Les systèmes de modération automatique sont mis en œuvre dans les services et applications Web où il est nécessaire de traiter un grand nombre de messages utilisateur. De tels systèmes peuvent réduire les coûts de la modération manuelle, l'accélérer et traiter tous les messages des utilisateurs en temps réel. Dans l'article, nous parlerons de la construction d'un système de modération automatique pour le traitement de l'anglais à l'aide d'algorithmes d'apprentissage automatique. Nous discuterons de l'ensemble du travail sur le pipeline depuis les tâches de recherche et le choix des algorithmes ML jusqu'au déploiement en production. Voyons où chercher des ensembles de données prêts à l'emploi et comment collecter vous-même les données pour la tâche.
Préparé avec Ira Stepanyuk ( id_step ), Data Scientist chez Poteha LabsDescription de la tâche
Nous travaillons avec des chats actifs multi-utilisateurs, où de courts messages de dizaines d'utilisateurs peuvent apparaître dans un chat toutes les minutes. La tâche consiste à mettre en évidence les messages toxiques et les messages contenant des remarques obscènes dans les dialogues de ces chats. Du point de vue de l'apprentissage automatique, il s'agit d'une tâche de classification binaire, où chaque message doit être affecté à l'une des classes.
Pour résoudre ce problème, il fallait tout d'abord comprendre ce que sont les messages toxiques et ce qui les rend exactement toxiques. Pour ce faire, nous avons examiné un grand nombre de messages utilisateur typiques sur Internet. Voici quelques exemples que nous avons déjà divisés en messages toxiques et normaux.
On peut voir que les messages toxiques contiennent souvent des mots obscènes, mais ce n'est toujours pas une condition préalable. Le message peut ne pas contenir de mots inappropriés, mais être offensant pour quelqu'un (exemple (1)). De plus, les messages parfois toxiques et normaux contiennent les mêmes mots qui sont utilisés dans différents contextes - offensants ou non (exemple (2)). De tels messages doivent également pouvoir se distinguer.
Après avoir étudié divers messages, pour notre système de modération, nous avons appelé
toxique les messages qui contiennent des déclarations avec des expressions obscènes et insultantes ou de la haine envers quelqu'un.
Les données
Données ouvertes
L'un des ensembles de données de modération les plus célèbres est l'ensemble de données du Kaggle
Toxic Comment Classification Challenge . Une partie du balisage dans l'ensemble de données est incorrecte: par exemple, les messages contenant des mots obscènes peuvent être marqués comme normaux. Pour cette raison, vous ne pouvez pas simplement participer à des compétitions Kernel et obtenir un algorithme de classification qui fonctionne bien. Vous devez travailler davantage avec les données, voir quels exemples ne suffisent pas et ajouter des données supplémentaires avec de tels exemples.
En plus des concours, il existe plusieurs publications scientifiques avec des liens vers des ensembles de données appropriés (
exemple ), mais toutes ne peuvent pas être utilisées dans des projets commerciaux. La plupart de ces ensembles de données contiennent des messages du réseau social Twitter, où vous pouvez trouver de nombreux tweets toxiques. De plus, des données sont collectées sur Twitter, car certains hashtags peuvent être utilisés pour rechercher et baliser des messages d'utilisateurs toxiques.
Données manuelles
Après avoir collecté l'ensemble de données à partir de sources ouvertes et formé sur celui-ci le modèle de base, il est devenu clair que les données ouvertes ne suffisent pas: la qualité du modèle n'est pas satisfaisante. En plus des données ouvertes pour résoudre le problème, une sélection non allouée de messages d'un messager de jeu avec un grand nombre de messages toxiques était à notre disposition.

Pour utiliser ces données pour leur tâche, ils devaient être étiquetés d'une manière ou d'une autre. À cette époque, il y avait déjà un classificateur de ligne de base formé, que nous avons décidé d'utiliser pour le marquage semi-automatique. Après avoir exécuté tous les messages à travers le modèle, nous avons obtenu les probabilités de toxicité de chaque message et triés par ordre décroissant. Au début de cette liste ont été collectés des messages contenant des mots obscènes et offensants. Au final, au contraire, il y a des messages d'utilisateur normaux. Ainsi, la plupart des données (avec des valeurs de probabilité très grandes et très petites) n'ont pas pu être balisées, mais immédiatement affectées à une certaine classe. Reste à marquer les messages qui sont tombés au milieu de la liste, ce qui a été fait manuellement.
