
Présentation
Il est temps de parler d'exceptions ou, plutôt, de situations exceptionnelles. Avant de commencer, regardons la définition. Qu'est-ce qu'une situation exceptionnelle?
Il s'agit d'une situation qui rend l'exécution du code actuel ou ultérieur incorrecte. Je veux dire différent de la façon dont il a été conçu ou conçu. Une telle situation compromet l'intégrité d'une application ou de sa partie, par exemple un objet. Il amène l'application dans un état extraordinaire ou exceptionnel.
Mais pourquoi devons-nous définir cette terminologie? Parce que cela nous maintiendra dans certaines limites. Si nous ne suivons pas la terminologie, nous pouvons nous éloigner trop d'un concept conçu qui peut entraîner de nombreuses situations ambiguës. Voyons quelques exemples pratiques:
struct Number { public static Number Parse(string source) { // ... if(!parsed) { throw new ParsingException(); } // ... } public static bool TryParse(string source, out Number result) { // .. return parsed; } }
Cet exemple semble un peu étrange, et c'est pour une raison. J'ai rendu ce code légèrement artificiel pour montrer l'importance des problèmes qui y apparaissent. Tout d'abord, regardons la méthode Parse . Pourquoi devrait-il lever une exception?
- Parce que le paramètre qu'il accepte est une chaîne, mais sa sortie est un nombre, qui est un type de valeur. Ce nombre ne peut pas indiquer la validité des calculs: il existe simplement. En d'autres termes, la méthode n'a aucun moyen dans son interface pour communiquer un problème potentiel.
- D'un autre côté, la méthode attend une chaîne correcte qui contient un certain nombre et aucun caractère redondant. S'il ne contient pas, il y a un problème dans les prérequis de la méthode: le code qui appelle notre méthode a passé des données erronées.
Ainsi, la situation lorsque cette méthode obtient une chaîne avec des données incorrectes est exceptionnelle car la méthode ne peut renvoyer ni une valeur correcte ni rien. Ainsi, la seule façon est de lever une exception.
La deuxième variante de la méthode peut signaler certains problèmes avec les données d'entrée: la valeur de retour ici est boolean qui indique une exécution réussie de la méthode. Cette méthode n'a pas besoin d'utiliser d'exceptions pour signaler des problèmes: elles sont toutes couvertes par la false valeur de retour.
Présentation
La gestion des exceptions peut sembler aussi simple que ABC: il suffit de placer try-catch blocs try-catch et d'attendre les événements correspondants. Cependant, cette simplicité est devenue possible grâce au travail considérable des équipes du CLR et du CoreCLR qui ont unifié toutes les erreurs provenant de toutes les directions et sources dans le CLR. Pour comprendre de quoi nous allons parler ensuite, regardons un schéma:
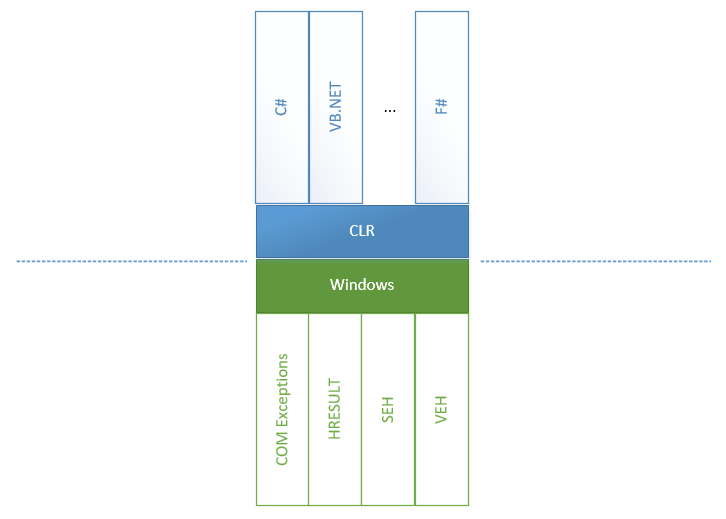
Nous pouvons voir qu'à l'intérieur du grand .NET Framework, il y a deux mondes: tout ce qui appartient à CLR et tout ce qui ne l'est pas, y compris toutes les erreurs possibles apparaissant dans Windows et d'autres parties du monde dangereux.
