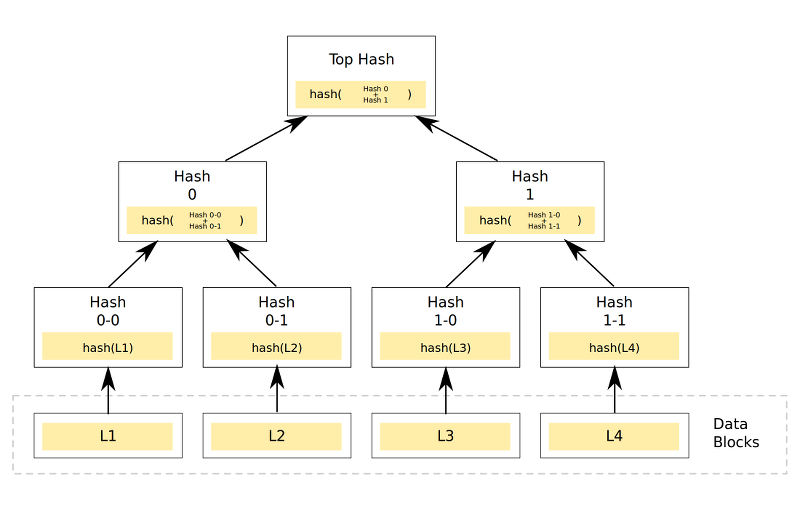
Cet article abordera les outils logiciels de sauvegarde qui, en divisant le flux de données en composants séparés (morceaux), forment un référentiel.
Les composants du référentiel peuvent en outre être compressés et chiffrés, et surtout - avec des processus de sauvegarde répétés - réutilisés à nouveau.
Une sauvegarde dans un référentiel similaire est une chaîne nommée de composants associés, par exemple, basée sur diverses fonctions de hachage.
Il existe plusieurs solutions similaires, je me concentrerai sur 3: zbackup, borgbackup et restic.
Résultats attendus
Étant donné que tous les candidats d'une manière ou d'une autre nécessitent la création d'un référentiel, l'un des facteurs les plus importants sera une estimation de la taille du référentiel. Dans le cas idéal, sa taille ne devrait pas dépasser 13 Go selon la méthodologie acceptée, voire moins - sous réserve d'une bonne optimisation.
Il est également hautement souhaitable de pouvoir sauvegarder des fichiers directement sans utiliser d'archiveurs tar, ainsi que de travailler avec ssh / sftp sans outils supplémentaires tels que rsync et sshfs.
Comportement de sauvegarde:
- La taille du référentiel sera égale ou inférieure à la taille des modifications.
- Une charge de processeur importante est attendue lors de l'utilisation de la compression et / ou du chiffrement, et une charge assez importante sur le sous-système réseau et disque est probable si le processus d'archivage et / ou de chiffrement fonctionne sur le serveur de stockage de sauvegarde.
- Si vous endommagez le référentiel, une erreur retardée est probable à la fois lors de la création de nouvelles sauvegardes et lors de la tentative de restauration. Il est nécessaire de planifier des mesures supplémentaires pour garantir l'intégrité du référentiel ou d'utiliser les moyens intégrés pour vérifier son intégrité.
Le travail avec le goudron est accepté comme valeur de référence, comme cela a été montré dans l'un des articles précédents.
Test de Zbackup
Le mécanisme général de l'opération zbackup est que le programme trouve des zones contenant les mêmes données dans le flux de données fourni à l'entrée, puis il les comprime et les chiffre éventuellement, en n'enregistrant chaque zone qu'une seule fois.
Pour la déduplication, une fonction de hachage en anneau 64 bits avec une fenêtre coulissante est utilisée pour vérifier par octets la coïncidence avec les blocs de données existants (similaire à la façon dont elle est implémentée dans rsync).
Pour la compression, lzma et lzo sont utilisés dans l'exécution multithread et pour le chiffrement - aes. Dans les dernières versions, il est possible à l'avenir de supprimer les anciennes données du référentiel.
Le programme est écrit en C ++ avec des dépendances minimales. L'auteur a apparemment été inspiré par la voie unix, donc le programme reçoit des données sur stdin lors de la création de sauvegardes, donnant un flux de données similaire à stdout lors de la restauration. Ainsi, zbackup peut être utilisé comme une très bonne «brique» lors de l'écriture de vos propres solutions de sauvegarde. Par exemple, l'auteur de l'article, ce programme est le principal outil de sauvegarde pour les machines domestiques depuis environ 2014.
Un tar standard sera utilisé comme flux de données, sauf indication contraire.
Voyons quels seront les résultats:La vérification du travail a été effectuée en 2 versions:
- un référentiel est créé et zbackup est lancé sur le serveur avec les données source, puis le contenu du référentiel est transféré vers le serveur de stockage de sauvegarde.
- un référentiel est créé sur le serveur de stockage de sauvegarde, zbackup est lancé via ssh sur le serveur de stockage de sauvegarde, les données lui sont transmises via pipe.
Les résultats de la première option étaient les suivants: 43m11s - lors de l'utilisation d'un référentiel non chiffré et d'un compresseur lzma, 19m13s - lors du remplacement du compresseur par lzo.