Augmentation des données
Souvent, dans les ensembles de données, vous pouvez voir les messages modifiés sur lesquels le classificateur se trompe et la personne comprend correctement leur signification.
En effet, les utilisateurs s'ajustent et apprennent à tromper les systèmes de modération afin que les algorithmes commettent des erreurs sur les messages toxiques, et que la signification reste claire pour la personne. Ce que les utilisateurs font maintenant:
- les fautes de frappe génèrent: vous êtes tout le cul stupide, vous fack ,
- remplacer les caractères alphabétiques par des nombres similaires dans la description: n1gga, b0ll0cks ,
- insérer des espaces supplémentaires: idiot ,
- supprimer les espaces entre les mots: dieyoustupid .
Afin de former un classificateur résistant à de telles substitutions, vous devez faire comme les utilisateurs: générer les mêmes modifications dans les messages et les ajouter à l'ensemble de formation dans les données principales.
En général, cette lutte est inévitable: les utilisateurs tenteront toujours de trouver des vulnérabilités et des hacks, et les modérateurs implémenteront de nouveaux algorithmes.
Description des sous-tâches
Nous étions confrontés à des sous-tâches pour analyser les messages selon deux modes différents:
- mode en ligne - analyse des messages en temps réel, avec une vitesse de réponse maximale;
- mode hors ligne - analyse des journaux de messages et attribution de dialogues toxiques.
En mode en ligne, nous traitons chaque message utilisateur et l'exécutons à travers le modèle. Si le message est toxique, cachez-le dans l'interface de chat, et si c'est normal, affichez-le. Dans ce mode, tous les messages doivent être traités très rapidement: le modèle doit donner une réponse si rapidement qu'il ne perturbe pas la structure du dialogue entre les utilisateurs.
En mode hors ligne, il n'y a pas de limite de temps pour le travail, et donc je voulais mettre en œuvre le modèle avec la plus haute qualité.
Mode en ligne. Recherche par dictionnaire
Quel que soit le modèle choisi ensuite, nous devons rechercher et filtrer les messages avec des mots obscènes. Pour résoudre ce sous-problème, il est plus facile de compiler un dictionnaire de mots et d'expressions non valides qui ne peuvent pas être ignorés et de rechercher ces mots dans chaque message. La recherche doit être rapide, donc l'algorithme de recherche de sous-chaîne naïve pour cette période ne convient pas. Un algorithme approprié pour trouver un ensemble de mots dans une chaîne est
l'algorithme Aho-Korasik . Grâce à cette approche, il est possible d'identifier rapidement certains exemples toxiques et de bloquer les messages avant qu'ils ne soient transmis à l'algorithme principal. L'utilisation de l'algorithme ML vous permettra de "comprendre la signification" des messages et d'améliorer la qualité de la classification.
Mode en ligne. Modèle d'apprentissage automatique de base
Pour le modèle de base, nous avons décidé d'utiliser une approche standard pour la classification des textes: TF-IDF + algorithme de classification classique. Encore une fois pour des raisons de vitesse et de performances.
TF-IDF est une mesure statistique qui vous permet de déterminer les mots les plus importants pour le texte dans le corps en utilisant deux paramètres: la fréquence des mots dans chaque document et le nombre de documents contenant un mot spécifique (plus en détail
ici ). Après avoir calculé pour chaque mot dans le message TF-IDF, nous obtenons une représentation vectorielle de ce message.
TF-IDF peut être calculé pour les mots du texte, ainsi que pour les mots et les caractères de n grammes. Une telle extension fonctionnera mieux, car elle sera capable de gérer des phrases et des mots fréquents qui n'étaient pas dans l'échantillon de formation (hors vocabulaire).
from sklearn.feature_extraction.text import TfidfVectorizer from scipy import sparse vect_word = TfidfVectorizer(max_features=10000, lowercase=True, analyzer='word', min_df=8, stop_words=stop_words, ngram_range=(1,3)) vect_char = TfidfVectorizer(max_features=30000, lowercase=True, analyzer='char', min_df=8, ngram_range=(3,6)) x_vec_word = vect_word.fit_transform(x_train) x_vec_char = vect_char.fit_transform(x_train) x_vec = sparse.hstack([x_vec_word, x_vec_char])
Exemple d'utilisation de TF-IDF sur n-grammes de mots et de caractèresAprès avoir converti les messages en vecteurs, vous pouvez utiliser n'importe quelle méthode classique de classification:
régression logistique, SVM ,
forêt aléatoire, boosting .