- La gestion structurée des exceptions (SEH) est une méthode standard utilisée par Windows pour gérer les exceptions. Lorsque des méthodes
unsafe sont appelées et que des exceptions sont levées, il y a une conversion CLR <-> non sûre des exceptions dans les deux sens: de non sécurisé à CLR et inversement. Cela est dû au fait que CLR peut appeler une méthode non sûre qui peut appeler une méthode CLR à son tour. - Le traitement d'exception vectorisé (VEH) est une racine de SEH et vous permet de placer vos gestionnaires dans des endroits où des exceptions peuvent être levées. En particulier, il a été utilisé pour placer
FirstChanceException . - Des exceptions COM + apparaissent lorsque la source d'un problème est un composant COM. Dans ce cas, une couche entre COM et une méthode .NET doit convertir une erreur COM en une exception .NET.
- Et, bien sûr, des emballages pour HRESULT. Ils sont introduits pour convertir un modèle WinAPI (un code d'erreur est contenu dans une valeur de retour, tandis que les valeurs de retour sont obtenues à l'aide des paramètres de méthode) en un modèle d'exceptions car il s'agit d'une exception standard pour .NET.
D'un autre côté, il existe des langages au-dessus de CLI, chacun ayant plus ou moins des fonctions pour gérer les exceptions. Par exemple, récemment VB.NET ou F # avait une fonctionnalité de gestion des exceptions plus riche exprimée dans un certain nombre de filtres qui n'existaient pas en C #.
Codes retour vs. exception
Séparément, je devrais mentionner un modèle de gestion des erreurs d'application à l'aide de codes retour. L'idée de simplement renvoyer une erreur est claire et claire. De plus, si nous traitons les exceptions comme un opérateur goto , l'utilisation de codes retour devient plus raisonnable: dans ce cas, l'utilisateur d'une méthode voit la possibilité d'erreurs et peut comprendre quelles erreurs peuvent survenir. Cependant, ne devinons pas ce qui est mieux et pour quoi, mais discutons du problème du choix en utilisant une théorie bien raisonnée.
Supposons que toutes les méthodes aient des interfaces pour traiter les erreurs. Ensuite, toutes les méthodes devraient ressembler à:
public bool TryParseInteger(string source, out int result); public DialogBoxResult OpenDialogBox(...); public WebServiceResult IWebService.GetClientsList(...); public class DialogBoxResult : ResultBase { ... } public class WebServiceResult : ResultBase { ... }
Et leur utilisation ressemblerait à:
public ShowClientsResult ShowClients(string group) { if(!TryParseInteger(group, out var clientsGroupId)) return new ShowClientsResult { Reason = ShowClientsResult.Reason.ParsingFailed }; var webResult = _service.GetClientsList(clientsGroupId); if(!webResult.Successful) { return new ShowClientsResult { Reason = ShowClientsResult.Reason.ServiceFailed, WebServiceResult = webResult }; } var dialogResult = _dialogsService.OpenDialogBox(webResult.Result); if(!dialogResult.Successful) { return new ShowClientsResult { Reason = ShowClientsResult.Reason.DialogOpeningFailed, DialogServiceResult = dialogResult }; } return ShowClientsResult.Success(); }
Vous pensez peut-être que ce code est surchargé par la gestion des erreurs. Cependant, je voudrais que vous reconsidériez votre position: tout ici est une émulation d'un mécanisme qui lève et gère les exceptions.