La charge sur le serveur avec les données source était la suivante (l'exemple avec lzma est montré, avec lzo il y avait environ la même image, mais la proportion de rsync était environ un quart du temps):
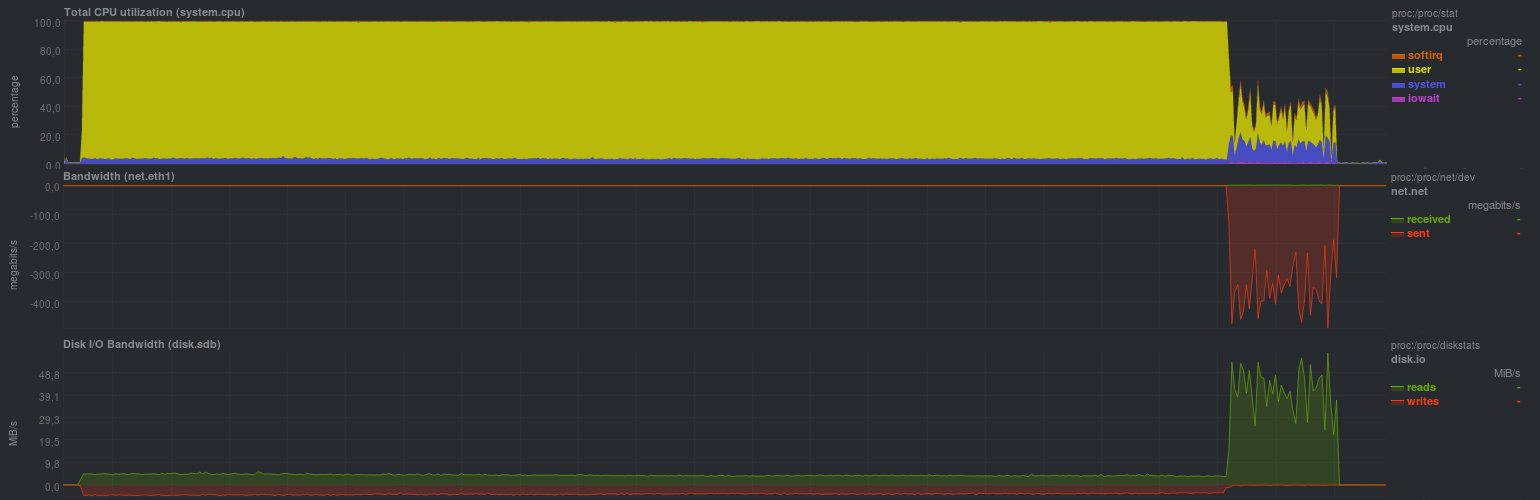
Il est clair qu'un tel processus de sauvegarde ne convient que pour des modifications relativement rares et légères. Il est également très souhaitable de limiter le fonctionnement de zbackup à 1 thread, sinon il y aura une charge de processeur très élevée, car le programme est très bon pour travailler dans plusieurs threads. La charge du disque était petite, ce qui, en général, avec un sous-système de disque ssd moderne, ne sera pas perceptible. Vous pouvez également voir clairement le début du processus de synchronisation des données du référentiel avec un serveur distant, la vitesse est comparable à rsync standard et dépend des performances du sous-système de disque du serveur de stockage de sauvegarde. L'inconvénient de l'approche est le stockage du référentiel local et, par conséquent, la duplication des données.