Nous avons décidé d'utiliser la régression logistique dans notre tâche, car ce modèle augmente la vitesse par rapport aux autres classificateurs ML classiques et prédit les probabilités de classe, ce qui vous permet de sélectionner de manière flexible un seuil de classification en production.
L'algorithme obtenu en utilisant TF-IDF et la régression logistique fonctionne rapidement et définit bien les messages avec des mots et des expressions obscènes, mais n'en comprend pas toujours le sens. Par exemple, souvent les messages avec les mots «
noir » et «
féminisme » tombaient dans la classe toxique. Je voulais résoudre ce problème et apprendre à mieux comprendre la signification des messages en utilisant la prochaine version du classificateur.
Mode hors ligne
Afin de mieux comprendre la signification des messages, vous pouvez utiliser des algorithmes de réseau neuronal:
- Intégrations (Word2Vec, FastText)
- Réseaux de neurones (CNN, RNN, LSTM)
- Nouveaux modèles pré-formés (ELMo, ULMFiT, BERT)
Nous allons discuter de certains de ces algorithmes et de la manière dont ils peuvent être utilisés plus en détail.
Word2Vec et FastText
Les modèles d'intégration vous permettent d'obtenir des représentations vectorielles de mots à partir de textes. Il existe
deux types de Word2Vec : Skip-gram et CBOW (Continuous Bag of Words). Dans Skip-gram, le contexte est prédit par le mot, mais dans CBOW, vice versa: le mot est prédit par le contexte.