Comment une méthode peut-elle signaler un problème? Il peut le faire en utilisant une interface pour signaler les erreurs. Par exemple, dans la méthode TryParseInteger , cette interface est représentée par une valeur de retour: si tout est OK, la méthode retournera true . Si ce n'est pas OK, il retournera false . Cependant, il y a un inconvénient ici: la valeur réelle est retournée via le paramètre de out int result . L'inconvénient est que d'une part la valeur de retour est logiquement et par perception a plus d'essence de "valeur de retour" que celle du paramètre out . D'autre part, nous ne nous soucions pas toujours des erreurs. En effet, si une chaîne destinée à l'analyse provient d'un service qui a généré cette chaîne, nous n'avons pas besoin de la vérifier pour les erreurs: la chaîne sera toujours correcte et bonne pour l'analyse. Cependant, supposons que nous prenions une autre implémentation de la méthode:
public int ParseInt(string source);
Ensuite, il y a une question: si une chaîne contient des erreurs, que doit faire la méthode? Doit-il retourner zéro? Ce ne sera pas correct: il n'y a pas de zéro dans la chaîne. Dans ce cas, nous avons un conflit d'intérêts: la première variante a trop de code, tandis que la deuxième variante n'a aucun moyen de signaler les erreurs. Cependant, il est en fait facile de décider quand utiliser des codes retour et quand utiliser des exceptions.
Si obtenir une erreur est une norme, choisissez un code retour. Par exemple, il est normal qu'un algorithme d'analyse de texte rencontre des erreurs dans un texte, mais si un autre algorithme qui fonctionne avec une chaîne analysée obtient une erreur d'un analyseur, il peut être critique ou, en d'autres termes, exceptionnel.
Try-catch-finally en bref
Un bloc try couvre une section où un programmeur s'attend à obtenir une situation critique qui est traitée comme une norme par du code externe. En d'autres termes, si un code considère que son état interne est incohérent en fonction de certaines règles et lève une exception, un système externe, qui a une vue plus large de la même situation, peut intercepter cette exception à l'aide d'un bloc catch et normaliser l'exécution du code d'application . Ainsi, vous légalisez les exceptions dans cette section de code en les interceptant . Je pense que c'est une idée importante qui justifie l'interdiction de capturer toutes try-catch(Exception ex){ ...} au cas où .
Cela ne signifie pas que la capture d'exceptions contredit certaines idéologies. Je dis que vous ne devez détecter que les erreurs que vous attendez d'une section particulière de code. Par exemple, vous ne pouvez pas vous attendre à tous les types d'exceptions héritées de ArgumentException ou vous ne pouvez pas obtenir NullReferenceException , car cela signifie souvent qu'un problème est plutôt dans votre code que dans celui appelé. Mais il convient de s'attendre à ce que vous ne puissiez pas ouvrir un fichier prévu. Même si vous êtes sûr à 200% que vous pourrez, n'oubliez pas de vérifier.
Le bloc finally est également bien connu. Il convient à tous les cas couverts par try-catch blocs try-catch . À l'exception de plusieurs rares situations spéciales , ce bloc fonctionnera toujours . Pourquoi une telle garantie de performance a-t-elle été introduite? Pour nettoyer les ressources et les groupes d'objets qui ont été alloués ou capturés dans le bloc try et dont ce bloc est responsable.
Ce bloc est souvent utilisé sans bloc catch lorsque nous ne nous soucions pas de l'erreur qui a cassé un algorithme, mais nous devons nettoyer toutes les ressources allouées à cet algorithme. Regardons un exemple simple: un algorithme de copie de fichiers a besoin de deux fichiers ouverts et d'une plage de mémoire pour un tampon de trésorerie. Imaginez que nous avons alloué de la mémoire et ouvert un fichier, mais que nous ne pouvions pas en ouvrir un autre. Pour envelopper tout dans une "transaction" atomiquement, nous mettons les trois opérations dans un seul bloc try (comme variante d'implémentation) avec des ressources finally nettoyées. Cela peut sembler un exemple simplifié mais le plus important est de montrer l'essentiel.