Plus intéressante et pratique en pratique, la deuxième option consiste à exécuter zbackup immédiatement sur le serveur de stockage de sauvegarde.
Tout d'abord, nous allons vérifier le fonctionnement sans utiliser de cryptage avec le compresseur lzma:
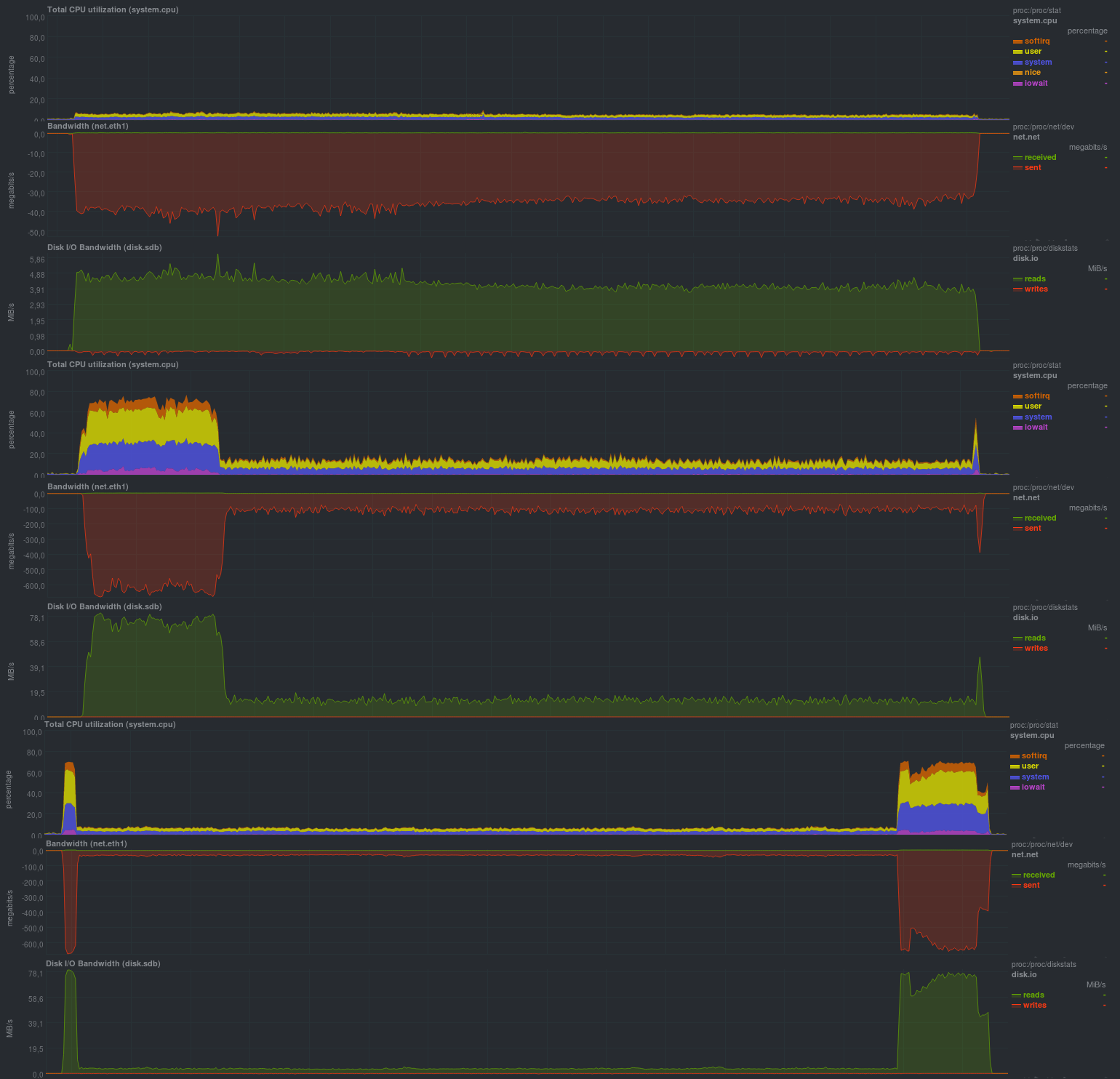
Le temps d'exécution de chaque test:
Si vous activez le chiffrement en utilisant aes, les résultats sont assez proches:
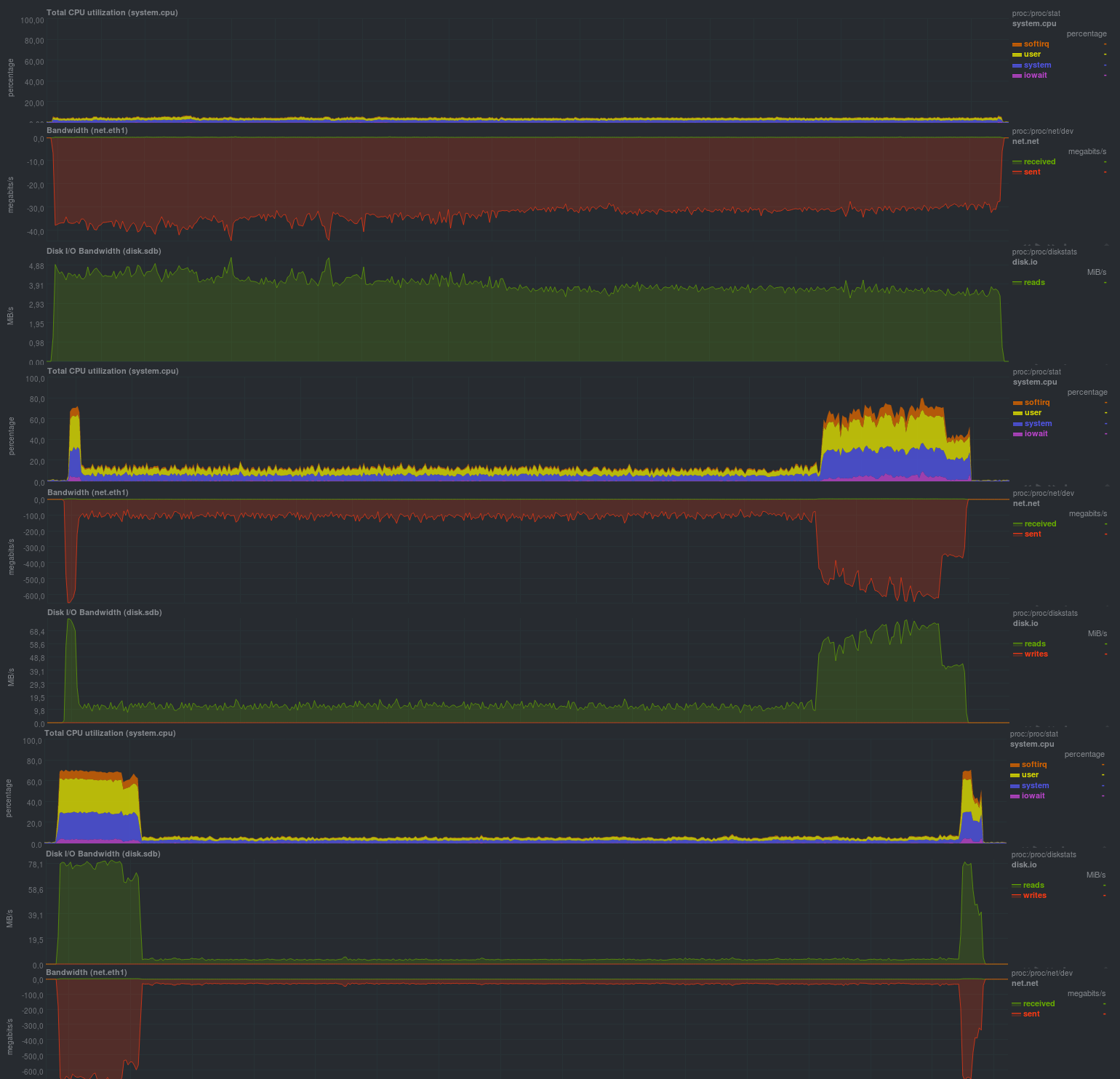
Temps de fonctionnement sur les mêmes données, avec cryptage:
Si le cryptage est combiné avec la compression sur lzo, cela se passe comme suit:
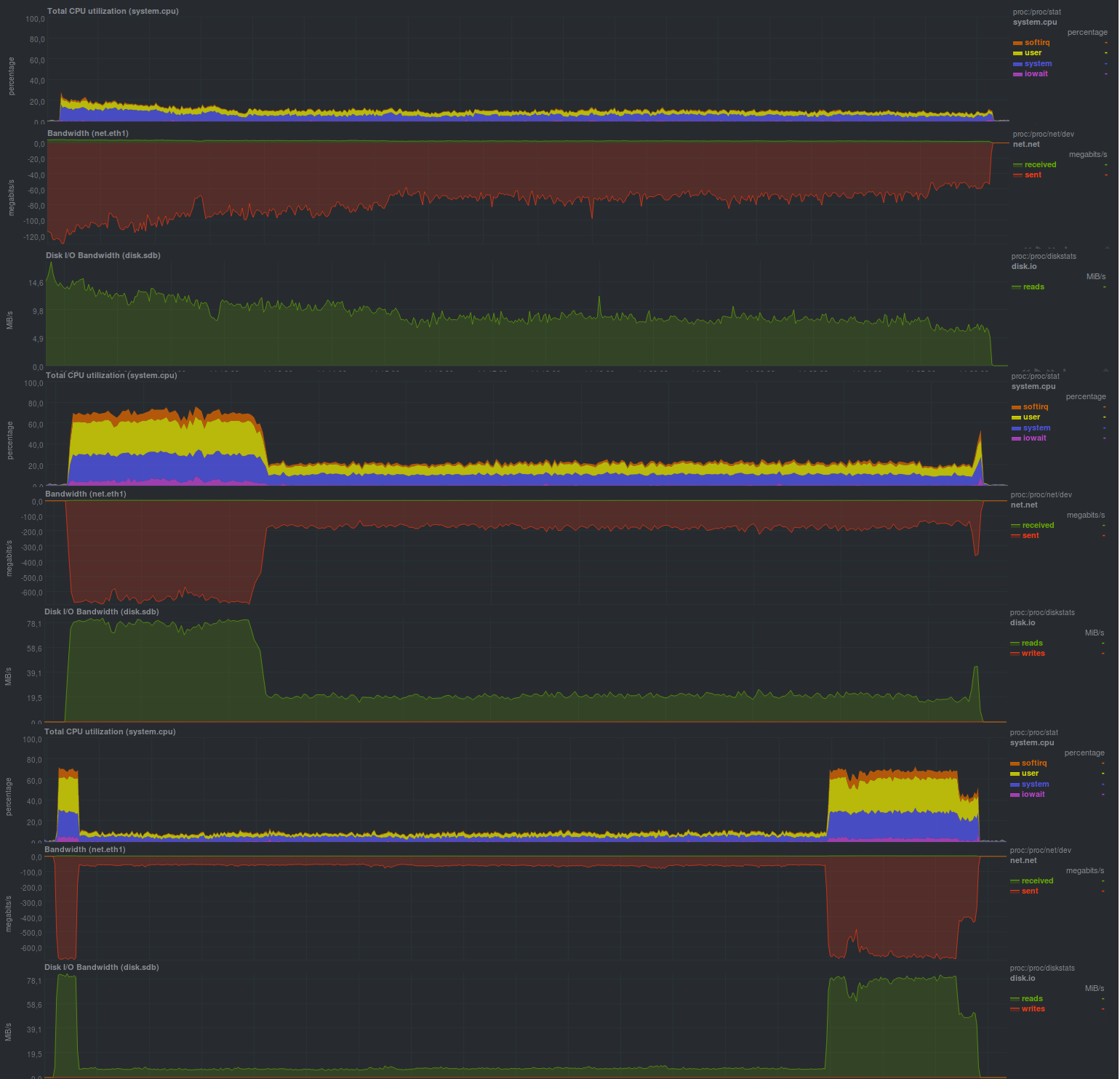
Temps de travail:
La taille du référentiel résultant était relativement la même et s'élevait à 13 Go. Cela signifie que la déduplication fonctionne correctement. De plus, sur des données déjà compressées, l'utilisation de lzo donne un effet tangible, en termes de temps de fonctionnement total, zbackup se rapproche de la duplicité / duplicati, cependant, il est 2 à 5 fois plus lent que ceux basés sur librsync.
Les avantages sont évidents: économiser de l'espace disque sur le serveur de stockage de sauvegarde. Quant aux outils de vérification du référentiel - ils ne sont pas fournis par zbackup, il est recommandé d'utiliser une baie de disques à sécurité intégrée ou un fournisseur de cloud.
En général, une très bonne impression, malgré le fait que le projet est en place depuis environ 3 ans (la dernière demande de fonctionnalité remonte à environ un an, mais sans réponse).
Test de borgbackup
Borgbackup est une fourche de grenier, un autre système de type zbackup. Il est écrit en python, possède une liste de fonctionnalités similaires à zbackup, mais sait en outre comment:
- Montez les sauvegardes via un fusible
- Vérifier le contenu du référentiel
- Travailler en mode client-serveur
- Utilisez divers compresseurs pour les données, ainsi que la définition heuristique du type de fichier lors de la compression.