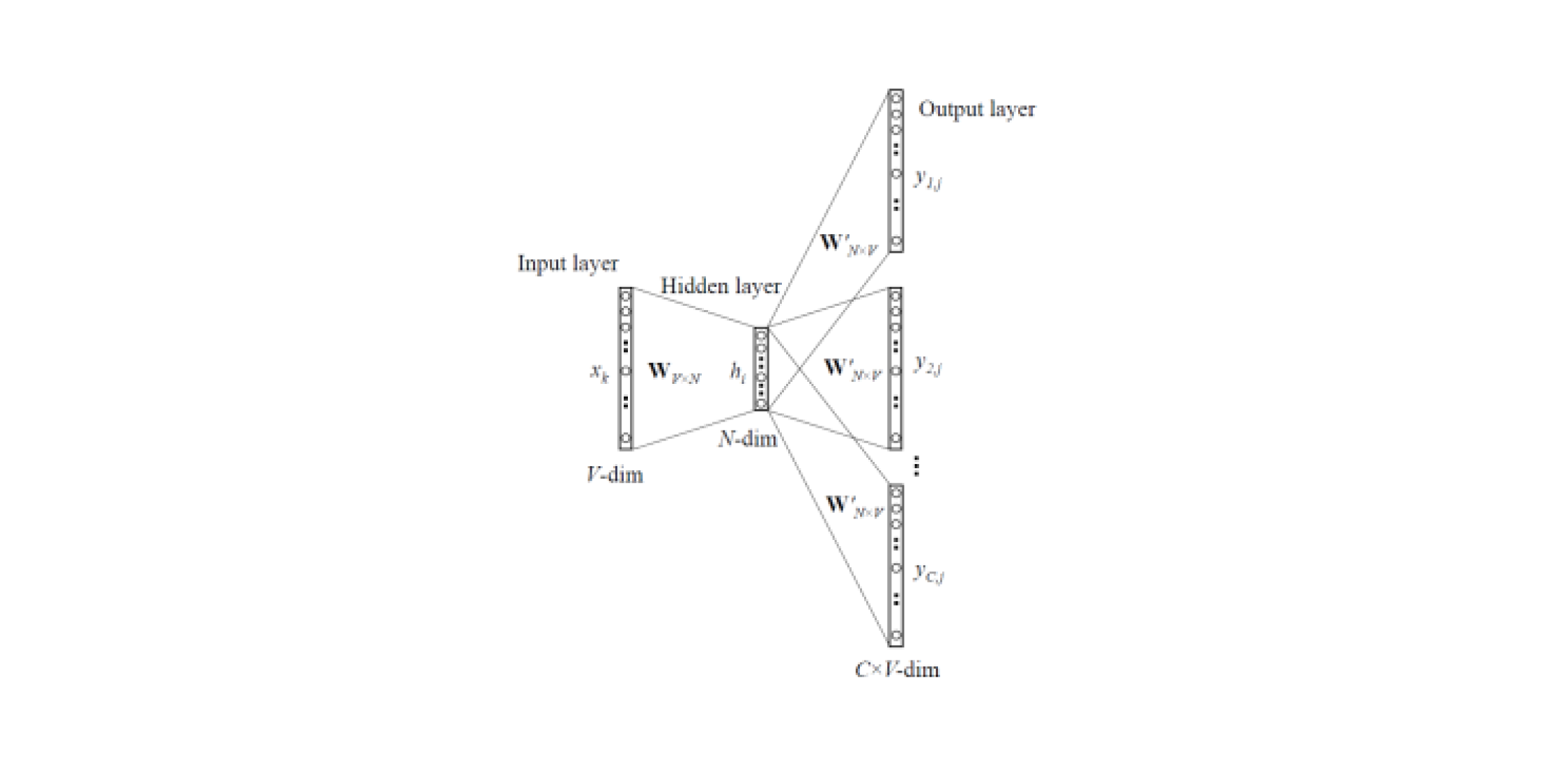
De tels modèles sont formés sur un grand corps de textes et vous permettent d'obtenir des représentations vectorielles de mots à partir d'une couche cachée d'un réseau neuronal formé. L'inconvénient de cette architecture est que le modèle apprend à partir d'un ensemble limité de mots contenus dans le corpus. Cela signifie que pour tous les mots qui n'étaient pas dans le corps des textes au stade de la formation, il n'y aura pas d'intégration. Et cette situation se produit souvent lorsque des modèles pré-formés sont utilisés pour leurs tâches: pour certains mots, il n'y aura pas d'intégration, en conséquence une grande quantité d'informations utiles sera perdue.
Pour résoudre le problème avec des mots qui ne sont pas dans le dictionnaire (OOV, hors vocabulaire), il existe un modèle d'intégration amélioré -
FastText . Au lieu d'utiliser des mots simples pour former le réseau neuronal, FastText décompose les mots en n-grammes (sous-mots) et apprend d'eux. Pour obtenir une représentation vectorielle d'un mot, vous devez obtenir des représentations vectorielles du n-gramme de ce mot et les ajouter.
Ainsi, les modèles Word2Vec et FastText pré-formés peuvent être utilisés pour obtenir des vecteurs de fonctionnalités à partir des messages. Les caractéristiques obtenues peuvent être classées à l'aide de classificateurs ML classiques ou d'un réseau neuronal entièrement connecté.