Ce qui manque réellement à C #, c'est un bloc de fault qui est activé chaque fois qu'une erreur se produit. C'est finally comme sous stéroïdes. Si nous avions cela, nous pourrions, par exemple, créer un point d'entrée unique pour enregistrer les situations exceptionnelles:
try { //... } fault exception { _logger.Warn(exception); }
Une autre chose que je devrais toucher dans cette introduction est les filtres d'exception. Ce n'est pas une nouvelle fonctionnalité sur la plate-forme .NET mais les développeurs C # peuvent être nouveaux pour elle: le filtrage des exceptions n'apparaissait que dans v. 6.0. Les filtres doivent normaliser une situation lorsqu'il existe un seul type d'exception combinant plusieurs types d'erreurs. Cela devrait nous aider lorsque nous voulons traiter un scénario particulier, mais devons d'abord attraper tout le groupe d'erreurs et les filtrer plus tard. Bien sûr, je veux dire le code du type suivant:
try { //... } catch (ParserException exception) { switch(exception.ErrorCode) { case ErrorCode.MissingModifier: // ... break; case ErrorCode.MissingBracket: // ... break; default: throw; } }
Eh bien, nous pouvons maintenant réécrire ce code correctement:
try { //... } catch (ParserException exception) when (exception.ErrorCode == ErrorCode.MissingModifier) { // ... } catch (ParserException exception) when (exception.ErrorCode == ErrorCode.MissingBracket) { // ... }
L'amélioration ici n'est pas dans le manque de construction de switch . Je crois que cette nouvelle construction est meilleure à plusieurs égards:
- en utilisant
when pour filtrer, nous capturons exactement ce que nous voulons et c'est juste en termes d'idéologie; - le code devient plus lisible sous cette nouvelle forme. En parcourant le code, notre cerveau peut identifier plus facilement les blocs pour gérer les erreurs car il recherche initialement les
catch et non les switch-case ; - le dernier mais non le moindre: une comparaison préliminaire est AVANT d'entrer dans le bloc de capture. Cela signifie que si nous faisons de fausses suppositions sur des situations potentielles, cette construction fonctionnera plus rapidement que de
switch dans le cas de lever une exception à nouveau.
De nombreuses sources disent que la particularité de ce code est que le filtrage a lieu avant le déroulement de la pile. Vous pouvez le voir dans les situations où il n'y a aucun autre appel, sauf d'habitude entre l'endroit où une exception est levée et l'endroit où la vérification du filtrage se produit.
static void Main() { try { Foo(); } catch (Exception ex) when (Check(ex)) { ; } } static void Foo() { Boo(); } static void Boo() { throw new Exception("1"); } static bool Check(Exception ex) { return ex.Message == "1"; }
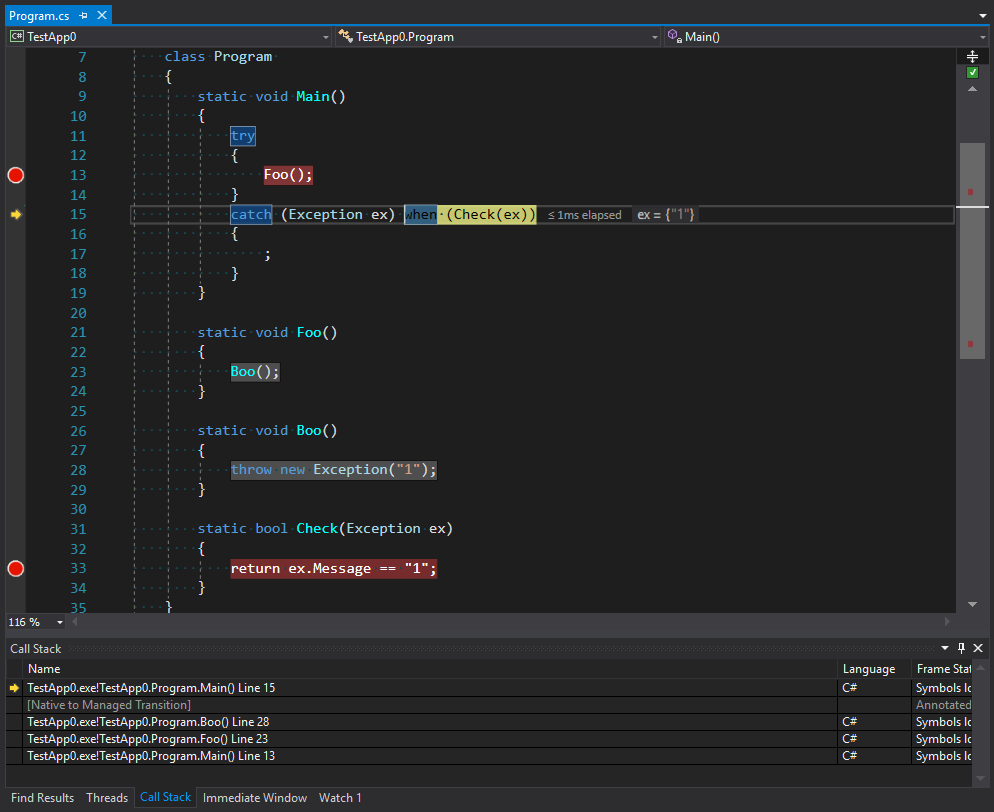
Vous pouvez voir sur l'image que la trace de la pile contient non seulement le premier appel de Main comme point pour intercepter une exception, mais la pile entière avant le point de lever une exception et la seconde entrant dans Main via un code non managé. Nous pouvons supposer que ce code est exactement le code pour lever des exceptions qui est au stade du filtrage et du choix d'un gestionnaire final. Cependant, tous les appels ne peuvent pas être traités sans déroulement de la pile . Je pense qu'une uniformité excessive de la plateforme génère trop de confiance en elle. Par exemple, lorsqu'un domaine appelle une méthode d'un autre domaine, il est absolument transparent en termes de code. Cependant, la façon dont les méthodes appellent le travail est une tout autre histoire. Nous allons en parler dans la prochaine partie.