- 2 options de cryptage, aes et blake
- Outil intégré pour
contrôles de performanceborgbackup benchmark crud ssh: // backup_server / repo / path local_dir
Les résultats sont les suivants:
CZ-BIG 96,51 Mo / s (10 fichiers 100,00 Mo à zéro: 10,36 s)
RZ-BIG 57,22 Mo / s (10 fichiers 100,00 Mo tous à zéro: 17,48 s)
UZ-BIG 253,63 Mo / s (10 fichiers 100,00 Mo à zéro nul: 3,94 s)
DZ-BIG 351,06 Mo / s (10 fichiers 100,00 Mo à zéro: 2,85 s)
CR-BIG 34,30 Mo / s (10 fichiers aléatoires 100,00 Mo: 29,15 s)
RR-BIG 60,69 Mo / s (10 fichiers aléatoires 100,00 Mo: 16,48 s)
UR-BIG 311,06 Mo / s (10 fichiers aléatoires 100,00 Mo: 3,21 s)
DR-BIG 72,63 Mo / s (10 fichiers aléatoires 100,00 Mo: 13,77 s)
CZ-MEDIUM 108,59 Mo / s (1000 fichiers à zéro de 1,00 Mo: 9,21 s)
RZ-MEDIUM 76,16 Mo / s (1000 fichiers 1,00 Mo à zéro absolu: 13,13 s)
UZ-MEDIUM 331,27 Mo / s (1000 fichiers à zéro 1,00 Mo: 3,02 s)
DZ-MEDIUM 387,36 Mo / s (1000 fichiers à zéro de 1,00 Mo: 2,58 s)
CR-MEDIUM 37,80 Mo / s (1000 fichiers aléatoires de 1,00 Mo: 26,45 s)
RR-MEDIUM 68,90 Mo / s (1000 fichiers aléatoires de 1,00 Mo: 14,51 s)
UR-MEDIUM 347,24 Mo / s (1000 fichiers aléatoires de 1,00 Mo: 2,88 s)
DR-MEDIUM 48,80 Mo / s (1000 fichiers aléatoires de 1,00 Mo: 20,49 s)