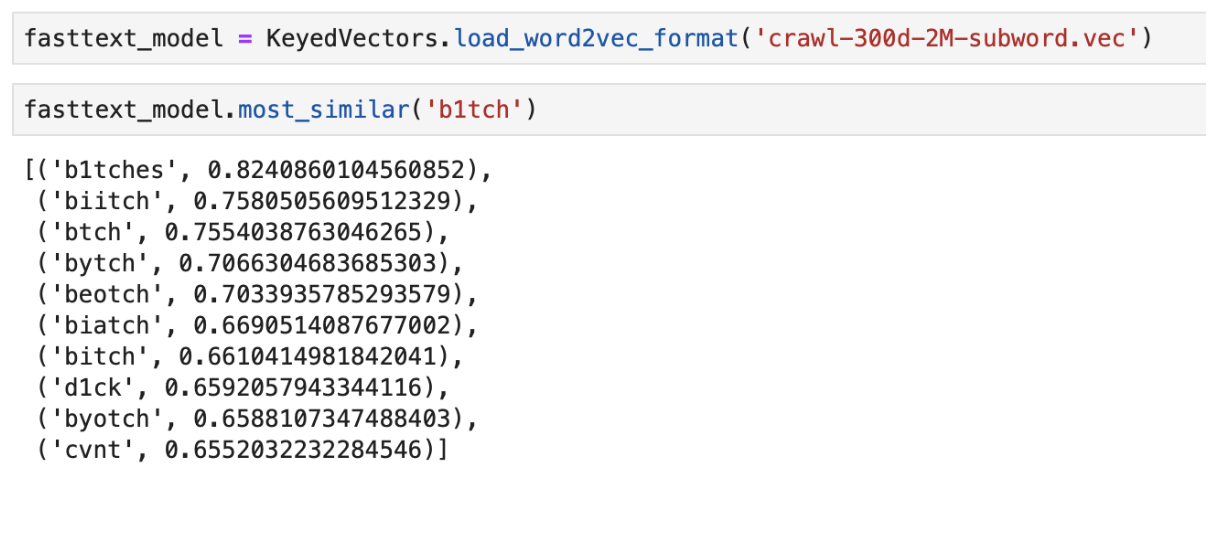 Un exemple de la sortie des mots «le plus proche» dans le sens en utilisant FastText pré- formé
Un exemple de la sortie des mots «le plus proche» dans le sens en utilisant FastText pré- forméClassificateur CNN
Pour le traitement et la classification des textes issus d'algorithmes de réseaux de neurones, les réseaux récurrents (LSTM, GRU) sont plus souvent utilisés, car ils fonctionnent bien avec les séquences. Les réseaux convolutifs (CNN) sont le plus souvent utilisés pour le traitement d'images, mais ils
peuvent également
être utilisés dans la tâche de classification de texte. Considérez comment cela peut être fait.
Chaque message est une matrice dans laquelle sur chaque ligne du jeton (mot) sa représentation vectorielle est écrite. La convolution est appliquée à une telle matrice d'une certaine manière: le filtre de convolution «glisse» sur des lignes entières de la matrice (vecteurs de mots), mais il capture plusieurs mots à la fois (généralement 2 à 5 mots), traitant ainsi les mots dans le contexte des mots voisins. Les détails de la façon dont cela se produit peuvent être vus sur l'
image .
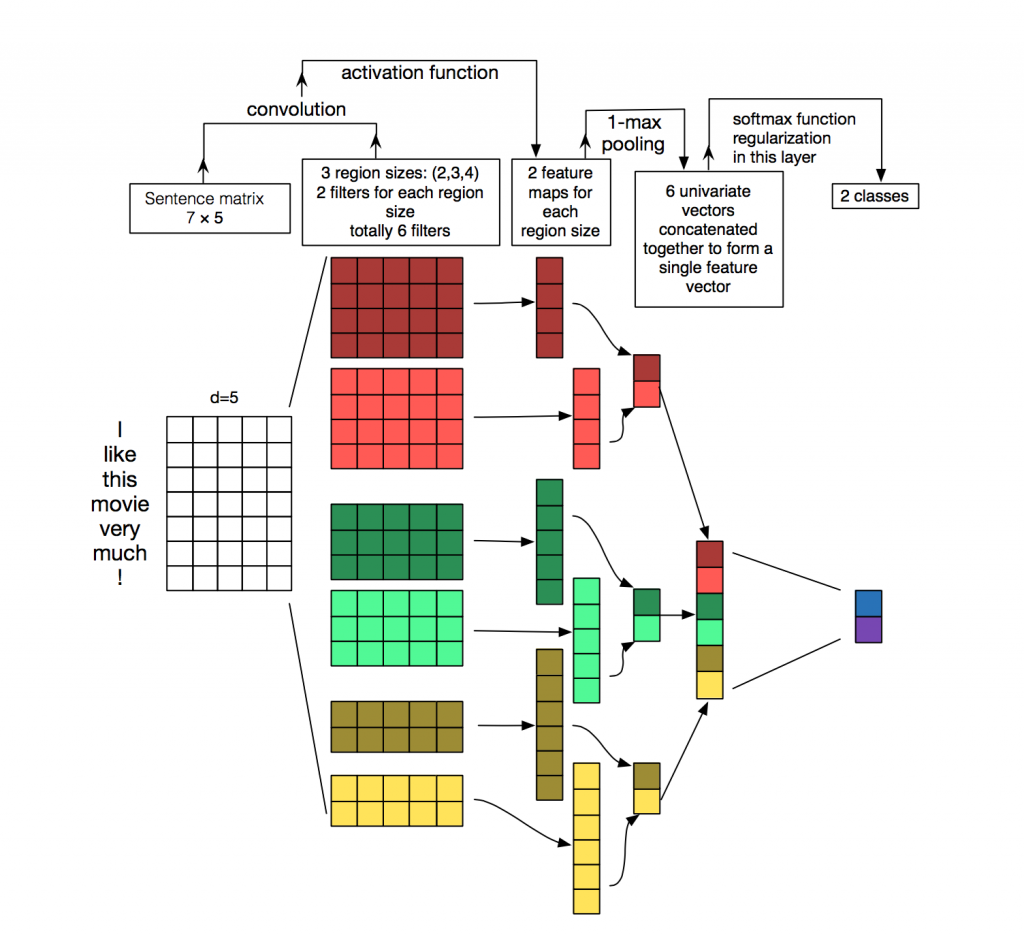
Pourquoi utiliser des réseaux convolutifs pour le traitement de texte alors que vous pouvez utiliser des récurrents? Le fait est que les convolutions fonctionnent beaucoup plus rapidement. En les utilisant pour la classification des messages, vous pouvez gagner beaucoup de temps sur la formation.
ELMo
ELMo (Embeddings from Language Models) est un modèle d'intégration basé sur un modèle de langage
récemment introduit . Le nouveau modèle d'intégration est différent des modèles Word2Vec et FastText. Les vecteurs de mots ELMo présentent certains avantages:
- La présentation de chaque mot dépend du contexte dans lequel il est utilisé.
- La représentation est basée sur des symboles, ce qui permet la formation de représentations fiables pour les mots OOV (hors vocabulaire).
ELMo peut être utilisé pour diverses tâches en PNL. Par exemple, pour notre tâche, les vecteurs de messages reçus à l'aide d'ELMo peuvent être envoyés au classificateur ML classique ou utiliser un réseau convolutionnel ou entièrement connecté.