Sérialisation
Commençons par regarder les résultats de l'exécution du code suivant (j'ai ajouté le transfert d'un appel à travers la frontière entre deux domaines d'application).
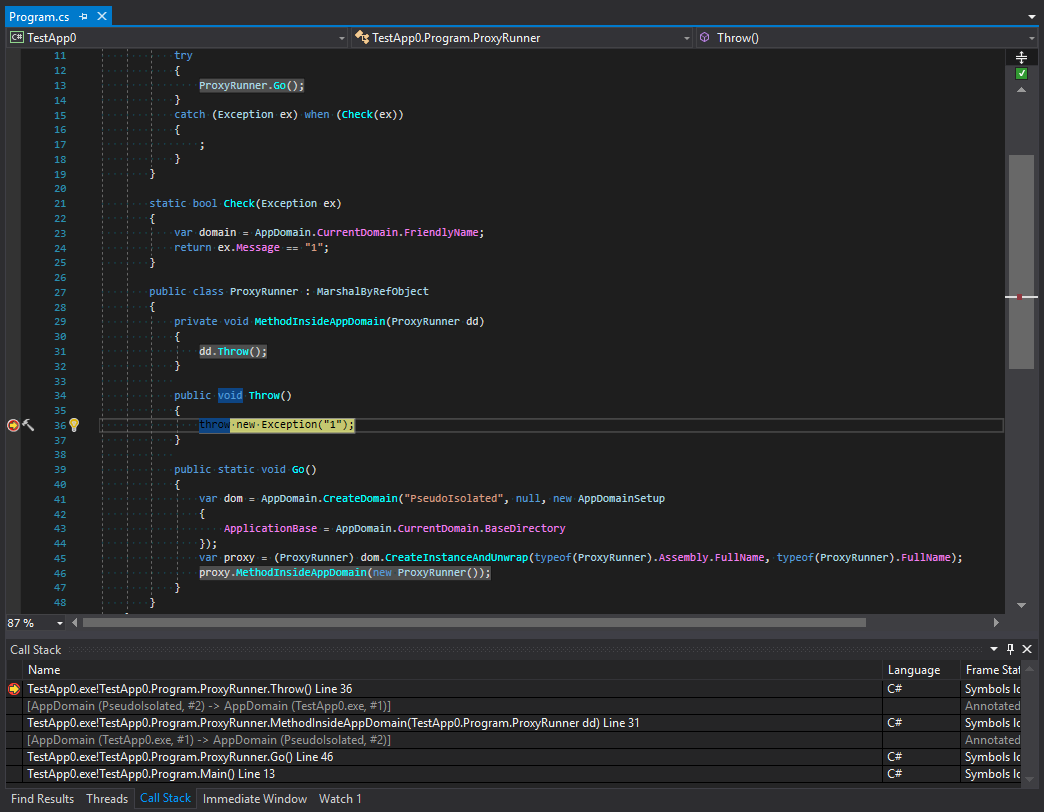
class Program { static void Main() { try { ProxyRunner.Go(); } catch (Exception ex) when (Check(ex)) { ; } } static bool Check(Exception ex) { var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe return ex.Message == "1"; } public class ProxyRunner : MarshalByRefObject { private void MethodInsideAppDomain() { throw new Exception("1"); } public static void Go() { var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup { ApplicationBase = AppDomain.CurrentDomain.BaseDirectory }); var proxy = (ProxyRunner) dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName); proxy.MethodInsideAppDomain(); } } }
Nous pouvons voir que le déroulement de la pile se produit avant d'arriver au filtrage. Regardons les captures d'écran. La première est prise avant la génération d'une exception:
Le second est après:
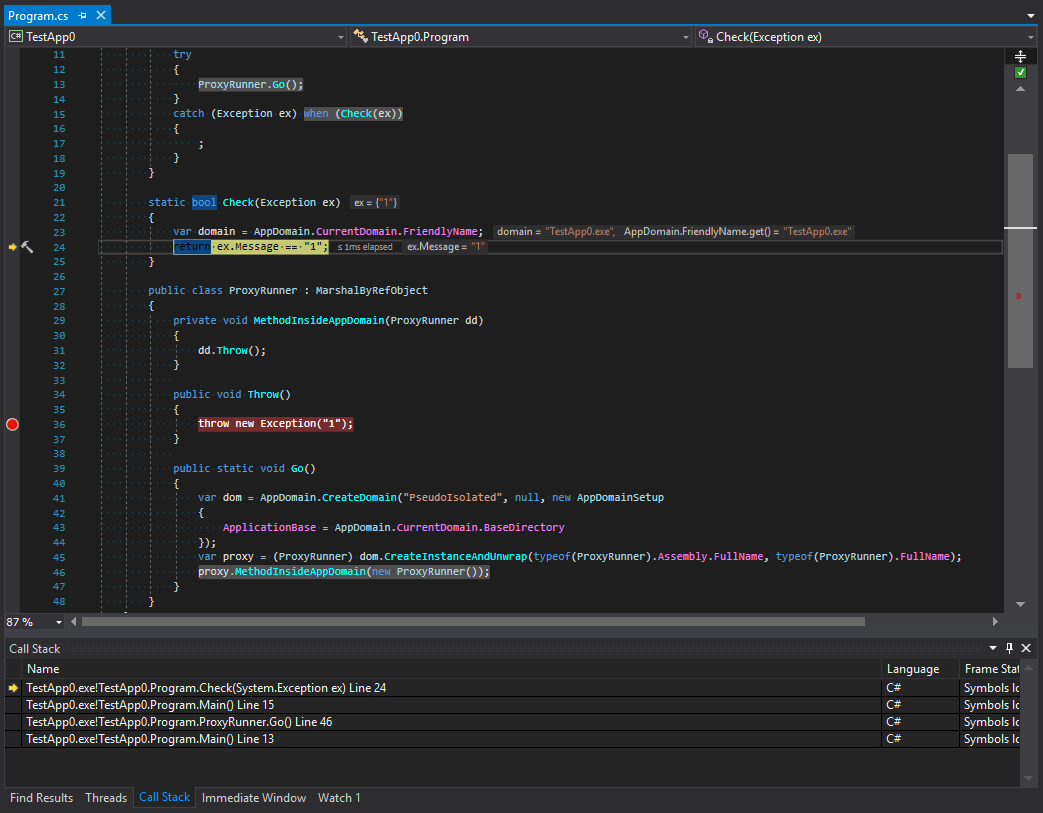
Étudions le suivi des appels avant et après le filtrage des exceptions. Que se passe-t-il ici? Nous pouvons voir que les développeurs de plates-formes ont créé quelque chose qui, à première vue, ressemble à la protection d'un sous-domaine. Le suivi est coupé après la dernière méthode de la chaîne d'appel, puis il y a le transfert vers un autre domaine. Mais je pense que cela semble étrange. Pour