CZ-SMALL 11,72 Mo / s (10000 fichiers à zéro de 10 000 ko: 8,53 s)
RZ-SMALL 32,57 Mo / s (10000 fichiers à zéro de 10 000 ko: 3,07 s)
UZ-SMALL 19,37 Mo / s (10000 fichiers à zéro de 10 000 ko: 5,16 s)
DZ-SMALL 33,71 Mo / s (10000 fichiers à zéro de 10 000 ko: 2,97 s)
CR-SMALL 6,85 Mo / s (10000 fichiers aléatoires de 10 000 ko: 14,60 s)
RR-SMALL 31,27 Mo / s (10000 fichiers aléatoires de 10 000 ko: 3,20 s)
UR-SMALL 12,28 Mo / s (10000 fichiers aléatoires de 10 000 ko: 8,14 s)
DR-SMALL 18,78 Mo / s (10000 fichiers aléatoires de 10 000 Ko: 5,32 s)
Lors des tests, l'heuristique sera utilisée en compression avec la définition du type de fichier (compression auto), et les résultats seront les suivants:
Tout d'abord, vérifiez l'opération sans chiffrement: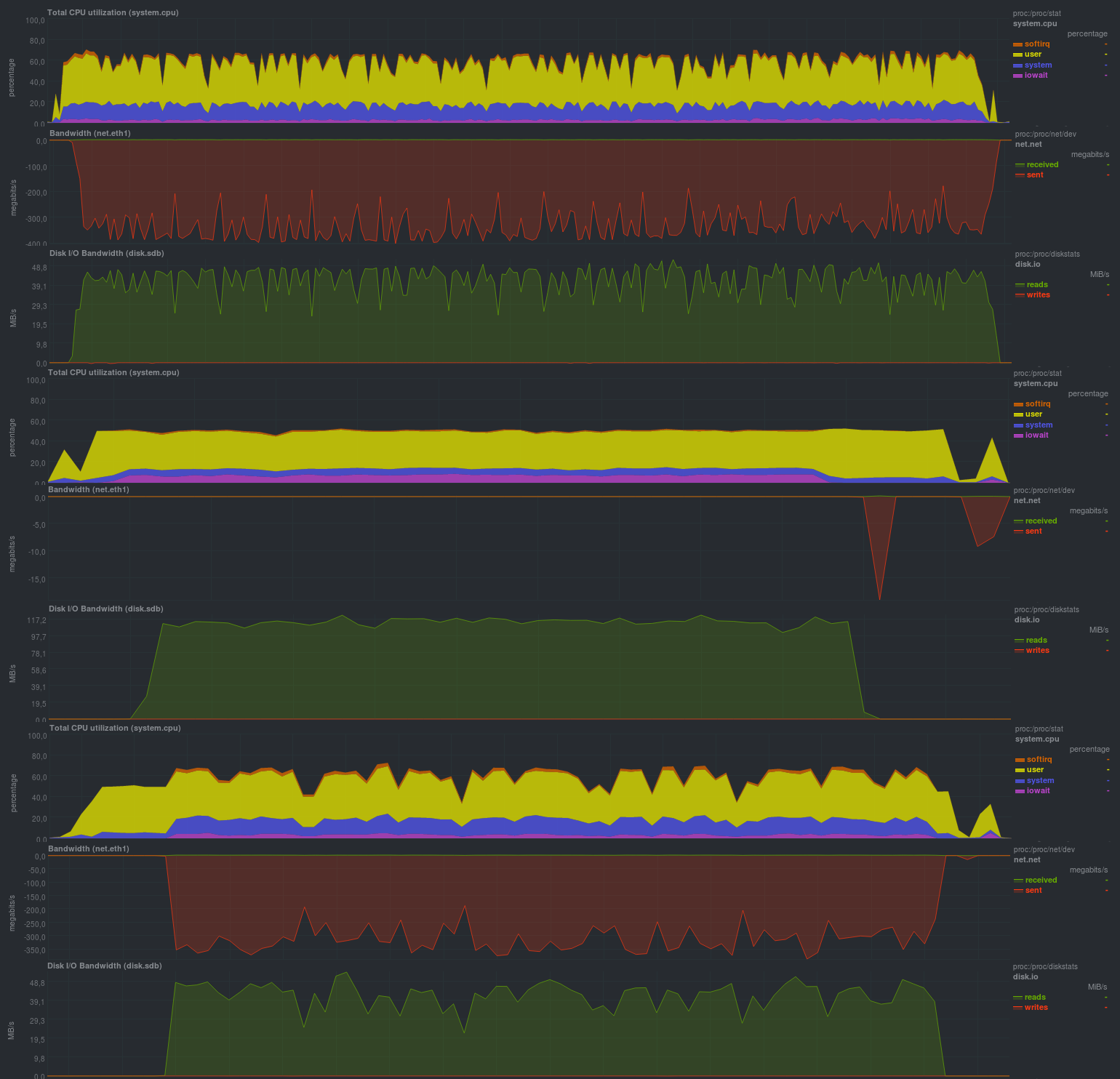
Temps de travail:
Si vous activez l'autorisation du référentiel (mode authentifié), les résultats seront proches:
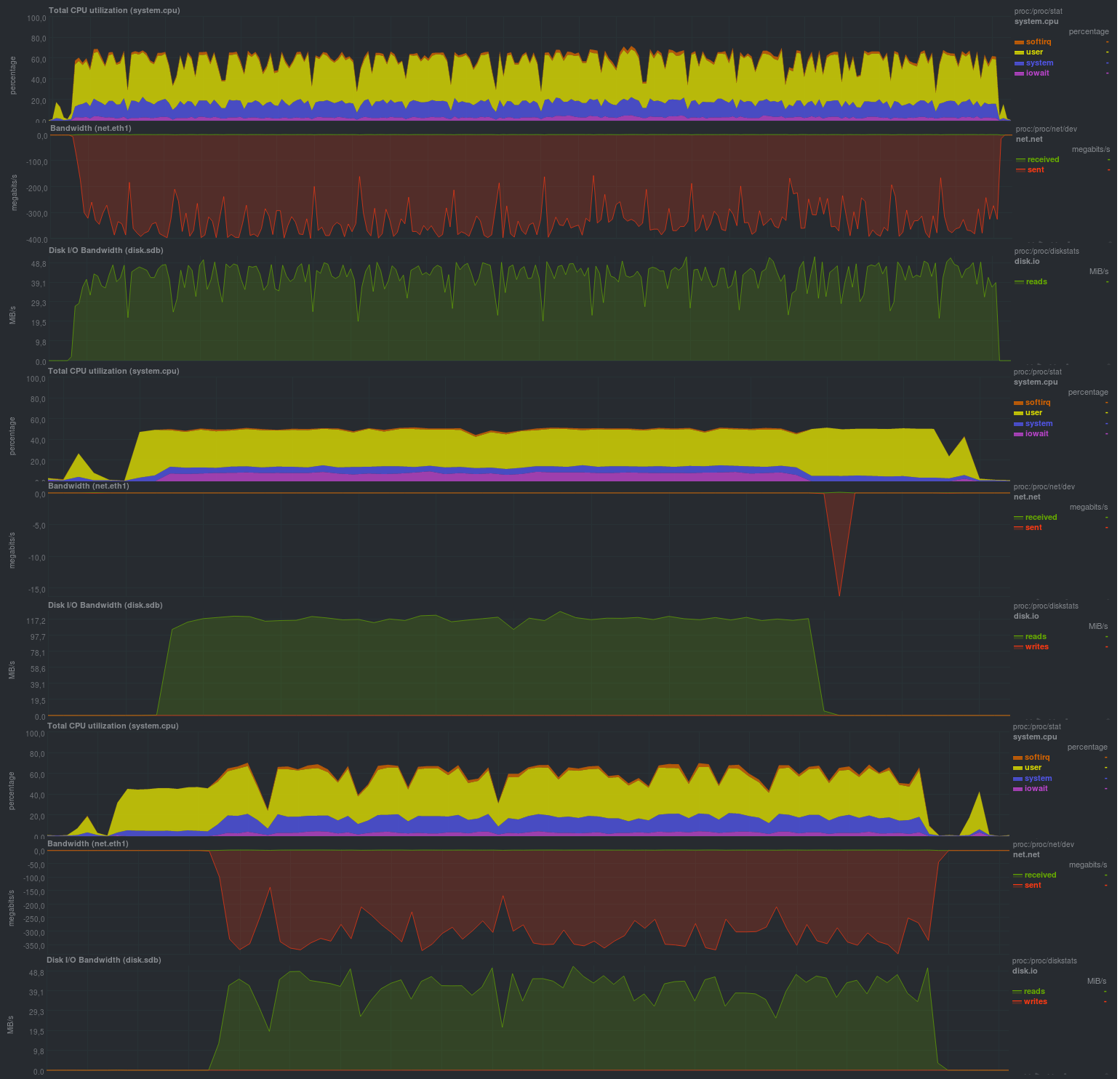
Temps de travail:
Lorsque le cryptage aes a été activé, les résultats ne se sont pas beaucoup détériorés:

Et si vous changez aes en blake, la situation s'améliorera complètement:
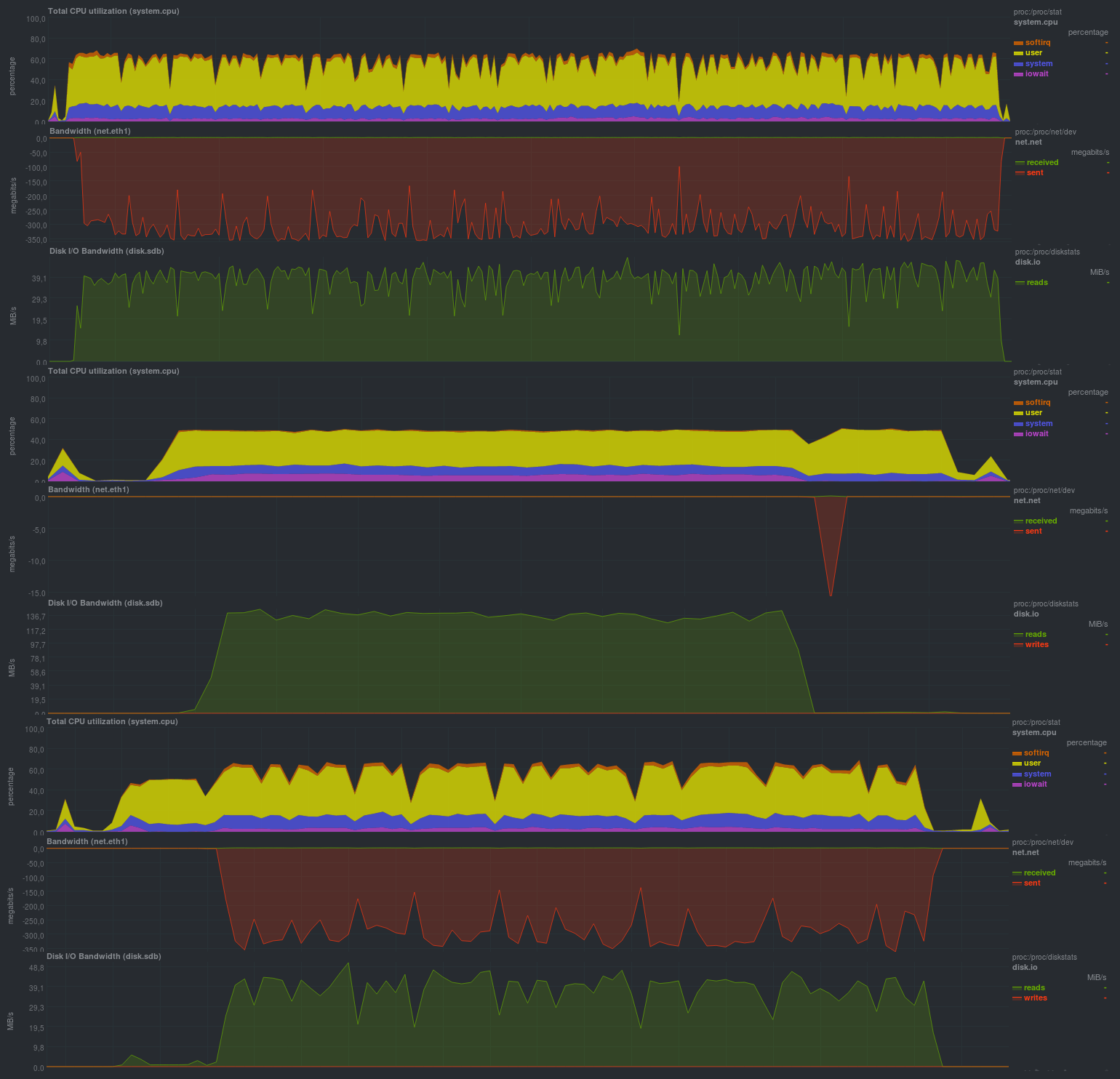
Temps de travail:
Comme dans le cas de zbackup, la taille du référentiel était de 13 Go et même légèrement moins, ce qui, en général, est attendu. Le temps de travail était très heureux, il est comparable aux solutions basées sur librsync, offrant des possibilités beaucoup plus larges. J'ai également été satisfait de la possibilité de définir divers paramètres via des variables d'environnement, ce qui donne un avantage très sérieux lors de l'utilisation de borgbackup en mode automatique. Également satisfait de la charge lors de la sauvegarde: à en juger par la charge du processeur - borgbackup fonctionne sur 1 thread.
Il n'y avait aucun inconvénient spécial lors de l'utilisation.
Test de restic
Malgré le fait que le restic soit une solution assez nouvelle (les 2 premiers candidats sont connus depuis 2013 et plus), il présente de très bonnes caractéristiques. Écrit en Go.
Par rapport à zbackup, il donne en outre:
- Vérification de l'intégrité du référentiel (y compris les pièces d'archivage).
- Une énorme liste de protocoles et de fournisseurs pris en charge pour le stockage des sauvegardes, ainsi que la prise en charge de rclone - rsync pour les solutions cloud.
- Comparaison de 2 sauvegardes entre elles.
- Montage du référentiel via un fusible.
