hiérarchique sécurisée basée sur des variables d'environnement
Un paramètre de configuration idéal devrait fournir:
(1) lire les clés du fichier de configuration et des variables d'environnement,
(2) garder les secrets en dehors du code du référentiel,
(3) structure de données hiérarchique (plutôt que plate) du fichier de configuration pour faciliter le travail avec les paramètres.
Plusieurs packages peuvent aider à implémenter ces points, tels que: rc, nconf et config.
Sinon: le non-respect de ces exigences de configuration entraînera une interruption du travail à la fois d'un développeur individuel et de toute l'équipe.
DétailsExplication d'un paragrapheLorsque vous traitez avec des paramètres de configuration, beaucoup de choses peuvent être ennuyeuses et ralentir:
1. La définition de tous les paramètres à l'aide de variables d'environnement devient très fastidieuse si vous devez saisir plus de 100 clés (au lieu de simplement les corriger dans le fichier de configuration), cependant, si la configuration sera spécifiée uniquement dans les fichiers de paramètres, cela peut être gênant pour DevOps. Une solution de configuration fiable doit combiner les deux méthodes: les fichiers de configuration et les remplacements de paramètres des variables d'environnement.
2. Si le fichier de configuration est JSON «plat» (c'est-à-dire que toutes les clés sont écrites comme une seule liste), alors avec une augmentation du nombre de paramètres, il sera difficile de travailler avec. Ce problème peut être résolu en formant des structures imbriquées contenant des groupes de clés selon les sections de paramètres, c'est-à-dire organiser une structure de données JSON hiérarchique (voir l'exemple ci-dessous). Il existe des bibliothèques qui vous permettent de stocker cette configuration dans plusieurs fichiers et de combiner les données de celles-ci au moment de l'exécution.
3. Il n'est pas recommandé de stocker des informations confidentielles (comme un mot de passe de base de données) dans des fichiers de configuration, mais il n'y a pas de solution pratique définie pour où et comment stocker ces informations. Certaines bibliothèques de configuration vous permettent de chiffrer les fichiers de configuration, d'autres chiffrent ces entrées lors des validations git, ou vous pouvez enregistrer des paramètres secrets dans des fichiers et définir leurs valeurs lors du déploiement via des variables d'environnement.
4. Certains scénarios de configuration avancés nécessitent que vous saisissiez des clés via la ligne de commande (vargs) ou synchronisiez les données de configuration via un cache centralisé tel que Redis afin que plusieurs serveurs utilisent les mêmes données.
Il existe des bibliothèques npm qui vous aideront à mettre en œuvre la plupart de ces recommandations, nous vous conseillons de jeter un œil aux bibliothèques suivantes:
rc ,
nconf et
config .
Exemple de code: la structure hiérarchique permet de trouver des enregistrements et de travailler avec des fichiers de configuration volumineux
{ // Customer module configs "Customer": { "dbConfig": { "host": "localhost", "port": 5984, "dbName": "customers" }, "credit": { "initialLimit": 100, // Set low for development "initialDays": 1 } } }
(Remarque du traducteur, les commentaires ne peuvent pas être utilisés dans le fichier JSON classique. L'exemple ci-dessus est tiré de la documentation de la bibliothèque de configuration, qui ajoute des fonctionnalités de pré-effacement des fichiers JSON des commentaires. Par conséquent, l'exemple fonctionne très bien, cependant, des linters tels que ESLint avec des paramètres par défaut peuvent "Jure" sur un format similaire).
Mot du traducteur:
- La description du projet indique que la traduction en russe a déjà été lancée, mais je n'ai pas trouvé cette traduction là-bas, j'ai donc repris l'article.
- Si la traduction vous semble très brève, essayez d'élargir les informations détaillées de chaque section.
- Désolé que les illustrations n'aient pas été traduites.