comprendre pourquoi cela se produit, rappelons la règle principale pour les types qui organisent l'interaction entre les domaines. Ces types doivent hériter de MarshalByRefObject et être sérialisables. Cependant, malgré la rigueur des types d'exception C #, ils peuvent être de toute nature. Qu'est-ce que cela signifie? Cela signifie que des situations peuvent se produire lorsqu'une exception à l'intérieur d'un sous-domaine peut être interceptée dans un domaine parent. De plus, si un objet de données qui peut entrer dans une situation exceptionnelle a des méthodes dangereuses en termes de sécurité, il peut être appelé dans un domaine parent. Pour éviter cela, l'exception est d'abord sérialisée, puis elle franchit la frontière entre les domaines d'application et réapparaît avec une nouvelle pile. Vérifions cette théorie:
[StructLayout(LayoutKind.Explicit)] class Cast { [FieldOffset(0)] public Exception Exception; [FieldOffset(0)] public object obj; } static void Main() { try { ProxyRunner.Go(); Console.ReadKey(); } catch (RuntimeWrappedException ex) when (ex.WrappedException is Program) { ; } } static bool Check(Exception ex) { var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe return ex.Message == "1"; } public class ProxyRunner : MarshalByRefObject { private void MethodInsideAppDomain() { var x = new Cast {obj = new Program()}; throw x.Exception; } public static void Go() { var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup { ApplicationBase = AppDomain.CurrentDomain.BaseDirectory }); var proxy = (ProxyRunner)dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName); proxy.MethodInsideAppDomain(); } }