Les intégrations pré-formées ELMo sont assez simples à utiliser pour votre tâche, un exemple d'utilisation peut être trouvé
ici .
Caractéristiques d'implémentation
API Flask
L'API prototype a été écrite en Flask, car elle est facile à utiliser.
Deux images Docker
Pour le déploiement, nous avons utilisé deux images de docker: celle de base, où toutes les dépendances ont été installées, et la principale pour lancer l'application. Cela économise considérablement du temps d'assemblage, car la première image est rarement reconstruite, et cela permet de gagner du temps lors du déploiement. Beaucoup de temps est consacré à la création et au téléchargement de bibliothèques d'apprentissage automatique, ce qui n'est pas nécessaire à chaque validation.
Test
La particularité de la mise en œuvre d'un assez grand nombre d'algorithmes d'apprentissage automatique est que même avec des métriques élevées sur l'ensemble de données de validation, la qualité réelle de l'algorithme en production peut être faible. Par conséquent, pour tester le fonctionnement de l'algorithme, toute l'équipe a utilisé le bot dans Slack. C'est très pratique, car tout membre de l'équipe peut vérifier la réponse que les algorithmes donnent à un message particulier. Cette méthode de test vous permet de voir immédiatement comment les algorithmes fonctionneront sur les données en direct.
Une bonne alternative est de lancer la solution sur des sites publics comme Yandex Toloka et AWS Mechanical Turk.
Conclusion
Nous avons examiné plusieurs approches pour résoudre le problème de la modération automatique des messages et décrit les caractéristiques de notre implémentation.
Les principales observations obtenues au cours des travaux:
- La recherche de dictionnaire et l'algorithme d'apprentissage automatique basés sur TF-IDF et la régression logistique ont permis de classer les messages rapidement, mais pas toujours correctement.
- Les algorithmes de réseau de neurones et les modèles pré-formés d'intégration peuvent mieux faire face à cette tâche et peuvent déterminer la toxicité au sens du message.
Bien sûr, nous avons publié la
démo ouverte
Poteha Toxic Comment Detection sur le bot
Facebook . Aidez-nous à améliorer le bot!
Je me ferai un plaisir de répondre aux questions dans les commentaires.