En général, la liste des possibilités est assez proche de borgbackup, à certains endroits plus, à certains endroits moins. Parmi les fonctionnalités - le manque de capacité à désactiver le cryptage, et donc les sauvegardes seront toujours cryptées. Voyons en pratique ce que vous pouvez retirer de ce logiciel:
Les résultats sont les suivants: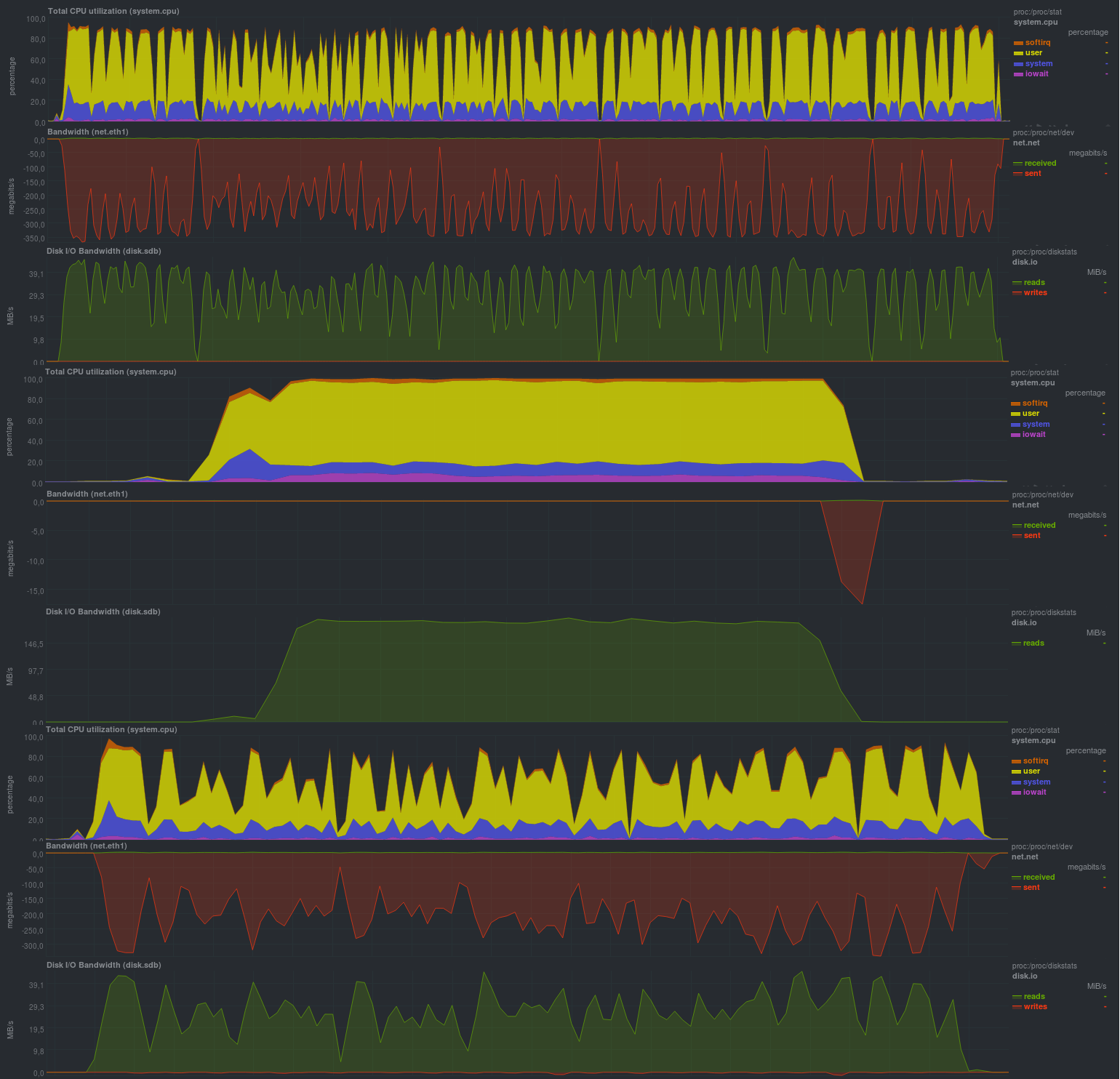
Temps de travail:
Les résultats sont également comparables aux solutions basées sur rsync et, en général, sont très proches de borgbackup, mais la charge du processeur est plus élevée (plusieurs threads fonctionnent) et en dents de scie.
Très probablement, le programme dépend des performances du sous-système de disque sur le serveur de stockage, comme c'était le cas avec rsync. La taille du référentiel était de 13 Go, tout comme zbackup ou borgbackup, il n'y avait aucun inconvénient évident lors de l'utilisation de cette solution.
Résultats
En fait, tous les candidats ont obtenu des indicateurs proches, mais à un prix différent. Borgbackup s'est révélé être le meilleur, un peu plus lent - restique, zbackup, vous ne devriez probablement pas commencer à postuler,
et s'il est déjà utilisé, essayez de passer à borgbackup ou restic.
Conclusions
La solution la plus prometteuse est restée c'est lui qui a le meilleur rapport capacités / vitesse, mais pour l'instant nous ne nous précipiterons pas vers des conclusions générales.
Borgbackup, en principe, n'est pas pire, mais zbackup est probablement mieux à remplacer. Cependant, pour garantir le fonctionnement de la règle 3-2-1, zbackup peut toujours être utilisé. Par exemple, en plus des outils de sauvegarde basés sur (lib) rsync.
Annonce
Sauvegarde, partie 1: Pourquoi avez-vous besoin d'une sauvegarde, un aperçu des méthodes, des technologies
Sauvegarde, Partie 2: Présentation et test des outils de sauvegarde basés sur rsync
Sauvegarde, Partie 3: Présentation et test de la duplicité, duplicati
Sauvegarde, Partie 4: Présentation et test de zbackup, restic, borgbackup
Sauvegarde, Partie 5: Test de Bacula et Veeam Backup pour Linux
Sauvegarde: pièce demandée par les lecteurs: revue AMANDA, UrBackup, BackupPC
Sauvegarde, partie 6: comparaison des outils de sauvegarde
Sauvegarde, partie 7: Conclusions
Publié par Finnix