Pour que le code C # puisse lever une exception de n'importe quel type (je ne veux pas vous torturer avec MSIL), j'ai exécuté une astuce dans cet exemple en convertissant un type en un type non comparable, afin que nous puissions lever une exception de tout type, mais le traducteur penserait que nous utilisons le type Exception . Nous créons une instance du type Program , qui n'est pas sérialisable à coup sûr, et levons une exception en utilisant ce type comme charge de travail. La bonne nouvelle est que vous obtenez un wrapper pour les exceptions non-exception de RuntimeWrappedException qui stockera une instance de notre objet de type Program intérieur et nous pourrons intercepter cette exception. Cependant, il y a de mauvaises nouvelles qui soutiennent notre idée: appeler proxy.MethodInsideAppDomain(); va générer SerializationException :
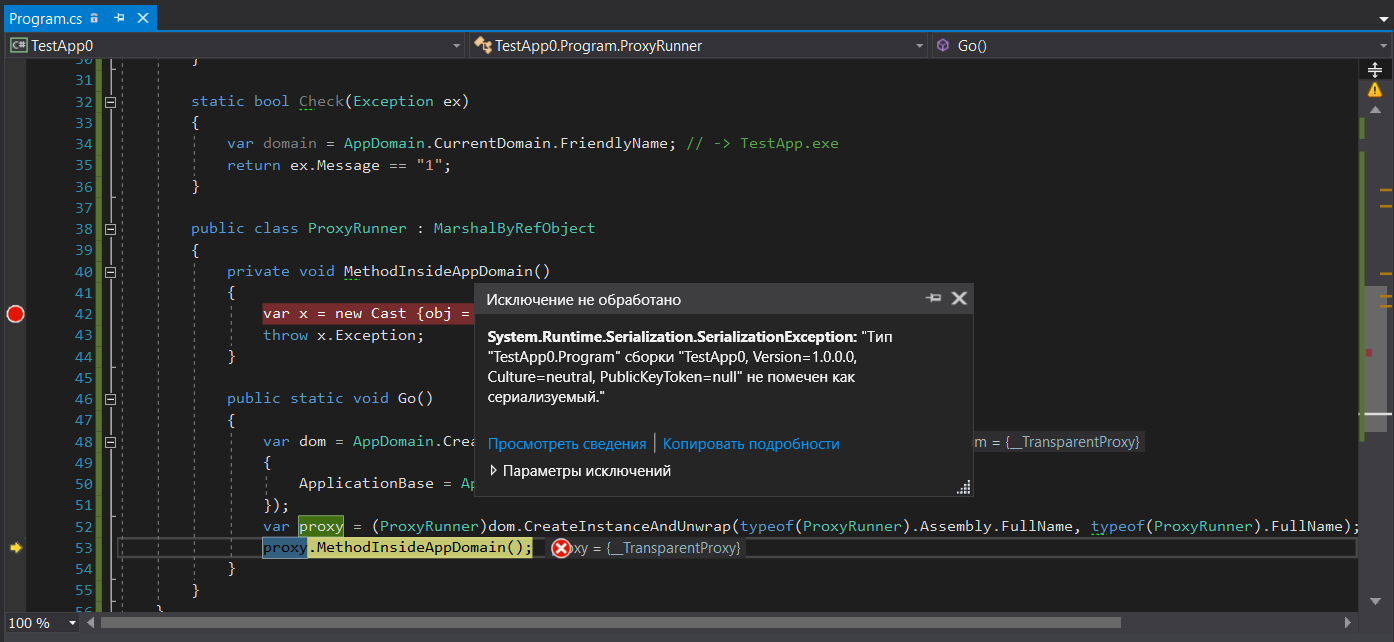
Ainsi, vous ne pouvez pas transférer une telle exception entre des domaines car il n'est pas possible de la sérialiser. Cela, à son tour, signifie que l'utilisation de filtres d'exception pour encapsuler les appels de méthodes dans d'autres domaines entraînera de toute façon un déroulement de la pile malgré le fait que la sérialisation ne semble pas nécessaire avec les paramètres FullTrust d'un sous-domaine.
Nous devons prêter une attention supplémentaire à la raison pour laquelle la sérialisation entre les domaines est si nécessaire. Dans notre exemple artificiel, nous créons un sous-domaine qui n'a pas de paramètres. Cela signifie que cela fonctionne de manière FullTrust. CLR fait entièrement confiance à son contenu et n'exécute aucune vérification supplémentaire. Cependant, lorsque vous insérez au moins un paramètre de sécurité, la confiance totale disparaîtra et CLR commencera à contrôler tout ce qui se passe à l'intérieur d'un sous-domaine. Ainsi, lorsque vous avez un domaine entièrement fiable, vous n'avez pas besoin d'une sérialisation. Admettez, nous n'avons pas besoin de nous protéger. Mais la sérialisation existe non seulement pour la protection. Chaque domaine charge tous les assemblys nécessaires une deuxième fois et crée leurs copies. Ainsi, il crée des copies de tous les types et de tous les VMT. Bien sûr, lorsque vous passez un objet de domaine en domaine, vous obtiendrez le même objet. Mais ses VMT ne seront pas les siens et cet objet ne peut pas être converti en un autre type. En d'autres termes, si nous créons une instance d'un type Boo et l'obtenons dans un autre domaine, le casting de (Boo)boo ne fonctionnera pas. Dans ce cas, la sérialisation et la désérialisation résoudront le problème car l'objet existera dans deux domaines simultanément. Il existera avec toutes ses données là où il a été créé et il existera dans le domaine d'utilisation en tant qu'objet proxy, garantissant que les méthodes d'un objet d'origine sont appelées.
En transférant un objet sérialisé entre domaines, vous obtenez une copie complète de l'objet d'un domaine dans un autre tout en conservant une délimitation en mémoire. Cependant, cette délimitation est fictive. Il est utilisé uniquement pour les types qui ne sont pas dans Shared AppDomain . Ainsi, si vous lancez quelque chose de non sérialisable en tant qu'exception, mais à partir de Shared AppDomain , vous n'obtiendrez pas d'erreur de sérialisation (nous pouvons essayer de lancer Action au lieu de Program ). Cependant, le déroulement de la pile se produira de toute façon dans ce cas: car les deux variantes devraient fonctionner de manière standard. Pour que personne ne soit confus.
 Ce chapitre a été traduit du russe conjointement par l'auteur et par des traducteurs professionnels . Vous pouvez nous aider avec la traduction du russe ou de l'anglais dans n'importe quelle autre langue, principalement en chinois ou en allemand.
Ce chapitre a été traduit du russe conjointement par l'auteur et par des traducteurs professionnels . Vous pouvez nous aider avec la traduction du russe ou de l'anglais dans n'importe quelle autre langue, principalement en chinois ou en allemand.
Aussi, si vous voulez nous remercier, la meilleure façon de le faire est de nous donner une étoile sur github ou sur fork repository  github / sidristij / dotnetbook .
github / sidristij / dotnetbook .